
DON’T FOLLOW ME
Spam Detection in Twitter
Alex Hai Wang
College of Information Sciences and Technology, The Pennsylvania State University, PA 18512, Dunmore, U.S.A.
Keywords:
Social network security, Spam detection, Machine learning, Classification.
Abstract:
The rapidly growing social network Twitter has been infiltrated by large amount of spam. In this paper, a spam
detection prototype system is proposed to identify suspicious users on Twitter. A directed social graph model
is proposed to explore the “follower” and “friend” relationships among Twitter. Based on Twitter’s spam
policy, novel content-based features and graph-based features are also proposed to facilitate spam detection.
A Web crawler is developed relying on API methods provided by Twitter. Around 25K users, 500K tweets,
and 49M follower/friend relationships in total are collected from public available data on Twitter. Bayesian
classification algorithm is applied to distinguish the suspicious behaviors from normal ones. I analyze the data
set and evaluate the performance of the detection system. Classic evaluation metrics are used to compare the
performance of various traditional classification methods. Experiment results show that the Bayesian classifier
has the best overall performance in term of F-measure. The trained classifier is also applied to the entire data
set. The result shows that the spam detection system can achieve 89% precision.
1 INTRODUCTION
Online social networking sites, such as Facebook,
LinkedIN, and Twitter, are one of the most popu-
lar applications of Web 2.0. Millions of users use
online social networking sites to stay in touch with
friends, meet new people, make work-related connec-
tions and more. Among all these sites, Twitter is the
fastest growing one than any other social networking
sites, surging more than 2,800% in 2009 according
to the report (Opera, 2009). Founded in 2006, Twit-
ter is a social networking and micro-blogging service
that allows users to post their latest updates, called
tweets. Users can only post text and HTTP links in
their tweets. The length of a tweet is limited by 140
characters.
The goal of Twitter is to allow friends communi-
cate and stay connected through the exchange of short
messages. Unfortunately, spammers also use Twitter
as a tool to post malicious links, send unsolicited mes-
sages to legitimate users, and hijack trending topics.
Spam is becoming an increasing problem on Twitter
as other online social networking sites are. A study
shows that more than 3% messages are spam on Twit-
ter (Analytics, 2009). The trending topics are also
often abused by the spammers. The trending topics,
which displays on Twitter homepage, are the most
tweeted-about topics of the minute, day, and week on
Twitter. The attack reported in (CNET, 2009) forced
Twitter to temporarily disable the trending topic and
remove the offensiveterms. I also observedone attack
on February 20, 2010 as shown in Figure 1.
Figure 1: A Twitter trending topic attack on February 20,
2010 (The offensive term is shown in the red rectangle and
is censor blurred).
Twitter provides several methods for users to re-
port spam. A user can report a spam by clicking on the
“report as spam” link in the their homepage on Twit-
ter. The reports are investigated by Twitter and the
accounts being reported will be suspended if they are
spam. Another simple and public available method
is to post a tweet in the “@spam @username” for-
mat where @username is to mention the spam ac-
142
Hai Wang A. (2010).
DON’T FOLLOW ME - Spam Detection in Twitter.
In Proceedings of the International Conference on Security and Cryptography, pages 142-151
DOI: 10.5220/0002996201420151
Copyright
c
SciTePress

count. I tested this service by searching “@spam”
on Twitter. Surprisingly the query results show that
this report service is also abused by both hoaxes and
spam. Only a few tweets report real malicious ac-
counts. Some Twitter applications also allow users to
flag possible spam. However, all these ad hoc meth-
ods require users to identify spam manually and de-
pend on their own experience.
Twitter also puts effort into cleaning up suspicious
accounts and filtering out malicious tweets. Mean-
while, legitimate Twitter users complain that their ac-
counts are mistakenly suspended by Twitter’s anti-
spam action. Twitter recently admitted to accidentally
suspending accounts as a result of a spam clean-up ef-
fort (Twitter, 2009a).
In this paper, the suspicious behaviors of spam
accounts on Twitter is studied. The goal is to apply
machine learing methods to automatically distinguish
spam accounts from normal ones. The major contri-
butions of this paper are as follows:
1. To the best of our knowledge, this is the first effort
to automatically detect spam on Twitter;
2. A directed graph model is proposed to explore the
unique “follower” and “friend” relationships on
Twitter;
3. Based on Twitter’s spam policy, novel graph-
based features and content-based features are pro-
posed to facilitate the spam detection;
4. A series of classification methods are compared
and applied to distinguish suspicious behaviors
from normal ones;
5. A Web crawler is developed relying on the API
methods provided by Twitter to extract public
available data on Twitter website. A data set of
around 25K users, 500K tweets, and 49M follow-
er/friend relationships are collected;
6. Finally, a prototype system is established to eval-
uate the detection method. Experiments are con-
ducted to analyze the data set and evaluate the per-
formance of the system. The result shows that the
spam detection system has a 89% precision.
The rest of the paper is organized as follows. In
Section 2 the related work is discussed. A directed
social graph model is proposed in Section 3. The
unique friend and follower relationships are also de-
fined in this part. In Section 4, novel graph-based and
content-based features are proposed based on Twit-
ter’s spam policy. Section 5 introduces the method in
which I collect the data set. Bayesian classification
methods are adopted in Section 6 to detect spam ac-
counts in Twitter. Experiments are conducted in Sec-
tion 7 to analyze the labeled data. Traditional classi-
fication methods are compared to evaluate the perfor-
mance of the detection ssystem. The conclusion is in
Section 8.
2 RELATED WORK
Spam detection has been studied for a long time. The
exsiting work mainly focuses on email spam detection
and Web spam detection. In (Sahami et al., 1998),
the authors are the first to apply a Bayesian approach
to filter spam emails. Experiment results show that
the classifier achievesa better performanceby consid-
ering domain-specific features in addition to the raw
text of E-mail messages. Currently spam email filter-
ing is a fairly mature technique. Bayesian spam email
filters are widely implemented both on modern email
clients and servers.
Web is massive and changes more rapidly com-
pared with email system. It is a significant challenge
to detect Web spam. (Gy¨ongyi et al., 2004) first for-
malized the Web spam detection problem and pro-
posed a comprehensive solution to detect Web spam.
The TrustRank algorithm is proposed to compute the
trust scores of a Web graph. Based on computed
scores where good pages are given higher scores,
spam pages can be filtered in the search engine re-
sults. In (Gyongyi et al., 2006), the authors based
on the link structure of the Web proposed a measure-
ment Spam Mass to identify link spamming. A di-
rected graph model of the Web is proposed in (Zhou
et al., 2007). The authors apply classification algo-
rithms for directed graphs to detect real-world link
spam. In (Castillo et al., 2007), both link-based fea-
tures and content-based features are proposed. A ba-
sic decision tree classifier is implemented to detect
spam. Semi-supervised learning algorithms are pro-
posed to boost the performance of a classifier which
only needs small amount of labeled samples in (Geng
et al., 2009).
For spam detection in other applications, the au-
thors in (Yu-Sung et al., 2009) present an approach
for detection of spam calls over IP telephony called
SPIT in VoIP system. Based on the popular semi-
supervised learning methods, an improved algorithm
called MPCK-Means is proposed. In (Benevenuto
et al., 2009), the authors study the video spammers
and promoters on YouTube. A supervised classifi-
cation algorithm is proposed to detect spammers and
promoters. In (Wang, 2010), a machine learning ap-
proach is proposed to study spam bots detection in
online social networking sites using Twitter as an ex-
ample. In (Krishnamurthy et al., 2008), the authors
collected three datasets of the Twitter network. The
DON'T FOLLOW ME - Spam Detection in Twitter
143
Twitter users’ behaviors, geographic growth pattern,
and current size of the network are studied.
3 SOCIAL GRAPH MODEL
In this work, Twitter is modeled as a directed graph
G = (V , A ) which consists of a set V of nodes (ver-
tices) representing user accounts and a set A of arcs
(directed edges) that connect nodes. Each arc is an
ordered pair of distinct nodes. An arc a = (i, j) is
directed from v
i
to v
j
which stands for the user i is
following user j. Following is one of the unique fea-
tures of Twitter. Unlike most other online social net-
working sites, following on Twitter is not a mutual
relationship. Any user can follow you and you do not
have to approve or follow back. In this way, Twitter
is modeled as a directed graph.
Since there may or may not be an arc in either
direction for a pair of nodes, there are four possible
states for each dyad. Four types of relationships on
Twitter are defined as follows:
First, followers represent the people who are fol-
lowing you on Twitter. In this paper, follower in Twit-
ter’s graph model is defined as:
Definition 1 (Follower). Node v
j
is a follower of
node v
i
if the arc a = ( j,i) is contained in the set of
arcs, A .
Based on the definition, followers are the incom-
ing links, or inlinks, of a node. Let the set A
I
i
denote
the inlinks of node v
i
, or the followers of user i.
Second, Twitter defines friends as the people
whose updates you are subscribed to. In other words,
friends are the people whom you are following. I give
a formal definition of the friend relationship in graph
model as follows:
Definition 2 (Friend). Node v
j
is a friend of node v
i
if the arc a = (i, j) is contained in the set of arcs, A .
Friends are the outgoing links, or outlinks, of a
node. Let the set A
O
i
denote the outlinks of node v
i
,
or the friends of user i.
Third, a novel relationship on Twitter, mutual
friend, is proposed. If two users are following each
other, or are the friends of each other, the relationship
between these two users is mutual friend. A formal
definition of the mutual friend relationship on Twitter
is defined as follows:
Definition 3 (Mutual Friend). Node v
i
and node v
j
are mutual friends if both arcs a = (i, j) and a = ( j,i)
are contained in the set of arcs, A .
Since a mutual friend is your follower and friend
at the same time, the set of mutual friends is the inter-
section of the set of friends and the set of followers.
If let A
M
i
denote the set of mutual friends of node v
i
,
the following holds: A
M
i
= A
I
i
∩ A
O
i
.
Finally, two users are strangers if there is no con-
nection between them. A formal definition is as fol-
lows:
Definition 4 (Stranger). Node v
i
and node v
j
are
strangers if neither arcs a = (i, j) nor a = ( j, i) is con-
tained in the set of arcs, A .
A B
C
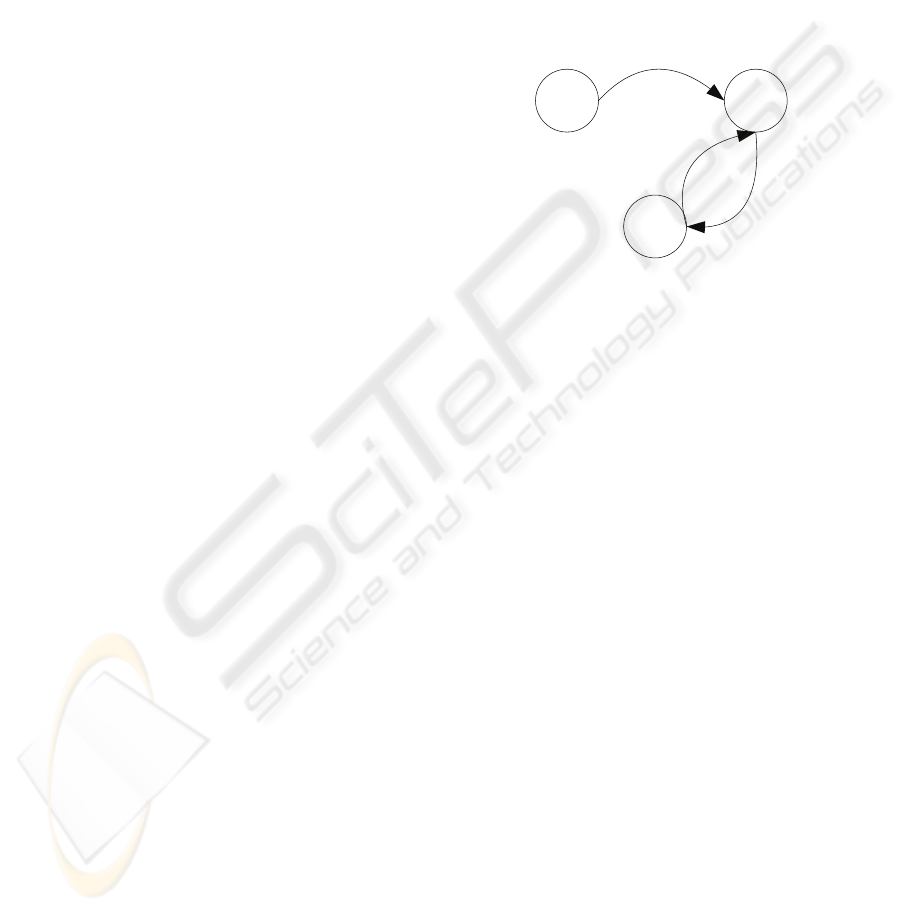
Figure 2: A simple Twitter graph.
A simple Twitter social graph example is shown in
Figure 2 where user A is following user B, and user
B and user C are following each other. Based on our
definitions, user A is a follower of user B. User B
is a friend of user A. User B and User C are mutual
friends. User A and user C are strangers.
Based the directed social graph model proposed
above, a real Twitter social graph is shown in Figure 3.
20 random users and their followers and friends are
collected from Twitter’s public timeline and the figure
is drawn using Pajek software (Nooy et al., 2004).
4 FEATURES
In this section, the features extracted from each Twit-
ter user account for the purpose of spam detection are
introduced. The features are extracted from differ-
ent aspects which include graph-based features and
content-based features. Based on the unique charac-
teristics of Twitter, novel features are also proposed in
this section.
4.1 Graph-based Features
One important function of twitter is that you can build
your own social network by following friends and al-
lowing others to follow you. Spam accounts try to fol-
low large mount of users to gain their attention. The
twitter’s spam and abuse policy (Twitter, 2009b) says
SECRYPT 2010 - International Conference on Security and Cryptography
144

Pajek
Figure 3: Twitter social graph.
that, “if you have a small number of followers com-
pared to the amount of people you are following”, it
may be considered as a spam account.
Three features, which are the number of friends,
the number of followers, and the reputation of a user,
are computed to detect spam from this aspect. Ac-
cording to the social graph model proposed in Sec-
tion 3, the indegree d
I
(v
i
) of a node v
i
, which is the
number of nodes that are adjacent to node v
i
, stands
for the feature of the number of followers. The feature
of the number of friends is represented by the outde-
gree d
O
(v
i
) of a node v
i
, which is the number of nodes
that are adjacent to v
i
.
Furthermore, a novel feature, reputation, is pro-
posed to measure the relative importance of a user on
Twitter. The reputation R is defined as the ratio be-
tween the number of friends and the number of fol-
lowers as:
R(v
i
) =
d
I
(v
i
)
d
I
(v
i
) + d
O
(v
i
)
(1)
Obviously if the number of followers is relatively
small compared to the amount of people you are fol-
lowing, the reputation is small and close to zero. At
the same time the probability that the associated ac-
count is spam is high.
4.2 Content-based Features
4.2.1 Duplicate Tweets
An account may be considered as a spam if you post
duplicate content on one account. Usually legitimate
users will not post duplicate updates.
Duplicate tweets are detected by measuring
the Levenshtein distance (Levenshtein, 1966) (also
known as edit distance) between two different tweets
posted by the same account. The Levenshtein dis-
tance is defined as the minimum cost of transform-
ing one string into another through a sequence of edit
operations, including the deletion, insertion, and sub-
stitution of individual symbols. The distance is zero
if and only if the two tweets are identical.
A typical Twitter spam page is shown in Figure 4.
As can be seen, spammers often include different
@usernames in their duplicate tweets to avoid be-
ing detected. This is also an efficient way to spam
legitimate users, since Twitter automatically collects
all tweets containing your @username for you. The
example in Figure 4 also shows that spammers in-
clude different #topics and “http” links in their dupli-
cate tweets. Because of the URL shortening service,
such as bit.ly, the different “http” links may have the
same destination. Based on these reasons, when the
Levenshtein distance is calculated between different
tweets, I clean the data by stopping the words con-
taining “@”, “#”, “http://”, and “www.” in the tweets.
In other words, the username information, topic infor-
mation, and links are ignored. Instead only the con-
tent of the tweets is considered. As shown in Fig-
ure 4, the duplicate tweets are circled in the same
color rectangles, although they have different @user-
name, #topic, and links.
After cleaning the data, the pairwise Levenshtein
distance is calculated in the user’s 20 most recent
tweets. If the distance is smaller than a certain thresh-
old, it is counted as one duplicate. In this paper, the
threshold is set to zero, which means two tweets are
considered as duplicate only when they are exactly the
DON'T FOLLOW ME - Spam Detection in Twitter
145

Figure 4: A Twitter spam page (Duplicate tweets are circled
in the same color rectangles).
same.
4.2.2 HTTP Links
Malicious links can spread more quickly than ever
before because of Twitters lightning-fast communica-
tions platform. Twitter filters out the URLs linked to
known malicious sites. However, a great vulnerabil-
ity is the presence of shorten URLs. Twitter only al-
lows users to post a short message within 140 charac-
ters. URL shortening services and applications, such
as bit.ly, become popular to meet the requirements.
Shorten URLs can hide the source URLs and obscure
the malicious sites behind them. As a result it pro-
vides an opportunity for attackers to prank, phish, and
spam. While Twitter does not check these shorten
URLs for malware, it is considered as spam if your
updates consist mainly of links, and not personal up-
dates according to Twitter’s policy.
The number of links in one account is measured
by the number of tweets containing HTTP links in the
user’s 20 most recent tweets. If a tweet contains the
sequence of characters “http://” or “www.”, this tweet
is considered containing a HTTP link.
4.2.3 Replies and Mentions
A user is identified by the unique username and can
be referred in the @username format on Twitter. The
@username creates a link to the user’s profile auto-
matically. You can send a reply message to another
user in @username+message format where @user-
name is the message receiver. You can reply to any-
one on Twitter no matter they are your friends/fol-
lowers or not. You can also mention another @user-
name anywhere in the tweet, rather than just the be-
ginning. Twitter automatically collects all tweets con-
taining your username in the @username format in
your replies tab. You can see all replies made to you,
and mentions of your username.
The reply and mention are designed to help users
to track conversation and discover each other on Twit-
ter. However, this service is abused by the spammers
to gain other user’s attention by sending unsolicited
replies and mentions. Twitter also considers this as a
factor to determine spamming. The number of replies
and mentions in one account is measured by the num-
ber of tweets containing the “@” symbol in the user’s
20 most recent tweets.
4.2.4 Trending Topics
Trending topics are the most-mentioned terms on
Twitter at that moment, in this week, or in this month.
Users can use the hashtag, which is the # symbol fol-
lowed by a term describing or naming the topic, to a
tweet. If there are many tweets containing the same
term, that helps the term to become a trending topic.
The topic shows up as a link on the home page of
Twitter as shown in Figure 1.
Unfortunately, because of how prominenttrending
topics are, spammers post multiple unrelated tweets
that contain the trending topics to lure legitimate users
to read their tweets. Twitter also considers an account
as spam “if you post multiple unrelated updates to
a topic using the # symbol”. The number of tweets
which contains the hashtag # in a user’s 20 most re-
cent tweets is measured as a content-based feature.
5 DATA SET
To evaluate the spam detection methods, a real data
set is collected from Twitter website. First I use Twit-
ter’s API methods to collect user’s detailed informa-
tion. Second, because no Twitter API method could
provide information of a specific unauthorized user’s
recent tweets, a Web crawler is developed to extra a
specific unauthorized user’s 20 most recent tweets.
SECRYPT 2010 - International Conference on Security and Cryptography
146
5.1 Twitter API
First I use the public timeline API method provided
by Twitter to collect information about the non-
protected users who have set a custom user icon in
real time. This method can randomly pick 20 non-
protected users who updated their status recently on
Twitter. Details of the user, such as IDs, screen name,
location, and etc, are extracted. At the same time, I
also use social graph API methods friends and follow-
ers to collect detailed information about user’s friends
and followers, such as the number of friends, the num-
ber of followers, list of friend IDs, list of followerIDs,
and etc. The friends and followers API methods can
return maximum 5,000 users. If a user has more than
5,000 friends or followers, only a partial list of friends
or followers can be extracted. Based on the observa-
tion, the medians of the number of friends and follow-
ers are around 300, so this constraint does not affect
the method significantly.
Another constraint of Twitter API methods is the
number of queries per hour. Currently the rate limit
for calls to the API is 150 requests per hour. This con-
strain affects the detection system significantly. To
collect data from different time and avoid congesting
Twitter, I crawl Twitter continuously and limit 120 re-
quests per hour per host.
5.2 Web Crawler
Although Twitter provides neat API methods for us,
there is no method that allows us to collect a spe-
cific unauthorized user’s recent tweets. The pub-
lic timeline API method can only return the most re-
cent update from different non-protected users (one
update per user). The user timeline API method can
return the 20 most recent tweets posted from an au-
thenticating user. The recent tweets posted by a user
are important to extract content-based features, such
as duplicate tweets. To solve this problem, a Web
crawler is developed to collect the 20 most recent
tweets of a specific non-protected user based on the
user’s ID on Twitter.
The public timeline API method is first used to
collect the user’s IDs of 20 non-protected users who
updated their status recently. Based on the user’s IDs,
the Web crawler extracts the user’s 20 most recent
tweets and saves it as a XML file.
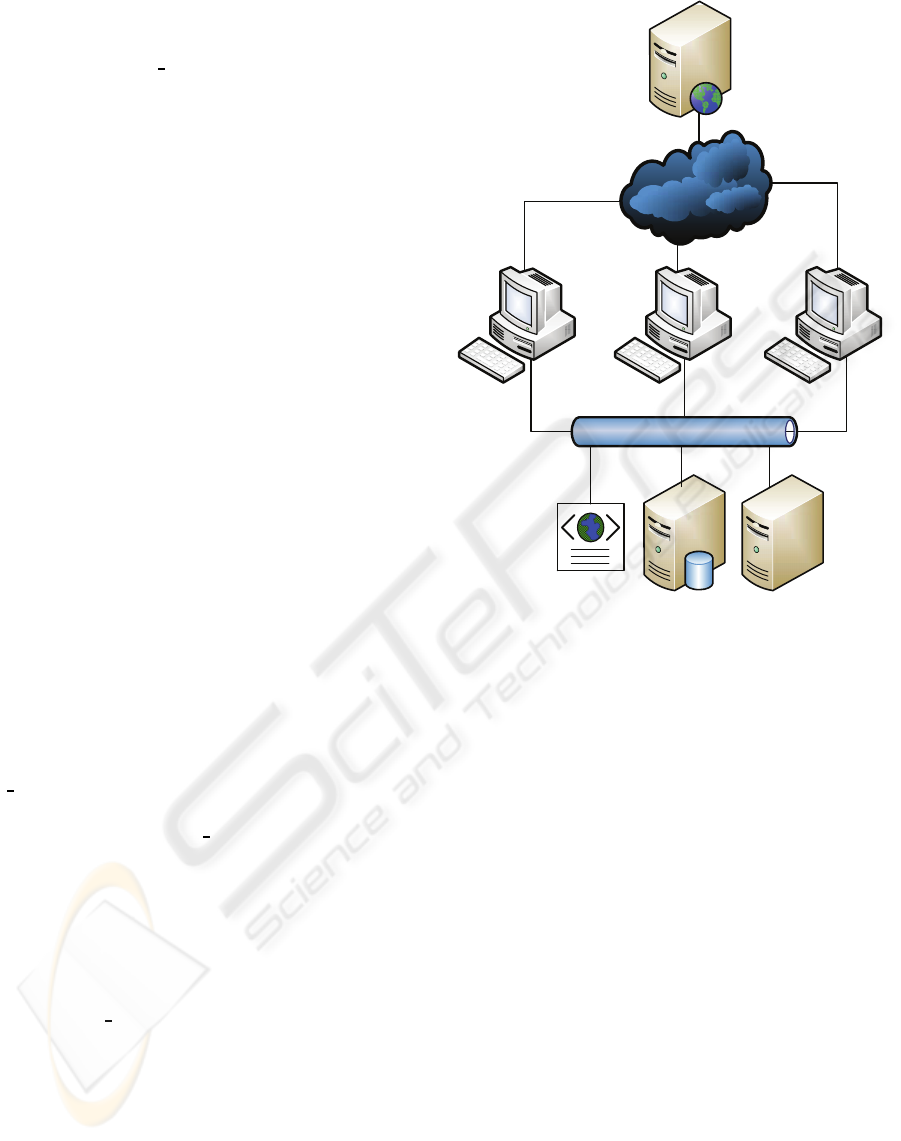
A prototype system structure is shown in Figure 5.
Currently 3 Web crawlers extract detailed user infor-
mation from Twitter website. The raw user tweets are
stored as XML files. Other user information, such as
IDs, list of friends and followers, are saved in a re-
lational database. The graph-based features are cal-
Web Crawler
Twitter Website
Relational
Database
XML files
Spam
Detector
Figure 5: Twitter spam detection system.
culated at the same time and stored in the relational
database. The XML files are parsed and the content-
based features are calculated. The results are saved in
the relational database.
Finally, I collect the data set for 3 weeks from
January 3 to January 24, 2010. Totally 25,847 users,
around 500K tweets, and around 49M follower/friend
relationships are collected from the public available
data on Twitter.
6 SPAM DETECTION
Several classic classification algorithms, such as de-
cision tree, neural network, support vector machines,
and k-nearest neighbors are compared. The na¨ıve
Bayesian classifier outperforms all other methods for
several reasons. First, Bayesian classifier is noise ro-
bust. On Twitter, the relationship between the feature
set and the spam is non-deterministic as discussed in
Section 4. An account cannot be predicted as spam
with certainty even though some of its features are
identical to the training examples. Bayesian classi-
DON'T FOLLOW ME - Spam Detection in Twitter
147
fier treats the non-deterministic relationship between
class variables and features as random variables and
captures their relationship using posterior probability.
While other methods cannot tolerate this kind of noisy
data or confounding factors, such as decision tree.
Another reason that Bayesian classifier has a bet-
ter performance is that the class label is predicted
based on user’s specific pattern. A spam probabil-
ity is calculated for each individual user based its be-
haviors, instead of giving a general rule. Also, na¨ıve
Bayesian classifier is a simple and very efficient clas-
sification algorithm.
The na¨ıve Bayesian classifier is based on the well-
known Bayes theorem:
P(Y|X) =
P(X|Y)P(Y)
P(X)
(2)
The conditional probability of P(Y|X) is also
known as the posterior probability for Y, as opposed
to its prior probability P(Y).
Each Twitter account is considered as a vector X
with feature values. The goal is to assign each ac-
count to one of two classes Y: spam and non-spam.
The big assumption of na¨ıve Bayesian classifier is
that the features are conditionally independent, al-
though research shows that it is “is surprisingly ef-
fective in practice” without the unrealistic indepen-
dence assumption (Rish, 2005). With the conditional
independence assumption, we can only estimate each
conditional probability independently, instead of try-
ing every combination of X.
To classify a data record, the posterior probability
is computed for each class:
P(Y|X) =
P(Y)
∏
d
i=1
P(X
i
|Y)
P(X)
(3)
Since P(X) is a normalizing factor which is equal
for all classes, we need only maximize the numerator
P(Y)
∏
d
i=1
P(X
i
|Y) in order to do the classification.
7 EXPERIMENTS
To evaluate the detection method, 500 Twitter user
accounts are labeled manually to two classes: spam
and non-spam. Each user account is manually evalu-
ated by reading the 20 most recent tweets posted by
the user and checking the friends and followers of
the user. The results show that there are around 1%
spam accounts in the data set. The study in (Analyt-
ics, 2009) shows that there is probably 3% spam on
Twitter. To simulate the reality and avoid the bias in
the crawling and label methods, additional spam data
are added to the data set. I search “@spam” on Twit-
ter to collect additional spam data. Only a small per-
centage of results report real spam. I clean the query
results by manually evaluating each spam report. Fi-
nally the data set is mixed to contain around 3% spam
data.
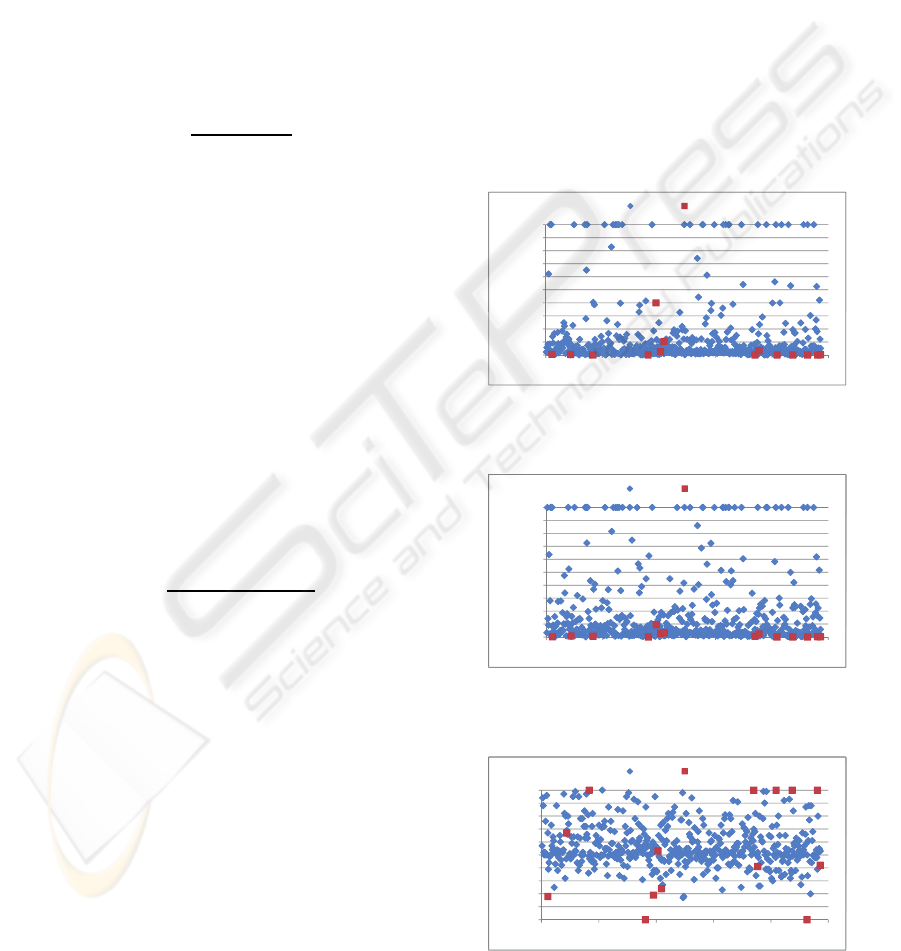
7.1 Data Analysis
Graph-based Features. Figure 6 show the graph-
based features proposed in Section 4.1. The number
of friends for each Twitter account is shown in Fig-
ure 6(a). Twitter spam policy says that “if you have a
small number of followers compared to the amount of
people you are following”, you may be considered as
a spam account. As can be seen, not all spam accounts
2000
2500
3000
3500
4000
4500
5000
m
ber of Friends
Non spam Spam
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 100 200 300 400 500
Number of Friends
Non spam Spam
(a) The number of friends (the maximum number
of friends is 5,000 which is the maximum return
value of Twitter friends API method).
5000
Non spam Spam
3500
4000
4500
5000
o
wers
Non spam Spam
2000
2500
3000
3500
4000
4500
5000
b
er of Followers
Non spam Spam
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
Number of Followers
Non spam Spam
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 100 200 300 400 500
Number of Followers
Non spam Spam
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 100 200 300 400 500
Number of Followers
Non spam Spam
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
0 100 200 300 400 500
Number of Followers
Non spam Spam
(b) The number of followers (the maximum num-
ber of followers is 5,000 which is the maximum
return value of Twitter followers API method).
100
Non spam Spam
70
80
90
100
(
%)
Non spam Spam
40
50
60
70
80
90
100
putation (%)
Non spam Spam
10
20
30
40
50
60
70
80
90
100
Reputation (%)
Non spam Spam
0
10
20
30
40
50
60
70
80
90
100
0 100 200 300 400 500
Reputation (%)
Non spam Spam
0
10
20
30
40
50
60
70
80
90
100
0 100 200 300 400 500
Reputation (%)
Non spam Spam
0
10
20
30
40
50
60
70
80
90
100
0 100 200 300 400 500
Reputation (%)
Non spam Spam
(c) The reputation.
Figure 6: Graph-based features.
SECRYPT 2010 - International Conference on Security and Cryptography
148

follow a large amount of user as we expected, instead
only 30% of spam accounts do that. The reason is that
Twitter allows users to mention or reply any other user
in their tweets. In other words, the spammers do not
need to follow legitimate user accounts to draw their
attention. The spammers can simply post spam tweets
and mention or reply another user in the @username
format in the tweets. These tweets will appear on the
user’s replies tab whose username is mentioned. In
this way, the spam tweets are sent out without actu-
ally following a legitimate user. The results show that
this is an efficient and common way to spam other
users as shown in Figure 4.
Figure 6(b) shows the number of followers for
each Twitter account. As we expected, usually the
spam accounts do not have a large amount of follow-
ers. But still I can find there are some spam accounts
having a relatively large amount of followers. They
may achieve that by letting other spam accounts to
follow them collusively or lure legitimate users to fol-
low them.
The reputation for each Twitter account is shown
in Figure 6(c). Surprisingly I find that some spam
accounts have a 100% reputation. The reason is as
mentioned above that the spam accounts do not have
to follow a legitimate user to send malicious tweets.
Because of this, some spam accounts do not have
a friend (d
O
(v
i
) = 0). However, the reputation fea-
ture shows the abnormal behaviors of spam accounts.
Most of them either have a 100% reputation or a very
low reputation. The reputation of most legitimate
users is between 30% to 90%.
Content-based Features. The content-based fea-
tures proposed in Section 4.2 are shown in Figure 7.
Twitter spam policy indicates that “multiple duplicate
updates on one account” is factor to detect spam. The
number of pairwise duplication in a user’s 20 most
recent tweets is shown in Figure 7(a). As expected,
most spam accounts have multiple duplicate tweets.
This is an important feature to detect spam. How-
ever, as shown in the figure, not all spam accounts
post multiple duplicate tweets. So we can not only
depend on this feature to detect spam.
The number of mentions and replies is shown in
Figure 7(b). As expected, most spam accounts have
the maximum 20 “@” symbol in their 20 most recent
tweets. This indicates that the spammers intend to
mention or reply legitimate users in their tweets to
gain attention. This will lure legitimate users to either
read their spam messages or even click the malicious
links in their tweets.
Figure 7(c) shows the number of links in each
user’s 20 most recent tweets. The results show that
most spam accounts have the maximum 20 links in
200
t
s
Non spam Spam
140
160
180
200
c
ate tweets
Non spam Spam
80
100
120
140
160
180
200
w
ise duplicate tweets
Non spam Spam
20
40
60
80
100
120
140
160
180
200
e
r of pairwise duplicate tweets
Non spam Spam
0
20
40
60
80
100
120
140
160
180
200
0 100 200 300 400 500
Number of pairwise duplicate tweets
Non spam Spam
0
20
40
60
80
100
120
140
160
180
200
0 100 200 300 400 500
Number of pairwise duplicate tweets
Non spam Spam
0
20
40
60
80
100
120
140
160
180
200
0 100 200 300 400 500
Number of pairwise duplicate tweets
Non spam Spam
(a) The number of pairwise duplications.
20
s
Non spam Spam
14
16
18
20
/
Mentions
Non spam Spam
8
10
12
14
16
18
20
o
f Replies/Mentions
Non spam Spam
2
4
6
8
10
12
14
16
18
20
N
umber of Replies/Mentions
Non spam Spam
0
2
4
6
8
10
12
14
16
18
20
0 100 200 300 400 500
Number of Replies/Mentions
Non spam Spam
0
2
4
6
8
10
12
14
16
18
20
0 100 200 300 400 500
Number of Replies/Mentions
Non spam Spam
0
2
4
6
8
10
12
14
16
18
20
0 100 200 300 400 500
Number of Replies/Mentions
Non spam Spam
(b) The number of mention and replies.
20
Non spam Spam
14
16
18
20
P
Links
Non spam Spam
8
10
12
14
16
18
20
e
r of HTTP Links
Non spam Spam
2
4
6
8
10
12
14
16
18
20
Number of HTTP Links
Non spam Spam
0
2
4
6
8
10
12
14
16
18
20
0 100 200 300 400 500
Number of HTTP Links
Non spam Spam
0
2
4
6
8
10
12
14
16
18
20
0 100 200 300 400 500
Number of HTTP Links
Non spam Spam
0
2
4
6
8
10
12
14
16
18
20
0 100 200 300 400 500
Number of HTTP Links
Non spam Spam
(c) The number of links.
20
Non spam Spam
14
16
18
20
htags
Non spam Spam
8
10
12
14
16
18
20
b
er of Hashtags
Non spam Spam
2
4
6
8
10
12
14
16
18
20
Number of Hashtags
Non spam Spam
0
2
4
6
8
10
12
14
16
18
20
0 100 200 300 400 500
Number of Hashtags
Non spam Spam
0
2
4
6
8
10
12
14
16
18
20
0 100 200 300 400 500
Number of Hashtags
Non spam Spam
0
2
4
6
8
10
12
14
16
18
20
0 100 200 300 400 500
Number of Hashtags
Non spam Spam
(d) The number of hashtags.
Figure 7: Content-based features.
their 20 most recent tweets. In other words, each
tweet contains a link for most spam accounts. How-
ever, the results also show that some legitimate users
also include links in all tweets. The reason is that
some companies join Twitter to promote their own
web sites. Usually they will include a link to their
own web page in each of their tweets.
Finally, Figure 7(d) shows the number of “#” tag
signs in each user’s 20 most recent tweets. Although
spamming Twitter trend topics is reported in news, I
DON'T FOLLOW ME - Spam Detection in Twitter
149
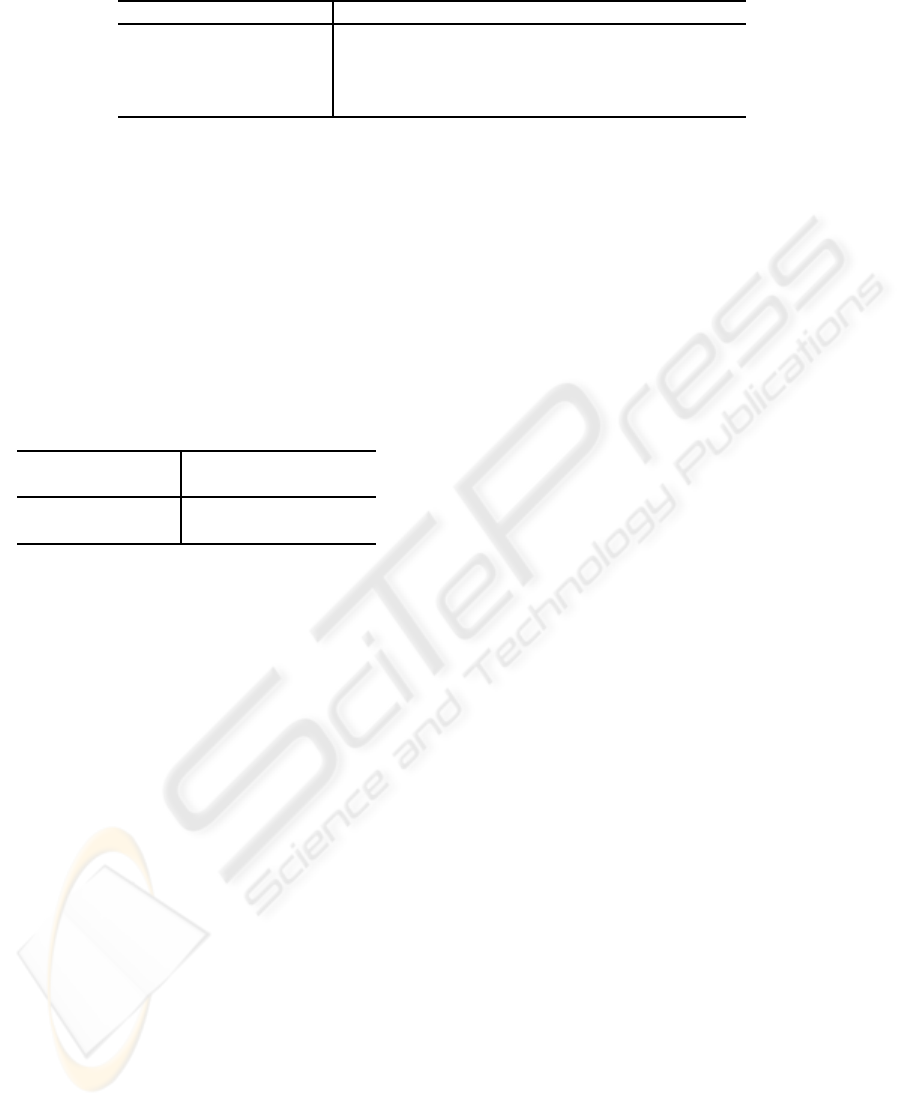
Table 1: Classification evaluation.
Classifier Precision Recall F-measure
Decision Tree 0.667 0.333 0.444
Neural Networks 1 0.417 0.588
Support Vector Machines 1 0.25 0.4
Na¨ıve Bayesian 0.917 0.917 0.917
cannot find that spammers attack trend topics in the
dataset. The reason is that this kind of attack usu-
ally occur in a very short period of time and does not
happen constantly on Twitter. It is difficult for us to
capture their trace. It does not mean that this kind of
attack is not common or not even exist.
7.2 Evaluation
The evaluation of the overall process is based on a
set of measures commonly used in machine learning
and information retrieval. Given a classification algo-
rithm, I consider its confusion matrix:
Prediction
Spam Not Spam
True Spam a b
Not Spam c d
where a represents the number of spam examples
that were correctly classified, b represents the spam
examples that were falsely classified as non-spam ,
c represents the number of non-spam examples that
were falsely classified as spam, and d represents the
number of non-spam examples that were correctly
classified. I consider the following measures: pre-
cision, recall, and F-measure where the precision is
P = a/(a + c), the recall is R = a/(a + b), and the
F-measure is defined as F = 2PR/(P+ R). For eval-
uating the classification algorithms, I focus on the F-
measure F as it is a standard way of summarizing both
precision and recall.
All the predictions reported in this paper are com-
puted using 10-fold cross validation. For each classi-
fier, the precision, recall, and F-measure are reported.
Each classifier is trained 10 times, each time using the
9 out of the 10 partitions as training data and comput-
ing the confusion matrix using the tenth partition as
test data. I then average the resulting ten confusion
matrices and estimate the evaluation metrics on the
average confusion matrix. The evaluation results are
shown in Table 1. The na¨ıve Bayesian classifier has
the best overall performance compared with other al-
gorithms, since it has the highest F score.
Finally, the Bayesian classifier learned from the
labeled data is applied to the entire data set. As men-
tioned in Section 5, information about totally 25,817
users was collected. It is nearly impossible for us
to label all the data. Instead I only manually check
the users who are classified as spam by the Bayesian
classifier. 392 users are classified as spam by the de-
tection system. I check the spam data by manually
reading their tweets and checking their friends and
followers. The results show that 348 users are real
spam accounts and 44 users are false alarms. This
means that the precision of the spam detection system
is 89% = 348/392.
8 CONCLUSIONS
In this paper, I study the spam behaviors in a popu-
lar online social networking site, Twitter. To formal-
ize the problem, a directed social graph model is pro-
posed. The “follower” and “friend” relationships are
defined in this paper. Based on the spam policy of
Twitter, novel content-based and graph-based features
are proposed to facilitate spam detection. Traditional
classification algorithms are applied to detect suspi-
cious behaviors of spam accounts. A Web crawler
using Twitter API methods is also developed to col-
lect real data set from public available information on
Twitter. Finally, I analyze the data set and evaluate
the performance of the detection system.
The results show that among the graph-based fea-
tures, the proposed reputation feature has the best per-
formance of detecting abnormal behaviors. No many
spam accounts follow large amount of users as we ex-
pected. Also some spammers have many followers.
For the content-based features, most spam ac-
counts have multiple duplicate tweets. This is an im-
portant feature to detect spam. However, not all spam
account post multiple duplicate tweets and some le-
gitimate users also post duplicate tweets. In this way
we can not only rely on this feature. The results also
show that almost all spam tweets contain links and
reply sign “@”.
Finally, several popular classification algorithms
are studied and evaluated. The results show that the
Bayesian classifier has a better overall performance
with the highest F score. The learned classifier is ap-
plied to large amount of data and achieve a 89% pre-
cision.
SECRYPT 2010 - International Conference on Security and Cryptography
150

REFERENCES
Analytics, P. (2009). Twitter study. http://www.
pearanalytics.com/wp-content/uploads/2009/08/
Twitter-Study-August-2009.pdf.
Benevenuto, F., Rodrigues, T., Almeida, V., Almeida, J.,
and Gonc¸alves, M. (2009). Detecting spammers and
content promoters in online video social networks.
In SIGIR ’09: Proceedings of the 32nd international
ACM SIGIR conference on Research and development
in information retrieval, pages 620–627, New York,
NY, USA. ACM.
Castillo, C., Donato, D., Gionis, A., Murdock, V., and Sil-
vestri, F. (2007). Know your neighbors: web spam
detection using the web topology. In SIGIR ’07: Pro-
ceedings of the 30th annual international ACM SIGIR
conference on Research and development in informa-
tion retrieval, pages 423–430, New York, NY, USA.
ACM.
CNET (2009). 4chan may be behind attack on twit-
ter. http://news.cnet.com/8301-13515 3-10279618-
26.html.
Geng, G.-G., Li, Q., and Zhang, X. (2009). Link based
small sample learning for web spam detection. In
WWW ’09: Proceedings of the 18th international con-
ference on World wide web, pages 1185–1186, New
York, NY, USA. ACM.
Gyongyi, Z., Berkhin, P., Garcia-Molina, H., and Pedersen,
J. (2006). Link spam detection based on mass esti-
mation. In VLDB ’06: Proceedings of the 32nd inter-
national conference on Very large data bases, pages
439–450. VLDB Endowment.
Gy¨ongyi, Z., Garcia-Molina, H., and Pedersen, J. (2004).
Combating web spam with trustrank. In VLDB ’04:
Proceedings of the Thirtieth international conference
on Very large data bases, pages 576–587. VLDB En-
dowment.
Krishnamurthy, B., Gill, P., and Arlitt, M. (2008). A few
chirps about twitter. In WOSP ’08: Proceedings of
the first workshop on Online social networks, pages
19–24, New York, NY, USA. ACM.
Levenshtein, V. I. (1966). Binary codes capable of correct-
ing deletions, insertions and reversals. Soviet Physics
Doklady, 10(8):707–710.
Nooy, W. d., Mrvar, A., and Batagelj, V. (2004). Ex-
ploratory Social Network Analysis with Pajek. Cam-
bridge University Press, New York, NY, USA.
Opera (2009). State of the mobile web. http://www.opera.
com/smw/2009/12/.
Rish, I. (2005). An empirical study of the naive bayes clas-
sifier. In IJCAI workshop on Empirical Methods in
AI.
Sahami, M., Dumais, S., Heckerman, D., and Horvitz, E.
(1998). A bayesian approach to filtering junk e-mail.
In AAAI Workshop on Learning for Text Categoriza-
tion.
Twitter (2009a). Restoring accidentally suspended ac-
counts. http://status.twitter.com/post/136164828/
restoring-accidentally-suspended-accounts.
Twitter (2009b). The twitter rules. http://help.twitter.com/
forums/26257/entries/18311.
Wang, A. H. (2010). Detecting spam bots in online social
networking websites: A machine learning approach.
In 24th Annual IFIP WG 11.3 Working Conference on
Data and Applications Security.
Yu-Sung, W., Bagchi, S., Singh, N., and Wita, R. (2009).
Spam detection in voice-over-ip calls through semi-
supervised clustering. In DSN ’09: Proceedings of the
2009 Dependable Systems Networks, pages 307 –316.
Zhou, D., Burges, C. J. C., and Tao, T. (2007). Transductive
link spam detection. In AIRWeb ’07: Proceedings of
the 3rd international workshop on Adversarial infor-
mation retrieval on the web, pages 21–28, New York,
NY, USA. ACM.
DON'T FOLLOW ME - Spam Detection in Twitter
151
