
A 3D USER INTERFACE FOR THE SEMANTIC NAVIGATION
OF WWW INFORMATION
Manuela Angioni, Roberto Demontis, Massimo Deriu and Franco Tuveri
CRS4 - Center for Advanced Studies, Research and Development in Sardinia, Polaris, 09010 Pula (CA), Italy
Keywords: 3D User Interface, Semantic net, WWW Information Retrieval.
Abstract: The automatic creation of a conceptual knowledge map using documents coming from the Web is a very
relevant problem because of the difficulty to distinguish between valid and invalid contents documents. In
this paper we present an improved search engine GUI for displaying and organizing alternative views of
data, by the use of a 3D graphical interface, and a method for organizing search results using a semantic
approach during the storage and retrieval of information. The presented work deals with two main aspects.
The first one regards the semantic aspects of knowledge management, in order to support the user during the
query composition and to supply to him information strictly related to his interests. The second one argues
the advantages coming from the adoption of a 3D user interface, to provide alternative views of data.
1 INTRODUCTION
A web-based search engine responds to a user’s
query with a list of documents. This list can be
viewed as the engine’s model of the user’s idea of
relevance the engine ‘believes’ that the first
document is the most likely to be relevant, the
second is slightly less likely, and so on. In the
specific context of the DART project (Angioni et
al., 2007), that is focused in the development of a
distributed architecture for a semantic search engine,
we think that the answer to a query can be given
providing the user with several kind of results, not
always related in the standard way the search
engines we use today do. A semantic approach for
information storage and retrieval is a way to
represent knowledge in the form of human language,
similar as it is represented in the human mind, but
while hyperlinks have come into widespread use, the
closely related semantic link is not yet widely used.
Semantic networks are a powerfull manner to
represent knowledge. A semantic network is
fundamentally a system for capturing, storing and
transferring information that works much the same
as (and is, in fact, modelled after) the human brain.
It is robust, efficient and flexible. It can grow to
extraordinary complexity, necessitating a
sophisticated approach to knowledge visualization,
balancing the need for simplicity with the full
expressive power of the network. In this paper we
expose a tool for the navigation of semantic
concepts by the use of a 3D user interface and a
semantic approach for information storage and
retrieval, that together permit users to share
information more effectively, and provide reductions
in query formulation and execution. To be effective
this new approach must be used, and thus an
approach that face the user with relevant resources
in reply to a query related to a specific domain of
interest is desirable. This motivation bring us to
develop a prototype, able to support the user during
the query composition and to supply information
strictly related to his interests, considering concepts
and solution related to the semantic aspects of
information retrieval.
2 RELATED WORKS
The issue of visually representing abstract
information by 3D is not new. Relevant backgrounds
for our work can be found in the field of Information
Visualization as well as in best practices techniques
adopted by existing solutions for ontology
representation. The works described below have
been assumed as a starting point in the development
of our project.
256
Angioni M., Demontis R., Deriu M. and Tuveri F. (2008).
A 3D USER INTERFACE FOR THE SEMANTIC NAVIGATION OF WWW INFORMATION.
In Proceedings of the Tenth International Conference on Enterprise Information Systems - HCI, pages 256-261
DOI: 10.5220/0001707202560261
Copyright
c
SciTePress

OntoRama (OntoRama, 2007) is an ontology
browser for RDF models based on a hyperbolic
layout of nodes and arcs. As the nodes in the center
are distributed on more space than those near to the
circumference, they are visualized with a higher
level of detail, while maintaining a reasonable
overview of the peripheral nodes. In addition to this
pseudo-3D space, OntoRama also introduces the
idea of cloned nodes in order to reduce the number
of crossed arcs and enhance the readability. The
duplicate nodes are displayed using an ad-hoc color
in order to avoid confusion. Unfortunately, this
application does not support editing and can only
manage RDF data.
Another interesting work is the OntoViz
(OntoViz, 2007) plug-in displays an ontology as a
graph by exploiting an open source library optimized
for graph visualization (Gansner & North, 1999).
Intuitively, classes and instances are represented as
nodes, while relations are visualized as oriented arcs.
Both nodes and arcs are labelled and displaced in a
way that minimizes overlapping, but not the size of
the graph. Therefore, the navigation of the graph,
enhanced only by magnification and panning tools,
does not provide a good overall view of the
ontology, as the graphical elements easily become
indistinguishable. OntoViz supports visualization of
several disconnected graphs at once. The users can
select a set of classes or instances to visualize.
OntoViz generates graphs that are static and non-
interactive which makes it less suitable for the
visualization of large ontologies.
TGViz (TGVizTab, 2007), similarly to OntoViz,
visualizes Protege (Protege, 2007) ontologies as
graphs. In this case however, the displacement of
nodes and arcs is computed using the spring layout
algorithm implemented in the Java TouchGraph
library (TouchGraph, 2007).
3 PROVIDING SEMANTIC
RELATION TO WEB BASED
KNOWLEDGE
Providing traditional Web searching with semantic
features is an application of the Semantic Web,
based on an explicit representation of semantics
about web resources and real world object. It is
aimed to improve both the proportion of relevant
material actually retrieved and the proportion of
retrieved material that is actually relevant. Recently,
research on information systems has increasingly
focused on how to effectively manage and share data
in a such heterogeneous and distributed
environment. In particular, the investigation of the
Semantic Web as an extension of the actual World
Wide Web, is aimed to make the Web content
machine understandable, allowing agents and
applications to access a variety of heterogeneous
resources (Dolog & W.Nejdl 2007).
It has been proposed to deal with problems such
as information overload and info-smog that are
responsible for the “lost on the net” effect and make
the web content inaccessible Our approach is to
index and retrieve information both in a generic and
in a specific context whether documents can be
mapped or not on ontologies, vocabularies and
thesauri. To achieve this goal, we perform a
semantic analysis process on structured and
unstructured parts of documents. The unstructured
parts need a linguistic analysis and a semantic
interpretation performed by means of Natural
Language Processing (NLP) techniques, while the
structured parts need a specific parser.
3.1 Semantic Analysis Process
A semantic analysis process will be carried out on
the transition from the old style of serving the web-
data visualization to the new style of providing the
3D graphical user interface. Firstly, we increase the
semantic net of WordNet (WordNet, 2007), a lexical
dictionary for the English language that groups
nouns, verbs, adjectives and adverbs into synonyms
sets, called synsets, linked by relations, such as
meronymy, synonymy or hyperonymy/hyponymy,
identifying valid and well-founded conceptual
relations and links contained in documents in order
to build a data structure, composed by concepts and
correlation between concepts and information, to
overlay the result set returned from the search
engine. At the same time we realized the
importance of being able to access a
multidisciplinary structure of documents, evaluating
several solutions like language specific thesaurus or
on-line encyclopedia. To achieve this goal we
choose a multidisciplinary, multilingual, web-based,
free content document encyclopaedia, such as
Wikipedia (Wikipedia, 2007), that contains about
1.900.000 encyclopedic information. We used the
great amount of documents included in Wikipedia to
extract new knowledge and to define a new semantic
net enriching WordNet. We added with new terms,
new associative relations and their classification, as
emphasized in (Harabagiu et al., 1999) where
authors identify several other weaknesses in the
WordNet semantic net constitution. In fact it
A 3D USER INTERFACE FOR THE SEMANTIC NAVIGATION OF WWW INFORMATION
257

contains about 115.000 word “senses”, that means
few number of connections between words related
by topics, not enough respect to the web language
dictionary. A conceptual map built using Wikipedia
pages allows a user to associate a concept to other
ones enriched with some relations that an author
points out. The use of Wikipedia guarantees, with
reasonable certainty, that such conceptual
connection is valid because it is produced by
someone who, at least theoretically, has the skills or
the experience to justify it. Moreover, the rules and
the reviewers controls set up guarantee reliability
and objectivity.
4 INTEGRATING 3D
INFORMATION
VISUALIZATION INTO
SEMANTIC NET
TECHNOLOGIES
One of the critical issue in our research was to
improve the user experience during the phases of
searching and extracting of the concepts. We
investigate new paradigm and model of UI, specially
deepening the study of 3D visualization. Although
the exposition of semantic networks into a 2D map
presentation can provide reasonably good results in
some cases, it is missing some important features to
make a real difference and provide satisfactory
results. Usually a user is presented with a flat panel,
limited in size, where information may be presented
in a form of color patches, sometimes textured, with
different shapes which can be distinguished when
the number of objects presented is low. The user
interaction is limited to selecting a point in the
panel. What we needeed was to exceeds the
capabilities of traditional interaction devices and
two-dimensional displays, allowing the user to
change the point of view, improving the perception
and the understanding of contents (Biström et al.
2005). Our goal was to traverse the net via concept
list views, via their relations, or by retracing the
user's history. The tool we developed, allows to
browse Web resources by means of the map of
concept. Formulating the query through the search
engine, the user can move through the SemanticNet
and extract the concepts which really interest him,
limiting the search field and obtaining a more
specific result. In a 3D space, a user can easily
understand the meaning of an object, simply
rotating, shifting, and moving it (Cellary et al.,
2004). Each node represented in the 3D view is a
concept and arcs are used to showed in order to
represents the different kinds of relations between
the concepts. If the representation is suitable for the
search context, the objects are easy to explore, and
the related information are learned faster and better
(Wiza et al, 2004).
4.1 Building The Semantic Net
In order to build the SemanticNet, we need to
condider terms and their classification. The reason is
that varied mental association of places, events,
persons and things depend on the cultural
backgrounds of the users' personal history. In fact,
the ability to associate a concept to another is
different from person to person. The SemanticNet is
definitely not exhaustive but it is limited by the
dictionary of WordNet, by the contents included in
Wikipedia and by the accuracy of the information
given by the system. Starting from the information
contained in Wikipedia about a term of WordNet,
the system is capable of enriching the SemanticNet
by adding new nodes, links and attributes, such as
IS-A or PART-OF relations. Moreover, the system is
able to classify automatically the textual contents of
web resources, indexed through the Classifier, a
module that uses WordNet Domains (Magnini et al.,
2002) and (Magnini et al., 2004), and applies a
density function, based on the synonyms and
hypernyms frequency (Scott, 1998) and the
computation of the number of synsets related to
each term of the document. In this way, the system
is able to retrieve the most frequently used “senses”
by extracting the synonyms relations given by the
use of similar terms in the document sentences.
Through the categorization of the document
itself it can associate the term the most correct
meaning and can assign a weight to each category
related to the content. In fact, each term in WordNet
has more than one meaning each corresponding to a
Wikipedia page. We therefore need to extract the
specific meaning described in the Wikipedia page
content, in order to build a conceptual map where
the nodes are the “senses” (synset of WordNet or
term+category) and the links are given both by the
WordNet semantical-linguistic relations and by the
conceptual associations built by the Wikipedia
authors. To achieve this goal, the system performs a
syntactic and a semantic disambiguation, as better
described by Angioni, Demontis and Tuveri (2007),
of the textual content of the Wikipedia page and
extracts its meaning associating it to a node
corresponding to the specific “sense” of a term in
WordNet (synset) or, if it does not exists in
ICEIS 2008 - International Conference on Enterprise Information Systems
258

WordNet, adding to the SemanticNet a new node
(term + category).
5 THE DISPLAYABLE DATA
STRUCTURE
As described before, we have enriched the WordNet
semantic net with new terms extracted from
approximately 60.000 Wikipedia articles
corresponding to WordNet terms. Through the
classification of the content of Wikipedia pages ,the
system assigns them a synset ID of WordNet, if it
exists. By analyzing the content of the Wikipedia
pages, a new kind of relation named
“COMMONSENSE” is defined, that delineates the
SemanticNet with the semantic relations “IS-A” and
“PART-OF” given by WordNet. The
COMMONSENSE relation is a connection between
a term and the links defined by the author of the
related Wikipedia page. These relations are
important each time the system give back results to a
query. Results provide the concepts referred in
WordNet or in the Wikipedia derived conceptual
map. The concept map is constituted by 25010 nodes
each corresponding to a “sense” of WordNet and
related to a page of Wikipedia. Starting from these
nodes, 371281 relations were extracted, part of
which are also included in WordNet, but in the most
case they are new relations extracted from
Wikipedia. Terms not contained in WordNet and in
Wikipedia are new nodes of the augmented semantic
net. Terms which meanings are different in
Wikipedia in respect with the meaning existing in
WordNet will be added as new nodes in the
SemanticNet but they will not have a synset ID
given by WordNet.
Figure 1: A view of the 3D UI with COMMONSENSE
relation.
In Figure 1 a portion of the SemanticNet is
described, starting from the node tiger. The
Wikipedia text related to the term is analyzed and
classified under the category Animals. In this way
the system is able to exclude one of the two senses
included in WordNet, the one having the meaning
related with person, and to take into consideration
only the sense related with animal.
So, all the new relations extracted from the page
itself as well as the relation included in WordNet can
be associated to this specific node by the system.
6 ARCHITECTURE OF THE 3D
USER INTERFACE
A major motivation for keeping 3D GUIs for
displaying search results simple is to keep them
user-friendly. In general the 3D UIs for displaying
virtual worlds need more immersive and ad hoc
hardware interfaces, anyway in our case one of the
essential requirements was to guarantee a good
usability by concrete representations and simplicity
(Houston, 2002).
As a consequence we need to keep the user into
a Web context, and allowing her/him to manage
interactive 3D contents within the Web browser.
Recently Web sites that include 3D content, i.e.
Web sites where users navigate and interact (at least
partially) through a 3D graphical interface, are
increasingly employed in different domains, such as
tutoring and training, tourism, e-commerce and
scientific visualization However, while a substantial
body of literature and software tools is available
about making 2D Web sites adaptive, very little has
been published on the problem of personalizing 3D
Web content and interaction.
6.1 Adaptive Manipulation Of 3D Web
Content
To identify the best approach to achieve the task of
adaptive manipulation of 3D Web content, we have
explored several 3D Web technology. The study has
been limited only to W3C languages able to describe
virtual worlds, we have deliberately choose to do not
consider java applets, flash interactive movies, and
other technologies that can be integrated into web
pages to view 3D contents. In particular at the
begining we have evaluated and discarded VRML
(VRML), 3DML (3DML tutorial). The reason to set
aside these languages is that they require plug-in
A 3D USER INTERFACE FOR THE SEMANTIC NAVIGATION OF WWW INFORMATION
259
modules with a partial support to their
specifications.
We also considered SVG (SVG) as another way
to avoid 3D interactive contents, specially because
SVG engines are natively supported by the most
common Web browsers. Unfortunately this language
is not dedicated to 3D graphics and it needs ad-hoc
extensions to process 3D contents, from our point of
view it looks too restrictive because makes the all
process too trivial and do not guarranties a good
level of interactivity. At the end of the analisy we
finally choose the X3D (eXtensible 3D) language
(Web 3D Consortium, 2007) This choice has been
driven by its features, specially because it is is the
ISO open standard for 3D content delivery on the
web supported by a large community of users.
Conceptually, the semantics of X3D describe an
abstract functional behaviour of time-based,
interactive 3D, multimedia information and do not at
all specify a specific software or hardware setup.
The key difference with the other languages is
inherent in the X3D runtime environment, in
particular the scene graph, which is a directed,
acyclic graph containing the objects represented as
nodes and object relationships in the 3D world. The
basic structure of X3D documents is very similar to
any other XML document. All elements are nested
within the X3D tag including the scene graph tag.
6.2 Implementation
The user interface that we have developed is a
software module used according to the user
preferences and the current user context that
provides an interactive scene defined by a X3D
document that represent the selected portion of
SemanticNet. Depending on the search context it
provides a three-dimensional view that guarantees a
better usability in terms of information navigation,
and it could also provide different layouts for
different cases. When the user provides a query
expressed in Natural Language, the system analyse
it, and returns a set of results containing the main
categories and the more representative synset found
If the results don’t fit with the the user need, he
can decide to reformulate a new query using the
SemanticNet in order to enrich the query with new
terms related or semantically near to the original
query
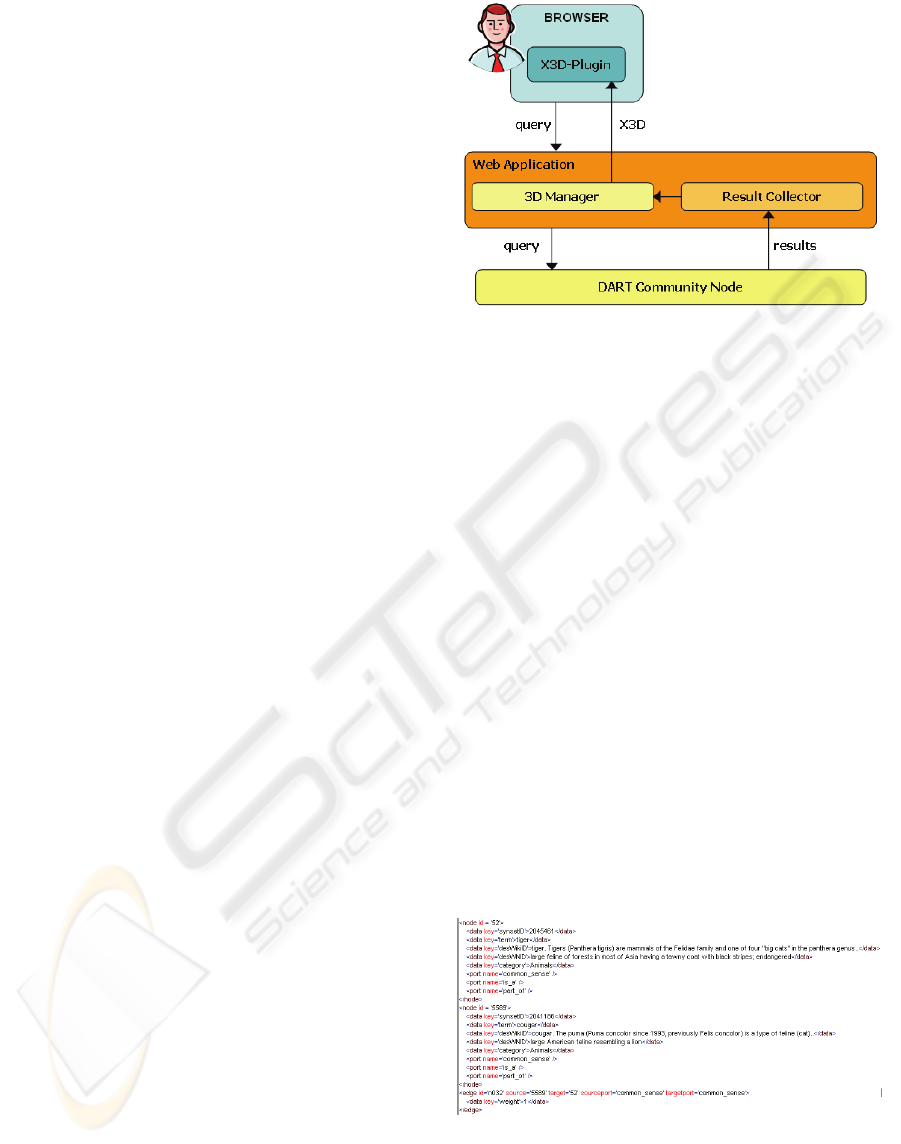
Figure 2: Software Architecture.
The module parts are:
• Web Application – it is the interface between the
SemanticNet and the front-end of the 3DUI. Its
tasks are to submit the query originated in the
browser to the SemanticNet, to forward results to
the ResultCollector, and finally to encapsulate
and to send the X3D document to the browser.
• ResultCollector – it has the role to collect the
retrieved terms semantically related each other
by the means of a concept list. It analize their
relations, and provide a suitable description
defined by a GraphML file (GraphML Working
Group ) and (Bonnel, 2005).
• 3D Manager – it receives and parse the
GraphML file that describe the interested portion
of the SemanticNet within its structural
properties including directed, undirected, mixed
and hierarchical graphs, starting from the
singular node. It also generates on the fly the
X3D document that offers an interactive 3D
scene with the search results. Subsequently it
sends the document to the Web application that
makes it available to the user browser.
Figure 3: An example of the GraphML exchange file.
ICEIS 2008 - International Conference on Enterprise Information Systems
260

7 CONCLUSIONS
The goal of search engines is increased usage and
the common wisdom is that a simpler interface
broadens the base of potential users. We have
presented a 3D interface for a web search engine that
permits the user to decide which other “meanings”
add to the original query. We have explored the
opportunity to provide a such software infrastructure
for the management of semantic knowledge
structures in the ambit of the WWW, investigating
new interaction models and design principles in
order to create a better interactive systems. The tool
we developed allow to browse Web resources by
means of the map of concept called “SemanticNet”
built enriching the WordNet semantic net with new
nodes, links and attributes. The importance of
integrating 3D Information Visualization into
semantic network technologies is that 3D may
support semantic search process providing
functionalities to make the information more
accessible and improving their usability. The future
works are focused on improvements in the interface
selection method and development of new interfaces
for the SemanticNet. It is expected that the interface
selection algorithm may be improved by registration
of user interactions, such as preferred visualization
interfaces and options selected in particular
interfaces.
REFERENCES
M. Angioni, et al., 2007, DART: “The Distributed Agent-
Based Retrieval Toolkit”. In Proc. of CEA 07, pp. 425-
433 Gold Coast – Australia.
Ontorama, 2007, from http://www.kvocentral.org/
software/ontorama.html
Ontoviz tab, 2007: Visualizing protege ontologies.
from http://protege.cim3.net/cgi-bin/wiki.pl?OntoViz
Gasner and North, 1999, . “An open graph visualization
system and its applications to software engineering”In
Software Practice and Experience , pp 30, 11,
1203.1233.
TgVizTab,2007, from http://users.ecs.soton.ac.uk/
ha/TGVizTab/
Protege, 2007, from http://protege.stanford.edu/
Touchgraph, from. http://www.touchgraph.com/
P.Dolog & W.Nejdl. “Semantic Web Technologies for the
Adaptive Web”. pp. 697-719.-2007
WordNet, 2007, from http://wordnet.princeton.edu
Wikipedia, 2007, from http://www.wikipedia.org
Harabagiu, Miller, Moldovan, 1999, WordNet 2 “A
Morphologically and Semantically Enhanced
resource”. Workshop SIGLEX'99: Standardizing
Lexical Resources.
Biström et al (2005). “Post-WIMP User Interface Model
for 3D Web Applications”. In Research Seminar on
Digital Media. Telecommunications Software and
Multimedia Laboratory, Helsinki University of
Technology. Finland, 2005
W.Cellary, et al. "Visualizing Web Search Results in 3D,"
In Computer, vol.37, no.5, pp. 87-89, May, 2004
W.Wiza, et al. (2004). "Periscope: a system for adaptive
3D visualization of search results". In Web3D '04:
Proceedings of the ninth international conference on
3D Web technology, pp. 29-40, New York, NY, USA.
ACM Press.
B. Magnini, C. Strapparava, G. Pezzulo, A.Gliozzo, “The
Role of Domain Information in Word Sense
Disambiguation. Natural Language Engineering”,
special issue on Word Sense Disambiguation, 8(4), pp.
359-373, Cambridge University Press. 2002
B. Magnini, C. Strapparava, “User Modelling for News
Web Sites with Word Sense Based Techniques”. User
Modeling and User-Adapted Interaction 14(2), pp.
239-257 - 2004
S. Scott, S. Matwin, “Text Classification using WordNet
Hypernyms”. COLING/ACL Workshop on Usage of
WordNet in Natural Language Processing Systems,
Montreal, 1998
M. Angioni, R. Demontis, F. Tuveri, “Enriching WordNet
to Index and Retrieve Semantic Information”. In 2nd
International Conference on Metadata and Semantics
Research, 11-12 October, Ionian Academy, Corfu,
Greece. 2007
B. Houston, Z. Jacobson, “A Simple 3D Visual Text
Retrieval Interface”. In TRO-MP-050 - Multimedia
Visualization of Massive Military Datasets. Workshop
Proceedings. 2002
VRML Virtual Reality Modeling Language,
http://www.w3.org/MarkUp/VRML/
3DML tutorial, http://www.flatland.net/blog/?page_id=48
Scalable Vector Graphics (SVG), http://www.w3.org/
Graphics/SVG/
Web 3D Consortium – Overnet, 2007, from
http://www.web3d.org.
GraphML Working Group: The GraphML file format.
http://graphml.graphdrawing.org/
N. Bonnel, A. Cotarmanac’h, A.Morin, 2005, Meaning
Metaphor for Visualizing Search Results, in
International Conference on Information Visualisation,
IEEE Computer Society, pp. 467–472.
A 3D USER INTERFACE FOR THE SEMANTIC NAVIGATION OF WWW INFORMATION
261
