
USING BITSTREAM SEGMENT GRAPHS FOR COMPLETE
DESCRIPTION OF DATA FORMAT INSTANCES
Michael Hartle, Friedrich-Daniel M¨oller, Slaven Travar, Benno Kr¨oger and Max M¨uhlh¨auser
Telecooperation, Technische Universit¨at Darmstadt, Hochschulstr. 10, D-64289 Darmstadt, Germany
Keywords:
Software engineering, data format, bitstream, complete description.
Abstract:
Manual development of format-compliant software components is complex, time-consuming and thus error-
prone and expensive, as data formats are defined in semi-formal, textual specifications for human engineers.
Existing approaches on a formal description of data formats remain at high-level descriptions and fail to
describe phenomena such as compression or fragmentation that are especially common in Multimedia file
formats. As a step-stone towards the description of data formats as a whole, this paper presents Bitstream
Segment Graphs as a complete model on data format instances and presents an example PNG where a complete
model on data format instances is required.
1 INTRODUCTION
A data format is an abstract concept for expressing
how some information is laid out in terms of bits and
bytes. Let us assume we want to know the width
of a Portable Network Graphics (PNG) image file.
The PNG file format (Duce, 2003) defines the over-
all structure, assigns the meaning of image width to
some bit range and maps these specific bits to a typed
literal. Using this knowledge, we know how to find
out the width of an image stored in a PNG file and
can write some code similar to Figure 2.
Now, when we implement an algorithm that works
on data following a data format, we translate data
format knowledge into source code. The resulting
source code for format-compliant processing strongly
depends on initial factors such as its purpose and as-
pects of the target environment. Such aspects involve
the underlying hardware, the operating system, the
programminglanguage, the style of programming, the
APIs we intend to use, how we want to keep the in-
formation in memory, whether or not the data format
is octet-aligned and so on. If we change one initial
factor, eg. switch from Java to C++, PHP or VHDL,
the result differs substantially in terms of software de-
sign and implementation. Once designed and imple-
mented, adapting source code to change factors is a
labourous manual task that is often undesirable.
1.1 Problem
In practice, current data formats in domains like Mul-
timedia have reached a tremendouscomplexity, which
can be demonstrated with an example. For writing
software that is natively capable of setting up a H.323
video conference call to a Microsoft NetMeeting soft-
ware client or a Sony hardware client, we needed
to implement the H.225 and H.245 protocols besides
others. The data format of their protocol messages
is defined using the Abstract Syntax Notation One
(ASN.1) (ITU-T, 1997) and the ASN.1 PER encoding
(ITU-T, 2002) in their respective specifications, all in
all involving several hundreds of pages basically in-
tended for human engineers.
Fortunately, formal ASN.1 specifications of H.225
and H.245 exist that can be translated into source code
using appropriate ASN.1 compilers. For an object-
oriented Java implementation capable of sending and
receiving the respective protocol messages, we did so
using openASN1 (Hoss and Weyland, 2007). The
translation resulted in 321 Java classes with 865kb
of source code for H.225 and in 1.005 Java classes
with 3.87mb of source code for H.245. So without fo-
cusing too much on the numbers, this example makes
obvious that manually translating data format knowl-
edge into source code is all but a trivial task for hu-
man engineers that make mistakes. For data formats
in general, this manual translation process is complex,
time-consuming and thus error-prone and expensive.
Unfortunately, ASN.1 is not generally applicable and
198
Hartle M., Möller F., Travar S., Kröger B. and Mühlhäuser M. (2008).
USING BITSTREAM SEGMENT GRAPHS FOR COMPLETE DESCRIPTION OF DATA FORMAT INSTANCES.
In Proceedings of the Third International Conference on Software and Data Technologies - ISDM/ABF, pages 198-205
DOI: 10.5220/0001891101980205
Copyright
c
SciTePress

up till now, related work in literature does not deliver
something comparable for data formats in general, as
we will see later in section 2.
Moreover, the initial factors of a translation often
do not remain constant. Data formats are revised, get
extended or have to be adapted to be interoperable
with deviating implementations. Instead of just read-
ing data, we may need to write it as well. We may
have to port parts of it to a J2ME mobile phone, or
an embedded system. We may even need to change
the programming language for better integration with
other components. With every change, we again have
to heavily adapt previous source or even retranslate,
using manual labour.
Automating the translation process of data format
knowledge to source code thus becomes attractive.
For that purpose, we need explicit data format knowl-
edge to be present in a machine-processable sense.
Yet, no suited model on data formats exists in lit-
erature, so for data format knowledge, we are cur-
rently limited human processing of semi-formal, tex-
tual specifications or source code of other implemen-
tations.
1.2 Restating the Problem
The intention of a data format is to provide a lossless
transport representation of information for the pur-
pose of storage and transmission for each of its data
format instances. A data format instance is a bijec-
tive mapping between structured, semantic literals as
information and a finite sequence of bits, or bitstream,
as transport representation, with an example shown
in Figure 1. A data format is a finite definition of a
possibly infinite set of data format instances, which is
analogous in definition to that of a formal language
(Mateescu and Salomaa, 1997).
Existing research in literature does not pro-
vide a complete, generally applicable and machine-
processable model for describing arbitrary data for-
mats such as those in practice. Just like a data format
is composed from its instances, we need to be able
to describe these instances before we can describe a
data format as a whole. As such a model on data for-
mat instances is a necessary prerequisite which does
not exist as well, it is the main subject of this paper.
1.3 Implications
Due to the lack of suited models, common engineer-
ing tasks with respect to data formats basically remain
manual processes for human engineers that make mis-
takes, which introduces follow-up problems:
• Defining or reverse-engineering of a data format
has no standard representation suited for auto-
mated documentation and exchange. Ensuring
correctness, completeness, consistency and unam-
biguousness of semi-formal, textual specifications
is entirely in the hand of human judgement and
therefore hard to guarantee.
• Designing and implementing format-compliant
components for typical purposes such as parsing,
in-memory representation and serialization for a
specific environment is a complex task in itself.
Since the complexity of a data format is usu-
ally present in its design and implementation as
well, this manual task becomes even more com-
plex and therefore error-prone. Until discovered
and patched, errors in the implementation can
lead to security issues such as buffer overflows or
break interoperability with other implementations
which is often hard to attribute to. Moreover, the
resulting implementation is bound to its intended
data format, environment and purpose, where any
non-trivial change to any of these requires sub-
stantial adaptation or even redevelopment. It can
be assumed that the arising development cost lim-
its the diversity of existing, reusable implementa-
tions.
• As long as access to and navigation of data in
a specific data format directly depends upon the
existance of suited format-compliant implemen-
tations that have to be developed manually, data
remains tightly coupled with these implementa-
tions. This is a hard problem for Digital Preser-
vation efforts of libraries, as the obsolescence of
applications over time threatens a large body of
digitally born data (Ross and Hedstrom, 2005) on
an individual, corporate and national scale (Wet-
tengel, 1998), much of which comprises our digi-
tal cultural heritage.
1.4 Contribution
In this paper, we present Bitstream Segment Graphs
(BSG) as a complete, generally applicable and
machine-processable model on data format instances,
serving a step-stone towards a later corresponding
model on data formats as a whole.
We start by taking a look on related work in lit-
erature (Section 2) and develop a more distinct no-
tion of completeness (Section 3). Based on that no-
tion, the formalism of Bitstream Segment Graphs is
defined (Section 4.1) and an algorithm for its compo-
sition is given, together with a visual representation
is given (Sections 4.2 and 4.3). Using our model, we
finally present a practical example (Section 5) that ex-
USING BITSTREAM SEGMENT GRAPHS FOR COMPLETE DESCRIPTION OF DATA FORMAT INSTANCES
199

int width = 32;
int height = 32;
byte bitDepth = 16;
byte colorType = 0;
byte compressionType = 0;
byte filterType = 0;
byte interlaceMethod = 0;
89 50 4e 47 0d 0a 1a 0a
00 00 00 0d 49 48 44 54
00 00 00 20 00 00 00 20
10 00 00 00 00 06 81 F9
6B 00 00 00 04 67 41 4d
41 00 01 86 a0 31 e8 96
5f 00 00 00 40 49 44 41
f
−1
f
Figure 1: A data format instance is a bijective mapping between a set of semanic literals (left) and a finite sequence of bits,
depicted as f, where the bit sequence is shown as hexdump (right) with the relevant segment colored in black. The presented
excerpt is the IHDR structure of the PNG image “oi2n0g16.png” (van Schaik, 1998).
// Write image header data
bufferOut.writeLong(width);
bufferOut.writeLong(height);
bufferOut.write(bitDepth);
bufferOut.write(colorType);
bufferOut.write(compressionMethod);
bufferOut.write(filterMethod);
bufferOut.write(interlaceMethod);
buffer = bufferOut.toByteArray();
// Write IHDR chunk
out.writeLong(buffer.length);
out.writeLong(0x49484454);
out.write(buffer);
out.writeLong(calcCRC(buffer));
// Read chunk header
length = in.readLong();
type = in.readLong();
if (type == 0x49484454)
{
in.readBuffer(buffer, 0, length);
crc = in.readLong();
if ((length == 13) && (crc ==
calcCRC(buffer))
{
tempIn = new ByteArrayInputStream(buffer);
bufferIn = new DataInputStream(tempIn);
// Read image header data
width = bufferIn.readLong();
height = bufferIn.readLong();
bitDepth = bufferIn.read();
colorType = bufferIn.read();
compressionType = bufferIn.read();
filterType = bufferIn.read();
interlaceMethod = bufferIn.read();
}
}
Figure 2: Example Java source code extracts for serializing (left) and parsing (right) a PNG IHDR structure which implements
data format knowledge.
isting approaches cannot describe completely and fi-
nally end the paper with conclusions (Sections 6) and
acknowledgements.
2 RELATED WORK
The primary source of research on data format de-
scription originates from the field of Multimedia,
where format-unaware, “dumb” delivery of multime-
dia data becomes a problem in the face of widely het-
erogenous environments. Network bandwidth and/or
latency may not allow timely delivery of multime-
dia data to the end-user. Devices may lack compu-
tational power for timely decoding or possess only a
display with limited screen resolution, which cannot
make full use of the encoded video. Research on Uni-
versal Media Access (UMA) addresses this problem
using format-aware on-the-fly content adaptation and
filtering.
UMA thus lead to research on data formats and
their specification, which resulted in MSDL-S (Eleft-
heriadis, 1996) for the documentation of data struc-
tures, its successors Flavor and XFlavor (Elefthe-
riadis and Hong, 2004) for the automated gener-
ation of format-compliant software components or
the Bitstream Syntax Description Language (BSDL)
(Amielh and Devillers, 2001) recombinations and ex-
tensions like gBSDL (Vetro et al., 2006), BFlavor
(De Neve et al., 2006) and gBFlavor (Deursen et al.,
2007) for high-level multimedia content adaptation
and filtering.
Upon closer examination, these approaches fo-
cus on a limited, typically high-level description of
data and do not describe transformations that may be
present in data format instances such as compression
ICSOFT 2008 - International Conference on Software and Data Technologies
200

or fragmentation. These approaches therefore do not
provide a model which is sufficient to describe arbi-
trary data formats and their instances to completion.
3 ANALYSIS
For an approach on data format description to be gen-
erally applicable in a real-world scenario, require-
ments need to be fulfilled. First of all, we need to
describe bitstreams of arbitrary partitioning, align-
ment and length in order to cover everything. Fur-
thermore, to describe the bijective mapping between
the bitstream and its contained information, we need
to describe its composition. These requirements can
be understood as varying degrees of completeness re-
garding the description of a data format instance and
can be restated as follows:
• Width-completeness is given if a data description
can cover arbitrary bitstreams. For general appli-
cability, it mandates bit granularity and support
for both arbitrary alignment and length for its de-
scriptive means.
• Depth-completeness is given if a data description
is width-complete and can provide for a bijective
mapping between the bitstream and its contained
information in the form of structured, semantic,
independent literals. It mandates the existence of
suited descriptive means for arbitrary transforma-
tions on bitstreams and the encoding of literals.
The previously identified problem of existing ap-
proaches on the description of data format instances
can now be restated as a lack of depth-completeness,
especially regarding block and concatenating trans-
formations. These are required eg. for handling
zlib-compressed bitstream segments in PNGs or in-
terleaved audio/video bitstream fragments in many
multimedia containers such as MPEG-4 or transport
streams such as MPEG-2 TS.
4 MODEL
We now introduce Bitstream Segment Graphs as a
generally applicable model on data format instances
which is width- and depth-complete.
4.1 Definition
The following definitions include the term bitstream
to make their scope explicit. Whenever no ambiguity
is introduced, it may be omitted otherwise.
Definition 4.1 (Bitstream Segment). Given a bit-
stream segment v ∈ V, the set of bitstream segments
V, the set of finite consecutive bit sequences B =
{0,1}
n
,n ∈ N \{0} and ϕ : V 7→ B, then the bitstream
segment v represents a finite consecutive bit sequence
ϕ(v) ∈ B.
Definition 4.2 (Bitstream Source). A bitstream
source is a root bitstream segment v
Root
∈ V with a
defined ϕ(v
Root
).
A bitstream source represents a digital item which
is composed according to a data format. Files, net-
work packets or file systems on some storage medium
are examples for octet-aligned bitstream sources.
Definition 4.3 (Bitstream Encoding). Given a bit-
stream encoding e = (rel, v,l) ∈ R
E
,v ∈ V,l ∈ L,
where R
E
is the set of bitstream encodings and L is
the set of literals, then for a given v, e specifies a map-
ping relation rel(ϕ(v),l), required to be bijective. It
is abbreviated with φ(v) = l, where φ : V 7→ L.
A bitstream segment can represent an encoded lit-
eral that is part of the data contained in a bitstream
source. For example, there are two bitstream seg-
ments within a PNG file which contain encoded inte-
gers that represent the width and height of the image.
Definition 4.4 (Bitstream Transformation). Given
a bitstream transformation t = (rel,V
in
,V
out
,P) ∈ R
T
,
where V
in
,V
out
are totally ordered sets with V
in
⊂
V,V
out
⊂ V,V
in
6=
/
0,V
out
6=
/
0,V
in
∩ V
out
=
/
0, R
T
is
the set of bitstream transformations and P is the set
of parameters, then t specifies a mapping relation
rel(V
in
,V
out
,P), required to be bijective, between V
in
and V
out
under application of P.
In general, a bitstream transformation t bijectively
maps a set of input bitstream segmentsV
in
to a a set of
new bitstream segments V
out
as result of the transfor-
mation. Normalized bitstream transformations cate-
gorized by |V
in
|:|V
out
| cardinality are
• the concatenating transformation of multiple frag-
ment segments into one composite segment (m:1),
• a class of block transformations such as decom-
pression or decryption (1:1) and
• segmenting transformation of a structured seg-
ment into multiple separate bitstream segments
(1:n).
Arbitrary transformations of m : n cardinality can be
composed by concatenating two or more normalized
transformations.
Definition 4.5 (Bitstream Segment Graph). Given
a set of bitstream transformations R
T
and a set of
USING BITSTREAM SEGMENT GRAPHS FOR COMPLETE DESCRIPTION OF DATA FORMAT INSTANCES
201

bitstream encodings R
E
, then R
T
and R
E
induce a
bitstream segment graph (BSG). It is a weakly con-
nected, directed acyclic rooted graph G = (V,E) with
a set of bitstream segments V as vertices and a set of
directed edges E ⊂ V ×V, connecting transformation
input/output pairs of bitstream segments. A BSG de-
scribes the composition of a bitstream source and is
complete iff
∀v ∈ V: (∃!t = (rel
t
,V
in
,V
out
,P) ∈ R
T
,v ∈ V
in
) ⊕
(∃!e = (rel
e
,v
e
,l) ∈ R
E
,v = v
e
)
A BSG is composed from bitstream transforma-
tions and encodings, which are required to have bi-
jective mapping relations. It therefore provides a
bijective mapping between its bitstream source and
its contained literals and thus satisfies the depth-
completeness requirement.
Definition 4.6 (Transformation Dependency). A
transformation dependency exists if for a bitstream
segment v there exists a nonempty set of bitstream seg-
ments ϖ(v) ∈ 2
V
with t = (rel,V
in
,V
out
,P) ∈ R
T
,v ∈
V
out
that v depends on, where ϖ :V 7→ V
n
,n ∈ N.
Definition 4.7 (Functional Dependency). A func-
tional dependency of a bitstream segment v ∈ V on
a nonempty set of bitstream segments V
dep
⊂ V with
v 6∈ V
dep
exists if the data format defines a function f
and mandates that φ(v) = f(V
dep
).
An example of both a transformation dependency
and a functional dependency is a bitstream segment
which encodes the variable length of another bit-
stream segment. For extracting the latter from a seg-
mentation, the value of the former is required as a pa-
rameter to the transformation. Another example of a
functional dependency is a Cyclic Redundancy Code
(CRC) on a set of bitstream segments, stored in an-
other bitstream segment.
Transformation and functional dependencies put
constraints on possible orders of processing for bit-
stream segments and validity that format-compliant
software implementations of parsers, object / stream-
ing models and serializers need to handle in their op-
eration.
4.2 Composition Algorithm
Using definitions 4.1 to 4.5, we are able to describe
the bijective mapping between a bitstream source and
its set of contained literals. The following simple al-
gorithm constructs a BSG step-by-step. For a con-
struction at step x, the tuple
(v
Root
,V
x
,V
leaf
x
,V
literal
x
,R
T
x
,R
E
x
)
describes a designated root bitstream segment v
Root
, a
set of bitstream segments V
x
, a set of leaf bitstream
segments V
leaf
x
, a set of literal bitstream segments
V
literal
x
, a set of bitstream transformations R
T
x
and a
set of bitstream encodings R
E
x
, whereas initial values
are
V
0
= {v
Root
}
V
leaf
0
= {v
Root
}
V
literal
0
=
/
0
R
T
0
=
/
0
R
E
0
=
/
0
Starting at step x = 1, each step either adds a trans-
formation or an encoding. For a transformation, the
addition of t = (rel,V
in
,V
out
,P) /∈ R
T
x−1
, V
in
⊆ V
leaf
x−1
results in
V
x
= V
x−1
∪V
out
V
leaf
x
= V
leaf
x−1
∪V
out
\V
in
V
literal
x
= V
literal
x−1
R
T
x
= R
T
x−1
∪ {t}
R
E
x
= R
E
x−1
whereas the addition of an encoding e = (rel,v,l) /∈
R
E
x−1
,v ∈ V
leaf
x−1
results in
V
x
= V
x−1
V
leaf
x
= V
leaf
x−1
\ v
V
literal
x
= V
literal
x−1
∪ {l}
R
T
x
= R
T
x−1
R
E
x
= R
E
x−1
∪ {e}
For step y, the tuple induces a BSG G
y
= (V
y
,E
y
)
where E
y
is defined as follows:
∀t = (rel,V
in
,V
out
,P) ∈ R
T
y
,
∀v
s
∈ V
in
,∀v
t
∈ V
out
: e = (v
s
,v
t
) ∈ E
y
These steps are repeated untilV
leaf
z
=
/
0, where the
algorithm terminates as no further addition of either
transformation or encoding to leaf bitstream segments
is possible.
4.3 Visual Representation
For the representation of a BSG, bitstream segments
are categorized into types, based on normalized trans-
formations and encodings as shown in Table 1. To
prevent a conflicting type assignment for bitstream
segments that have both the “upward” composite type
and another “downward” type, an identity transfor-
mation is inserted after the composite and the “down-
ward” type is assigned to the newly inserted bitstream
segment.
ICSOFT 2008 - International Conference on Software and Data Technologies
202

Table 1: Types of bitstream segments.
Bitstream segment participates in
Leaf Encoding Transformation Type
yes no no Generic
yes any no Primitive
no no segmentation input Structure
no no transformation input Transcode
no no concatenation input Fragment
no no concatenation output Composite
Depending on their type, segments are depicted as
shown in Figure 3, where start and end denote inclu-
sive start and exclusive end bit positions relative to
the parent bitstream segment(s), type denotes the bit-
stream segment type, parameter denotes a parameter
for some types and id denotes some plaintext identifi-
cation.
start
end
type
id
start
end
role
parameter
id
Figure 3: Visual representations; generic, structure and
composite bitstream segments (left); fragment, primitive
and transcode bitstream segments (right).
Besides the visual representation, we have defined
an RDF ontology based on bitstream segment types
for storage, processing and interchange of bitstream
segment graphs for arbitrary data, and implemented
a Java-based annotation tool for their construction.
Both the RDF ontology and the annotation tool are
subject of another publication.
5 EXAMPLE
The PNG Test Suite (van Schaik, 1998) includes
the file oi2n0g16.pngwhich contains zlib-compressed
grayscale image data in the form of filtered scanlines,
fragmented in two separate chunks. The file was se-
lected as its composition contains both a block trans-
formation and a concatenation transformation, which
other approaches cannot describe completely due to a
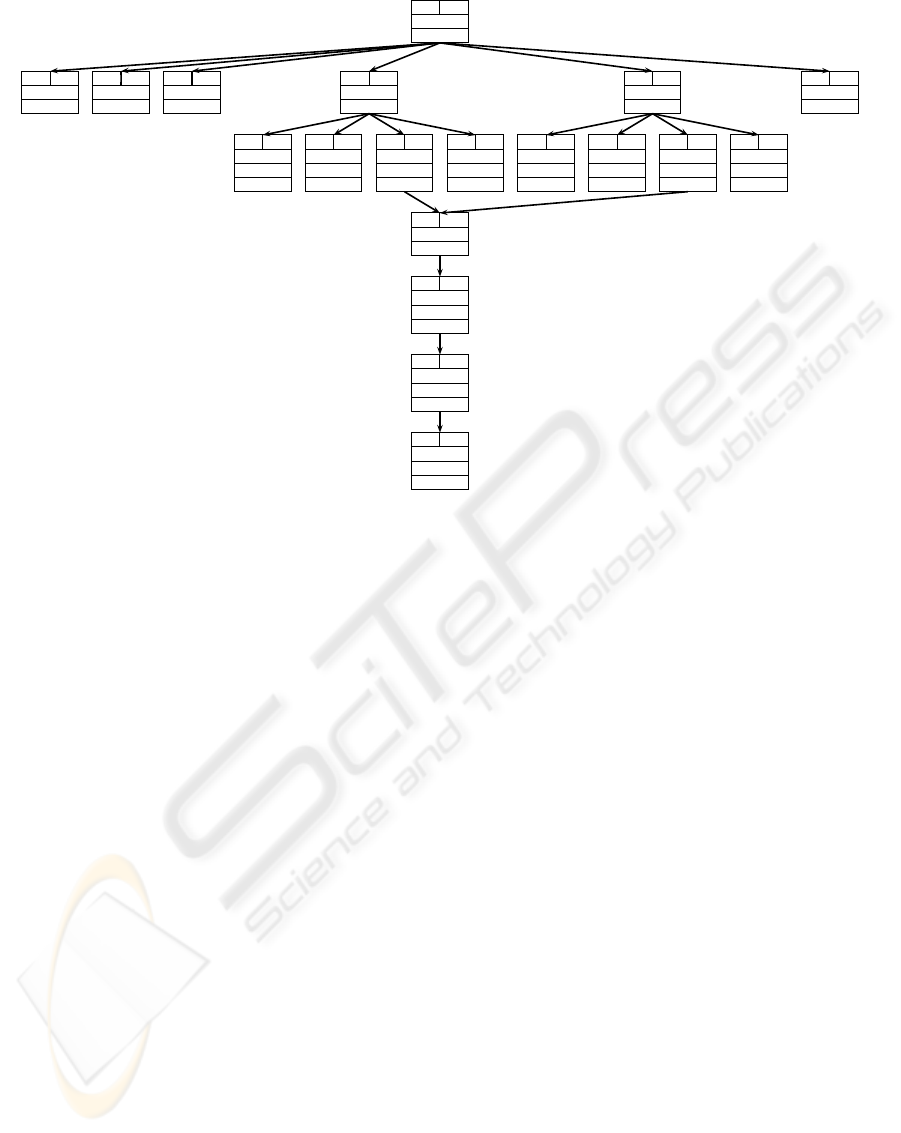
lack of depth-completeness. Figure 4 shows a partial
bitstream segment graph with a depth-complete de-
scription of the contained pixel data including the re-
quired two segmentations, concatenation, decompres-
sion and PNG-specific filtering block transformation.
For the sake of readability, the remaining more sim-
ple structures Signature, IHDR, gAMA and IEND are
shown in a collapsed state only as they just contain
several primitive segments.
File → IDAT #1,IDAT #2
IDAT #n → Len #n,Type #n,Data #n,CRC #n
Data #1,Data #2 → Composite
Compressed → Scanlines
Scanlines → Pixels
An example for both a transformational dependency
and a functional dependency is the segmentation of
IDAT #1 and IDAT #2 as the length of Data #1 and
Data #2 depends on φ(Len #1) and φ(Len #2) re-
spectively. Examples of functional dependencies are
CRC #1 and CRC #2, as φ(CRC #n) depends on
φ(Type #n) and φ(Data #n).
6 CONCLUSIONS
6.1 Summary
This paper has given an in-depth introduction on
needs of research on data format description. It
linked the description of data formats and data for-
mat instances and introduced the terminology of
depth-complete and dependency-complete descrip-
tions. Based on this terminology, the paper con-
tributed the Bitstream Segment Graph as a formalism
for depth-complete data format instance descriptions
and defined a corresponding visual representation.
Using a real-world PNG from a test suite, we have
shown an example that requires depth-completeness
and presented its BSG representation.
Although Bitstream Segment Graphs were devel-
oped for the description of data formats as a whole,
a model on data format instances has merits on its
own. It allows to document the composition of data
and thus serves well during reverse-engineering of in-
stances of unpublished data formats used in protocols
and file formats. A practical example is the reverse-
engineering of exploits in IT Security using BSGs
(Hartle et al., 2008) in order to understand its mecha-
nisms and patch vulnerable implementations.
USING BITSTREAM SEGMENT GRAPHS FOR COMPLETE DESCRIPTION OF DATA FORMAT INSTANCES
203
0 1.432
Structure
File
0 64
Structure
Signature
64 264
Structure
IHDR
264 392
Structure
gAMA
392 1.000
Structure
IDAT #1
1.0001.336
Structure
IDAT #2
1.3361.432
Structure
IEND
0 32
Primitive
int
Len #1
32 64
Primitive
byte[4]
Type #1
64 576
Fragment
#1
Data #1
576 608
Primitive
byte[4]
CRC #1
0 32
Primitive
int
Len #2
32 64
Primitive
byte[4]
Type #2
64 304
Fragment
#2
Data #2
304 336
Primitive
byte[4]
CRC #2
0 752
Composite
Composite
0 752
Transcode
zlib
Compressed
0
16.640
Transcode
PNG Filter
Scanlines
0 16.384
Primitive
short[32][32]
Pixels
Figure 4: Partial bitstream segment graph for file “oi2n0g16.png”, showing the bijective mapping of two PNG IDAT chunks
to a 16 bit grayscale image with a resolution of 32× 32 pixel.
6.2 Outlook
Further research on data format instance description
such as the application of machine learning are cur-
rently underway and will hopefully result in a model
for describing arbitrary data formats. Once data for-
mats can be described completely in a formal way,
processing and applying data format knowledge in an
automated manner should help simplify the develop-
ment of format-compliant software components and
remove the tight coupling of data and applications.
ACKNOWLEDGEMENTS
The authors would like to thank Tobias Klug, Guido
Rling and Gina Hue for providing feedback on drafts
as well as Clayton Hoss and Marc Weyland for devel-
oping openASN1 as their diploma thesis.
REFERENCES
Amielh, M. and Devillers, S. (2001). Multimedia Content
Adaption with XML. In 8th International Conference
on Multimedia Modelling, pages 127–145.
De Neve, W., Van Deursen, D., De Schrijver, D., Ler-
ouge, S., De Wolf, K., and Van de Walle, R. (2006).
BFlavor: A harmonized approach to media resource
adaptation inspired by MPEG-21 BSDL and XFlavor.
EURASIP Signal Processing: Image Communication,
21(10):862 –889.
Deursen, D. V., Neve, W. D., Schrijver, D. D., and de Walle,
R. V. (2007). Automatic generation of generic Bit-
stream Syntax Descriptions applied to H.264/AVC
SVC encoded video streams. iciap, 0:382–387.
Duce, D. (2003). Portable Network Graphics (PNG) Spec-
ification (Second Edition): Information technology –
Computer graphics and image processing – Portable
Network Graphics (PNG): Functional specification.
ISO/IEC 15948:2003 (E).
Eleftheriadis, A. (1996). The Benefits of Using MSDL-
S for Syntax Description. Contribution ISO/IEC
JTC1/SC29/WG11 MPEG96/M1555.
Eleftheriadis, A. and Hong, D. (2004). Flavor: a formal lan-
guage for audio-visual object representation. In MUL-
TIMEDIA ’04: Proceedings of the 12th annual ACM
international conference on Multimedia, pages 816–
819, New York, NY, USA. ACM Press.
Hartle, M., Schumann, D., Botchak, A., Tews, E., and
Mhlhuser, M. (2008). Describing Data Format Ex-
ploits using Bitstream Segment Graphs. Proceedings
of The Third International Multi-Conference on Com-
puting in the Global Information Technology ICCGI
2008.
Hoss, C. and Weyland, M. (2007). openASN.1: En-
twicklung und Evaluation eines ASN.1-Compilers
und PER-Codecs unter Java. Diploma the-
sis, Reliable Basic Support group, Depart-
ICSOFT 2008 - International Conference on Software and Data Technologies
204

ment of Computer Science, TU Darmstadt.
http://www.openasn1.de/media/documents/Diplomarbeit-
openASN.1-0.5.0b.pdf, last accessed 2008-04-02.
ITU-T (1997). Recommendation X.680 (12/97) — Abstract
Syntax Notation One (ASN.1): Specification of Basic
Notation. ITU-T, Geneva.
ITU-T (2002). Recommendation X.691 (07/02) — ASN.1
Encoding Rules: Specification of Packed Encoding
Rules (PER). ITU-T, Geneva.
Mateescu, A. and Salomaa, A. (1997). Formal Languages:
an Introduction and a Synopsis, chapter 1, pages 1–
40. Springer Verlag.
Ross, S. and Hedstrom, M. (2005). Preservation research
and sustainable digital libraries. Int. J. on Digital Li-
braries, 5(4):317–324.
van Schaik, W. (1998). PngSuite - the
official set of PNG test images.
http://www.schaik.com/pngsuite/pngsuite.html,
last accessed 2008-01-02.
Vetro, A., Timmerer, C., and Devillers, S. (2006). The
MPEG-21 Book, chapter Digital Item Adaptation -
Tools for Universal Multimedia Access, pages 243–
281. John Wiley and Sons Ltd.
Wettengel, M. (1998). German Unification and Electronic
Records, chapter 18, pages 265–276. Oxford Univer-
sity Press. ISBN 0198236336.
USING BITSTREAM SEGMENT GRAPHS FOR COMPLETE DESCRIPTION OF DATA FORMAT INSTANCES
205
