
IMPROVING COOPERATIVE MANAGEMENT
Fuzzy Modeling and Proximity Networks
Seyed Shahrestani
School of Computing and Mathematics, University of Western Sydney
Locked Bag 1797, DC NSW 275, Penrith South, Australia
Keywords: Awareness modeling, Cooperative management, Fuzzy logic, Fuzzy proximity network, Network
management.
Abstract: The Internet, and perhaps of more relevance to this work, large enterprise networks are complex ICT
systems of prime business importance. The effectiveness of management of any complex system is heavily
dependent on understanding the functions of its components and their interactions with one another. As
such, quantifying collaboration and awareness levels can play significant roles in improving the
management efficiency. In most cases though, it is impossible to identify precise crisp models describing
the roles, functions, and interactions of such components in a useful manner. This can in turn be related to
the fact that the characterization of these concepts by human beings and managers is heavily based on the
use of linguistic variables. These variables and the communication of perceptions based on them are fuzzy
concepts in nature. This paper further elaborates these issues. To identify solutions, it discusses the relevant
notions of soft computing and explores the ways that the utilization of fuzzy awareness modelling can help
in improving cooperative management effectiveness.
1 INTRODUCTION
Provision of collaborative services requires
cooperation among various entities of an
organization. Associations and collaborations of
humans are partially or fully dictated by their level
of awareness of the ability of others to support them
to fulfil their responsibilities. As such, awareness
modelling and levels can play significant roles in
improving the management efficiency. To facilitate
collaborative services, some way to analyze
cooperation levels is needed. It is well established
that one of the fundamental problems in achieving
robust systematic solutions to problems encountered
in cooperative management environments relates to
the difficulty in quantifying collaboration and
awareness levels, for example see (Basker et al,
2002).
As discussed by several researchers, including
(Grudin, 1994) and (Lim, 2009), associations and
collaborations of humans are partially or fully
dictated by their level of awareness of the ability of
others to support them to fulfil their responsibilities.
One of the basic difficulties in achieving robust
analytical solutions in cooperative management
environments relates to the difficulty in quantifying
cooperation and awareness levels, for instance see
(Wang and Chang, 2004). These models heavily
depend on the use of intelligence. Conventional IT
solutions provide some degree of artificial
intelligence (AI) for processing and filtering the
data. However, human interactions remain essential,
as the data is often incomplete and conflicting or the
information may be irrelevant to the task in hand.
Furthermore, proper implementation and
utilization of AI enabled tools need to be considered.
For example, (Huang et al, 2008) have shown that
AI based network management systems that deal
with the problems at network layer, are mostly based
upon expert system techniques. From a broader
point of view, the ability to handle huge amounts of
information is a prerequisite for management of
complex systems. These issues have been discussed
in our previous works, for instance see (Shahrestani,
2008).
From a practical point of view, the assignment of
the awareness levels for various entities and roles
involved in a given task is more suitably achieved
with the linguistic propositions and words like
minimal or high. As we have shown before
71
Shahrestani S..
IMPROVING COOPERATIVE MANAGEMENT - Fuzzy Modeling and Proximity Networks.
DOI: 10.5220/0003645000710076
In Proceedings of the 6th International Conference on Software and Database Technologies (ICSOFT-2011), pages 71-76
ISBN: 978-989-8425-76-8
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

(Shahrestani, 2001), this can be related to the fact
that humans prefer to think and reason qualitatively,
which in turn leads to imprecise descriptions,
models, and required actions. Clearly in cooperative
management, the need for exploiting the tolerance
for imprecision and uncertainty to achieve
robustness and low solution costs is evident. This is
in fact, the guiding principle of soft computing and
more particularly fuzzy logic introduced by (Zadeh,
1965). In his break through work (Zadeh, 1994)
introduced the calculus of fuzzy logic as a means for
representing imprecise propositions (in a natural
language) as non-crisp, fuzzy constraints on a
variable.
This work will further discuss the utilization of
fuzzy logic concepts to identify a fuzzy framework
to quantify awareness levels to facilitate their
implementation. In that sense, uncertainty permeates
the entire management process. As we have
discussed before (Shahrestani, 2003), the latter piece
of information can be easily amended and handled
by fuzzy logic based approaches.
The remainder of this paper is structured as
follows. Section 2 establishes the background and
motivations for fuzzy awareness modeling. This is
further expanded in Section 3, where the design
framework incorporating the agent-based
cooperative management concepts are discussed. In
Section 4, notions relevant to fuzzy proximity
networks and execution of the design methodology
through are presented. The last section presents the
concluding remarks.
2 FUZZY AWARENESS MODEL
Awareness modeling is an area that has witnessed
significant research to define various types of
awareness and supporting awareness. In most of
these works, for instance see the pioneering works
(Grudin, 1994), it is argued that an individual’s level
of awareness is increased by insight and awareness
of information about a given event or object, rather
than by actually receiving that information. At any
case, to be of practical value in any collaborative
environment, a design methodology incorporating a
reasonable approach for utilization of awareness
levels is a prerequisite.
In most cases, some researchers such as (Wang
and Cheng, 2004) have argued that awareness levels
of an entity are altered by perception of information
about a given experience or object, rather than by
getting the actual information. Either way, for
effective integrated management, where shared
objectives and collaborations are the norm,
utilization of awareness levels is a requirement. In
this respect, it can be noted that in general it may be
advantageous to describe the awareness levels of any
role using the semantic definitions that are in fact
based on the use of linguistic variables, as first
discussed in (Mamdani, 1977). As stated before, it
can be noted that in general human beings
characterize the awareness levels of any role using
the semantic definitions through the use of linguistic
propositions and variables. For instance, a
supervisor may characterize a technician by simply
stating, “Technician D is the best in our group for
upgrading a particular link.” This can be easily
interpreted as: within the group of people of this
supervisor, D has the maximum awareness level for
that particular job. Such a characterization can be
conveniently modeled through utilization of fuzzy
logic and fuzzy modeling.
The fuzzy modeling is based on the fuzzification
of crisp values. For instance, assume that awareness
level, AL, of a given role, for instance technician D,
is defined in the crisp terms, e.g., between 0 and 4 in
the form
AL (D) = a (where a is crisply defined as a member
of {0, 1, 2, 3, 4}).
This is now replaced by
AL (D) is A.
where A is a fuzzy subset of the universe of the
awareness levels of the technician role. Following
on from the example above, for the most suitable
technician to do the job, the technician’s lowest
awareness level is represented by
AL (D) is maximal.
In this sense, while AL (D) = a, is a particular
description of the possible values of the technician’s
awareness level, the fuzzy set A represents a
possibility distribution. Now, the possibility of the
linguistic variable AL (D) is represented by a
linguistic value as the label of the fuzzy set taking a
particular (numerical) value b given by
Possibility {AL (D) = b} =
μ
A
(b).
The knowledge about AL of each role for a
given task that is based on linguistic variables can
act as a descriptive and flexible profile for that role.
Given the semantic definitions that are actually
based on the use of linguistic variables this notion of
fuzzy logic is obviously more appropriate. More
specifically, the fuzzy values signify a technician’s
AL that can be used for different purposes. The
profiles can be used for identifying and ranking of
suitable technicians for a given task or conversely,
for a given technician it provides a means for
detection of the additional knowledge that the
technician needs to carry out a given task efficiently.
ICSOFT 2011 - 6th International Conference on Software and Data Technologies
72

Furthermore, through forming of fuzzy clusters of
profiles, one can establish aggregate profiles. Such
aggregate profiles can be used an overall picture of
the AL of the technicians within the organization.
One can now characterize interactions with fuzzy-
based definition of the awareness levels. These
provide for the description of the complex systems
and interactions using the knowledge and experience
of customers, managers, and others involved using
simple semantics.
3 DESIGN STRUCTURE
This work is based on the proper choice of the
repositories and information as guided by the
collaboration of all the individuals involved in
accomplishing a common goal. This may lead to the
concept of virtual awareness levels. The information
repositories are mostly structured on the utilization
of compound document-centric object architecture
similar to those described in (Umar, 1997).
Compound document architecture, made popular
through Microsoft Active X/DCOM, helps express
structured and unstructured knowledge in the form
of documents with hyperlinks. Over the years, they
have greatly evolved and are the cornerstone of web-
based document systems. In this sense, the required
awareness and the needed information are
essentially provided using compound documents
based on an object-oriented and web-based system
accessible via a browser and search engines.
Given the required awareness levels for the
variety of tasks in complex systems, each human
role is provided with a software agent. Each agent
attempts to provide the required awareness level to
the human role it is serving by interaction with other
agents and by search through the information base.
The implementation of such a multi-agent
framework needs to consider a range of intelligent
techniques, such as case-based reasoning, active
directories, neural networks, and appropriate rules
and policies.
To improve cooperation and efficiency, each role
through its agent, must be capable of determining all
relevant information for the task. In other words, the
task rather than the individual should dictate the
relevance of information and passing them on to the
human role. The information that is passed to the
individuals is built upon the possible connection
among various queries made by all involved
individuals. In this fashion, the overall conduct in
achieving the common goal can benefit from the
combined awareness levels of human roles and local
decisions.
As with normal practice in most human
organizations, to achieve overall coherency a
coordinator role is also considered. The role takes an
overall view of the tasks in hand. For instance to
avoid flooding any role with irrelevant or loosely
relevant information, the coordinator must be able to
grade the suitability of the information for the
individuals in accomplishing their functions in the
project. The correctness of the retrieval of such
information can be defined in the context of the
problem using the notion of membership in a fuzzy
set around the desired keyword.
Many of the current approaches are capable of
retrieving all relevant documents containing the
information that is indexed by the used keywords
and ranking them by some degree of relevance
according to the query made by an individual. In
most of these approaches, the presence or absence of
the keywords in the query and the indexing terms of
the documents form the basis for evaluation of the
relevance of a document to the query.
It can be note that generally speaking, it is easy
to combine multiple keywords within the query
made by an individual as an aggregate fuzzy set
using fuzzy operators. In a similar fashion, one may
propose that queries from several individuals can
also be based on the simplistic approach of
considering them as a single query with multiple
keywords.
However, as pointed out by many researchers,
for instance see (Horng et al, 2008) and (Shrivanian
and Lippe, 2009), basing IR systems on such
approaches will have fundamental shortcomings.
Among the basic deficiencies that need to be dealt
with here, is the lack of ability to express the
linguistic based queries made by humans in a formal
way needed for machine interpretation and
processing. Another and probably more fundamental
problem relates to identifying suitable ways for
representation and inference of concepts and the
context in which they appear. In machines, the
concepts need to be precisely defined, leading to
lack of generalization that in turn causes the number
of cases that need to be dealt with increase rapidly.
4 FUZZY PROXIMITY
NETWORK SCHEME
Within a cooperative environment, an intelligent
system can be built upon the collaborative nature of
IMPROVING COOPERATIVE MANAGEMENT - Fuzzy Modeling and Proximity Networks
73
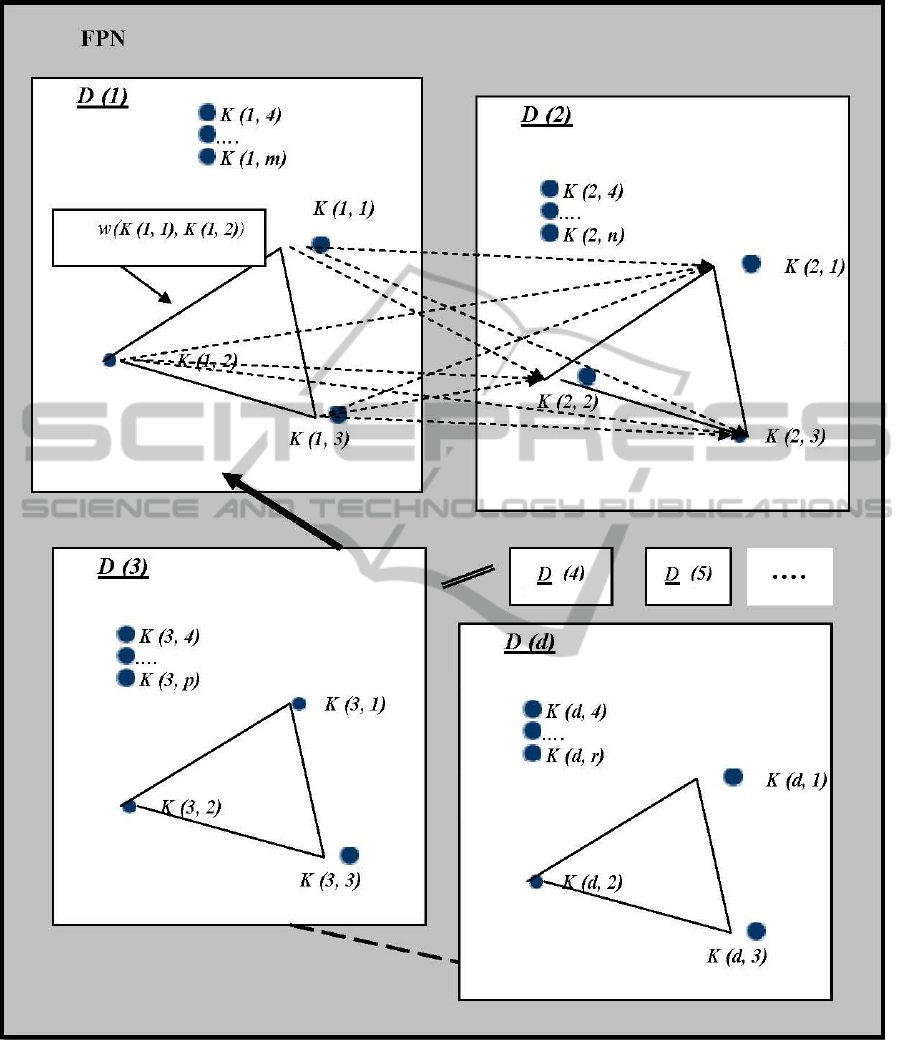
Figure 1: Formation of fuzzy proximity network (FPN).
the queries by noting the implicit connection
between the individuals. One of the main
applications of the awareness model of the user (or
its agent) is related to the use of the awareness level
terms as part of the query, resulting in an expanded
query. The intelligent information system will then
be able to elevate the awareness levels of the
individuals by pointing to them the data set items
they might have been missing otherwise.
As it will be shortly discussed, the Fuzzy
Proximity Network (FPN) performs the needed
aggregation. The network achieves the
representation of the fuzzy awareness engine for the
implementation of the multi-agent framework.
ICSOFT 2011 - 6th International Conference on Software and Data Technologies
74

Through computation with words and the use of
linguistic variables, the solutions need to manage the
inherent fuzziness in human queries, representation
of concepts and coordination, properly and
efficiently.
To address the lack of flexibility in representing
documents and queries, fuzzy systems that deal with
this type of problem for individual users have also
been studied and developed by several researchers.
In such approaches, a fuzzy set will represent each
keyword. The membership value of each piece of
information or document indicates its degree of
relevance to the fuzzy set denoted by the keyword.
In this way, it is easy to use linguistic qualifiers for
computing with words to help the information
retrieval process. While this can help in indexing
and the querying process, users can also employ it to
provide feedback information. Such information can
be used to evaluate the retrieval system and in turn
for evaluation of the awareness agent.
A scheme that is based on fuzzy proximity
networks in line with the work reported in (Shenoi,
1989) can be utilized to build the required intelligent
system. The network is capable of providing
coordination services for cooperating agents. It can
also conveniently take the technicians’ awareness
levels and profiles into account while processing
their queries. The coordinator role and its agent can
evaluate and aggregate the queries from individual
agents to help the cooperating agents in achieving
their common goal. One important aspect of such
coordination relates to connecting the cooperating
agents by pointing information and documents
relevant to their task, even when one agent has not
asked for them. To achieve this, the system needs to
be able to process queries from different cooperating
users as collaborative queries. In this case, each
node i of the fuzzy proximity network represents a
keyword. The weight w(i, j) represents the fuzzy
relevance of the two keywords at nodes i and j. Such
a scheme does emphasize the keyword structures
and connections, rather than focusing on the
keywords themselves. The relevance between the
keywords is based on the co-occurrence of a
keyword or the so-called Miyamoto’s measure,
similar to what is reported in (Miyamoto, 1983).
Stated simply, this measure implies that the more
often two keywords occur simultaneously, the higher
is their relevance to one another.
Consider a fuzzy proximity scheme, partially
shown in Figure1. Here, as in any case of practical
importance, the pieces of information are in several
documents, including a document d denoted by D
(d), where the k
th
keyword in d is represented by
K(d, k). The keywords within any given document
are considered to be related to each other. For
instance, keywords K (1, 1), K (1, 2), … K (1, m) are
considered to be related, as they appear within the
same document, D (1). The fuzzy relevance of
keywords is represented by the weight w between
their respective nodes. For example, here the fuzzy
relevance between the two keywords K (1, 1) and K
(1, 2) is represented by the weight w (K (1, 1), K (1,
2)). In accordance with the co-occurrence concepts,
if document D (1) refers to another piece of
information in D (2) or is referred to by the
information content of D (3), then the keywords K
(2, 1), K (2, 2), … K (2, n) as well as the keywords K
(3, 1), K (3, 2), … K (3, p) are also considered to be
related to each other, although in a weaker sense.
This type of information will establish the initial
setting of weights in the network model. Obviously,
after this initial stage, the weights can be updated
through adaptive mechanisms and supervised
learning.
For each document, its characterizing attributes
are calculated based on a maximum spanning tree,
see (Sun, 1990). Here, as in several other
applications, a spanning tree is the tree that covers a
given set of nodes, i.e. keywords. The weight of the
tree W (.), is the sum of the weights of the branches
in that tree. A maximum spanning tree is established
as the tree with the maximum weight for a particular
set of nodes. Given a query Q (q), its maximum
spanning tree weight W (Q), is used as the
characterizing measure of the query. The weight of
the maximum spanning tree for the keywords
common between Q (q) and a document D (d)
divided by W (Q) is used to represent the
characterizing attribute measure R (.), of document
D (d) with regard to Q (q). These characterizing
attributes calculated for all of the documents, are
then used for ranking the documents with regard to
their relevance to the query Q (q).
In summary, each human role in a cooperative
management environment is supported by a software
agent that assists the process to collaboration by
helping realize the right level of awareness at the
right time for each collaborating role. Although
conceptually one could use many different
paradigms of artificial intelligence (e.g., case based
reasoning, model-based reasoning, fuzzy logic etc),
this paper discusses the design of an awareness
agent based on fuzzy logic. It is possible to use a
number of ways to involve fuzzy logic in the design
of such systems, as discussed in (Shahrestani, 2005).
Here, the Fuzzy Proximity Network (FPN) has
provided us with a simple example that illustrates
IMPROVING COOPERATIVE MANAGEMENT - Fuzzy Modeling and Proximity Networks
75

the role of fuzzy logic in the practical deployment of
awareness model in any cooperative information
system design.
Additionally, the previously established levels of
awareness for different individuals involved in a
project are used in conjunction with their queries to
form a joint index set. These can be considered as
the virtually combined queries from several
collaborating individuals. They form the basis for
the retrieval of several inter-related pieces of
information that improve the awareness levels of all
group members cooperating to achieve a common
goal. It is worth noting that the virtual joint query is
not formed through a union of the keywords used in
the queries of the individuals. The joint query is
rather based on reflection of combination of the
keywords, structure and the supposed awareness
levels of the involved individuals. They account for
the connection of keywords that are linked together
to form a structured concept. This is achieved by
using the characterizing features based on the
maximum spanning trees. Given that the information
from various collaborators are being combined, the
amalgamation of the keywords, rather than
emphasizing on the keywords themselves, is highly
beneficial.
5 CONCLUSIONS
This paper has discussed fuzzy awareness modelling
as part of an efficient cooperative management
design framework. In the proposed framework,
higher levels of cooperation are facilitated through
collaborative joint queries. These queries result in
higher awareness levels for the combined roles of all
individuals involved in a given task The framework
is based on multiple agents, where each human role
is supported by an agent. The development of multi-
agent cooperative management systems is based on
the notions of fuzzy logic and processing of
linguistic variables. The development and
implementation of an FPN for management
information retrieval was used as an illustrative
example.
REFERENCES
D. Bakser, D. Georgakopoulos, H. Schuster and
A.Cichocki, 2002. Awareness Provisioning in
Collaboration Management. In Int. Journal of
Cooperative Information Systems, vol. 11.
J. Grudin, J., 1994. Computer supported cooperative work:
history and focus. In IEEE Computer Magazine.
Lim, E., Tam, H., Wong, S., Liu, J., and Lee, R., 2009.
Collaborative content and user-based web ontology
learning system. In Proceedings IEEE International
Conference on Fuzzy Systems, FUZZ-IEEE 2009.
Wang, Q., Cheng, L., 2004. A flexible awareness
measurement and management architecture for
adaptive applications. In Proc. Global
Telecommunications Conference.
Huang, Y., Chen, J., Kuo, Y., and Jeng, Y., 2008. An
intelligent human-expert forum system based on fuzzy
information retrieval technique. In Expert Systems
with Applications, 34 (1).
Shahrestani, S., 2008. Utilization of Soft Computing to
Improve Cooperative Management Efficiency. In
WSEAS Transactions on Circuits and Systems, 7 (7).
Shahrestani,S., 2001. Fuzzy logic and integrated network
management. In Proceedings Fuzzy Logic and the
Internet-FLINT.
Zadeh, L. A., 1965. Fuzzy sets. In Information and
Control, vol. 8.
Zadeh, L. A., 1994. Soft computing and fuzzy logic. In
IEEE Software, vol. 11, no. 6.
Shahrestani, S., 2003. Fuzzy detection and integrated
network management. In Enhancing the power of the
Internet: Studies in Fuzziness and Soft Computing,
Editors: M. Nikravesh, L. A. Zadeh, B. Azvine, and R.
Yagar, Springer.
Mamdani, E., 1977. Application of fuzzy logic to
approximate reasoning using linguistic synthesis. In
IEEE Trans. Computers, vol. 26.
Umar, L., 1997. Client-Server Object-Oriented Internet
Environments, Prentice Hall.
Horng, Y., Chen, S., Chang, Y., and Lee, C., 2008. A new
method for fuzzy information retrieval based on fuzzy
hierarchical clustering and fuzzy inference techniques.
In IEEE Trans on Fuzzy Systems,” 13 (2).
Shirvanian, M. and Lippe, W., 2009. Efficiency increase
of fuzzy query languages by using indexes for selected
operations. In Proceedings IEEE International
Conference on Fuzzy Systems, FUZZ-IEEE 2009.
Shenoi, S., and Melton, A., 1989. Proximity relations in
the fuzzy relational database model. In Fuzzy Sets and
Systems, vol. 31.
Miyamoto, S. S., Miyake, T. and Nakayama, K., 1983.
Generation of a pseudo-thesaurus for information
retrieval based on co-occurrences and fuzzy set
operation. In IEEE Trans. On Systems, Man, and
Cybernetics, vol. 13, no 1.
Sun, C., 1990. An information retrieval model for
coordination systems based on fuzzy proximity
networks. In Proc. IEEE International Conference on
Systems, Man and Cybernetic.
Shahrestani, S., 2005. Exploiting Structure and Concepts
for Enhanced Management of Information and
Networked Systems. In World Scientific and
Engineering Academy and Society Transactions on
Computers, issue7, vol. 4.
ICSOFT 2011 - 6th International Conference on Software and Data Technologies
76
