
XML DATA INTEGRATION IN PEER-TO-PEER DATA
MANAGEMENT SYSTEMS
Tadeusz Pankowski
Institute of Control and Information Engineering, Pozna´n University of Technology, Poland
Faculty of Mathematics and Computer Science, Adam Mickiewicz University, Pozna´n, Poland
Keywords:
XML data integration, query propagation, XML functional dependencies, P2P data management.
Abstract:
P2P systems are commonly accepted as an efficient means of sharing data among large, diverse and dynamic
set of users. Nowadays sharing data imposes new challenges in P2P systems concerning supporting advanced
querying beyond simple keyword-based retrieval. We assume that each peer stores schema of its local data,
mappings to some other peers, and schema constraints (functional dependencies). The goal of the integration is
to answer queries formulated against arbitrarily chosen peers. The answer consists of data stored in the queried
peer as well as data of its direct and indirect acquaintances. We focus on the problem of query propagation
and merging partial answers in such environment. We show how XML functional dependencies defined over
schemas, determine the selection of the merging mode of partial answers to increase information content of
the answer by recovering some missing values. We show how the discussed method has been implemented in
SixP2P system (Semantic Integration of XML data in P2P environment).
1 INTRODUCTION
Peer-to-peer (P2P) data management systems are be-
coming increasingly attractive as an efficient means
of sharing data among large, diverse and dynamic sets
of users (Madhavan and Halevy, 2003; Tatarinov and
Halevy, 2004). In such setting, the autonomous com-
puting nodes (the peers) cooperate to share resources
and services. The peers are connected to some other
peers they know or discover (Bernstein et al., 2002;
Koloniari and Pitoura, 2005; Pankowski, 2006). In
such systems, the user issues queries against an arbi-
trarily chosen peer and expects that the answer will
include relevant data stored in all P2P connected data
sources. The data sources are related by means of
schema mappings, which are used to specify how
data structured under one schema (the source schema)
can be transformed into data structured under another
schema (the target schema) (Fagin et al., 2004; Fux-
man et al., 2006). A query must be propagated to
all peers in the system along semantic paths of map-
pings and reformulated accordingly. The partial an-
swers must be merged and sent back to the user peer
(Melnik et al., 2005; Yu and Popa, 2004).
In this paper, we focus on the impact of the rela-
tionship between schema constraints and queries on
the way of query execution (query propagation and
merging answers delivered by interrogated peers). We
show how some missing values (denoted by null) may
be inferred (discovered) in the integration process. In
particular, in Proposition 2.1 we formulate a formal
condition saying when it is reasonable to use so called
full merge while merging partial answers. The dis-
cussed methods were implemented in SixP2P system.
The system is based on formal foundations underly-
ing this paper, and implements algorithms translating
high-level specifications of schemas, constraints and
queries into XQuery programs performing data trans-
formation, query evaluation and discovering missing
data (Brzykcy et al., 2007).
Section 2 introduces a running example and gives
motivation of the research. We discuss query execu-
tion strategies and show how the result of queries de-
pends on the chosen strategy. In Section 3 we dis-
cuss implementation of SixP2P system. We sketch
its architecture and illustrate the way the queries and
answers are propagated in the system. Section 4 con-
cludes the paper.
296
Pankowski T. (2008).
XML DATA INTEGRATION IN PEER-TO-PEER DATA MANAGEMENT SYSTEMS.
In Proceedings of the Fourth International Conference on Web Information Systems and Technologies, pages 296-300
DOI: 10.5220/0001529602960300
Copyright
c
SciTePress

SXEV
SXE
WLWOH
Ä;0/´
DXWKRU
QDPH
Ä-RKQ´
XQLYHUVLW\
Ä1<´
,
DXWKRU
QDPH
Ä$QQ´
XQLYHUVLW\
Ä/$´
SXEV
SXE
WLWOH
\HDU" DXWKRU
QDPH
XQLYHUVLW\"
6
3
SXEV
SXE
WLWOH
DXWKRU
QDPH
XQLYHUVLW\"
6
3
DXWKRUV
DXWKRU
QDPH
SDSHU
WLWOH
\HDU"
6
3
SXEV
,
DXWKRUV
DXWKRU
QDPH
Ä
$QQ´
SDSHU
WLWOH
Ä;0/´
\HDU
Ä´
,
Figure 1: XML schema trees S
1
, S
2
, S
3
, and their instances I
1
, I
2
and I
3
, located in peers P
1
, P
2
, and P
3
.
2 QUERY EXECUTION
STRATEGIES
In Figure 1 there are three peers P
1
, P
2
, and P
3
along
with XML schema trees, S
1
, S
2
, S
3
, and schema in-
stances I
1
, I
2
, and I
3
, respectively. Further on, we
will assume that XML schemas can be represented
by tree-pattern formulas (Arenas and Libkin, 2005;
Pankowski et al., 2007).
In P2P data integration systems a query formu-
lated against an arbitrary target schema (owned by a
target peer) must be propagated to all partners of the
target peer, these peers propagate it further to their
partners, etc. In this way the query can reach all
sources, which can contributeto the final answer. Par-
tial answers are merged step-by-step and successively
sent towards the target peer. In such scenario the fol-
lowing three issues are of special importance:
1. Query propagation – using the information pro-
vided by the query and by available schemas,
the peer has to decide who to send (propagate)
the query to, and whether a coming propagation
should be accepted in order to avoid cycles and to
increase the expected amount of information.
2. Query reformulation – a query received and ac-
cepted by P
i
from P
j
has to be reformulated in
such a way that it can be evaluated over S
i
and
its answer conforms to S
j
.
3. Merging partial answers. A peer can decide
whether the received answers should be merged
with or without the whole peer’s local instance.
This decision is made based on the functional de-
pendencies defined over the local schema.
We assume that a peer makes decision locally
based on its knowledge about its schema and schema
constraints and about the query that should be exe-
cuted and propagated. The chosen strategy and the
way of merging partial answers determine both the fi-
nal answer and the cost of the execution.
We will use XML functional dependencies
(XFDs) (Arenas, 2006) as schema constraints. Over
S
3
the following XFD can be defined:
/authors/author/paper/title→
/authors/author/paper/year
(1)
This XFD can be specified as the formula:
/authors/author/paper[title= x
title
]/year = x
year
meaning that each value of x
title
uniquely determines
the text value x
year
of year.
Let us consider some possible strategies of execu-
tion query q over S
1
q := /pubs[pub[title= x
title
∧ year = x
year
∧author[name = x
name
∧university = x
univ
]]] ∧ x
name
= ”John”,
where the first conjunct is the schema, variables
x
title
,x
year
,x
name
, and x
univ
are bound to text values of
an instance of S
1
; x
name
= ”John” is the query quali-
fier. The answer should contain information stored in
all three sources shown in Figure 1.
Thus, one of three strategies can be realized:
3
3
3
3
3
3
3
3
3
D FE
T
T
T
$QV
D
$QV
F
$QV
E
Figure 2: Three execution strategies of the query q.
Strategy (a). Query q is sent to P
2
and P
3
, where it
is reformulated to, respectively, q
21
(from P
2
to P
1
)
and q
31
(from P
3
to P
1
). The answers q
21
(I
2
) and
q
31
(I
3
) are returned to P
1
. In P
1
these partial answers
are merged with the local answer q
11
(I
1
) and a final
answer Ans
a
is obtained. This process can be written
as follows (⊔ denotes the merge operation):
Ans
a
= ⊔{Ans
a
11
,Ans
a
21
,Ans
a
31
},
Ans
a
11
= q
11
(I
1
) = {(x
title
: ⊥,x
year
: ⊥,x
name
: ⊥,
x
univ
: ⊥)},
Ans
a
21
= q
21
(I
2
) = {(x
title
: XML, x
name
: John,
x
univ
: NY)},
Ans
a
31
= q
31
(I
3
) = {(x
name
: ⊥,x
title
: ⊥,x
year
: ⊥)},
Ans
a
= {(x
title
: XML, x
year
: ⊥,x
name
: John,
x
univ
: NY)}.
XML DATA INTEGRATION IN PEER-TO-PEER DATA MANAGEMENT SYSTEMS
297

Strategy (b). It differs from strategy (a) in that P
2
after receiving the query propagates it to P
3
and waits
for the answer q
32
(I
3
). The result is equal to Ans
a
:
Ans
b
= ⊔{Ans
b
11
,Ans
b
21
,Ans
b
31
} =
= {(x
title
: XML,x
year
: ⊥,x
name
: John,
x
univ
: NY)},
Strategy (c). In contrast to the strategy (b), the
peer P
3
propagates the query to P
2
and waits for the
answer. Next, the peer P
3
decides to merge the ob-
tained answer q
23
(I
2
) with the whole its instance I
3
.
The decision is based on the existence of the func-
tional dependency (1) and Proposition 2.1.
Ans
c
= ⊔{Ans
c
11
,Ans
c
21
,Ans
c
31
}),
Ans
c
23
= q
23
(I
2
) = {(x
title
: XML,x
year
: ⊥,
x
name
: John)},
Ans
c
31
= q
31
(⊔{I
3
,Ans
c
23
}) =
= {(x
title
: XML,x
year
: 2005,x
name
: John)}
Ans
c
= {(x
title
: XML,x
year
: 2005,x
name
: John,
x
univ
: NY)}.
While computing the merge ⊔{I
3
,Ans
c
23
} a missing
value of x
year
is discovered. Thus, the answer Ans
c
provides more information than Ans
a
and Ans
b
.
The above example shows that it is important to
decide which of two merging modes should be used
in the peer while partial answers are to be merged:
• partial merge – all partial answers are merged
without taking into account the source instance
stored in the peer (e.g. the strategy (b));
• full merge – the whole source instance in the peer
is merged with all received partial answers; during
this operation XFDs are used to discover missing
values; finally the query is evaluated on the result
of the merge (e.g. the strategy (c)).
Criterion of the selection is the possibility of dis-
covering missing values during the process of merg-
ing. To make the decision one has to analyze XFD
constraints specified for the peer’s schema and the
query qualifier.
Proposition 2.1 states the condition when there is
no sense in applying full merge because no missing
value can be discovered (Pankowski, 2008).
Proposition 2.1. Let S(x) be a schema, q be a query
with qualifier ψ(y), y ⊆ x, and I
A
be an answer to q
received from a propagation. Let ψ(z) = x be an XFD
defined over S(x). If one of the following two condi-
tions holds: (a) x ∈ y, or (b) z ⊆ y, then no missing
value can be discovered by full merge, i.e.
q(merge(I,I
A
)) = merge(q(I),I
A
).
3 DATA INTEGRATION IN
SIXP2P
The discussed method of semantic data integration is
realized in the SixP2P system. The overall architec-
ture of the system is in Figure 3, and the software
structure is given in Figure 4.
!"
#!
!"
#!
!"
#!
$
%
&'
( )*+,
&)( )-#
,.
,.
,.
Figure 3: Overall architecture of SixP2P.
Each peer in SixP2P has its own local database
consisting of two parts: data repository of data avail-
able to other peers, and 6P2P repository of data nec-
essary for performing integration processes (informa-
tion about partners, schema mappings, schemas, con-
straints, partial answers, etc.). Using the query inter-
face (QI) a user formulates a query. The query execu-
tion module (QE) controls the process of query refor-
mulation, query propagation to partners, merging of
partial answers, discovering missing values, and re-
turning partial answers (Figure 5). Communication
between peers (QAP) is realized by means of Web
Services technology. Layers in Figure 4 show tasks
realized by particular modules.
5HFHLYLQJTXHU\
4XHU\UHIRUPXODWLRQ
LQWRP\VFKHPD
4XHU\SURSDJDWLRQ
&ROOHFWLQJDQVZHUV
0HUJLQJDQVZHUV DQGP\
ORFDO GDWDRYHUP\VFKHPD
/RFDOTXHU\H[HFXWLRQ
RYHUPHUJHGGDWD
$QVZHUWUDQVIRUPDWLRQ
LQWRRZQHU¶VVFKHPD
6HQGLQJDQVZHU
2ZQHUSHHU
TXHU\LQJ
4XHU\
,QWHUIDFH
8VHU
3DUWQHUSHHU
DQVZHULQJ
0\SHHU
Figure 4: Software architecture of SixP2P.
In Figure 5 there is the (simplified) structure of
6P2P repository showing the propagation of queries
and answers in the SixP2P system consisting of
three peers: P
1
, P
2
, and P
3
. Specification of the
query is translated into executable form to myQuery
WEBIST 2008 - International Conference on Web Information Systems and Technologies
298
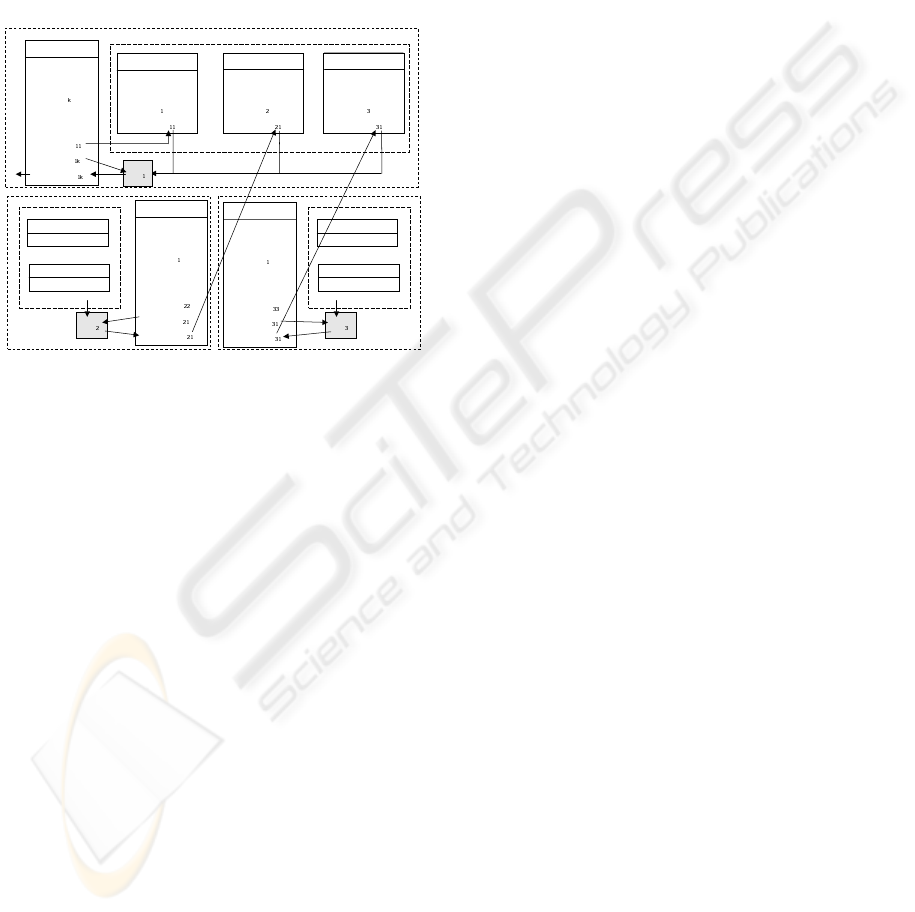
(an XQuery program to be executed over the local
database) and to tgtQuery (an XQuery program trans-
forming the obtained answer into the target schema).
The query q
1
is propagated to (all or some) partners of
P
1
– among them also to P
1
itself. Each propagation
is recorded in table Propagations, where: propagID
identifies the propagation; qryPosId identifies the po-
sition in table Queris; srcPeer is the URL of the
source partner, where the query has been propagated;
srcAnswer is the answer obtained from the srcPeer.
34XHULHV
TU\3RV,G
TU\,GT
WJW3HHU3
WJW3URSDJ,G
WJW3RV,G
P\4XHU\T
WJW4XHU\T
WJW$QVZHU,
33URSDJDWLRQV
SURSDJ,G
TU\3RV,G
VUF3HHU3
VUF$QVZHU,
33URSDJDWLRQV
SURSDJ,G
TU\3RV,G
VUF3HHU3
VUF$QVZHU,
33URSDJDWLRQV
SURSDJ,G
TU\3RV,G
VUF3HHU3
VUF$QVZHU,
$QV
34XHULHV
TU\3RV,G
TU\,GT
WJW3HHU3
WJW3URSDJ,G
WJW3RV,G
P\4XHU\T
WJW4XHU\T
WJW$QVZHU,
34XHULHV
TU\3RV,G
TU\,GT
WJW3HHU3
WJW3URSDJ,G
WJW3RV,G
P\4XHU\T
WJW4XHU\T
WJW$QVZHU,
33URSDJDWLRQV
33URSDJDWLRQV
$QV
33URSDJDWLRQV
33URSDJDWLRQV
$QV
3
3
3
Figure 5: Query and answers propagation in SixP2P.
All srcAnswers are merged (using full or par-
tial mode) resulting to the Ans
1
. Next, tgtQuery
is evaluated over Ans
1
to obtain tgtAnswer, which
is ultimately sent to tgtPeer and stored in tgtPeer’s
Propagations table in the tuple identified by the pair
(tgtPropagId,tgtPosId). The evaluation removes du-
plicates and considers key constraints.
4 CONCLUSIONS
The paper presents a novel method for schema map-
ping and query reformulation in XML data integra-
tion systems in P2P environment. We discussed some
issues concerning query propagation strategies and
merging modes, when missing data is to be discov-
ered in the P2P integration processes. We showed,
how to use functional dependencies to select the way
of query propagation and data merging, to increase
the information content of the answer. The approach
is fully implemented in SixP2P system. We present
its general architecture, and sketched the way how
queries and answers are sent across the P2P envi-
ronment. In SixP2P, schemas, schema constraints,
schema mappings, and queries are specified in a
uniform and precise way. We develop algorithms
for automatic generation of XQuery programs which
perform operations of query reformulation and data
merging.
ACKNOWLEDGEMENTS
The work was supportedin part by the Polish Ministry
of Science and Higher Education under Grant N516
015 31/1553.
REFERENCES
Arenas, M. (2006). Normalization theory for XML. SIG-
MOD Record, 35(4):57–64.
Arenas, M. and Libkin, L. (2005). XML Data Exchange:
Consistency and Query Answering. In PODS Confer-
ence, pages 13–24.
Bernstein, P. A., Giunchiglia, F., Kementsietsidis, A., My-
lopoulos, J., Serafini, L., and Zaihrayeu, I. (2002).
Data management for peer-to-peer computing : A vi-
sion. In WebDB, pages 89–94.
Brzykcy, G., Bartoszek, J., and Pankowski, T. (2007). Se-
mantic Data Integration in P2P Environment using
Schema Mappings and Agent Technology, AMSTA
2007. In Lecture Notes in Computer Science 4496,
pages 385–394. Springer.
Fagin, R., Kolaitis, P. G., Popa, L., and Tan, W. C. (2004).
Composing schema mappings: Second-order depen-
dencies to the rescue. In PODS, pages 83–94.
Fuxman, A., Kolaitis, P. G., Miller, R. J., and Tan, W. C.
(2006). Peer data exchange. ACM Trans. Database
Syst., 31(4):1454–1498.
Koloniari, G. and Pitoura, E. (2005). Peer-to-peer manage-
ment of XML data: issues and research challenges.
SIGMOD Record, 34(2):6–17.
Madhavan, J. and Halevy, A. Y. (2003). Composing map-
pings among data sources. In VLDB, pages 572–583.
Melnik, S., Bernstein, P. A., Halevy, A. Y., and Rahm, E.
(2005). Supporting executable mappings in model
management. In SIGMOD Conference, pages 167–
178.
Pankowski, T. (2006). Management of executable schema
mappings for XML data exchange. In Database Tech-
nologies for Handling XML Information on the Web,
EDBT 2006 Workshops, Lecture Notes in Computer
Science 4254, pages 264–277.
Pankowski, T. (2008). Pattern based XML data integration
in P2P environment. submitted.
Pankowski, T., Cybulka, J., and Meissner, A. (2007). Rea-
soning About XML Schema Mappings in the Presence
of Key Constraints and Value Dependencies. In Web
Reasoning and Rule Systems, Lecture Notes in Com-
puter Science 4524, pages 374–376.
Tatarinov, I. and Halevy, A. Y. (2004). Efficient query refor-
mulation in peer-data management systems. In SIG-
MOD Conference, pages 539–550.
XML DATA INTEGRATION IN PEER-TO-PEER DATA MANAGEMENT SYSTEMS
299

Yu, C. and Popa, L. (2004). Constraint-Based XML Query
Rewriting For Data Integration. In SIGMOD Confer-
ence, pages 371–382.
WEBIST 2008 - International Conference on Web Information Systems and Technologies
300
