
FEATURE SETS FOR PEOPLE AND LUGGAGE RECOGNITION IN
AIRPORT SURVEILLANCE UNDER REAL-TIME CONSTRAINTS
J. Rosell-Ortega, G. Andreu-Garc´ıa, A. Rodas-Jord`a, V. Atienza-Vanacloig and J. Valiente-Gonz´alez
DISCA, Universidad Polit´ecnica de Valencia, camino de Vera s/n Valencia. Spain
Keywords:
Surveillance, object classification, object recognition, shadow removal, feature sets.
Abstract:
We study two different sets of features with the aim of classifying objects from videos taken in an airport.
Objects are classified into three different classes: single person, group of people, and luggage. We have used
two different feature sets, one set based on classical geometric features, and another based on average density
of foreground pictures in areas of the blobs. In both cases, easily computed features were selected because
our system must run under real-time constraints. During the development of the algorithms, we also studied if
shadows affect the classification rate of objects. We achieved this by applying two shadow removal algorithms
to estimate the usefulness of such techniques under real-time constraints.
1 INTRODUCTION
1
In this paper we present a comparative study re-
garding classification within the framework of visual
surveillance. Our aim is to classify each moving ob-
ject in the input video as a single person, a group of
people or unattended luggage.
Visual surveillance, either indoors or outdoors, is
an active research topic in computer vision and var-
ious surveillance systems have been proposed in re-
cent years: (Haritaoglu et al., 2000), (W. Hu et al.,
2004), (Wren et al., 1997). The visual surveillance
process may be divided into the following steps: en-
vironment modelling, motion detection, object clas-
sification, tracking, behaviour understanding, human
identification and data fusion.
In our application, airport surveillance, attention
must be paid to individuals standing alone, groups of
people, and luggage. The system consists of a set of
cameras with a DSP running low-level vision algo-
rithms, covering the complete airport. One of their
tasks is classifying objects in each frame by consider-
ing just the information gathered through the camera
and a limited local history, if any. This classification
is then fed to a higher level which controls several
cameras and fuses all the incoming data.
It is important that the features used to give this
1
Acknowledgments: This work is supported partially by
the sixth framework programme priority IST 2.5.3 Embed-
ded systems. Project 033279
initial classification are quickly computed, and cru-
cial to have a high local rate of successful classifi-
cation; despite higher levels may correct local clas-
sification errors. We used two different feature sets.
Geometric features, which are mentioned in many pa-
pers discussing surveillance systems and another set
of features based on the average density of foreground
pixels in areas of the blobs. Both sets of features
attempt to extract the essence of object silhouettes.
Unfortunately, shadows can connect separate objects
and deform shapes. We investigate the suitability, or
not, of using shadow removal algorithms for obtain-
ing higher classification success rates in real-time sys-
tems.
In section 2 we explain how we extracted figures
from videos and converted them into blobs; shadow
removal algorithms are introduced in 3, the feature
sets we used are explained in section 4. Section 5
shows the experiments we made and the obtained re-
sults. Finally, 6 present our conclusions and future
works.
2 BLOB SEGMENTATION
Some considerations must be borne in mind regarding
blob extraction:
• One blob-one object: each blob must contain a
complete object and each complete object must be
included into a blob.
662
Rosell-Ortega J., Andreu-Gar
´
cıa G., Rodas-Jordà A., Atienza-Vanacloig V. and Valiente-González J. (2008).
FEATURE SETS FOR PEOPLE AND LUGGAGE RECOGNITION IN AIRPORT SURVEILLANCE UNDER REAL-TIME CONSTRAINTS.
In Proceedings of the Third International Conference on Computer Vision Theory and Applications, pages 662-665
DOI: 10.5220/0001082506620665
Copyright
c
SciTePress

• Different objects cannot be in the same blob, if
they are sepparate in the frame.
• Different objects can be included in the same blob
if there is occlusion or overlapping between them.
Detecting blobs involves learning an adaptive
background model. Various background learning
techniques may be found in (L. Wang and Tan, 2003).
These background model will be used as a reference
in background substration. The scheme for detecting
motion also involves temporal differences between
three successive frames. Only those blobs whose
mass exceeds a threshold are considered to be ob-
jects, discarding the rest. Blobs are joined according
to proximity rules. For each blob, the smallest box
enclosing it (called bounding box, BB) is calculated.
Some samples may be seen on figure 1.
3 SHADOW REMOVAL
Several shadow removal algorithms have been de-
veloped (Rosin and Ellis, 1995), (Javed, 2002),
(Onoguchi, 1998). Removing shadows is important
in order to improve object disambiguation and classi-
fication. Shadows can be of two types:
• Self shadows: these are part of the object which
are not illuminated by direct light. They will not
affect the shape or silhouette of an object, so we
will ignore them.
• Cast shadows: these are the area in the back-
ground projected by the object in the direction
of light rays. They affect seriously the shape of
blobs by enlarging them or joining several blobs
together.
Algorithms introduced in (Rosin and Ellis, 1995)
for grayscale images and in (Xu et al., 2005) for RGB
space were used, testing the gain of the RGB space
algorithm over grayscale approach.
4 FEATURE SETS
We used two different feature sets: geometric features
and foreground pixel density, introduced in the fol-
lowing sections.
Geometric features are usually discussed when
dealing with classification aspects; we chose the most
efficient in classification success rate and computa-
tional cost to meet the real-time response constraint.
We used the following:
• Aspect ratio: given by
BB
height
BB
width
.
Figure 1: Captured images of different instances of single
person, group of people. and luggage, with their associated
blob and the blob after removing shadows in gray levels and
RGB space.
• Dispersedness: given by
Perimeter
2
Area
.
• Solidity: computed as
Area
ConvexArea
.
• Foreground ratio:
foregroundpixels
Totalamounto f pixels
Taking into account that objects of different
classes show different pattern of occupancy, the fore-
ground pixel density is computed, see figure ??. We
divide a bounding box into a grid of n×m cells; intro-
ducing this way the requirement of scale invariance.
For each cell, the amount of foreground pixels (P
i
)
and background pixels (B
i
) is calculated and the re-
sult of the division
P
i
P
i
+B
i
is stored.
5 EXPERIMENTS AND RESULTS
Off-line experiments were made with data obtained
from indoor video sequences taken on different days
with different light conditions, scene activity and
Figure 2: Sample of person, group of people, and luggage
with a 4× 4 grid.
FEATURE SETS FOR PEOPLE AND LUGGAGE RECOGNITION IN AIRPORT SURVEILLANCE UNDER
REAL-TIME CONSTRAINTS
663

camera location; including people with luggage, pro-
jected shadows and lighting changes. Feature sets are
evaluated focusing on the recognition rate and the im-
provement introduced by shadow removal algorithms.
Data consists of blobs extracted from videos of
different lengths recorded by ourselves, together with
a bitmap crop of its bounding box from the real video
in RGB space and in grey levels. We extracted 4659
blobs, which were filtered by size (minimum size 250
pixels) removing up to 49% of the total. We then man-
ually labelled the remaining blobs, corresponding to
1371 images of class single people, 367 of class group
of people and 631 images of class luggage.
The criteria we followed to label blobs was:
• Every blob representing a person with or without
luggage is labelled as single person.
• Blobs representing an object are classified accord-
ing to the object as single person, group of people,
and luggage.
• At least 2/3 of the figure must be inside the
bounding box.
• A blob representing more than two people is con-
sidered to be a group of people, provided that at
least 2/3 of two people are visible. No matter how
many objects occluded may occur nor which kind
of objects are present.
Any other blob was not considered for further pro-
cessing.
For each image, we kept the result of applying to it
the shadow removal algorithms introduced in section
3 and calculated both feature sets discussed in sec-
tion 4 to the original image and the resulting images,
yielding 6 different data sets of 2369 images.
65
70
75
80
85
90
95
100
1 3 5 7 9 11 13 15
Classification success rate
Number of neighbours
with shadows
Shadows removed. Grays
Shadows removed. RGB
Figure 3: Classification rate of images with and without
shadows using geometric features.
We trained a k-nn classifier with different ran-
domly chosen images; the training set was con-
structed using 80% of the database and the test set was
composed of the other 20%. The experiments were
repeated 100 times to ensure the statistical indepen-
dence of the selected samples. The optimal number
65
70
75
80
85
90
95
100
1 3 5 7 9 11 13 15
Classification success rate
Number of neighbours
with shadows
Shadows removed. Grays
Shadows removed. RGB
Figure 4: Classification rate of images with, and without
shadows, using the matrix of foreground pixels density.
Grid size is 4× 4.
of regions to divide each blob into was found by di-
viding the blobs into different sets of 2×2, .., 10× 10
regions and classifying objects using a k-nn classifier.
A grid of size 4×4 was chosen because it is the small-
est with a good classification rate.
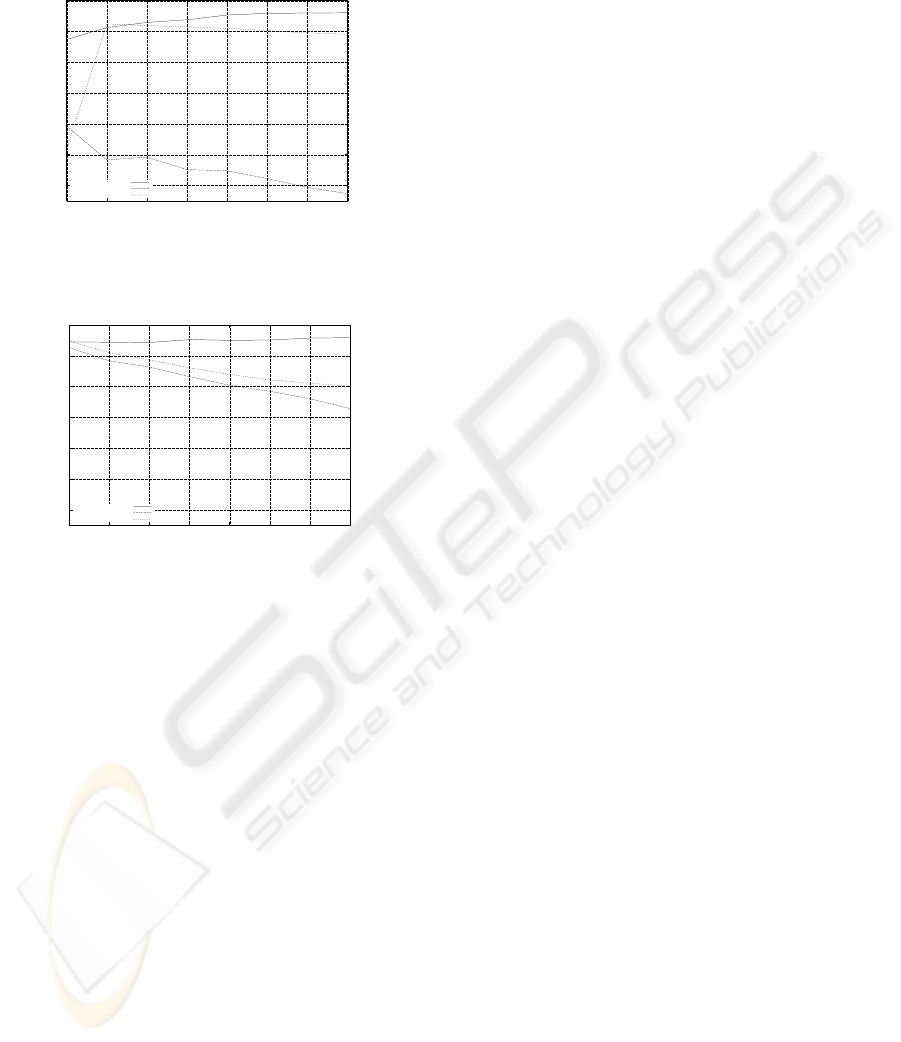
In figure 3 and 4 we show the global results of ob-
ject classification for different values of k and for each
feature set. In figure 3, we show the results using ge-
ometric features with shadows left and with shadows
removed. In figure 4, we show the same results for
also show results for foreground pixel density with
shadows and with shadows removed, using a grid size
of 4 × 4. It can be seen for geometric features that
for k = 1 the classification rate is 68%. For higher
values of k, the classification rate rises and stays be-
tween 87% and 90%. While foreground pixel density
behaves completely differently and shows a good suc-
cess rate (95%− 92%) for values of k between 1 and
5 and then decreases as k grows.
Table 1: Comparison of the confusion rates between groups
of people, person (P), or luggage (L) classes. Top rows cor-
respond to geometric features and bottom rows correspond
to foreground pixel density.
k 1 3 5 7 9 11 13
P geo. 36.25 48.39 48.39 50.73 51.69 54.51 54.51
L geo. 0.22 0.09 0.02 0.17 0.12 0.08 0.09
P den. 0.48 0.89 11.06 13.79 15.76 16.33 15.93
L den. 0.02 0.02 0.01 0.04 0.14 0.27 0.56
Figures 5 and 6 show performance of both fea-
ture sets for each class. Class person and luggage
have a good classification success rate in both cases;
but group of people class shows low values, worse
for geometric features than for foreground pixel den-
sity. Analyzing confusion between classes, we saw
that classes person and group of people are easily
confused, other interclass confusions are low. Both
feature sets are valid for classifying person and lug-
gage class with a good degree of accuracy. In table 1
rows indicate the percentage of confusion of samples
VISAPP 2008 - International Conference on Computer Vision Theory and Applications
664
of class group of people classified as either person or
luggage; top rows correspond to geometric features
and bottom rows to foreground pixel density.
40
50
60
70
80
90
100
1 3 5 7 9 11 13 15
Classification success rate
Number of neighbours
Person
Group of people
Luggage
Figure 5: Classification success rates using geometric fea-
tures, each line correspond to results for one class.
40
50
60
70
80
90
100
1 3 5 7 9 11 13 15
Classification success rate
Number of neighbours
Person
Group of people
Luggage
Figure 6: Classification success rates using foregroud pix-
els density features, each line corresponds to results for one
class.
Removing shadows increases the classification
success rate; although the gain may be low under cer-
tain constraints. For instance, for a movie in which
the complete tracking loop takes up to 0.91 seconds,
and there are an average of 1.8 objects per frame, the
grayscale approach takes up to 14.03 seconds on av-
erage per frame; and the RGB space approach around
30.10 seconds on average per frame.
6 CONCLUSIONS
We tested two different sets of features: geometric
features and foreground pixel density. The former
shows a poorer global performance due to the fact
that the group of people class is often mis-classified as
person, although luggage and person classes are clas-
sified satisfactorily. Foreground pixel density shows
a better performance with less interclass confusion,
although performance decreases when k increases,
leading to a poor performance in both groups of peo-
ple and luggage classes. Geometric features seem to
be more stable than the foreground pixel density. Re-
sults show that, independently of the features we use,
removing shadows increases the performance of the
classifier although the difference may not be worth
the effort in cases in which time performance is im-
portant.
Currently a head detection algorithm is under de-
velopment to improve classification of group of peo-
ple class. A method based on people symmetry axis
detection is expected to be useful for detecting the
number of people represented in a blob. Experiments
were carried out off-line, and after these conclusions,
we will adapt this classification scheme for on-line
operation and apply it to real-time video.
REFERENCES
Haritaoglu, I., Harwood, D., and Davis, L. S. (2000). W4:
Real-time surveillance of people and their activities.
IEEE Transactions on Pattern Analysis and Machine
Intelligence, pages 809 – 830.
Javed, O. (May, 2002). Tracking and object classifica-
tion for automated surveillance. The seventh Euro-
pean Conference on Computer Vision (ECCV 2002),
Copenhagen.
L. Wang, W. H. and Tan, T. (2003). Recent developments
in human motion analysis. Pattern Recognition, pages
585 – 601.
Onoguchi, K. (1998). Shadow elimination method for mov-
ing object detection. Proceedings of the 14th Interna-
tional Conference on Pattern Recognition, page 583.
Rosin, P. and Ellis, T. (1995). Image difference threshold
strategies and shadow detection. Proceedings of the
6th British Machine Vision Conference. BMVA Press.,
pages 347 – 356.
W. Hu, T. T., Wang, L., , and Maybank, S. (2004). A survey
on visual surveillance of object motion and behaviors.
IEEE Transacions on Systems Man, and Cybernetics-
part C: Applications and Reviews, pages 334 – 351.
Wren, C. R., Azarbayejani, A., Darrell, T., and Pentland,
A. P. (1997). Pfinder: Real-time tracking of the hu-
man body. IEEE Transactions on Pattern Analysis and
Machine Intelligence, pages 780 – 785.
Xu, L., Landabaso, J. L., and Pard`as, M. (2005). Shadow re-
moval with blob-based morphological reconstruction
for error correction. ICASSP 2005. USA, pages 729 –
732.
FEATURE SETS FOR PEOPLE AND LUGGAGE RECOGNITION IN AIRPORT SURVEILLANCE UNDER
REAL-TIME CONSTRAINTS
665
