
DYNAMIC QUERY EXPANSION BASED ON USER’S REAL TIME
IMPLICIT FEEDBACK
Sanasam Ranbir Singh
Department of CSE, Indian Institute of Technology Guwahati, Assam, India
Hema A. Murthy
Department of CSE, Indian Institute of Technology Madras, Tamil Nadu, India
Timothy A. Gonsalves
Department of CSE, Indian Institute of Technology Mandi, Himachal Pradesh, India
Keywords:
Query expansion, Real time implicit feedback, Query log, Relevant term, Search engine.
Abstract:
Majority of the queries submitted to search engines are short and under-specified. Query expansion is a com-
monly used technique to address this issue. However, existing query expansion frameworks have an inherent
problem of poor coherence between expansion terms and user’s search goal. User’s search goal, even for the
same query, may be different at different instances. This often leads to poor retrieval performance. In many
instances, user’s current search is influenced by his/her recent searches. In this paper, we study a framework
which explores user’s implicit feedback provided at the time of search to determine user’s search context. We
then incorporate the proposed framework with query expansion to identify relevant query expansion terms.
From extensive experiments, it is evident that the proposed framework can capture the dynamics of user’s
search and adapt query expansion accordingly.
1 INTRODUCTION
Term mismatch between query terms and document
terms is an inherent problem that affects the precision
of an information retrieval (IR) system. Majority of
the queries submitted to Web search engines (WSE)
are short and under-specified (Jansen et al., 2000;
Craig et al., 1999). Short queries usually lack suffi-
cient words to capture relevant documents and thus
negatively affect the retrieval performance. Query
expansion (QE) is a technique that addresses this is-
sue (Xu and Croft, 1996), where original query is sup-
plemented with additional related terms or phrases.
Existing query expansion frameworks have the
problem of poor coherence between expansion terms
and user’s search goal. For instance, if the query
jaguar
be expanded as the terms {
auto
,
car
,
model
,
cat
,
jungle
,...} and user is looking for documents
related to
car
, then the expansion terms such as
cat
and
jungle
are not relevant to user’s search goal.
The simplest way to determine user’s search goal
is to ask users for explicit inputs at the time of search.
Unfortunately, majority of the users are reluctant to
provide any explicit feedback (Carroll and Rosson,
1987). The retrieval system has to learn user’s pref-
erences automatically without any explicit feedback
from the user. Query log is a commonly used re-
source to determine user’s preferences automatically
without any overhead to the user (Kelly and Tee-
van, 2003; Agichtein et al., 2006; Joachims, 2002).
However, such studies are not flexible enough to cap-
ture the changing needs of users over time. If we
want to model the complete dynamics of user’s prefer-
ences from query log, we will need an extremely large
query log and huge computational resources. More-
over, user may always explore new search areas. This
makes the task of modelling user’s search dynamics
an extremely difficult and expensive problem.
In this paper, we study a framework to expand
user’s search query dynamically based on user’s im-
plicit feedback provided at the time of search. It is ev-
ident from the analysis that, in many instances, user’s
112
Ranbir Singh S., A. Murthy H. and A. Gonsalves T..
DYNAMIC QUERY EXPANSION BASED ON USER’S REAL TIME IMPLICIT FEEDBACK.
DOI: 10.5220/0003104901120121
In Proceedings of the International Conference on Knowledge Discovery and Information Retrieval (KDIR-2010), pages 112-121
ISBN: 978-989-8425-28-7
Copyright
c
2010 SCITEPRESS (Science and Technology Publications, Lda.)

implicit feedback provided at the time of search pro-
vides sufficient clues to determine what user wants.
For example, if the query
jaguar
is submitted im-
mediately after the query
national animals
, it is
very likely that user is looking for the information re-
lated to
animal
. Such a small feedback can provide
a very strong clue to determine user’s search prefer-
ence. This is the main motivation of this paper. From
extensive experiments, it is evident that the proposed
framework has the potential to expand user’s queries
dynamically based on user’s search pattern.
1.1 Problem Statement
Let q be a query and E
(q)
= { f
q,1
, f
q,2
, f
q,3
, ...} be
the set of expansion terms for the query q returned
by a traditional query expansion mechanism. In gen-
eral, many of these expansion terms are not relevant
to user’s search goal. Now, the task is to identify
the expansion terms in E
(q)
which are relevant to
user’s search goal by exploiting user’s implicit feed-
back provided by the user at the time of search.
The rest of the paper is organized as follows. In
Section 2, we then discuss background materials. In
Section 3, we present few observations of query log
analysis which inspire the proposed framework. In
Section 4, we discuss our proposed query expansion
framework. Section 5 discusses evaluation method-
ologies. Section 6 present experimental observations.
The paper concludes in Section 7.
2 BACKGROUND MATERIALS
2.1 Notations and Definitions
2.1.1 Vector Space Model
We use the vector space model (Salton et al., 1975)
to represent a query or a document. A document d or
a query q is represented by a term vector of the form
d = {w
(d)
1
, w
(d)
2
, ..., w
(d)
m
} or q = { w
(q)
1
, w
(q)
2
, ..., w
(q)
m
},
where w
(d)
i
and w
(q)
i
are the weights assigned to the i
th
element of the set d and q respectively.
2.1.2 Cosine Similarity
If v
i
and v
j
are two arbitrary vectors, we use co-
sine similarity to define the similarity between the
two vectors. Empirically, cosine similarity can be ex-
pressed as follows.
sim(v
i
, v
j
) =
∑
m
k=0
w
ik
.w
jk
q
∑
m
k=0
w
2
ik
.
q
∑
m
k=0
w
2
jk
(1)
2.1.3 Kullback-Leibler Divergence (KLD)
Given two probability distributions p
i
and p
j
of a ran-
dom variable, the distance between p
i
and p
j
can be
defined by Kullback-Leibler divergence as follows.
KLD(p
i
||p
j
) = p
i
. log
p
i
p
j
(2)
2.1.4 Density based Term Association
In the study (Ranbir et al., 2008), a density based term
association (DBTA) is proposed to estimate the term
associations. We also use the same estimator in this
paper. IfW denotes a collection of terms and t f(x,W)
denotes term frequency of a term x in W, then the
density of word x in W is defined as
d(x,W) =
t f (x,W)
|W|
(3)
Further, the combine density of two terms x and y oc-
curring together in W is defined as follows.
d({x, y},W) =
min(t f(x,W),t f (y,W))
|W| − min(t f(x,W), t f(y,W))
(4)
Let λ(x) represents the set of windows
1
containing
the word x and λ(x, y) represents the set of windows
containing both the words x and y. Given a corpora of
windows, the relative density score of x and y together
in a window is defined as
rd(x, y) =
C
A+ B −C
(5)
where C =
∑
W
i
∈λ(x,y)
d({x, y},W
i
), A =
∑
W
i
∈λ(x)
d(x,W
i
) and B =
∑
W
i
∈λ(y)
d(y,W
i
). The
rd(x, y) represents how large is the amount of infor-
mation shared between x and y relative to the space
covered by x and y. Further, the probability of a word
y given a word x is defined as follows.
Pr(y|x) =
∑
W
i
∈λ(x,y)
d({x, y},W
i
)
∑
W
i
∈λ(x)
d(x,W
i
)
(6)
This probability represents how confidently one word
associates with another word. Now, Equations (5)
and (6) are combined to define DBTA between two
words x and y as follows
DBTA(x, y) = Pr(x|y).rd(x, y).Pr(y|x) (7)
2.1.5 Real Time Implicit Feedback (RTIF)
In this paper, we differentiate two types of implicit
feedback; history and active. The active implicit feed-
back are the feedback provided by user at the time of
1
A window refers to a document or a set of sentences.
DYNAMIC QUERY EXPANSION BASED ON USER'S REAL TIME IMPLICIT FEEDBACK
113

search. We also refer to it by real time implicit feed-
back in this paper. A query session has been defined
differently in different studies (Jansen et al., 2000;
Jaime et al., 2007). This paper considers the defini-
tion discussed in (Jansen et al., 2000) and defines as a
sequence of query events submitted by a user within
a pre-defined time frame. Any feedback provided be-
fore the current query session is considered history.
2.2 Background on QE
Global analysis (Jones, 1971; Qiu and Frei, 1993) is
one of the first QE techniques where a thesaurus is
built by examining word occurrences and their rela-
tionships. It builds a set of statistical term relation-
ships which are then used to select expansion terms.
Although global analysis techniques are relatively ro-
bust, it consumes a considerable amount of computa-
tional resources to estimate corpus-wide statistics.
Local analysis techniques use only a subset of the
document that is retrieved through an initial ranking
by the original query. Thus, it focuses only on the
given query and its relevant documents. A number
of studies including the ones in (Xu and Croft, 1996;
Xu and Croft, 2000; Attar and Fraenkel, 1977; Croft
and Harper, 1979) indicate that local analysis is ef-
fective, and, in some cases, outperforms global anal-
ysis. However, local analysis based query expansion,
even with the best of methods, has an inherent inef-
ficiency for reformulating a query, that is, additional
online processing for mining expansion terms (Biller-
beck and Zobel, 2005).
The above studies focus on document side analy-
sis and they do not take the query side analysis into
account. Thus they, in fact, do not address the prob-
lem of poor coherence between expansion terms and
user’s search goal. This paper addresses this issue
by exploring user’s implicit feedback provided by the
user’s in real time.
3 FEW MOTIVATING
OBSERVATIONS
3.1 Query Log Vs Academic Research
After the AOL incident in August 2006
2
, no query
logs are available publicly (not even for academic
researches). Obtaining query log from commercial
search engines had always been a very difficult task
to academic research communities. One alternative
2
http://www.nytimes.com/2006/08/09/technology/
09aol.html
Table 1: Characteristics of the clicked-through log dataset.
Source Proxy logs
Search Engine Google
Observation Periods 3 months
# of users 3182
# of query instances 1,810,596
% of clicked queries 53.2%
Figure 1: Pictorial representation of the query sessions.
for research communities to obtain query log is to
use organizational local proxy logs. From the proxy
logs, we can extract in-house click-through informa-
tion such as user’s id, time of search, query, click doc-
uments and the rank of the clicked documents.
In this study, we use a large proxy log of three
months. We extract the queries submitted by the
users to google search engine and users’ clicked re-
sponses to the results. Table 1 shows the characteris-
tics of the click-through query log extracted from the
three-months long proxy logs. To prove that the In-
House query log has similar characteristics with that
of server side query log, we also analyse AOL query
log. The analysis described in this paper is strictly
anonymous; data was never used to identify any iden-
tity.
3.1.1 Constructing Query Session
For every user recorded in the query log, we extract
sequence of queries submitted by the user. Figure 1
shows a pictorial representation of the procedure to
construct query sessions. The upper arrows ↑ repre-
sent the arrival of the query events. Each session is
defined by the tuple Γ =< t
e
1f
, uid, E, δ >. Just before
the arrival of first query from the user u, the first query
session has an empty record i.e., Γ =< φ, u, φ, δ >.
When user u submits his/her first query q, Γ is up-
dated as Γ =< t
e
1f
, u, E, δ >, where E = {e
1
}, e
1
=<
t
e
1f
,t
e
1l
, q
1
, φ >, q
1
= q and t
e
1f
= t
e
1l
. The down ar-
rows ↓ in the Figure 1 represent the clicked events.
As user clicks on the results for the query q
1
, e
1
gets
updated as e
1
=< t
e
1f
,t
e
1l
, q
1
, D
(q
1
)
> where D
(q
1
)
is
the set of clicked documents and t
e
1l
is the time of the
last click.
When the second query q is submitted by the user
u, it forms the second event e
2
=< t
e
2f
,t
e
2l
, q
2
, φ >,
KDIR 2010 - International Conference on Knowledge Discovery and Information Retrieval
114
0
10
20
30
40
50
60
1(0.75-1)(0.5-0.75](0.25-0.5](0-0.25]0
% of query instances
Similarity ranges
Similarity between consecutive queries
AOL
In-House
(a)
0
10
20
30
40
50
60
1(0.75-1)(0.5-0.75](0.25-0.5](0-0.25]0
% of query instances
Similarity ranges
Average similarity between a query and its previous queries
AOL
In-House
(b)
Figure 2: Similarity between the queries in a query session.
where q
2
= q and t
e
2f
= t
e
2l
. If t
e
2f
− t
e
1l
≤ δ, then e
2
is inserted into Γ and E is updated as E = {e
1
, e
2
}. If
t
e
2f
−t
e
1l
> δ, then e
2
can not be fitted in current query
session Γ. In such a case, e
2
generates a new query
session with e
2
as its first event i.e., e
2
becomes e
1
and
E = {e
1
} in the new query session. We, then, shift the
current session Γ to the newly formed session. In this
way, we scan the entire query sequence submitted by
the user u and generate the query sessions.
3.2 Exploring Recent Queries
To form the basis of the proposed framework, we
analyse two characteristics of user’s search patterns
during a short period of time defined by a query
session: (a) similarity between recently submitted
queries and (b) user’s topic dynamics.
3.2.1 Similarity between Queries
In this section, we estimate average similarity be-
tween the queries submitted during a query session
0
10
20
30
40
50
1 2 3 >4
% of query sessions
# categories
In-House
AOL
Figure 3: Distribution of the query session with the number
of class labels of the visited documents.
(defined by δ = 30min) using cosine similarity de-
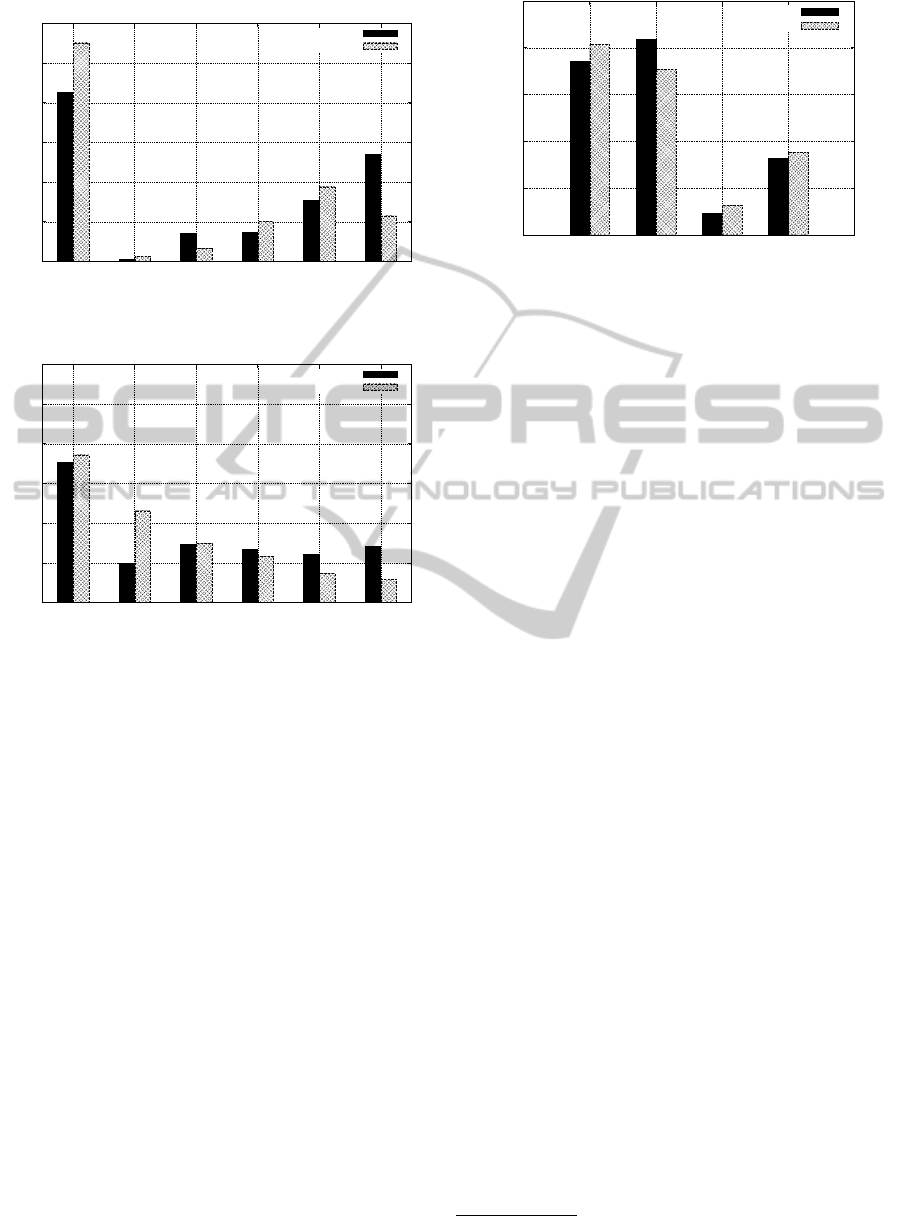
fined in Equation (1). Figure 2.(a) shows that almost
55% of the consecutive queries have non-zero simi-
larity (58% for AOL).
Further in Figure 2.(b), we report the average sim-
ilarity between a query and its previous queries in a
session. Almost 65% of the queries have similarity
larger than 0. It suggests that a significant number
of queries in a session share common search con-
text. Further, two queries with similar search con-
text may have similarity 0. For example, the queries
madagascar
and
die hard 2
. Although, both the
queries means movies, their similarity is 0. There-
fore, the plots in Figure 2 represent the lower bound.
3.2.2 Topic Dynamics
We further study the distribution of the categories of
the documents that user visits during a query session.
To study topic dynamics of the user, we first need to
assign a label to each of the visited documents. For
this task, we have employed a seed-based classifier
(the same classifier discussed in (Ranbir et al., 2010))
built over Open Directory Project
3
(ODP). We clas-
sify each visited document by the top 15 class labels
of ODP.
Figure 3 shows the distribution of the topics that
users explore in each query session. It clearly sug-
gests that users visit documents belonging to one or
two categories in majority of the query sessions. Only
in around 21% of total query sessions for In-House
query log (around 24% for AOL query log), users ex-
plore more than two categories.
Remarks:
The above observations (similarity and
topic dynamics) show that, in many instances, queries
in a session often share common search context. This
3
www.dmoz.org
DYNAMIC QUERY EXPANSION BASED ON USER'S REAL TIME IMPLICIT FEEDBACK
115
Baseline IR
Baseline QE
processing real time
implicit feedback
User’s Search
Context Extraction
Identifying Relevant
QE terms
?
resubmit expanded query
applicability
check
yes
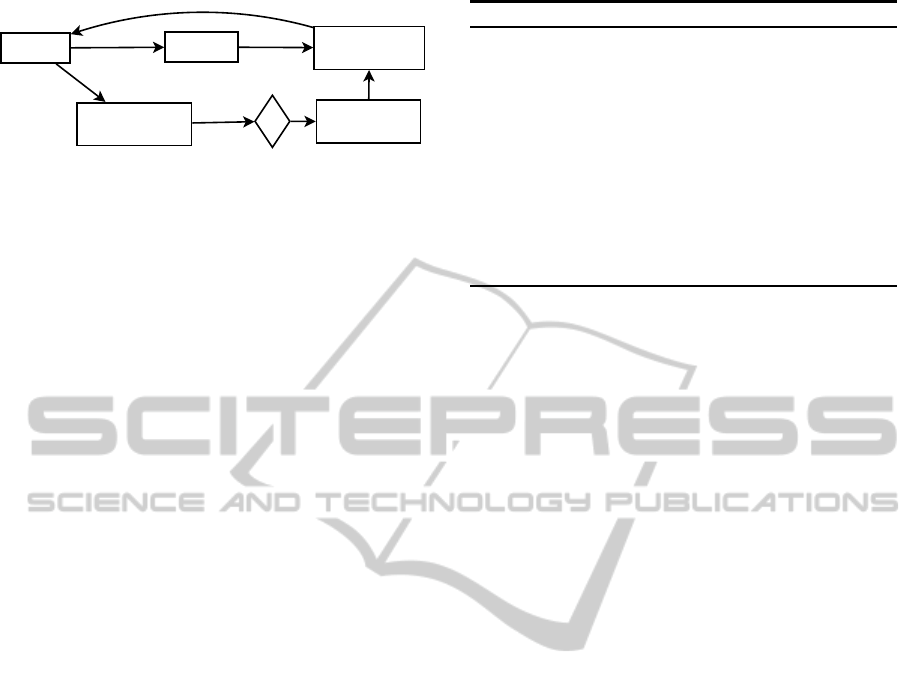
Figure 4: Proposed framework.
motivates us to explore user’s real time implicit feed-
back to determine user’s search context.
4 PROPOSED QE FRAMEWORK
To realise the effect of real time implicit feedback
on query expansion, we systematically build a frame-
work as shown in Figure 4. It has five major compo-
nents.
1.
Baseline Retrieval Systems.
It retrieves a
set of documents which are relevant with user’s
query and provides the top most R relevant docu-
ments to query expansion unit.
2.
Baseline Query Expansion.
Using the docu-
ments provided by the IR system, it determines
a list of expansion terms which are related to the
query submitted by the user.
3.
Processing real time implicit feedback
:
It constructs query session using the procedure
discussed in Section 3.1.1.
4.
Applicability Check.
Some query session
may not have enough evidences of sharing com-
mon search context. This unit verifies whether
the newly submitted query shares common search
context with that of the other queries in the ses-
sion.
5.
Determining Search Context.
It determines
user’s search context by exploiting the implicit
feedback provided by the users in the current
query session. It then identifies the relevant ex-
pansion terms.
4.1 Baseline Query Expansion
We first build a baseline query expansion system
over the baseline retrieval system. In this study, we
use a KLD (see Equation 2) based QE as discussed
in (Billerbeck et al., 2003) as baseline QE. Algo-
rithm 1 shows formal procedure of the baseline QE.
Algorithm 1: Conventional QE through local analysis.
1: run original query q and retrieve relevant docu-
ments
2: select top m documents as local set R
3: extracted all terms t from local set R
4: for all terms t ∈ R do
5: calculate KLD
6: end for
7: rank terms t based on their KLD weight
8: add top |E| terms to original query q
9: run expanded query q and rank documents using
PL2
4.2 Determining User’s Search Context
Let Γ =< t
e
1f
, u, E, δ > be the current query session
as defined in Session 3.1.1, where E is the sequence
of n query events. Let Q
(Γ)
and D
(Γ)
be the set of
queries and visited documents respectively present in
E. Let q
n+1
be a new query submitted by the user
u and E
(q
n+1
)
= { f
q
n+1
,1
, f
q
n+1
,2
, f
q
n+1
,3
, ...} be the set
of expansion terms extracted using Algorithm 1 for
the query q
n+1
. Now the task is to identify relevant
terms with that of user’s search goal. Algorithm 2
summarises the procedure.
4.2.1 Common Query Terms
This section corresponds to Step 3 of Algorithm 2.
It exploits the list of previous queries Q
(Γ)
submit-
ted by the user in the current query session Γ) and
determines the popular query terms using a function
qf( f, Q
(Γ)
) which is the number of queries in Q
(Γ)
containing the term f . We consider a term f pop-
ular if its frequency is greater than a threshold i.e.,
qf( f, Q
(Γ)
) ≥ Θ
Q
. In this study, majority of the query
sessions are short and the term frequencies are small.
Therefore, we set threshold to Θ
Q
= 1.
4.2.2 Common Document Terms
This section corresponds to Step 5 of Algorithm 2.
Intuitively a popular term among the documents in
D
(Γ)
can also represent user’s search context. How-
ever, such a term should not only be a good represen-
tative term of D
(Γ)
, but also be closely associated with
the query. As done in local analysis based query ex-
pansion, KLD (as defined in Equation (??)) is a good
measure to extract informative terms from D
(Γ)
. We
estimate association between a query and a term us-
ing a density based score function DBTA(q
n+1
, f) de-
fined in Equation (8). It defines association between
two terms DBTA( f
i
, f
j
). However, q
n+1
may have
more than one term. To estimate association between
KDIR 2010 - International Conference on Knowledge Discovery and Information Retrieval
116

a query and a term, we use a simple average function
as follows:
DBTA(q
n+1
, f) =
1
|q
n+1
|
∑
f
i
∈q
n+1
DBTA( f
i
, f) (8)
where |q
n+1
| is the number of terms in q
n+1
.
Algorithm 2: Identify relevant query expansion terms.
1: E
(q
n+1
)
rtif
= φ
2: for all terms f ∈ E
(q
n+1
)
do
3: if qf( f, Q
(Γ)
) ≥ Θ
Q
{see Section 4.2.1} then
4: Insert f in E
(q
n+1
)
rtif
5: else if score
P
(D )
( f) ≥ Θ
P
(D )
{see Sec-
tion 4.2.2} then
6: Insert f in E
(q
n+1
)
rtif
7: else if f ∈ P
(E )
{see Section 4.2.3} then
8: Insert f in E
(q
n+1
)
rtif
9: else if score
P
(S )
( f) ≥ Θ
dbta
{see Section 4.2.4}
then
10: Insert f in E
(q
n+1
)
rtif
11: else if score
P
(C )
( f) ≥ Θ
P
(C )
{see Section 4.2.5}
then
12: Insert f in E
(q
n+1
)
rtif
13: end if
14: end for
15: for all terms f ∈ E
(q
n+1
)
and f 6∈ E
(q
n+1
)
rtif
do
16: if ∃ f
′
∈ E
(q
n+1
)
rtif
s.t. DBTA( f, f
′
) ≥ Θ
dbta
then
17: Insert f in E
(q
n+1
)
rtif
18: end if
19: end for
20: return E
(q
n+1
)
rtif
Harmonic mean (Sebastiani, 2002) is a popular
measure to merge the goodness of two estimators.
Therefore, the values of KLD and DBTA are com-
bined using the harmonic mean between the two.
However, the two values are at different scales: KLD
scales between − ∞ to +∞ and DBTA scales between
0 to 1. To make the two estimators coherent to
each other, the estimators are further normalized us-
ing min-max normalization (Lee, 1995) as follows.
normalize(g) =
g− min
g
max
g
−min
g
(9)
where g is an arbitrary function. Now, the harmonic
mean score between the two can be defined as fol-
lows:
score
P
(D )
( f) =
2· KLD
(D
(Γ)
)
( f) · DBTA(q
n+1
, f)
KLD
(D
(Γ)
)
( f) + DBTA(q
n+1
, f)
(10)
If an expansion terms f ∈ E
(q
n+1
)
has a score greater
than a threshold Θ
P
(D )
i.e., score
P
(D )
( f) ≥ Θ
P
(D )
,
then the term f is selected. In this study, the threshold
value is set to an arbitrary value 0.5. It is because in-
tuitively the normalized average may cover the upper
half of the term collections.
4.2.3 Expansion Terms of Previous Queries
This section corresponds to Step 7 of Algorithm 2.
Let e
i
=< t
e
if
,t
e
il
, q
i
, D
(q
i
)
c
> be a query event in E,
where i 6= n + 1 and E
(q
i
)
be the expansion terms of
the query q
i
. If an expansion term f ∈ E
(q
i
)
is also
present in any document d ∈ D
(q
i
)
c
, then it is selected.
The set of such terms is denoted by P
(E )
i
and is for-
mally define as follows:
P
(E )
i
= { f| f ∈ E
(q
i
)
and ∃d ∈ D
(q
i
)
c
s.t. f ∈ d} (11)
We assume that the visited documents against a query
are relevant to user’s information need of that query.
Therefore, this set represents the set of expansion
terms of previous queries in the same query session
which are actually relevant to user’s search goal. For
all the queries in Q
(Γ)
, Equation (11) is repeated and
all P
(E )
i
are merged i.e., P
(E )
= ∪P
(E )
i
. An expansion
term f ∈ E
(q
n+1
)
is assumed to be relevant to user’s
current search context, if f ∈ P
(E )
.
4.2.4 Synonyms of Query Terms
This section corresponds to Step 9 of Algorithm 2.
There are publicly available tools like
Wordnet
4
,
WordWeb
5
which can provide synonyms of a given
term. Such expert knowledge can be used effectively
to select the expansion terms.
Let P
(S )
be the list of synonyms
6
for all the query
terms in Q
(Γ)
extracted using Wordnet. If an expan-
sion terms f ∈ E
(q
n+1
)
has an score greater than a
threshold Θ
dbta
i.e., score
P
(S )
( f) ≥ Θ
dbta
, then the
term f is considered to be relevant to user’s search
goal.
score
P
(S )
( f) =
DBTA( f, f
′
), iff ∈ P
(S )
and
∃ f
′
∈ P
(E )
s.t.
DBTA( f, f
′
) ≥ Θ
dbta
0, Otherwise
(12)
4
http://wordnet.princeton.edu
5
http://wordweb.info/free/
6
We apply the Wordnet command
wn auto synsn
to
get list of synonyms. We pass the output of this command
to a script. This script processes the output and returns the
list of synonyms.
DYNAMIC QUERY EXPANSION BASED ON USER'S REAL TIME IMPLICIT FEEDBACK
117

In this study, the threshold Θ
dbta
is set to an arbitrary
value i.e., the average value of DBTA( f, f
′
) over the
corpus. However, more sophisticated procedure to
set threshold value will be to study the distribution
of positive and negative associations.
4.2.5 Category Specific Terms
This section corresponds to Step 11 of Algorithm 2.
Another important information that can be extracted
from implicit feedback is dominant class labels in
D
(Γ)
. It is observed in Section 3.2.2 that users of-
ten confine their searches to a small number of class
labels. We also expect that majority of the documents
in D
(Γ)
confine to few dominant class labels. The rel-
evant expansion terms should have close association
with the dominant class labels. In the study (Ran-
bir et al., 2010), the authors studied a new measure
known as within class popularity and it is observes
that WCP provides better association as compared
to other estimators such as mutual information, chi-
square (Yang and Pedersen, 1997). In this study, we
use the same measure WCP to estimate association
between a term and class.
If C be the set of global class labels and C
(Γ)
be
the set of dominant class labels of the current query
session Γ. We select a term f ∈ E
(q
n+1
)
if ∃c ∈ C
(Γ)
such that
c = max
∀c
i
∈C
{wcp( f, c
i
)} (13)
where
wcp( f, c
i
) =
Pr( f|c
i
)
∑
|C |
k=1
Pr( f|c
k
)
(14)
4.2.6 Mining more Context Terms
This section corresponds to the steps 15 to 19 in Al-
gorithm 2. Let E
(q
n+1
)
rtif
be the set of relevant ex-
pansion terms thus obtained from the above sections.
Still there may be terms in E
(q
n+1
)
which are not in-
cluded in E
(q
n+1
)
rtif
, but closely related to some terms
in E
(q
n+1
)
rtif
. Intuitively, such missing terms are also re-
lated to the context of user’s search goal. Therefore,
we further determine missing terms as follows:
• for all terms t ∈ E
(q
n+1
)
and t 6∈ E
(q
n+1
)
rtif
: if ∃t
′
∈
E
(q
n+1
)
rtif
s.t. DBTA(t,t
′
) > Θ
dbta
, then insert the
term t in E
(q
n+1
)
rtif
.
Now, we consider the terms in E
(q
n+1
)
rtif
as the expan-
sion terms related to the context of user’s search goal.
4.3 Applicability Check
The above procedures to identify relevant expansion
terms will return good results if the newly submitted
query q
n+1
indeed has the same search preference as
that of other queries in E. But this condition is not
always true. In some query sessions, there may not be
enough evidences of having common search context.
Therefore, it is important to perform an applicabil-
ity check before applying the above procedures. For
every newly submitted query q
n+1
, we perform an ap-
plicability check. We estimate average cosine simi-
larity among the expanded terms of all queries in the
session. If the average similarity of a current session
is above a user-defined threshold Θ
sim
, then it is as-
sumed that the queries in the current query session
share common search context.
5 EVALUATION
METHODOLOGY
To evaluate the proposed framework we define three
metrics – (i)quality: measure the quality of expan-
sion terms, (ii) precision@k: measure retrieval effec-
tiveness and (iii) dynamics: measure the capability of
adapting to the changing needs of users.
The best evidence to verify the quality of the ex-
panded terms or retrieval effectiveness of a system is
to cross check with the documents actually visited by
the user for the subjected query. Let q be an arbitrary
query and D
(q)
c
be the set of documents actually vis-
ited by the user for q. Now, given an IR system and a
query expansion system, let E
(q)
be the set of expan-
sion terms for the query q. Then, the quality of the
expansion terms is defined as follows:
quality =
|ρ(E
(q)
, D
(q)
c
)|
|E
(q)
|
(15)
where ρ(E
(q)
, D
(q)
c
) is the matching terms between
E
(q)
and D
(q)
c
i.e.,
ρ(E
(q)
, D
(q)
c
) = { f| f ∈ E
(q)
, ∃d ∈ D
(q)
c
s.t. f ∈ d}
Let D
(q)
n
be the set of top n documents retrieved
by the IR system. To define retrieval effectiveness,
we determine the number of documents in D
(q)
n
which
are closely related to the documents in D
(q)
c
. We
use cosine similarity (see Equation (1)) to define the
closeness between two documents. Let D
(q)
r
be a set
of documents in D
(q)
n
for which the cosine similarity
KDIR 2010 - International Conference on Knowledge Discovery and Information Retrieval
118

Table 2: List of the 35 queries. #Γ indicates number of query sessions and #Z indicates the number different search context.
query #Γ #Z query #Γ #Z query #Γ #Z query #Γ #Z
blast 15 1 books 18 4 chennai 18 3 coupling 10 2
crunchy munch 38 1 indian 14 2 games 59 1 jaguar 3 2
kate winslet 23 2 mallu 38 1 milk 15 2 namitha 22 1
nick 20 1 rahaman 2 1 passport 38 2 roadies 10 1
statics 36 4 times 5 2 science 16 2 scholar 16 3
simulation 3 1 smile pink 2 1 tutorial 11 6 reader 11 3
ticket 38 3 crank 10 1 engineering village 12 1 maps 15 4
nature 28 2 reshma 15 1 savita 2 1 dragger 11 2
sigma 11 2 spy cam 10 1 java 17 2
with at least one of the document in D
(q)
c
is above a
threshold Θ
sim
i.e.,
D
(q)
r
= {d
i
|d
i
∈ D
(q)
n
, ∃d
j
∈ D
(q)
c
s.t. sim(d
i
, d
j
) ≥ Θ
sim
}
In this study we define D
(q)
r
with the threshold value
Θ
sim
= 0.375. In our dataset, the majority of the co-
click documents have cosine similarity in the range
of [0.25,5). We have considered the middle point as
the threshold value. Now we use the precision@k to
measure the retrieval effectiveness and define it as fol-
lows:
precision@k =
|D
(q)
r
|
k
(16)
Last we define the dynamics in query expansion.
For a query, the system is expected to return different
expansion terms for different search goals. Let E
(q)
i
and E
(q
)
j
be the set of expansion terms for a query q
at two different instances i and j. Then we define the
dynamics between the two instances as follows:
δ
(q)
(i, j) = 1− sim(E
(q)
i
, E
(q)
j
) (17)
If there are n instances of the query q then we estimate
the average dynamics as follows
E(δ
(q)
(i, j)) =
n(n− 1)
2
∑
i6= j
δ
(q)
(i, j) (18)
6 PERFORMANCE OF THE
PROPOSED FRAMEWORK
We build two baseline retrieval systems (i) an IR sys-
tem which indexes around 1.6 million documents us-
ing PL2 normalization (He and Ounis, 2005), denoted
by LIR, and (ii) a meta-search interface which re-
ceives queries from the users and submit it to Google
search engine, denoted by GIR. On top of these sys-
tems, we have incorporated the proposed framework.
Table 3: Average quality of the top 20 expansion terms over
35 queries given in Table 2.
Baseline Proposed
LIR GIR LIR GIR
0.287 0.329 0.536(+86.7%) 0.562(+70.8%)
6.1 Experimental Queries
A total of 35 queries are selected to conduct the
experiments from the In-House query log discussed
in Section 3.1. Top most popular non-navigational
queries (Broder, 2002) of length 1 and 2 words are
selected.
Table 2 shows the list of 35 selected queries. This
table also shows the number of query sessions for
each of the individual queries and denoted by ”#”.
A total of 612 query sessions are found for these 35
queries. A query may have different search goals
at different times. We manually verify and mark all
these 612 instances. While verifying we broadly dif-
ferentiate the goals (e.g. ”java programming” and
”java island” are two different goals, however ”java
swing” and ”core jave” have same goal). Table 2 also
shows the number of different search goals for indi-
vidual query (denoted by ”#Z ”). It shows that 20 out
of 35 (i.e., 57.1%) queries have varying search pref-
erences at different times.
6.2 Quality of Expansion Terms
Table 3 shows the average quality of the expansion
terms over all 35 queries. There is a significant im-
provement in quality. On an average there is an im-
provement from 0.287 to 0.536 (86.7% improvement)
on local IR system. For the Google meta search, there
is an improvement of 70.8% from 0.329 to 0.562.
DYNAMIC QUERY EXPANSION BASED ON USER'S REAL TIME IMPLICIT FEEDBACK
119

6.3 Retrieval Effectiveness
Now, we compare the retrieval effectiveness of the
proposed expansion mechanism with the baseline ex-
pansion mechanism. We use the precision at k mea-
sure (defined in Equation (16)) to estimate retrieval
effectiveness. In Table 4, we compare the retrieval
performance of the baseline system and the proposed
system in terms of the average of the precision at k
for all 612 query instances. If a query has no vis-
ited documents, we simply ignore them. Note that,
the set of visited documents D
(q)
c
is obtained from
the query log whereas the set D
(q)
n
is obtained from
the experimental retrieval system after simulating the
query sequence. Table 4 clearly shows that our pro-
posed framework outperforms the baseline systems
for both the local IR system and Google results.
Table 4: Precision@k returned by different systems using
top 20 expansion terms.
top k Baseline Proposed
LIR GIR LIR GIR
10 0.221 0.462 0.749 0.763
20 0.157 0.373 0.679 0.710
30 0.113 0.210 0.592 0.652
40 0.082 0.153 0.472 0.594
50 0.052 0.127 0.407 0.551
6.4 Component Wise Effectiveness
In the section 4.2, we define different components that
contribute to the expansion terms. In this section, we
study the effect of each componentseparately. Table 5
shows the quality of the expansion terms returned by
each component (considering the top 20 expansion
terms). In the table, P
(Q )
denotes set of expansion
terms based on query terms (Section 4.2.1), P
(D )
de-
notes the document terms (Section 4.2.2), P
(E )
de-
notes combine expansion terms of previously submit-
ted queries (Section 4.2.3), P
(S
R
)
denotes word sense
(Section 4.2.4)and P
(C )
denotes class specific terms
(Section 4.2.5). We observe that expansion terms ex-
tracted using P
(D )
and P
(E )
contribute the most. This
observation is true for both the local retrieval system
and Google results. The summation of the percent-
ages in each row is more than 100%. It is because,
there are overlapping terms among the components.
6.5 Retrieval Efficiency
Though the proposed framework provides better re-
trieval effectiveness, it has an inherent efficiency
problem. Apart from the time required for query
Table 5: Average quality of individual components over 35
queries given in Table 2.
P
(Q )
P
(D )
P
(E )
P
(S
R
)
P
(C )
LIR 8.3% 39.8% 37.9% 4.6% 12.1%
GIR 8.8% 43.3% 39.2% 6.9% 8.4%
Table 6: Average retrieval efficiency of different expansion
system in seconds.
Baseline IR Baseline QE Proposed QE
LIR GIR LIR GIR LIR GIR
1.028 0.731 3.961 3.205 14.518 14.149
expansion (Algorithm 1), the proposed framework
needs computational time for determining context for
user’s search goal. Table 6 shows the efficiency of
different retrieval systems. It clearly shows that the
proposed framework has poor efficiency. It can be
noted that the computational overhead is an order of
magnitude higher than that of general expansion and
without expansion.
The focus of this paper is to investigate feasibil-
ity of query expansion dynamically by exploiting real
time implicit feedback provided by the users at the
time of search. There will be additional computa-
tional overhead to process the expansion in real time.
The implementation of the experimental systems are
not optimal. Though the computational overhead re-
ported in Table 6 is high, with efficient programming
and hardware supports we believe that the overhead
can be reduced to reasonable level.
6.6 Dynamics
Table 7 shows the average of the average dynamics
of different systems over all experimental queries. It
clearly shows that the baseline system has a dynamics
of zero in all cases. It indicates that baseline systems
always return the same expansion terms irrespective
of user’s search goal. Whereas the proposed frame-
work has a small dynamics among the instances of the
same query with same goal and high dynamics among
the query instances of the same query with different
goals. It indicates that the proposed framework is able
to adapt to the changing needs of the users and gener-
ate expansion terms dynamically.
Table 7: Average of average dynamics over all queries.
Baseline QE Proposed QE
Goal LIR GIR LIR GIR
Same 0 0 0.304 0.294
Different 0 0 0.752 0.749
KDIR 2010 - International Conference on Knowledge Discovery and Information Retrieval
120

7 CONCLUSIONS
In this paper, we explore user’s real time implicit
feedback to analyse user’s search pattern during a
short period of time. From the analysis of user’s click-
through query log, we observe two important search
patterns – user’s information need is often influence
by his/her recent searches and user’s searches over a
short period of time often confine to 1 or 2 categories.
In many cases, the implicit feedback provided by the
user at the time of search have enough clues of what
user wants. We explore query expansion to show that
the information submitted at the time of search can
be used effectively to enhance search retrieval perfor-
mance. We proposed a query expansion framework,
which explores recently submitted query space. From
various experiments, we observed that the proposed
framework provides better relevant terms compared
to the baseline query expansion mechanisms. Most
importantly, it can dynamically adapt to the changing
needs of the user.
REFERENCES
Agichtein, E., Brill, E., Dumais, S., and Ragno, R. (2006).
Learning user interaction models for predicting web
search result preferences. In SIGIR’06: Proceedings
of the 29th annual international ACM SIGIR confer-
ence on Research and development in information re-
trieval, pages 3–10. ACM.
Attar, R. and Fraenkel, A. S. (1977). Local feedback in full-
text retrieval systems. Journal of ACM, 24(3):397–
417.
Billerbeck, B., Scholer, F., Williams, H. E., and Zobel, J.
(2003). Query expansion using associated queries. In
CIKM ’03: Proceedings of the twelfth international
conference on Information and knowledge manage-
ment. ACM.
Billerbeck, B. and Zobel, J. (2005). Document expansion
versus query expansion for ad-hoc retrieval. In ADCS
’05: Proceedings of the tenth Australasian document
computing symposium.
Broder, A. (2002). A taxonomy of web search. SIGIR Fo-
rum, 36(2):3–10.
Carroll, J. M. and Rosson, M. B. (1987). Paradox of the
active user. In Interfacing thought: cognitive aspects
of human-computer interaction, pages 80–111. MIT
Press.
Craig, S., Monika, H., Hannes, M., Monika, H., and
Michael, M. (1999). Analysis of a very large web
search engine query log. SIGIR Forum, 33(1):6–12.
Croft, W. B. and Harper, D. J. (1979). Using probabilistic
model of document retrieval without relevance infor-
mation. Journal of Documentation, 35:285–295.
He, B. and Ounis, I. (2005). Term frequency normalisation
tuning for bm25 and dfr model. In ECIR’05: Proceed-
ings of the 27th European Conference on IR Research,
pages 200–214.
Jaime, T., Eytan, A., Rosie, J., and Michael, A. S. P. (2007).
Information re-retrieval: Repeat queries in yahoo’s
logs. In SIGIR07: Proceedings of the 30th annual in-
ternational ACM SIGIR conference on Research and
development in information retrieval, pages 151–158.
ACM.
Jansen, B. J., Spink, A., and Saracevic, T. (2000). Real
life, real users, and real needs: a study and analysis of
user queries on the web. Information Processing and
Management, 36(2):207–227.
Joachims, T. (2002). Optimizing search engines using click-
through data. In SIGKDD’02: Proceedings of the
ACM Conference on Knowledge Discovery and Data
Mining, pages 133–142. ACM.
Jones, S. (1971). Automatic keyword classification for in-
formation retrieval. Butterworths, London, UK.
Kelly, D. and Teevan, J. (2003). Implicit feedback for infer-
ring user preference: A bibliography. SIGIR Forum,
32(2):18–28.
Lee, J. H. (1995). Combining multiple evidence from dif-
ferent properties of weighting schemes. In SIGIR ’95:
Proceedings of the 18th annual international ACM SI-
GIR conference on Research and development in in-
formation retrieval, pages 180–188, New York, NY,
USA. ACM.
Qiu, Y. and Frei, H. (1993). Concept based query expan-
sion. In SIGIR93: Proceeding of the 16th Interna-
tional ACM SIGIR Conference on Research and de-
velopment in information retrieval, pages 151–158.
ACM.
Ranbir, S. S., Murthy, H. A., and Gonsalves, T. A. (2008).
Effect of word density on measuring words associa-
tion. In ACM Compute, pages 1–8.
Ranbir, S. S., Murthy, H. A., and Gonsalves, T. A. (2010).
Feature selection for text classification based on gini
coefficient of inequality. In FSDM’10: Proceedings
of the Fourth International Workshop on Feature Se-
lection in Data Mining, pages 76–85.
Salton, G., Wong, A., and Yang, C. S. (1975). A vector
space model for automatic indexing. ACM Communi-
cation, 18(11):613–620.
Sebastiani, F. (2002). Machine learning in automated text
categorization. ACM Computing Survey, 34(1):1–47.
Xu, J. and Croft, W. B. (1996). Query expansion using lo-
cal and global document analysis. In SIGIR’96: Pro-
ceedings of the Nineteenth Annual International ACM
SIGIR Conference on Research and Development in
Information Retrieval, pages 4–11.
Xu, J. and Croft, W. B. (2000). Improving the effectiveness
of information retrieval with local context analysis.
ACM Transaction on Information System, 18(1):79–
112.
Yang, Y. and Pedersen, J. O. (1997). A comparative
study on feature selection in text categorization. In
ICML’97: Proceedings of the Fourteenth Interna-
tional Conference on Machine Learning, pages 412–
420. ACM.
DYNAMIC QUERY EXPANSION BASED ON USER'S REAL TIME IMPLICIT FEEDBACK
121
