
A MODEL TO RATE TRUST IN COMMUNITIES OF PRACTICE
Javier Portillo-Rodriguez, Juan Pablo Soto
Alarcos Research Group, University of Castilla-La Mancha, Paseo de la Universidad, 4 , Ciudad Real, Spain
Aurora Vizcaino, Mario Piattini
Alarcos Research Group, University of Castilla-La Mancha, Paseo de la Universidad, 4 , Ciudad Real, Spain
Keywords: Communities of Practice, Knowledge Management, Trust, Reputation.
Abstract: Communities of Practice are an important centre of knowledge exchange in which feelings such as
membership or trust play a significant role since both is the basis for a suitable sharing of knowledge.
However, current Communities of Practice are often “virtual” as their members may be geographically
distributed. This makes it more difficult for a feeling of trust to take place. In this paper we describe a trust
model designed to help software agents, which represent communities of practice members, to rate how
trustworthy a knowledge source is. It is important to clarify that we also consider members as knowledge
sources since, in fact, they are the most important knowledge providers.
1 INTRODUCTION
In recent years Knowledge Management (KM) has
become an important success factor for companies.
The purpose of knowledge management is to help
companies to create, share and use knowledge more
effectively (Davenport, 1997). Information
technologies play a key role in achieving these goals
but are only a small component in an overall system
that must integrate the supporting technology with
people-based business processes. Nowadays,
organizations must operate in a climate of rapid
market change and high information volume, and
this increases the necessity to create knowledge
management systems which support the knowledge
process. KM is not a technological solution but is
rather, primarily, a people oriented process which
takes into account such factors as leadership, culture,
expertise and learning, with technology playing a
supporting role. Using this idea as a base, we have
studied how people obtain and increase their
knowledge in their daily work. This study led us to
the conclusion that employees frequently exchange
knowledge with people who work on similar topics,
and consequently communities are either formally or
informally created. These communities can be called
“communities of practice”, by which we mean
groups of people with a common interest where each
member contributes knowledge about a common
domain (Wenger, 1998).
Communities of practice (CoPs) enable their
members to benefit from each other’s knowledge.
This knowledge resides not only in people’s minds
but also in the interaction between people and
documents. CoPs share values, beliefs, languages,
and ways of doing things. Many companies report
that such communities help reduce problems caused
by a lack of communication, and save time by
“working smarter” (Wenger, 2002). An interesting
fact is that members of a community are frequently
more likely to use knowledge built by their
community team members than those created by
members outside their group (Desouza, 2006). This
factor occurs because people trust more in the
information offered by a member of their
community than in that supplied by a person who
does not belongs to that community. Of course, the
fact of belonging to the same community of practice
already implies that these people have similar
interests and perhaps the same level of knowledge
about a topic. Consequently, the level of trust within
a community is often higher than that which exists
outside the community. As a result of this, as is
claimed in (Desouza, 2006), knowledge reuse tends
to be restricted within groups. Therefore, people, in
real life in general and in companies in particular,
193
Portillo-Rodriguez J., Pablo Soto J., Vizcaino A. and Piattini M. (2008).
A MODEL TO RATE TRUST IN COMMUNITIES OF PRACTICE.
In Proceedings of the Tenth International Conference on Enterprise Information Systems - AIDSS, pages 193-198
DOI: 10.5220/0001685701930198
Copyright
c
SciTePress

prefer to exchange knowledge with “trustworthy
people” by which we mean people they trust. For
these reasons we consider the implementation of a
mechanism in charge of measuring and controlling
the confidence level in a community in which the
members share information to be of great
importance.
Bearing in mind that people exchange
information with “trustworthy knowledge sources”
we have designed a trust model to help CoPs
members to decide whether a knowledge source (for
instance a person) is trustworthy or not. In the
following section we describe various definitions of
two related concepts: trust and reputation. In Section
3 we then explain a trust model which can be used in
CoPs. Section 4 describes how the trust model can
be used and how it works. In Section 5 we compare
our proposal with other related works and finally, in
Section 6, we present some conclusions and future
work.
2 TRUST AND REPUTATION
Trust is a complex notion whose study is usually
narrowly scoped. This has given rise to an evident
lack of coherence among researchers in the
definition of trust. For instance in (Barber, 2004)
the authors define trust as confidence in the ability
and intention of an information source to deliver
correct information. In (Wang, 2003), Wang and
Vassileva define trust as a peer’s belief in another
peer’s capabilities, honesty and reliability based on
his/her own direct experiences. In (Mui, 2001) trust
is defined as a subjective expectation that one agent
has about another’s future behavior based on the
history of their encounters.
Social scientists have collectively identified
three types of trust, which are:
- Interpersonal trust which is the trust one
agent directly has in another agent
(McKnight, 1996).
- System trust or impersonal trust refers to
trust that is not based on any property or
state of trustee but rather on the perceived
properties or reliance on the system or
institution within which that trust exists.
For instance, inherited experiences of an
organization.
- Dispositional trust, or Basic trust, describes
the general trusting attitude of the truster.
This is “a sense of basic trust, which is a
pervasive attitude toward oneself and the
world” (McKnight, 1996).
Experiences and knowledge form the basis for
trust in future familiar situations (Luhmann, 1979).
For this reason, the frequency and intensity of
interactions between people provide an increased
level of habituation which reinforces trust between
the parties.
Another important concept related to trust is
reputation. Several definitions of reputation can be
found in literature, such as that of Mui et al in (Mui,
2001) who define reputation as a perception that one
agent has of another’s intentions and norms. Barber
and Kim define this concept as the amount of trust
that an agent has in an information source, created
through interactions with information sources
(Barber, 2004) and Wang and Vassileva in (Wang,
2003) define reputation as a peer’s belief in another
peer’s capabilities, honesty and realibility based on
recommendations received from other peers.
In our work we intend to follow the definition
given by Wang and Vassileva which considers that
the difference between both concepts depends on
who has the previous experience, so if a person has
direct experiences of, for instance, a knowledge
source we can say that this person has a trust value
in this knowledge. However if another person has
had the previous experience and recommends a
knowledge source to us, then we can say that this
source has a reputation value.
3 TRUST MODEL IN CoPs
Our aim is to provide a trust model based on real
world social properties of trust in Communities of
Practice (CoPs) by which we mean groups of people
with a common interest where each member
contributes knowledge about a common domain
(Wenger, 1998). An interesting fact is that members
of a community are frequently more likely to use
knowledge built by their community team members
than those created by members outside their group
(Desouza, 2006). This factor occurs because people
trust more in the information offered by a member of
their community than in that supplied by a person
who does not belong to that community. Of course,
the fact of belonging to the same community of
practice already implies that these people have
similar interests and perhaps the same level of
knowledge about a topic. Consequently, the level of
trust within a community is often higher than that
which exists outside the community. As a result of
this, as is claimed in (Desouza, 2006), knowledge
reuse tends to be restricted within groups. Therefore,
people, in real life in general and in companies in
ICEIS 2008 - International Conference on Enterprise Information Systems
194

particular, prefer to exchange knowledge with
“trustworthy people” by which we mean people they
trust. For these reasons we consider the
implementation of a mechanism in charge of
measuring and controlling the confidence level in a
community in which the members share information
to be of great importance.
Most previous trust models calculate trust by
using the users’ previous experience with other users
but when there is no previous experience, for
instance, when a new user arrives, these models
cannot calculate a reliable trust value. We propose
calculating trust by using four factors that can be
stressed depending on the circumstances. These
factors are:
• Position: employees often consider information
that comes from a boss as being more reliable
than that which comes from another employee
in the same (or a lower) position as him/her
(Wasserman, 1994). However, this is not a
universal truth and depends on the situation. For
instance in a collaborative learning setting
collaboration is more likely to occur between
people of a similar status than between a boss
and his/her employee or between a teacher and
pupils (Dillenbourg, 1999). Such different
positions inevitably influence the way in which
knowledge is acquired, diffused and eventually
transformed within the local area. Because of
this, as will later be explained, this factor will
be calculated in our research by taking into
account a weight that can strengthen this factor
to a greater or to a lesser degree.
• Expertise: This term can be briefly defined as
the skill or knowledge that a person who knows
a great deal about a specific thing has. This is an
important factor since people often trust experts
more than novice employees. In addition,
“individual” level knowledge is embedded in
the skills and competencies of the researchers,
experts, and professionals working in the
organization (Nonaka, 1995). The level of
expertise that a person has in a company or in a
CoP could be calculated from his/her CV or by
considering the amount of time that a person has
been working on a topic. This is data that most
companies are presumed to have.
• Previous experience: This is a critical factor in
rating a trust value since, as was mentioned in
the definitions of trust and reputation, previous
experience is the key value through which to
obtain a precise trust value. However, when
previous experience is scarce or it does not exist
humans use other factors to decide whether or
not to trust in a person or a knowledge source.
One of these factors is intuition.
• Intuition: This is a subjective factor which,
according to our study of the state of the art, has
not been considered in previous trust models.
However, this concept is very important
because when people do not have any previous
experience they often use their “intuition” to
decide whether or not they are going to trust
something. Other authors have called this issue
“indirect reputation or prior-derived reputation”
(Mui, 2002). In human societies, each of us
probably has different prior beliefs about the
trustworthiness of strangers we meet. Sexual or
racial discrimination might be a consequence of
such prior belief (Mui, 2002). We have tried to
model intuition according to the similarity
between personal profiles: the greater the
similarity between one person and another, the
greater the level of trust in this person as a result
of intuition.
Figure 1: Trust Model.
By taking all these factors into account, we have
defined our own model with which to rate trust in
CoPs, and this is summarized in Figure 1.
4 USING OUR TRUST MODEL
The main goal of this model is to rate the level of
confidence in an information source or in a provider
of knowledge in a CoP.
As the model will be used in virtual communities
where people are usually distributed in different
locations we have implemented a multi-agent
architecture in which each software agent acts on
behalf of a person and each agent uses this trust
A MODEL TO RATE TRUST IN COMMUNITIES OF PRACTICE
195
model to analyze which person or piece of
knowledge is more trustworthy.
We have chosen the agent paradigm because it
constitutes a natural metaphor for systems with
purposeful interacting agents, and this abstraction is
close to the human way of thinking about their own
activities (Wooldridge, 2001). This foundation has
led to an increasing interest in social aspects such as
motivation, leadership, culture or trust (Fuentes,
2004).
In our case, the model is going to be used in
CoPs and this fact implies several considerations.
The number of interactions that an agent will
have with other agents in the community will be low
in comparison with other scenarios such as auctions.
This is very important because we cannot use trust
models which need a lot of interactions to obtain a
reliable trust value; it is more important to obtain a
reliable initial trust value and it is for this reason that
we use position, expertise and intuition.
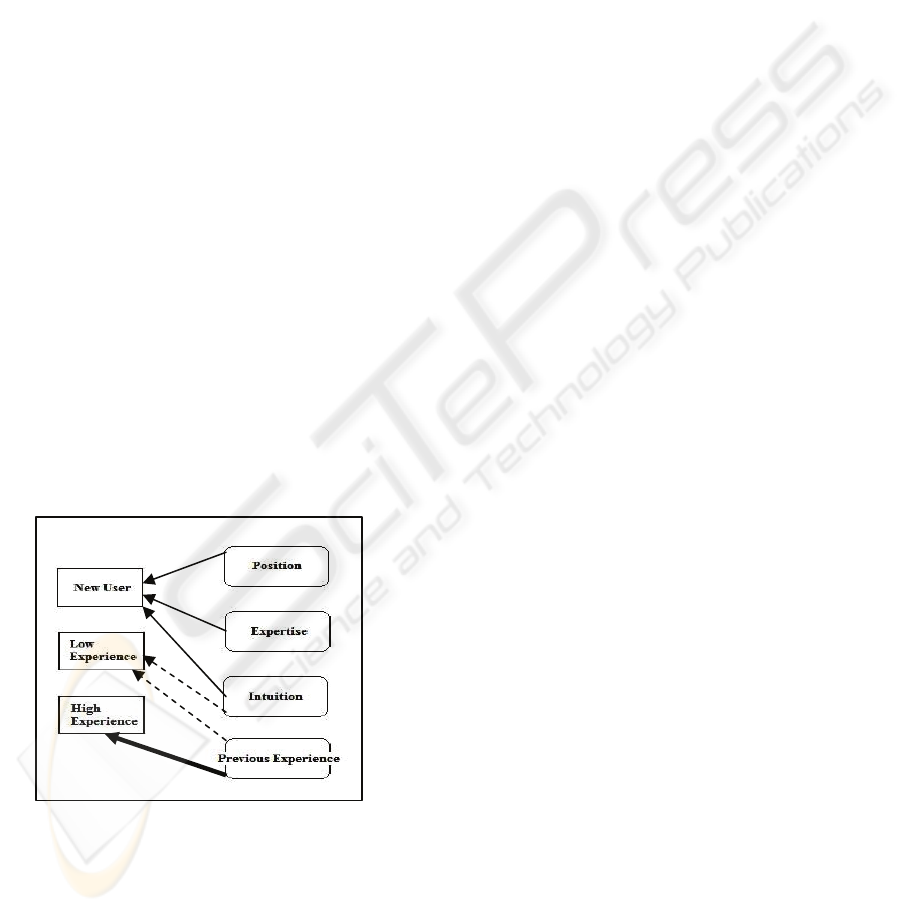
As we observed in the previous section in Figure
1, we use four factors to obtain a trust value, but
how do we use these factors? We have classified
these four factors into two groups: objective factors
(position and expertise) and subjective factors
(intuition and previous experience). The former is
given by the company or community and the latter
depends on the agent itself and the agent’s
experience in time. There are four different ways of
using these factors, which depend upon the agent’s
situation (see Figure 2):
Figure 2: Using the Trust Model.
• If the agent has no previous experience, for
instance because it is a new user in the
community, then the agent uses position,
expertise and intuition to obtain an initial
trust value and this value is used to
discover which other agents it can trust.
• When the agent has previous experience
obtained through interactions with other
agents but this previous experience is low
(low number of interactions), the agent
calculates the trust value by considering
the intuition value and the experience
value. For instance, if an agent A has a
high experience value for agent B but
agent A has a low intuition value for agent
B (profiles are not very similar), then agent
A reduces the value obtained through
experience. In this case the agent does not
use position and expertise factors
(objective factors) because the agent has its
own experience and this experience is
adjusted with its intuition which is
subjective and more personalized.
• When the agent has enough previous
experience to consider that the trust value it
has obtained is reliable, then the agent only
considers this value.
In order to test our model we have developed a
prototype system into which CoPs members can
introduce documents and where these documents
can also be consulted by other people. The goal of
this prototype is to allow software agents to help
users to discover the information that may be useful
to them, thus decreasing the overload of information
that employees often have and strengthening the use
of knowledge bases in enterprises. In addition, we
try to avoid the situation of employees storing
valueless information in a knowledge base.
The main feature of this system is that when a
person searches for knowledge in a community
his/her software agent has to evaluate that
knowledge in order to indicate whether:
The knowledge obtained was useful.
How it was related to the topic of the search (for
instance a lot, not too much, not at all).
With this information, and by using our trust
model, the agent calculates the most trustworthy
knowledge sources and sorts these documents by
using the trust model and considering the most
reliable documents according to his/her user profile
and preferences (Soto et al., 2007).
5 RELATED WORKS
This research can be compared with other trust
models. In models such as eBay(ebay, 2007) and
Amazon (Amazon.com, 2007), which were
ICEIS 2008 - International Conference on Enterprise Information Systems
196

proposed to resolve specific situations in online
commerce, the ratings are stored centrally and the
reputation value is computed as the sum of those
ratings over six months. Thus, reputation in these
models is a global single value. However, these
models are too simple (in terms of their trust values
and the way they are aggregated) to be applied in
open multi-agent systems. For instance, in (Zacharia,
1999) the authors present the Sporas model, a
reputation mechanism for loosely connected online
communities where, among other features, new
users start with a minimum reputation value, the
reputation value of a user never falls below the
reputation of a new user and users with very high
reputation values experience much smaller rating
changes after each update. The problem in this
approach is that when somebody has a high
reputation value it is difficult to change this
reputation or the system needs a high amount of
interactions. A further approach of the Sporas
authors is Histos which is a more personalized
system than Sporas and is orientated towards highly
connected online communities. In (Sabater, 2002)
the authors present another reputation model called
REGRET in which the reputation values depend on
time: the most recent rates are more important than
previous rates. (Carbó, 2003) presents the AFRAS
model, which is based on Sporas but uses fuzzy
logic. The authors presents a complex computing
reputation mechanism that handles reputation as a
fuzzy set while decision making is inspired in a
cognitive human-like approach. In (Abdul-Rahman,
2000) the authors propose a model which allows
agents to decide which agents’ opinions they trust
more and to propose a protocol based on
recommendations. This model is based on a
reputation or word-of-mouth mechanism. The main
problem with this approach is that every agent must
keep rather complex data structures which represent
a kind of global knowledge about the whole
network.
Barber and Kim present a multi-agent belief
revision algorithm based on belief networks (Barber,
2004). In their model the agent is able to evaluate
incoming information, to generate a consistent
knowledge base, and to avoid fraudulent information
from unreliable or deceptive information sources or
agents. This work has a similar goal to ours.
However, the means of attaining it are different. In
Barber and Kim’s case they define reputation as a
probability measure, since the information source is
assigned a reputation value of between 0 and 1.
Moreover, every time a source sends knowledge that
source should indicate the certainty factor that the
source has of that knowledge. In our case, the focus
is very different since it is the receiver who
evaluates the relevance of a piece of knowledge
rather than the provider as in Barber and Kim’s
proposal.
In (Huynh, 2004) the authors present a trust and
reputation model which integrates a number of
information sources in order to produce a
comprehensive assessment of an agent’s likely
performance. In this case the model uses four
parameters to calculate trust values: interaction trust,
role-based trust, witness reputation and certified
reputation. We use a certified reputation when an
agent wants to join a new community and uses a
trust value obtained in other communities but in our
case this certified reputation is composed of the four
previously explained factors and is not only a single
factor.
The main differences between these reputation
models and our approach are that these models need
an initial number of interactions to obtain a good
reputation value and it is not possible to use them
discover whether or not a new user can be trusted. A
further difference is that our approach is orientated
towards collaboration between users in CoPs. Other
approaches are more orientated towards competition,
and most of them are tested in auctions.
6 CONCLUSIONS AND FUTURE
WORK
This paper describes a trust model which can be
used in CoPs. The goal of this model is to help
members to estimate how trustworthy a person or a
knowledge source is since when a community is
spread geographically, the advantages of face-to-
face communication often disappear and therefore
other techniques, such as our trust model, should be
used to obtain information about other members.
One contribution of our model is that it takes
into account objective and subjective parameters
since the degree of trust that one person has in
another is frequently influenced by both types of
parameters. We therefore try to emulate social
behaviour in CoPs.
We are testing our model in a prototype into
which CoPs members can introduce documents, and
software agents should decide how trustworthy these
documents are for the user that they represent.
As future work, we are planning to add new
functions to the prototype such as for instance,
expert detection and recognition of fraudulent
A MODEL TO RATE TRUST IN COMMUNITIES OF PRACTICE
197

members who contribute with no useful knowledge.
We would like to stress that we are working on
depurating our trust model in order for it to be used
in knowledge management systems with the goal of
fostering the usage of this kind of tools since
employees who frequently complain about them
claim that these systems often store a lot of
knowledge but it is difficult to know how
trustworthy it is and which is more relevant for each
user.
REFERENCES
Abdul-Rahman, A., Hailes, S. (2000) 33rd Hawaii
International Conference on Systems Sciences
(HICSS'00), IEEE Computer Society., 6, 6007.
Amazon.com (2007).
Barber, K., Kim, J. (2004) In 4th Workshop on Deception,
Fraud and Trust in Agent SocietiesMontreal Canada,
pp. 1-12.
Carbo, J., Molina, M., Davila, J. (2003) International
Journal of Cooperative Information Systems, 12, 135-
155.
Davenport, T. H., Prusak, L. (1997) Working Knowledge:
How Organizations Manage What They Know, Project
Management Institute. Harvard Business School Press,
Boston, Massachusetts.
Desouza, K., Awazu, Y., Baloh, P. (2006) IEEE Software,
30-37.
Dillenbourg, P. (1999) Collaborative Learning Cognitive
and Computational Approaches. Dillenbourg (Ed.).
Elsevier Science.
ebay (2007).
Fuentes, R., Gómez-Sanz, J., Pavón, J. (2004) In Wang, S.
et al (Eds.) ER Workshop 2004, Springer Verlag,
LNCS 3289, pp. 458-469.
Huynh, T., Jennings, N., Shadbolt, N. (2004) Proceedings
of 16th European Conference on Artificial
Intelligence, 18-22.
Luhmann, N. (1979) In Wiley, Chichester.
McKnight, D., Chervany, N. (1996) In Technical Report
94-04, Carlons School of Management, University of
Minnesota.
Mui, L., Halberstadt, A., Mohtashemi, M. (2002)
International Conference on Autonomous Agents and
Multi-Agents Systems (AAMAS'02), 280-287.
Mui, L., Mohtashemi, M., Ang, C., Szolovits, P.,
Halberstadt, A. (2001) In 11th Workshop on
Information Technologies and Systems (WITS)New
Orleands.
Nonaka, I., Takeuchi, H. (1995) The Knowledge Creation
Company: How Japanese Companies Create the
Dynamics of Innovation, Oxford University Press.
Sabater, J., Sierra, C. (2002) Proceedings of the Fifth
International Conference on Autonomous Agents, 3,
44-56.
Soto, J. P., Vizcaino, A., Portillo-Rodriguez, J. and
Piattini, M. (2007) Proceedings of International
Conference on Software and Data Technologies
(ICSOFT).
Wang, Y., Vassileva, J. (2003a) Proceedings of the 3rd
International Conference on Peer-to-Peer Computing.
Wang, Y., Vassileva, J. (2003b) Proceedings of IEEE
Conference on P2P Computing.
Wasserman, S., Glaskiewics, J. (1994) Sage Publications
.
Wenger, E. (1998) Communities of Practice: Learning
Meaning, and Identity, Cambridge University Press,
Cambridge U.K.
Wenger, E., McDermott, R., Snyder, W. (2002)
Cultivating Communities of Practice.
Wooldridge, M., Ciancarini, P. (2001) Agent-Oriented
Software Engineering: The State of the Art.
Zacharia, G., Moukas, A., Maes, P. (1999) 32nd Annual
Hawaii International Conference on System Science
(HICSS-32).
ICEIS 2008 - International Conference on Enterprise Information Systems
198
