
SCENE DATA SYNCHRONIZATION IN SORT-FIRST RENDERING
SYSTEM FOR LARGE DYNAMIC SCENES
He Bing and Wang Yangzihao
State Key Laboratory of Virtual Reality Technology and Systems, Beihang University, Beijing, China
Keywords:
Scene data synchronization, Cluster parallel rendering, Sort-first, Dynamic scenes.
Abstract:
In this paper we built a cluster-based sort-first rendering system. Unlike previous sort-first rendering systems
for static scenes, ours can cope with large dynamic scenes with massive data. A set of strategies are designed
and implemented to give solutions for scene data synchronization in our system. The experimental results
show that our system maintains favorable data consistency for dynamic scenes and is highly scalable with
solid improvement of rendering performance. Using 16 computing nodes, our system can achieve interactive
visualization result in the test physical simulation scene which contains 10,000 moving rigid-body models and
building models with massive geometric and texture data.
1 INTRODUCTION
With the development of graphics hardware, visual-
ization applications with massive data sets are made
possible using cluster-based parallel rendering. Based
on where the sort from object-space to screen space
occurs, there are three parallel rendering architec-
tures: sort-first, sort-last and sort-middle. With low
communication cost and the advantage of frame-to-
frame coherence, sort-first has been the most widely
studied and used architecture of parallel rendering. It
is highly scalable and is particularly suitable for clus-
ter implementation.
During the past decades, several sort-first ren-
dering systems are developed and applied to various
applications(Mueller, 1995) (Samanta et al., 1999)
(Samanta et al., 2000) (Humphreys et al., 2001)
(Humphreys et al., 2002). However, sort-first render-
ing strategy with large dynamic scenes remains an un-
solved problem. It is mainly due to the difficulty of
keeping the consistency of the moving object’s status
(position, velocity, etc.) among each rendering node.
One of the key issues in solving this problem is scene
data synchronization.
In this paper, we build a multi-thread sort-first ren-
dering system with physical computing module and
implemented a set of methods on scene management
and scene data synchronization to cope with massive
dynamic data sets. Using our strategy, we achieved
interactive visualization result in a scene which con-
tains more than 10,000 moving rigid-body models
and building models with massive geometric and tex-
ture data.
2 RELATED WORK
A comprehensive survey on cluster-based parallel
rendering goes beyond the scope of this paper. See
(Pajarola, 2008) and (Staadt et al., 2008). In this sec-
tion, we will focus on sort-first architecture and scene
data synchronization issue.
Molnar et al. have classified parallel rendering
based on where the visibility sort occurs into sort-
first, sort-last and sort-middle in(Molnar et al., 1994).
In sort-first architecture, little intervene is done to
graphic pipeline. Mueller (Mueller, 1995) has pointed
out that in the sort-first architecture, the screen is par-
titioned into non-overlapping tiles (usually with rect-
angular shapes) and the rendering nodes are responsi-
ble for all the rendering computation that affects their
respective screen regions. According to the frame-to-
frame coherence, the network overhead is minimized.
Data synchronization is a fundamental issue in
distributed systems. Several sort-first rendering sys-
tems have developed their own scene data synchro-
nization strategies. In Samanta’s retained mode ren-
dering system for static scenes(Samanta et al., 1999),
because the client and all the servers read the same 3D
scene graph from disk and store it entirely in memory,
there is no data synchronization requirement. In im-
207
Bing H. and Yangzihao W..
SCENE DATA SYNCHRONIZATION IN SORT-FIRST RENDERING SYSTEM FOR LARGE DYNAMIC SCENES.
DOI: 10.5220/0003363002070210
In Proceedings of the International Conference on Computer Graphics Theory and Applications (GRAPP-2011), pages 207-210
ISBN: 978-989-8425-45-4
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

mediate mode system such as WireGL(Humphreys
et al., 2001) and Molnar’s first sort-first rendering
system(Molnar et al., 1994), scene data synchroniza-
tion is mainly pixel redistribution between each two
frames during the rendering of static scenes. In the
rendering of dynamic scenes though, scene data syn-
chronization becomes more difficult due to the reason
that several parameters of the moving objects (trans-
formation matrix, velocity, acceleration et al.) are
needed to be synchronized between each two frames.
As far as we know, works on this specific topic are
rare.
3 OVERVIEW
The prototype sort-first parallel rendering system we
have built is composed by a single display and a clus-
ter of computing nodes connected by 1000M band-
width local area network. Logically, we divided the
PC clusters into three groups: controlling node, com-
puting node and image composition node.
A controlling node is in charge of the scene data
synchronization, task decomposition and load balanc-
ing. It controls the running of the whole system. A
computing node performs all the computing tasks.
There are two kinds of computing nodes: rendering
node and physical computing node. Note the clas-
sification is conceptual, in our system, every com-
puting machine contains one pair of rendering node
and physical computing node at the same time. The
rendering node renders the scene within a given sub
frustum assigned by the controlling node, the physical
computing node performs the collision detection and
response within a spatial region assigned by the con-
trolling node. The image composition node receives
all resulting images from the computing nodes and
composes them into the final result.
For each frame, the controlling node first performs
task decomposition for rendering nodes and physi-
cal computing nodes respectively according to load
information received from the latest frame. Then it
collects the collision detection/response results from
each physical computing node and generates update
information which will then be sent back to each com-
puting machine along with the rendering and physi-
cal computing tasks. The physical computing nodes
and the rendering nodes perform their tasks. Differ-
ent rendering results are sent to the image compo-
sition node and the collision detection/response re-
sults are sent back to the controlling node along with
load information such as rendering time and primitive
counts.
Client1 Client2 Client3 ClientN
…
LAN
Controlling Server
LAN
Image Composition Machine
Figure 1: Topology structure of our sort-first parallel ren-
dering system.
4 SCENE DATA
SYNCHRONIZATION
Alan Chalmers and Erik Reinhard (Chalmers and
Reinhard, 1998) pointed out that in a distributed sys-
tem, the option to maintain sequential consistency is
an expensive one. Therefore, the weak consistency
technique is proposed to improve the performance.
Using this technique, the local cache will stay incon-
sistent until the application process orders the data
manager to repair the inconsistency. We built our
scene data synchronization strategy on the base of
weak consistency. We use a frame-rate control strat-
egy to guarantee that each rendering node has ac-
cess to the updated data of moving objects in the
scene. To resolve the conflicts of octree update and
scene rendering in multi-thread environment, we use
a double-buffering approach. Finally, a strategy us-
ing overlapped octree region is proposed to avoid data
inconsistency during the collision detection/response
phase.
In parallel rendering system for dynamic scenes,
real-time communication of updated objects infor-
mation among each computing nodes is the key is-
sue. It is difficult to send updated objects informa-
tion to the rendering node which will render them in
the next frame before the rendering node starts to ac-
quire the information. To solve this problem, we set
up two time systems in our prototype system. Ren-
dering nodes compute object’s transformation matrix
using interpolation from its rendering time t
r
, orig-
inal position, velocity and acceleration stored in an
object information list. The physical simulation time
t
p
is ahead of rendering time by φ seconds. Physical
computing nodes use this period of time to process
GRAPP 2011 - International Conference on Computer Graphics Theory and Applications
208

data pre-processing and objects information update.
φ adaptively changes during the rendering process,
guarantee that every rendering node can get access to
the updated data of moving objects.
If t
r
runs ahead of t
p
, data inconsistency of ob-
jects in different neighboring rendering nodes will
be caused. To prevent such situation, we propose a
duplex frame-rate control method, using both time
control and frame number synchronization. In our
method, physical computing nodes and rendering
nodes receive instructions from both the controlling
node and the image composition node to maintain a
smooth frame rate. As shown in figure 2, the simula-
tion and rendering starts together when all computing
nodes in the clusters have connected to both the con-
trolling node and the image composition node. Each
physical computing node sends different updated ob-
jects information to controlling node according to dif-
ferent task distribution. After the data processing,
the controlling node sends the information to object
information list on each rendering node. Each ren-
dering node renders different part of the result image
with an unique frame number according to its unique
task distribution, then sends the image to the compo-
sition node, when images from all rendering nodes
with the same frame number are received by the im-
age composition node, rendering nodes can start the
rendering of the next frame. A frame-rate control pro-
gram runs on each rendering node turns the rendering
thread to sleep when t
p
− t
r
< φ for a shot period of
time: (φ − (t
p
− t
r
)). This strategy minimizes the cou-
pling between rendering nodes and physical comput-
ing nodes and gives us the convenience of generat-
ing different task distribution for rendering nodes and
physical computing nodes.
Image
Composition
Node
Controlling
Node
Computing
Nodes
Request
Permission of
Rendering Next Frame
Rendering Tasks and
Physical Computing Tasks
Sub Images
Simulation time and
rendering time too close,
Start Frame-rate Control
Figure 2: The Frame-Rate Control Strategy.
Due to the reason that our division of physical
computing node and rendering node is only concep-
tual, one machine with multi-core CPUs can be both
the physical computing node and the rendering node
to take the advantage of parallel power. If we use
one set of octree for both objects information update
and octree traverse for rendering, a read/write con-
flict might be caused. We proposed a special double-
buffering approach as our memory optimization strat-
egy. We use two set of octrees pointed to a single data
set, one is in charge of objects information update and
the other is in charge of octree traverse for model ren-
dering. Two octrees switch their tasks every frame.
Thus we get a good balance between data delay and
data inconsistency. Experiments show that by using
this strategy, no read/write conflict is caused during
the running of the system.
According to the physical computing task distri-
bution, each physical computing node only processes
physical simulation in a sub-region of the whole
scene. Objects on the boundaries of the sub-region
may collide with objects from other sub-regions, due
to the missing of objects information from other
regions, such collisions would be mistakenly over-
looked by the physical computing node. The solution
is to use an overlapped octree region for each physical
computing node. Information of the objects in over-
lapped regions is stored in every octree node which
contains these regions. We add a data preprocessing
program at the controlling node to remove the redun-
dant collision information caused by overlapped oc-
tree regions.
5 IMPLEMENTATIONS AND
RESULTS
We implemented our prototype system using 18 com-
puters with Intel Core(TM)2 Quad CPU and Nvidia
GTX 260 GPU. One computer serves as the control-
ling node, one computer serves as the image compo-
sition node, all other 16 computers serve as both the
rendering node and the physical computing node.
We set up two dynamic scenes with automatic
camera tracking (see figure 3). The left one is the
explosion scene of 10,000 rigid objects and the left
one is 10,000 moving objects flying among buildings
of Tianjin Jiefang Southern Road. To test the scal-
ability of our system, we run our system with 4, 8,
and 16 computing nodes respectively. From the fig-
ure 4 we can conclude that our system has improved
the rendering performance with the increasing num-
ber of computing nodes used in the system. Though
with too many computing nodes, the overload from
network may balance out the performance improve-
ment.
Figure 5 shows the effectiveness of our scene data
synchronization strategy. Without our scene data syn-
chronization strategy, the right figure has an artifact in
the composition result caused by data inconsistency.
In the left figure, we use our scene data synchroniza-
tion to completely eliminate the scene data inconsis-
tency.
SCENE DATA SYNCHRONIZATION IN SORT-FIRST RENDERING SYSTEM FOR LARGE DYNAMIC SCENES
209
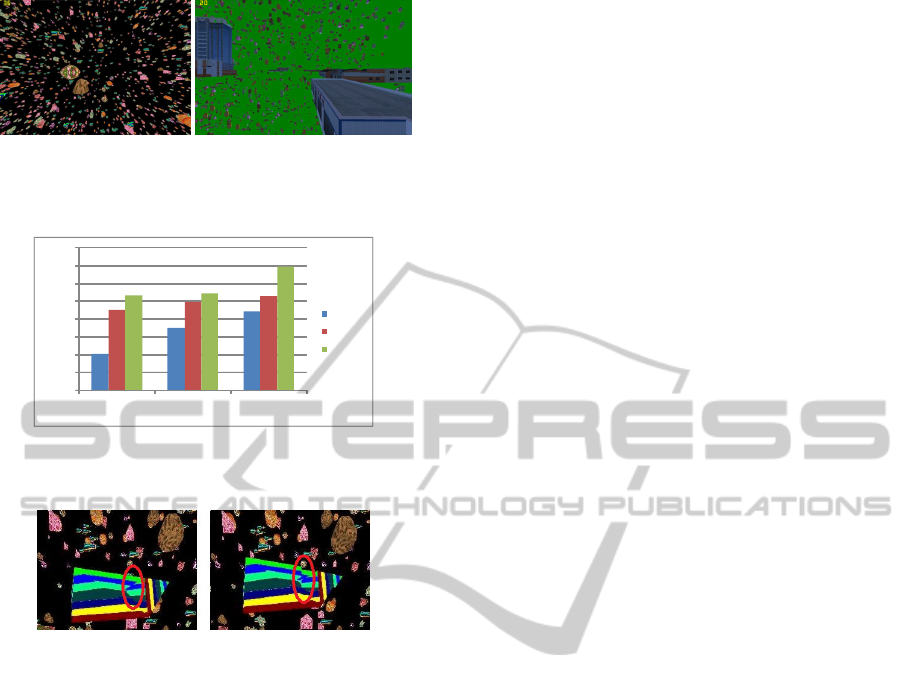
Figure 3: Left: Objects explosion scene (36 f ps, with
876,267 primitives); Right: City model scene (20 f ps, with
1,485,218 primitives).
0
5
10
15
20
25
30
35
40
4 Computing
Nodes
8 Computing
Nodes
16 Computing
Nodes
Frames Per Second
Min FPS
Avg FPS
Max FPS
Figure 4: FPS Comparison of our experimental scene with
4, 8, and 16 computing nodes.
Figure 5: Two frames(partial) at the same rendering time
with(left) and without(right) scene data synchronization
strategy.
6 CONCLUSIONS
We designed and implemented a cluster-based sort-
first parallel rendering system which is capable of ren-
dering large dynamic scenes with massive data. We
focus on scene data synchronization strategy based
on the weak consistency technique. To improve the
overall performance of the cluster-based parallel ren-
dering system, we proposed a set of algorithms to ac-
quire scene data synchronization in the rendering of
dynamic scenes with massive data. Experiments show
that our system has good scalability and the strategies
we proposed can effectively keep the scene data con-
sistency with interactive frame rate.
For future work we are interested in improving the
performance of the parallel rendering system by trans-
porting some of the scene data synchronization, scene
management and load balancing algorithms to GPU
Clusters. Future cluster-based parallel rendering sys-
tems should support both static scenes and dynamic
scenes, they should also be a hybrid of cluster parallel
and GPU parallel.
REFERENCES
Chalmers, A. and Reinhard, E. (1998). Parallel and dis-
tributed photo-realistic rendering. In Philosophy of
Mind: Classical and Contemporary Readings. Oxford
and, pages 608–633. University Press.
Humphreys, G., Eldridge, M., Buck, I., Stoll, G., Everett,
M., and Hanrahan, P. (2001). Wiregl: a scalable
graphics system for clusters. In SIGGRAPH ’01: Pro-
ceedings of the 28th annual conference on Computer
graphics and interactive techniques, pages 129–140,
New York, NY, USA. ACM.
Humphreys, G., Houston, M., Ng, R., Frank, R., Ah-
ern, S., Kirchner, P. D., and Klosowski, J. T. (2002).
Chromium: a stream-processing framework for inter-
active rendering on clusters. In SIGGRAPH ’02: Pro-
ceedings of the 29th annual conference on Computer
graphics and interactive techniques, pages 693–702,
New York, NY, USA. ACM.
Molnar, S., Cox, M., Ellsworth, D., and Fuchs, H. (1994).
A sorting classification of parallel rendering. IEEE
Computer Graphics and Applications, 14:23–32.
Mueller, C. (1995). The sort-first rendering architecture for
high-performance graphics. In I3D ’95: Proceedings
of the 1995 symposium on Interactive 3D graphics,
pages 75–ff., New York, NY, USA. ACM.
Pajarola, R. (2008). Cluster parallel rendering. In SIG-
GRAPH Asia ’08: ACM SIGGRAPH ASIA 2008
courses, pages 1–12, New York, NY, USA. ACM.
Samanta, R., Funkhouser, T., Li, K., and Singh, J. P. (2000).
Hybrid sort-first and sort-last parallel rendering with a
cluster of pcs. In HWWS ’00: Proceedings of the ACM
SIGGRAPH/EUROGRAPHICS workshop on Graph-
ics hardware, pages 97–108, New York, NY, USA.
ACM.
Samanta, R., Zheng, J., Funkhouser, T., Li, K., and Singh,
J. P. (1999). Load balancing for multi-projector ren-
dering systems. In HWWS ’99: Proceedings of
the ACM SIGGRAPH/EUROGRAPHICS workshop on
Graphics hardware, pages 107–116, New York, NY,
USA. ACM.
Staadt, O. G., Walker, J., Nuber, C., and Hamann, B. (2008).
A survey and performance analysis of software plat-
forms for interactive cluster-based multi-screen ren-
dering. In SIGGRAPH Asia ’08: ACM SIGGRAPH
ASIA 2008 courses, pages 1–10, New York, NY, USA.
ACM.
GRAPP 2011 - International Conference on Computer Graphics Theory and Applications
210
