
ROLE-BASED CLUSTERING OF SOFTWARE MODULES
An Industrial Size Experiment
Philippe Dugerdil and Sebastien Jossi
Department of Information Systems, HEG-Univ. of Applied Sciences, 7 rte de Drize, 1227 Geneva, Switzerland
Keywords: Reverse-engineering, software process, software clusterin
g, software reengineering, program
comprehension, industrial experience.
Abstract: Legacy software system reverse engineering has been a hot topic for more than a decade. One of the key
problems is to recover the architecture of the system i.e. its components and the communications between
them. Generally, the code alone does not provide much clue on the structure of the system. To recover this
architecture, we proposed to use the artefacts and activities of the Unified Process to guide the search. In our
approach we first recover the high-level specification of the program. Then we instrument the code and
“run” the use-cases. Next we analyse the execution trace and rebuild the run-time architecture of the
program. This is done by clustering the modules based on the supported use-case and their roles in the
software. In this paper we present an industrial validation of this reverse-engineering process. First we give
a summary of our methodology. Then we show a step-by-step application of this technique to real-world
business software and the result we obtained. Finally we present the workflow of the tools we used and
implemented to perform this experiment. We conclude by giving the future directions of this research.
1 INTRODUCTION
To extend the life of a legacy system, to manage its
complexity and decrease its maintenance cost, it
must be reengineered. However, reengineering
initiatives that do not target the architectural level
are more likely to fail (Bergey et al. 1999).
Consequently, many reengineering initiatives begin
by reverse architecting the legacy software. The
trouble is that, usually, the source code does not
contain many clues on the high level components of
the system (Kazman, O’Brien, Verhoef 2003).
However, it is known that to “understand” a large
software system, which is a critical task in
reengineering, the structural aspects of the software
system i.e. its architecture are more important than
any single algorithmic component (Tilley, Santanu,
Smith 1996). A good architecture is one that allows
the observer to “understand” the software. To give a
precise meaning to the word “understanding” in the
context of reverse-architecting, we borrow the
definition by Biggerstaff et al. (Biggerstaff,
Mitbander, Webster 1994): “A person understands a
program when able to explain the program, its
structure, its behavior, its effects on its operational
context, and its relationships to its application
domain in terms that are qualitatively different from
the tokens used to construct the source code of the
program”.
In other words, the structure of the system should
be m
appable to the domain concepts (what is usually
called the “concept assignment problem”). In the
literature, many techniques have been proposed to
split a system into components. These techniques
range from clustering (Andritsos, Tzerpos 2005)
(Wen, Tzerpos 2004), slicing (Verbaere 2003) to the
more recent concept analysis techniques (Eisenbarth,
Koschke 2003)(Tonella 2001) or even mixed
techniques (Tonella 2003). However the syntactical
analysis of the mere source code of a system may
produce clusters of program elements that cannot be
easily mapped to domain concepts because both the
domain knowledge and the program clusters have
very different structures. However to find a good
clustering of the program elements (i.e. one for
which the concept assignment is straightforward)
one should first understand the program. But to
understand a large software system one should know
its structure. This resembles the chicken and egg
syndrome. To escape from this situation, we propose
to start from an hypothesis on the architecture of the
system. Then we proceed with the validation of this
5
Dugerdil P. and Jossi S. (2007).
ROLE-BASED CLUSTERING OF SOFTWARE MODULES - An Industrial Size Experiment.
In Proceedings of the Second International Conference on Software and Data Technologies - SE, pages 5-12
DOI: 10.5220/0001329100050012
Copyright
c
SciTePress
architecture using a run time analysis of the system.
The theoretical framework of our technique has been
presented elsewhere (Dugerdil 2006). In this paper
we present the result of the reverse engineering of an
industrial-size legacy system. This shows that our
technique scales well and allows the maintenance
engineer to easily map high-level domain concepts
to source code elements. It then helps him to
“understand” the code, according to the definition of
Biggerstaff et al.
2 SHORT SUMMARY OF OUR
METHOD
Generally, legacy systems documentation is at best
obsolete and at worse non-existent. Often, its
developers are not available anymore to provide
information of these systems. In such situations the
only people that still have a good perspective on the
system are its users. In fact they are usually well
aware of the business context and business relevance
of the programs. Therefore, our iterative and
incremental technique starts from the recovery of the
system use-cases from its actual users and proceeds
with following steps (Dugerdil 2006):
• Redocumentation of the system use-cases;
• Redocumentation of the corresponding business
model;
• Design of the robustness diagram associated to
all the use-cases;
• Redocumentation of the high level structure of
the code;
• Execution of the system according to the use-
cases and recording of the execution trace;
• Analysis of the execution trace and
identification of the classes involved in the
trace;
• Mapping of the classes in the trace to the
classes of the robustness diagram with analysis
of the roles.
• Redocumentation of the architecture of the
system by clustering the modules based on their
role in the use-case implementation.
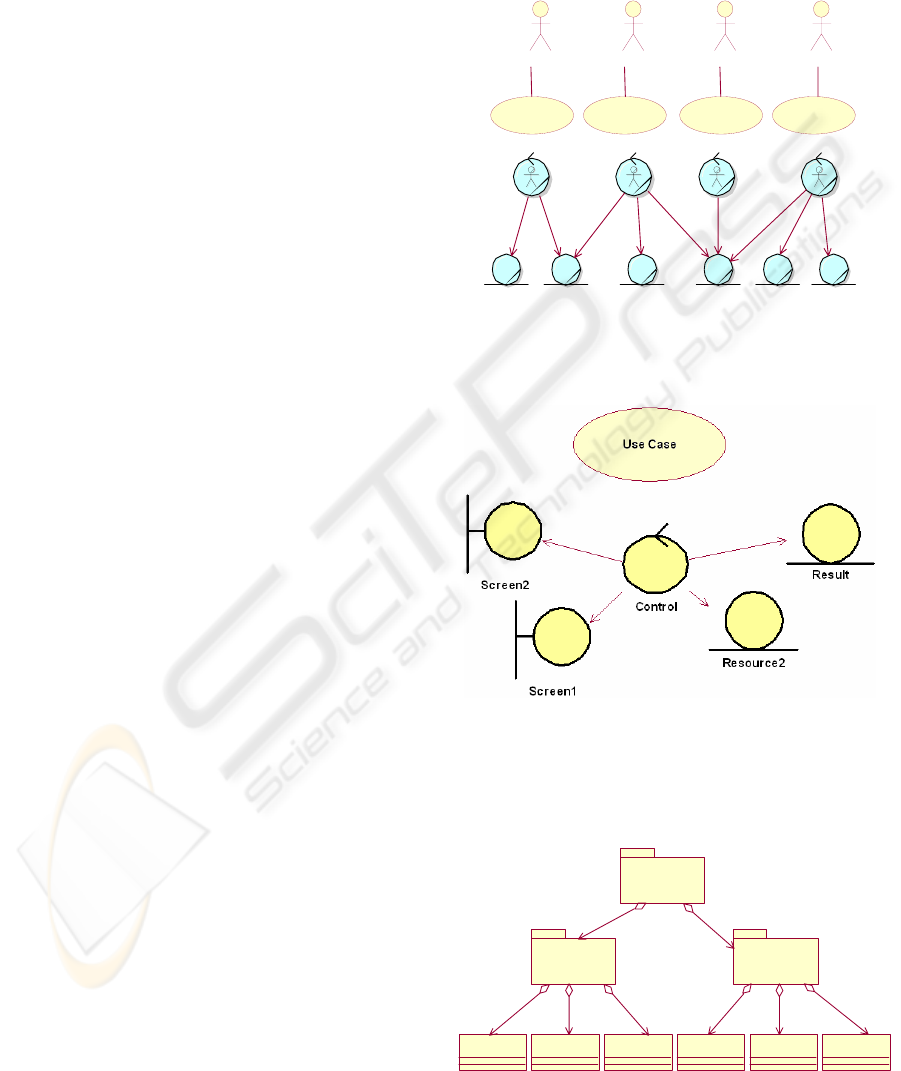
Figure 1 shows a use-case model and the
corresponding business analysis model. Then, for
each use-case we rebuild the associated robustness
diagram (UML2 name for the Analysis Model of the
Unified Development Process (Jacobson, Booch,
Rumbaugh 1999)). These robustness diagrams
represent our best hypothesis on the actual
architecture of the system. Then, in the subsequent
steps, we must validate this hypothesis and identify
the roles the modules play. Figure 2 presents an
example of a robustness diagram with their UML
stereotypical classes that represent software roles
for the classes (Jacobson, Booch, Rumbaugh 1999).
User 1 User 4User 3User 2
Business
entity1
Business
Entity2
Business
Entity3
Business
Entity4
Bu s in e s s
Entity5
Business
Entity6
UseCase1 UseCase2 UseCase3 UseCase4
User 4User 3User 2User 1
Figure 1: Use-case model and business model.
Figure 2: Use-case and robustness diagram.
The next step is to recover the visible high level
structure of the system (classes, modules, packages,
subsystems) from the analysis of the source code,
using the available syntactic information (fig 3).
Subsystem1
Package1 Package2
Class1 Class2 Class3 Class4 Class5 Class6
Figure 3: The high-level structure of the code.
ICSOFT 2007 - International Conference on Software and Data Technologies
6
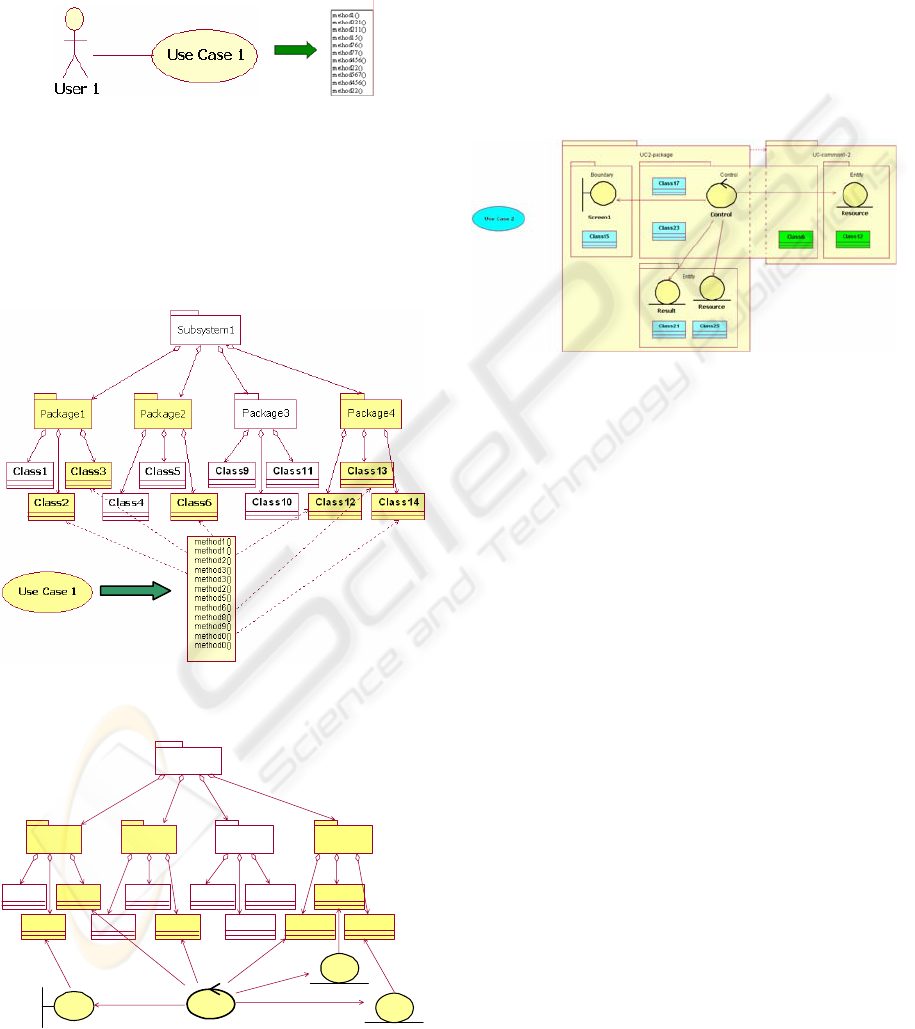
Now, we must validate our hypothetical architecture
(robustness diagrams) against the actual code of the
system and find the mapping from the stereotypical
classes to the actual modules. First, we run the
system according to each use-case and record the
execution trace (fig. 4).
Figure 4: Use-case and the associated execution trace.
Next, the functions in the trace are linked to the
classes or modules they belong to. These are the
classes or modules that actually implement the use-
case. These classes or modules are then highlighted
in the high level structure of the code (fig. 5).
Figure 5: From the trace to the high level structure of the
code.
Subsystem1
Package1 Package2
Class1
Class2
Class3
Class4
Class5
Class6
Package4
Class9
Package3
Class10
Class11
Class12
Class13
Class14
Resource
Resource
Control
Screen1
Figure 6: Mapping actual classes to software roles.
The classes found are further analysed to find
evidence of a database access function or of a screen
display function. This let us categorize the classes as
entities (access to database tables) or boundaries
(interface to the user). The remaining classes will be
categorized as control classes. Figure 6 presents the
result of such a mapping. The last step in our
method is to cluster the actual classes or modules
according to the use-case they implement and to
their role as defined above. This represents the
recovered architecture of the system. Figure 7 shows
such a recovered architecture for a single use-case.
Figure 7: Recovered architecture for a use-case.
3 INDUSTRIAL EXPERIMENT
This technique has been applied to an industrial
packaged software. This system manages the welfare
benefit in Geneva. It is a fat-client kind of client-
server system. The client is made of 240k lines of
VB6 code. The server consists of 80k lines of
PL/SQL code accessing an Oracle database. In this
paper, for the sake of conciseness, we will
concentrate on the reverse engineering of the client
part of this system. But the technique has been
applied as well to the server part.
3.1 Recovering the Use-cases
Due to heavy workload of the actual users of this
system we recovered the used-cases by interacting
with the user-support people who know the domain
tasks perfectly well. Then we documented the 4
main use-cases of the system by writing down the
user manipulation of the system and video recording
the screens through which the user interacted (Figure
8). From this input, we were able to rebuild the
business model of the system (Figure 9). In the latter
diagram, we show the workers (the tasks) and the
resources used by the workers. Each system actor of
the use-case model corresponds to a unique worker
ROLE-BASED CLUSTERING OF SOFTWARE MODULES - An Industrial Size Experiment
7
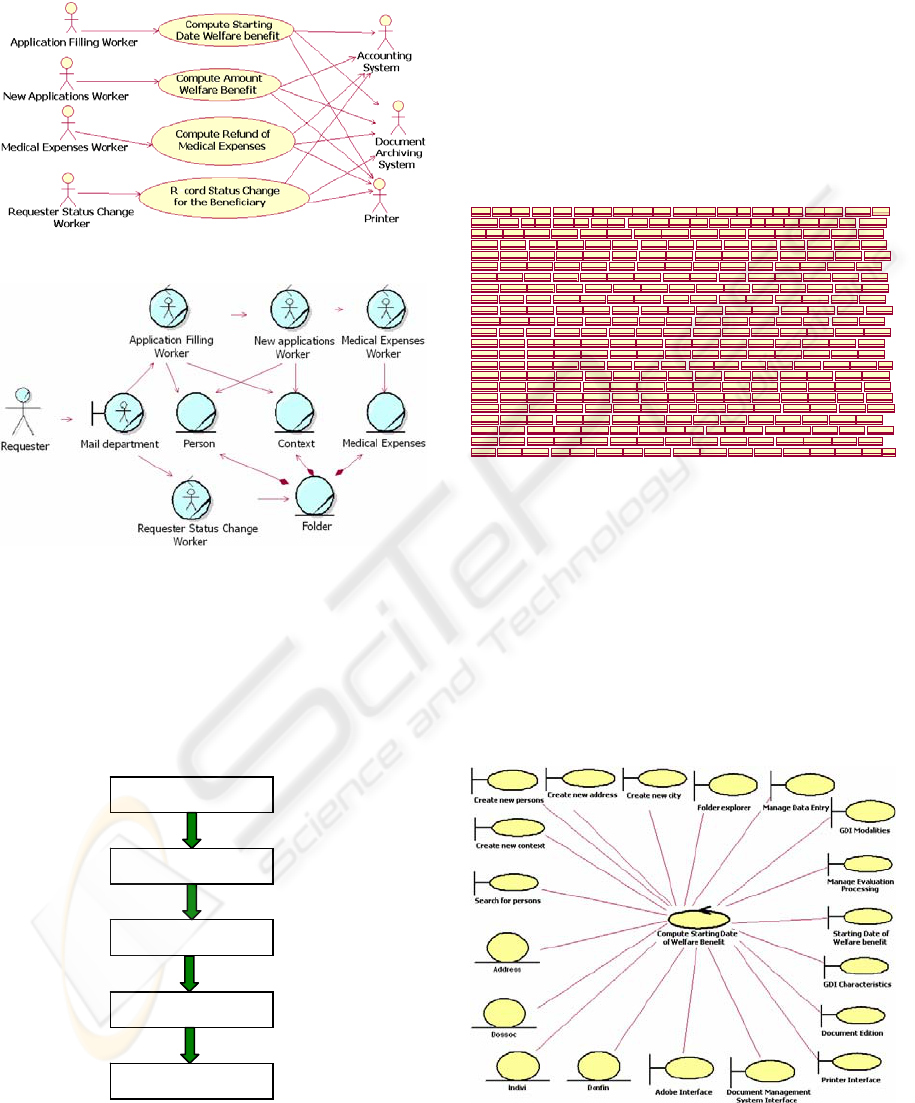
in the business model. The technique used to infer
the business model come from the Unified Process.
Figure 8: The main use-cases of the system.
Figure 9: The recovered high level business model.
3.2 Recovering the Visible Structure
In our experiment we did not have any specific tool
at our disposal to draw the modules and module
dependencies, neither for VB6 nor PL/SQL.
However, we regularly use the Rational/IBM XDE
environment which can reverse-engineer Java code.
Figure 10: Visible high level structure extraction
workflow.
Then, we decided to generate skeleton Java classes
from both the VB6 and PL/SQL code to benefit from
XDE. Each module in VB6 or PL/SQL is
represented as a class and the dependencies between
modules as associations. We then wrote in Java our
own VB6 parser and Java skeleton generator. Figure
10 presents the workflow for the display of the
visible high-level structure of the VB6 client tier of
the system. The resulting high-level structure
diagram is presented in figure 11. There are 360
modules in this diagram.
VQPRO 011
_
FR
M
VQPRO012
_
FR
M
VQPRO 016
_
FR
M
VQPRO 017
_
FRMVQPRO 018
_
FR
M
VQPRO019
_
FRMVQPRO999
_
FRM VRECO0 01
_
FRMVREG PIEC
_
FR
M
VRELA001
_
FRMVREUN001
_
FR
M
VSGFI001
_
FRMVSGFI002
_
FR
M
VSGFI003
_
FRM
VSGFI004
_
FRMVSGFI005
_
FRMVSGFI006
_
FRMVSGFI007
_
FRMVSGFI 008
_
FRMVSI TU001
_
FR
M
VTACH001
_
FR
M
VTACHE01
_
FRMVTACHE0 2
_
FR
M
VTACHE03
_
FR
M
VTFRA001
_
FR
M
VTIER0 01
_
FR
M
VTIER00 2
_
FRM VTINS001
_
FR
M
VTRAC001
_
FR
M
VTRAC002
_
FR
M
VTRAC003
_
FRMVTRAC004
_
FR
M
VTRAC005
_
FRMVTRAC006
_
FRMVTRACABI
_
FRMVTTER001
_
FRMVTTER010
_
FRMVTTER025
_
FRMVTTER045
_
FR
M
VTTER065
_
FRMVTYPDPIE
_
FRMVTYPFRML
_
FR
M
VVALQUES
_
FR
M
VVTIR004
_
FRM
VVTIR0 05
_
FR
M
VVTIR0 06
_
FR
M
VVTIR00 7
_
FRMVVTIR009
_
FRMVVTI R010
_
FRMVXTRT001
_
FR
M
VXTRT002
_
FR
M
VXTRT003
_
FR
M
VXTRT004
_
FRMVYTYP002
_
FR
M
VYTYP003
_
FR
M
VYTYP 004
_
FRMVYTYP005
_
FR
M
VYTYP006
_
FR
M
VYTYP007
_
FR
M
VYTYP009
_
FR
M
VYTY P 010
_
FRMVZARC001
_
FRMX
_
CONNX0
_
FR
M
X
_
CONNX1
_
FRM
X
_
CONNX2
_
FRMX
_
ERREUR
_
FR
M
X
_
QUICK
_
FRMZ
_
ATTENT
_
FRM Z
_
DGEN00
_
FR
M
Z
_
DGEN01
_
FRMZ
_
EDIT00
_
FRM Z
_
RGEN00
_
FR
M
BDOC CHAPEAU2 Couleu
r
ENC FENERECH FENET
_
T
2
FORMULE
_
BAS
FTRAD001
_
BA
S
FZGBU000
1
GED GLOBCONSHABILI
T
INTER
V
LANGU
E
Lo
g
emen
t
ODBCBNI
V
ODBCHN I
V
Pol
y
mor
p
h
e
PRODUI
T
QUALI TE S RECHPRES TSUI VAUDX
_
CONN
X
X
_
DBTOO L X
_
ERROR X
_
INIWIN
X
_
LO
G
X
_
QUIC
K
X
_
SPREAD
X
_
STRIN
G
X
_
WINAP
I
X
_
WIN SP
E
Z
_
DECTY
P
Z
_
FENET
R
Z
_
GENERI Z
_
RECPR
E
Z
_
SERVDZ
_
SERVD2 Z
_
SERVIC Z
_
SERVL
_
BAS Z
_
SERVRL Z
_
SERVSS
VPIND001
_
FR
M
VPLAN001
_
FR
M
VPLAV001
_
FRMVPOLY000
_
FRMVPOLY001
_
FR
M
VPOLY002
_
FRMVPOUR001
_
FR
M
VPPIL001
_
FR
M
VPPRO001
_
FR
M
VQPRO 0 0 1
_
FRMV Q PR O002
_
FRMVQP RO003
_
FR
M
VQPRO 004
_
FRMVQPR O 0 05
_
FRMVQ PRO006
_
FR
M
VPART015
_
FR
M
VPART016
_
FRM VPART017
_
FRMVPART018
_
FR
M
VPART019
_
FRMVPART020
_
FRMVPART021
_
FR
M
VPDIA001
_
FRMVP EN S 001
_
FR
M
VPENS003
_
FRMVPENS004
_
FR
M
VPIEC001
_
FRMVPIEC002
_
FR
M
VPIEC003
_
FRMVPI ECFOU
_
FR
M
VNOTSITU
_
FRMVPAKEV 01
_
FRMVPART001
_
FR
M
VPART002
_
FR
M
VPART003
_
FRMVPART004
_
FR
M
VPART005
_
FRMVPART006
_
FR
M
VPART007
_
FRMVPART008
_
FR
M
VPART009
_
FRMVPART011
_
FR
M
VPART012
_
FRMVPART013
_
FR
M
VPART014
_
FRM
VNINT017
_
FRMVNI NT018
_
FR
M
VNINT019
_
FRMVNI NT020
_
FR
M
VNINT025
_
FRMVNINT026
_
FRM VNINT027
_
FRMVNINT028
_
FR
M
VNINT029
_
FR
M
VNINT030
_
FRMVNI NT031
_
FR
M
VNINT032
_
FR
M
VNINT033
_
FR
M
VNOTNODA
_
FR
M
VNOTRESU
_
FRM
VMESPAC1
_
FRM VMESS001
_
FRMVMESS002
_
FRMVMESS003
_
FR
M
VMMOT01 5
_
FR
M
VMMOT110
_
FR
M
VMMOT210
_
FRMVMMOT220
_
FRMVNINT001
_
FRMVNI NT004
_
FR
M
VNINT005
_
FR
M
VNINT006
_
FRMVNI NT011
_
FR
M
VNINT014
_
FRMVNI NT015
_
FR
M
VJCAD020
_
FR
M
VJDSO00 2
_
FR
M
VJDSO003
_
FR
M
VJDSO0 04
_
FRMVJDSO005
_
FR
M
VKPRE001
_
FRMVKPRE002
_
FRMVKPRE003
_
FR
M
VLIST001
_
FRMVLOCA001
_
FR
M
VLOG E0 0 1
_
FR
M
VLOGE0 02
_
FRMVLOGE003
_
FR
M
VLOGE004
_
FRM VPENS002
_
FRM
VJCAD004
_
FRMVJCAD005
_
FRMVJCAD006
_
FR
M
VJCAD007
_
FRMVJCAD008
_
FR
M
VJCAD009
_
FRMVJCAD010
_
FR
M
VJCAD011
_
FR
M
VJCAD012
_
FR
M
VJCAD013
_
FR
M
VJCAD014
_
FRMVJCAD016
_
FR
M
VJCAD017
_
FRMVJCAD018
_
FR
M
VJCAD019
_
FRM
VGDO C 00 6
_
FR
M
VGDOC007
_
FR
M
VGPRO 001
_
FR
M
VHELP001
_
FR
M
VINDI001
_
FRMVINDI002
_
FRMVINDI003
_
FR
M
VINDI004
_
FRMVINDI006
_
FR
M
VINDI999
_
FRMVINST001
_
FRMVINTF001
_
FRMVJCAD001
_
FR
M
VJCAD002
_
FRM
A
PROPOSBAS
VECPR009
_
FRMVEVAR001
_
FRMVFACT003
_
FRMVFENMODI
_
FR
M
VFINA001
_
FR
M
VFORM001
_
FRMVG ARA001
_
FR
M
VGBIL001
_
FR
M
VGDIA001
_
FR
M
VGDIA002
_
FR
M
VGDOC0 01
_
FRMVGDOC002
_
FR
M
VGDOC003
_
FR
M
VGDOC004
_
FR
M
VGDOC0 05
_
FRM
VDCAT004
_
FR
M
VDCAT010
_
FRMVDCAT011
_
FR
M
VDCAT012
_
FR
M
VDOCU001
_
FR
M
VDOMA001
_
FR
M
VDOMA002
_
FRMVECPR001
_
FRMVECPR002
_
FRMVECPR003
_
FRMVECPR004
_
FR
M
VECPR005
_
FRMVECPR006
_
FR
M
VECPR007
_
FRMVECPR008
_
FR
M
VCBUD001
_
FRMVCBUD002
_
FR
M
VCBUD003
_
FRMVCBUD004
_
FR
M
VCBUD00 5
_
FRMVCBUD007
_
FR
M
VCBUD010
_
FR
M
VCBUD01 1
_
FR
M
VCLBA001
_
FRMVCOMP001
_
FRMVCONT001
_
FR
M
VCONT002
_
FRMVCONT003
_
FR
M
VCOUR001
_
FR
M
VCTRP001
_
FRM
VAHAB045
_
FR
M
VAHAB090
_
FRMVARRA001
_
FRMVASSU002
_
FRMVBARE001
_
FRMVBDEM001
_
FR
M
VBDEM002
_
FR
M
VBDEM003
_
FRMVBDEM0 04
_
FR
M
VBDEM005
_
FR
M
VBDEM006
_
FRMVBDEM007
_
FR
M
VBDEM0 08
_
FRMVBRAPA01
_
FRMVBUDG001
_
FR
M
V
_
RSPE05
_
FRMV
_
RSPE06
_
FR
M
V
_
SPJ001
_
FR
M
V
_
SPJ002
_
FRMV
_
SPJ003
_
FR
M
V
_
SPJ005
_
FRM V
_
SPJ006
_
FRMV
_
SPJ007
_
FRMV
_
SPJ008
_
FRMVAACT060
_
FR
M
VAACT070
_
FR
M
VAACT080
_
FRMVACTI001
_
FR
M
VAHAB015
_
FRMVAHAB035
_
FR
M
FZGBU007
_
FR
M
FZGBU009
_
FRMFZGBU010
_
FR
M
LIBLAPPO
_
FRMLISTPRO
1
LISTPRO
2
LISTPRO
3
LISTPRO4LISTPRO5LISTPR O
6
V
_
ASV001
_
FRMV
_
OUTE XT
_
FRMV
_
RMR001
_
FRMV
_
RSPE01
_
FR
M
V
_
RSPE02
_
FRMV
_
RSPE0 3
_
FR
M
V
_
RSPE04
_
FRM
FENC005
_
FR
M
FENC006
_
FR
M
FZGBU002
_
FRM FMENUPOP
_
FR
M
FREFAC01
_
FRMFTRAD001
_
FRM FZ AUT001
_
FRMFZAUT002
_
FR
M
FZAUT003
_
FRMFZGBU000
_
FRMFZGBU001
_
FRMFZGBU003
_
FRMFZGBU005
_
FR
M
FZGBU006
_
FRMFZGBU008
_
FR
M
CHAPEA
U
FENC000
_
FR
M
LISTFEN
E
VZORA00
0
VZORA002
_
FRMVZORA003
_
FR
M
VZORA004
_
FR
M
VZORA005
_
FR
M
VZORA006
_
FRM VZORA0 07
_
FRMEXPLORER
_
FR
M
F
_
BVR001
_
FR
M
FENC001
_
FR
M
FENC002
_
FR
M
FENC003
_
FRMFENC004
_
FR
M
A
PROPOS
_
FR
M
F
_
CHRG01
_
FR
M
ONGLPARA
~ enc~ z_generi
Z_AMI
Design1
Figure 11: Visible high level structure of the client.
3.3 Building the Robustness Diagram
The robustness diagram is built by hand using the
heuristics set forth by the Unified Process. Figure 12
presents the robustness diagram of the first use-case
called “Compute the starting date of welfare
benefit”. It is the second largest use-case of this
system. Again, this diagram has been built from the
analysis of the use-case only, without taking the
actual code into account.
VB code
Java
g
enerato
r
Java code
XDE u
p
load
Module dis
p
la
y
Figure 12: Robustness diagram of the first use-case.
ICSOFT 2007 - International Conference on Software and Data Technologies
8

3.4 Running the Use-case
The next step is to “execute” the use-cases i.e. to run
the system following the manipulations expressed by
the use-cases. Then the execution trace must be
recorded. Again, we have not found any specific
environment able to generate an execution trace for
the client part written in VB6. Then we decided to
instrument the code to generate the trace (i.e. insert
trace generation statement in the source code).
Therefore we wrote an ad-hoc VB6 instrumentor in
Java. The modified VB6 source code must then be
recompiled before being executed. The format of the
trace we generate is:
<moduleName><functionSignature><parameterValues>
The only parameter values we record in the trace are
the one with primitive types, because we are
interested in SQL statements passed as parameters.
This will help us find the modules playing the role
of “Entities” (see below). For the server part
(PL/SQL), the trace can be generated using the
system tools of Oracle.
3.5 Trace Analysis
In the next step we analysed the trace to find the
modules involved in the execution. The result for the
client part is presented in figure 13. We found that
only 44 modules are involved in the processing of
this use-case, which is one of the biggest in the
application. But this should not come as a surprise.
Since this system is a packaged software, then a lot
of the implemented functions are unused.
VQPRO01 1_F RMVQPRO012_FR
M
VQPRO01 6_F RMVQPRO 017 _F RMVQPRO018_FR MVQPRO0 19_ FR MV Q PRO999_FRM VRECO001 _FRMVREGPIEC _F R MVRELA001_FRMVREUN001_FRMVSGFI001_FRMVSG F I002_FRMVSGFI003_FRM
VSGFI004_FRMVSGFI005_FRMVSGFI006_FRMVSGFI007_FRMVSGFI008_FRMVSITU001_FRM
VTACH001_FRM
VTACHE01_FRMVTACHE02_FRM VTACHE03 _F RMVTFRA001_FR
M
VTIER001_FRMVTIER002_FRM VTINS001_FRMVTRAC001_FRMVTRAC002_FRM
VTRAC003_FRMVTRAC004 _FRMVTRAC005 _F RMVTRAC006_FRMVTRACABI_FRMVTTER001_FRMVTTER010_FRMVTTER025_FRMVTTER045_FRM VTTER065_FRMVTYPDPIE_ F RMVTYPF R ML _F R MVVALQUES_FR
M
VVTIR004_FRM
VVTIR005_FRM
VVTIR006_FRMVVTI R007_FRMVVTIR009_FRMVVTIR010_FRMVXTRT001_FRMVXTRT002_FRMVXTRT003_FRM VXTRT004_FRMVYTYP002_FRMVYTYP003_FRM VYT YP004_FRMVYTYP 005 _F RMVYTYP006_FRM
VYTY P00 7_FR MVYTYP009_ FRMVYTYP 010 _FR MVZARC001_FRMX_CONNX0_FRM
X_CONNX1_FRM
X_CONNX2_FRMX_ERREUR_FRMX_QUICK_F RMZ_ATTENT_FRM Z_DGEN00_FRMZ_DGEN01_FRMZ_EDIT00_FRM Z_RGEN00_FRM
BDOC CHAPEAU2 Couleur ENC FENERECH FENET_T2 FORMULE_BAS
FTRAD001_B AS FZGBU0001 GED GLOBCONSHABILI
T
INTER
V
LANGUE Lo
g
emen
t
ODBC BNI
V
ODBCHNI
V
Polymo r phe PRODUI
T
QUALI TES RECHPRES TSUI VAUDX_CONN
X
X_DBTOOL X_ERROR X_INIWIN
X_LO
G
X_QUICK X_SPREAD
X_STRINGX_WINAPI X_WINSPE Z_DECTYP Z_FENETRZ_GE NE RI Z_RECPRE Z_SER V DZ_SE RVD2 Z_SERVI C Z_SERVL_B AS Z_SERVRL Z_SERVSS
VPIND001_FRMVPLAN001_FRMVPLAV001_FR MVPOLY000_ F RMVPOLY00 1_FRMVPOLY002_FRMVPOUR001_FR
M
VPPIL001_FRMVPPRO001_FR MVQPRO001_FRMVQPRO002 _FR MVQPRO00 3_FRMVQPRO004_FRMVQPRO005_FRMVQPRO006 _FR
M
VPART015_FRMVPART016_FRM VPART017_FRMVPART018_FRM VPART019_FRMVPART020_FRMVPART021_FRMVPDIA001_FRMVPENS001_FRMVPENS003_FR MVPENS004_FRM VPIEC001_FRMVPIEC002_FR
M
VPIEC003_FRMVPI ECFOU_FRM
VNOTSITU_F RMVPAKEV01_FRMVPART001_FRMVPART002_FRMVPART003_FRMVPART004_FRMVPART005_FRMVPART006_FRMVPART007_FRMVPART008_FRMVPART009_FRMVPART011_FRMVPART012_FRMVPART013_FRMVPART014_FRM
VNINT017_FRMVNINT018_FR
M
VNINT019_FRMVNINT020_FR
M
VNINT025_FRMVNINT026_FRM VNI NT027_FRMVNINT028_FRMVNINT029_FR
M
VNINT030_FRMVNINT031_FR
M
VNINT032_FR
M
VNINT033_FRMVNOTNODA_FRMVNOTRESU_FRM
VMESPAC1 _FRM VMES S001_FRMVMESS002_FRMVMESS003_FR
M
VMMOT015_F RMVMMOT 110 _FR MVMMOT210_ FRMVMMOT220_FRMVNINT001_F RMVNINT004_FR
M
VNINT005_FR
M
VNINT006_FRMVNINT011_FR
M
VNINT014_FRMVNINT015_FR
M
VJCAD020_FRMVJDSO002_FRMVJDSO003_FR
M
VJDSO004_FR MVJDSO00 5_FR
M
VKPRE001_FRMVKPRE002_FRMVKPRE003_FRMVLIST001_FRMVLOCA001_FRMVLOGE001_FR MV LOGE00 2_F RMVLOGE003_FRMVLOG E 004 _FRM VPENS002_FR M
VJCAD004_FRMVJCAD005_FRMVJCAD006_FRMVJCAD007_FRMVJCAD008_FRMVJCAD009_FRMVJCAD010_FRMVJCAD011_FRMVJCAD012_FRMVJCAD013_FRMVJCAD014_FRMVJCAD016_FRMVJCAD017_FRMVJCAD018_FRMVJCAD019_FRM
VGDOC006_FRMVGDO C0 07_FRMVGPRO001_FRMVHELP001_FR
M
VINDI001_FRMVINDI002_FRMVINDI003_FR
M
VINDI004_FRMVINDI006_FR
M
VINDI999_FRMVINST001_FRMVINTF001_FRMVJCAD001_FRMVJCAD002_FR M APROPOSBAS
VECPR009_FRMVEVAR001_FRMVFACT003_FRMVFEN MODI_FR
M
VFINA001_FR
M
VFORM001_FR MVGARA001_FRMVGBIL001_FRMVGDIA001_FRMVGDIA002_FRMVG DO C0 01_FRMVGDOC002_FRMVGDOC003_FRMVGDOC004_FRMVGDOC005_F RM
VDCAT004_FRMVDCAT010_FRMVDCAT011_FRMVDCAT012_FRMVDOCU001_FRMVDOMA001_FRMVDOMA002_FRMVECPR001_FRMVECPR002_FRMVECPR003_FRMVECPR004_FRMVECPR005_FRMVECPR006_FRMVECPR007_FRMVECPR008_FRM
VCBUD001_FRMVCBUD002_FRMVCBUD003_FRMVCBUD004_FRMVCBUD005_FRMVCBUD007_FRMVCBUD010_FR
M
VCBUD011_FRMVCLBA001_FR MVCOMP001_FRMVCONT001_FRMVCONT002_ FR MVCONT003_FRMVCOUR001_FRMVCTRP001_FRM
VAHAB045 _FR
M
VAHAB090_FRMVARRA001_FRMVASSU002_FRMVBARE001_FRMVBDEM001_FRMVBDEM002_FRMVBDEM003_FRMVBDEM004_FRMVBDEM005_F RMVBDEM006_FRMVBDEM007_FRMVB DEM0 08_ FR MVBRAPA01_FRMVBUDG001_FR
M
V_RSPE05_FRMV_RSPE06_FRMV_SPJ001_FRMV_SPJ002_FRMV_SPJ003_FRMV_SPJ0 05_ FRM V_SPJ006_FRMV_SPJ007 _F RMV_SPJ008_FRMVAACT060_FRMVAACT070_FRMVAACT080_FRMVACTI001_FR
M
VAHAB015_FRMVAHAB035_FR
M
FZGB U00 7_F R
M
FZGBU009_FRMFZGBU010_FR
M
LIBLAPPO_FRMLISTPRO1LISTPRO2 LISTPRO3LISTPRO4LISTPRO5LISTPRO6V_ASV001_FRMV_OUT EX T _F R MV_RMR001_FRMV_RSPE01_FRMV_RSPE02_FRMV_RSPE03_FR MV_RSPE04_FRM
FENC005_FR
M
FENC006_FR
M
FZGB U002 _F RM FME NUPO P_FRMFREFAC01_FRMFTRAD001_FRM FZAUT001_FRMFZAUT002_FRMFZAUT003_FRMFZGBU000_FRMFZGBU001_FRMFZGBU003_FRMFZGB U005 _F R
M
FZGBU0 06_FRMFZGBU008_FR
M
CHAPEAUFENC000_FR
M
LISTFENE VZORA000 VZORA002_FRMVZORA003 _F RM VZORA004_FRM VZORA005_F RM VZO RA006_ FRM VZO RA0 07_ FRMEXPLORE R_ FR M F_BVR001_FRMFENC001_FR
M
FENC002_FR
M
FENC003_FRMFENC004_FR
M
APROPOS_FRM
F_CHRG01_FRM
ONGLPARA
~ enc~ z_generi
Z_AMI
Design1
Figure 13: Modules involved in the first use-case.
The last step is to sort out the roles of the modules in
the execution of the use case. This will allow us to
cluster the modules according to their role. Then we
analysed the code of the executed functions to
identify screen-related functions (i.e. VB6 functions
used to display information). The associated
modules then play the role of the boundaries in the
robustness diagram. Next, we analysed the
parameter values of the functions to find SQL
statements. The corresponding modules play the role
of the entities in the robustness diagram. The
remaining modules play the role of the control
object. The result of this analysis is presented in
figure 14. The modules in the top layer (red) are
boundaries (screens), the bottom layer (yellow) are
the entities and the middle layer (blue) contains the
modules playing the role of the control object.
VXTRT004_FRM
X
_ERREUR_FRMZ_ATTENT_FRMZ_DGEN01_FR M
Z_RGEN00_FR M
BDOC
Couleur
ENC
FENERECHFENET_T2
HABILI
T
INTER
V
LANGUE
ODBCBNI
V
ODBC HNI V
PolymorphePRODUIT
QUALITESTSU
I
VAUD
X
_CONN
X
X
_DBTOOL
X_ERRORX_INIWIN
X
_LO
G
X
_SPREAD
X
_STRIN
G
X
_WIN AP
I
Z_FENETR
Z_GENER
I
Z_SERVD Z_SERVD2
Z_SERVIC
Z_SERVRLZ_SERVSS
VQPRO004_FRM VQPRO005_FRM
VNINT001_FRM
VI ND I001_FRM
LISTPRO2
FMENUPOP_FRM
CHAPEAU
FENC002_FRM
ONGLPARAZ_AM
I
Desi
g
n1
Figure 14: software roles of the involved modules.
As an alternative view, we map the modules of the
client part to the robustness diagram we built from
the use-case. By correlating the sequence of use in
the use-case and the sequence of appearance in the
execution we can identify each boundary object. As
for the entity objects, they are not specific to any
given table. In fact, we found that each entity
module is involved in the processing of many tables.
Figure 15: Modules to robustness diagram mapping.
Then, we represented all of them in the robustness
diagram without mapping to any specific database
table. The result of the mapping is represented in
ROLE-BASED CLUSTERING OF SOFTWARE MODULES - An Industrial Size Experiment
9

figure 15. Since the number of modules that play the
role of the control object is large, they are not shown
in the diagram. In this experiment, we were not able
to map the boundary labelled with the “unmapped”
note (bottom). In fact they represent interfaces with
external systems that we cannot reach from the test
environment we used in our experiments. Therefore
no mapping was possible.
3.6 Role-based Clustering of Modules
Figure 16 represents the role-based clustering of the
client modules identified in our experiment. First, all
the modules are grouped in a package named after
the use-case they implement. Second the modules
are grouped after the Robustness-Diagram role (§2)
they play in this implementation. This represents a
specific view of the system’s architecture. It
corresponds to the role the module play in the
currently implemented system. It is important to
note that this architecture can be recovered whatever
the maintenances to the system. Since it comes from
the execution of the system, it can cope with the
dynamic invocation of modules, something
particularly difficult to analyse using static analysis
only.
UC: calculer debut des droits
Entitities
Control
Boundaries
VXTR T004_FRMX_ERREUR_FRMZ_ATTENT_FRMZ_DGEN01_FRM
Z_RGEN00_FRM
BDOC
Couleur
ENC
FENERECHFENET_T2
HABILITINTER
V
LANGUE
ODBCBNI
V
ODBCHNI
V
Pol
y
morphePRODUIT
QUALITESTSU I
VAUD
X_CONNX
X_DBTOOL
X_ERRORX_INIWIN
X_LOG
X_SPREAD
X_STRING
X_WINAPI
Z_FENETR
Z_GENER
I
Z_SERVD Z_SERVD2
Z_SERVIC
Z_SERVRLZ_SERVSS
VQPRO004_FRM VQPRO005_FRM
VNI NT001_FR M
VINDI001_F R M
LISTPRO2
FMENUPOP_FRM
CHAPEAU
FENC002_FRM
ONGLPARAZ_AMIDesi
g
n1
Figure 16: Recovered architecture of the main use-case of
the system.
4 TOOLS WORKFLOW
In figure 17, we present the overall workflow of the
tools we used to analyse the system. On the left we
find the tools to recover the visible high level
structure of the system. On the right we show the
tools to generate and analyse (filter) the trace. In the
center of the figure we show the use-case and the
associated robustness diagram.
Figure 17: Workflow of the reverse-engineering tools.
5 RELATED WORK
The problem to link the high level behaviour of the
program to the low-level software components has
been the source of many research works and
publications. Often, in the literature, the authors try
to solve the problem by designing an algorithm that
groups the software elements according to some
criteria. Among the most popular techniques we find
static clustering and formal concept analysis.
• The clustering algorithms groups the statements
of a program based on the dependencies between
the elements at the source level, as well as the
analysis of the cohesion and coupling among
candidate components (Mitchell 2003) (Kuhn,
Ducasse, Girba 2005).
• Formal concept analysis is a data analysis
technique based on a mathematical approach to
group the «objects» that share some common
«attributes». Here the object and attributes can
be any relevant software elements. For example,
the objects can be the program functions and the
attributes the variables accessed by the functions
(Linding, Snelting 1997) (Siff, Reps 1999). For
ICSOFT 2007 - International Conference on Software and Data Technologies
10

example, this technique has been proposed to
identify the program elements associated to the
visible features of the programs (Rajlich, Wilde
2002) (Eisenbarth, Koschke 2003).
In fact, these techniques try to partition the set of
source code statements and program elements into
subsets that will hopefully help to rebuild the
architecture of the system. The key problem is to
choose the relevant set of criteria (or similarity
metrics (Wiggert 1997)) with which the “natural”
boundaries of components can be found. In the
reverse-engineering literature, the similarity metrics
range from the interconnection strength of Rigi
(Müller, Orgun, Tilley, Uhl 1993) to the sophisti-
cated information-theory based measurement of
Andritsos (Andritsos, Tzerpos 2003) (Andritsos,
Tzerpos 2005), the information retrieval technique
such as Latent Semantic Indexing (Marcus 2004)
(Kuhn, Ducasse, Girba 2005) or the kind of variables
accessed in formal concept analysis (Siff, Reps
1999) (Tonella 2001). Then, based on such a
similarity metric, an algorithm decides what element
should be part of the same cluster (Mitchell 2003).
On the other hand, Gold proposed a concept
assignment technique based on a knowledge base of
programming concepts and syntactic “indicators”
(Gold 2000). Then, the indicators are searched in the
source code using neural network techniques and,
when found, the associated concept is linked to the
corresponding code. However he did not use his
technique with a knowledge base of domain
(business) concepts. In contrast with these
techniques, our approach is “business-function-
driven” i.e. we clusters the software elements
according to the supported the business tasks and
functions. The domain modelling discipline of our
reverse-engineering method presents some similarity
with the work of Gall et al. (Gall, Klosch,
Mittermeier 1996) (Gall, Weidl 1999). These
authors tried to build an object-oriented
representation of a procedural legacy system by
building two object models. First, with the help of a
domain expert, they build an abstract object model
from the specification of the legacy system. Second,
they reconstruct an object model of the source code,
starting from the recovered entity-relationship model
to which they append dynamic services. Finally,
they try to match both object models to produce the
final object oriented model of the procedural system.
The authors report that one of the main difficulties is
the assignation of the dynamic features to the
recovered objects (what they call the “ambiguous
service candidates”). In contrast, our approach does
not try to transform the legacy system into some
object-oriented form. The robustness diagram we
build is simply a way to document the software
roles. Our work bears some resemblance to the work
of Eisenbarth and Koschke (Eisenbarth, Koschke
2003) who used Formal Concept Analysis. However
the main differences are:
1. The scenarios we use have a strong business-
related meaning rather than being built only to
exhibit some features. They represent full use-
cases.
2. The software clusters we build are interpretable
in the business model. We do group the software
element after their roles in the implementation of
business functions.
3. We analyse the full execution trace from a real-
use-case to recover the architecture of the
system.
4. The elements we cluster are modules or classes
identified in the visible high-level structure of
the code.
Finally, it is worth noting that the use-cases play, in
our work, the same role as the test cases in the
execution slicing approach of Wong et al. (Wong,
Gokhale, Horgan, Trivedi 1999). However, in our
work, the “test cases” are not arbitrary but represent
actual use-cases of the system.
6 CONCLUSION
The reverse-engineering process we present in this
article rests on the Unified Process from which we
borrowed some activities and artefacts. The
techniques are based on the actual working of the
code in real business situations. Then, the
architecture we end up with is independent on the
number of maintenances to the code. Moreover it
can cope with situation like dynamic calls, which are
tricky to analyse using static techniques. We
actually reverse-engineered all the use-cases of the
system and found that the modules involved in all of
them were almost the same. Finally, this experiment
seems to show that this technique is scalable and is
able to deal with industrial size software.
As a next step in this research we are developing a
semi-automatic robustness diagram mapper that
takes a robustness diagram and a trace file as input
and produces a possible match as output. This
system uses a heuristic-based search engine coupled
to a truth maintenance system.
ROLE-BASED CLUSTERING OF SOFTWARE MODULES - An Industrial Size Experiment
11

ACKNOWLEDGEMENTS
We gratefully acknowledge the support of the
“Reserve Strategique” of the Swiss Confederation
(Grant ISNET 15989). We also thank the people at
the CTI of the Canton Geneva (Switzerland) who
helped us perform the industrial experiment.
REFERENCES
Andritsos P., Tzerpos V. 2003. Software Clustering based
on Information Loss Minimization. Proc. IEEE
Working Conference on Reverse engineering.
Andritsos P., Tzerpos V. 2005. Information Theoretic
Software Clustering. IEEE Trans. on Software
Engineering 31(2), 2005.
Bergey J. et al. 1999. Why Reengineering Projects Fail.
Software Engineering Institute, Tech Report
CMU/SEI-99-TR-010, Apr. 1999.
Bergey J., Smith D., Weiderman N., Woods S. 1999.
Options Analysis for Reengineering (OAR): Issues and
Conceptual Approach. Software Engineering Institute,
Tech. Note CMU/SEI-99-TN-014.
Biggerstaff T. J., Mitbander B.G., Webster D.E. 1994.
Program Understanding and the Concept Assignment
Problem. Communicaitons of the ACM, CACM 37(5).
Binkley D.W., Gallagher K.B. 1996. Program Slicing.
Book chapter in: Advances in Computers, vol 43,
Academic Press, 1996.
Dugerdil Ph. 2006. A Reengineering Process based on the
Unified Process. IEEE International Conference on
Software Maintenance.
Eisenbarth T., Koschke R. 2003. Locating Features in
Source Code. IEEE Trans. On Software Engineering
29(3) March 2003.
Gall H., Klosch R. Mittermeir R. 1996. Using Domain
Knowledge to Improve Reverse Engineering. Int. J. on
Software Engineering and Knowledge Engineering
(IJSEKE), 6(3).
Gall H., Weidl J. 1999. Object-Model Driven Abstraction
to Code Mapping. Proc. European Software
engineering Conference, Workshop on Object-
Oriented Reengineering.
Gold N. E. 2000. Hypothesis-Based Concept Assignment
to Support Software Maintenance. PhD Thesis, Univ.
of Durham.
Jacobson I., Booch G., Rumbaugh J.1999. The Unified
Software Development Process. Addison-Wesley
Professional.
Kazman R., O’Brien L., Verhoef C. 2003. Architecture
Reconstruction Guidelines, 3
rd
edition. Software
Engineering Institute, Tech. Report CMU/SEI-2002-
TR-034.
Kuhn A., Ducasse S., Girba T. 2005. Enriching Reverse
Engineering with Semantic Clustering. Proc. IEEE
IEEE Working Conference on Reverse engineering.
Linding C., Snelting G. 1997. Assessing Modular
Structure of Legacy Code Based on Mathematical
Concept Analysis. Proc IEEE Int. Conference on
Software Engineering .
Marcus A. 2004. Semantic Driven Program Analysis. Proc
IEEE Int. Conference on Software Maintenance .
Mitchell B.S. 2003. A Heuristic Search Approach to
Solving the Software Clustering Problem. Proc IEEE
Conf on Software Maintenance.
Müller H.A., Orgun M.A., Tilley S., Uhl J.S. 1993. A
Reverse Engineering Approach To Subsystem
Structure Identification. Software Maintenance:
Research and Practice 5(4), John Wiley & Sons.
Wiggert T.A. 1997 – Using Clustering Algorithms in
Legacy Systems Remodularisation. Proc. IEEE
Working Conference on Reverse engineering.
Rajlich V., Wilde N, 2002. The Role of Concepts in
Program Comprehension. Proc IEEE Int. Workshop
on Program Comprehension.
Siff M., Reps T. 1999. Identifying Modules via Concept
Analysis. IEEE Trans. On Software Engineering 25(6).
Tilley S.R., Santanu P., Smith D.B. 1996. Toward a
Framework for Program Understanding. Proc. IEEE
Int. Workshop on Program Comprehension.
Tonella P. 2001. Concept Analysis for Module
Restructuring. IEEE Trans. On Software Engineering,
27(4).
Tonella P. 2003. Using a Concept Lattice of
Decomposition Slices for Program Understanding and
Impact Analysis. IEEE Trans. On Software
Engineering. 29(6)
Verbaere M. 2003 - Program Slicing for Refactoring. MS
Thesis, Oxford University.
Wen Z., Tzerpos V. 2004 – An Effective measure for
software clustering algorithms. Proc IEEE Int.
Workshop on Program Comprehension.
Wiggert T.A. 1997. Using Clustering Algorithms in
Legacy Systems Remodularisation. Proc. IEEE
Working Conference on Reverse engineering.
Wong W.E., Gokhale S.S., Horgan J.R., Trivedi K.S.
1999. Locating Program Features using Execution
Slices. Proc. IEEE Conf. on Application-Specific
Systems and Software Engineering & Technology.
ICSOFT 2007 - International Conference on Software and Data Technologies
12
