
ONTOLOGIES DERIVED FROM WIKIPEDIA
A Framework for Comparison
Alejandro Metke-Jimenez, Kerry Raymond and Ian MacColl
Faculty of Science and Technology, Queensland University of Technology, Brisbane, Australia
Keywords:
Ontology, Wikipedia.
Abstract:
Since its debut in 2001 Wikipedia has attracted the attention of many researchers in different fields. In recent
years researchers in the area of ontology learning have realised the huge potential of Wikipedia as a source
of semi-structured knowledge and several systems have used it as their main source of knowledge. However,
the techniques used to extract semantic information vary greatly, as do the resulting ontologies. This paper
introduces a framework to compare ontology learning systems that use Wikipedia as their main source of
knowledge. Six prominent systems are compared and contrasted using the framework.
1 INTRODUCTION
Ontologies play a central role not only in the Seman-
tic Web vision but also in other fields such as natu-
ral language processing and document classification.
However, there have been several criticisms of the
traditional, engineering-oriented approach to ontol-
ogy building and, therefore, considerable research has
been done in the area of automatic ontology learning
(Hepp, 2007).
Many researchers have started using Wikipedia
as the main source for ontology learning systems.
Wikipedia is an interesting resource because it is built
by the community so its overall structure has not been
imposed but, rather, reflects the consensus reached
by its users. Several approaches have been used to
extract semantic information from Wikipedia and the
type and quality of the ontologies that have been gen-
erated varies greatly. This paper addresses the re-
search question of how to compare these approaches.
Section 2 introduces the framework and explains
its dimensions in detail. Section 3 provides a descrip-
tion of the six systems that were selected for this anal-
ysis that use Wikipedia as their main source of infor-
mation and shows how these can be classified using
the framework. Section 4 discusses future work. Fi-
nally, Section 5 summarises the paper’s research con-
tributions.
2 A FRAMEWORK FOR
COMPARISON
Other frameworks to compare ontology learning sys-
tems have been developed in the past (Shamsfard
and Abdollahzadeh Barforoush, 2003; Zhou, 2007).
However,their dimensions fail to consider key aspects
that need to be taken into consideration when dealing
with a resource such as Wikipedia. The purpose of
the proposed framework is to enable an easy way to
compare current approaches that rely specifically on
Wikipedia. We propose a framework with the follow-
ing eight dimensions:
1. Type of ontology being generated
2. Wikipedia features used
3. Derived ontology elements
4. Additional sources used
5. Extraction mechanism
6. Natural language independence
7. Degree of automation
8. Evaluation method
Each dimension is explained in detail in the rest of
this section.
2.1 Type of Ontology being Generated
The term ontology comes from the field of philoso-
phy but it has been borrowed by the computer sci-
ence community. Depending on the field, the exact
382
Metke-Jimenez A., Raymond K. and MacColl I..
ONTOLOGIES DERIVED FROM WIKIPEDIA - A Framework for Comparison.
DOI: 10.5220/0003094003820387
In Proceedings of the International Conference on Knowledge Engineering and Ontology Development (KEOD-2010), pages 382-387
ISBN: 978-989-8425-29-4
Copyright
c
2010 SCITEPRESS (Science and Technology Publications, Lda.)

meaning of ontology can be slightly different. Many
researchers refer to the term vaguely, usually citing
Gruber’s definition that states that an ontology is a
“specification of a set of shared concepts and their re-
lationships in some domain” (Gruber, 1993). We be-
lieve that in the context of the proposed framework, it
is necessary to refer to a definition that is much more
specific. We propose classifying ontologies based on
their goal since we believe this is what defines their
characteristics. The following is the classification we
use in the framework.
An Association Ontology is the most basic type of
ontology and its goal is to provide measures of
semantic relatedness between its resources (con-
cepts, individuals, or both). Its relationships have
no type but typically include a numeric value to
indicate a degree of relatedness between the con-
nected resources.
Lexical Ontologies focus on including several lex-
ical representations of concepts and individuals
and also is-a relationships between them. These
ontologies are used to assist in natural language
processing tasks where the word disambiguation
problem is a major challenge.
Classification Ontologies are used to classify re-
sources. These ontologies include is-a relation-
ships and a large set of concepts and individuals.
When a concept in an ontology is used to classify
some resource, the user is indicating that the re-
source is about that concept.
Representational Ontologies are used to provide an
abstract representation of some reality. These
are usually fine-grained and specific to some do-
main. Relationships are usually more complex
than the ones found in classification ontologies,
since modelling a domain often requires express-
ing additional conditions and restrictions that go
beyond the simple taxonomic ones. However,
these ontologies do not require complex reason-
ing since it is not the intention of the modellers to
be able to derive new knowledge from the ontol-
ogy.
Knowledge Repositories are used to answer seman-
tically rich queries. These ontologies enable auto-
mated reasoning, comparable to a human expert,
and therefore require different types of relation-
ships, axioms, and complex reasoning. In prac-
tice, complex reasoning is very expensive compu-
tationally so these ontologies are restricted either
in size or in complexity.
2.2 Wikipedia Features Used
This dimension is concerned with the Wikipedia fea-
tures being used as sources of semantic information.
A good review of Wikipedia’s most important fea-
tures can be found in (Medelyan et al., 2009).
2.3 Derived Ontology Elements
Ontologies are composed of different elements and
also have different levels of expressiveness. Every ap-
proach deals at least with the extraction of concepts
and relationships between them. For example, a sim-
ple way of deriving the concepts of an ontology is by
creating one for each article in Wikipedia.
2.4 Additional Sources Used
Even though Wikipedia is a good source of semantic
information, many research projects have chosen to
use additional sources to improve the quality of the
generated ontology.
2.5 Extraction Mechanism
This dimension is concerned with the actual mecha-
nism used to extract the information from Wikipedia
(and possibly other sources) and turn it into an on-
tology. Several different techniques have been used
for this purpose and can be classified in the following
major categories:
Linguistic Analysis relies on natural language pro-
cessing and typically do not make use of
Wikipedia’s special features (it is treated just like
regular text).
Rule-based Methods define rules based on common
patterns observed in Wikipedia.
Statistical Methods are based on statistical informa-
tion (such as word co-ocurrence, for example).
Machine Learning Approaches use either super-
vised or unsupervised machine learning tech-
niques to extract or derive new semantic informa-
tion.
Connectivity-based Algorithms make use of the in-
ternal links in Wikipedia in order to treat it like
a graph in which the articles represent the nodes
and the links represent the edges.
Transformation-based methods use structured or
semi-structured information and define rules to
transform it to elements in the target ontology.
ONTOLOGIES DERIVED FROM WIKIPEDIA - A Framework for Comparison
383

2.6 Natural Language Independence
This dimension is closely related to the extraction di-
mension since it refers to the applicability of the ap-
proach to sources in a language different than the one
the approach was originally designed to work with.
2.7 Degree of Automation
This dimension is concerned with the degree of man-
ual intervention required for the approach to work
and has the following possible values: manual, semi-
automatic, or fully automatic.
2.8 Evaluation Method
This dimension classifies the approach used to evalu-
ate the generated ontology. These approaches can be
classified in four main categories (Brank et al., 2005):
Comparative methods, where the ontology is com-
pared with a “gold standard”.
Proxied methods, where the results of using the on-
tology in an application domain (such as docu-
ment classification) are compared.
Data-based methods, where the“fit” of the ontology
to a domain is measured from a source of data
(such as a collection of documents).
Human-assessed methods, where the quality of the
ontology is evaluated by a group of people against
some predefined criteria.
3 USING OUR FRAMEWORK
A considerable amount of research has been de-
voted to the extraction of semantic information from
Wikipedia using various approaches (a good review
can be found in (Medelyan et al., 2009)). Our frame-
work is useful to classify ontology learning systems
that use Wikipedia as their main source of informa-
tion. Using the framework allows understanding how
these systems work and identifying gaps that might be
exploited to improve the content of the generated on-
tologies. This section shows the results of using the
framework to classify six systems. Table 1 shows a
summary of the results.
3.1 DBpedia
The DBpedia project focuses on extracting simple se-
mantic information from Wikipedia’s structure and
templates in the form of RDF triples (Auer et al.,
2008). The DBpedia dataset contains about 103 mil-
lion RDF triples. Some of these include very specific
information (mainly from the data extracted from the
infoboxes) and some include metadata (such as the
page links between Wikipedia articles). The dataset
is available on the group’s web page.
The goal of DBpedia is to create a knowledge
repository with general knowledge extracted from
Wikipedia. It uses two main sources of information:
database dumps and the page templates. The relation-
ships extracted from the database dumps are untyped
and only indicate that an article is related somehow to
the articles to which it is linked. The templates allow
extracting both attributes and several typed relation-
ships, mainly from individuals.
3.2 Wikipedia Thesaurus
The Wikipedia Laboratory group created an asso-
ciation thesaurus from Wikipedia by using several
techniques that calculate the semantic relatedness be-
tween articles (Ito et al., 2008). The thesaurus is avail-
able on the group’s web page.
An association thesaurus contains concepts and
relationships between them, with a numeric value that
indicates how close the concepts are semantically.
The researchers use several techniques to achieve the
same result. One of these, known as pfibf (Path Fre-
quency - Inversed Backward link Frequency), uses
Wikipedia’s internal links to derive the relatedness
measure. It is similar to the traditional tfidf (Term
Frequency - Inverse Document Frequency) method
used in data mining, but specifically designed to deal
with Wikipedia’s structure. Another method is based
on link co-ocurrence analysis. In this approach the
relatedness measures are calculated based on the co-
occurrence of pairs of links in the articles.
The resulting thesaurus was assessed by humans
and also compared with a “gold standard” for word
similarity.
3.3 WikiNet
The EML Research group created a large scale, multi-
lingual concept network (Nastase et al., 2010). The
resource consists of language-independent concepts,
relationships between them, and their corresponding
lexical representations in different languages. The
dataset is available on the group’s web page.
The multi-lingual concept network is similar to
WordNet, but derived automatically from Wikipedia.
It is not intended to replace WordNet but rather to
complement it, since WordNet has limited coverage
despite its high quality.
KEOD 2010 - International Conference on Knowledge Engineering and Ontology Development
384
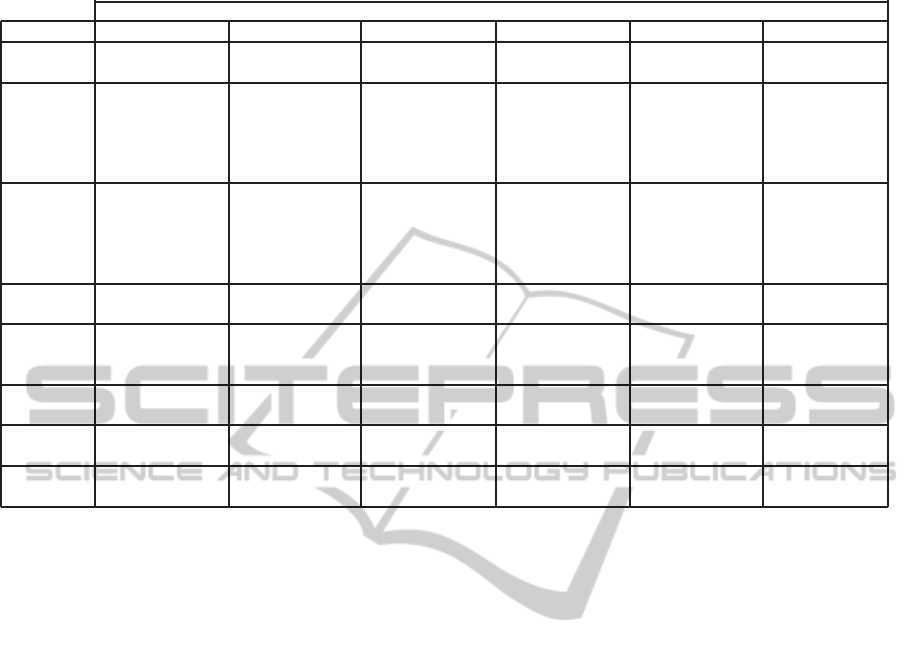
Table 1: Results of applying the framework to the six selected systems.
System
Dimension DBPedia WikipediaThesaurus WikiNet YAGO WikiOnto WikiTaxonomy
Type of Knowledge repository Association Lexical Knowledge repository Representational Classification
Ontology
Derived Concepts Concepts Concepts Concepts Concepts Concepts
Elements Individuals Numeric relations Individuals Attributes Individuals Individuals
Attributes Is-a relations Is-a relations Is-a relations Is-a relations
Untyped relations Instance-of relations Instance-of relations Instance-of relations
Other relations Other relations Other relations
Wikipedia Articles Articles Articles Infoboxes Articles Categories
Features Internal links Article text Categories Categories Internal links Internal links
Templates Internal links Internal links Redirects Sections Article text
Cross-language links
Disambiguation pages
Additional None None None WordNet WordNet None
Sources
Extraction Transformation-based Statistical methods Linguistic analysis Rule-based Transformation-based Linguistic analysis
Mechanism Connectivity-based Transformation-based Machine learning Connectivity-based
Statistical methods Linguistic analysis Rule-based
Language Partial Yes Yes Yes Partial Partial
Independence
Degree of Automatic Automatic Automatic Automatic Assisted Automatic
Automation
Evaluation Not specified Human assessed Human assessed Human assessed Not specified Comparative
Method Comparative Comparative
Several Wikipedia features are used to derive the
content of the network. Articles and categories are
used to derive concepts. In order to derive relations,
syntactic analysis is performed on category names to
extract relations and these are propagated to their ar-
ticles. Information found in infoboxes is also used
to further type these relationships. Finally, cross-
language links are used to create an index that in-
cludes the different language representations of each
concept.
The resulting concept network was evaluated by
comparing it with Cyc and YAGO. The comparison
was performed both manually and automatically.
3.4 YAGO
YAGO (Yet Another Great Ontology) is a project that
aims to create a huge general-purpose ontology that
includes both concepts and named/entities (Suchanek
et al., 2008). The ontology can be accessed through
several front ends and can also be downloaded from
the project’s web page.
The authors use different heuristics to extract at-
tributes and relationships from the infoboxes of the
articles, deduce types based on Wikipedia’s category
network, and extract is-a relations. Also, Word-
Net is used as the source for an organised taxonomy
in which the concepts extracted from Wikipedia are
placed. WordNet synsets are used to derive the mean-
ing of Wikipedia concepts, using Wikipedia redirects
to find alternative names for entities, and applying
heuristics based on the Wikipedia categories to extract
additional information.
The resulting ontology was assessed by present-
ing the facts to human judges for evaluation. For each
fact the judges could select if the fact was correct, in-
correct, or that they did not know.
3.5 WikiOnto
The goal of the WikiOnto project is not to create
an ontology but to provide an environment to assist
in the extraction and modelling of ontologies, using
Wikipedia as the main source of information (Silva
and Jayaratne, 2009). Even though the goal of the
project is not to create an ontology, it was included
in the evaluation because it can be considered a semi-
automatic approach to ontology building.
The environment enables users to choose an arti-
cle of interest as the starting point and it provides sug-
gestions of other concepts that might be relevant to
include in the ontology using clustering techniques.
The ontology builder can add new concepts to the
ontology and then specify the relationships between
them. The authors plan to implement syntactic anal-
ysis in order to suggest relations between concepts
other than is-a.
ONTOLOGIES DERIVED FROM WIKIPEDIA - A Framework for Comparison
385

Table 2: Derived elements and Wikipedia features used in the evaluated systems.
Derived Element
Concepts & Relations
Wikipedia Feature Individuals Attributes Untyped Numeric Is-a Instance-of Other
Articles
Title D, T, N, Y, O
Definition Sentence
Overview Paragraph
Sections O O
Text T X X
Templates D D
Infoboxes N, Y
Internal Links O D T O
External Links
Cross-language Links N
Category Links N Y
Categories
Title N, X N, Y, X X
Text
Parent Categories N, X X
Cross-language Links N
Redirects Y
Disambiguation Pages N
Edit Histories
Discussion Pages
D = DBpedia, T = Wikipedia Thesaurus, N = WikiNet, Y = YAGO, O = WikiOnto, X = WikiTaxonomy
3.6 WikiTaxonomy
WikiTaxonomy is an ontology derived from
Wikipedia’s category structure. It includes con-
cepts, individuals, and simple taxonomic relations
(Ponzetto and Strube, 2008). The ontology is
available in RDFS format.
The authors use a combination of connectivity-
based methods and linguistic-based methods to derive
is-a relations between Wikipedia categories. These
relations are then propagated using inference-based
methods. Finally, concepts and individuals are identi-
fied by using several heuristics.
4 FUTURE WORK
By analysing the cross-product between the frame-
work’s derived elements and Wikipedia features di-
mensions it is easy to identify which Wikipedia fea-
tures have been used to derivecertain type of semantic
information. Table 2 shows the result of applying this
cross-product to the six systems that were previously
classified with the framework. Future work will in-
volve using this information to identify new sources
of semantic information and deriving new mecha-
nisms to exploit it.
5 CONCLUSIONS
This paper introduces a framework to compare ap-
proaches to deriving ontologies automatically or
semi-automatically from Wikipedia. Six prominent
systems are classified using the framework and their
most relevant characteristics are summarised. Finally,
the cross-product of two of the framework’s dimen-
sions is used to show how new sources of semantic
information in Wikipedia can be identified.
ACKNOWLEDGEMENTS
This research is supported in part by the CRC Smart
Services, established and supported under the Aus-
tralian Government Cooperative Research Centres
Programme, and a Queensland Universityof Technol-
ogy scholarship.
REFERENCES
Auer, S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak,
R., and Ives, Z. (2008). Dbpedia: A nucleus for a
web of open data. In The Semantic Web, volume
KEOD 2010 - International Conference on Knowledge Engineering and Ontology Development
386

4825/2008, pages 722–735. Springer Berlin / Heidel-
berg.
Brank, J., Grobelnik, M., and Mladeni´c, D. (2005). A sur-
vey of ontology evaluation techniques. In Proceedings
of the Conference on Data Mining and Data Ware-
houses (SiKDD 2005).
Gruber, T. R. (1993). A translation approach to portable
ontology specifications. Knowledge Acquisition,
6(2):199–221.
Hepp, M. (2007). Possible ontologies: How reality con-
strains the development of relevant ontologies. IEEE
Internet Computing, 11(1):90–96.
Ito, M., Nakayama, K., Hara, T., and Nishio, S. (2008).
Association thesaurus construction methods based on
link co-occurrence analysis for wikipedia. In Pro-
ceeding of the 17th ACM Conference on Information
and Knowledge Management, Napa Valley, Califor-
nia, USA. ACM.
Medelyan, O., Milne, D., Legg, C., and Witten, I. H. (2009).
Mining meaning from wikipedia. International Jour-
nal of Human-Computer Studies, 67(9):716–754.
Nastase, V., Strube, M., Boerschinger, B., Zirn, C., and El-
ghafari, A. (2010). Wikinet: A very large scale multi-
lingual concept network. In Proceedings of the Sev-
enth conference on International Language Resources
and Evaluation (LREC’10), Valletta, Malta. European
Language Resources Association (ELRA).
Ponzetto, S. and Strube, M. (2008). WikiTaxonomy: A
large scale knowledge resource. In Proceeding of the
2008 conference on ECAI 2008: 18th European Con-
ference on Artificial Intelligence, pages 751–752. IOS
Press.
Shamsfard, M. and Abdollahzadeh Barforoush, A. (2003).
The state of the art in ontology learning: a framework
for comparison. Knowl. Eng. Rev., 18(4):293–316.
Silva, L. N. D. and Jayaratne, L. (2009). Wikionto: A
system for semi-automatic extraction and modeling of
ontologies using wikipedia xml corpus. International
Conference on Semantic Computing, 0:571–576.
Suchanek, F. M., Kasneci, G., and Weikum, G. (2008).
Yago: A large ontology from wikipedia and wordnet.
Web Semantics: Science, Services and Agents on the
World Wide Web, 6(3):203–217.
Zhou, L. (2007). Ontology learning: state of the art and
open issues. Information Technology and Manage-
ment, 8(3):241–252.
ONTOLOGIES DERIVED FROM WIKIPEDIA - A Framework for Comparison
387
