
BROWSING A STRUCTURED MULTIMEDIA REPOSITORY
Rui Lopes and Lu
´
ıs Carric¸o
LaSIGE, University of Lisbon, Edif
´
ıcio C6, Campo Grande, 1749-016 Lisboa, Portugal
Keywords:
Multimedia Repository, Hypermedia, Semantic Browsing, Web User Interfaces.
Abstract:
Browsing large amounts of assorted multimedia poses several challenges on creating a supporting user in-
terface. Even further, if metadata, structures and relations are defined on top of multimedia fragments, the
complexity of a multimedia repository increases. However, this is also a path for exploiting new browsing
mechanisms. This paper presents insights on which aspects should be available on a task-oriented user in-
terface for browsing a structured multimedia repository, centred on speeding up interaction through media
independent navigation schemes and user advisory.
1 INTRODUCTION
Digital media support changed radically the way in-
formation is consumed. Nowadays, accessing dig-
ital contents is a common task, especially through
the Web and its overwhelming size. Also, recent
trends give the user an active role on producing con-
tents on different media (blogs, photographs, pod-
casts, videos) and establishing relations between me-
dia components, instead of just passively consuming
information.
With such a massive amount of information avail-
able, new challenges arise. Recent efforts (Berners-
Lee et al., 2001) envision a Web of semantically de-
scribed information, to be shared by different appli-
cations. With this framework, pieces of information
can be mixed, repurposed, and interlinked accord-
ing to different criteria (such as complementing an
e-learning environment with content from an online
encyclopedia).
To support such scenarios, there is a need for a
storage and retrieval capable repository for multime-
dia contents, metadata, and relationships. Ever fur-
ther, these contents should not be perceived as black-
boxed pieces of information. With the imposition of
content structuring, each fragment may have its own
semantics associated, allowing for its reuse in other
contexts.
In such a repository it is critical to have a large and
rich multimedia corpora, and its corresponding meta-
data and relations. To enable this, some tasks can
be automated (e.g., crawling for new content, infer
knowledge), but some tasks may only be performed
by humans (e.g, fixing incorrect information origi-
nated from automation).
To cope with the amount of contents and the com-
plexity inherent of having metadata and relations in
the repository, its management user interface must be
carefully crafted. This paper discusses these browsing
aspects in a web-based interface for managing a struc-
tured multimedia repository that supports the storage
and description of multimedia information fragments.
2 GOALS AND REQUIREMENTS
The effectiveness of the user interface for browsing a
structured multimedia repository is based on achiev-
ing the following set of goals:
• Simple user interface: as a huge amount of con-
tents may need manual editing of their corre-
sponding metadata, the user interface must not be
an obstacle on performing these tasks;
• Ease browsing of multimedia fragments: brows-
ing tasks should be centred around content frag-
429
Lopes R. and Carriço L. (2007).
BROWSING A STRUCTURED MULTIMEDIA REPOSITORY.
In Proceedings of the Third International Conference on Web Information Systems and Technologies - Web Interfaces and Applications, pages 429-432
DOI: 10.5220/0001282404290432
Copyright
c
SciTePress
ments, their siblings, children, etc.;
• Alternate navigation methods: having different
methods for browsing the repository allows the
user to select the best way for finding or reaching
some multimedia content;
• Overall views: providing an overall view of the
repository’s contents helps the user to choose
what tasks have to be performed;
• Advice to the user: the user must be advised with
some pointers that otherwise would take too long
to be found through exploration;
• Collaboration: the user interface has to promote
multi-user activities, as a single user is unable to
perform all required tasks.
These goals can only be achieved by fulfilling the
following set of requirements:
• Large scale: the repository requires efficient
forms for visualizing and browsing multimedia
contents, as traditional efforts are geared towards
single media types, or do not scale up;
• Multitasking: many tasks in the repository may
trigger actions that will take some time to com-
plete (e.g., uploading a video). This time can be
used to perform other tasks;
• Media agnostic: the browsing capabilities should
be independent from media types, resulting in a
coherent user interface where users will perform
better on any task;
• Cope with structures and relations: as the reposi-
tory also contains structures and relations, these
concerns should be explicitly present on the
browsing interface;
• Filtering: the browsing interface should provide
means for narrowing the browsable set of contents
through filtering.
3 RELATED WORK
Typically, multimedia browsing is centred either on
a single media type (H
¨
urst and Stiegeler, 2002; Al-
banese et al., 2004). The fact that real scenarios must
take into account all media types, poses severe dif-
ficulties on interacting with a multimedia repository.
Even further, search tasks consume more time, as the
user has to perceive the semantics of each content (in-
stead of using metadata to provide this information
instantly).
Recent studies (Lew et al., 2006) on content-based
multimedia information retrieval have identified what
challenges have not been achieved: creating new hu-
man centred methods based on exploratory interac-
tion; enforce collaboration efforts; and provide mul-
timedia assets taxonomic classification and browsing.
Consequently, the architecture for a new multimedia
repository must take into account these challenges.
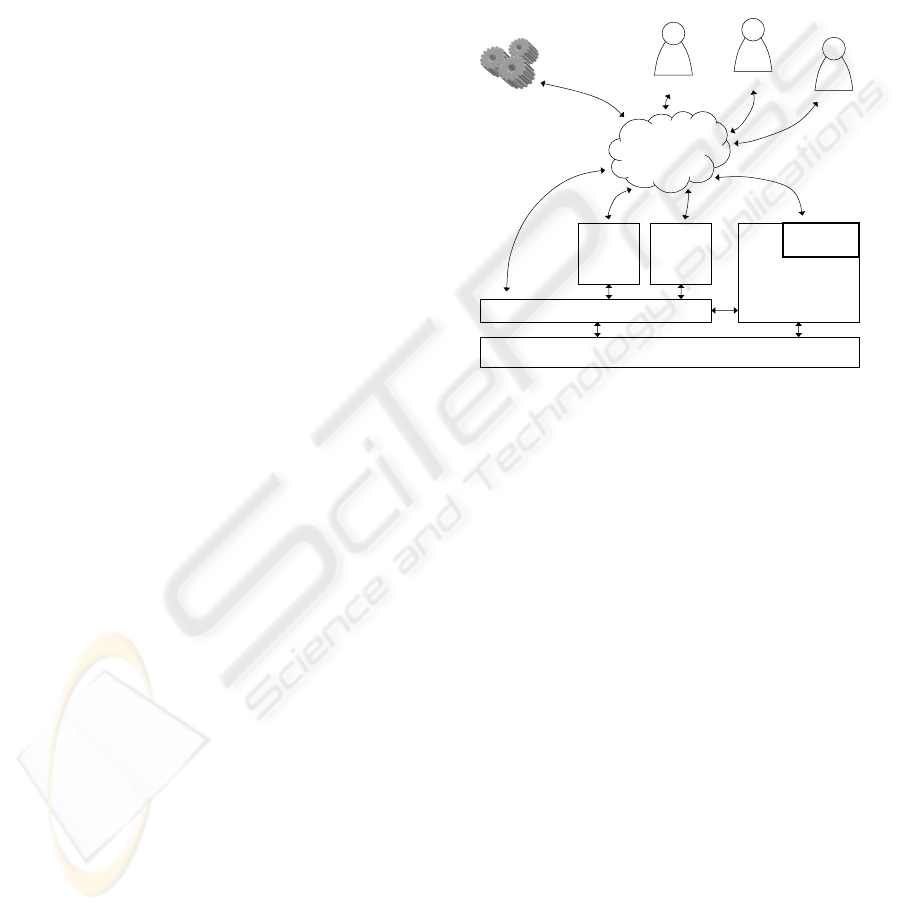
4 OVERALL ARCHITECTURE
An architecture was defined as the ground basis for
an environment based on structured multimedia frag-
ments stored in a repository (Figure 1).
Structured Multimedia Repository
Admin
User Interface
Data
Mining
Doc.
Creation
API
Browsing
WWW
third-party
service
user
user
user
Figure 1: Overall System Architecture.
The main architectural decision relates to the
Web’s distributed nature as its central point. Every as-
pect within the architecture is a producer and/or con-
sumer of resources through services with specific in-
terfaces: an API is provided for developing these ser-
vices on top of the repository (e.g., documents cre-
ation or third-party services), whereas a user inter-
face provides repository management (including the
browsing aspects).
5 BROWSING INTERFACE
A Web-based user interface was created for manag-
ing the structured multimedia repository. This inter-
face supports different tasks, such as importing new
content in different media formats, triggering mul-
timedia document production tasks, editing content
metadata, or creating structures and establishing re-
lations between multimedia fragments. However, to
perform these tasks successfully, users need to grasp
the repository’s contents through different points of
view. Therefore, several browsing aspects within the
user interface were defined and classified into two
main concerns: overviews and instances.
WEBIST 2007 - International Conference on Web Information Systems and Technologies
430
Faced with millions of multimedia fragments,
users may feel daunted on choosing a starting point
for working on repository’s contents. Overviews pro-
vide different possibilities for browsing the reposi-
tory and start new tasks, as seen on Figure 2. Five
overviews are provided:
2
5
5
5
3
4
1
Figure 2: Browsing Overviews.
1. Filter: a keyword-based filtering capability is pro-
vided to the user, allowing to dynamically adapt
all other overviews accordingly. This feature en-
ables the user to explore different perspectives and
subsets of the repository without browsing a spe-
cific repository instance, helping the user to better
perceive which contents the repository has;
2. Pinned Blocks: users are provided with mecha-
nisms for pinning contents and viewing all pins,
thus leveraging collaboration efforts;
3. Tag Cloud: with tags, users can freely classify a
content according to their own perception. The
cloud feature displays all tags that have been ap-
plied by users, with font sizes relative to each tag’s
count. This results on visualizing a user-created
taxonomy of the repository’s content;
4. Suggestions: a mechanism searches the repository
for incomplete metadata, advising the user to fill
the blanks. This feature enforces the complete-
ness of the repository;
5. Latest: the user is presented with the latest con-
tents and relations added to the repository, new
starting points for browsing activities.
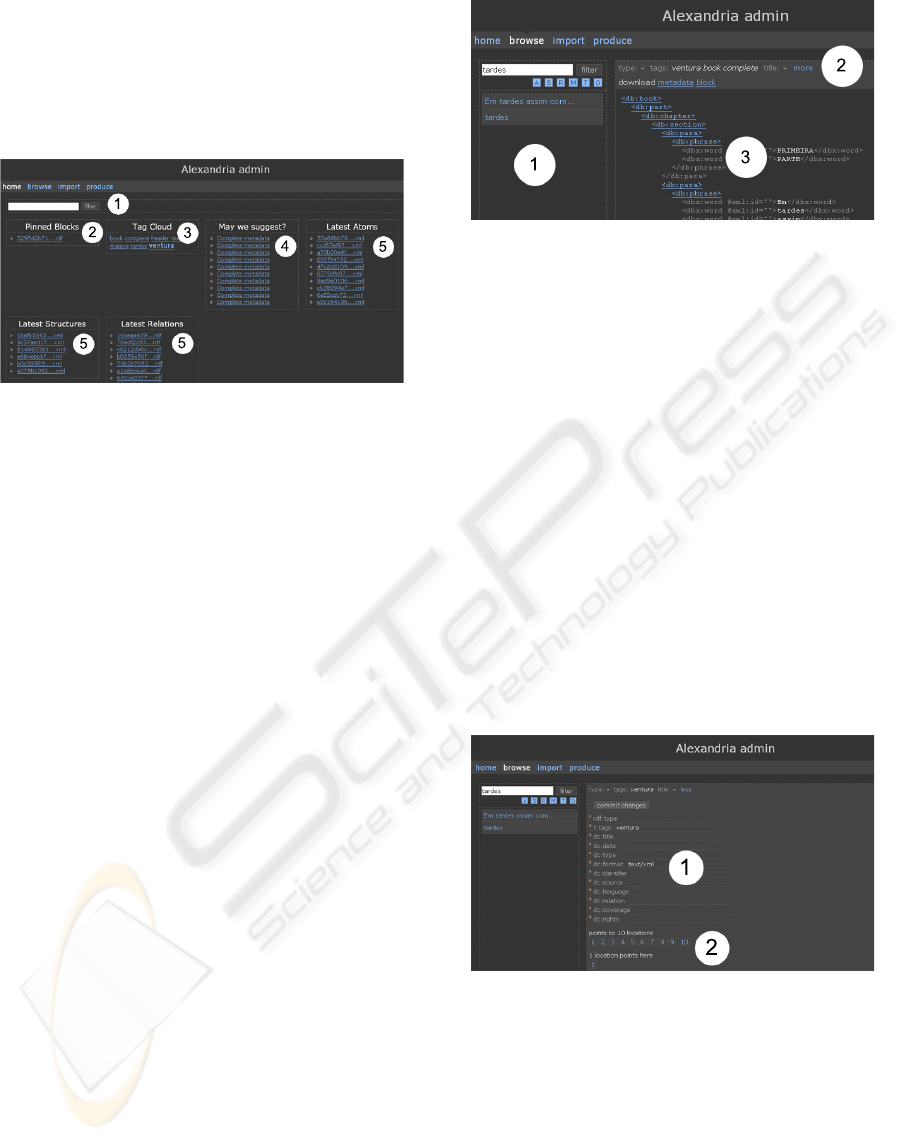
After choosing a starting point for browsing, the
user is presented with its respective instance, as seen
on Figure 3. Three different aspects can be perceived
within the browsing instance:
1. Search: while browsing, the user has the option
to search the repository. However, instance search
feature enables more complex exploratory tasks,
such as multiviews;
2. Metadata summary: to quickly grasp the subject
of a given instance, the interface presents its corre-
sponding ontology, tags and title, links for down-
loading content and metadata. Both ontology and
1
2
3
Figure 3: Browsing Instance.
tags summaries are navigable objects mapped into
search tasks, providing the user with other brows-
ing possibilities;
3. Content: this section presents the current in-
stance’s content. As the repository is based on
structuring multimedia fragments, each structure
is dynamically built and presented, enabling the
user to grasp its full content. Also, each structure
node is itself a navigation point for browsing its
children within the repository.
Expading the metadata summary, a full view is
presented (Figure 4). Here, users are able to: (1) view
and edit metadata fields, and (2) view different avail-
able navigation possibilities (inclusion, composition,
and relations) for exploring the repository, based on
the current browsing instance. It is worth noticing that
metadata fields are also starting points for exploratory
tasks from the user (similar to Tag Cloud browsing).
1
2
Figure 4: Metadata view for Browsing Instance.
6 IMPLEMENTATION
The browsing user interface for the structured multi-
media repository was implemented with Web-based
technologies. As most users are comfortable on in-
teracting with the Web, this will ease interaction with
the browsing user interface. Simple multitasking is
also leveraged just by opening a new window or tab
BROWSING A STRUCTURED MULTIMEDIA REPOSITORY
431

in the browser, enabling its fast response. Another di-
rect consequence is the instant availability of the user
interface (no software installed on the client side), in-
creasing its dissemination and usage.
The repository was implemented on top of eX-
ist (Meier, 2002), a native XML database. This deci-
sion allows using XML formats for document struc-
tures (Walsh et al., 2002), metadata and relations.
Also, using an XML database allows for volatile data
schemes, as opposed to relational databases. Con-
sequently, any ontology instance can be inserted on
multimedia fragments metadata, thus enforcing ex-
tensibility to any knowledge inference mechanism.
Executing queries on the repository is performed with
XQuery (Boag et al., 2006). Different abstraction lay-
ers on information retrieval have been implemented,
and may be used in the future as basic constructs for
smarter mechanisms. On top of XQuery modules, the
browsing interface has been implemented as a thin
layer returning XHTML.
On top of the user interface, a set of unobtrusive
javascript functionalities were added to improve the
usability of its browsing characteristics. This way,
tasks that require high computational resources (e.g.,
complex searching within the repository) can be trig-
gered asynchronously, leveraging the user interface’s
responsiveness.
7 CONCLUSIONS AND FUTURE
WORK
This paper presented new browsing aspects for man-
aging a structured multimedia repository. These as-
pects were centred on speeding up exploratory activi-
ties within the repository, typically based on navigat-
ing between relations, structures, and semantic infor-
mation of a huge amount of multimedia fragments.
Two different browsing concerns were presented,
overviews and instances, providing exploratory cues
to start browsing the repository, and visualizing con-
crete fragments and their own browsing opportunities,
respectively. These concerns are crucial, given the
amount of fragments and the complexity of structures
that may be related to each other.
As future work, it is desirable to support searching
by example for images, sound and video resources.
Also, allowing the repository metadata layer to ref-
erence any Web resource (instead of just referencing
multimedia fragments stored inside of it) will ease
coping with repository feeding. Furthermore, by in-
troducing data mining techniques, better advice can
be provided to users. Lastly, other collaboration tech-
niques may improve the repository’s browsing tasks,
such as communities specialized in specific topics.
ACKNOWLEDGEMENTS
This work is being funded by Fundac¸
˜
ao para a Ci
ˆ
encia
e Tecnologia, through grant POSI/EIA/61042/2004,
and scholarship SFRH/BD/29150/2006.
REFERENCES
Albanese, M., Cesarano, C., and Picariello, A. (2004). A
multimedia data base browsing system. In CVDB
’04: Proceedings of the 1st international workshop on
Computer vision meets databases, pages 35–42, New
York, NY, USA. ACM Press.
Berners-Lee, T., Hendler, J., and Lassila, O. (2001). The
semantic web. Scientific American.
Boag, S., Chamberlin, D., Fern
´
andez, M. F., Florescu, D.,
Robie, J., and Sim
´
eon, J. (2006). XQuery 1.0: An
XML Query Language. W3C candidate recommen-
dation, World Wide Web Consortium (W3C).
H
¨
urst, W. and Stiegeler, P. (2002). User interfaces for
browsing and navigation of continuous multimedia
data. In NordiCHI ’02: Proceedings of the second
Nordic conference on Human-computer interaction,
pages 267–270, New York, NY, USA. ACM Press.
Lew, M. S., Sebe, N., Djeraba, C., and Jain, R. (2006).
Content-based multimedia information retrieval: State
of the art and challenges. ACM Trans. Multimedia
Comput. Commun. Appl., 2(1):1–19.
Meier, W. (2002). eXist: An open source native XML
database. In Proc. of 2nd Annual International Work-
shop on Web and Databases, NetObjectDays 2002,
Erfurt, Germany.
Walsh, N., Muellner, L., and Stayton, B. (2002). Docbook:
The Definitive Guide. O’Reilly, 2.0.8 edition.
WEBIST 2007 - International Conference on Web Information Systems and Technologies
432
