
TTLS: A GROUPED DISPLAY OF SEARCH RESULTS BASED
ON ORGANIZATIONAL TAXONOMY USING THE LCC&K
INTERFACE
Vicki Mordechai, Ariel J. Frank
Department of Computer Science, Bar-Ilan University, Ramat-Gan, Israel
Offer Drori
SHAAM – Information Systems, Poaly Zedek ST. #4, Jerusalem, Israel
Keywords: Exploratory Search, Faceted Search, Information Retrieval, LCC&K, Organizational Taxonomy, TTLS.
Abstract: One of the major problems in the process of Information Retrieval (IR) arises at the stage where the user
reviews the results list. This paper presents the latest research in a series of research works that aims at
finding the most vital information components, within a list of search results, so as to assist the user in high-
quality decision making as to which of the resulting documents are included within the sought after results
of the search task We propose here a new model for displaying the results named TTLS (Taxonomy Tree &
LCC&K Snippet). The experimentation setup included execution of different search tasks by a group of 60
participants. The tasks were performed via the BASE and TTLS interfaces. From the resulting times
comparison it is clear that the execution times of tasks done via the TTLS interface is shorter that those done
via the BASE interface. It can be seen that in the BASE interface it was needed to open more documents in
order to locate the relevant information than in the TTLS interface. It turns out that the majority of users
(77%) prefer to use the TTLS interface.
1 INTRODUCTION
One of the major problems in the process of
Information Retrieval (IR) arises at the stage where
the user reviews the results list. Most Search
Engines (SE) nowadays present the results as a
continuous list, ranked by the closeness of the results
to the terms of the search query. The deficient
ranking of the SEs, in combination with the
continuous prolonged list, makes it difficult for the
user to locate the relevant information sought after.
Besides the large number of answers probably
returned as result of the search query, the document
entries in the list do not appear in any order of
topics, and therefore the process of filtering out the
results becomes unwieldy. This process is even
harder when pursuing exploratory research tasks,
where there is more than a single relevant document,
and which necessitates a wide understanding of the
listed results.
This paper presents the latest research in a series
of research works that aims at finding the most vital
information components, within a list of search
results, so as to assist the user in high-quality
decision making as to which of the resulting
documents are included within the sought after
results of the search task.
The paper is organized as follows. Section 2
reviews the relevant previously conducted research
works. Following, the new TTLS (Taxonomy Tree
and LCC&K Snippet) model for displaying the
results is introduced in section 3. Section 4 presents
the TTLS prototype and the conducted
experimentation results. Summary and conclusions
are presented in section 5.
2 PREVIOUS RESEARCH
The research literature includes several works
intended to investigate the influence of various
47
Mordechai V., Frank A. and Drori O. (2008).
TTLS: A GROUPED DISPLAY OF SEARCH RESULTS BASED ON ORGANIZATIONAL TAXONOMY USING THE LCC&K INTERFACE.
In Proceedings of the Tenth International Conference on Enterprise Information Systems - HCI, pages 47-53
DOI: 10.5220/0001682400470053
Copyright
c
SciTePress

information components on the display of query
results. Since these vital information components
have already been found and analyzed in the
previous research works (Drori & Tamir, 2005;
Drori, 2000), and have formed the basis of the
LCC&K (Line in Context, Categories & Keywords)
research interface, we concentrate here on the
innovative addition manifested in the combination of
a categories tree with the LCC&K interface.
2.1 Information Components on each
Document in Results List
Drori, of the Hebrew University in Jerusalem, Israel,
has conducted a series of research works (Drori &
Alon, 2003; Drori & Tamir, 2005; Drori, 2000)
aimed at finding the information components most
preferred by the user and their influence when
displayed as part of the search results list. The
findings have shown that use of documents titles,
lines of text in search context, and keywords, are
preferable to displaying the same information
without these components. A similar finding has
been observed regarding the document categories,
and the ensuing model has been realized by the
LCC&K interface.
The LCC&K model depends only on the
rankings of the list entries and hence can be
improved. This is due to the fact that to gain
information on the degree of similarity or difference
between the listed documents, it is necessary to scan
all the documents. The documents associated with
the same category can be dispersed along the entire
results list. Therefore there is no good overall picture
of the relevant categories structure and the dispersal
of the documents within.
In research by Ivory et al. (Ivory et al., 2004) it
has been noted that users prefer to see additional
information components regarding the documents
over being able to control the way that the list is
sorted. They argue that users feel that the process of
finding the answer is more effective when they do
not have to access documents that do not answer
their search goals. Therefore, the display of
additional fields for each document can assist the
user in deciding if to access the document at all or
not.
2.2 Category-based Interface
In research by Dumais (Dumais & Chen, 2000) it
has been shown that interfaces where categories are
displayed by the interface are more effective than
interfaces that just display the results list. An
interface that is built up from categories has been
found to be more effective than a comparable
interface that includes, as part of the document title,
the category that is associated with the document.
The users preferred category-based interfaces that
have turned out to be faster by 50% in finding the
answer.
Category-based interfaces include:
• Grouper (Zamir & Etzioni, 1999) – An interface
developed for the meta-search engine
HuskySearch, which displays search results in
clusters. Each cluster is characterized by
phrases that are common to the documents
included in it and by several (up to 3) example
titles. The motivation was to develop a fast
clustering method that is independent of the
retrieval engine, so it can be made part of a
meta-search engine or an end-station browser.
Usability studies have shown though that users
do not like clusters that are unordered and
inconsistent, preferring a known and structured
interface in which the categories are displayed
with a uniform level of granularity (Pratt et al.,
1999; Rodden et al., 2001).
• Vivisimo (vivisimo) – A meta-search interface
that provides clustered results based on dynamic
categorization (to the Clusty search engine for
example). Such commercial platforms do not
expose their clustering algorithms and no
usability results have been published for them.
Nonetheless, it seems that the Vivisimo
categorization method uses common terms,
those that appear together in retrievals and in
common phrases. The construction of the tree
hierarchy is based, seemingly, on a recursive
activation of the same method on the
subcategories.
• FINDEX (Kaki, 2005) – An interface that
generates dynamic categories based on the
words and phrases common in the document's
snippet. The search component makes use of the
Google Web API services. The display is given
as a single level tree. Since the algorithm is
based on statistical analysis, and there is no
reference to the meanings of words, there is no
"promise" that the categories will be
meaningful. In fact, there are situations where
the category names lack context or are
incomprehensible to the users.
ICEIS 2008 - International Conference on Enterprise Information Systems
48

Figure 1: The TTLS interface.
• TLCC (Titles, Lines in Context & Categories) –
As part of the research work that led to the
development of the LCC&K interface (Drori
&Alon, 2003), the advantage of adding
categories to the search results list was
investigated. The research findings showed
significant benefit to the users of the category-
based interfaces in varied aspects – it was faster,
easier to use, provided higher confidence in the
process of finding the answer, and even less
misleading compared to the interface having no
categories.
• HFC (Hierarchical Faceted Categories) – For a
category, whether automatically generated or
pre-defined, it is important to concentrate on the
use made of it. In recent years, content-based
categories have become abundant, and form part
of the metadata that can be associated with a
document. The Web contains repositories, such
as newspapers or medical ones, which in
addition to documents include metadata that
contain categories. The document added tagging
practically enables the logical display of the
documents. Taxonomy includes information
organized in a way that reflects the major
components of the domain dealt with. The list
of categories is usually manually generated, and
the process of associating the documents with
categories can be done manually or
automatically. Recently, the HFC method
(Hearst, 2006) has been developed and
investigated in both the academic and industrial
worlds. The main principle of this approach is
the use of a hierarchical structure of categories
that are associated with facets. Each facet stands
for some super category or dimension, for the
sake of examining a collection of documents.
Each facet is associated with its relevant
categories. The HFC structure enables
navigation in several ways, as part of a process
of "diving" into the results list, where the
metadata also assists the user.
3 THE TTLS MODEL
We propose here a new model for displaying the
results named TTLS (Taxonomy Tree & LCC&K
Snippet) (Mordechai, Drori & Frank, 2007). The
TTLS model assists the user in locating, in a short
time, the information sought after by focusing on the
relevant documents per search task. The challenge is
to find the best way to display the results including
categories so as to assist the user in locating the
relevant documents out of many results.
The main idea is based on exposing the metadata
available in the repository as part of the interface,
and making use of it to organize and order the
results list according to the HFC principles. Such
metadata can be used for a "logical view" on the
results list, enabling exploratory research tasks that
utilize categories to decide on how to advance: scroll
TTLS: A GROUPED DISPLAY OF SEARCH RESULTS BASED ON ORGANIZATIONAL TAXONOMY USING THE
LCC&K INTERFACE
49

in the results list, refine the retrieval, etc. In addition,
an enhanced document snippet could assist the user
in deciding if some document is relevant without
needing to access it for a deeper check.
The TTLS model proposes to enhance the
display of the search results by a combination of:
1. Categories-based grouping of documents –
categories are based on manual tagging that was
done based on terms of an organizational
taxonomy. The categories are organized by
facets, where each facet is a main branch of the
taxonomy tree. The tree branches are ordered by
an algorithm described below.
2. Line in Context – relevant lines of text in the
search context are displayed as well as the
categories and keywords of the document
snippet, based on the previously defined
LCC&K interface.
A prototype implementing the TTLS model is
shown in Fig. 1.
The advantages of the proposed model:
• The user gets information on the dispersal of
documents between the various categories and
facets.
• The display of the structure directs toward
focusing on a specific category without
requiring the explicit scanning of the
documents' titles.
• The document snippets help in comprehending
the document contents so as to decide if the
document is relevant.
3.1 Ranking of Categories
To decide the order of the categories in the
taxonomy tree we use the common tfidf (term
frequency – inverse document frequency) method.
This method is based on the Vector model for each
document and is a popular ranking method since it's
considered a simple and fast method (Baeza-Yates &
Ribeiro-Neto, 1999).
It is proposed here to do an analogy of terms in
the original equation (words in documents) to our
terms (topics in retrieval), as follows:
Frequency of word in document ~
Frequency of topic in retrieval
Frequency of word in repository ~
Frequency of topic in repository
Hence:
Importance of category C
i
in retrieval q:
)(max
)(5.0
5.0
,
qf
qf
tf
Cjj
Ci
qCi
∗
+=
(1)
– Number of documents associated
with category C
i
in retrieval q
Importance of category C
i
in repository D:
)(
log
Df
D
idf
Ci
Ci
=
(2)
D – Number of documents in the repository
– Number of documents associated
with category Ci in repository D
And in summation for each category we will get
its weight by multiplication of the two parameters:
=
qCi
W
,
Ci
idf *
qCi
tf
,
(3)
4 THE TTLS PROTOTYPE AND
EXPERIMENTATION
The goal of the prototype is to show that the
proposed TTLS model does solve the
aforementioned problem. To investigate and
evaluate the new method, an experiment was setup
to compare the TTLS model/interface to a base
model/interface that currently exists in an
information retrieval system. The base
model/interface, named here BASE, displays only a
ranked results list. The purpose of the experiment is
to check if and how the suggested solution is
different from the extant solution in aspects of
response times, number of documents to be scanned,
and several subjective measures.
The repository referred to has manual pre-tagged
documents. As part of the experiment, response
times and correctness of the answers were measured
(as objective data), as well as, for example, ease of
use and effectiveness for users (as subjective data).
As the experiment showed, the TTLS model does
serve the users better than the previous one.
)(qf
Ci
)(Df
Ci
ICEIS 2008 - International Conference on Enterprise Information Systems
50

4.1 Experimentation Setup
The experimentation setup included execution of
different search tasks by a group of 60 participants.
The tasks were performed via the BASE and TTLS
interfaces. For the sake of the experimentation, a
repository of around 400 documents that are relevant
to the search tasks was constructed. The original
repository includes millions of documents that were
manually tagged, and out of them, the
experimentation repository was filled with the
documents that can satisfy the search tasks.
The experiment compared two ways of
displaying the results based on a pre-defined set of
queries and the pre-prepared collection of relevant
answers. The categories in the TTLS interface were
presented based on the structure of the
organizational taxonomy.
The search tasks were pre-defined based on the
approaches of (Drori, 2000) and (Dumais et al.,
2001) in a similarly conducted experimentation. The
reasoning of this approach is to neutralize the
variance that exists between search capabilities of
users of differing levels, so as to enable the
measuring in a "clean" way, without noises, of the
stage of users scanning the results, which is expected
to improve. This limitation will be removed, of
course, in a full implementation of the model. The
types of search tasks were taken from the daily
contents world of the users so as to reflect real work
and create motivation for utilization of professional
knowledge by the user in executing the task.
The efficiency of search and the user satisfaction
were checked via use of two dimensions: objective
data, i.e., response time and correctness of answer,
and subjective data, i.e., ease of use, effectiveness
for users, level of confidence, satisfaction rate, and
the relevancy of the information components. After
completion of tasks in each of the interfaces, users
filled in a questionnaire. A computerized process
was used for the questionnaire input that was stored
into a database. The experimentation setup also
logged information in a way that enabled exact
analysis of response times and documentation of all
operations done by the experiment participants.
4.2 Experimentation Process
As part of the experiment, a repository including
relevant documents and screens was constructed.
The experiment was run one-on-one between the
experiment conductor and a single participant at a
time. There was an option to perform a dummy task
before the real experiment. The time given to the
participants was unlimited. The correctness of the
result(s) was verified by the experiment conductor
while it was run.
4.3 Experimentation Tasks
The experimentation included four search tasks out
of the contents world of the users. Two of the tasks
were more focused – finding a document containing
the needed information, and two tasks were research
oriented – retrieval of information contained in
several documents.
It should be noted that this experiment was run at a
government installation so the explicit scenarios
used and the actual contents can not be revealed.
Nonetheless, we will demonstrate the style and
nature of queries using similar search tasks from the
culture and leisure domains:
• Example of a focused query –
in what year did Izhar Cohen win the
Eurovision contest?
• Example of a research oriented query –
find exemplary documents that mention the
relation between the actor Moni Moshonov and
the Habimah Theater, and in which of its plays
was he an actor?
The position of the relevant documents in each
one of the four tasks is detailed in Table 1. The order
of retrievals was balanced in a random manner so
that each task was done by different users in
different ways.
Table 1: Position of the relevant document(s) in the
original list of documents.
Task
Position of relevant
document(s) in original list
Focused 1 13 out of 33
Focused 2 6 out of 95
Research 1 99, 100, 103 out of 109
Research 2
63, 73, 85, 90, 91, 92
out of 119
4.4 Experimentation Outcomes
We use the following parameters for the
experiments:
• MEAN – average received.
TTLS: A GROUPED DISPLAY OF SEARCH RESULTS BASED ON ORGANIZATIONAL TAXONOMY USING THE
LCC&K INTERFACE
51
• SD – standard deviation of the MEAN of all
observations. The smaller the SD so is the
distribution of the data, and the MEAN is more
meaningful.
• P – probability that here is the percentage of
likelihood of chance that the researcher is
willing to risk and accept the results.
In referencing Table 2, it can be seen that for
each of the parameters, besides "Amount of
information shown", the TTLS model/interface has a
clear advantage.
4.4.1 Comparison of Execution Times
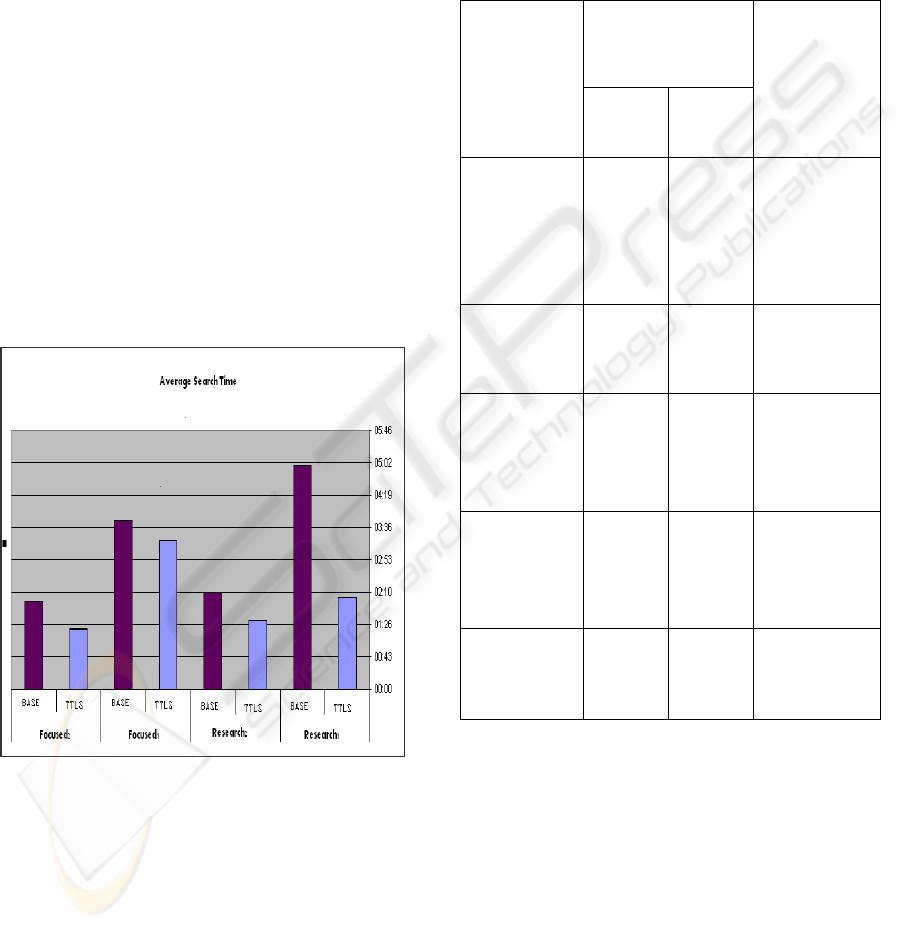
From the resulting times comparison (see Fig. 2) it is
clear that the execution times of tasks done via the
TTLS interface is shorter that those done via the
BASE interface. For the exploratory research tasks,
the gap in the execution times is even larger. In the
focused tasks the gap was between 13% to 44%
while in the research tasks the gap turned out to be
between 39% to 240%!
Figure 2: Comparison of execution times of task.
4.4.2 Number of Documents Accessed
The enhanced document snippet is designed to assist
the user in deciding whether a document is relevant
without the need of opening it. Each access of the
user to a document was logged and a comparison
between the two approaches was done. It can be
seen that in the BASE interface it was needed to
open more documents in order to locate the relevant
information than in the TTLS interface. In the BASE
interface, 6.7 documents on average were opened
while in the TTLS interface the comparable number
was only 2.2. In general, from the analysis of the
questionnaires, it turns out that the majority of users
(77%) preferred to use the TTLS interface "most
times" and "always".
Table 2: Results of t-test for checking variance between
the two interfaces.
Significance
T-test
P<0.05
Interface
MEAN
(SD)
Tested
Variable
TTLS
BASE
yes
4.41
)0.76(
2.71
)1.05(
Comfort
feeling
during
retrieval
process
no
3.45
)0.62(
3.40
)1.06(
Amount of
information
shown
yes
4.33
)0.54(
2.50
)0.89(
Relevancy
of
information
associated
with title
yes
2.06
)0.60(
2.63
)0.80(
Misleading
information
associated
with title
yes
4.46
)0.53(
2.78
)0.86(
Confidence
feeling
during use
4.4.3 Explanation of Outcomes
When the user scans the beginning of the list and
does not find what is sought after, the ranked
taxonomy tree is approached for assistance. When
the user arrives at the requested category or one that
looks like it is relevant, the document snippet
enables a relatively fast decision making on the
relevancy of the document, based both on the
associated categories and on the text lines in search
context. Consequently, the number of documents
that the user opens until what is sought after is found
ICEIS 2008 - International Conference on Enterprise Information Systems
52

is smaller and the process of information retrieval is
considerably shortened.
5 SUMMARY AND
CONCLUSIONS
To overcome the hardship of effectively handling a
large number of results, we have proposed the TTLS
model that combines several techniques for display
of the results including a ranked taxonomy tree and
an enhanced document snippet. The goal of the
prototype built was to exhibit that the proposed
model does solve the above problem. The prototype
was used to investigate both execution times and
correctness of answers, as well as effectiveness and
ease of use by users. It has been found in the
experimentation that the TTLS model can indeed
serve the users better than the previous models.
In order to increase the effectiveness of the
model, and respond to additional needs of the users,
it is highly recommended to invest in further
improvements, enhancements and investigations of
the model and prototype. Further extensive
experimentation is needed with more participants so
as to accumulate enough results that are amenable to
reaching wider conclusions by use of statistical
tools. Another research direction is the automatic
generation of categories that as of now are manually
associated with the documents. Moreover, the
compatibility between the manual catalog and the
automatic one in utilization of extant algorithms for
document cataloging in given contents worlds can be
investigated.
To summarize, the proposed method of ranking
the branches of the taxonomy tree is innovative. This
is in addition to other parts of the user interface that
have been proposed before, each on its own, such as
the display of taxonomy tree, display of facets, or
display of snippets based on the LCC&K model. The
integrated display of these components in the TTLS
model, and the evaluation process with real users,
constitute the contribution, presented in this paper,
to the information retrieval field.
REFERENCES
Baeza-Yates, R. & Ribeiro-Neto, B., 1999, “Modern
Information Retrieval”, Addison-Wesley, New York.
Drori, O., 2000, “Refinement of Search in Information
Systems and Improving Presentation of Results for
End Users, As Efficient Tools for Decision Making
Process”, Ph.D. Thesis, The Hebrew University,
Jerusalem, Israel.
Drori, O. & Alon, N., 2003, “Using Documents
Classification for Displaying Search Results List”,
Journal of Information Science, 29(2), p. 97-106.
Drori, O. & Tamir, E., 2005, “Display of Search Results in
Hebrew: A Comparison Study between Google and
LCC&K Interface”, Journal of Information Science,
31(3), p. 164-177.
Dumais, S. & Chen, H., 2000, “Hierarchical Classification
of Web Content”, SIGIR 2000, Athens, Greece, ACM
Press, New York, p. 256-263.
Dumais, S. T., Cutrell, E. & Chen, H., 2001, “Optimizing
Search by Showing Results in Context”, CHI 2001,
Seattle, WA, USA, p. 277-284.
Hearst, M. A., 2006, “Clustering versus Faceted
Categories for Information Exploration”,
Communications of the ACM, Vol. 49, No. 4, p. 59-
61.
Ivory, M.Y., Yu, S. & Gronemyer, K., 2004, “Search
Result Exploration: A Preliminary Study of Blind and
Sighted Users’ Decision Making and Performance”,
CHI 2004, ACM Press, Vienna, Austria, p. 1453-1456.
Kaki, M., 2005, “Findex: Search Result Categories Help
Users when Document Ranking Fails”, CHI 2005,
Portland, Oregon, USA: ACM Press, p. 131-140.
Mordechai, V., Drori, O., & Frank, A. J., 2007, “Grouping
Search Results by Organizational Taxonomy Using
LCC&K Interface”, Technical Report No. 2007-5,
Leibniz Center for Research in Computer Science,
School of Computer Science and Engineering, Hebrew
University of Jerusalem, Israel.
Pratt, W., Hearst, M. A. & Fagan, L., 1999, “A
Knowledge-based Approach to Organizing Retrieved
Documents”, Proceedings of 16th Annual Conference
on Artificial Intelligence, Orlando, FL, USA.
Rodden, K., Basalaj, W., Sinclair, D. & Wood, K.R.,
2001, “Does Organization by Similarity Assist Iimage
Browsing?”, Proceedings of ACM SIGCHI, p. 190-
197.
vivisimo, www.vivisimo.com, Clustering Meta-search
Engine, Referenced at July 2005.
Zamir, O. & Etzioni, O., 1999, “Grouper: A Dynamic
Clustering Interface to Web Search Results”, WWW8
Proceedings, Toronto, Canada, p. 1361-1374.
TTLS: A GROUPED DISPLAY OF SEARCH RESULTS BASED ON ORGANIZATIONAL TAXONOMY USING THE
LCC&K INTERFACE
53
