
AdaptIE
Using Domain Language Concept to Enable Domain Experts in Modeling of
Information Extraction Plans
Wojciech M. Barczy
˜
nski, Felix F
¨
orster, Falk Brauer
SAP AG, SAP Research CEC Dresden, Chemnitzer Str. 48, Dresden, Germany
Daniel Schuster
Technische Universit
¨
at Dresden, Dresden, Germany
Keywords:
Information extraction, Domain adaption, User interface, Process modeling.
Abstract:
Implementing domain specific Information Extraction (IE) technologies to retrieve structured information
from unstructured data is a challenging and complex task. It requires both IE expertise (e.g., in linguistics)
and domain knowledge, provided by a domain expert who is aware of, say, the text corpus specifics and entities
of interest. While the IE expert role is addressed by several approaches, less has been done in enabling domain
experts in the process of IE development. Our approach targets this issue. We provide a base platform for
collaboration of experts through IE plan modeling languages used to compose basic IE operators into complex
IE flows. We provide each of the experts with a language that is adapted to their respective expertise. IE
experts leverage a fine grained view and domain experts use a coarse grain view on execution of IE. We
use Model Driven Architecture concept to enable transition among the languages and operators provided by
an algebraicIE framework. To prove applicability of our approach we implemented an Eclipse based tool –
AdaptIE– and demonstrate it in a real world scenario for the SAP Community Network.
1 INTRODUCTION
The problem of managing unstructured text and
present the information in structured form, com-
monly known as Information Extraction (IE), is be-
coming increasingly important. The amount of
human-generated information (unstructured data) is
constantly growing and contains a lot of valuable
information, comprising Web 2.0 data as well as
enterprise-internal wikis, technical blogs, and com-
munity portals. In recent years there has been a con-
siderable amount of interest in developing IE systems,
e.g., (Reiss et al., 2008; Shen et al., 2007). Many ex-
isting frameworks are general purpose extraction sys-
tems - they use algebraic operators (similar to SQL)
or logical programming languages (based on Data-
log) to provide extraction functionality. However, us-
ing those kinds of systems imposes severe usability
challenges on domain experts. The usability of such
systems is important, because (domain) knowledge is
a key element in achieving high accuracy of IE (see,
e.g., (Sarawagi, 2008)). As domain knowledge we
denote both knowledge about semantic and document
structure. Contemporary solutions require from do-
main experts to familiarize themselves with the IE
system, to gain technical expertise, and focus on the
extraction task itself instead of contributing their do-
main knowledge.
In our work we approach the usability issue of IE
languages from a user perspective. In particular we
specify this research question as: how to foster the
collaboration between IE and domain experts to make
them contribute their distinct knowledge into the de-
velopment of a domain-specific IE system (DES)?
Our approach addresses this question by providing an
IE language platform based on an algebraic extrac-
tion framework, introduced in Section 3, (e.g., (Shen
et al., 2008)) and the concept of domain specific lan-
guages from Model Driven Architecture (MDA) re-
search (Bosch and Dittrich, 2004). We provide each
of the experts with an IE plan modeling language that
is adapted to their respective expertise. An IE expert
has a fine grain view (e.g., regular expression used in
an IE operator) and a domain expert leverages a coarse
249
M. Barczyñski W., Förster F., Brauer F. and Schuster D. (2010).
AdaptIE - Using Domain Language Concept to Enable Domain Experts in Modeling of Information Extraction Plans.
In Proceedings of the 12th International Conference on Enterprise Information Systems - Databases and Information Systems Integration, pages
249-256
DOI: 10.5220/0002902602490256
Copyright
c
SciTePress

grain view (an IE operator is seen as a black box) on
a IE plan they both work on. We use the concept of
model transformation to enable transition among each
of languages and algebraic model of an IE framework.
Therefore, created extraction plans are stored in an IE
repository for later reuse. Experts’ work follows a
process that structures actions in creating DES from
Generic Extraction System (GES). GES provides a set
of generic IE operators that performs most common
IE tasks, e.g., regular expression extraction.
We implemented our approach as an Eclipse based
(http://www.eclipse.org) graphical modeling tool –
AdaptIE– for both the IE experts as well as the domain
experts. To demonstrate benefits of our approach we
apply it in a scenario of text extraction of an SDN fo-
rum (http://forums.sdn.sap.com). AdaptIE was also
used to construct IE plans used for entity recognition
in a retrieval system presented in (Brauer et al., 2009).
Our contributions are: we show how a concept of
domain specific languages can be applied in IE re-
search to foster collaboration between different kinds
of experts in order to simplify creation of DES. More-
over we provided a process model for creating DES
from GES and special-purpose languages for IE ex-
traction task modeling for each of the experts. Our
work can be seen as an effort to find synergies be-
tween different research areas to bring new value to
information systems research stated in the claremont
report (Agrawal et al., 2008). In particular, authors
of the report name as one of the challenges, the de-
velopment of new declarative languages that enable
non-experts (in our case non-IE experts) in develop-
ing programs (IE plans, respectively) for complex in-
formation systems (IE system).
We start our discussion by identifying related
work in Section 2. Our work relies on a generic IE
framework that we introduce in Section 3. We fur-
ther generalize and describe in detail a process for cre-
ating IE systems for different target domains in Sec-
tion 4. Section 5 provides insight into AdaptIE, which
is built on top of an algebraic IE framework. We val-
idate our concepts by considering the problem of ex-
tracting products and error messages from the SDN in
(Section 6). Section 7 concludes and discusses future
directions of our work.
2 RELATED WORK
IE frameworks. GATE (Bontcheva et al., 2004) and
UIMA (Ferruci and Lally, 2004) proposed architec-
tural approaches for Information Extraction systems
which at that time provided a common infrastructure
for IE. Both provide an object oriented framework
for black box composition of Information Extraction
modules in a pipeline. However, combined mod-
ules have to share the same semantics and incorporate
information extraction logic and domain knowledge
within the code itself.
IE languages. To overcome the drawbacks of archi-
tectural approaches, recent work propose languages
for operator composition and separation of domain
knowledge from the code. Notable approaches in this
area are (Reiss et al., 2008) and (DeRose et al., 2007).
Reiss et al. proposed an SQL like language, called
AQL, to combine a very small set of well defined al-
gebraic operators (Reiss et al., 2008). The aim is to
simplify using Information Extraction technology and
bring it closer to non IE experts familiar with SQL. The
drawback of this approach is the limitation for IE ex-
perts to plug custom operators. DeRose et al. present
a concept of extraction plans as a representation of
extraction programs composition. This approach was
extended by a Datalog like language for plan creation
- XLOG (Shen et al., 2007). The authors state that
XLOG might help IE engineers to speed up IE plans
constructions by relaying on the clear semantic of
logic programming language. Our approach extends
these approaches in three major points. First, we pro-
vide a clear separation between extraction logic and
domain knowledge without limiting IE experts in ex-
tending the extraction logic by introducing new op-
erators. Next, we provide a mechanism and user
interfaces for customizing and composing operators
into easy understandable extraction programs, pre-
compiled via code generation and ready to use by
the domain users. Last, we enable domain experts,
who are not familiar to IE, to contribute their domain
knowledge.
MDA and MDE. We realize our approach using do-
main specific languages (DSL) and model driven ar-
chitecture (MDA). The foundations of metamodeling
in general, independent from a particular technology
are presented in (Favre, 2004a). A metamodel is in-
troduced there and incrementally refined in (Favre,
2004b). Petrasch et al. explain in (Petrasch and
Meimberg, 2006) in detail the MDA standard defined
by the Object Management Group and lays down the
fundamentals of model-driven software architecture.
AdaptIE tool is used to create domain specific lan-
guages for each of the users.
3 CONCEPTS AND
BACKGROUND
This section presents in detail an algebraic extraction
framework, which is introduced in (Barczynski et al.,
ICEIS 2010 - 12th International Conference on Enterprise Information Systems
250
2009). The framework provides a set of generic oper-
ators and algebra which defines how to compose and
extend them in order to perform extraction. This clear
semantic allows us to make our approach generic for
all operators, which are described in the terms of the
framework. Moreover we introduce domain indepen-
dent and domain specific operators. As mentioned in
Section 2, there are other algebraic IE frameworks,
which could be used as well. Operators work on
annotations, which are extracted parts (fragments of
text) of a document, such as the title of a HTML page
or a recognized product. They contain semantic meta-
data: the entity type (e.g., SAP Product), and the ex-
tracted entity itself (e.g., NetWeaver 2004s) with, if
available, a unique id (e.g., an OKKAM Id (Bouquet
et al., 2008)). An operator takes as input a set of anno-
tations and returns new ones. Every operator has a set
of parameters for customizing its functionality. Those
parameters can be general (e.g., name and id) and do-
main specific (e.g., regular expression for ErcRegEx).
Table 1: Example of operators in the IE framework.
Operator Name Description
Import Imports documents from a given data source.
Basic Operators
ErcRegEx Extracts text using a regular expression.
RxR Extracts text between two regular expressions.
SentenceEx Detects sentences.
NounGrpEx Creates annotations for nouns groups.
ErcDict Extracts using a dictionary.
Relation Operators
ErcRel Relates annotations with objects in structured data.
Relate Combines two entities to one complex entity
Set Operators
Group Groups annotations by document id.
Operators. Each framework operator (see Table 1)
is considered atomic if it conducts a single and in-
divisible task in IE. Tasks include extracting entities,
identifying relationships, or combining extracted en-
tities. In our framework we distinguish the follow-
ing groups of atomic operators: Basic operators are
used to extract entities from unstructured documents.
Grammatical rules or dictionaries can be used for this
purpose. Relation operators combine extracted anno-
tations to complex entities or map complex entities
to structured data. Set operators, known in query lan-
guages, such as SQL, allow applying group, union and
aggregation on extracted entities. Complex operators
- atomic operators (as well as complex operators) can
be chained together to build complex extraction op-
erators. Complex operators encapsulate a complete
task in the process of IE (e.g., extracting the relation
between product and error message).
Domain adaptation. Both types of operators are ab-
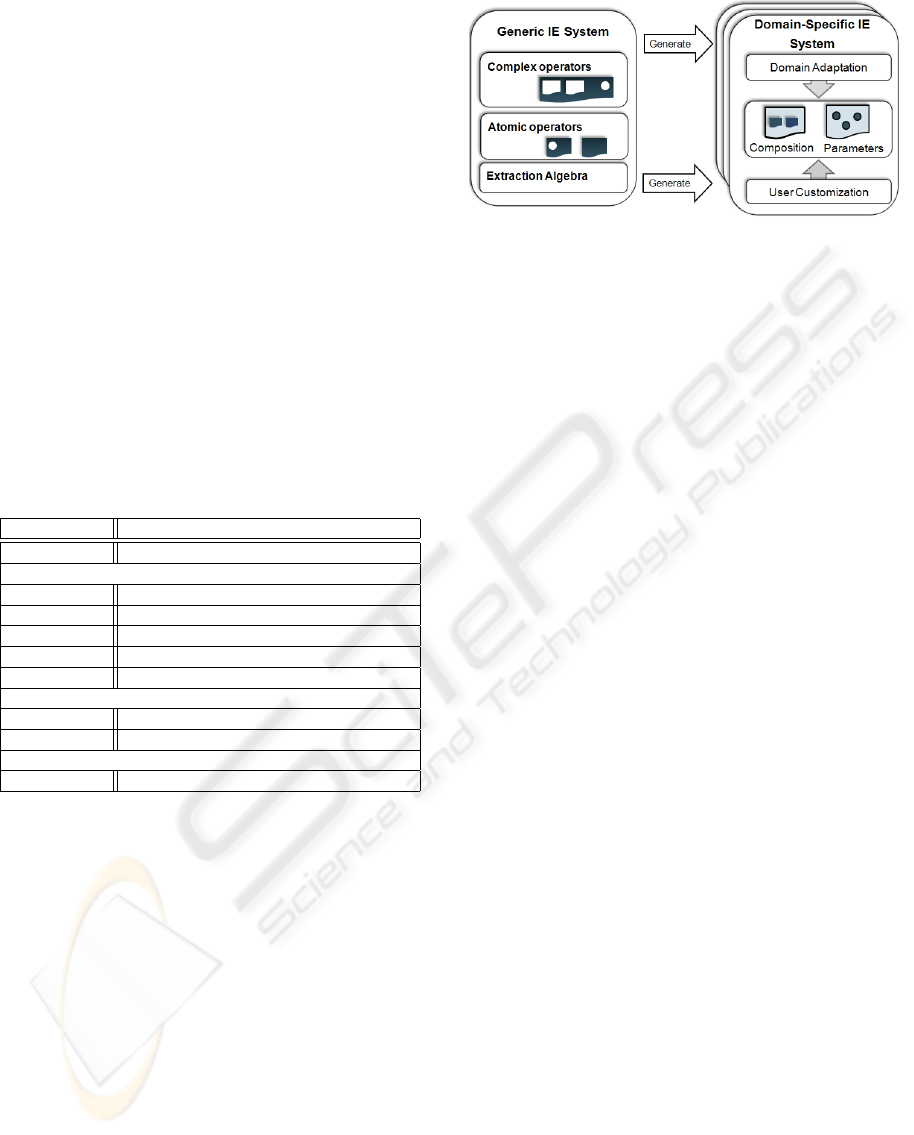
Figure 1: Instantiating a GES to DES.
stract and only provide a skeleton (structure and func-
tionality), but without configuration, they lack the do-
main knowledge necessary for the execution (see Fig-
ure 1). By using a generic approach for IE (Generic
Extraction System - GES) we gain extensibility and
generality. But this gain comes along with the need to
provide additional information in the framework - do-
main adaptation, user customization and composition
(see Figure 1). Such a customized framework we call
Domain Specific Extraction System (DES). As such
we speak of domain-independent operators and after
being provided with domain specific values for pa-
rameters of domain-specific operators. The method-
ology for creating DES is provided in Section 4.
4 USER-CENTRIC IE
This section provides a classification of user roles in
IE, followed by an overview and an explanation of
our approach. Specifically we explain the sequence
of steps, called IE (domain) adaptation process.
4.1 IE Adaptation Process
Users of IE Systems. Different users are involved in
the process of extracting data and as a consequence,
they use IE systems to fulfill different tasks. We clas-
sify users by their level of expertise and distinguish
two such types. We leave out end users that use a
completed DES because this issue does not bring any-
thing new to our discussion.
First, we have IE experts (e.g., IE Consultant and
IE Engineer) that are familiar with the concepts of IE.
They know about NLP, operators, about variability of
their settings, and also know about the right order in
which they have to be arranged (e.g., noun grouping
before applying other extraction operators). These
users are able to create extraction plans by combin-
ing and configuring the IE operators appropriately.
Second, there are domain experts (e.g., Product
Manager). They concentrate on their specific area and
AdaptIE - Using Domain Language Concept to Enable Domain Experts in Modeling of Information Extraction Plans
251
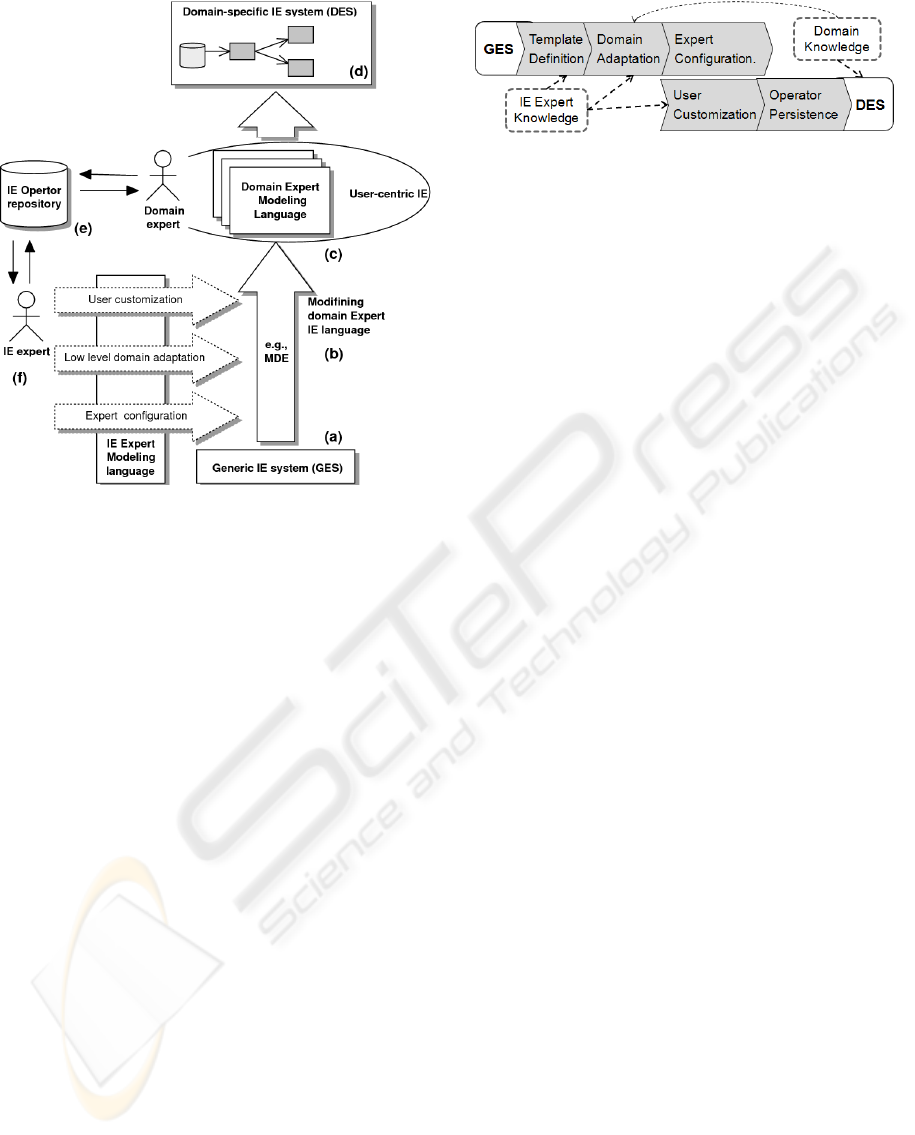
Figure 2: IE adaptation.
contribute their domain knowledge rather than focus
on the extraction task itself. Regarding IE, they do not
need to be aware of system internals. They usually do
not have IE expertise and they are, thus, not able to
deal with the complexity of IE. They need to formu-
late complex queries against unstructured data. They
require a tool, which let to focus on their task.
IE adaptation Process. Figure 2 shows an overview
of our approach. The base is an IE framework (GES)
- see Figure 2a. As the domain expert (Figure 2c)
does not have the expertise to deal with the complex-
ity of creating a complex extraction program, the IE
expert (Figure 2f) uses an adaptation process (Fig-
ure 2b) to prepare and pre-configure operators for the
domain expert. It is the initial step; afterwards whole
process consists of iterations over IE plan by both
experts. First the IE expert prepares operators with
generic configuration to the domain expert. Adapta-
tion consists of combining and adjusting atomic oper-
ators appropriately as well as performing a customiza-
tion tailored to specific domain expert’s needs. Ad-
ditionally – in next iterations after receiving feedback
from the domain expert – the IE expert tunes operators
based on his IE knowledge, e.g., by setting caching
strategies. As such, a set of domain-specific extrac-
tion operators can be created and stored in a reposi-
tory. The adaptation is done by using an expert graph-
ical interface. As a result domain expert is provided
with necessary operators in his IE modeling language.
The language uses familiar vocabulary (e.g., names
Figure 3: Actions necessary to provide DES.
of operators) and hides all fine-grained tuning param-
eters. Using this language, the domain expert con-
tributes his domain knowledge (e.g., knowledge about
the structure of forum threads) using an intuitive GUI
(see Figure 7), which allows modeling concrete ex-
traction programs. Subsequently, a domain expert can
import and export previously defined (complex) oper-
ators from repository (Figure 2e). Moreover an IE ex-
pert can access adapted operators to specific domain.
Final result of several iterations is a DES, depicted
in Figure 2d.
4.2 Users’ Roles and Actions
Several steps have to be performed to incorporate the
needed information in the GES, and to create a DES.
Those steps form an adaptation process which is de-
picted in Figure 3 (see also Figure 2b and Figure 2e).
In the following we will discuss the necessary steps
and focus on interaction between IE and domain ex-
perts.
Template Definition. The IE expert is solely respon-
sible for defining templates. Templates are a mean to
describe the structure of each operator type. They can
be written by defining XML-files by hand or by using
the IE expert interface. Parameters, their types, and
default values can be defined. Every template con-
sists of parameters common to all operators (e.g. id,
name, and version), but also allows the definition of
operator-specific parameters. The usage of an opera-
tor may be limited to a certain context. For instance,
in contrast to other operators, the Import-operator
must not have predecessor operators, or ErcDict, the
dictionary-based operator needs to be connected to an
external data source providing the dictionary. Tem-
plates serve three purposes. First, they decouple IE
plan modeling from the concrete implementation in
the IE system. Second, they help to automate the pro-
cess of extending the system with new operators (add
to the tool GUI) and third, they constrain the applica-
tion of an operator.
Domain Adaptation. An IE system needs to be
configured appropriately for one application domain,
thus, domain-specific information has to be added.
Refining Operators. Refining operators means to pro-
ICEIS 2010 - 12th International Conference on Enterprise Information Systems
252

vide values for parameters contained in atomic op-
erators. We distinguish common parameters (such
as name, and version), performance parameters (e.g.
caching, memory usage), and domain parameters (e.g.
location of dictionary). Parameters may be left un-
specified by the IE expert, in that case, we speak of
partial refinement.
Composing Operators. Operators might require (e.g.,
for achieving higher precision) the execution of other
operators before they can be used. This usually in-
cludes operators for importing data or for natural lan-
guage (pre-) processing, such as annotating sentences
and noun groups. Thus, it is possible to combine
atomic extraction operators in the right order to model
complex extraction operators or to combine atomic
and complex operators to build a complete extraction
program. This is called operator composition and can
be done before or after operator refinement.
Both IE experts and domain experts are responsi-
ble for performing the domain adaptation. For the ex-
pert it means to translate requirements formulated by
a domain expert to the world of IE and (partially) pre-
configure domain-specific operators. The domain ex-
pert, based on his domain knowledge, completes the
partial refinement and models the final extraction plan
using a DES (Figure 2d).
Expert Configuration. The IE expert, based on his
knowledge or in response to the domain expert re-
quest, performs fine-grained tuning. For example, he
redefines operators for achieving higher recall.
User Customization. After providing the domain-
knowledge, the IE expert performs final adjustments
to hide the complexity and the details from the do-
main expert, thus customizing the system to domain
expert requirements. We introduce here different cat-
egories of customization and how they are performed
to provide user-centric IE. We denote those categories
dimensions of customization. Customization can be
applied on the following dimensions:
Operator Parameters. We allow the IE expert to hide
parameters, set them read-only and provide default
values. This provides a higher level of abstraction for
the domain expert.
Operator Composition. Complex operators are cre-
ated by combining atomic operators. They hide inter-
nal structure and complexity of extraction flows. Cer-
tain steps of the IE process are not of interest for the
domain expert but nevertheless important and needed
in overall process.
Operator Documentation. As soon as an operator is
configured and provided with parameters, it is ready
Figure 4: Model transformation is used to implement the
user customization.
to be used in a domain-specific context. As such, the
semantics of the operator specified. This should be
reflected in its description, help, and examples. We
use a description-attribute for this purpose.
Debug and Runtime Feedback. If the IE expert
changes the IE language for the domain expert it
should affect also error and debug messages. The do-
main expert should see ”Product extractor failed...”
instead of ”ErcRgx operator...”. This dimension is
changed implicitly by changes in the IE language.
DES. The domain expert uses the DES to build ex-
traction programs. He can model extraction plans us-
ing prepared complex operators. Besides, if there is
a need, he can contact the IE expert and request for
the tuning the operators. The IE expert will perform
one of the actions shown in Figure 3. We allow the
domain expert to perform domain adaptation by oper-
ator composition and parameter adjustments.
Operator Persistence. All domain-specific operators
are persisted in an operator repository. The major aim
of an operator repository is to store operators, for fu-
ture retrieval and reuse. Domain-specific operators
are associated and persisted within the domain they
are applied to. Domain experts can choose a domain
they want to work with, and load a profile containing
all the operators for this specific domain.
5 IMPLEMENTATION
AdaptIE tool is built on top of Eclipse Modeling
Framework. We use different metamodels to provide
abstract syntax for our extraction languages. Addi-
tionally, we use GMF (GMF, 2009) to provide con-
crete syntax through graphical user interfaces. Fig-
ure 4 shows the 4-layer metamodel architecture. Ele-
ments on one layer are said to be instances of elements
from the above layer and specify elements on the layer
below. On M0 are concrete IE plans modeled in UIs in
AdaptIE - Using Domain Language Concept to Enable Domain Experts in Modeling of Information Extraction Plans
253
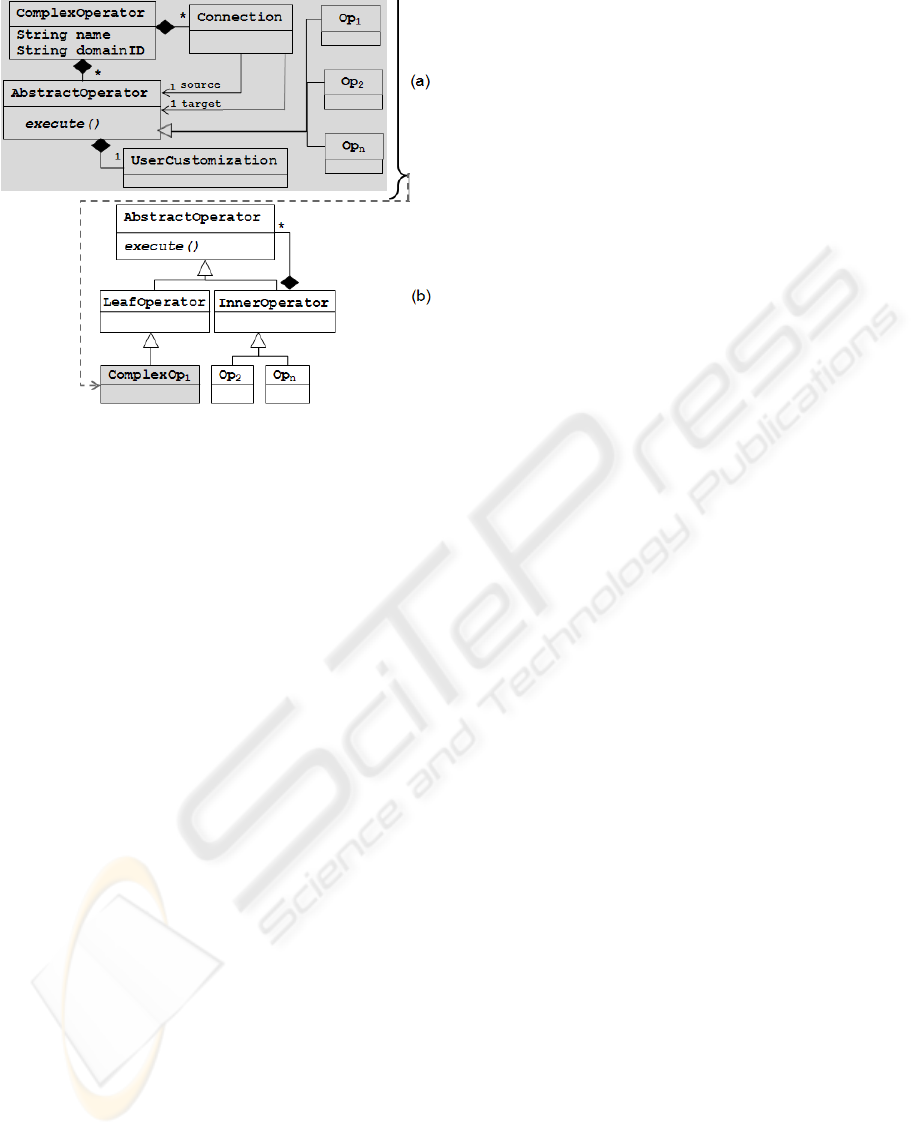
Figure 5: IE expert (a) and domain expert (b) metamodels
(simplified).
M1. On the very left in Figure 4 (level M1) we have
extraction programs or complex operators conform-
ing to the expert metamodel. The M2 is described by
means of its metamodel - M3 (Ecore (EMF, 2008)).
The same applies for composition programs written
using the end-user (domain expert) DSL. Those pro-
grams conform to the end-user metamodel.
In this work we analyze concrete instances of “ex-
pert operators” located on M1. We generate elements
for the end-user metamodel, which resides on M2 i.e.,
we need to cross the layers. The transformation is vi-
sualized by the dashed bold arrow in Figure 4. We de-
scribe model transformations by defining relations be-
tween two models. The mapping between source and
target model is described in terms of their metamod-
els i.e., one level higher than input and output model.
In our case we describe rules using Ecore elements.
The transformation itself has to be defined as a
model conforming to a metamodel defining model
transformation semantics. Java and the ATLAS Trans-
formation Language (ATL) (ATLAS, 2006) provides
means to define and execute a model transformation.
In the prototype we used Java, but we consider to use
ATL in the next versions of AdaptIE. An excerpt of
the IE expert metamodel is shown in the UML class
diagram in Figure 5a. Intuitively, it allows model-
ing an instance of ComplexOperator by combining
AbstractOperators with Connections. The User
Customization class defines a user-centric adjust-
ment. The domain expert metamodel (Figure 5b) al-
lows to nest InnerOperators until a LeafOperator
(representing an atomic operator) is used, which does
not allow further nesting.
We use model transformation for two purposes:
First, it allows combining complex operators created
in the expert language using the domain expert lan-
guage. Second, we can use model transformation
for implementing the user customization. This takes
the form of analyzing concrete instances of the ex-
pert metamodel and generating elements for the do-
main expert metamodel. For example, a parameter
marked ”invisible” will not appear in the domain ex-
pert model.
6 EVALUATION
As a method to proof applicability of our method-
ology, we have selected a scenario based evaluation
(Hevner et al., 2004). Because we want to show that
our approach can be implemented and used to solve
issues in a real world scenario.
Scenario. We consider analysis of relation between
SAP Products and error messages (Java and ABAP
exceptions) in SDN forum. Results of such analysis
can help to understand which kind of problems de-
velopers and consultants encounter. In this scenario a
product manager is our domain expert. He knows the
forum, conventions used by its members well. More-
over he has access to structured data about products,
error messages, etc. He starts by selecting the data
source for analysis, e.g., RSS feed. The manager con-
figures the Import-operator himself. He provides the
number of items to be imported and the database con-
nectivity information. The next step is to extract prod-
ucts and error messages. As the domain expert is
not interested in how to extract things, therefore he
uses an operator repository and search extractors for
his domain. There are available Java, and ABAP ex-
ceptions extractors, but no operator for SAP Product.
Therefore he contacts an IE expert, and asks him for
such an operator. Moreover he provides the IE expert
with a taxonomy about SAP Products - SAP Terms
database. SAP Terms database contains all terminolo-
gies used in documentation about a product and list of
product’s subcomponents.
The IE expert does not need to understand SDN
forum data, so she can focus on her task to provide
an operator, which is able to use the taxonomy. Us-
ing AdaptIE, she composes operators as shown in
Figure 6b. The IE expert starts by applying pre-
processing operators for a morphological analysis.
First, she extracts sentences (SentenceEx) followed
by noun groups (NounGrpEx), thus, rejecting preposi-
tions, conjunctions, and relative pronouns that are not
considered important. Next, she applies ErcDict, re-
alizing a connection to the SAP Term database. The
ICEIS 2010 - 12th International Conference on Enterprise Information Systems
254
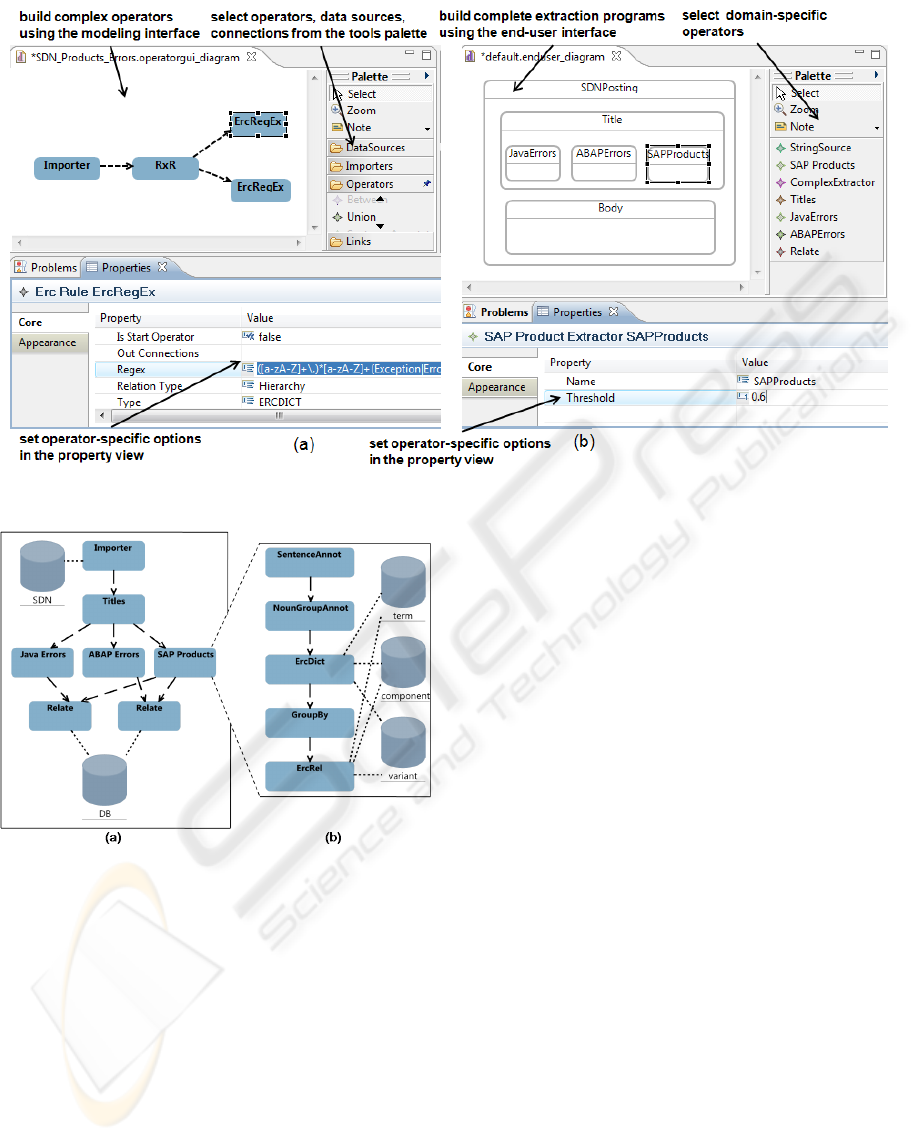
Figure 7: Visual tools for IE expert (a) and end-user (b).
Figure 6: (a) Plan for extracting products and errors
(b) Complex operator (IE Expert’s view).
IE expert provides database access information and
decides to set the isCached property to keep ex-
tracted entities in memory thus reducing database ac-
cess time. Next, she saves the new IE plan as a oper-
ator and store it in repository. The IE expert specifies
additionally that a domain expert will see SAP prod-
ucts as a atomic operator.
Now, the product manager can import the ready-
to-use operators and connect them to build the fi-
nal extraction program (Figure 6a). He knows that
most of forum members put in their post about prob-
lems SAP products and error names together in the
HTML title. Moreover he knows that his product
is used in two scenarios with software components
written in Java and Abap. Therefore he selects
to extract both Java and ABAP exceptions. Fig-
ure 6 shows the complete extraction program mod-
eled by the product manager, and the complex oper-
ator for identifying SAP Products as modeled by the
IE expert. If operators do not perform as expected,
he may consult the expert again. So he does not
need to spend a lot of time trying to find a mistake
in, e.g., regular expression for Java Exceptions ex-
traction: ([a-zA-Z]*\\.)*[a-zA-Z]+(Exception
|Error)[a-zA-Z]*. As such, they can both work on
refinement iteratively and use the operator repository
(powered by the transformation engine) for exchang-
ing operators.
Tools. The current implementation of AdaptIE in-
cludes tools for the IE and domain experts. Figure 7a
shows the IE expert’s tool. It allows to create ex-
traction programs and to model complex operators.
The expert has access to all parameters and configu-
ration options. A low-level view on operators allows
fine-tuning the execution of complex IE plans. Fur-
thermore, the tool allows him to perform a user cus-
tomization, i.e., renaming operators and parameters,
setting parameters, marking them mandatory, visible,
or read-only as well as providing default values for
the end-user. Once operators have been created, they
can be associated with a target domain and archived
in the repository.
The domain expert tool (Figure 7b) allows for
building the final extraction program by combining
previously defined domain-specific operators. Access
AdaptIE - Using Domain Language Concept to Enable Domain Experts in Modeling of Information Extraction Plans
255

to the repository and import of complex operators
is supported. We are currently investigating a more
declarative UI, which follows the document structure.
7 CONCLUSIONS
To summarize, this paper contribute an IE language
platform that can be a base for involving domain ex-
perts in IE plan modeling. We presented a process
for creating a domain-specific IE system. We showed
how our approach can be implemented using MDE
and a generic IE framework. As a proof of concept
we have developed AdaptIE and show how it can be
successfully applied in a real world scenario. As a fu-
ture work, we want to continue to bring IE to causal
users in two directions. The first direction is further
investigation on IE languages for non IE expert users.
The second direction is work on automatic genera-
tion (driven by information available in, e.g., database
schema or descriptions of OLAP cubes) of IE plan to
simplify performing ad-hock Business analysis over
unstructured data.
REFERENCES
Agrawal, R., Ailamaki, A., Bernstein, P. A., Brewer, E. A.,
Carey, M. J., Chaudhuri, S., Doan, A., Florescu, D.,
Franklin, M. J., Molina, H. G., Gehrke, J., Gruenwald,
L., Haas, L. M., Halevy, A. Y., Hellerstein, J. M., Ioan-
nidis, Y. E., Korth, H. F., Kossmann, D., Madden, S.,
Magoulas, R., Ooi, B. C., O’Reilly, T., Ramakrishnan,
R., Sarawagi, S., Stonebraker, M., Szalay, A. S., and
Weikum, G. (2008). The claremont report on database
research. SIGMOD Rec., 37(3):9–19.
ATLAS (2006). Atlas Transformation Language (ATL)
User Manual v0.7. Nantes.
Barczynski, W. M., Brauer, F., Loeser, A., and Mocan, A.
(2009). Algebraic information extraction of enterprise
data: Methodology and operators. In IK-KR Workshop
at 20th International Joint Conference on Artificial In-
telligence 2009 (to be published).
B
´
ezivin, J. and Heckel, R., editors (2005). Language
Engineering for Model-Driven Software Develop-
ment, 29. February - 5. March 2004, volume 04101
of Dagstuhl Seminar Proceedings. Internationales
Begegnungs- und Forschungszentrum f
¨
ur Informatik
(IBFI), Schloss Dagstuhl, Germany.
Bontcheva, K., Tablan, V., Maynard, D., and Cunningham,
H. (2004). Evolving gate to meet new challenges in
language engineering. Natural Language Engineer-
ing, 10(3-4):349–373.
Bosch, J. and Dittrich, Y. (2004). Domain-Specific Lan-
guages for a Changing World. http://www.ide.hk-
r.se/ bosch/papers/dslincw.ps.
Bouquet, P., Stoermer, H., Niederee, C., and Mana, A.
(2008). Entity Name System: The Backbone of an
Open and Scalable Web of Data. In ICSC 2008,
number CSS-ICSC 2008-4-28-25 in CSS-ICSC, pages
554–561. IEEE Computer Society.
Brauer, F., Barczynski, W., Hackenbroich, G., Schramm,
M., Mocan, A., and Foerster, F. (2009). Rankie:
Document retrieval on ranked entity graphs (demo).
In 35th conference International Conference on Very
Large Data Bases (VLDB) 2009.
DeRose, P., Shen, W., 0002, F. C., Doan, A., and Ramakr-
ishnan, R. (2007). Building structured web commu-
nity portals: A top-down, compositional, and incre-
mental approach. In (Koch et al., 2007), pages 399–
410.
EMF (2008). Eclipse Modeling Framework. Documen-
tation available at http://www.eclipse.org/modeling/
emf/.
Favre, J.-M. (2004a). Foundations of meta-pyramids: Lan-
guages vs. metamodels - episode ii: Story of thotus
the baboon1. In (B
´
ezivin and Heckel, 2005).
Favre, J.-M. (2004b). Foundations of model (driven) (re-
verse) engineering : Models - episode i: Stories of
the fidus papyrus and of the solarus. In (B
´
ezivin and
Heckel, 2005).
Ferruci, D. and Lally, A. (2004). Uima: an architectural ap-
proach to unstructured information processing in the
corporate research environment. Natural Language
Engineering, 10(3-4):327–348.
GMF (2009). http://gmf.eclipse.org.
Hevner, A. R., March, S. T., Park, J., and Ram, S. (2004).
Design science in information systems research. MIS
Quarterly, 28(1).
Koch, C., Gehrke, J., Garofalakis, M. N., Srivastava, D.,
Aberer, K., Deshpande, A., Florescu, D., Chan, C. Y.,
Ganti, V., Kanne, C.-C., Klas, W., and Neuhold, E. J.,
editors (2007). Proceedings of the 33rd International
Conference on Very Large Data Bases, University of
Vienna, Austria, September 23-27, 2007. ACM.
Petrasch, R. and Meimberg, O. (2006). Model Driven Archi-
tecture Eine praxisorientierte Einfhrung in die MDA.
dpunkt.verlag.
Reiss, F., Raghavan, S., Krishnamurthy, R., Zhu, H., and
Vaithyanathan, S. (2008). An algebraic approach to
rule-based information extraction. In ICDE, pages
933–942. IEEE.
Sarawagi, S. (2008). Information extraction. Foundations
and Trends in Databases, 1(3):261–377.
Shen, W., DeRose, P., McCann, R., Doan, A., and Ramakr-
ishnan, R. (2008). Toward best-effort information ex-
traction. In SIGMOD ’08: Proceedings of the 2008
ACM SIGMOD international conference on Manage-
ment of data, pages 1031–1042, New York, NY, USA.
ACM.
Shen, W., Doan, A., Naughton, J. F., and Ramakrishnan, R.
(2007). Declarative information extraction using dat-
alog with embedded extraction predicates. In (Koch
et al., 2007), pages 1033–1044.
ICEIS 2010 - 12th International Conference on Enterprise Information Systems
256
