
TAG RECOMMENDATION BASED ON USER’S BEHAVIOR
IN COLLABORATIVE TAGGING SYSTEMS
Nagehan Ilhan and S¸ule G¨und¨uz
¨
O˘g¨ud¨uc¨u
Istanbul Technical University, Department of Computer Engineering, Maslak, Istanbul, 34469 Turkey
Keywords:
Collaborative tagging, Recommender systems, Tag suggestions, Social network analysis.
Abstract:
Social bookmarking Web sites allow users submitting their resources and labeling them with arbitrary key-
words, called tags, to create folksonomies. Tag recommendation is an important element of collaborative
tagging systems which aims at providing relevant information to users by proposing a set of tags to each
newly posted resource. In this paper, we focus on the task of tag recommendation when a user examines a
document based on the user’s tagging behavior. We explore the use of this semantic relationship in modeling
the user tagging behavior. The experiments are performed on the data set obtained from a social bookmarking
site. Our experimental result show that our method is efficient in modeling users’ tagging behavior and it can
be used to recommend tags for resources.
1 INTRODUCTION
Collaborative tagging systems are popular tools for
creating, collecting and sharing huge amounts of so-
cial data over the Web (Golder and Huberman, 2006).
Social bookmarking services allow Web users to an-
notate the resources with freely chosen keywords
called tags. The tags given by a user to a resource
reflect the interest of the user in the resource as well
as the understanding of the content of the resource.
Most of the social bookmarking Web sites assist users
during the labeling process by recommending tags.
Recommending tags can employ on various purposes
such as increasing the probability of a resource’s get-
ting annotated or reminding the user what a resource
is about. There are numerous social bookmarking
Web sites providing these services, the most popular
being Delicious
1
. Delicious is a widely used social
bookmarking service devoted to tag URL’s. The aim
of this work is to model the tagging behavior of users
in order to recommend them personalized tags related
to the document they are interested in.
In this paper, we propose a method to enrich the
model of tagging behavior in a folksonomy by adding
some semantics based on the WordNet hierarchy of
concepts (Fellbaum, 1998). We focus on modeling
users’ tagging behavior effectively which in turn will
increase the recommendation accuracy. Our model
does not only consider previously used bookmarks of
1
http://del.icio.us.com/
the users but also takes into account the content of
the document. This feature is also helpful to handle
cold-start situations. Our objective is firstly to ex-
tract tagging pattern of users by analyzing the simi-
larity between user tags and the content of the doc-
ument in order to represent this relationship between
folksonomy tags and the content. The content of a
document is divided in this study into five different
components called document sections (e.g. page title,
main content, heading 1 etc.). We find out effect rates
of different document sections on user tagging behav-
ior while she/he is bookmarking a Web page. Then,
we calculate score points for each user that reflects
the probability of choosing tags by a user that appear
in a particular section of the document. We generate
our recommendation set by considering the calculated
rates of the user.
The rest of the paper organized as follows. We
mentioned related works in Section 2. Our proposed
method is introduced in Section 3. We then present
our experiments and discuss results in Section 4. Fi-
nally, Section 5 concludes the paper.
2 RELATED WORK
There exist statistical investigations about the us-
age dynamics and tagging patterns of tag collections
(Golder and Huberman, 2005)(Kipp and Campbell,
2007).
570
Ilhan N. and Gündüz-Ö
˘
güdücü ¸S..
TAG RECOMMENDATION BASED ON USER’S BEHAVIOR IN COLLABORATIVE TAGGING SYSTEMS.
DOI: 10.5220/0003151005700573
In Proceedings of the 3rd International Conference on Agents and Artificial Intelligence (ICAART-2011), pages 570-573
ISBN: 978-989-8425-40-9
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

In (Lee and Chun, 2007) content-based tag rec-
ommendation which uses graph representation is pre-
sented. Their system recommends the tags extracted
from the content of a blog using an artificial neural
network which uses WordNet and word frequencies
in the training step. An example of content-based tag
recommendation which uses graph representation is
presented in (Lee and Chun, 2007). Their system rec-
ommends the tags extracted from the content of a blog
using an artificial neural network which uses Word-
Net and word frequencies in the training step.
The authors in (Tatu et al., 2008) utilize informa-
tion from resource content and the folksonomic struc-
ture of the graph. They use the graph to create a set
of tags related to the resource and a set of tags re-
lated to the user. Then the system enrich tag vocab-
ularies of the set of tags related to resource or user
by WordNet based search for words that represent the
same concept in order to recommend to the user. A
method which creates resource related tags with the
keywords found in the resource’s title and extending
them with the tags that co-occur with the base tags in
the system is presented in (Lipczak et al., 2009). Ex-
isting tag recommendation studies use previous tags
that has been assigned to the resource by other users.
Thus, they become insufficient when a new resource
appears. Our recommendation model utilize content
of the Web document, hence new or frequently as-
signed resources does not alter our recommendation
success.
3 PROPOSED METHOD
3.1 Analysis of Tagging Behavior
It can be assumed that Web pages can be represented
by their text. In this study, this text is separated into
five different sections: (1) main content for long texts
in the body part of the document (C); (2) page title
(P), (3) heading 1 (H1); (4) heading 2 (H2); and (5)
the anchor text in the links (A). There are 6 heading
tags available in HTML coding and H1 is the largest
being at the top of the heading structure hierarchy. In
the remaining part of this paper, dx
i
denotes one of
this five sections of a document d
i
. A preprocessing
step is performed which includes stop word removal
and stemming of terms. The main content of a Web
page is then represented by top-k terms that have the
highest frequency among the other terms in the body
part of the document. The terms in a section of the
document are combined into a single vector:
−→
dx
i
= (wx
1
, f
i1
), (wx
2
, f
i2
), . . . , (wx
n
, f
in
) (1)
where wx
1
, wx
2
, . . . , wx
n
are terms that appear in the
corresponding section dx
i
and f
i1
, f
i2
, . . . , f
in
are the
frequencies of the terms. Thus, a Web document can
be represented by 5 term vectors. Instead of com-
monly used TF-IDF (Term Frequency/Inverse Doc-
ument Frequency) weighting scheme we used TF
weighting in vector representations.
The tags assigned to a Web document are com-
bined into a single tag vector:
−→
tt
i
= (t
1
, f
i1
), (t
2
, f
i2
), . . . , (t
l
, f
il
) (2)
where t
1
, t
2
, . . . , t
l
are tags assigned by users to docu-
ment d
i
and f
i1
, f
i2
, . . . , f
il
are the frequencies of the
corresponding tags in that document.
As stated earlier, the aim of this step is to find
a relationship between terms appeared in the docu-
ment and the tags assigned to it. For this reason, the
similarity between each term vector and tag vector of
the document is computed using the cosine similarity
measure:
sim(
−→
dx
i
,
−→
tt
i
) =
−→
dx
i
•
−→
tt
i
k
−→
dx
i
kk
−→
tt
i
k
(3)
The second step of tag analysis comprises of
determining the semantic relationship between the
scope of a document and tags of this document using
WordNet. Each term in each term vector of a doc-
ument is converted into its hypernym and hyponym
versions using WordNet. A term’s hypernym is a gen-
eral term whereas a hyponym is specific. The fre-
quency f
ij
of a termt
j
in a term vector of d
i
is mapped
to its hypernyms/hyponyms {h
1
, . . . , h
j
, . . . , h
r
}. The
frequencies of synonym terms are determined in a
similar way of hypernym/hyponymcase. The similar-
ity between each term vector and synonym tag vector
is computed based on the cosine measure.
3.2 Personalized Tag Recommendations
We are given a set of users U = {u
1
, u
2
, . . . , u
N
}, a
set of Web pages R = {d
1
, d
2
, . . . , d
K
} and a set of
tags T = {t
1
, t
2
, . . . , t
M
}. In this paper, we will use the
following notations:
• tags(u
i
) ⊆ T is the set of tags used by user u
i
.
• tags(u
i
, d
j
) ⊆ tags(u
i
) is the set of tags given by
user u
i
to a Web page d
j
.
• tags(d
j
) ⊆ T is the set of tags given to Web page
d
j
.
• tags(dx
j
) ⊆ tags(d
j
) is the set of tags of Web page
d
j
that appear in the dx
j
part of that page. Note
that dx can be one of the five different sections of
the document, such as main content, page title, h1,
h2 or anchor text.
TAG RECOMMENDATION BASED ON USER'S BEHAVIOR IN COLLABORATIVE TAGGING SYSTEMS
571
For each user u
i
, a score is calculated to determine
whether the user selects tags related to the content of
the document and if so from which part of the doc-
ument or (s)he assigns tags from her/his own vocab-
ulary independent from the content of the document.
First, a score value is computed for each document
section-user pair which is the probability of choosing
tags by that user that appear in dx section in a docu-
ment:
score
dx
j
,u
i
=
|tags(u
i
, d
j
) ∩ tags(dx
j
)|
|tags(u
i
, d
j
)|
(4)
Each document section dx
j
contributes to the final
set of tag recommendations with n
x, j
tags which is
proportional to the score value of this section. Let the
final set of recommendations consists of k tags. The
number of tags in the final recommendations set that
are part of dx
j
is:
n
x, j
=
score
dx
j
,u
i
∑
x
score
dx
j
,u
i
× k (5)
A recommendation set R(u
i
, dx
j
) is formed for user
u
i
with n
x, j
tags that have the highest frequency in
term vector dx
j
. Finally, user u
i
is provided with a set
of k recommended tags R(u
i
, d
j
) for a particular Web
document d
j
:
R(u
i
, d
j
) =
[
x
R(u
i
, dx
j
) (6)
4 EXPERIMENTAL RESULTS
4.1 Data Preperation
The experiments are performed on two different
datasets which are collected from the Delicious Web
site. The details of the datasets are given in Table 1.
Table 1: Dataset Information.
Urls Users Tags
Dataset1 1013 45654 42169
Dataset2(train) 25122 1020 82626
Dataset2 (test) 25880 1020 85321
Each Web document in each dataset is parsed
to remove HTML tagging. The same preprocess-
ing step is performed on each Web document and
the set of user tags by applying a stop word removal
and Porter’s stemming algorithm (Jones and Willet,
1997). Each Web document is divided into 5 sec-
tions by representing each section by a term vector
as explained in Section 3.1. Hypernym, hyponym
Figure 1: Similarity values between term and tag vectors of
documents.
Figure 2: Similarity values between hypernym term and tag
vectors of documents.
and synonym vectors of each term vector of each
document are constructed using WordNet (Fellbaum,
1998). Then the cosine similarity between each (hy-
pernym/hyponym/synonym) term vector and tag vec-
tor of documents is calculated.
For simplification, we present the following ex-
perimental settings, S1-S3. In S1, the cosine similar-
ity between each term vector dx
j
and the tag vector tt
j
of d
j
is calculated using Eq. 3. The cosine similarity
between hypernyms of term vectors and tag vectors of
documents is calculated in S2. The synonym of term
vector is constructed for S3 and the cosine similarity
is calculated between synonym term vectors and tag
vectors. In each setup, the similarity values are aver-
aged over the entire set of documents in Dataset1.
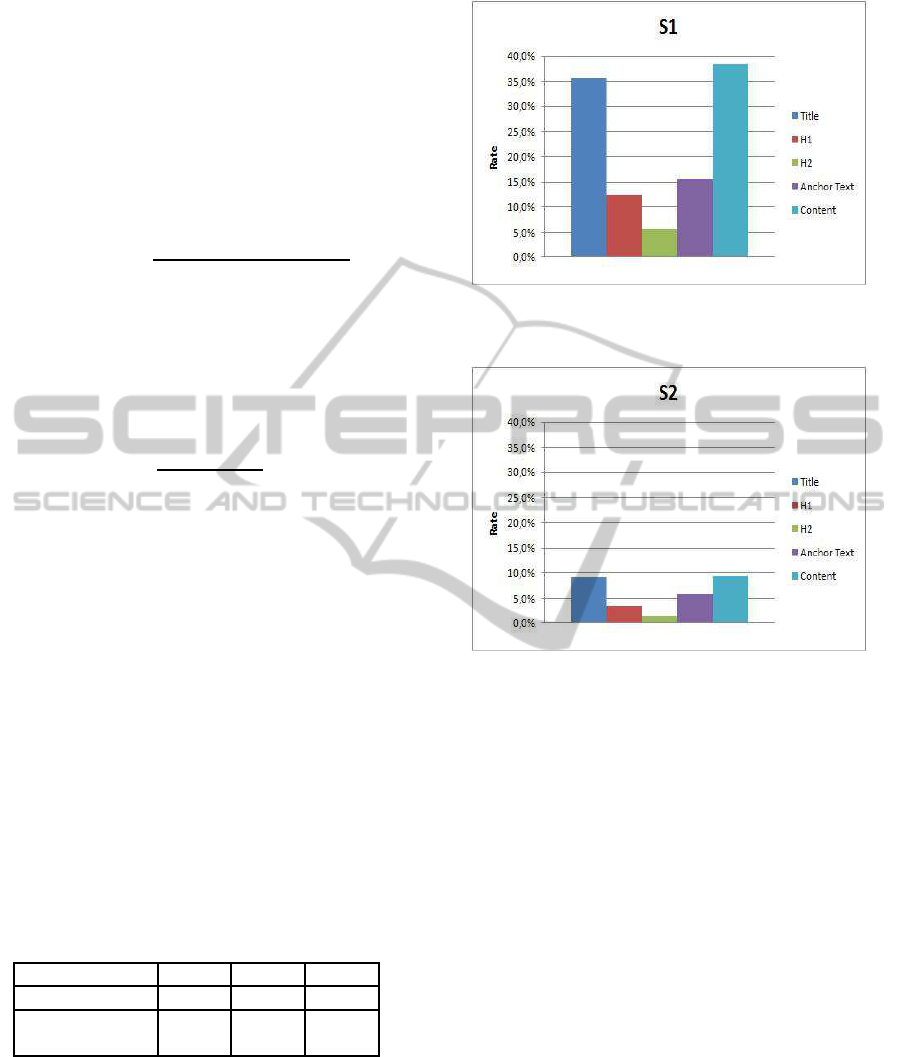
Fig. 1, 2 and 3 show the similarity results for S1,
S2 and S3, respectively. The similarity between term
vector obtained from the content and the tag vector
is higher than the similarities between the remaining
term vectors and tag vector. The similarity value ob-
tained by using page title is close to the similarity
value of using content term vector.
Based on these result, a hybrid recommendation
ICAART 2011 - 3rd International Conference on Agents and Artificial Intelligence
572

Figure 3: Similarity values between synonym term and tag
vectors of documents.
Figure 4: Recommendation Results.
set for users by only calculating the users’ tagging
scores on page title and content of Web documents.
The recommendation set consists of 10 tags (k) which
is empirically determined. Recommendation results
given in Figure 4 support our prior review on simi-
larities between tags and document content. Recom-
mendation set generated by just using most frequent
content terms outperforms the set generated by using
most frequent page title terms. However, the recom-
mendation rate of our hybrid recommendation set per-
forms better than both sets.
5 CONCLUSIONS
In this paper, we considered the content of a resource
as tag source in creating the recommendation set. We
investigated the similarity between different parts of
the content of the resource with the tags assigned to
the resources. Our main aim was to determine which
part of the document has valuable tags and can be a
potential tag source. It is also examined that if the se-
mantically related terms of the content can be used as
tag source or not. Results indicate that users tend to
choose terms that appear in the content of the docu-
ment rather than selecting terms that are semantically
similar to the terms in the document.
Afterwards, we proposed a recommendation
model which rates users’ tag selection to assign re-
sources. These rates measure the likeness of user tags
with different parts of the document and represents
which part of the document’s text is selected by the
user. Then, our recommendation set is generated by
considering those rates. Results show that users are
more likely to select tags from main content when
compared to titles and our proposed recommendation
technique outperforms the recommendation methods
in which tags are created using only the main content
and the title terms.
ACKNOWLEDGEMENTS
The authors are supported by the Scientific and Tech-
nological Research Council of Turkey (TUBITAK)
EEEAG project 110E027.
REFERENCES
Fellbaum, C., editor (1998). WordNet: an electronic lexical
database. MIT Press.
Golder, S. and Huberman, B. A. (2005). The structure of
collaborative tagging systems. Journal of Information
Science, 32(2):198–208.
Golder, S. A. and Huberman, B. A. (2006). Usage pat-
terns of collaborative tagging systems. J. Inf. Sci.,
32(2):198–208.
Jones, K. S. and Willet, P., editors (1997). Readings in
Information Retrieval. Morgan Kaufmann Publisher-
sand Inc., San Francisco, California.
Kipp, M. E. and Campbell, G. D. (2007). Patterns and
inconsistencies in collaborative tagging systems: An
examination of tagging practices. Proceedings of the
American Society for Information Science and Tech-
nology, 43(1):1–18.
Lee, S. O. K. and Chun, A. H. W. (2007). Automatic tag
recommendation for the web 2.0 blogosphere using
collaborative tagging and hybrid ann semantic struc-
tures. In ACOS’07, pages 88–93.
Lipczak, M., Hu, Y., Kollet, Y., and Milios, E. (2009). Tag
sources for recommendation in collaborative tagging
systems. In Eisterlehner, F., Hotho, A., and Jschke,
R., editors, ECML PKDD Discovery Challenge 2009
(DC09), volume 497 of CEUR-WS.org, pages 157–
172.
Tatu, M., Srikanth, M., and D’Silva, T. (2008). Rsdc’08:
Tag recommendations using bookmark content. In
Proceedings of the ECML/PKDD 2008, pages 96–
107.
TAG RECOMMENDATION BASED ON USER'S BEHAVIOR IN COLLABORATIVE TAGGING SYSTEMS
573
