
DESIGN A REVERSE LOGISTICS INFORMATION SYSTEM
WITH RFID
Carman Ka Man Lee
1
, Tan Wil Sern
1
and Eng Wah Lee
2
1
School of Mechanical & Aerospace Engineering, Nanyang Technological University, Singapore
2
Singapore Institute of Manufacturing Technology, Singapore
Keywords: Reverse Logistics, Radio Frequency Identification (RFID), Genetic Algorithm, Location determination.
Abstract: Recently, reverse logistics management has become an integral part of the business cycle. This is mainly
due to the need to be environmental friendly and urgent need to reuse scarce resources. Traditionally,
reverse logistics activities have been a cost center for most businesses without generating extra revenue.
However, due to recent increase in commodity and energy prices, reverse logistics management could
eventually be a cost savings method. In this research, we propose using Radio Frequency Identification
(RFID) technology to better optimize and streamline reverse logistics operations. Using RFID, we try to
eliminate parts of the unknowns in reverse logistics flow that made reverse logistics model complicated.
Furthermore, Genetic algorithm is used to optimize the place of initial collection center so as to cover the
largest population possible in order to reduce logistics cost and provide convenience to end users. This study
is based largely on literature review of past workings and also experiments are conducted on RFID
hardware to test for its suitability. The significance of this paper is to adopt ubiquitous RFID technology and
Genetic Algorithms for reverse logistics so as to obtain an economic reverse logistics network.
1 INTRODUCTION
Reverse Logistics is the management of the return
flow of materials from end users back to the
producers. The management for reverse logistics is
the opposite of conventional supply chain flow.
Recently, reverse logistics management came into
focus in an effort to cut cost. As of 1999, total value
of merchandise returned in the U.S amounted to $62
billion. This represents a loss of around $10 -$15
billion to retailers while the cost of handling
returned products was estimated to be $40 billion
(ReturnBuy, 2000). However, the management of
reverse logistics is complicated due to the many
unknowns in the system and integration of reverse
logistics to the forward logistics also proves to be a
challenge (Fleischmann et al., 1997). This paper
aims to overcome the uncertainties in reverse
logistics process using wireless technology such as
Radio Frequency Identification (RFID) to enable the
dissemination of product information in real time.
Genetic Algorithm (GA) is widely used in various
aspects in supply chain to find out the optimized
solution (Min et al., 2003). In this paper, GA is
employed to determine the optimum location to
deploy the various initial collection centers to
develop an optimum reverse logistics network
linking initial collection point and centralized return
centers.
2 RELEVANT LITERATURE
2.1 Reverse Logistics
Reverse logistics is a field of interest with many
recent studies conducted and models developed.
Many models have been developed with regards to
reverse logistics management with Barros et al.
presenting a network for recycling of sands
(Fleischmann et al., 1997). In his model, he
proposed a multi-level capacitated warehouse model
while using scenario analysis to solve for the
uncertainties in the return flow. Spengler et al. on
the other hand developed a mixed-integer linear
programming model for recycling of industrial waste
(Fleischmann et al., 1997) based on a multi-level
capacitated warehouse location. At present, not
many studies have been done to formulate a model
integrating forward and reverse logistics process.
Most of the models currently are planned based on
forward logistics purposes. Min et al. (Min et al.,
2003) developed a decision support system to
293
Lee C., Sern T. and Lee E. (2009).
DESIGN A REVERSE LOGISTICS INFORMATION SYSTEM WITH RFID.
In Proceedings of the 11th International Conference on Enterprise Information Systems - Artificial Intelligence and Decision Support Systems, pages
293-299
DOI: 10.5220/0001856802930299
Copyright
c
SciTePress

support the design of distribution and collection
networks. By using the location of the facility, the
system can determine the optimal good flows in the
return network and the resulting costs (Fleischmann
et al., 1997). From these literature reviews, it is
shown that reverse logistics process is not
necessarily the opposite of forward logistics.
Reverse logistics is more complicated in a sense that
there are different actors involved and the
uncertainties in the system are higher. This has not
been addressed by most of the models at present and
hence we will try to solve this in this research.
2.2 Radio Frequency Identification
(RFID)
Radio Frequency identification (RFID) has been
invented long ago but only recently has the
technology emerge in mainstream applications.
RFID is mainly used to tag products for
identification purposes much like bar-code system
today. However, RFID offers value-added advantage
in that RFID does not need line-of-sight for
operation and can read multiple tags at the same
time, which has been a constraint for bar-code
technology (Want, 2007). Much research is being
done at the moment to search for application usage
of RFID with recent adopters being US retail giant
Wal-mart and Tesco. Although RFID promises a lot
of advantages, there are also constraints and
concerns about the technology. Most importantly is
the additional cost needed to implement RFID
technology to the current system because at the time
being, RFID hardware is still costly. Secondarily,
there is also a concern on the reliability of RFID
technology and finally concern for privacy (Hunt,
2007). At the time being, not many studies have
been done to integrate RFID technology to reverse
logistics management system and this is an area
where we will try to explore.
2.3 Genetic Algorithm
Genetic Algorithm (GA) is a form of mathematical
optimization technique. GA can be used in various
applications such as determining the optimum flow
for a factory production process, optimum traveling
route to determination of location of warehouses.
As compared to traditional optimization
techniques, genetic algorithm is more robust due to
the following features:
• Genetic algorithm works with a set of
parameter and not the parameter itself. This
lends to the robustness of genetic algorithm.
• Genetic algorithm search from a solution space
and not a single point. Hence, genetic
algorithm method does not depend on the
existence of derivatives like traditional
optimization techniques do.
• Genetic algorithm uses an objective function to
determine the score of a chromosome and not
based on derivatives or other auxiliary
knowledge.
• Genetic algorithm uses probabilistic transition
rules. This means that genetic algorithm selects
strings to be included in the next stage or
process based on probability whereby
chromosomes with higher score are assigned a
higher probability to be selected. This is the
basis of survival of the fittest law.
All these advantages of genetic algorithm make it
more robust and useful as compared to other
traditional methods.
3 PROBLEM DEFINITION
As stated earlier, reverse logistics management is
complex and involves a huge amount of unknowns.
In-depth study has been done in this field and
mathematical models have been developed to
enhance the efficiency of reverse logistics. However,
there are still limitations due to the following
reasons:
1. Reverse distribution network is full of
uncertainties such as the quantity and quality of
the returned products from end users.
2. Different actors involved in the reverse
distribution channel require different inventory
control mechanism.
3. Forms of reuse differ for each product
requiring different planning and coordination.
4. Difficulties in inventory control in systems
with return flow.
Furthermore, there are also problems associated with
integrating reverse flow of material into forward
logistics due to:
1. Reverse distribution is not necessarily
symmetric picture of forward distribution.
2. Special characteristics of reverse logistics
include:
• Many-to-few network structure
• System uncertainties
3. Returned products may be sent to original
producer or to third party recycling centre.
Hence, further uncertainties and unknowns are
involved.
ICEIS 2009 - International Conference on Enterprise Information Systems
294

4. Modification and extension may be necessary
to tailor for reverse distribution.
For illustrative purposes, let us suppose that a
computer manufacturer (called Apple hereafter)
selling hardware to end-users intends to recycle used
computers from its customers. Customers who wish
to return the computer will dispose their computer at
the various initial collection points and Apple will
employ logistics providers to collect the disposed
computer from the initial collection points.
Given the limited space at the initial collection
points, returned products should be collected and
shipped to the centralized collection centre as soon
as possible and the components collected should be
determined as soon as the returned products reaches
the centralized collection center.
At the centralized collection center, components
that can be reused may be redistributed after minor
cleaning or refurbishing while defective components
will undergo recycling processes. With the above
situation as a model, we wish to address the
following issues:
1. Location of initial collection point such as to
cover the largest possible population in an area.
2. Location of centralized collection center such
that transportation from initial collection point
to the centralized collection center is minimum.
3. Method to obtain component information most
efficient and timely from the returned product
to determine for its quantity and quality.
4 MODEL DESIGN
4.1 Framework of Reverse Logistics
Reverse logistics is the management of material flow
opposite to the conventional supply chain flow
(Fleischmann et al., 1997). It encompasses logistic
activities to transform used products from end users
back to usable products again.
Reverse logistics management involves 3 main
stages:
1. Distribution planning aspects – This stage
involves physical transportation of used
products from end users back to the producers.
2. Transformation – The recovery of returned
product back to usable product. There are
several ways of transformation including:
Direct reuse, Repair, Recycling and
Remanufacturing.
3. Inventory Management – This is to manage
inventory level and to integrate supply flow
from both the traditional supply chain and also
from reverse logistics (Fleischmann et al.,
1997).
Dimensions of Reverse Logistics. There are
many instances of reuse criteria. These can be
classified as motivational, items recovered, forms of
reuse and the actors that are involved in the process.
Reuse motivation can be due to economical and also
ecological. In terms of economical, usually
machinery parts can be reused with slight repairs
and this saves cost as compared to manufacturing a
new part. As for ecological concerns, companies are
increasingly being pressured to take back all their
sales materials for recycling purposes in order to be
eco-friendly.
As for different types of materials recovered, the
forms of reuse may vary as well. The different forms
of reuse includes:
• Direct Reuse. Returned materials can be
reused directly without major repairs except for
cleaning. Examples of such products are bottles
and containers.
• Repair. This process is to restore failed
products into working order. However, the
performance of the repaired product might be
reduced.
• Recycling. This process recovers material
without conserving any of the initial product
structure. Commonly recycled items are scraps,
paper and glass.
• Remanufacturing. This process differs from
recycling in that the recovered product retains
its original characteristics. Examples are
automotive engines and machines.
Finally, there are also different actors involved in
reverse logistics. Actors play different parts in the
reverse logistics process such as collection, testing
and product recovery. Due to the different actors
involved in reverse logistics, integrating reverse and
forward logistics pose a major challenge.
As stated in the problem definition section, there
are many challenges in designing an optimum
reverse logistics management system and integrating
forward and reverse logistics. Most of the problems
arose mainly due to uncertainties in the reverse flow
of materials both in terms of quantity and quality
and also the timeliness of the information gathered.
Below, we propose a model that integrates RFID
technology into the reverse logistics framework to
eliminate the uncertainties involved in the process.
Furthermore, we will also employ genetic algorithm
optimization technique to determine the optimum
location for the initial collection point so as to
maximize user coverage and reduce logistics cost
involved in the process.
DESIGN A REVERSE LOGISTICS INFORMATION SYSTEM WITH RFID
295
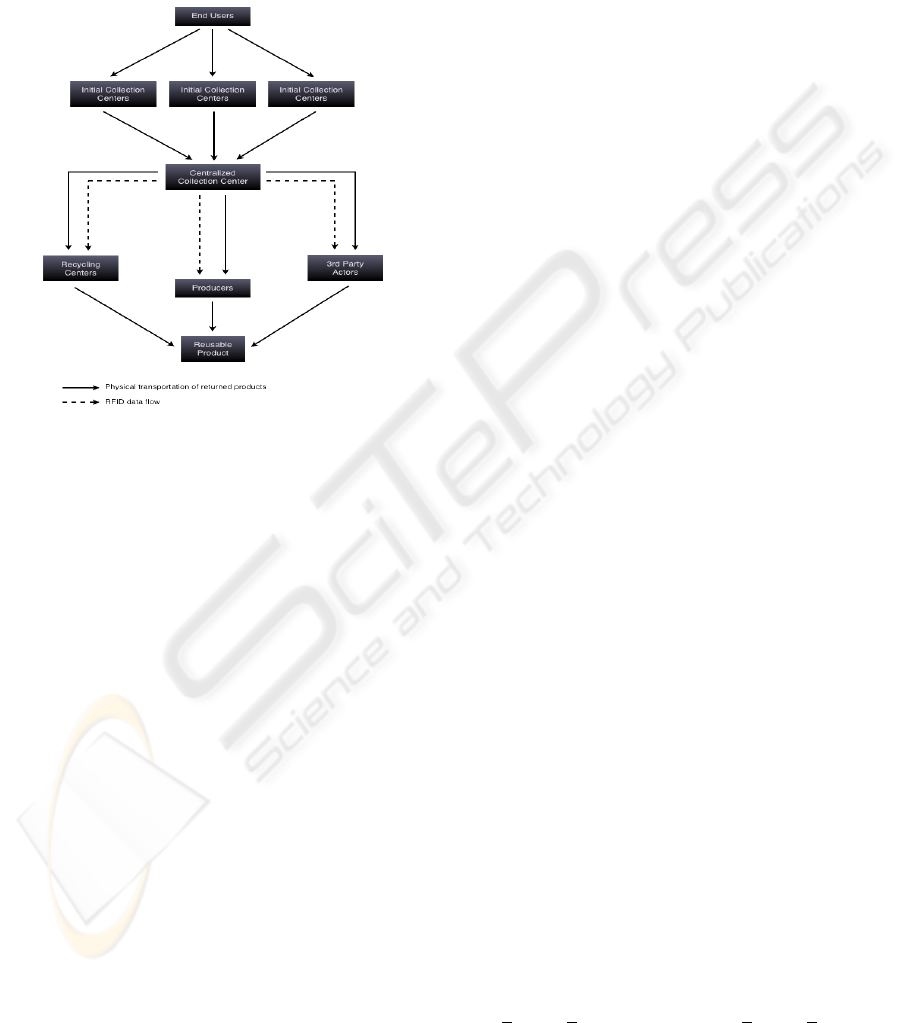
4.2 The Reverse Logistics Model
The physical flow and RFID data flow for reverse
logistics process are shown in Figure 1. The main
elements in reverse logistics includes end user,
intial collection points, centralzied collection center
and produccer.
Figure 1: Flow chart of reverse logistics process.
4.2.1 End Users
End users are customers of the company who wishes
to dispose off of their old products or are returning
their products due to defects. End users would
demand for convenience and accessibility. Hence,
the initial collection points have to be loacated
within short travelling distance to the customers.
4.2.2 Initial Collection Points
In order to determine the placement of the initial
collection points, we shall employ the genetic
algorithm optimization technique. The locations and
density of population in an area are recorded and
amount of initial collection center is determined.
Using the genetic algorithm program, the optimum
location to employ the initial collection center is
determined.
Genetic Algorithm. Genetic algorithm is one of
many population-based optimization techniques.
Population-based technique induces a pattern whose
present state depends on the past states; hence
incorporate implicit memory structure (Min et al.,
2003). Genetic algorithm is based on the theory of
evolution whereby an initial population is generated,
subsequently the population space are evaluated
against a pre-defined function to remove inferior
solutions. After that, mutation of strings will then
occur and this process repeats until the optimum
solution is found.
The Working Mechanism of Genetic Algorithm.
Genetic algorithm technique starts with
initialization. The close (0) or open (1) of collection
point(cp) is encoded in the chromosome For
instance:
cp
1
cp
2
… …cp
n
1 0 1 1 1 0 0 0 1
After the initialization phase, the chromosomes in
the solution space will be evaluated with reference
to a pre-defined objective function. The
chromosome with a higher score will be chosen to
form an intermediate solution space. This is called
the selection process.
For our reverse logistics determination of collection
point, an example of the objective function would be
as below:
Minimize
)XXX(
iiiii
n
1i
i
⋅+⋅+⋅
∑
=
hps
FC: Fixed cost per unit of initial collection point
n: Number of initial collection points
VC: Variable cost of initial collection point
LC: Logistic cost per unit of returned product
OC: Other costs
After roulette wheel mate selection, one point
crossover process (crossover rate 0.8) takes place.
The crossover process selects a string randomly in
the intermediate solution space and modifies its gens
value randomly. This is to ensure that all possible
solutions are explored and also to avoid the solution
space from converging to a local maxima or minima.
Example of how the mutation operator works:
parents offspring
1 1 --- 1 0 0 0 1 1 1 --- 1 10 0 0
0 0 --- 1 10 0 0 0 0 --- 1 0 0 0 1
Exchange site
After the crossover operation, 2 new chromosomes
will be formed and this will ensure diversity in the
solution phase. Next step is mutation operation with
mutation rate as 0.01. Unlike crossover operation,
mutation involves only 1 gene. The operator
randomly selects gens and assigns random value to it
as shown below:
Before After
1 1
1 0 1 0 1 0 1 0 1 0 1 1 1 0
The random gene alteration process also works to
ensure that diversity in the solution set is maintained
ICEIS 2009 - International Conference on Enterprise Information Systems
296
and that the solution do not converge pre-maturely
to a local maxima or minima.
Finally is the replacement process. After the
mutation has taken place, the chromosomes are then
evaluated again against the objective function.
Chromosomes with higher scores will then be
chosen into the next round of mutation process while
the chromosomes with lower scores are discarded.
Through these processes, the solution space will
converge to the most optimum solution desired.
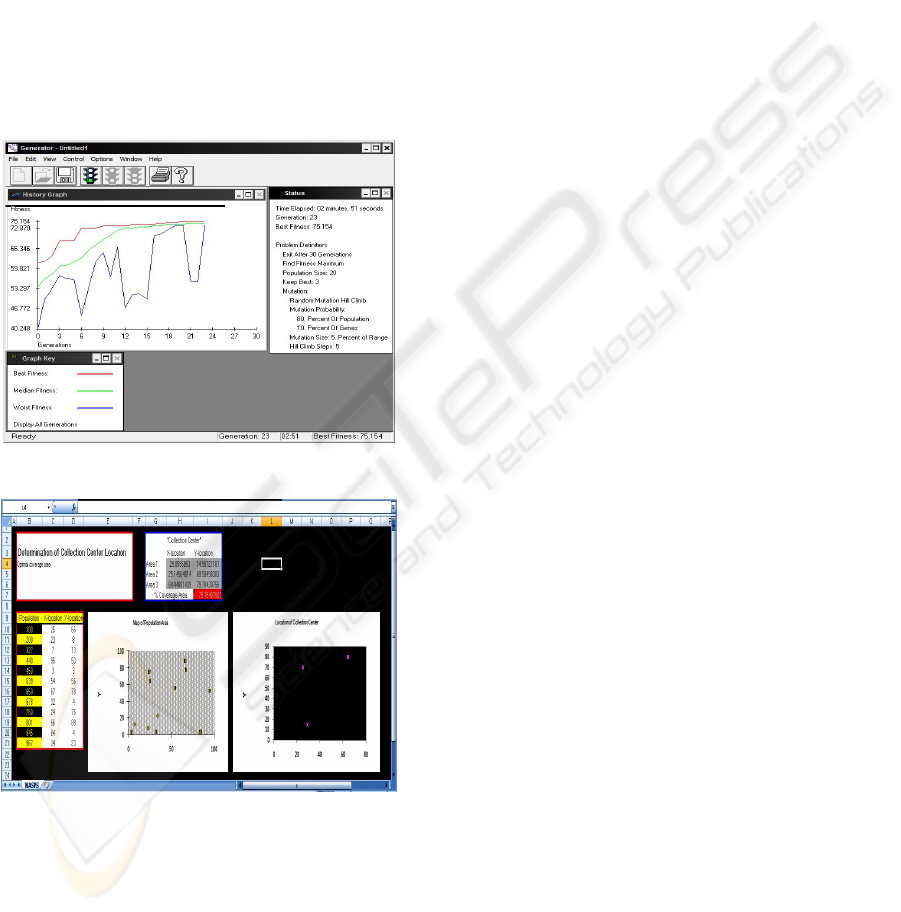
Design Framework. As shown in Figure 2 and 3,
using the genetic algorithm generator program, we
could determine the location of initial collection
point to achieve the best possible population
coverage.
Figure 2: Genetic Algoritm Generator.
Figure 3: Determination of initial collection point location.
However, this method of optimization is based on an
ideal case scenario. The program does not take into
account factors such as accessibility and
convenience to the end users. Therefore, the model
above is merely an indication of the approximate
location. Even so, we could still employ the
knowledge acquired above to be applied when
making a final decision on the placement of the
collection center.
Furthermore, a collection schedule will have to
be planned for regular pick-up at the initial
collection center back to the centralized collection
center. Due to the limited space available at the
initial collection centers, pick-up schedule has to be
regular and frequent. Planning of the pick-up
schedule is not covered in this paper.
4.2.3 Centralized Collection Center
The centralized collection center is a place where all
the return products will be sent to from the initial
collection center. This is where the returned
products will be sorted, stored and distributed to
undergo their respective process. Hence, the
centralized collection center is where the workflow
begins and is where we shall employ RFID
technology to optimize the efficiency.
Radio Frequency Identification (RFID) for
Reverse Logistics. Radio Frequency Identification
or RFID has moved from upcoming technology to
mainstream application in recent years. RFID is
currently been used to replace the tradition bar-code
system as it can read data without the need of being
in line-of-sight and the RFID tags can store much
more data than bar codes. Among the earliest
adopters of RFID includes Wal-Mart, Tesco and the
US Department of Defence (Want., 2007). However,
most of the usage of RFID at them moment is
mainly focused on the forwards logistics. In this
paper, we will integrate RFID technology into the
reverse logistics system to overcome problems faced
in the system.
RFID Working Principles. The very fundamental
working of RFID technology is based on
electromagnetic wave (EM). There are 2 different
types of RFID designs, mainly: Near field RFID and
Far field RFID. Near field RFID operates based on
Faraday’s principle of magnetic induction. This
system uses EM waves to power the RFID tag and
the tag transmits data back to the reader through load
modulation. Range of operation for this system
varies inversely with the frequency of operation
while energy from induction reduces with distance.
Far field RFID on the other hand captures the EM
wave propagated from the reader and reflects back
the EM wave through the embedded antenna on the
tag. This method of operation is known as back
scattering. The reader will then receive the reflected
wave pattern and interprets the data. Operational
range for this system is limited by the amount of
energy received by the tag from the reader.
DESIGN A REVERSE LOGISTICS INFORMATION SYSTEM WITH RFID
297

Types of RFID Tags. There are 2 types of RFID
tags: active and passive. Active RFID tags require
power source to operate. This power source can be
either from a power infrastructure or an integrated
battery. Since the tags require external power source,
they have limited lifespan. On the other hand,
passive tags receive power from the RFID reader.
Hence they are only activated upon being read by
the reader and have unlimited lifespan. Furthermore,
RFID tags shown in Figure 4 come in different
shape and sizes for different usage purposes. There
are also different types of tags for use on different
material surfaces.
Figure 4:Different shape and sizes of RFID Tags (Want.,
2007).
Advantages of RFID for Reverse Logistics. RFID
technology provides numerous advantages for the
proposed model in reverse logistics processes.
Among the advantages are:
• No line-of-sight needed. This enables data to
be read from the tag in returned products at any
orientation and hidden away from sight.
• Long-range reading is also possible with RFID.
This enables the reader to be at a distance away
from the tag while still being able to read the
tag. This is an added advantage for logistics
purposes.
• Multiple tag reading is also supported by
RFID. As compared to bar-code system, which
can only read 1 bar code at any one time, RFID
can read multiple tags at the same time. This
will enable the returned flow of products be
read at once when passing through the RFID
readers.
• RFID technology also allows for real time
tracking. When the returned product is in range
of the RFID reader, it will be read immediately
without human intervention. The data read by
the reader can subsequently be sent to the
respective actors involved in the reverse
logistics process.
RFID Constraints in Reverse Logistics. Even
though RFID provides a huge amount of advantages
over traditional system, it is not without its own
disadvantages. Chief among them are:
• Orientation of tags relative to the reader.
Although RFID tags do not require line-of-
sight for reading, however under certain
orientations, RFID tags can be hard to read.
This will pose a problem as the returned
products would be oriented randomly and this
could prevent the reader from reading the tags
effectively.
• Signal blockage. If the returned product is
made of metal casing, the RFID tag could be
enclosed in the casing causing EM wave to be
unable to penetrate the metal case and hence
will not be able to be read. This constraint is
particularly pronounced when tagging
components that are enclosed in a casing such
as computers, television sets and others.
• Cost. At the time being, the cost of RFID
hardware is still high. Moreover, reverse
logistics is usually seen as a cost center for
most companies and are not revenue
generating. Hence, companies are reluctant to
invest huge amount of money in this
technology. However, this cost is dropping as
the system gets more commercialized and more
companies adopt the technology.
• Privacy. Privacy is also a concern for end
users, as they fear that companies can still track
the products after consumers have purchased it.
However, certain measures have been taken to
address this issue.
In this paper, we have worked within the limitations
imposed by RFID technology to implement RFID to
design a better reverse logistics management system.
At the centralized collection center, RFID system
can be set up at the point of entry to scan each and
every collected product that has been tagged. An
important assumption made in this research is that
tagging is done at the forward logistics process and
is carried down to the reverse logistics process. The
RFID reader can read every tag passing through the
entry point and the system will relay this
information to the control centre.
With this data acquired through the RFID reader,
we are able to tell the quantity and type of product
returned in real time and without much human
intervention. This solves part of the unknowns in the
reverse logistics process. With the data acquired,
different products can be sorted according to their
respective category and this reduces time wastage in
between handling.
ICEIS 2009 - International Conference on Enterprise Information Systems
298

4.2.4 Producers
Fianally, the loop ends at the producer of products
who receive the returned flow of material and
convert it back to usable products to be sold back to
the end users. This cycle will repeat and make up the
reverse logistics process.
4.3 Case Example
As a summary of the whole process, a company (eg.
Apple Computers) can employ RFID technology to
tag all of their products during manufacturing. This
RFID tag will be used during the forward logistics to
replace bar-code technology. The tag will remain
with the product until the consumer decide to
dispose off of the product. Hence, the consumer will
return the product to the initial collection center
situated at various location throughout the area. A
routine collection schedule will ensure that returned
products are collected regularly from the initial
collection center back to the centralized collection
center. Once back in the center, the RFID reader
situated at the entrance will read the tags on the
returned product and disseminate the data to the
control center. This data will then be used to activate
the various work flow associated with each and
every returned product. Finally, the returned product
can be recycled and sent back to the original
producer to be made into new products and
distributed again.
5 CONCLUSIONS
In this paper, we formulated a model that integrates
Radio Frequency Identification (RFID) into reverse
logistics management in order to eliminate part of
the unknowns in the process. By doing this, we are
able to better plan and optimize the reverse logistics
network. Furthermore, we also utilized genetic
algorithm optimization technique to determine the
optimum location of initial collection points. This
will enable us to further reduce logistical cost
involved in reverse logistics. However, further study
about model evaluation with real-time data should
be done and comparing GA with other optimization
techniques can be carried out to show the
effectiveness of GA. We believe this paper could be
a reference point for further research to be
performed upon.
ACKNOWLEDGEMENTS
We wish to acknowledge the funding support for
this project from Nanyang Technological University
under the Undergraduate Research Experience on
Campus (URECA) programme.
REFERENCES
ReturnBuy. The new dynamics of returns: the profit,
customer and business intelligence opportunities in
returns. Ashburn, Virginia; White Paper; 2000,
ReturnBuy.com.
M. Fleischmann, J.M. Bloemhof-Ruwaard, R. Dekker, E.
V. D. Laan, Jo A.E.E. van Nunen, L. H. Van
Wassenhove, “Quantitative models for reverse
logistics: A review”, European Journal of Operational
Research 103, 1997, pp. 1-17.
R. Want, “An introduction to RFID technology”,
Pervasive Computing, January-March 2006, pp 25-33.
V. D. Hunt, A.Puglia, M. Puglia, RFID: A Guide to Radio
Frequency Identification. Wiley-Interscience, 2007.
H. Min, H. J. Ko, C. S. Ko, “A genetic algorithm apporach
to developing the multi-echelon reverse logistics
network for product returns”, Omega: The
International Journal of Management Science, vol 34,
2003, pp. 56-69.
DESIGN A REVERSE LOGISTICS INFORMATION SYSTEM WITH RFID
299
