
BIO-INSPIRED AUDITORY PROCESSING
FOR SPEECH FEATURE ENHANCEMENT
HariKrishna Maganti and Marco Matassoni
Fondazione Bruno Kessler, Center for Information Technology, IRST, via Sommarive 18, 38123 Povo, Trento, Italy
Keywords:
Bio-inspired auditory processing, Gammatone filtering, Modulation spectrum, Reverberation, Automatic
speech recognition.
Abstract:
Mel-frequency cepstrum based features have been traditionally used for speech recognition in a number of
applications, as they naturally provide a higher recognition accuracies. However, these features are not very
robust in a noisy acoustic conditions. In this article, we investigate the use of bio-inspired auditory features
emulating the processing performed by cochlea to improve the robustness, particularly to counter environmen-
tal reverberation. Our methodology first extracts robust noise resistant features by gammatone filtering, which
emulate cochlea frequency resolution and then a long-term modulation spectral processing is performed which
preserves speech intelligibility in the signal. We compare and discuss the features based upon the performance
on Aurora5 meeting recorder digit task recorded with four different microphones in a hands-free mode at a real
meeting room. The experimental results show that the proposed features provide considerable improvements
with respect to the state of the art feature extraction techniques.
1 INTRODUCTION
A significant trend in ubiquitous computing is to fa-
cilitate the user to communicate and interact naturally
with concerned applications. Speech is an appealing
mode of communication for such applications. The
human-machine interaction using automatic speech
processing technologies is a diversified research area,
which has been investigated actively (Kellermann,
2006; Droppo and Acero, 2008).
Speech acquisition, processing and recognition in
a non-ideal acoustic environments are complex tasks
due to presence of unknownadditive noise, reverbera-
tion and interfering speakers. Additive noise from in-
terfering noise sources, and convolutive noise arising
from acoustic environment and transmission channel
characteristics contribute to a degradation of perfor-
mance in speech recognition systems. This article ad-
dresses the problem of robustness of automatic speech
recognition (ASR) systems due to convolutive noise
by modeling techniques performed by cochlea in hu-
man auditory processing system.
The influence of additive background noise on the
speech signal can be expressed as
y(n) = x(n) + n(n) (1)
where y(n) is the degraded speech signal, x(n) rep-
resents the clean signal, n(n) is the additive noise,
which is uncorrelated with the speech signal and un-
known. Different techniques have been proposed
based on voice activity detection based noise estima-
tion, minimum statistics noise estimation, histogram
and quantile based methods, and estimation of the
posteriori and a priori signal-to-noise ratio (Woelfel
and McDonough, 2009). In Ephraim and Cohen
(Ephraim and Cohen, 2006), various approaches to
speech enhancement based on noise estimation and
spectral subtraction are discussed. Apart from the sta-
tionary background noise, another important source
of degradation is caused by reverberation produced in
acoustic environment. The speech signal acquired in
a reverberant room can be modeled as convolution of
the speech signal with the room impulse response,
y(n) = x(n) ∗ h(n) (2)
where y(n) is the degraded speech signal, x(n) repre-
sents the clean signal, h(n) is the impulse response
of the room. The impulse response depends upon
the distance between the speaker and the microphone,
and room conditions, such as movement of people
in the room, clapping, opening or closing doors, etc.
Thus extracting robust features which can handle var-
ious room impulse responses is a complex and chal-
lenging task. A variant of spectral subtraction has
51
Maganti H. and Matassoni M..
BIO-INSPIRED AUDITORY PROCESSING FOR SPEECH FEATURE ENHANCEMENT.
DOI: 10.5220/0003145800510058
In Proceedings of the International Conference on Bio-inspired Systems and Signal Processing (BIOSIGNALS-2011), pages 51-58
ISBN: 978-989-8425-35-5
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

been proposed in (Habets, 2004) to enhance speech
degraded by reverberation.
In general to improve robustness of the noisy
speech, processing can be performed at signal, fea-
ture or model level. Speech enhancement techniques
aim at improving the quality of speech signal cap-
tured through single microphone or microphone ar-
ray (Omologo et al., 1998; Martin, 2001). Robust
acoustic features attempt to represent parameters less
sensitive to noise by modifying the extracted fea-
tures. Common techniques include cepstral mean nor-
malization (CMN) and cepstral mean subtraction and
variance normalization (CMSVN) and relative spec-
tral (RASTA)filtering (Droppo and Acero, 2008; Her-
mansky and Morgan, 1994). Model adaptation ap-
proach modify the acoustic model parameters to fit
better with the observed speech features (Omologo
et al., 1998; Gales and Young, 1995).
Performance of the human auditory system is
more adept at noisy speech recognition. Auditory
modeling, which simulates some properties of the
human auditory system have been applied to speech
recognition system to enhance its robustness. The in-
formation coded in auditory spike trains and the in-
formation transfer processing principles found in the
auditory pathway are used in (Holmberg et al., 2005;
Deng and Sheikhzadeh, 2006). The neural synchrony
is used for creating noise-robust representations of
speech (Deng and Sheikhzadeh, 2006). The model
parameters are fine-tuned to conform to the popula-
tion discharge patterns in the auditory nerve which
are then used to derive estimates of the spectrum on a
frame-by-frame basis. This was extremely effectivein
noise and improved performance of the ASR dramat-
ically. Various auditory processing based approaches
were proposed to improve robustness (Ghitza, 1988;
Seneff, 1988; Dau et al., 1996) and in particular, the
works described in (Deng and Sheikhzadeh, 2006;
Flynn and Jones, 2006) were focused to address the
additive noise problem. Further, in (Kleinschmidt
et al., 2001) a model of auditory perception (PEMO)
developed by Dau et al. (Dau et al., 1996) is used as
a front end for ASR, which performed better than the
standard MFCC for an isolated word recognition task.
Principles and models relating to auditory processing,
which attempt to model human hearing to some extent
have been applied for speech recognition in (Herman-
sky and Morgan, 1994; Hermansky, 1997).
The important aspect in a speech recognition sys-
tem is to have abstract representation of highly redun-
dant speech signal, which is achieved by frequency
analysis. The cochlea and hair cells of the inner
ear perform spectrum analysis to extract relevant fea-
tures. The models for auditory spectrum analysis are
based on filterbank design, which are usually char-
acterized by non-uniform frequency resolution and
non-uniform bandwidth on linear scale. Examples
include popular speech analysis techniques, namely
Mel frequency cepstrum and perceptual linear pre-
diction which try to emulate human auditory percep-
tion. Other important processing is based upon Gam-
matone filter bank, which is designed to model hu-
man cochlear filtering and is shown to provide robust-
ness in adverse noise conditions for speech recogni-
tion tasks (Flynn and Jones, 2006; Schlueter et al.,
2006). In (Flynn and Jones, 2006), gammatone based
auditory front-end exhibited robustperformance com-
pared to traditional front-ends based on MFCC, PLP
and standard ETSI frontend. For large vocabulary
speech recognition tasks, the performance of these
features have been competitive with standard fea-
tures like MFCC and PLP (Schlueter et al., 2006).
Another important psychoacoustic property is mod-
ulation spectrum of speech, which is important for
speech intelligibility (Dau et al., 1996; Drullman
et al., 1994). The relative prominence of slow tem-
poral modulations is different at various frequencies,
similar to perceptual ability of human auditory sys-
tem. Particularly, most of the useful linguistic in-
formation is in the modulation frequency components
from the range between 2 and 16 Hz, with dominant
component at around 4 Hz (R.Drullman et al., 1994;
Kanedera et al., 1999; Hermansky, 1997). Modula-
tion spectrum based features computed over longer
windows have been effective in measuring speech in-
telligibility in noisy environments (Houtgast et al.,
1980; Kingsbury, 1998).
In this work, an alternate approach based on psy-
choacoustic properties combining gammatone filter-
ing and modulation spectrum of speech, to preserve
both quality and intelligibility for feature extraction
is presented. Gammatone frequency resolution re-
duces the ASR system sensitivity to environmental
reverberant signal attributes and improve the speech
signal characteristics. Further, long-term modulation
preserves the linguistic information in the speech sig-
nal, improving the accuracy of the system. The fea-
tures derived from the combination are used to pro-
vide robustness, particularly in the context of mis-
match between training and testing reverberant envi-
ronments. The studied features are shown to be reli-
able and robust to the effects of the hands-free record-
ings in the reverberant meeting room. The effective-
ness of the proposed features is demonstrated with ex-
periments which use real-time reverberant speech ac-
quired through four different microphones. For com-
parison purposes the recognition results obtained us-
ing conventional features are tested, and usage of the
BIOSIGNALS 2011 - International Conference on Bio-inspired Systems and Signal Processing
52
proposed features proved to be efficient.
The paper is organized as follows: Section 2 gives
an overview of the auditory inspired features, in-
cluding gammatone filter bank processing and mod-
ulation spectrum processing. Section 3 describes
the methodology for feature extraction. Section 4
presents database description, experiments and re-
sults. Section 5 discusses the results. Finally, Section
6 concludes the paper.
2 FEATURE DESCRIPTION
In this section, a brief introduction and general
overview of auditory features based on gammatone
filter bank and modulation spectrum is presented.
2.1 Gammatone Filter Bank
The gammatone filter was first conceptualized by
Flanagan as a model of the basilar membrane dis-
placement in the human ear (Flanagan, 1960). Jo-
hannesma used it to approximate responses recorded
from the cochlear nucleus in the cat (Johannesma,
1972). de Boer and de Jongh used a gammatone func-
tion to model impulse responses from auditory nerve
fiber recordings, which have been estimated using a
linear reverse-correlation technique (de Boer, 1973).
Patterson et al. showed that the gammatone filter
also delineates psychoacoustically determined audi-
tory filters in humans (Patterson et al., 1987).
Gammatone filters are linear approximation of
physiologically motivated processing performed by
the cochlea(Slaney, 1993), comprise series of band-
pass filters, whose impulse response is defined by:
g(t) = at
n−1
cos(2π f
c
t + φ)e
−2πbt
(3)
where n is the order of the filter, b is the bandwidth
of the filter, a is the amplitude, f
c
is the filter center
frequency and φ is the phase.
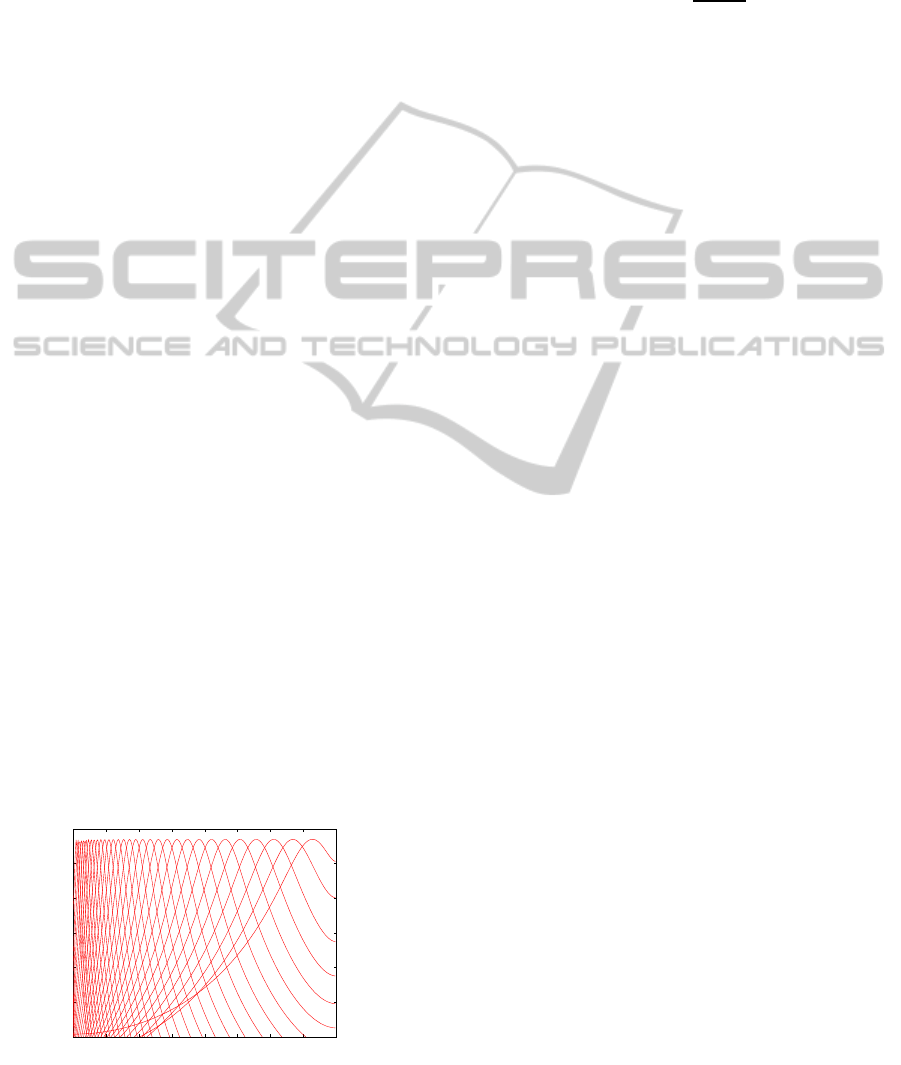
0 500 1000 1500 2000 2500 3000 3500 4000
−60
−50
−40
−30
−20
−10
0
Frequency(Hz)
Filter Response (dB)
Figure 1: Frequency response for the 32-channel gamma-
tone filterbank.
The filter center frequencies and bandwidths
are derived from the filter’s Equivalent Rectangular
Bandwidth (ERB) as detailed in (Slaney, 1993). In
(Glasberg and Moore, 1990), Glasberg and Moore re-
late center frequencyand the ERB of an auditory filter
as
ERB( f
c
) = 24.7(
4.37f
c
1000
+ 1) (4)
The filter output of the m
th
gammatone filter , X
m
can be expressed by
X
m
(n) = x(n) ∗ h
m
(n) (5)
where h
m
(n) is the impulse response of the filter.
The frequency response of the 32-channel gam-
matone filterbank is as shown in Fig. 1.
2.2 Modulation Spectrum
The temporal evolution of speech spectral parameters,
which describe slow variation in energy represent
important information associated with phonetic seg-
ments (Greenberg, 1997). The low-frequency modu-
lations encode information pertaining to syllables, by
virtue of variation in the modulation pattern across the
acoustic spectrum. Dudley showed that essential in-
formation in speech is embedded in modulation pat-
terns lower than 25 Hz distributed over a few as 10
discrete spectral channels (Dudley, 1939). Further,
studies by Drullman et al. confirmed the importance
of amplitude modulation frequencies on speech intel-
ligibility, particularly modulation frequencies below
16Hz contributing to speech intelligibility (Drullman
et al., 1994). Houtgast and Steeneeken demonstrated
that modulation frequencies between 2 and 10 Hz can
be used as an objective measure of speech intelligibil-
ity, for assessing quality of speech over wide range of
acoustic environments (Houtgast et al., 1980).
The long-termmodulations examine the slow tem-
poral evolution of the speech energy with time win-
dowsin the range of 160 - 800 ms, contrary to the con-
ventional short-term modulations studied with time
windows of 10 -30 ms which capture rapid changes
of the speech signals. Generally, the modulation spec-
trum is computed as following: Speech signal X(k) is
segmented into frames by a window function w(k,t),
where t is frame number. Short-time Fourier trans-
form of the windowed speech signal X(t, f) is calcu-
lated as
Y(t, f) =
∞
∑
i=−∞
X( f − i)W(i,t) (6)
The modulation spectrum Y
m
( f,g) is obtained by ap-
plying Fourier transform on the running spectra, ob-
BIO-INSPIRED AUDITORY PROCESSING FOR SPEECH FEATURE ENHANCEMENT
53

Figure 2: Processing stages of the gammatone modulation spectral feature.
tained by taking absolute values |Y(t, f)| at each fre-
quency, expressed as
Y
m
( f,g) = FT[|Y(t, f)|]|
t=1,...T
(7)
where T is the total number of frames and g is the
modulation frequency. The relative prominence of
slow temporal modulations is different at various fre-
quencies, similar to perceptual ability of human audi-
tory system. Most of the useful linguistic information
is in the modulation frequency components from the
range between 2 and 16 Hz, with dominant compo-
nent at around 4 Hz (Drullman et al., 1994; Kanedera
et al., 1999). In (Kanedera et al., 1999), it has been
shown that for noisy environments, the components
of the modulation spectrum below 2 Hz and above 10
Hz are less important for speech intelligibility, par-
ticularly the band below 1 Hz contains mostly infor-
mation about the environment. Therefore the recog-
nition performance can be improved by suppressing
this band in the feature extraction.
The comparative waveforms, spectrograms, gam-
matonegrams and modulation spectrum density plots
of the clean and noisy versions corrupted with con-
volutive and additive noises of the same speech utter-
ance are as shown in Fig. 3. From modulation spec-
trum density plots, some of the important characteris-
tics of the modulation spectrum can be observed. The
important information of speech is concentrated in the
area from 2 Hz and 16 Hz, particularly 2 Hz and 4 Hz
contain crucial information related to the variation of
phonemes.
3 METHODOLOGY
The block schematic for the gammatone modulation
spectrum based feature extraction technique is shown
in Fig. 2. The speech signal first undergoes pre-
emphasis, which flatten the frequency characteristics
of the speech signal. The signal is then processed by a
gammatone filterbank which uses 32 frequency chan-
nels equally spaced on the equivalent ERB scale as
shown in Fig. 1. The impulse responses of the gam-
matone filterbank are similar to the impulse responses
of the auditory system found in physiological mea-
surements (de Boer, 1973). The filterbank is linear
and does not consider nonlinear effects such as level-
dependent upward spread of masking and combina-
tion tones. The computationally effective gamma-
tone filter bank implementation as described in (Ellis,
2010) is used. The gammatone filter bank transform
is computed over L ms and the segment is shifted by n
ms. The log magnitude resulting coefficients are then
decorrelated by applying a discrete cosine transform
(DCT). The computations are made over all the in-
coming signal, resulting in a sequence of energy mag-
nitudes for each band sampled at 1/n Hz. Then, frame
by frame analysis is performed and a N-dimensional
parameter is obtained for each frame. The modulation
spectrum of each coefficient which is defined as the
Fourier transform of its temporal evolution is com-
puted. In each band, the modulations of the signal
are analyzed by computing FFT over the P ms Ham-
ming window and the segment is shifted by p ms.
The energies for the frequencies between the 2 - 16
Hz, which represent the important components for the
speech signal are computed.
For example, if the given signal x(t) is sampled at
BIOSIGNALS 2011 - International Conference on Bio-inspired Systems and Signal Processing
54

1 2 3 4 5
−0.5
0
0.5
1
(a)
Amplitude
Time (sec)
1 2 3 4 5
−0.5
0
0.5
1
(b)
Amplitude
Time (sec)
1 2 3 4 5
−1
−0.5
0
0.5
(c)
Amplitude
Time (sec)
Frequenzy (Hz)
Time (sec)
0 1 2 3 4 5
0
1000
2000
3000
4000
Frequenzy (Hz)
Time (sec)
0 1 2 3 4 5
0
1000
2000
3000
4000
Frequenzy (Hz)
Time (sec)
0 1 2 3 4 5
0
1000
2000
3000
4000
Frequenzy (Hz)
Time (sec)
0 1 2 3 4 5
0
1000
2000
3000
4000
Frequenzy (Hz)
Time (sec)
0 1 2 3 4 5
0
1000
2000
3000
4000
Frequenzy (Hz)
Time (sec)
0 1 2 3 4 5
0
1000
2000
3000
4000
Frequenzy (Hz)
Modulation Freq (Hz)
0 10 20 30 40 50
0
1000
2000
3000
4000
Frequenzy (Hz)
Modulation Freq (Hz)
0 10 20 30 40 50
0
1000
2000
3000
4000
Frequenzy (Hz)
Modulation Freq (Hz)
0 10 20 30 40 50
0
1000
2000
3000
4000
Figure 3: Waveform, spectrogram, gammatonegram, and modulation spectrum density plots for the (a)clean, (b)reverberant
and (c)additive noise corrupted speech.
8 kHz, a first-order high pass pre-emphasis filter is
applied and short segments of speech are extracted
with a 25 ms rectangular window. The window is
shifted by 10 ms which corresponds to a frame rate
of 100 Hz. Each speech frame is then processed by
a 32-channel gammatone filterbank. The 32 logarith-
mic gammatone spectral values are transformed to the
cepstral domain by means of a DCT. Thirteen cep-
stral coefficients C0 to C12 are calculated. C0 is re-
placed by logarithm of the energy computed from the
speech samples. The modulation spectrum of each
coefficient, (sampled at 100Hz) is calculated with a
160 ms window, shifted by 10 ms. Thirteen coeffi-
cients C13 to C26 which are first-order derivatives are
further extracted. The features are named gammatone
filterbank modulation cepstral (GFMC) features.
The same processing is also performed by replac-
ing gammatone filterbank with Mel filterbank in the
Figure 2 resulting in Mel-frequency modulation cep-
stral (MFMC) features. The performance of these fea-
BIO-INSPIRED AUDITORY PROCESSING FOR SPEECH FEATURE ENHANCEMENT
55

tures in comparison to GFMC features are discussed
in Section 4.
4 EXPERIMENTS AND RESULTS
To evaluate the performance, a full HTK based recog-
nition system is used. The HMM-based recognizer ar-
chitecture specified for use with the Aurora 5 database
is used (Hirsch, 2007). The training data is down-
sampled version of clean TIDigits at a sampling fre-
quency of 8 kHz, with 8623 utterances. There are
eleven whole word HMMs each with 16 states and
with each state having four Gaussian mixtures. The
sil model has three states and each state has four mix-
tures.
4.1 Convolutive Noise
The experiments are conducted on a subset of the
Aurora-5 corpus - meeting recorder digits. The data
comprise real recordings in a meeting room, recorded
in a hands-free mode at the International Computer
Science Institute in Berkeley. The dataset consists of
2400 utterances from 24 speakers, with 7800 digits
in total. The speech was captured with four differ-
ent microphones, placed at the middle of the table
in the meeting room. The recordings contain only a
small amount of additive noise, but have the effects of
hands-free recording in the reverberant room. There
are four different versions of all utterances recorded
with four different microphones, with recording lev-
els kept low.
Table 1 shows the results in % word accuracies for
meeting recording digits recorded with four different
microphones, labeled as 6, 7, E and F. The average
performance of four microphones for different fea-
tures is shown at the last column of the table. ETSI-2
correspond to the standard advanced front-end as de-
scribed in (Hirsch, 2007). PLP and MFCC are the
standard 39-dimensional Perceptual linear prediction
and Mel frequency features along with their delta and
acceleration derivatives. MFMC indicate Mel Fre-
quency Modulation Spectral based Cepstral (MFMC)
features where the first thirteen features are extracted
in a traditional way, and the rest are the modulation
features (13) and their derivatives (13) derived as dis-
cussed in Section 3, except for Gammatone filterbank
being replaced with Mel filterbank. The GFCC fea-
tures are extracted in a similar way as reported in Sec-
tion 3 with C0 to C12 being the corresponding cep-
stral coefficients. GFMC indicate Gammatone Fre-
quency Modulation Spectral based Cepstral (GFMC)
features derivedin a same way as GFCC but appended
with modulation spectral features corresponding to
C13 toC26 and their corresponding derivatives as dis-
cussed in Section 3.
Table 1: Word recognition accuracies (%) for different
feature extraction techniques on four different microphones.
Channel 6 7 E F Average
ETSI-2 64.3 47.6 58.1 62.7 58.1
PLP 73.8 63.8 68.1 71.4 69.2
MFCC 75.8 64.7 67.3 75.9 70.9
MFMC 75.6 61.0 70.8 77.9 71.3
GFCC 86.0 79.0 78.3 84.2 81.9
GFMC 87.8 82.7 82.2 86.9 84.9
From Table 1, it is evident that the advanced ETSI
front-end has highest error rates compared to the
MFCC and PLP. This demonstrates that for reverber-
ant environments the advanced ETSI front-end is not
effective as compared to its performance in the pres-
ence of additive background noise. It can be inferred
that the techniques applicable for additive background
noise removal are not suitable to handle reverberant
conditions. The MFMC features have better perfor-
mance than MFCC, which in turn had better perfor-
mance than PLP. It can also be seen that the GFCC
features were effective, performing better than any of
the baseline systems (ETSI-2, PLP, MFCC). This is
consistent with the earlier studies which have shown
that gammatone based features exhibit robust perfor-
mance compared to MFCC, PLP features and ETSI
frontend (Flynn and Jones, 2006; Schlueter et al.,
2006).
It can also be observed that the performance of
GFMC is the best among all the baselines and fea-
tures compared, and consistent across all the chan-
nels. However, the combination of Mel filtering and
modulation spectral features is not as beneficial as
gammatone filtering with modulation spectral fea-
tures. This clearly demonstrates the efficiency of this
combination of these features in reverberation condi-
tions.
4.2 Additive Noise
Further, to test the efficiency for practical conditions
which contain additive noises, preliminary experi-
ments were conducted on close-talk, hands free of-
fice and hands free livingroom with clean and 15
dB SNR additive noise corrupted signals. The data
is from Aurora-5 database, where condition is simu-
lated as combination of additive noise and reverber-
ation(Hirsch, 2007). Aurora-5 covers all effects of
noises as they occur in realistic application scenarios.
BIOSIGNALS 2011 - International Conference on Bio-inspired Systems and Signal Processing
56

In this experiments, hands free speech input in a office
and in a living room is considered. In Table 2, Ctalk,
HFOffice, HFLroom, -, A represents close-talk, hands
free office, hands free living room, no additive noise
and with additive noise of 15 dB SNR respectively.
Table 2: Word recognition accuracies (%) for clean, hands
free office and hands free living room conditions.
Feature Ctalk HFOffice HFLroom
- A - A - A
MFCC 99.4 94.3 90.1 61.6 75.8 40.2
PLP 99.3 85.2 88.6 65.1 74.3 46.9
GFCC 99.5 88.1 89.1 65.6 73.8 48.9
GFMC 99.5 92.8 92.2 73.3 78.6 57.4
From Table 2, it can be observed that for all the
features the performance degrades significantly in ad-
ditive noise compared to no additive noise case. Also,
it can be seen that GFCC has better performance than
MFCC and PLP in case of hands free office and hands
free living room. It can be observed that for almost
all cases GFMC has better performance than GFCC,
MFCC and PLP indicating efficiency of this features
in additive noise conditions.
5 DISCUSSION
The results from both Table 1 and Table 2 indicate that
the gammatone frequency resolution was effective in
reducing system sensitivity to reverberation and ad-
ditive noise, and improved the speech signal charac-
teristics. It can also be observed from Table 1, that
the combination of gammatone filtering with modu-
lation spectral features is beneficial than the combi-
nation of Mel filtering and modulation spectral fea-
tures. The emphasis on slow temporal changes in the
spectral structure of long-term modulations preserved
the required speech intelligibility information in the
signal which further improved the accuracy of the
system. Thus, by extracting features that model hu-
man hearing to some extent mimicking the processing
performed by cochlea, particularly emulating cochlea
frequencyresolution was beneficial for speech feature
enhancement.
6 CONCLUSIONS
The paper has presented auditory inspired modulation
spectral features for improving ASR performance in
presence of room reverberation. The proposed fea-
tures were derived from features based on emulat-
ing the processing performed by cochlea to improve
the robustness, specifically gammatone frequency fil-
tering and long-term modulations of the speech sig-
nal. The features were evaluated on Aurora-5 meeting
recorder digit task recorded with four different micro-
phones in hands-free mode at a real meeting room.
Results were compared with standard ETSI advanced
front-end and conventional features. The results show
that the proposed features perform consistently bet-
ter both in terms of robustness and reliability. The
work also presented some preliminary results in addi-
tive noise scenario where the speech signal was cor-
rupted with 15 dB SNR noise, simulated with hands-
free office and hands-free living room conditions. The
results are promising, performing better than the con-
ventional features, indicating the efficiency of this
features in additive noise scenario.
Our study raised number of issues, including
study of auditory inspired techniques for improve-
ment of standard additive noise removal techniques
to deal with reverberation condition. The gammatone
filter implemented in this work is linear which does
not consider nonlinear effects such as level-dependent
upward spread of masking and combination tones.
For the future, we like to investigate these issues to ef-
ficiently deal with real world noisy speech, and eval-
uate these features on large vocabulary tasks.
REFERENCES
Dau, T., Pueschel, D., and Kohlrausch, A. (1996). A quan-
titative model of the effective signal processing in the
auditory system. The Journal of the Acoustical Society
of America, 99:3615–3622.
de Boer, E. (1973). On the principle of specific coding.
Journal of Dynamic Systems, Measurement and Con-
trol, (Trans. ASME), 95:265– 273.
Deng, L. and Sheikhzadeh, H. (2006). Use of Temporal
Codes Computed From a Cochlear Model for Speech
Recognition. Psychology Press.
Droppo, J. and Acero, A. (2008). Environmental Robust-
ness. Springer Handbook of Speech Processing.
Drullman, R., Festen, J. M., and Plomp, R. (1994). Effect of
temporal envelope smearing on speech reception. The
Journal of the Acoustical Society of America, pages
1053–1064.
Dudley, H. (1939). Remarking speech. The Journal of the
Acoustical Society of America, 11:169–177.
Ellis, D. P. W. (2010). Gammatone-like spectrograms.
http://www.ee.columbia.edu/ dpwe/resources/matlab/
gammatonegram.
Ephraim, Y. and Cohen, I. (2006). Recent Advances in
Speech Enhancement. CRC Press.
BIO-INSPIRED AUDITORY PROCESSING FOR SPEECH FEATURE ENHANCEMENT
57

Flanagan, J. (1960). Models for approximating basilar
membrane displacement. The Journal of the Acous-
tical Society of America, 32:937.
Flynn, R. and Jones, E. (2006). A comparative study of
auditory-based front-ends for robust speech recogni-
tion using the aurora 2 database. In IISC, IET Irish
Signals and Systems Conference.
Gales, M. J. F. and Young, S. (1995). A fast and flex-
ible implementation of parallel model combination.
In ICASSP’95, IEEE International Conference on
Acoustics, Speech, and Signal Processing, pages 133–
136. IEEE.
Ghitza, O. (1988). Temporal non-place information in the
auditory-nerve firing patterns as a front-end for speech
recognition in a noisy environment. Journal of Pho-
netics.
Glasberg, B. and Moore, B. (1990). Derivation of audi-
tory filter shapes from notched-noise data. Hearing
Research, 47:103–108.
Greenberg, S. (1997). On the origins of speech intelligi-
bility in the real world. In ESCA Workshop on Ro-
bust Speech Recognition for Unknown Communica-
tion Channels.
Habets, E. A. P. (2004). Single-channel speech dereverber-
ation based on spectral subtraction. In ProRISC’04,
15th Annual Workshop on Circuits, Systems and Sig-
nal Processing.
Hermansky, H. (1997). Auditory modeling in automatic
recognition of speech. In ECSAP.
Hermansky, H. and Morgan, N. (1994). Rasta processing
of speech. IEEE Transactions on Speech and Audio
Processing, 2(4):578–589.
Hirsch, H. G. (2007). Aurora-5 experimental framework
for the performance evaluation of speech recognition
in case of a hands-free speech input in noisy environ-
ments. http://aurora.hsnr.de/aurora-5/reports.html.
Holmberg, M., Gelbart, D., Ramacher, U., and Hemmert,
W. (2005). Automatic speech recognition with neural
spike trains. In Interspeech’05, 9th European Con-
ference on Speech Communication and Technology,
pages 1253–1256.
Houtgast, T., Steeneken, H. J. M., and Plomp, R. (1980).
Predicting speech intelligibility in rooms from the
modulation transfer function. Acustica, 46(1):60 –72.
Johannesma, P. I. (1972). The pre-response stimulus en-
semble of neurons in the cochlear nucleus. In Sym-
posium on Hearing Theory (Institute for Perception
Research), Eindhoven, Holland, pages 58 – 69.
Kanedera, N., Arai, T., Hermansky, H., and Pavel, M.
(1999). On the relative importance of various com-
ponents of the modulation spectrum for automatic
speech recognition. Speech Comm., 28:43–55.
Kellermann, W. (2006). Some current challenges in multi-
channel acoustic signal processing. The Journal of the
Acoustical Society of America, 120(5):3177–3178.
Kingsbury, B. E. D. (1998). Perceptually Inspired Signal-
processing Strategies for Robust Speech Recognition
in Reverberant Environments. PhD Thesis.
Kleinschmidt, M., Tchorz, J., and Kollmeier, B. (2001).
Combining speech enhancement and auditory fea-
ture extraction for robust speech recognition. Speech
Comm., 34:75–91.
Martin, R. (2001). Noise power spectral density estimation
based on optimal smoothing and minimum statistics.
IEEE Transactions on Speech and Audio Processing,
9(5):504–512.
Omologo, M., Svaizer, P., and Matassoni, M. (1998). En-
vironmental conditions and acoustic transduction in
hands-free speech recognition. Speech Comm., 25:75–
95.
Patterson, R. D., Nimmo-Smith, I., Holdsworth, J., and
Rice, P. (1987). An efficient auditory filterbank based
on the gammatone function. In meeting of the IOC
Speech Group on Auditory Modelling at RSRE.
R.Drullman, J.Festen, and R.Plomp (1994). Effect of re-
ducing slow temporal modulations on speech recep-
tion. The Journal of the Acoustical Society of Amer-
ica, 95:2670–2680.
Schlueter, R., Bezrukov, I., Wagner, H., and Ney, H. (2006).
Gammatone features and feature combination for
large vocabulary speech recognition. In ICASSP’06,
IEEE International Conference on Acoustics, Speech,
and Signal Processing.
Seneff, S. (1988). A joint synchrony/mean-rate model of
auditory speech processing. Journal of Phonetics,
16:55–76.
Slaney, M. (1993). An efficient implementation of the pat-
terson holdsworth auditory filterbank. In Apple Com-
puters, Perception Group.
Woelfel, J. and McDonough, J. (2009). Distant Speech
Recognition. John Wiley, 1st edition.
BIOSIGNALS 2011 - International Conference on Bio-inspired Systems and Signal Processing
58
