
BRIDGING NAVIGATION, SEARCH AND ADAPTATION
Adaptive Hypermedia Models Evolution
Evgeny Knutov, Paul De Bra, David Smits and Mykola Pechenizkiy
Department of Computer Science, Eindhoven University of Tec
hnology, P.O. Box 513, 5600 MB, Eindhoven, The Netherlands
Keywords:
Search, Navigation, Browsing, Adaptation, Personalization, Open corpus, Dexter model, AHAM, GAF.
Abstract:
Adaptive Hypermedia Systems (AHS) have long been concentrating on adaptive guidance of links between
domain concepts. In this paper we first study parallels between navigation and linking in hypertext on the
one hand and information searching or querying on the other hand. We show that to a large extent linking
and searching can be modeled in the same way. Secondly we present a transition towards search in AHS by
aligning the web search process with the layered structure of AHS and link adaptation process. In the end we
sketch the on-going implementation of an open corpus adaptation carried out in the context of the ’Grapple’
adaptive e-learning environment.
1 INTRODUCTION
The most referenced (but certainly not only) Adaptive
Hypermedia (AH) model dates back to 1999. Since
AHAM (De Bra et al., 1999) new terms, definitions
and models have been introduced and realized in pro-
totypes (Knutov et al., 2009). Most AH models focus
on a layered architecture and concentrate on adapta-
tion to the linking and navigation between concepts of
an application domain. This architecture dates back
to the Dexter Hypertext Model (Halasz and Schwartz,
1994). With the exploding popularity of the Web
searching rather than linking is becoming the prevail-
ing form of information access. Hence, apart from
adaptive linking there is now also a need to provide
personalized search in order to meet the requirements
of every particular user. This paper deals with bring-
ing linking and search together, both in an adaptive
hypermedia context. We consider the issues of adap-
tive searching, searching in an adaptive environment,
or for instance more familiar in AH field - Open Cor-
pus Adaptation (Brusilovsky and Henze, 2007). In
the end we discuss the on-going implementation of
an open-corpus adaptation in the context of Grap-
ple (De Bra et al., 2010) project.
In this paper we bring navigation and search in AH
context together by means of the following steps:
• We revisit Dexter Hypertext Model and draw
parallels between navigation links and queries
(section 2);
• We look at the problem of adaptive search and
have a brief look at search in Open Corpus envi-
ronments as a representative use-case (section 3);
• We show 2 use-cases for the interchangeability of
navigation and search (section 4);
• In section 5 we show the evolution of Hyper-
text/Hypermedia modelling from Dexter Model
through AHAM to the proposed GAF model, out-
line advantages of each framework in adaptive en-
vironment and as a result we align the conven-
tional search process with the generic adaptation
process model (derived from GAF);
• In section 6 we discuss the ongoing implementa-
tion of an open corpus adaptation in the Grapple
adaptive e-learning environment as a real use-case
of bridging navigation and adaptation in one go;
• In section 7 we conclude with the issues and ad-
vantages by comparing search methods to con-
ventional hypermedia navigation; we outline chal-
lenges and future work directions.
2 BROWSING, NAVIGATION
AND QUERIES: THE DEXTER
MODEL REVISITED
In this section we revisit the Dexter Model to show
that hyperlinks are essentially already represented by
queries, which makes it possible to replace the navi-
314
Knutov E., De Bra P., Smits D. and Pechenizkiy M..
BRIDGING NAVIGATION, SEARCH AND ADAPTATION - Adaptive Hypermedia Models Evolution.
DOI: 10.5220/0003341503140321
In Proceedings of the 7th International Conference on Web Information Systems and Technologies (WEBIST-2011), pages 314-321
ISBN: 978-989-8425-51-5
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

gation structure of the hypertext model with queries
(and particularly considering search queries) instead
of resolving navigation links.
In Figure 4 (left model) the layered structure of the
Dexter Hypertext Reference model is presented. Here
the storage layer emphasizes ‘glueing’ components
and links together to form hypertext networks. These
components are generic containers of data (where
there is no difference between content types, graph-
ical and textual components). On the other hand,
the within-component layer of Dexter Model is con-
cerned with the contents and structure within the com-
ponents of the hypertext network.
The Hypertext system requires functions to refer
to locations(items) within the content of an individual
component. It is done by anchoring (e.g. to support
span-to-spanlinks). These anchors provide aforemen-
tioned functionality while at the same time maintain
a clear separation of storage and within-component
layers.
The basic addressability in the storage layer of the
Dexter Model concerns the component. This com-
ponent could be an atom, a link, or a composite en-
tity which may be comprised of other components.
Atomic components are primitives which are deter-
mined by the within-components layer. Atomic in-
stances can be called ‘nodes’ of the hypertext sys-
tem. Links here are entities which represent relations
between other components. They are usually a se-
quence of 2 or more ‘endpoint specifications’ each
referring to a component in the hypertext. A more de-
tailed structure of the overall organization of the stor-
age layer is shown in Figure 1, it includes specifiers,
links and anchors.
Component info
Attributes
Presentation spec
Anchors
Content
‘some arbitrary
text’
Specifier
Component spec:
Anchor_ID #1
Direction: FROM
Presentation spec.
Specifier
Component spec:
Anchor_ID #1
Direction: TO
Presentation spec.
Component info
Attributes
Presentation spec
Anchors
Content
-------
-------
------
Value IDValue ID
resolvs to
resolvs to
query
“TO”
conventional
Web links
Figure 1: Dexter Model Storage layer (incl. specifiers,
links, anchors).
Simplifying the model and considering only the
Web model of linking, where only the ‘TO’ resolver
exists (in terms of Dexter Model) we can see the com-
plementarity of a linking and searching notions (Fig-
ure 2).
C RS
Direction (TO, FROM)
Anchor_ID
---------------------
FROM = void in Web
notion of linking
Component Info.
and corresponding
Content
specifies resolves to
Specifier
Figure 2: Linking - Query model.
3 WEB SEARCH AND ADAPTIVE
SEARCH
In this section we summarize adaptation methodolo-
gies that are (or can be) applied in the search envi-
ronment, such as querying information using a web
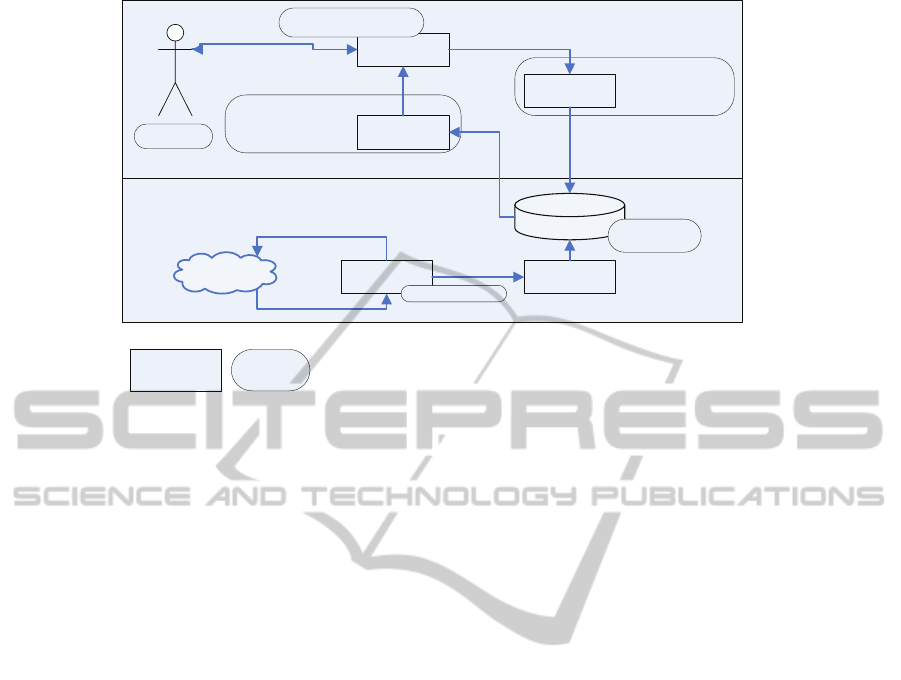
search engine. Figure 3 represents conventional Web
search functionality enhanced with adaptation fea-
tures (presented with oval-shaped blocks).
To supplement the schematic view of ‘adaptive
search’ we generalize how these approaches can be
applied within the search process and present them in
the in Table 1. As three major components we dis-
tinguish adaptation of the input parameters, then the
search query itself and output results. In addition we
consider user modelling aspects involvedin the search
process.
Open Corpus Search and Navigation
As defined in (Brusilovsky and Henze, 2007) search
falls under one of the types of information access
in AHS. In particular it is represented by Adaptive
Information Retrieval (Adaptive IR), typically im-
plemented using keyword-based search mechanisms.
Examples of keyword-based search in Open-Corpus
AH can be found in the ‘SisKill’ and ‘Webert’ sys-
tems where link ordering and annotation is performed
or in ‘ML-Tutor’, and ‘YourNews, TaskSieve’ where
link ordering and generation is done and many other
custom systems (Olston and Chi, 2003). As a result a
‘search’ mechanism or Adaptive IR contributes to the
AH field and brings Open Corpus adaptation closer.
Therefore we consider that employing the comple-
mentarity of search and navigation may have a high
impact in Open Corpus Adaptation.
4 USE-CASES
We show two representative use-cases which fully
comply with the idea of ‘query-link’ interchangeabil-
ity.
Use-Case 1: I’m Feeling Lucky. Using the ‘I’m
Feeling Lucky’ button on Google takes you directly
to the first result page. This is an example of what
BRIDGING NAVIGATION, SEARCH AND ADAPTATION - Adaptive Hypermedia Models Evolution
315

Table 1: Generic approaches to search adaptation & adaptive search.
Parameters Adaptation User modelling aspects
Input - adapting user input (translating keywords (e.g.
into English), aligning with an ontology, using
a definition of keyword, rephrasing search re-
quests, etc.);
- letting the user choose the field of search or use
the domain/user pre-defined information (prede-
fined set of topics, types, etc.) (e.g. pictures,
blogs, internet, intranet, videos, etc.);
- narrowing down search input according to the
user profile;
- (auto)suggesting predefined search parameters
(suggested search);
- personalizing the search input (e.g. us-
ing particular search engine for a particular
user/interest/data type: use mapquest looking for
address or google image search looking for pic-
tures)
- (auto)suggesting predefined search parameters
for the user (suggested search using UM)
Search
query
- query reformulation (e.g. query expansion);
- adapting query parameters (match-
ing/extracting/mapping keywords of a query);
- adding external lexicon (e.g. using predefined
queries comprising a certain lexicon);
- using predefined labelled queries (according to
user/group historical search data, user parame-
ters [preferences, interests]);
- using semantically related queries (if there is
an available ontology)
- querying multiple UM from different systems
(e.g. distributed UM);
- querying for user undefined parameters (e.g.
user interests are not defined in the profile but
can be retrieved (queried) from the access log);
- using personalized indexes for search
Output - ranking search results, relating to the results of
other users, etc. (e.g. collaborative recommenda-
tions);
- adapting the output content and presentation
(annotating/highlighting/presentation) (e.g. AH
methods);
- adapting the output navigation (creating lists,
tables of contents, local/global maps, etc.)
- user profile can be updated with the results (or
search keywords) of the searched information to
be used for suggesting/recommending relevant
‘next searches’;
- used search keywords can comprise and accu-
mulate and update the user personalized search
indexes
we mean by link-query interchangeability: the search
query is interpreted as a link specification and in fact
the ‘click’ works just like a web link bringing us di-
rectly to the top ranked search result of the search en-
gine. As defined in (Rose and Levinson, 2004) this
type of online behaviour is defined by the navigational
goal, which is stated by the user when he or she has
a specific web site in mind and the reason why the
search query is done is that he or she may not know
or remember the URL or it is just easier to do a search
rather than type in an URL (e.g. ‘Royal Dutch air-
lines’, ‘Eindhoven University of Technology’, etc.).
Use-Case 2: Collaborative Searching and Linking.
Collaborative linking and recommendations were in-
vestigated in the field of data mining involving collab-
orative filtering and recommendations (Smyth et al.,
2009). Here we consider it from the perspective of
navigation and search. When the system recommends
a link to a user, this link is represented by the query
which filters the results of others, aggregates, then
ranks and presents the top rated link to the concerned
user based on the collaborative results.
Often these links are represented by the immedi-
ate query which is executed on the click. It retrieves
and presents the result to the user, rather than showing
some pre-calculated link. In fact the navigation here is
completely replaced by the query execution and data
retrieval process, but the user still sees the hyperlink
on the web page and perceives this as a navigation
rather than as querying.
Thus ‘collaborative link’ (and navigation in gen-
eral) is essentially a query which takes into account
the premises of all the users involved in inferenc-
ing (filtering) a particular link and resolves the des-
tination by presenting the result of the query. The
WEBIST 2011 - 7th International Conference on Web Information Systems and Technologies
316
making recommendations,
adapting presentation
of search results, etc.
adapting the
search query
(reformulation,
extern lexicon, etc.)
Front-end process
Back-end process
WWW
Web crawler Indexer
User Interface
Ranking
Query parser
Indexes
search
adaptive
functionality
conventional
web search
functionality
Legend:
user model
personalized
index
personalized UI
(presentation.navigation, etc.)
query/result
adapted: query input
adaptive crawling
Figure 3: Adaptive Search.
‘HeyStaks’ (Smyth et al., 2009) — social networking
and recommendation engine is a good example of col-
laborative linking, querying and presenting links as a
result of a query over preferences of multiple users in-
volved in ‘stak’ creation which serves a basis for rec-
ommendation and ranking using mechanisms of col-
laborative promotions.
Use-Case 3: Open-corpus. According to definition
Open corpus AH system is an AHS which operates
on an open corpus of documents, e.g., a set of docu-
ments that is not known at design time and, moreover,
can constantly change and expand” (Brusilovsky and
Henze, 2007). Open-corpus systems in general pro-
vide the flexibility of search and navigation in one
go. Essentially they replace the conventional navi-
gation with the indexed terms and search mechanism
on the open corpus. Open-corpus domain has the di-
rect application of navigation and search which is in-
creasingly considered in adaptiveapplications is scru-
tinized. This is where resources come from search re-
sults in dynamic learning object repositories or from
a Web search engine (see section 3). The ongoing im-
plementation of an open-corpus adaptation within the
adaptive e-learning environment ”Grapple” (De Bra
et al., 2010) is carried out. We discuss the details of
this implementation in section 6.
5 FROM DEXTER MODEL,
THROUGH AHAM, TO GAF
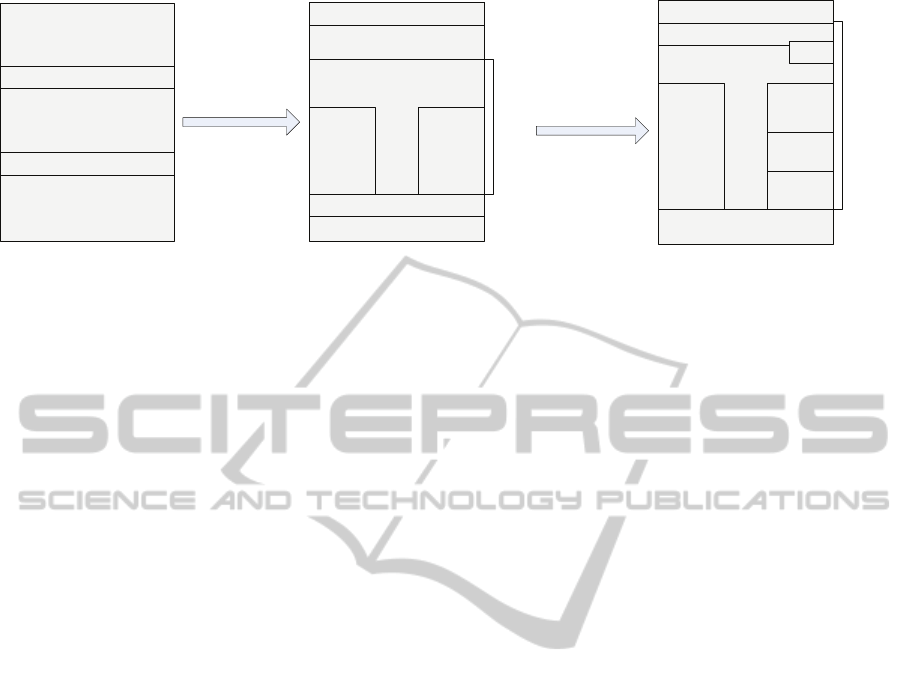
In Figure 4 we show the evolution of the Hypertext
reference models, from Hypertext to Adaptive Hy-
permedia to the new Generic Adaptation Framework
(GAF) which encapsulates most recent developments
in AH and adjacent fields.
A brief discussion of the Dexter model can be
found in (section 2), so here we would like to concen-
trate on the adaptation features evolution and outline
major differences of these systems.
The AHAM (De Bra et al., 1999) reference model
could be considered as an adaptive extension to the
Dexter model. Major points of AHAM are:
• Any AHAM application must be based on a
Domain Model (DM), describing how the in-
formation content of the application or ‘hyper-
document’ is structured (using a conceptual rep-
resentation of knowledge).
• A User Model (UM) must be devised and its
sustainability should be maintained representing
preferences, knowledge, goals, navigation and
other relevant user aspects.
• The presentation of content and link structure
must be adapted to the user’s behaviour as well
as to the user’s knowledge and interest. Thus an
Adaptation Model (AM) should be defined con-
sisting of adaptation rules. The rules define both
the process of generating the adaptive presenta-
tion and that of updating UM.
In AHAM the Storage layer split to support Do-
main and User modelling in order to facilitate adapta-
tion to user attributes based on the conceptual struc-
ture of the domain, represented by the concept-link
structure. And the Adaptation Model (AM) encapsu-
lates the Adaptive Engine (AE) functionality, the rule
system performing adaptation based on the value of
UM attributes.
Moving towards a more elaborate framework,
BRIDGING NAVIGATION, SEARCH AND ADAPTATION - Adaptive Hypermedia Models Evolution
317
Adaptation Model
Runtime Layer
(presentation of hypertext,
user interaction, dynamics)
Presentation Specification
Storage Layer
(a database containing a
network of nodes and links)
Anchoring
Within Component Layer
(the content/structure inside
the nodes)
- adaptation (rule sysrtem)
- user modelling
- domain modelling
- search
- group adaptation
- higher order adaptation
- enhanced reasoning
- data mining support
- open corpus
- user/usage context
- semantic web / ontologies
Run-time Layer
Presentation Specification
Within-component layer
Anchoring
Domain
Model
User
Model
Storage
Layer
Application Model
Presentation Model
Resource Layer
Domain
Model
User
Model
Storage
Layer
Context
Model
Adaptation Model (AE)
Group
Model
HOA
Dexter Model
AHAM GAF
Figure 4: From Dexter, through AHAM, to GAF.
GAF will enhance adaptation capabilities and include
new methodologies and techniques, facilitating more
elaborate adaptation. In figure 5 we present an ex-
tended draft architecture of GAF and briefly outline
the enhancements (comparing to AHAM).
• Ontologies are used in order to provide interoper-
ability in adaptive applications. These ontologies
must be agreed upon, considering concept struc-
tures and meanings, therefore ontologies as a base
concept structures are accepted in more and more
research fields. A Domain Model based on an on-
tology makes interoperability feasible.
• Open corpus adaptation which is increasingly
considered in adaptive applications is scrutinized.
This is where resources come from search results
in dynamic learning object repositories or from a
Web search engine (see section 3).
• Data Mining is a valuable tool with respect to
clustering users into groups based on their navi-
gational patterns or capturing long term effects of
adaptation rules.
• Group-based adaptation will extend the adapta-
tion by taking group models into account. It de-
termines partitioning of the users into groups and
and adapting to the group model.
• Higher order adaptation will monitor the user’s
behaviour also to adapt the adaptation behaviour.
• Multimedia adaptation provides a content type in-
dependence at any application level, providing a
generalization of adaptation techniques and meth-
ods to work with.
• Context Awareness allows system and application
to be decoupled from the existing environment,
and makes them more sensitive to adapt in many
other ways rather than through a set of predefined
rules. We consider usage and user context for
GAF: both capturing the context of user behaviour
and Domain Model usage, allowing to adapt to
user and concept contexts (e.g. environment set-
tings).
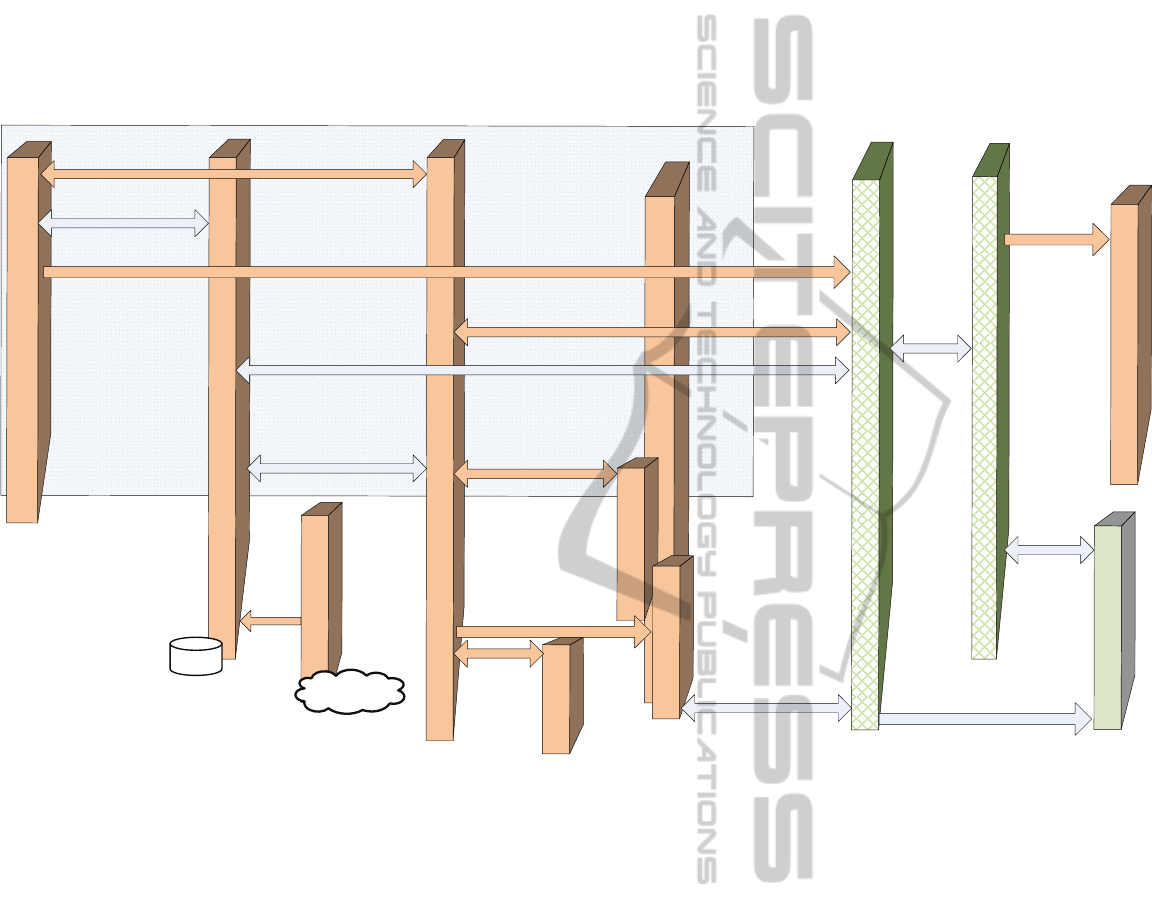
Search Illustrates Compliance with the Generic
AHS. Figure 5 presents compliance of a search pro-
cess and an overlaying Generic Adaptation Process
(GAP) sequence chart. Where GAP represents the
process chart constructed by coupling the layers of
GAF — a general purpose AHS proposed in sec-
tion 5 and described in (Knutov, 2008; Knutov, 2009).
Here we assign search process steps from Figure 3
to a single layer or a transition in the system (men-
tioned on Figure 4). Though we’re facing certain
issues discriminating Recommendation Engine func-
tionality, in particular Search Engine and Ranking
mechanisms (in this respect Application Model (AM)
and Adaptation Model/Engine (AE) can be treated ac-
cordingly) we could align the search process and de-
scribe its functionality (in terms of aforementioned
models) with GAF. On the one hand this proves a
generic property of GAF, and on the other hand it
opens new horizons to facilitate search aspects in the
AH field.
The search process complies with the reference
structure of AHS as follows:
• The User states the goal thus formulating a new
search query, which can be considered as stating
or choosing a particular concept (set of concepts)
to followin AHS. It can be interpreted and aligned
with DM (availability of concepts, concept struc-
tures and sequences, etc.) and UM (considering
user competencies, preferences, experience, etc.)
thus re-formulating and refining the search query
(matching it with the common lexicon or using se-
mantically related terms).
• The Domain Model is defined by the search in-
dex, representing keywords used to facilitate fast
and reliable information retrieval, which is ac-
quired from the Resource Model (and essentially
WWW). The index information is obtained from
WWW by means of crawling which is similar to
the process of resolving content information of a
concept in AHS.
WEBIST 2011 - 7th International Conference on Web Information Systems and Technologies
318
G
o
a
l
M
o
d
e
l
D
o
m
a
in
M
o
d
e
l
U
s
e
r
M
o
d
e
l
C
o
n
t
e
x
t
M
o
d
e
l
R
e
s
o
u
r
c
e
M
o
d
e
l
A
p
p
lic
a
t
i
o
n
M
o
d
e
l
G
r
o
u
p
M
o
d
e
l
A
d
a
p
t
a
t
io
n
M
o
d
e
l
P
r
e
s
e
n
t
a
t
io
n
M
o
d
e
l
H
ig
h
e
r
O
r
d
e
r
A
d
a
p
t
a
t
io
n
U
s
e
r
C
o
n
t
e
x
t
U
s
a
g
e
C
o
n
t
e
x
t
parsing query
Group
formation
Defining the
usage context
Acquiring user
context
UM-DM
overlay
sustainability
Acquiring
resources for
the concepts
Defining
user goal
Aligning goal with
the Domain
Considering
usage context
Passing
content to be
rendered and
presented
Maintaining
and
Acquiring
Adaptive rules
of higher order
Initiating
adaptation
Invoking
adaptation
Methods and
techniques
Retrieving/updating
UM state
Maintaining and
updating HOA with
system usage data
Retrieving concept
corresponding domain
information (hierarchy,
resources, meta data)
Crawler
index
User – stating
the query
User Profile
IP, profile, etc.
www
Search
and Result
history
Ranking
User Interface:
Presenting search
results, snippets,
ranking info., etc.
Search
Engine
Search Query
Interpreting
Query
(refolmulation,
extern lex., etc.)
Accumulating user
search history
Maintaining
collaborative
profile
AHS
Overlay
Model
AH
methods and
techniques
Figure 5: Search compliance with Generic Adaptation Process.
BRIDGING NAVIGATION, SEARCH AND ADAPTATION - Adaptive Hypermedia Models Evolution
319
• The Context Model defines user and usage con-
text properties such as IP address, user pro-
file/stereotype, or search and result histories ac-
cordingly.
• The Group Model refers to maintaining a collab-
orative profile of the user or stereotyping search
results by location or user age group and gender,
which later can be used to rank and recommend
results.
• Retrieving and updating UM refers to storing and
accumulating UM search history which can be
used to reformulate queries or retrieve personal-
ized results.
• Application and Adaptation Models may refer
to the Search Engine and Ranking mechanisms,
however it may not be entirely clear how to dis-
tinguish some particular parts of those. Here we
would refer to the Adaptation Model for Ranking,
since they both to some extent perform adaptation
of the results. The Application Model then serves
as the core of the system: coupling other layers
and dispatching information in AHS or perform-
ing a search as the Search Engine.
• The Presentation Model renders search results and
presents a ranked result list, snippets, additional
rank information, groups result, etc.
6 ONGOING IMPLEMENTATION
OF OPEN CORPUS
ADAPTATION
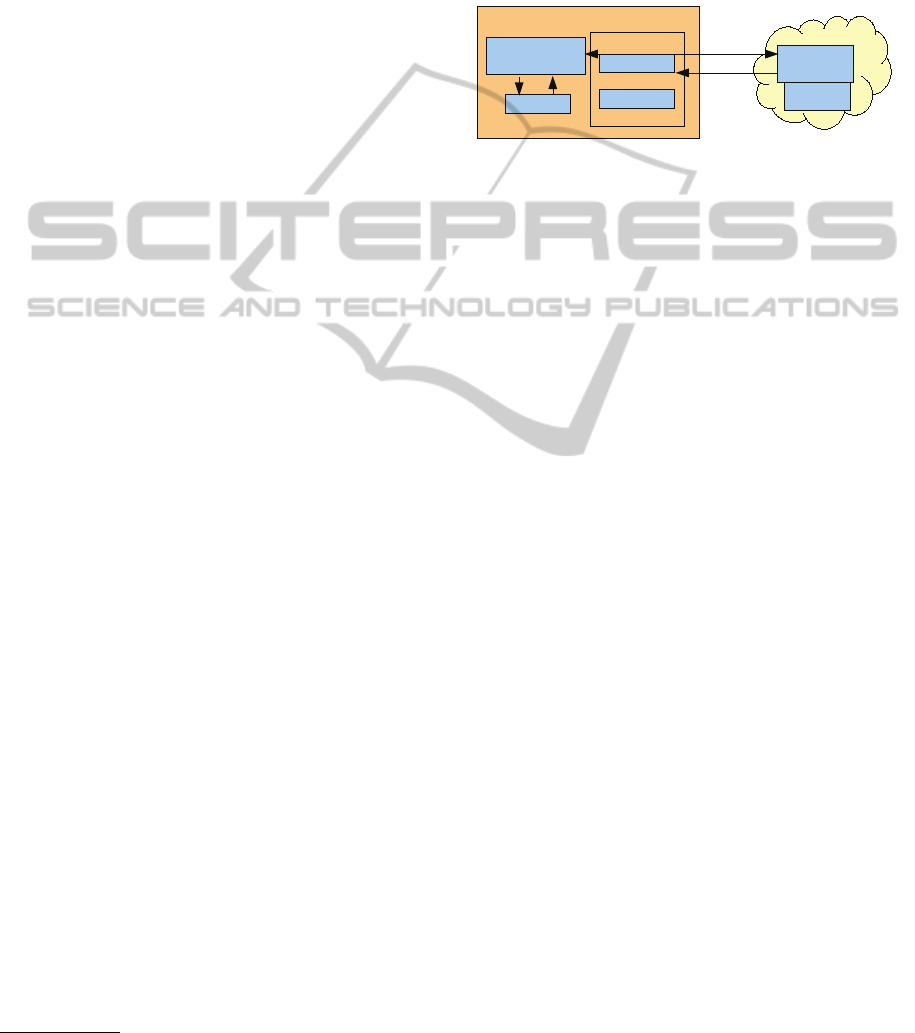
Hereafter we discuss the ongoing implementation of
the aforementioned use-case 3 an Open Corpus adap-
tation, which is carried out in the context of adaptive
e-learning environment ‘Grapple’
1
.
The adaptation engine part in Grapple and the
UM service part need domain model information and
adaptation model to do the reasoning part (here we
consider the adaptation model to be part of the do-
main model). The Open Corpus service of Grapple
allows domain and adaption model to be stored ex-
ternally and later retrieved. The information can be
stored in separate files using the GAM format (which
represents concept definitions and their relations), or
inside resources using the meta element description.
In the Open Corpus setting the URI that identifies
the concept is used as a URL to locate domain model
information for the concept. When the concept URI is
used as a URL the resulting document is scanned for
1
http://www.grapple-project.org/
a meta element with name attribute gale.dm. The con-
tents of this meta element is expected to be GAM code
which describes the concept. In nothing is found, the
Open Corpus service searches further. It performs the
search from the current path in the URL up to the root
of the server specified. The first description found on
the current concept is used. Figure 6 presents the idea
of an Open Corpus Adaptation in ‘Grapple’.
!
!
Figure 6: Open Corpus Adaptation.
7 CONCLUSIONS AND FUTURE
WORK
We conclude by summarizing the benefits of linking
and querying interoperability in an AH context.
Links and Queries in Adaptation — flexibility and
interchangeability of links and queries prompt the
area of AH research to go more towards the direc-
tion of Open Corpus adaptation, AE rule systems and
Recommender systems. The flexibility to choose be-
tween conventional adaptive navigation techniques or
adapt search queries using corresponding techniques
(Table 1) will facilitate AHS development and face
them towards the area of more traditional web search
and web information systems (WIS) in general.
Interoperability and Re-usability — usage of link-
ing and queries makes systems more flexible in terms
of interoperability, compatibility and re-usability.
Queries have more flexibility as an intermediate inter-
change format (e.g. for RuleSystems used in AH sys-
tems). The lack of of the properties actually stops the
spread of AHS into the area of Open Corpus, that’s
why this paper can become a pushing point and we
particularly focus on the implementation of the open-
corpus adaptation.
Dynamic Nature of Queries — Queries are more
of a dynamic nature rather than links. Queries repre-
sent a parametric structure, which makes them more
dynamic and in practice they can generalize different
link types.
Data Provenance — Queries contain provenance
information that can be easily analyzed and inter-
preted (e.g. using data base query provenance infor-
mation). This is also possible with the linked struc-
tures, however comparing to conventional hyperlinks
requires additional metadata.
WEBIST 2011 - 7th International Conference on Web Information Systems and Technologies
320

Search and Recommender Engines are more flexi-
ble for introducing or discovering new rules — Rule
systems which are conventionally used in AHS are
facilitated by using queries, providing the compatibil-
ity properties with the existing AH rule systems (e.g.
ECA type of rules).
In the future we plan to extend the search adap-
tation process sequence, elaborate the description,
in particular inter-layer transactions, emphasizing the
interoperability of a new AH developments (Ontolo-
gies, Open Corpus, Higher-Order Adaptation etc.)
in the context of the search process. This may re-
quire unifying search and linking methods for AH
field. We also plan to present new use-cases and
show how exactly user experience, data provenance
and open corpus adaptation are facilitated by the link-
ing and search interchangeability and compliance in
the AH field. We intend to map search goals classifi-
cation on navigational behaviour to show that differ-
ent search queries may be complimentary to naviga-
tion and browsing. The ongoing implementation of
an Open-Corpus adaptation shows the real use-case
linking and domain model and adaptation model ex-
traction which facilitates AHS to use external (open
corpus) information to perform adaptation to a partic-
ular user’s needs.
ACKNOWLEDGEMENTS
This work has been supported by the NWO GAF:
Generic Adaptation Framework project and Grap-
ple project.
REFERENCES
Brusilovsky, P. and Henze, N. (2007). Open Corpus Adap-
tive Educational Hypermedia. In Brusilovsky, P.,
Kobsa, A., and Nejdl, W., editors, The Adaptive Web,
pages 671–696. Springer.
De Bra, P., Houben, G.-J., and Wu, H. (1999). AHAM: a
Dexter-Based Reference Model for Adaptive Hyper-
media. In Hypertext, pages 147–156. ACM.
De Bra, P., Smits, D., van der Sluijs, K., Cristea, A.,
and Hendrix, M. (2010). Grapple personalization
and adaptation in learning management systems. In
ED-MEDIA’10: Proc.of World Conference on Ed-
ucational Multimedia, Hypermedia and Telecommu-
nications 2010, pages 3029–3038. Chesapeake, VA:
AACE.
Halasz, F. and Schwartz, M. (1994). The dexter hypertext
reference model. Commun. ACM, 37(2):30–39.
Knutov, E. (2008). GAF: Generic Adaptation Framework.
In Nejdl, W., Kay, J., Pu, P., and Herder, E., editors,
Adaptive Hypermedia and Adaptive Web-Based Sys-
tems, 5th International Conference, AH 2008, Han-
nover, Germany, July 29 - August 1, 2008. Proceed-
ings, pages 400–404. Springer.
Knutov, E. (2009). Gaf: Generic adaptation framework.
Hypertext 2009 SRC poster.
Knutov, E., De Bra, P., and Pechenizkiy, M. (2009). AH 12
years later: a comprehensive survey of adaptive hyper-
media methods and techniques. New Rev. Hypermedia
Multimedia, 15(1):5–38.
Olston, C. and Chi, E. H. (2003). ScentTrails: Integrat-
ing browsing and searching on the Web. ACM Trans.
Comput.-Hum. Interact., 10(3):177–197.
Rose, D. E. and Levinson, D. (2004). Understanding user
goals in web search. In WWW ’04: Proceedings of
the 13th international conference on World Wide Web,
pages 13–19, New York, NY, USA. ACM.
Smyth, B., Briggs, P., Coyle, M., and O’Mahony, M.
(2009). Google shared. a case-study in social search.
In Houben, G.-J., McCalla, G. I., Pianesi, F., and Zan-
canaro, M., editors, UMAP, pages 283–294. Springer.
BRIDGING NAVIGATION, SEARCH AND ADAPTATION - Adaptive Hypermedia Models Evolution
321
