
AUTOMATIC FEEDBACK SYSTEM FOR COLLABORATIVE
LEARNING USING CHATS AND FORUMS
Traian Rebedea, Stefan Trausan-Matu and Costin Chiru
“Politehnica” University of Bucharest, Department of Computer Science and Engineering
313 Splaiul Independetei, Bucharest, Romania
Keywords: Computer-supported collaborative learning, Automatic feedback, Discourse analysis, Natural language
processing, Chat, Forum, Dialogism, Polyphony.
Abstract: Instant messaging (chat) conversations and discussion forums have become widely used in education in the
last few years, especially in the context of Computer-Supported Collaborative Learning (CSCL), Self-
Regulated Learning and within Communities of Practice. Nevertheless, discourse in chats with multiple
participants and in discussion forums is often composed of several intertwining threads. Furthermore,
several chat environments for CSCL support and encourage the existence of parallel threads by providing
explicit referencing facilities. The paper proposes a discourse model for the analysis of such chat and forum
discussions, based on Mikhail Bakhtin’s dialogic theory. Based on this model, a system has been designed
and is currently under development. It analyzes chat conversations and discussion forums for discovering
implicit links between utterances that build into conversation threads. More important for CSCL is to
measure the involvement and collaboration of the participants that are involved in a problem solving task.
The system begins with a NLP pipe and concludes with inter-animation identification in order to generate
feedback for the learners.
1 INTRODUCTION
The analysis of a regular online chat or forum may
prove very difficult at this moment due to the
limitations of the Natural Language Procesing
(NLP) techniques, to the presence of social noise,
the large number of domains that should be
considered and other factors. However, this
approach is useful when considering chat and forum
discussions of students that are engaged in a learning
activity or of experts that are trying to solve a
particular problem. Furthrmore, the students are
usually closely monitored by their tutors or teachers.
Several studies in Computer Supported
Collaborative Learning (CSCL) (Stahl, 2006) have
showed that using web collaboration is useful for the
students, but they seldom receive any feedback from
the tutors for this kind of activities due to the
difficulty of assessing them. There are two important
reasons why conversation artifacts – such as chat
and forum discussions – that are produced by the
learners are rarely considered by tutors and teachers
for evaluation (as compared to other written texts
such as essays). The main reason is because the
human analysis of a discussion is more difficult
especially due to the existence of the inter-animating
threads. Moreover, providing quality feedback to the
learners is a time-consuming task. In order to tackle
these problems, a previous version of the system was
tested by tutors and was considered useful, reducing
the analysis time per conversation by almost 50%
(Rebedea & Trausan-Matu, 2009). These results
have encouraged us to improve the system in order
to provide feedback to both tutors and learners.
Our approach provides details on both a
theoretical framework and an analysis system for
online discussions of students. First, polyphony is
considered as a theoretical model for a particular
kind of online conversations: instant messenger
(chat) conversations with multiple participants and
discussion forums. The practical objective is to
implement a service for analyzing such online
conversations and providing feedback in order to
encourage the appearance of multiple voices and of
parallel threads of discussions. These aims may be
obtained by catalyzing debates and inter-animation,
which are premises for supporting understanding,
358
Rebedea T., Trausan-Matu S. and Chiru C. (2010).
AUTOMATIC FEEDBACK SYSTEM FOR COLLABORATIVE LEARNING USING CHATS AND FORUMS.
In Proceedings of the 2nd International Conference on Computer Supported Education, pages 358-363
DOI: 10.5220/0002860503580363
Copyright
c
SciTePress

studying and creative thinking of virtual teams of
learners or researchers.
The implemented analysis method integrates
results from Natural Language Processing (NLP) -
content and conversation analysis, Social Networks
Analysis (SNA) and a novel idea (Trausan-Matu and
Rebedea, 2009), the identification of polyphonic
threading in chats. The system was used for CSCL
in assignments for computer science students. As
preparation for these assignments, the students are
grouped into teams of 4-7 participants and each of
them has to study and to support a given topic in a
chat debate. Firstly, the learners have to read some
materials about that topic in order to understand the
subject. During the discussions, they present their
points of view, they debate and inter-animate, all of
these improving their own and the others’
understanding of the domain. After concluding a
chat session, they can launch the system which
provides graphical and textual feedback and
preliminary scores both for each student and for the
group as a whole. The tutors also use the system for
providing them a better insight of the conversation
in order to assess the results of the students and
offering them a detailed feedback.
The paper continues with a section that presents
the theoretical framework. The design of the
feedback system is detailed in the third section and
the paper ends with conclusions that offer insight in
the limitations and possible improvements of the
current approach.
2 INTER-ANIMATION IN
ONLINE CONVSERSATIONS
Several important differences arise in discourse
analysis between monologue and dialogue. While
the former uses a unidirectional form of
communication from speaker to listener (Jurafsky
and Martin, 2009), the latter is usually modelled as a
phone-like (or face-to-face) type of conversation.
Typically, speech acts, dialog acts or adjacency pairs
(Jurafsky and Martin, 2009) are the units of analysis.
Even if there are attempts to analyze conversations
with multiple participants using transacts (Dysthe,
1996, Joshi and Rosé, 2007), this approach is also
based on a two interlocutors’ model. For chats, TF-
IDF (Adams and Martell, 2008, Schmidt and Stone),
Latent Semantic Analysis – LSA (Dong, 2006), rule-
based classifiers (Kontostathis et al., 2009), Social
Network Analysis (Dong, 2006), WordNet
(wordnet.princeton.edu) (Adams and Martell, 2008,
Dong, 2006), Support Vector Machines and other
classifiers (Joshi and Rosé, 2007), plus the
TagHelper environment (Rosé et al., 2007) that is
based on the WEKA machine learning toolkit
(http://www.cs.waikato.ac.nz/ml/weka/) are have
been employed for achieving several tasks: detection
of topics and links (Adams and Martell, 2008),
dialog acts (Kontostathis et al., 2009), lexical chains
(Dong, 2006) or other complex relations like
transactivity and argumentation (Rosé et al., 2007).
In phone and face-to-face dialogs at any given
moment in time there is only a single speaker. Thus,
the discussion is usually single-threaded. However,
discussion boards and chat environments like the
one used in the Virtual Math Teams (VMT) project
(Stahl, 2009) offer referencing facilities. This
facility is extremely important in online
conversations with several participants because it
allows the existence of several discussion threads or
voices, in parallel. The co-occurrence of several
voices gives birth to inter-animation and polyphony,
phenomena identified in any text by Mikhail Bakhtin
(1993). Voices may be considered as particular
positions, which may be taken by one or more
persons when they emit an utterance, which has
explicit and implicit links and influences a part of
the other voices. Thus, each utterance is filled with
“overtones” of several previous utterances. In order
to detect these overtones, in our system we start
from explicit and implicit links and build a graph
that connects the utterances and, in some cases,
words or even phrases. In this graph, discussion
threads may be identified. Each thread may be
considered as a voice which becomes less or more
powerful than the others. The graph and the threads
are then used to compute several measures of
contribution to the conversation regarding
collaboration and inter-animation for each
participant.
3 AUTOMATIC ANALYSIS OF
CHATS AND FORUMS
The system has been designed as a web-service that
receives an input conversation and outputs data into
several web widgets that can be integrated into a
LMS platform such as Moodle or a social network
platform as Elgg. The input is a chat or forum log of
the conversation that is stored as an XML file using
a schema that was designed for encoding chat
conversations and discussion forums. A pre-
processing module is available that several chat
AUTOMATIC FEEDBACK SYSTEM FOR COLLABORATIVE LEARNING USING CHATS AND FORUMS
359

formats to a valid XML input file (e.g. Yahoo
Messenger in text format, other text format chats,
VMT html format).
The output provided by the system contains
numerical, textual and graphical feedback for the
tutors and learners, including the following:
The list of most important (used, discussed)
concepts in a chat / forum, considering semantic
similarities between the concepts;
The coverage of the important concepts specified
by the tutor;
A score for each utterance in the conversation;
A score for each participant in the conversation;
The most important utterances of each
participant (the ones with the largest scores – the
score for an utterance uses a complex formula
that takes into account the concepts used, dialog
acts, the links between utterances and SNA
factors);
Dialogue and argumentation acts identified in
each utterance / post;
Portions of the conversations with important
collaboration (argumentation, convergence and
divergence);
Social Network Analysis (SNA) scores like:
centrality degree, input and output degree
PageRank, etc.;
Graphics with the evolution of the scores of the
participants during the chat conversation;
Module for the visualization of the conversations
graph with filtering enabled;
Other indicators and statistics that are going to be
added with the development of the service /
system.
Figure 1 presents the technical architecture of the
system which consists of several layers as described
below:
1. Firstly, the data is processed by a NLP pipe
(spelling correction, stemmer, tokenizer, POS
tagger, NP chunker);
2. In the Semantic sub-layer: concepts are searched
in a linguistic ontology (e.g. Wordnet) and a list of
key concepts (or a domain ontology). In addition,
LSA may be used as alternative to ontologies. Other
technologies can also be used for computing the
semantic similarity between concepts – for example
Wikipedia-based similarity measures (Ponzetto and
Strube, 2007).
3. Advanced NLP and discourse analysis
techniques (the identification of speech acts, lexical
chains, adjacency pairs, co-references, discussion
threads, etc.) are used in order to find out
interactions among the participants;
5. Polyphony sub-layer uses the interactions and
advanced discourse structures to look for
convergence and divergence and polyphonic inter-
animation;
6. Social Network Analysis by taking into account
the social graph induced by the participants and
interactions that have been discovered.
7. Combine the results of the previous sub-layers to
offer textual and graphical feedback and a grade
proposal for each participant to a chat or forum
discussion.
Figure 2 offers an overview of the functionality
of the system and specifies the most important
communication between the modules using arrows.
The key modules are presented in more detail in the
following subsections.
Figure 1: The layered architecture of the feedback system.
3.1 The NLP Pipe and Pattern
Language for Conversations
The first step of the processing is done by a NLP:
spelling correction, stemmer, tokenizer, Named-
Entity recognizer, POS tagger and parser, NP-
chunker. The modules in the NLP pipe are mainly
those provided by the Stanford NLP software group
(http://nlp.stanford.edu/software), with the exception
of the spell checker (implemented using Jazzy, see
http://jazzy.sourceforge.net/). Two alternative NLP
pipes are under development, integrating modules
from GATE and LingPipe.
A special module, called PatternSearch was
implemented for searching occurrences that match
particular expressions a conversation. This module is
CSEDU 2010 - 2nd International Conference on Computer Supported Education
360
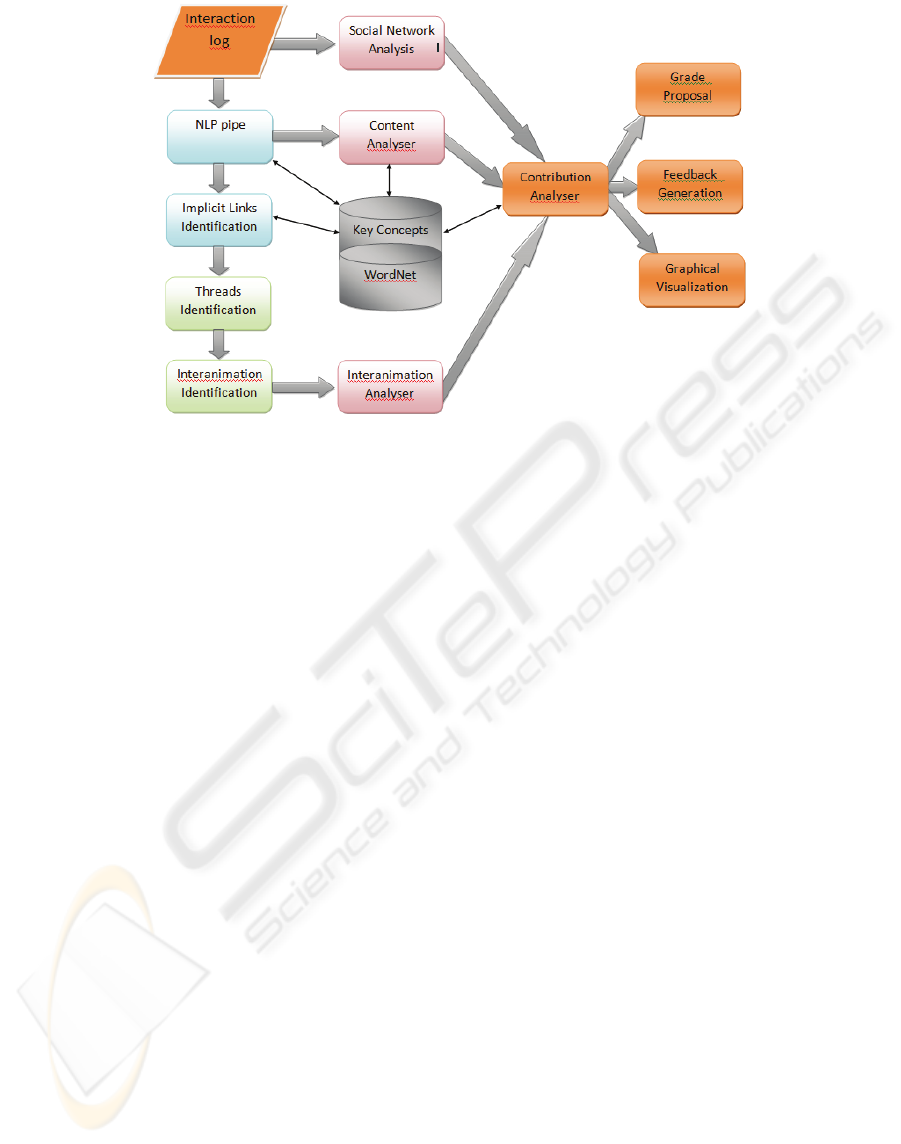
Figure 2: Main modules of the analysis and feedback system.
used for several other tasks: cue-phrases
identification, implicit links identification and
adjacency pairs identification. Furthermore, it is
used by the tutors and teachers to search for
particular patterns that are considered important.
In addition to a simple regular expression search,
the module allows considering not only words, but
also synonyms (e.g. using the pattern <S “word”>),
hypernyms and hyponyms via WordNet, words’
stems (the pattern <D “stem”>) and their part of
speech (the patterns <NN>, <NNS>, <VB>, etc.).
Another novel facility is the consideration of
utterances as a search unit, for example, specifying
that a word should be searched in the previous n
utterances and that two expressions should be in two
utterances.
For example, the expressions <S ref[10]>
implies finding the utterances that contain a
synonym to a word that appeared in the previous 10
utterances. Even more complicated expressions can
be built using variables, negation, conjunctions and
disjunctions of clauses, plus the precedence operator
#. Thus, the expression:
<S "convergence"> #[*] cube
searches pairs of utterances that have a synonym of
“convergence” in the first utterance and “cube” in
the second. One result from a particular chat is the
pair of utterances 1103 and 1107:
1103 # 1107. overlap # cube [that
would stil have to acount for the
overlap that way] # [an idea: Each cube
is assigned to 3 edges. Then add the
edges on the diagonalish face.]
The search is made at utterance level - the
program checks the utterances one by one (and if
there is a match between a part of the utterance and
the searched expression, both the utterance and the
specific text that matched are indicated).
3.2 Content-based Analysis
The content analysis identifies the main concepts of
the chat or forum using the NLP pipe, cue-phrases
and graph algorithms. It also identifies speech acts
derived from DAMSL (Allen and Core, 1997) and
argumentation types in utterances, as in Toulmin’s
theory (1958). Concepts are searched in the lexical
database Wordnet (wordnet.priceton.edu) and in a
collection of key concepts and their inter-relations
for the subject, provided by the teacher. If a domain
ontology is also provided, the system uses it to find
concepts that have a high measure of similarity.
Furthermore, advanced NLP and discourse
analysis identify various types of implicit links:
Repetitions (of ordinary words or Named
Entities);
Lexical chains, which identify relations among
the words in the same post / utterance or in
different ones, by using semantic similarity
measured based on WordNet (the semantic sub-
layer);
Adjacency pairs (Jurafsky and Martin, 2009) –
pairs of specific speech acts – answers to a single
question in a limited window of time (in which
the echo of the “voice” of the question remains),
greeting-greeting;
AUTOMATIC FEEDBACK SYSTEM FOR COLLABORATIVE LEARNING USING CHATS AND FORUMS
361

Co-references (the BART system (
Versley et al.,
2008) is used – see http://bart-coref.org/)
3.3 Words, Voices, Threads, Inter-
animation and Collaboration
In the implementation of our analysis tool, we start
from the key concepts and associated features that
have to be discussed and that are provided by the
teacher. Each participant is assigned to support a
position which corresponds to a key concept.
Implicitly, that corresponds to a voice emitting that
concept and the associated features. We may
identify other, additional voices in the conversation
by detecting recurrent themes, new concepts.
Therefore, a first, simple perspective is to have a
word-based approach on voices: We consider that a
repeated word (that is a noun, verb, adjective or
adverb) becomes a voice. The number of repetitions
and some additional factors (e.g. presence in some
specific patterns) may be used to compute the
strength of that voice (word).
Voices continue and influence each other
through explicit or implicit links. In this perspective,
voices correspond to threads. A thread may be a
reasoning or argumentation chain (Toulmin, 1958), a
chain of rhetorical schemas, chains of co-references,
lexical chains and even only chains of repeated
words. The identification of argumentation chains,
rhetorical schemas or co-references in texts and
conversations are very difficult tasks for Natural
Language Processing. Chains of repeated words,
however, are very easy to detect, the sole problem
being the elimination of irrelevant repeated words.
Lexical chains can also be detected very easy, but
their construction is more difficult and the resulted
lexical chains are greatly influenced by the choice of
the ontology and similarity measures.
The evaluation of the contributions of each
learner considers several features like the coverage
of the expected concepts, readability measures, the
degree to which they have influenced the
conversation or contributed to the inter-animation. In
terms of our polyphonic model, we evaluate to what
degree they have emitted sound and strong
utterances that influenced the following discussion,
or, in other words, to what degree the utterance
became a strong voice.
The automatic analysis considers the inter-
animation patterns in the chat. It uses several criteria
such as the presence in the chat of questions,
agreement, disagreement or explicit and implicit
referencing. In addition, the strength of a voice (of
an utterance) depends on the strength of the
utterances that refer to it. If an utterance is
referenced by other utterances that are considered
important, obviously that utterance also becomes
important.
By using this method of computing their
importance, the utterances that have started an
important conversation within the chat, as well as
those that began new topics or marked the passage
between topics, are more easily emphasized. If the
explicit relationships were always used and the
implicit ones could be correctly determined in as
high a number as possible, then this method of
calculating the contribution of a participant would be
considered (Trausan-Matu and Rebedea, 2009).
The implemented system supports the analysis of
collaboration among learners: It produces different
kinds of information about discussions in chat and
forum discussions, both quantitative and qualitative,
such as various metrics, statistics and content
analysis results such as the coverage of the key
concepts related to executing a task and the
understanding of the course topics or the inter-
threaded structure of the discussion. In addition, the
system provides feedback about the involvement of
each learner, generates a preliminary assessment and
visualizes the interactions and the social
participation. Finally, the system identifies the most
important chat utterances or forum posts (that
express different opinions, missing topics/concepts,
misleading posts, misconceptions or wrong relations
between concepts).
The results of the contribution analyzer are
annotated in the XML file of the chat or forum. The
annotations are associated to feedback provided for
utterances, for the participants or for the
conversation as a whole.
As graphical feedback, the service provides
interactive visualization and analysis of the
conversations graph with filtering enabled. The
graphical representation of chats was designed to
facilitate an analysis based on the polyphony theory
of Bakhtin and to permit the best visualization of the
conversation. For each participant in the chat, there
is a separate horizontal line in the representation and
each utterance is placed in the line corresponding to
the issuer of that utterance, taking into account its
positioning in the original chat file – using the
timeline as an horizontal. Each utterance is
represented as a rectangular node having a
horizontal length proportional with the textual length
of the utterance. The distance between two different
utterances is proportional to the time between the
utterances (Trausan-Matu and Rebedea, 2009).
CSEDU 2010 - 2nd International Conference on Computer Supported Education
362

4 CONCLUSIONS
A new theory, inspired from Bakhtin’s ideas was
proposed for explaining and evaluating collaboration
and inter-animation in chat and forum discussions.
Its main idea is the consideration of intertwining of
discussion threads similarly with counterpoint in
polyphonic music. Graphical visualization and
various metrics are computed using a wide range of
NLP and SNA techniques.
Although the first experiments with the system
showed that the polyphony model is useful for
providing feedback to the tutors to understand better
the inter-animation and collaboration processes,
further testing is necessary to determine its relevance
for the learners and whether the results it provides
influences their behaviour. Moreover, some of the
linguistic components have to be improved in order
to provide a more accurate result.
ACKNOWLEDGEMENTS
The research presented in this paper was partially
performed under the FP7 Language Technologies
for Lifelong Learning project (LTfLL -
http://www.ltfll-project.org) and the K-Teams
National CNCSIS project.
REFERENCES
Adams, P. H., Martell, C. H., 2008. Topic detection and
extraction in chat. In Proceedings of the 2008 IEEE
International Conference on Semantic Computing,
pages 581-588.
Allen, J., Core, M., 1997. Draft of DAMSL: Dialog Act
Markup in Several Layers – available online at
http://www.cs.rochester.edu/research/speech/damsl/Re
visedManual/
Bakhtin, M. M., 1993. Problems of Dostoevsky’s poetics
(Edited and translated by Caryl Emerson).
Minneapolis: University of Minnesota Press.
Dong, A., 2006. Concept formation as knowledge
accumulation: A computational linguistics study.
Artif. Intell. Eng. Des. Anal. Manuf. 20, 1 (Jan. 2006),
35-53.
Dysthe, O., 1996. The Multivoiced Classroom:
Interactions of Writing and Classroom Discourse.
Written Communication, 13.3: 385-425.
Joshi, M., Rosé, C. P., 2007. Using Transactivity in
Conversation Summarization in Educational Dialog.
In Proceedings of the SLaTE Workshop on Speech and
Language Technology in Education.
Jurafsky, D., James H. Martin, J.H., 2009. Speech and
Language Processing. An Introduction to Natural
Language Processing, Computational Linguistics,
and Speech Recognition. Second Edition, Pearson
Prentice Hall.
Kontostathis, A. , Edwards, L. , Bayzick, J., McGhee, I.,
Leatherman, A. and Moore, K., 2009. Comparison of
Rule-based to Human Analysis of Chat Logs. In 1st
International Workshop on Mining Social Media
Programme, Conferencia de la Asociación Española
para la Inteligencia Artificial CAEPIA 2009.
Ponzetto, S.P., Strube, M., 2007. An API for measuring
the relatedness of words in Wikipedia. In Proceedings
of the 45th Annual Meeting of the ACL on Interactive
Poster and Demonstration Sessions, June 25-27, 2007,
Prague, Czech Republic.
Rebedea, T., Trausan-Matu, S., 2009. Computer-assisted
evaluation of CSCL chat conversations, Proceedings
of CSCL 2009 Conference, volume 2.
Rose, C. P., Wang, Y.C., Cui, Y., Arguello, J., Stegmann,
K., Weinberger, A., Fischer, F., 2007. Analyzing
Collaborative Learning Processes Automatically:
Exploiting the Advances of Computational Linguistics
in Computer-Supported Collaborative Learning,
International Journal of Computer Supported
Collaborative Learning.
Schmidt, A.P., Stone, T.K.M.: Detection of topic change
in IRC chat logs - available online at
http://www.trevorstone.org/school/ircsegmentation.pdf
Stahl, G., 2006. Group Cognition: Computer Support for
Building Collaborative Knowledge. MIT Press.
Stahl., G. (Ed.), 2009. Studying Virtual Math Teams.
Boston, MA: Springer US.
Toulmin, S., 1958. The Uses of Arguments. Cambridge
Univ. Press.
Trausan-Matu, S., Rebedea, T., 2009. Polyphonic Inter-
Animation of Voices in VMT, in Stahl., G. (Ed.),
Studying Virtual Math Teams, Springer, 451 – 473.
Versley, Y., Ponzetto, S.P., Poesio, M., Eidelman, V.,
Jern, A., Smith, J., Yang, X., Moschitti, A., 2008.
BART: A Modular Toolkit for Coreference Resolution.
Companion Volume of the Proceedings of the 46th
Annual Meeting of the Association for
Compuatational Linguistics (ACL 2008).
AUTOMATIC FEEDBACK SYSTEM FOR COLLABORATIVE LEARNING USING CHATS AND FORUMS
363
