
TOWARDS MKDA: A DATA MINING SEMANTIC WEB SERVICE
Vincenzo Cannella, Giuseppe Russo and Roberto Pirrone
Universita’ degli Studi Palermo, Dipartimento Ingegneria Informatica - DINFO
Viale delle Scienze ed. 6 p.3, 90128 Palermo, Italy
Keywords:
Data Mining, Knowledge Discovery in Databases, Semantic Web Service, Medical Knowledge Discovery
Assistant, Knowledge Discovery Process.
Abstract:
Nowadays a huge amount of raw medical data is generated. These data, analyzed with data mining techniques,
could be used to produce new knowledge. Unluckily such tasks need skilled data analysts, and not so many
researchers in medical field are also data mining experts. In this paper we present a web based system for
knowledge discovery assistance in Medicine able to advice a medical researcher in this kind of tasks. The
experiment specifications are expressed in a formal language we have defined. The system GUI helps the user
in the their composition. The system plans a Knowledge Discovery Process (KDP). The KDP is designed on
the basis of rules in a knowledge base. Finally the system executes the KDP and produces a model as result.
The system works through the co-operation of different web services specialized in different tasks. The choice
of web services is based on the semantic of their functionalities, according to a common OWL ontology. The
system is still under development.
1 INTRODUCTION
In recent years the availability of huge medical data
collections has sometimes dramatically brought to
light the (in)ability to analyze them. Medical centers
have huge databases containing therapies, diagnoses
and personal data of their patients. Moreover, the au-
tomatic devices of relevant data acquisition, such as
MRI and PET, extract more and more accurate medi-
cal images of patients. Medical images are produced
in such a number that they can only be analyzed with
the help of complex systems. All these raw data could
be usefully investigated by medical researchers to find
new knowledge. In this view a very important appli-
cation field is the Knowledge Discovery in Databases
(KDD) that, according to (Fayyad et al., 1996), is de-
fined as the “non-trivial process of identifying valid
novel, potentially useful and ultimately understand-
able patterns in data” . This task is brain-intensive.
It is usually designed by a human expert. Unluckily
the KDD techniques needs a specific skill, and usu-
ally doctors are not data mining experts. In this work
we propose Medical Knowledge Discover Assistant
(MKDA). It is a new tool that we are still develop-
ing, to help knowledge discovery process in medical
field for non expert users in data mining techniques,
as doctors usually are. The system receives the formal
specification of the medical experiment research, in-
cluding goals and the inputs characteristics. The user
should say “what” she wants, and not “how” to get it.
The system must plan and execute a suitable Knowl-
edge Discovery Process (KDP), designed according
to the user’s needs and the application domain. Fi-
nally, it returns the results. The interaction between
the user and the system must be designed carefully. A
not expert user must be free from the too technical as-
pects of the process, and she must be guided through
hits and helps.
The rest of the paper is arranged as follows. The next
paragraph describes the state of the art for Knowl-
edge Discovery Assistants. The third paragraph intro-
duces a new language to describe the specifications
of a medical experimental research. The forth one
presents the knowledge base that helps in construc-
tion of experiments. Then a new knowledgediscovery
workflow model is presented in the fifth paragraph.
The sixth one describes the functionalities of MKDA
system followed by the system architecture in the sev-
enth paragraph. Finally, conclusions and future works
are reported.
129
Cannella V., Russo G. and Pirrone R. (2008).
TOWARDS MKDA: A DATA MINING SEMANTIC WEB SERVICE.
In Proceedings of the Fourth International Conference on Web Information Systems and Technologies, pages 129-134
DOI: 10.5220/0001521801290134
Copyright
c
SciTePress

2 THE STATE OF THE ART
In recent years many researches have been carried
out in KDD, with the aim of developing a tool able
to perform an autonomous data analysis. The in-
volved field is essentially a combination of some as-
pects of many research areas such as knowledge based
systems, machine learning and statistics. In Mlt-
Consultant (Sleeman et al., 1995) the selection of a
machine learning method is made with the support of
a knowledge-based system. Mlt-Consultant chooses
the learning methods on the basis of the syntactic
properties of their inputs and outputs according to a
set of rules. Another approach is the meta-learning
approach. NOEMON (Kalousis and Hilario, 2001)
relies on a mapping between dataset characteristics
and inducer performance to propose inducers for spe-
cific dataset steps. The most appropriate classifier for
a dataset is suggested on the basis of the similarity of
the dataset with existing ones and on the performance
of the classifier for the latter.
The DM Assistant System(Charest et al., 2006)
used the case-based reasoning. It has a collection of
pre-defined cases. Every time, the system compares a
new case with this collection of cases, and establishes
the most similar one. This system has been inspired
to the CRISP-DM model (cri, 2000).
Another approach is related to the possibility to
build the entire process needed to achieve the goal.
As an example the IDEA System (Bernstein et al.,
2005) starts from characteristics of the data and of
the desired mining result. Then it uses an ontology
to search for and enumerate the data mining processes
that are valid for producing the desired result from the
given data. Each search operator corresponds to the
inclusion in the DM process of a different data min-
ing technique. In this field some commercial tools as
IBM DB Intelligent have also been built. Miner (Han
et al., 1996) integrates a relational database system,
a Sybase SQL server, with a concept hierarchy mod-
ule, and a set of knowledge discovery modules. An-
other commercial tool is Clementine (Engels, 1996)
(Wirth et al., 1997). In this system the user-guidance
module uses a task/method decomposition to guide
the user through a stepwise refinement of a high-level
data mining process. Important issues in this field are
open source. Yale (Eliassi-Rad et al., 2006) is an en-
vironment for machine learning experiments and data
mining. It supports the paradigm of rapid prototyp-
ing. Yale provides a rich variety of methods which al-
lows rapid prototyping for new applications. Yale can
be used mainly by users skilled in KDD. Yale uses
Weka (Witten and Frank, 1999), a collection of Java
implementations of machine learning algorithms. The
preparation of data is supported in Yale by numerous
feature selection and construction operators. How-
ever, Yale is applied to a single input data table. The
Mining Mart software (Euler, 2005) can be used to
combine data from several tables, or to prepare large
data sets inside a relational database instead of main
memory as in Yale. Mining Mart also provides oper-
ators that ease the integration with Yale.
3 MEDICAL EXPERIMENTAL
RESEARCH SPECIFICATION
The medical researcher has to define the experiment
formally, setting its specification. She has to list the
collection of features of her research, as data, goals,
metrics and models.
We have defined an XML-compliant experiment
specification language, a suitable formal language to
describe the inputs. Formally the defined language
ESL (Experiment Specification Language) is used to
represent: the set of data useful to problem definition,
the set of user goals, the set of metrics used to evalu-
ate the process results and the representation used for
results. Composing such a description could be too
hard for a not expert user. To solve this problem, we
have designed and implemented a very simple GUI
interface. The user can express her needs graphically,
and the GUI composes automatically the correspon-
dent description of the specification. The definition
of possible goals drives the entire process of data dis-
covery. The goal definition makes possible the fitting
of user choices with system capabilities. Some of the
most important goals in data mining are represented
in the following list.
• Association Analysis: it defines the process of
finding frequent and relevant patterns in terms of
composition rules;
• Correlation Analysis: it is used to define the de-
gree of relation in the association analysis. The
correlation analysis gives a measure of the cor-
rectness degree of the association;
• Classification: given a certain number of at-
tributes useful to identify a class, the classification
goal is used to find a model describing the situa-
tion;
• Prediction: the goal is the same of the classifica-
tion but inputs are continuous;
• Relevance Analysis: it is used to define which the
relevant patterns are to describe a certain model
useful to aggregate data
WEBIST 2008 - International Conference on Web Information Systems and Technologies
130

• Cluster Analysis: it is used to classify data not
previously classified into clusters;
• Outlier Analysis: it follows the cluster analysis
and is used to estimate which are the characteris-
tics of not included data in the clusterization pro-
cess;
• Evolution Analysis: defines the time or space
data evolution in terms of a model that represents
changes.
Due to complexity of processes many possible
metrics to evaluate the system have to be used. It’s
possible to distinguish them in terms of computation
load, usefulness of new founded patterns, novelty.
Measures are mostly related to particular data min-
ing algorithms or tasks. In fact, they are in direct re-
lation to goals that user wants to obtain. The same
considerations are also valid for the set of possible
task-dependent representations. The input data are
of different types: numerical data, categorical data,
complex symbolic descriptions, rules. A deeper dif-
ferentiation of data is in relation to data composition.
Three different input classes have been defined. The
first is the object class: data matrix, dissimilarity ma-
trix, single values, graphs are some possible exam-
ples. The second is the special input class, as, for in-
stance, numerics, dates, therapy, diagnoses, diseases,
patients, counts, IDs, binary data that are used for im-
ages or videos, texts and documents. The third class is
the variable type class like internal variables, symmet-
ric or asymmetric binary variables, discrete variables,
continue variables, scaled variables. The type of in-
put data is a first factor to discriminate the possible
choices in the design of the workflow.
4 THE KNOWLEDGE BASE
The Knowledge Base of the system supports the gen-
eration of a complete experiment starting from user
requests expressed in a formal language. The knowl-
edge base is built in a modular way and is organized
in two main levels. In the highest level there is the
definition of concepts that are used for the experi-
ments. The concepts have been grouped in relation to
the roles they have in the KDP. The knowledge base
is a composition of different aspects. Some key terms
involved in the process have to be defined. An ex-
periment is the composition of a workflow, a model, a
set of evaluations about the model fitting with initial
problem and a representation of the obtained model to
obtain a possible goal. A model is a formal and well
definition specification of the result obtained from an
experiment over some particular data. A model is ob-
tained through a sequence of steps in a workflow. The
workflow steps are essentially grouped in three aggre-
gates: data pre-processing, data mining process and
data post-processing. Also the composition rules have
been added inside the knowledge bases. Rules define
the workflow steps sequence and the choice method
to select operators for a particular step.
The design of the Knowledge Base has been in-
spired mainly to the frames. The operators are de-
fined as frame. In general, also on the basis of the
paradigm of OWL-S, each operator has four princi-
pal characteristics. It can receive an input, produce
an output, be activated under certain constraints, and
change the general conditions of the process at the
end of its execution. The operators are organized ac-
cording to a taxonomy. If an operator belong to a
certain parental line, it inherits the characteristics of
its ancestors, but they have been redefined. Opera-
tors in the Knowledge Base are classified according
to the step of he workflow in which they are involved,
too. In particular,there are: data generation operators,
I/O operators, pre-processing operators, mining oper-
ators, post-processing operators, validation operators,
and visualization operators. This classification helps
the expert system during the planning phase, reduc-
ing the search space. Inputs and outputs have been
classified and organized according a taxonomy too.
There are many different input-output operators, ac-
cording to the type of the data source or to the file for-
mat of the data file. Many different types of outputs
are possible. Some operators manages data. They can
change the content or the structure of the data input.
Other operators are involved in the generation of the
model resulted from the data mining. There are many
possible models. They are classified into: Bayesian
ones, neural nets, numerical classifier, numerical re-
gression and prevision models, rules, trees. Each of
these classes is divided into sub-classes. The expert
system can choose an operator on the basis of the
model it is able to produce. To define domain struc-
ture an OWL-Dl (owl, 2004) ontology has been built.
As previously seen, it is possible to split the ontology
in different sub-ontologies. The links between the el-
ements in the same sub-ontology are homogeneous
and defines structural properties. The links through
different sub-ontologies define the relations between
different types of elements.
5 OUR KDD WORKFLOW
MODEL
Knowledge discovery in database can be planned as a
process consisting of a set of steps. The sequence of
TOWARDS MKDA: A DATA MINING SEMANTIC WEB SERVICE
131
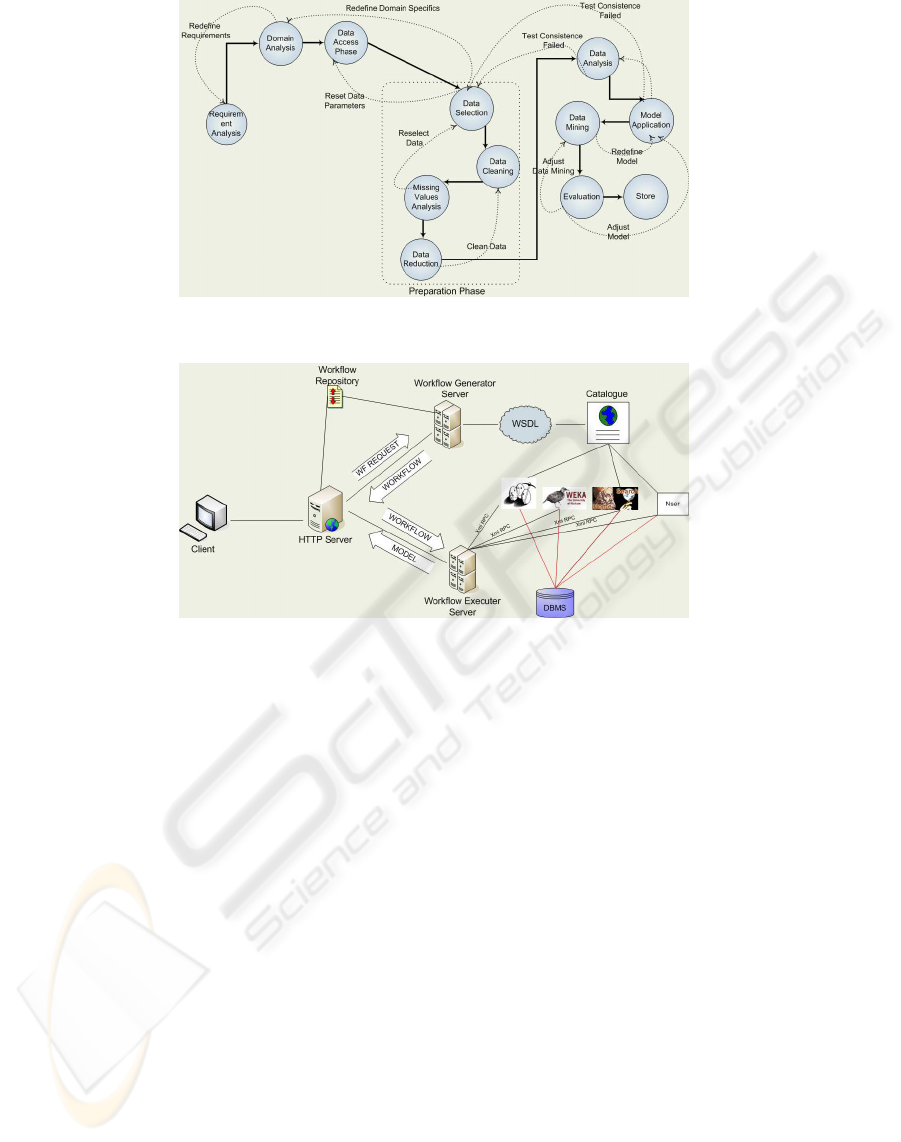
Figure 1: The workflow of a Knowledge Discovery Process.
Figure 2: The system architecture and the data flow.
these steps is described with a workflow of the pro-
cess. We designed a general workflow model as syn-
thesis of different workflows described by literature.
Because most of them cover only partially the knowl-
edge discovery process, we tried to redesign a more
general workflow (see figure 1).
The workflow is the combination of some possi-
ble phases. Phases in the workflow must not be nec-
essarily followed linearly. The process may contain
loops. The workflow can be divided into main macro-
phases, in their turns divided into sub-phases: prob-
lem analysis and specifications definition, choice of
the tasks and their execution, results analysis. These
three phases are recognizable at a very high view of
the process. During the first phase, the analyst inter-
acts with the user to understand her needs and expec-
tations to build consequently effective experiments.
The analyst must explicit objectives and knowledge
discovery goals clearly and correctly, or the entire
process design could be wrong. For this reason the
first phase is particularly tricky. To encompass prob-
lems related with this phase, as just said, we devel-
oped a particular problem definition language. We
wanted to make the problem definition simpler espe-
cially for all not very skilled users. The user must
define evaluation criteria too. On the basis of these
criteria final results of the workflow can be evaluated
to establish the satisfaction of user’s needs. The sec-
ond phase of the workflow is tightly related to the first
one. It deals with the definition of relevant knowledge
on the application domain. This knowledge is used
by the analyst to extract some domain-driven process
choices. At the end this phase is documented, and a
possible loop is sometimes necessary. In data access
phase, the user defines the specific characteristics of
the dataset that must be mined. This phase often needs
to consult different sources and bring together data
in a common format with consistent definitions for
fields and keys. Collected data could contain either
too much, less or irrelevant information. These prob-
lems are solved during the preparation phase, before
the application of the modeling and discovery tech-
niques. Data transformation mainly is performed in
two ways: horizontally (changing the dimensionality
of the data) and vertically (changing the number of
data items). The preparation phase is usually the most
time and hardware resources consuming one. In re-
turn for this computation load, this phase makes pos-
WEBIST 2008 - International Conference on Web Information Systems and Technologies
132

sible saving resources in the next phases of the work-
flow and getting better results. The preparation phase
can be split into four different sub-phases: data selec-
tion, data cleaning, missing values handling and data
reduction. None of these phases is mandatory, and the
execution of the preparation phase can contain many
loops.
During the data mining phase data are analyzed
through the chosen techniques. The application of
data mining techniques requires parameters calibra-
tion to optimal values. Therefore, another data prepa-
ration and transformation step is often needed. After
the model has been produced, it is converted in an au-
tonomous application able to implement the model.
The deployment phase deals with this task. Some-
times, the model can be emulated directly through the
development tool, which it has been developed with.
Other times, it is necessary to implement a new ap-
plication in a specific programming language. The
evaluation phase establishes how the model is suitable
for user’s needs according to the success and evalua-
tion criteria specified in the first phase. If the system
satisfies user’s requests, the entire workflow can be
recorded into a repository. In this way, it can be em-
ployed again in similar tasks.
6 SYSTEM FUNCTIONALITIES
We are developing a Web intelligent system able to
analyze data in an experiment, and to design a knowl-
edge discovery process in those data to extract new
knowledge from them. The inputs of the system are
the data, the preferences of the user and the domain
knowledge regarding the problem treated with the ex-
periment. The system has two outputs: the model
describing the new knowledge mined from the data,
and the workflow applied to get the model. The lat-
ter one can be recorded in a repository and re-used in
new similar tasks. Initially the system must be able
to analyze data evaluating the presence of problems
like noise or missing data. The system must resolve
these problems to get data that can be used for the
construction of the model. It must reach a trade-off
between the accuracy and the time cost. The charac-
teristics of the produced model should be chosen by
the user. The choices of the system are not manda-
tory. The user can change some parts of the work-
flow to get a different result. In other cases, the sys-
tem can propose different possible workflows and the
user chooses what she prefers. In these cases, the user
can choose to try many different workflows to find
the best one. The user can interact with the system in
two different ways. As just said, we have developed
a problem definition language. The user can define
the experiment through this language. This function-
ality has been developed for expert users or repeti-
tive processes. On the other hand, the system has
a simple GUI which allows the user to define easily
the problem and that compose automatically the de-
scription. The interaction process has been inspired
to programmable interaction with users like in chat-
bot systems. Unlike such systems, our interaction is
graphical. In particular, we refer to ALICE chatbot
(ali, ), a system that owns a repository composed of
question-answer patterns which are called categories.
These categories are structured with the Artificial In-
telligence Markup Language an XML-compliant lan-
guage. The dialogue is based on algorithms for auto-
matic detection of patterns in the statements. Our in-
teraction process functionalities are developed in the
same manner: the couples question-answer are cat-
egorized and through this mechanism is possible to
have a tight interaction. This interaction allows the
system to collect information about both tasks and
needs of the users.
7 SYSTEM ARCHITECTURE
MKDA system has been designed according to the
well-known web service architecture in conjunction
with the client-server three-tier one (see figure 2).
The core application is executed on an HTTP
server. The client connects to this server remotely.
Through an intuitive GUI she composes the charac-
teristics of the experiment. The interface of the client
has been developed using the AJAX technologies,
which stands for Asynchronous JavaScript and XML.
The web pages developed through this technology are
more flexible, and can easily and quickly be reconfig-
ured on the basis of the content that has to be shown
or on the basis of the user interaction. The interface
dynamically composes the description of the request
of the user in the language described previously. At
this point the request is sent to the server. After-
wards, the request is sent to the workflow generator
web service (WGWS), which analyzes this request,
and constructs the correspondent knowledge discov-
ery workflow. At this aim, it queries the knowledge
base module. At the same time, it consults the Ex-
periment Comparator Service, which, on the basis of
a case-based reasoning, lists all past experiments in
the repository matching the user’s requests. Then it
consults the data mining tasks catalogue managed by
the tasks catalogue web service (TCWS). TCWS ad-
vertises the list of tasks that the system can employ.
These tasks are the basic ones that make a workflow.
TOWARDS MKDA: A DATA MINING SEMANTIC WEB SERVICE
133

This list is very long. It includes all operators of li-
braries and systems as, for instance, Weka, Yale and
Ptolemy. These three systems have been embedded
into web services, which make possible to use re-
motely their functionalities. The tasks are advertised
in WSDL. The data retrieved in this way are inserted
into the description of each step of the final work-
flow. The workflow is generated automatically by the
expert system through a planning process. The sys-
tem must evaluates the possible actions, and plan a
sequence of actions able to produce the desired goal.
The choices in the planning phase are related to the
characteristics of the actions. The planner links ac-
tions together, matching the data flowing in the work-
flow. The system must bind these services with the
steps of the workflow. Actually, the binding is syntac-
tical, based on a shared ontology. The system matches
the functionalities of each step to the functionalitiesof
the services in the web, and produces a description of
how the workflow should be executed. During the ex-
ecution of the workflow, these data are used to know
where each task has to be executed. After the work-
flow has been generated, it is sent to the workflow ex-
ecutor web service (WEWS). It manages and coordi-
nates the steps of the workflow. Each step is executed
resorting to the Yale, Weka and Ptolemy web services.
These services can access the database, and return the
result of the execution of the workflow as model. The
model is returned by the WEWS to the application on
the HTTP server and sent to the client as reply to its
initial request. The model together with the workflow
can be recorded into the repository. They form an ex-
periment. The collection of experiments can be con-
sulted. In this way the user can eventually re-employ
a past workflow when she must work with a similar
experiment.
8 CONCLUSION AND FUTURE
WORKS
In this work we have proposed a new web based sys-
tem to help knowledge discovery in medical field for
non expert users. We have described system archi-
tecture and functionalities. The system is able in a
very simple manner to collect the characteristic of
the treated experiments. Then a knowledge discovery
worflow is generate according to the workflow model
we have designed. Finally the system is able to ex-
ecute the workflow and produces a model as result.
The user should concentrate on the specification of
the problem, while most of the implementation should
be delegated to the system. The system is under devel-
opment yet. The web infrastructure and the workflow
model has been realized and future work is focused
on its whole development and test.
REFERENCES
Alice. http://www.alicebot.org/.
(2000). Crisp-dm. http://www.crisp-dm.org/.
(2004). Owl web ontology language use cases and require-
ments.
Bernstein, A., Provost, F. J., and Hill, S. (2005). Toward
intelligent assistance for a data mining process: An
ontology-based approach for cost-sensitive classifica-
tion. IEEE Trans. Knowl. Data Eng., 17(4):503–518.
Charest, M., Delisle, S., Cervantes, O., and Shen, Y. (2006).
Invited paper: Intelligent data mining assistance via
cbr and ontologies. In DEXA ’06: Proceedings of the
17th International Conference on Database and Ex-
pert Systems Applications, pages 593–597, Washing-
ton, DC, USA. IEEE Computer Society.
Eliassi-Rad, T., Ungar, L. H., Craven, M., and Gunopu-
los, D., editors (2006). Proceedings of the Twelfth
ACM SIGKDD International Conference on Knowl-
edge Discovery and Data Mining, Philadelphia, PA,
USA, August 20-23, 2006. ACM.
Engels, R. (1996). Planning tasks for knowledge discovery
in databases; performing task-oriented user-guidance.
In KDD, pages 170–175.
Euler, T. (2005). Publishing operational models of data min-
ing case studies. In Proc. of the Workshop on Data
Mining Case Studies at the 5th IEEE International
Conference on Data Mining (ICDM), page 99.
Fayyad, U. M., Piatetsky-Shapiro, G., Smyth, P., and Uthu-
rusamy, R., editors (1996). Advances in Knowledge
Discovery and Data Mining. AAAI/MIT Press.
Han, J., Fu, Y., Wang, W., Chiang, J., Gong, W., Koperski,
K., Li, D., Lu, Y., Rajan, A., Stefanovic, N., Xia, B.,
and Za¨ıane, O. R. (1996). Dbminer: A system for
mining knowledge in large relational databases. In
KDD, pages 250–255.
Kalousis, A. and Hilario, M. (2001). Model selection via
meta-learning: A comparative study. International
Journal on Artificial Intelligence Tools, 10(4):525–
554.
Sleeman, D. H., Rissakis, M., Craw, S., Graner, N., and
Sharma, S. (1995). Consultant-2: pre- and post-
processing of machine learning applications. Int. J.
Hum.-Comput. Stud., 43(1):43–63.
Wirth, R., Shearer, C., Grimmer, U., Reinartz, T. P.,
Schl¨osser, J., Breitner, C., Engels, R., and Lindner,
G. (1997). Towards process-oriented tool support
for knowledge discovery in databases. In PKDD
’97: Proceedings of the First European Symposium on
Principles of Data Mining and Knowledge Discovery,
pages 243–253, London, UK. Springer-Verlag.
Witten, I. H. and Frank, E. (1999). Data Mining: Practi-
cal Machine Learning Tools and Techniques with Java
Implementations. Morgan Kaufmann.
WEBIST 2008 - International Conference on Web Information Systems and Technologies
134
