
IMPROVED SERVICE RANKING AND SCORING: SEMANTIC
ADVANCED MATCHMAKER (SAM)
Erdem S. Ilhan, Gokay B. Akkus
Department of Computer Engineering, Bogazici University, Istanbul, Turkey
Ayse B. Bener
Department of Computer Engineering, Bogazici University, Istanbul, Turkey
Keywords: Matchmaking, semantic similarity, scoring, ranking, OWL-S, bi-partite graph, scoring, semantic distance.
Abstract: In recent years Semantic Web has drawn a lot of attention in order to solve the problem of automatic
discovery and processing of web services. Although there are different efforts and frameworks for semantic
annotation and discovery of web services, they mostly classify the discovered web services as set-based.
Improvement in matching process could be gained by the use of ontological information in a useful form.
The goal of this research is to propose a more accurate discovery method using the ontological distance
information defined and ranked by users. In this paper, we focus on one of the most challenging tasks in
service discovery: matchmaking process. We use an efficient matchmaking algorithm based on bi-partite
graphs. Our proposed algorithm uses attribute ranking through weight assignment. Our experiment results
show that bi-partite matchmaking has advantages over other approaches in the literature for parameter
pairing problem. We present value added approaches in matchmaking such as property-level matching,
semantic distance information and WordNet scoring. The value added approaches provide better scoring
scheme and allows similarity to be captured resulting in ranking of services according to their relatedness.
1 INTRODUCTION
In recent years, web services became the dominant
technology in providing the interoperability among
different systems throughout the web. The problem
of finding the right and most suitable web services
for user needs emerges when open e-commerce
systems are widely used and user requirements
dynamically change over time.
Although there are currently proposed
technologies for discovery of web services, such as
UDDI (http://www.uddi.org,, 2006.), they do not
satisfy the full discovery requirements. This
discovery process is based on syntactical matching
and keyword search that does not allow the
automatic processing of web services. To solve the
problem of automatic discovery and processing of
web services, the Semantic Web (
http://www.w3.org/2001/sw/, 2006.) as a new vision
is proposed. The Semantic Web is an effort by the
W3C consortium (http://www.w3.org/, 2006.), and
one of its main purposes is to facilitate the discovery
of web resources.
There are different efforts and frameworks for
semantic annotation and discovery of web services
(Motta, E., J. Domingue, L. Cabral and M. Gaspari,
2003, Fensel, D. and C. Bussler, 2002). For web
service discovery they also propose some techniques
and algorithms. However, they mostly classify the
discovered web services in set-based approaches.
They do not focus on rating the web services using
semantic distance information (Klein, M., B. Konig-
Ries and M. Muussig, 2005).
The evolution of web services, from
conventional services to semantic services, caused
service descriptions contain extra information about
functional or non-functional properties of web
services. The semantic information included in the
service descriptions enables the development of
advanced matchmaking schemes, capable of
assigning degrees of match to the discovered
services. Semantic discovery of web services means
semantic reasoning over a knowledge base, where a
95
S. Ilhan E., B. Akkus G. and B. Bener A. (2007).
IMPROVED SERVICE RANKING AND SCORING: SEMANTIC ADVANCED MATCHMAKER (SAM).
In Proceedings of the Second International Conference on Evaluation of Novel Approaches to Software Engineering , pages 95-102
DOI: 10.5220/0002586700950102
Copyright
c
SciTePress

goal describes the required web service capability as
input. Semantic discovery adds accuracy to the
search results in comparison to traditional Web
service discovery techniques, which are based on
syntactical searches over keywords contained in the
web service descriptions (U. Keller, Lara R.,
Polleres A, 2004).
Improvement in matching process could be
gained by the use of ontological information in a
useful form. With the use of this information, it can
be possible to rate the services found in discovery
process. As in real life, users/ agents should be able
to define how they see the relation of ontological
concepts from their own perspective. Similarity
measures have been widely used in information
systems (Voorhees, E, 1998, Ginsberg, A., 1993,
Lee, J., M. Kim and Y. Lee, 1993), cognitive
science, software engineering and AI (Agirre, E. and
G. Rigau, 1996, Hovy, E., 1998, Wang, Y. and E.
Stroulia, 2003). So integration of knowledge from
these techniques can improve the matching process.
By using semantic distance definition
information, we aim to get a rated and ordered set of
web services as the general result of the discovery
process. We believe that this would be better than
set-based classification of discovered services. In
this paper, we propose a new scheme of
matchmaking that aims to improve retrieval
effectiveness of semantic matchmaking process. Our
main argument is that conventional evaluation
schemes do not fully capture the added value of
service semantics and they do not consider the
assigned degrees of match, which are supported by
the majority of discovery engines. The existing
approach to service matchmaking contains
subsumption values regarding the concept that the
service supports. In our proposed approach, we add
semantic relatedness values onto existing
subsumption-based procedures. We introduce value
added approaches to matchmaking process such as
property-level matching, semantic distance
information and WordNet scoring. Property-level
matching provides capturing similarity between
concepts that do not have a subsumption relation. So
that, services that would not be classified, are ranked
with our matchmaking agent. Similarity distance
provides user’s profile to be represented in the
ontology. Similarity distance weights can be
assigned on the links between concepts to specify
concepts relatedness to each other in an explicit way.
Also by making use of WordNet, we introduce a
second source of semantic repository to be utilized
in matchmaking. Our test results in section 5
indicate that these value added approaches increases
the captured semantic relations between parameters
of services and provide a better ranking of services
resulting in better user experience in matchmaking.
2 RELATED WORK
Semantic Web services aim to realize the vision of
the Semantic Web, i.e. turning the Internet from an
information repository for human consumption into
a worldwide system for distributed Web computing
(http://www.w3.org/2001/sw/, 2006.). The system is
a machine-understandable media where all the data
is combined with semantic metadata. The domain
level formalizations of concepts form up the main
element within this system, which is called ontology
(http://www.w3.org/Submission/OWL-S, 2004).
Ontology represents concepts and relations between
the concepts; these can be hierarchical relations,
whole-part relations, or any other meaningful type of
linkage between the concepts(H. El-Ghalayini, M.
Odeh, R. McClatchey, and T. Solomonides,, 2005).
The semantic matchmaking process is based on
ontology formalizations over domains. In the
upcoming section we present some of the selective
research on the matchmaking process considering
the concepts that we build our research on.
Matchmaking of Web services considers the
relationship between two services. The first one is
called the advertisement and the other is called the
request (Klusch, M., Fries, B., Khalid, M., and
Sycara, K.. 2005). Advertisement denotes the
services description of the existing services while
the request indicates the picture of service
requirements (Wang, Y. and E. Stroulia, 2003).
In (Wang, H., Zengzhi L., Fan L., 2006), the
problem of capability matchmaking is analyzed with
regarding to Web services, especially the
Preconditions and Effects (PE) matchmaking. In the
paper, the authors present a service similarity
function that determines similar parameter classes
by using a matching process over synonym sets,
semantic neighbourhood, and distinguishing
features. Parameter pairing is the process that is used
for matching service descriptions. In the work,
maximum weight bi-partite graph matching method
is utilized for parameter finding; the weights of bi-
partite graph’s edges are evaluated with matching
degree between function parameters calculated by
the similarity function mentioned above.
Although good results are obtained with the
usage of this method, it should still be improved in
two terms: One is that, it needs to be extended on
pre-condition and affect because the matching is
ENASE 2007 - International Conference on Evaluation on Novel Approaches to Software Engineering
96

performed only on parameters of input and output,
and the functional signature is not sufficient to
identify what it does. The other is that this
framework should be combined with particular
directory service like UDDI in order to improve the
discovery efficiency.
In (Paolucci M.; Kawamura,T.; Payne,T. and
Sycara,K. , 2002) the authors present an algorithm
that deals with the localization of Web services. The
research does not address the interoperability
problem. The system introduced uses the service
profile ontology from the DAML-S specification
language but only considers the matching of input
and output concepts defined by the same ontology.
Traditional approaches to modelling semantic
similarity between Web Services compute subsume
relationship for function parameters in service
profiles within a single ontology. In (Ruiqiang Guo,
Dehua Chen, Jiajin Le, 2005) a graph theoretic
framework based on bi-partite graph matching for
finding the best correspondences among function
parameters belonging to advertisement and request
is introduced. On computing semantic similarity
between a pair of function parameters, a similarity
function is introduced, determining similar entity,
which relaxes the requirement of a single ontology
and accounts for the different ontology
specifications. The function presented for semantic
similarity across different ontologies provides an
approach to detect similar parameters. The method is
based on a matching process over weighted sum of
synonym sets, semantic neighbourhood, and
distinguishing features. The method mainly lacks
use of functional similarities and lexical evaluation
of semantic mappings.
In (COMPSAC, 2006), a semantic ranking MSC
is designed to rank the results of advertisements
matchmaking. MSC stands for the initials of three
factors’ second words: Semantic Matching Degree
(to capture the semantic aspects of attributes),
Semantic Support (to describe the interestingness or
potential usefulness of an attribute) and Relational
Confidence (to capture the association relationships
among attributes). Three categories of attributes are
defined in advertisements matchmaking:
Generalizable Nominal Attribute (GNA) whose
values can form a concept hierarchy; Numeric
Attribute (NUA), called quantitative attribute, whose
values are numeral; Nominal Attribute (NOA)
whose values are neither numeral nor can form a
concept hierarchy. Three new factors are designed to
capture the semantic characteristics and relationships
of the attributes: Semantic Matching Degree,
Semantic Support and Relational Confidence.
3 PROBLEM STATEMENT
The first step in service composition is identifying
the domain of interest by means of taxonomy of
subject categories. The discovery and selection of
services those are suitable for a given request is
obtained in two phases. Firstly, matchmaking
approach is based on the ontological framework. It is
applied on the set of available services in order to
find services that match needs of the requestor from
a functional point of view. Secondly, services are
ranked and further refined. This is done by taking
into account context information of the requestor.
Then preconditions or post-conditions can be
defined as mandatory or optional.
The problem that we are concerned is the first
step of this scenario: given a request r, finding right
web services for r. The main goal of this research is
to gain better precision and recall values on
matchmaking by considering user requests in web
services discovery.
The previous work on semantic matchmaking
focused on taking advantage of a single
implementation based on some information retrieval
theory. The experimental research so far has shown
simple subsumption based matchmaking is not
sufficient to capture semantic similarity.
In this research, we aim to provide an efficient
and accurate matchmaking algorithm using scoring
and ranking based on similarity distance
information, extended subsumption and property
level similarity assessment in a general semantic
web service discovery framework.
4 PROPOSED SOLUTION
In this paper we propose a hybrid approach on
semantic matchmaking. Our proposed solution uses
decision modules that can be plugged in and out. We
have implemented some of these modules to add
semantic relatedness values onto existing
subsumption-based procedures. Our proposed
matchmaker agent mainly provides ranking and
scoring based on concept similarity. The
components of the proposed system are shown in
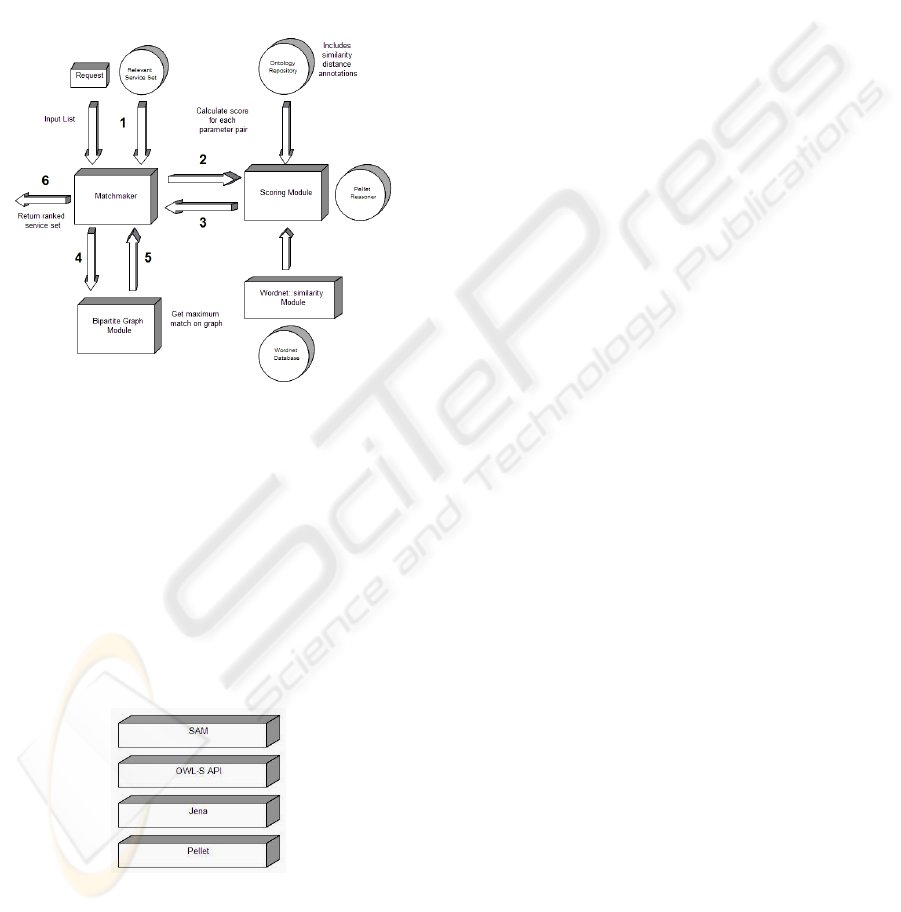
Figure 1. Request service definition and the
corresponding relevant services set, which are
discovered through conventional discovery
mechanisms, are presented as input to the system.
The ontology and services we use are retrieved from
“OWL-S Service Retrieval Test Collection version
2.1”. The services in the collection are mostly
extracted from public UDDI registries, providing
IMPROVED SERVICE RANKING AND SCORING: SEMANTIC ADVANCED MATCHMAKER (SAM)
97
582 web services described in OWL-S from seven
different domains. The OWL-S Test collection
version 2.1 contains 29 queries, each of which
associated with a set of 10 to 15 services (Mahboob
Alam Khalid, Benedikt Fries, Patrick Kapahnke,
2006). We extended some ontologies in this test
collection for our own purposes in order to better
demonstrate the features of our proposed
matchmaking agent. We believe that a formal test
collection of OWL-S services is crucial for the
evaluation of matchmaking agents.
Figure 1: Matchmaking agent components.
The main software components of our proposed
matchmaking agent are shown in Figure 2. The top
layer represents our matchmaker SAM (Semantic
Advanced Matchmaker). OWL-S API models the
service, profile, process and grounding ontologies of
OWL-S in an easy to use manner. It is a widely used
API in semantic applications. OWL-S API also
presents interfaces for reasoning operations and
utilizes Jena constructs at the back-end. At the
bottom of the hierarchy we have Pellet reasoner for
OWL reasoning operations.
Figure 2: Software components of matchmaking agent.
We believe that a discrete scale (exact, plug-in,
subsume, and fail) of service classification is not
sufficient for a matchmaking process. On the other
hand, semantic ranking of services can capture a set
of services that are lost in a discrete scale match.
Semantic similarity assessment is a crucial step for
the ranking process. In our proposed system, we
present value-added similarity assessment
approaches between service and request parameter
pairs.
4.1 Matching Algorithm
Previous research has shown that bi-partite graph
matching algorithm is a good fit for finding
matching parameters in a service and request pair
(Herbert Alexander Baier Saip, Claudio Leonardo
Lucchesi, 1993). Bi-partite graph matching provides
us a solution for parameter pairing problem. We
consider the inputs and outputs as separate cases and
partition the service parameters and request
parameters to form the bi-partite graph. The
similarity assessment process of our matchmaker
assigns weights for each parameter pair on this bi-
partite graph. A maximum weight match on the final
graph leaves us with the optimum matching
parameter pairs and with a score that is sum of the
weights between matched parameter pairs. We
repeat this process for each service and request pair
and finally rank the services according to their score
from bi-partite graph matching algorithm.
As we stated before the process that
differentiates the services is the similarity
assessment process. We consider OWL-S profiles of
service definitions and assign similarity scores for
input and output parameter pairs. We present the
following value-added features for similarity
assessment: Subsumption based similarity, WordNet
based similarity, similarity distance information and
WordNet similarity assessment.
4.1.1 Subsumption based Similarity
Assessment
We make use of OWL-DL constructs subClassOf,
disjointWith, complementOf, unionOf and
intersectionOf to assess concept similarity based on
subsumption. If two concepts are explicitly stated to
be complement or disjoint, a zero score is directly
assigned. Otherwise, we check for subclass relation
and also assess according to property level
assessment procedure described below.
We wanted to capture similarity values in bi-
partite graph since it is important to decompose
concepts that include the characteristic of “a union
of”. Following this approach, we always pair and
assess score for atomic concepts in matchmaking
process.
ENASE 2007 - International Conference on Evaluation on Novel Approaches to Software Engineering
98

4.1.2 Property-level Similarity Assessment
We have assumed that in matchmaking it is also
important to have properties and their associated
range in measuring the degree of match. Such as, if
two concepts have similar properties (properties
having subclass relation) and their range classes are
similar, then this improves their level of similarity.
Using property level similarity assessment ranks a
service that would normally be eliminated by a
conventional matchmaker. For example, a user
request may favour a particular author for a novel. A
service, which returns articles that are written by that
particular author, will have a high score even though
the concept of “an article” does not compare to the
concept of “a novel”. Therefore our proposed system
returns positive results for concepts that have similar
properties as well as the similar concepts.
4.1.3 Similarity Distance based Assessment
To represent similarity distance information we
applied N-ary relation pattern in OWL, which is
used to represent additional attributes on a property.
The additional attribute in our case is the similarity
distance value. Figure 3 shows how this pattern is
organized:
Figure 3: N-ary relation pattern in OWL, representing
similarity distance information.
SimilarityRelation concept is introduced as a
class with this pattern and the similarity distance
value is represented as the range of
hasSimilarityDegree property of this concept. The
similar classes are represented as Concept_1 and
Concept_2 in Figure 3.
We follow the standards approach by
representing similarity distance information in
OWL, which can be imported and used in other
ontologies (Şenvar, M. and Bener, A., 2006).
Similarity distance information is useful in reflecting
user’s profile on the ontology. The importance and
relatedness of concepts for the user are represented
as weights on the ontology. In addition, if similarity
distance annotation is not found between two
concepts, then a default distance value is assigned
according to the following formula:
Sd
x,y
= 1/|subClassOf(x)
direct
| (1)
In the above formula Sd
x,y
represents similarity
distance between concepts x and y and
|subClassOf(x)
direct
| represents the number of
elements in set of direct subclasses of concept x.
4.1.4 WordNet based Similarity Assessment
WordNet organizes words into synonym sets, which
are also linked to each other representing a semantic
relation. In our matchmaker we take WordNet as a
secondary source of information with the ontology
repository. We aimed at reasoning with these highly
structured information sources in order to get more
reliable result sets.
We make use of wordnet::similarity open source
project to assess similarity score among words. The
path length criterion is used for score assignment.
The parameter types of services are presented as
input to wordnet::similarity module.
5 EVALUATION AND RESULTS
In order to evaluate the performance of our proposed
matchmaking agent we extended the book ontology
in OWL-S Service Retrieval Test Collection (OWL-
S TC) and also modified related request and service
definitions accordingly (Mahboob Alam Khalid,
Benedikt Fries, Patrick Kapahnke,, 2006). As shown
in Figure 4, we added subclasses of Magazine,
namely Foreign-Magazine and Local-Magazine
classes.
Figure 4: Printed Material ontology section.
As shown in Figure 5, we created subclasses of
Publisher: Ordinary-Publisher, Alternative-
Publisher and Premium-Publisher. We also created
Local-Author and Foreign-Author classes, which are
subclasses of class Author.
The matchmaking agent is developed in Java and
it makes use of open source semantic web libraries
like OWL-S API and Jena. We also used Pellet as
the reasoning engine for OWL operations.
IMPROVED SERVICE RANKING AND SCORING: SEMANTIC ADVANCED MATCHMAKER (SAM)
99
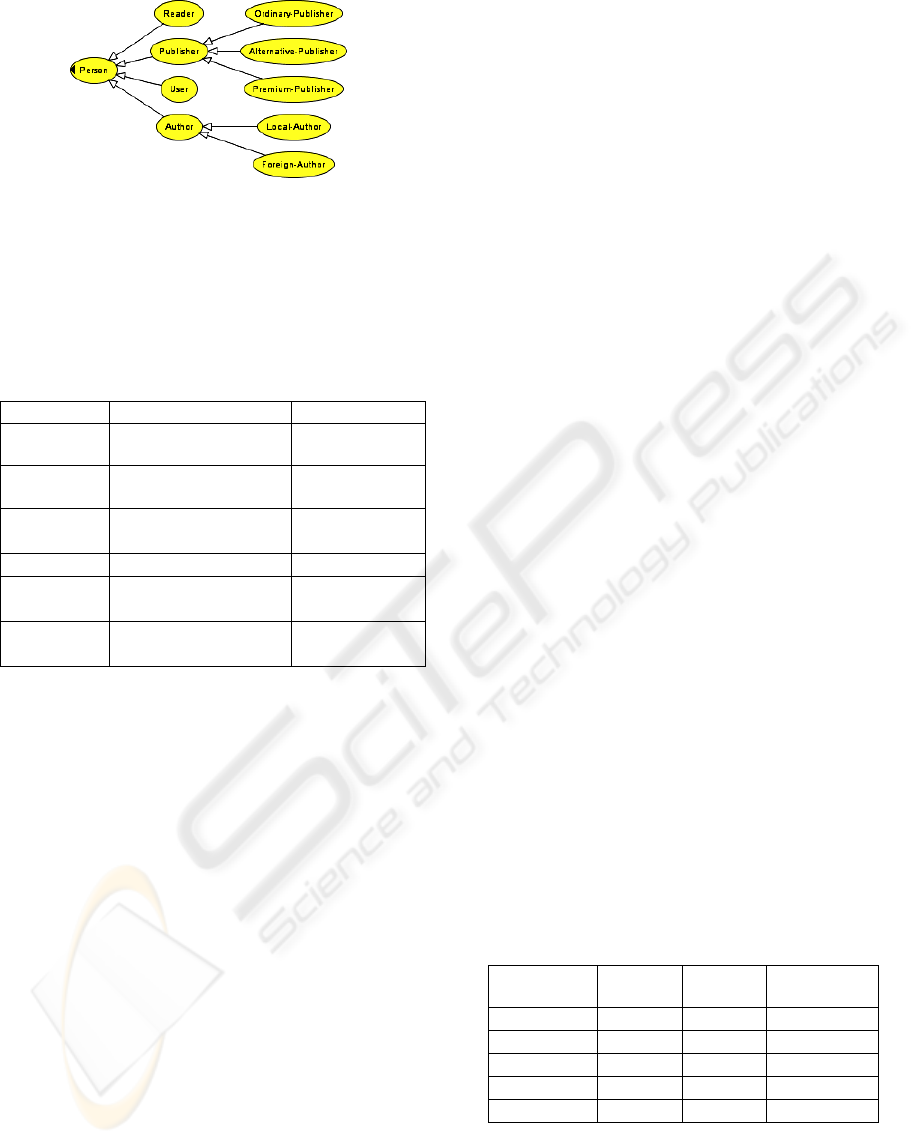
Figure 5: Person ontology section.
To represent subsumption reasoning, similarity
distance based assessment and property-level
similarity assessment capabilities we define the
following request and services as described in Table
1:
Table 1: Test request and service set.
Inputs Outputs
Request Ordinary-Publisher,
Novel, Paper-Back
Local-Author,
Genre
Service 1 Publisher,
ScienceFictionBook
Author, Price
Service 2 Book, Alternative-
Publisher, Book-Type
Publisher,
Price, Date
Service 3 FantasyNovel, Author
Price, Comic
Service 4 Newspaper, Book-
Type, Person
Review,
Fantasy
Service 5 Publication, Book-
Type, Reader
Time,
Publisher
For the above test collection the property level
similarity assessment plays an important role. Even
though Novel concept has no subclass relation with
ScienceFictionBook concept, both concepts have
properties like writtenBy and publishedBy. Thus, our
matchmaker applies a subsumption reasoning on
ranges for these properties, which are Author with
its subclasses, and Publisher with its subclasses.
Finally, an additional score is provided for these
services. A conventional matchmaker would have
ignored these services as a “fail”.
The property level matching score is determined
by the following formula:
Sp
x,y
= w
p
*Subsumption
x,y
(2)
In the above equation, Sp
x,y
represents property
level match score between range concepts x and y.
We use the semantic score obtained through
subsumption, property level matching and semantic
distance. WordNet
x,y
represents the WordNet score
for concept names. The coefficients for subsumption
and WordNet are fixed at 0.9 and 0.1 after making
several experimental runs. We plan to apply a neural
network training approach to determine values for
coefficients utilizing a large training data in future.
The following equation represents how the
subsumption score and WordNet score is considered
as the final similarity score.
S
x,y
= w
sub
*Subsumption
x,y
+
w
word
*WordNet
x,y
(3)
S
x,y,
in the above equation,
represents final similarity
score between concepts x and y. Subsumption
x,y
represents semantic score obtained through
subsumption, property level matching and semantic
distance. WordNet
x,y
represents the WordNet score
for concept names. The coefficients for subsumption
and WordNet are fixed at 0.9 and 0.1 after making
experimental runs. We plan to apply a neural
network training approach to determine values for
coefficients utilizing a large training data in future.
To consider how semantic distance information
affects our ranking we introduced the following
weights into the book ontology as described in
following list:
Publisher → Ordinary-Publisher: 0.2
Publisher → Alternative-Publisher: 0.5
Publisher → Premium-Publisher: 0.3
Author → Local-Author: 0.3
Author → Foreign-Author: 0.7
Magazine → Foreign-Magazine: 0.7
Magazine → Local-Magazine: 0.3
Book → Short-Story: 0.2
Book → Science-Fiction-Book: 0.4
Book → Novel: 0.3
Book → Encyclopedia: 0.1
Novel → Science-Fiction-Novel: 0.6
Novel → Fantasy-Novel: 0.2
Novel → Romantic-Novel: 0.2
Book-Type → Hard-Cover: 0.7
Book-Type → Paper-Back: 0.3
The ranking with semantic distance information is
listed in Table 2 as follows:
Table 2: Service I/O similarity scores.
Input
Score
Output
Score
Overall
Score
Service1 0.916 0.143 0.452
Service 2 0.345 0.096 0.195
Service 3 0.896 0.0003 0.444
Service 4 0.148 0.0003 0.059
Service 5 0.187 0.096 0.075
Considering the inputs Service 1 got the greatest
score as it has a subsume relation with the request
parameter Ordinary-Publisher and property-level
matching with Novel parameter. The third request
parameter is not considered, as the service only
ENASE 2007 - International Conference on Evaluation on Novel Approaches to Software Engineering
100

needs two. For the outputs we have Service 1 ranked
higher than others. Indeed, none of the services
satisfy all output requirements of the request. But
considering similarity distance information the
ranking is determined as above. Overall score favors
the output score by assigning a higher weight to that,
as the outputs of a service is more important to the
requestor. As a result, Service 1 is the most related
service for the specified request.
The similarity distance formulation is defined as
follows:
Sd
x,y
= Sd
x,t
* Sd
t,k
*…*Sd
m,y
(4)
In the above equation, Sd
a,b
∈ [0,1] for any a and
b pair. Sd
x,y
represents similarity distance between
concepts x and y. The product of similarity distance
values on the path from x and y gives the value for
Sd
x,y
. If the concepts are not subclasses of eachother
then we take the path including their first common
parent in the hierarchy.
The final subsumption similarity score
considering the similarity distance is shown below:
Ss
x,y
= w
direction
* Sd
x,y
(5)
w
direction
in the above equation,
varies according to
the subsumption property. Considering input
parameters the service parameter to subsume the
request parameter is favored and in the case of
outputs the reverse is true. So, we set w
direction
coefficient to either 0.6 or 0.4 according to this
approach. The values are determined after running
experimental tests.
6 CONCLUSION
We proposed a novel advanced matchmaker, which
introduces new value-added approaches like
semantic distance based similarity assessment,
property level assessment and WordNet similarity
scoring. Instead of classifying candidate web
services in a discrete scale, our matchmaking agent
applies a scoring scheme to rank candidate web
services according to their relevancy to the request.
The ranking property enables to include some of
the relevant web services in the final result set
whereas they would have been discarded in a
discrete scale classification. Additionally, our
proposed matchmaking agent improves
subsumption-based matchmaking by utilizing OWL
constructs efficiently and by considering down to a
level of concept properties in the process.
We also introduced semantic distance annotation
in ontology to represent relevancy of concepts to the
user in a numerical way. Semantic distance
annotations improve the relevancy of returned web
service set as they actually represent user’s view of
ontology. WordNet similarity measurement is also
presented as a value-added feature, which acts as a
secondary source of information, strengthening the
power of reasoning.
Our experiment results show that property level
matching can be a good method to capture
similarities between concepts that do not have a
subsumption relationship. An improvement at this
point can be to consider similarity between
properties in addition to similarity of property range
objects. Besides, similarity distance information
provided us with a method to further differentiate
the importance of concepts from the point of view of
the user. The test results show how similarity
distance plays an important role in service ranking.
We are still working on other ontologies to
further test our matchmaker agent and plan to
consider preconditions and effects of services in
matchmaking process. This will require the use of
SWRL (Semantic Web Rule Language) to represent
preconditions and effects as rules in the system.
Another improvement will be to add context
aware decision-making capabilities, enabling our
matchmaking agent to reason based on user profiles,
preferences, past actions etc. The system that we
have presented can be considered as a basis for the
development of context-aware agent.
REFERENCES
Wang, H., Zengzhi L., Fan L., 2006. An Unabridged
Method Concerning Capability Matchmaking of Web
Services, In Proceedings of the 2006 IEEE/WIC/ACM
International Conference on Web Intelligence.
Klusch, M., Fries, B., Khalid, M., and Sycara, K., 2005.
OWLS-MX: Hybrid Semantic Web Service Retrieval.
In 1st Intl. AAAI Fall Symposium on Agents and the
Semantic Web, AAAI Press, Arlington VA.
U. Keller, Lara R., Polleres A., WSMO Web Service
Discovery, www.wsmo.org/2004/d5/d5.1/v0.1/20041112/.
H. El-Ghalayini, M. Odeh, R. McClatchey, and T.
Solomonides, 2005. Reverse Engineering Ontology to
Conceptual Data Models, In Proceeding (454)
Databases and Applications.
Universal Discovery Description and Integration
Protocol, http://www.uddi. org, 2006. Semantic Web,
W3C, http://www.w3.org/2001/sw/, 2006.
W3C, World Wide Web Consortium, http://www.w3.org/,
2006.
Mahboob Alam Khalid, Benedikt Fries, Patrick Kapahnke,
2006. OWL-S Service Retrieval Test Collection
Version 2.1, Deutsches Forschungszentrum für
Künstliche Intelligenz GmbH Saarbrücken, Germany.
IMPROVED SERVICE RANKING AND SCORING: SEMANTIC ADVANCED MATCHMAKER (SAM)
101

Herbert Alexander Baier Saip, Claudio Leonardo
Lucchesi, Matching Algorithms for Bi-partite Graphs,
Relatorio Tecnico DCC-03/93.
Motta, E., J. Domingue, L. Cabral and M. Gaspari, 2003
"IRS-II: A Framework and Infrastructure for Semantic
Web Services", Proceedings of the 2nd International
Semantic Web Conference (ISWC2003), Vol. 2870 of
LNAI., Springer, pp.306-318, Florida, USA. OWL-S
Submission,
http://www.w3.org/Submission/OWL-S, 2004.
Fensel, D. and C. Bussler, 2002. "The Web Service
Modeling Framework: WSMF", Electronic
Commerce: Research and Applications, Vol. 1, No. 2,
pp. 113-137.
Klein, M., B. Konig-Ries and M. Muussig, 2005. "What is
needed for semantic service descriptions? A proposal
for suitable language constructs", Proceedings of
Inernational Journal of Web and Grid Services, Vol.
1, No. 3/4, pp. 328-364.
Voorhees, E., 1998 "Using WordNet for Text Retrieval”,
C. Fellbaum(Editor),"WordNet: An Electronic Lexical
Database", pp. 285-303, The MIT Press, Cambridge.
Ginsberg, A., 1993 "A Unified Approach to Automatic
Indexing and Information Retrieval", IEEE Exper,
Vol. 8, No. 5, pp 46-56.
Lee, J., M. Kim and Y. Lee, 1993. "Information Retrieval
Based on Conceptual Distance in IS-A Hierarchies",
Journal of Documentation, Vol. 49, No. 2, pp. 188-207.
Agirre, E. and G. Rigau, 1996 “Word Sense
Disambiguation Using Conceptual Density”,
Proceedings of the 16th Conference on
ComputationalLlinguistics, Vol.1, pp. 16-22.
Hovy, E., 1998 “Combining and Standardizing Large-
scale, Practical Ontologies for Machine Translation
and Other Uses", Proceedings of the 1st International
Conference on Language Resources and Evaluation
(LREC), Granada, Spain.
Wang, Y. and E. Stroulia, 2003 “Semantic Structure
Matching for Assessing Web-Service Similarity”,
Proceedings of the 1st International Conference on
Service Oriented Computing, Trento, Italy.
Ruiqiang Guo, Dehua Chen, Jiajin Le, 2005. Matching
Semantic Web Services accross Heterogeneous
Ontologies, Proceedings of the 2005 The Fifth
International Conference on Computer and
Information Technology (CIT’05).
Paolucci,M., Kawamura,T., Payne,T., and Sycara,K.,
2002. Semantic matching of web services capabilities.
In Horrocks, I. And Hendler, J.eds.Proc. of the 1st
International Semantic Web Conference(ISWC),
pages333-347. Springer.
MSC: A Semantic Ranking for Hitting Results of
Matchmaking of Services, Proceedings of the 30th
Annual International Computer Software and
Applications Conference (COMPSAC'06)
O. Taha, T. Dhavalkumar, Al-Dabass D., 2006. Semantic-
Driven Matchmaking of Web Services Using Case-
Based Reasoning, IEEE International Conference on
Web Services.
Şenvar, M. and Bener, A., 2006, “Matchmaking of
Semantic Web Services Using Semantic- Distance
Information”, Lecture Notes in Computer Science by
Springer Verlag, ADVIS 2006, October, 18-20, İzmir,
Turkey.
ENASE 2007 - International Conference on Evaluation on Novel Approaches to Software Engineering
102
