
REVERSE MARKET SEGMENTATION WITH PERSONAS
Harri Ketamo
Satakunta University of Applied Sciences, Pori, Finland
Kristian Kiili
Tampere University of Technology, Pori unit, Pori, Finland
Jarkko Alajääski
University of Turku, Department of Teacher Education, Rauma, Finland
Keywords: User Experiences, Digital Learning Materials, Market Segmenting, Adaptive Systems.
Abstract: In this study the user experiences of commercial educational product were gathered in order to build the
personas that can be used to revising the market segmentation. Personas are empirically formed archetypical
characters representing distinct behavioural clusters, goals and the motivation of end users. Usually
personas are used in different production phases as tools that help designers and marketing people in
decision making. In this study, the personas were formed by applying k-means cluster analysis into
quantified user interviews. According to the results of the study, qualitatively formed personas showed their
strengths as decision making tools: They helped publisher to maintain the focus on a learner's needs, wants
and requirements during the whole process of development.
1 INTRODUCTION
According to Cooper (1999) personas are
empirically formed archetypical characters
representing distinct behavioural clusters, goals and
the motivation of end users. Usually personas are
used in different production phases as tools that help
developers, producer and publishers to make
reasonable and empirically based design decisions
(e.g. Cooper, Reimann & Cronin 2007).
In practice, personas and market segmentation
has been seen as complementary methods (e.g.
Kujala & Kauppinen 2004; Grudin & Pruitt 2002).
Traditional market segmentation can help the
designers to build commercially more effective
personas for product development.
However, in this study, the real user experiences
were used to build the personas that can be used
when revising the market segmentation. In other
words, the “from segments to personas” -process is
reversed to “from experiences to personas to
segments”
The reason, why the reversed market
segmentation is used relays to the complexity of
adaptive/personalized content. The idea of adaptive
educational systems is to produce individual and
optimized learning experiences (Eklund &
Brusilovsky 1999; Brusilovsky 2001) and the high
end user models that are relatively complex. In terms
of complexity, a definition for a complete adaptive
system can be based on the capability of self-
organization.
The persona approach provides a sound design
framework for complex adaptive learning materials.
One of the main benefits of using personas is that it
helps to eliminate the problem of the "elastic
learner". An elastic learner stretches and adapts
during the design process, allowing designers to
implement almost anything. However, real learners
are not elastic. Thus, the persona method aims to
design of learning materials that will stretch and
adapt to the learner's needs - not the other way
around. Such an approach is the key to effective
learning experience.
63
Ketamo H., Kiili K. and AlajÃd’Ãd’ski J.
REVERSE MARKET SEGMENTATION WITH PERSONAS.
DOI: 10.5220/0002781300630068
In Proceedings of the 6th International Conference on Web Information Systems and Technology (WEBIST 2010), page
ISBN: 978-989-674-025-2
Copyright
c
2010 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2 RESEARCH TASK AND
METHODS
2.1 Research Tasks
This study focuses on the 1) evaluation of the
product and 2) finding most suitable customers
(segments) for Mathematics Navigator. The
collected data includes qualitative and quantitative
variables. In this study the focus is on qualitative
data. Quantitative data, such as test scores and
improvement measures in learning results are used
to support the decision making.
In this study, user prototypes are formed
empirically according to qualitatively measured user
experience. The research tasks are:
1. To form personas from the user experiences
gathered with interviews.
2. To find most suitable market segment for
Mathematics Navigator.
3. To evaluate the usefulness of the persona -
method.
The sample (n=74) consists of first year class
teacher students at the University of Turku,
Department of Teacher Education in Rauma. All of
the participants had an upper secondary school
degree on mathematics – Basically all of the
mathematics related to this study is based on upper
secondary school mathematics curriculum.
2.2 Materials
Mathematics Navigator is a product family
published by Otava Publishing Company Ltd.
Mathematics Navigator is designed to operate as a
personal tutor and guide in the studies. It supports
the development of a student's mathematical skills
and abilities and helps the student in recognizing
his/her mathematical strengths and weaknesses.
Mathematics Navigator gathers information on
the student's actions while studying. On the basis of
these, Mathematics Navigator adjusts the set of
exercises and/or content presented to the student in
order to optimally support his/her development.
Thus, the learning paths are formed individually.
Furthermore, the student is able to follow the
development of his/her competence profile.
The user interface of Mathematics Navigator
consists of a menu-bar and three main areas (Figure
1). At the left side of the interface is the table of
contents that have two different views of the
content: 1) The traditional book-like table of
contents and 2) an exercise adapted table of
contents.
Figure 1: User interface of Mathematics Navigator and the
basic mathematics course (in Finnish).
The exercises are presented in the right-bottom
corner of the user interface one at a time. The
exercises can't be neglected, changed or left behind
without giving an answer. The learning profile is
always (real-time) adjusted on basis of the answer to
the current exercise. The exercises are selected to
support the individual user's needs. There are no
fixed paths through the topics: the path is based on
the student's learning profile and by Mathematics
Navigator estimated need for exercises and contents.
The guiding factors in the exercise selection are: 1)
The course structure (the traditional table of
contents). 2) Student’s learning abilities and areas of
weaknesses measured and estimated by Mathematics
Navigator during the studying process. 3) Critical
points, derived from the learning community's
actions, derived from generalized success patterns in
answering the exercises.
The competence profile values are indicated with
colours that vary from red (insufficient skills or not
yet estimated skills) to green (good skills). Those
skills mastered and measured within a certain theme
will be transferred with certain estimates to other
themes requiring similar (by proximity or by
hierarchy) skills.
2.3 Measures and Analyses
In the beginning of the experimental period, a pre-
test, and at the end of it, a post-test, were arranged
for measuring the educational effect of the
Mathematics Navigator. The tests were based on the
Finnish lower secondary school and partly upper
secondary school mathematics curricula. After the
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
64
post-test feedback was gathered through the
following two open questions (originally in Finnish):
1. What kind of good or positive experiences
did you have during your work with
Mathematics Navigator?
2. What kind of development needs or negative
experiences did you encounter during your
work with Mathematics Navigator?
At first, feedback was analyzed with a quantitative
method – a thematic analysis was conducted. The
thematic analysis started with forming main themes.
The themes were formed as archetypes of enough
similar comments. The themes were reviewed by
two independent professional learning material
producers. One has a background in social sciences
and the other has a background in natural sciences.
Finally 16 themes were determined. Several themes
could occur in one feedback. The number of times a
theme was emphasized was not calculated. The
theme either exists in the feedback or then there was
no such theme in the feedback. The number of
different themes in a single feedback varied from
zero to eight themes per feedback.
The quantification of the qualitative data was
done as a binary data matrix, where each test person
was represented by a case (as done traditionally).
Each theme was represented by a variable, the value
of which is either 1 or 0. The variable got a value of
1 only if the theme that variable described was
expressed in the feedback. In the other case, the
value of the variable was 0. The quantified data was
extended by the results from the pre- and post test.
In this study, k-means clustering was used to
build the personas according to the quantified binary
data. Thus, k-means clustering was designed to work
with continuous variables. It is note worthy that k-
means clustering has been successfully used with
binary data (e.g. Postaire, Zhang & Lecocq-Botte
1993; Ordonez 2003). The differences between
continuous and binary data should be taken into
account while analyzing the results. Finch (2005)
has shown that there are small differences between
different proximity calculation methods with k-
means. In this study, k-means cluster analysis was
used to maximize the distances between clusters. In
this approach, the proximity calculations are not as
crucial as compared to cases where we are aiming to
form tight clusters and extract all the outliers.
In this paper, the clustering result is discussed
along with literature on behavioural theories in order
to ensure the validity of clustering. Secondly, we use
clustering to characterize the personas, the clustering
result is not in and of itself a result alone - it is a
starting point for building personas.
3 RESULTS
3.1 Thematic Analysis
The written feedback was classified into thematic
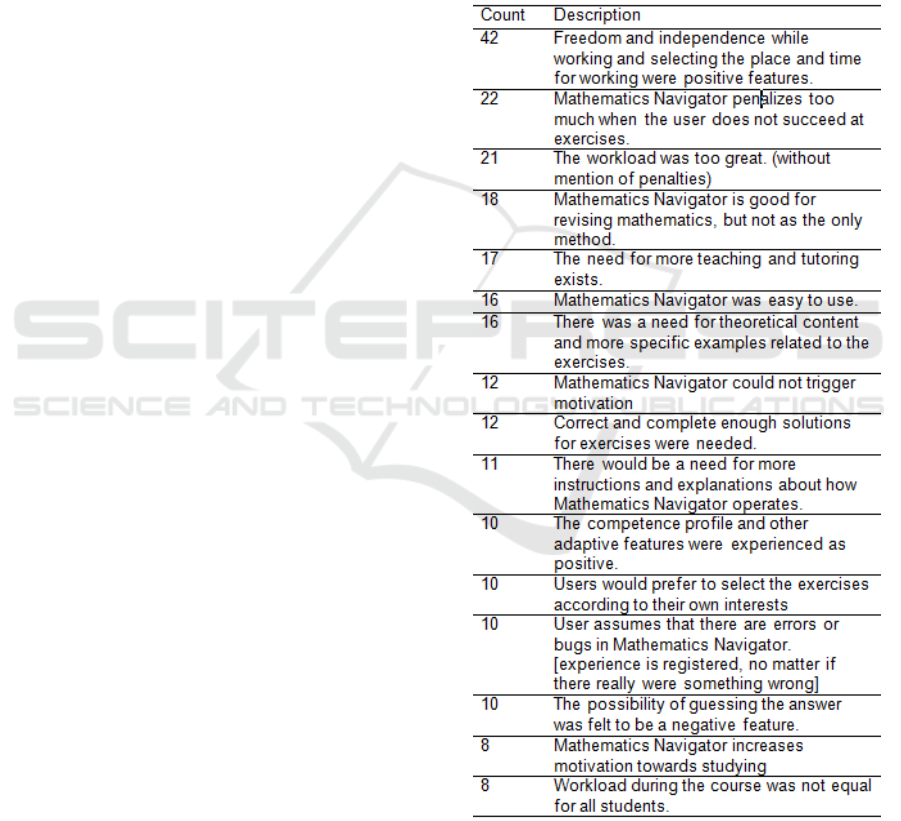
categories in three iteration phases (table 1).
Table 1: Theme frequencies and descriptions.
In the first phase all the different expressions were
extracted. In the second phase, the expressions were
integrated into 14 themes. In the third iteration
phase, the themes were reviewed by two external
people (not the authors) who are professional
REVERSE MARKET SEGMENTATION WITH PERSONAS
65
learning material producers. One has a background
in social sciences and the other has a background in
natural sciences. During this review, two themes
were divided into four themes and finally there were
16 themes with relatively unambiguous definitions
(table 1).
Most of the feedback expressions contained
several themes. The number of different themes in a
single feedback varies from zero to eight themes per
feedback. The number of times a theme was
emphasized was not calculated. The theme either
exists in the feedback or then there is no such theme
in the feedback.
3.2 Clusters based on Thematic
Analysis
Quantifying the qualitative data is described in
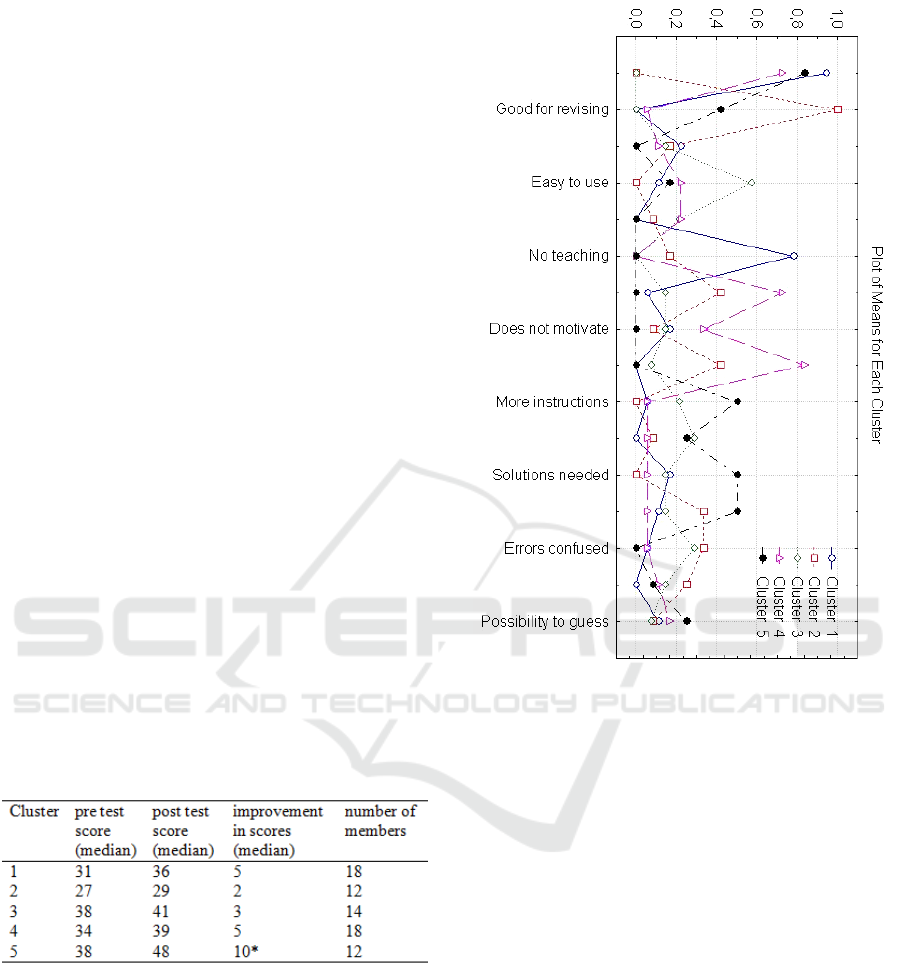
method -section. The visualization of k-means
clustering is shown in figure 2. In the clustering, the
distances between clusters were maximized in order
to build personas that 1) form a proximate group and
2) are as different as possible to other clusters in
order to support further development design.
The clusters are interesting when comparing the
learning achievements and skills between the
clusters. Generally, the average improvement in test
scores was 5 points (median, when N=74), which
achieves a statistically significant difference (t=-
2,054, df=146, p=0,042). When focusing on learning
achievements by clusters, there was only one group
with a statistically significant improvement.
Table 2: Learning outcome for each cluster.
In Table 2 the learning outcome (improvement in
test score) and skills (test score) measured in pre-
and post-test are shown. According to the results,
only members in cluster 5 have had a statistically
significant improvement (t=-2,082, df=22, p=0,049)
in test scores.
Figure 2: Plot of means for clusters received from
quantified feedback data.
Next we build qualitative descriptions of the
personas according to the classification of features
of the clusters. For this we determine the major
feature, which is represented by the theme that is
mentioned by more than 60% of the cluster
members. A minor feature is represented by the
theme that is mentioned by more than 40% of the
cluster members, but less than 60% of the cluster
members.
According to these limits, we can build the
following personas and their descriptions (Table 3).
The personas (each cluster) were given a name in
order to highlight their definitions as user
archetypes. Short descriptions of the personas are
following:
Matti (representing cluster 1) values freedom and
independence in digital learning systems. However,
he still wants clear teaching and tutoring features.
Teaching and tutoring make him feel more confident
due to his average skills in mathematics.
Kirsi (representing cluster 2) prefers traditional
classroom teaching. She thinks that digital learning
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
66

materials are good for revising, but are not adequate
as the only method. She does not like learning
systems that penalize too much for mistakes made,
but she values positive encouragement. Kirsi does
not like to work much for success that usually leaves
the learning outcome poor.
Table 3: Personas and their descriptions.
Aapo (representing cluster 3) is relatively good at
mathematics. He masters the use of digital products
quite well and easily masters the use of new
systems. Aapo values challenges that motivate him.
Non-challenging tasks do not engage Aapo.
Eero (representing cluster 4) is a student that
wants everything to be easy. He values freedom and
independence in studying, but does not like to work
much for success. Eero does not like learning
systems that penalize too much for mistakes made,
but values positive encouragement.
Anna (representing cluster 5) values freedom and
independence in digital learning systems. She needs
a lot of theoretical content and specific examples of
exercises. Furthermore, she needs extensive, clear
instructions and explanations about how learning
systems operate. She also values complete and
correct solutions for exercises. Although, Anna's
mathematic skills are relatively good, working with
good digital learning materials encourages her to
reach an even higher skill level.
3.3 Analysis about Personas
The formed personas are classified as primary,
secondary and tertiary personas in accordance with
their importance to define the potential customers.
Anna (5) is selected as a primary persona
because of her good learning outcome and
constructive design ideas. Also Matti (1) is classified
as a primary persona. Anna and Matti will also be
the main sources, when further developing
Mathematics Navigator. By accepting all three needs
for further development suggested by persona 5, we
can also support persona 1's suggestion for more
teaching and tutoring: Adding detailed solutions to
exercises with more detailed content can be expected
to help persona 1 in some way. Because of his lower
skills at the beginning, we cannot be sure if this is
enough.
Kirsi (2) is selected as a secondary persona: By
developing instructions as suggested by Anna, we
can also deliver ideas on how Mathematics
Navigator can be used during classroom teaching in
a pedagogically meaningful way. However, several
pedagogical tests without a scientific context have
been done in classrooms by teachers. We can
produce directions about good practices in
classrooms after we have collected feedback from
those teachers.
Aapo (3) and Eero (4) are classified as tertiary
personas. Aapo has relatively good skills with
relation to the objectives of the learning material.
We can hope that he learned something that we have
not measured. Aapo's positive feedback about
Mathematics Navigator allows us to determine that
there was nothing critical in Mathematics Navigator.
However, when developing Mathematics
Navigator we have to ensure that the user interface
remains as easy to use as it is now. Eero has a
negative attitude against learning, self-studying in
particular. Learning is not always easy. It can
certainly be fun, but according to previous studies, a
good learning outcome requires work. It would be a
crucial mistake to make Mathematics Navigator
easier or more abbreviated. Hopefully more
informative directions will help this persona to better
understand the nature of self-studying and learning.
Kirsi's and Eero's concern about the competence
profiling system being too penalizing is valuable
from a motivational point of view. In order to
engage and motivate users, the profiling system will
REVERSE MARKET SEGMENTATION WITH PERSONAS
67

be fixed. In the future, the exercise selection will be
based on a real competence profile, while the visible
competence profile will be designed to be more
humane: it will not immediately penalize for one
mistake.
4 CONCLUSIONS
Personas are powerful design tools if they are used
correctly. They help designers, producers and
publishers to maintain focus on a learner's needs,
wants and requirements during the whole
development process. Furthermore, personas enable
the whole production team to achieve a shared
understanding of the requirements and the context
within the learning taking place. Production team
can make decisions based on user archetypes rather
than basing the decisions on their own intuition or
personal likes.
In this study personas were constructed in order
to ground publishing decisions of Mathematics
Navigator. Qualitative user feedback was analyzed
thematically at first. Secondly the users were bound
to a certain clusters according to the proximity of
their feedback. Finally strict clusters with
meaningful common nominators were named as
personas. Personas in this study are based on the
mathematical modelling of quantified user
experiences and therefore they are highly valid
archetypes of the tested population. If the archetypes
had been formed only according to thematically
analyzed feedback, the outcome of the study would
have been different.
Furthermore, several decisions about further
development have been made according to results of
this study: 1) The quality and quantity of feedback
from Mathematics Navigator to the learner will be
improved. Complete solutions to exercises will be
added. Also, tools for accessing completed exercises
and solutions will be designed. 2) General
instructions will be rewritten in accordance with the
feedback. However, this could have been done
without the personas -method, but the importance of
the task would have not been so clear to the
developers. 3) The competence profile that was
experienced as being too penalizing will be fixed.
Exercise selection will be based on a real
competence profile, while the visible competence
profile will be designed to be more humane: it will
not penalize immediately for one mistake.
During this study a new research challenge
emerged: Is it possible to construct artificial test
users according to personas? According to this idea
artificial users represent archetypes of human users
with a certain variance in behaviour. In other words,
the artificial users are computational representations
of personas: They will be constructed according to
the behaviour of real users in digital environments
by analyzing the behaviour as quantitative
phenomena and designing a representation of a
system, corresponding to the behaviour. Such a
system can be implemented as a software agent. As
a test person, a software agent can communicate
with the educational systems by e.g. Web Services
interfaces. An interesting question is related to the
behaviour of the artificial user: Is its general level
comparable to the behaviour of human users?
REFERENCES
Brusilovsky, P. (2001) Adaptive Hypermedia. User
Modeling and User-Adapted Interaction. 2001 vol 11,
pp. 87-110.
Cooper, A. (1999). The inmates are running the asylum.
New York: Macmillan.
Cooper, A., Reimann, R. & Cronin, D. (2007). About Face
3: The Essentials of Interaction Design. Indianapolis,
Indiana: Wiley Publishing Inc.
Eklund, J. & Brusilovsky, P. (1999). InterBook: an
Adaptive Tutoring System. UniServe Science News;
1999 vol 12.
Finch, H. (2005). Comparison of Distance Measures in
Cluster Analysis with Dichotomous Data. Journal of
Data Science, vol 3(1), pp. 85-100.
Grudin, J. & Pruitt J. (2002). Personas, participatory
design and product development: an infrastructure for
engagement. In Proceedings of the 7th biennial
particpatory design conference, Malmö, Sweden, June
2002, pp. 144-161.
Kujala, S. & Kauppinen, M. (2004). Identifying and
Selecting Users for User-Centered Design. In
Proceedings of the third Nordic conference on Human-
computer interaction, October 2004. Tampere,
Finland, pp. 297-303.
Ordonez, C. (2003) Clustering Binary Data Streams with
K-means. In Association for Computing Machinery
(ACM) Special Interest Group: Management of Data
(SIGMOD) Workshop on Research Issues on Data
Mining and Knowledge Discovery (DMKD), pp. 10-
17.
Postaire, J.G., Zhang, R.D. & Lecocq-Botte, C. (1993).
Cluster Analysis by Binary Morphology. IEEE
Transactions on Pattern Analysis and Machine
Intelligence, vol. 15(2), pp. 170-180.
WEBIST 2010 - 6th International Conference on Web Information Systems and Technologies
68
