
A ROBUST BACKGROUND SUBTRACTION ALGORITHM USING
THE A Σ − ∆ ESTIMATION
Applied to the Visual Analysis of Human Motion
Juan Carlos Le
´
on, Fabio Mart
´
ınez and Eduardo Romero
CimaLab, Universidad Nacional de Colombia, Bogot
´
a, Colombia
Keywords:
Background Subtraction, Motion Analysis, Σ∆ Estimation.
Abstract:
This paper introduces a novel method for segmenting the human silhouette in video sequences, based on
a local version of the classical Σ∆ filter. A main difference of our approach is that the filter is not pixel-
wise oriented, but rather region wise adjusted by using scaled estimations of both the pixel intensity and the
horizontal (vertical) gradient, i.e., a multiresolution wavelet decomposition using Haar functions. The classical
Σ∆ filter is independently applied to each component of the obtained feature vector, previously normalized and
a single scalar value is associated to the pixel by averaging the feature vector components. The background
is estimated by setting a threshold in a histogram constructed with these integrated values, attempting to
maximize the interclass variance. This strategy was evaluated in a set of 6 videos, taken from the Human Eva
data set. Results show that the proposed algorithm provides a better segmentation of the human silhouette,
specially in the limbs, which are critical for human movement analysis.
1 INTRODUCTION
Visual analysis of human motion implies the detec-
tion, follow up and characterization of relevant pat-
terns in a sequence of images. Usually the main
features to detect are the position and alignment of
the human body parts (human pose). While visual
markers can be employed for this task(Kirtley, 2005),
the result is usually a simplified model of the human
body. Most detection methods use a background esti-
mation as preprocessing step, attempting to eliminate
pixels with no temporal change.
Background subtraction methods use a sequence
of images ({I
i
}
i=1:t
) to build a model of the static
scene (M
i
), and establish a rule to set a pixel value
in I
i
as either background or foreground.
A main contribution of the present paper was to
adapt the classical Σ∆ pixel wise estimation to a lo-
cal version of the filter, which is much more robust
to local variations and tracks better the image object
edges. The basic idea was to approach the pixel in-
formation with a multiresolution decomposition, con-
serving the edge features in the gradient estimations
while the low frequency characteristics regularize the
numerical difference, i.e., a classical wavelet approx-
imation. The obtained Haar coefficients are used in-
dependently in a classical Σ − ∆ estimation, averaged
and used to construct an histogram in which an opti-
mal threshold maximizes the interclass variance. This
paper is organized as follows: Section 2 introduces
the Σ − ∆ operator, and the proposed extension, sec-
tion 3 demonstrates the effectiveness of the method,
finally section 4 concludes with a discussion of the
proposed method and possible future works.
2 MATERIALS AND METHODS
Among the background subtraction techniques, the
Σ−∆ operator represents a family of background sub-
traction methods, well known for their computational
efficiency and capability to work without any prior
knowledge of the scene, even in no controlled illumi-
nation conditions.
While this operator offers a baseline for back-
ground subtraction in human movement analysis, it
is still limited regarding its accuracy and robustness
to noise. As observed in figure 1, relevant parts of the
human figure, as the shins and lower arms, are miss-
ing. Noise is present on the image, especially while
the model converges to a good approximation of the
background.
These limitations can be attributed to the selected
484
Carlos León J., Martínez F. and Romero E..
A ROBUST BACKGROUND SUBTRACTION ALGORITHM USING THE A Σ-â
´
L ˛E ESTIMATION - Applied to the Visual Analysis of Human Motion.
DOI: 10.5220/0003868204840489
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2012), pages 484-489
ISBN: 978-989-8565-03-7
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

Figure 1: Output of the Basic Σ − ∆ Algorithm for a se-
quence of the Human Eva Dataset.
pixel descriptors in a single frame, i.e. the regu-
lar Σ − ∆ uses a single pixel intensity. This may be
better approached by introducing local information.
The present investigation proposes an extension of the
Σ − ∆ background subtraction algorithm, focusing on
region features rather than on pixel intensity.
2.1 The Σ − ∆ Operator
The non linear operator Σ∆ increases the correlation
between adjacent frames by oversampling a signal at
higher rates than the specified by the Nyquist theo-
rem. This operator dynamically updates a background
model M
t
(x), by comparing each image I
t
(x) with the
current background model M
t
(x), using a simple up-
dating rule: If I
t
(x) is greater (lower) than M
t
(x), then
a positive increase (decrease) ∆ is performed. The ab-
solute difference |I
t
(x)−M
t
(x)| is used to compute an
estimate of the per pixel variance V
t
(x), based on this
estimate pixels are classified as either foreground or
background (Manzanera and Richefeu, 2007), a de-
tailed description can be found on algorithm 1.
2.2 Region Features
As stated above, a main limitation of the Σ∆ back-
ground subtraction is that it operates exclusively over
the intensity values of a pixel through an image se-
quence I
t
, restricting thereby the accuracy and ro-
bustness of the background estimation process. We
approached herein this problem by projecting each
frame I
t
into a multiresolution space. Unlike a clas-
sical multiresolution decomposition, the different im-
age scales are not herein obtained by a simple down-
sampling of the original image, but rather by a local
pixel neighbourhood smoothing upon which a block
Haar wavelet analysis is carried out. In our scheme
Algorithm 1: Basic Σ − ∆ Algorithm.
Initialization: M
0
(x) = I
0
(x)
for each Frame t do
M
t
(x) = M
t−1
(x) + sgn(I
t
(x) − M
t−1
(x))
∆
t
(x) =
|
M
t
(x) − I
t
(x)
|
end for
Initialize: V
0
(x) = ∆
t
(x)
for each Frame t do
for each pixel x such that ∆
t
(x) 6= 0 do
V
t
(x) = V
t−1
(x) + sgn(N × ∆
t
(x) −V
t−1
(x))
if ∆
t
(x) < V
t
(x) then
D
t
(x) = 0
else
D
t
(x) = 1
end if
end for
end for
we use a set of features calculated from the Speeded
Up Local Descriptor (SULD), proposed by Zhao et
al. (Zhao et al., 2009) and now on used as a pixel
descriptor. The low frequency is computed as the av-
erage of a neighbourhood centred at the pixel, while
the high frequency is calculated by firstly averaging
a spatial shifted version of the previously used neigh-
bourhood, and then differences between the up-down
(left-right) shifted neighbourhoods are stored. The
calculated values are closely related to the gradients
and therefore to the edges along the x and y axes, as
seen in figure 2. Each image pixel is associated to
a feature vector with three components containing an
average of the different scale pixel descriptors, i.e.,
the neighbourhood sizes. This allows to systemati-
cally remove finer details or high-frequency informa-
tion from an image, achieving a compact description
of the most relevant information which is usually pre-
served through multiple scales. Therefore, the first
step of our approach was to build, for each pixel, a
multidimensional feature vector containing the local
first order information.
These features are calculated for each of the n
channels of the image and used as input of the Σ − ∆
algorithm, after normalization, yielding a 3n dimen-
sional descriptor for each pixel.
2.2.1 Efficient Feature Calculation
Two of the features are calculated as the difference of
the sum of pixel intensities within two shifted boxes,
either vertically or horizontally. This can be effi-
ciently computed using the summed area table known
as the integral image (Viola and Jones, 2001), case in
which an image (ii) replaces a pixel value (i) with the
sum of the intensity of every pixel located above and
A ROBUST BACKGROUND SUBTRACTION ALGORITHM USING THE A ∑-∆ ESTIMATION - Applied to the
Visual Analysis of Human Motion
485

Figure 2: Descriptors, from left to right: original image, vertically and horizontally filter response maps, sum of values in
region.
before it, formally:
ii(x, y) =
∑
x
0
≤x
∑
y
0
≤y
i(x
0
, y
0
) (1)
The use of the integral image optimizes calculation of
the region intensity sum as:
∑
j<x
0
≤k
∑
m<y
0
≤n
i(x
0
, y
0
) = ii( j,m)+ii(k, n) −ii(k, m) −ii( j, n)
(2)
2.3 Foreground Classification Criteria
The basic Σ− ∆ algorithm uses a simple classification
criterion: the last pixel intensity variation (∆
t
(x)) is
compared with an estimation of the cumulated vari-
ance (V
t
(x)), if the result is positive then the pixel
is marked as foreground, otherwise it is considered
as background (see algorithm 1). This metric does
not fit our multidimensional representation: while the
mentioned criterion may be applied to each feature,
another metric must be built to produce a final deci-
sion from the obtained set of per-feature decisions.
To overcome these limitations, we propose a multidi-
mensional metric that associates the feature vector to
a single scalar value, obtained by integrating on ev-
ery feature component and shifting from the [−1, 1]
to the [0, 2] interval. Each image pixel is assigned
then to a particular (P
t
) value, an estimate of the re-
gional changes, the higher (lower) a P
t
value is the
more (less) likely the corresponding pixel in I
t
is a
foreground pixel. A change is then defined if the his-
tory of regional changes is smaller than the change
reported by the current local analysis. For achieving
so, we exploit the characteristics of the histogram’s
waveform of P
t
, where background pixels are near 0
and their number is significantly larger than the fore-
ground pixels. Hence we build two classes, one with
a small (large) number of bins which contains most
(few) scene pixels: the background (foreground). We
are interested in a value that maximizes the intra-class
variance by comparing the variances of the two pre-
viously defined classes. For doing so, let us suppose
that we have k different bins, starting from an initial
bin, a class is composed of a set of bins that are pro-
gressively increased by including new bins into the
class. The algorithm includes new bins in each class
by running forward (backward) over the histogram,
starting from 0 and k for the background and fore-
ground classes, respectively. The goal is to stop when
the variance of the two classes is alike and its mag-
nitude is maximum. We search then for a bin (γ)
where the consecutive per group variances are close
and large in magnitude for both classes as follows:
for a histogram with k bins let
α
i
= var(bin
0
....bin
i−1
) − var(bin
0
....bin
i
) (3)
the consecutive variance of a background estimation
composed of bins 0 to i, likewise let
β
i
= var(bin
k
, ..., bin
i+1
) − var(bin
k
, ..., bin
i
) (4)
the difference of variances for the foreground group
up to bin i. A set of candidate bins Γ
i
is stablished
with
i ∈ Γ ⇐⇒
α
i
β
i
≈ −1 (5)
Among all the candidates in Γ
i
we choose γ as as
the one with the larger magnitude in the variance dif-
ferences i.e.
γ = max
Γ
i
|α
i
β
i
| (6)
2.4 Dataset Description
Validation was carried out with a subset of the Hu-
man Eva Dataset (Sigal et al., 2010), composed from
3 different subjects, each captured from 2 different
cameras for a total of 6 sequences. Each sequence
was manually labeled, as frame n has almost the same
foreground and background of frame n ± 1 labeling
was done only once per 10 frames, additionally the
labeling only started at the 40th frame this accounts
for an initial estimation of the background (stabiliza-
tion) of both algorithms.
3 EVALUATION AND RESULTS
There are well know metrics to evaluate the perfor-
VISAPP 2012 - International Conference on Computer Vision Theory and Applications
486

mance of a binary classification, however most of
these metrics assume that there is approximately a
balanced quantity of elements in the classes. In this
dataset the foreground usually amounts to less than
the 10% of pixels in the image, hence we choose the
true positive rate (TPR), and the Matthews Correla-
tion Coefficient (MCC), the former is independent of
the class distribution, while the later is designed to
measure the quality of the classification even with un-
balanced classes.
During the evaluation of the algorithm it was clear
that scales (box sizes) larger than 11 were not appro-
priate for the segmentation of relative small objects
in movement (like the hands and forearms), also the
body boundaries are not properly located. Therefore
we first seek for a combination of scales between 1
and 11 that provides the best results, for this partic-
ular dataset the selected scales were 1,3 and 5. The
results are summarized in tables 1 & 2.
Table 1: True positive Rate.
Sequence Regular Σ − ∆ TPR Proposed Σ − ∆ TPR
1 37.94% 67.46%
2 55.73% 68.95%
3 31.61% 69.23%
4 57.63% 73.25%
5 48.62% 71.94 %
6 65.86% 78.05%
Table 2: Matthews Correlation Coefficient.
Sequence Regular Σ − ∆ MCC Proposed Σ − ∆ MCC
1 0.557 0.683
2 0.707 0.678
3 0.524 0.721
4 0.725 0.731
5 0.656 0.713
6 0.767 0.774
The TPR of the proposed method outperforms the
regular Σ∆ in every test sequence, this can be at-
tributed to the better detection of the limbs in motion,
specially the shins and forearms (see figure 6).
An interesting feature of the proposed algorithm
can be analysed with table 1, our method offers a large
improvement for sequences 1, 3 and 5 (30.06% aver-
age) however the improvement for sequences 2, 4 and
6 is smaller (13.71% average). This is related to the
background of the sequences, on the first group the
background has several objects of different colors on
it i.e. it contains borders, the background of the later
group has a single color and is nearly flat (see figure
3). The absence of borders lowers the effectiveness of
the proposed algorithm as the input information for
the Σ∆ comes mainly from the intensities of neigh-
bouring pixels.
Figure 3: Sequences 2,4,6 on the left side, sequences 1, 3, 5
on the right side.
While the TPR shows a significant improvement
of our algorithm over the regular Σ∆, the MCC shows
cases where there is not a significant improvement
over the base algorithm. This can be attributed to the
nature of the dataset, where the moving object (human
body) is present and in motion on the first frames, this
generates ghosts on every scene for both algorithms,
these ghosts last longer in our algorithm thus increas-
ing the amount of False Positives on the first frames,
drawing down the average MCC for the sequence.
This can be seen in figures 4 and 7, while the first
frames show an MCC for the proposed algorithm un-
der the MCC of the regular sigma delta, on the next
frames (when the ghost starts to fade) the MCC of
our algorithm is better, even in the second sequence,
where out algorithm had an average MCC under the
regular Σ∆ (fig. 4).
Again the nature of the background seems to have
influence on how long the ghosts last, scenes 1, 3
and 5. have ghosts that last shorter than the ghosts
in scenes 2,4,6.
3.1 Performance
As stated on section 2, one of the main features of the
Σ∆ Background subtraction is its computational effi-
ciency, therefore we briefly analyze the performance
penalty of the multiscale features and the new classi-
fication criterion.
A GNU Octave implementation of both algo-
rithms was tested on an core i7 processor at 3.3 Ghz,
on this set up the average the regular Σ∆ can pro-
cess 6.72 million pixels per second. The speed of the
proposed extension depends on the number of scales
A ROBUST BACKGROUND SUBTRACTION ALGORITHM USING THE A ∑-∆ ESTIMATION - Applied to the
Visual Analysis of Human Motion
487
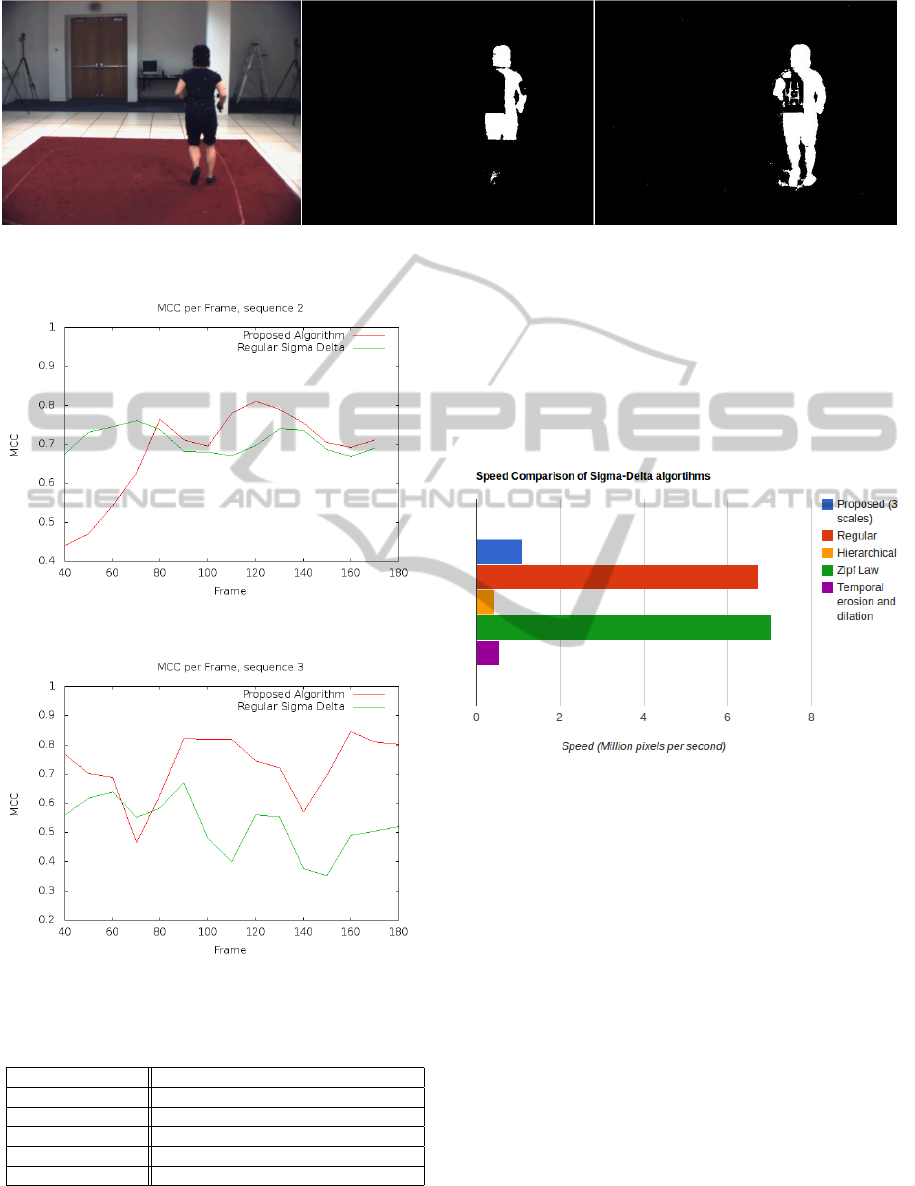
Figure 6: Results of the segmentation, from left to right, Original image, regular Σ∆ segmentation, proposed algorithm
segmentation.
Figure 4: Comparison of the per frame MCC for sequence
2.
Figure 5: Comparison of the per frame MCC for sequence
3.
Table 3: Proposed algorithm processed pixels per second.
Number of scales Average pixels per second (millions)
1 1.61
2 1.31
3 1.06
4 0.89
5 0.77
used for the analysis, we calculated the average speed
of the proposed algorithm for a number of scales be-
tween 1 and 9, the results are summarized on table 3.
Although the base Σ∆ is faster, when the proposed
algorithm is compared with other variations of the
Σ∆ operator for background subtraction proposed on
the literature (Manzanera, 2007)(Lionel Lacassagne,
2009) (Richefeu and Manzanera, 2006) it shows an
average performance (see figure 7).
Figure 7: Speed of other Σ∆ algorithms (million pixels per
second).
4 CONCLUSIONS
An novel method for segmenting the human silhou-
ette in video sequences based on the Σ∆ background
subtraction, was introduced on this paper, this method
offers a significant improvement in the background
segmentation over the base Σ∆, at the expense of com-
putational cost.
The proposed algorithm enhances the pixel de-
scription with local features, allowing a multiscale
representation of each frame, which results in an im-
proved detection of the human body silhouette, this
methods improves the quality of the segmentation,
specially at the arms and lower limbs, which is critical
for tasks that require a proper description of the dy-
namics of the human body, as gait analysis and video
surveillance.
VISAPP 2012 - International Conference on Computer Vision Theory and Applications
488

REFERENCES
Kirtley, C. (2005). Clinical Gait Analysis: Theory and
Practice. Churchill Livingstone.
Lionel Lacassagne, A. M. . A. D. (2009). Motion detection:
Fast and robust algorithms for embedded systems. In
IEEE International Conference on Image Processing.
Manzanera, A. (2007). Sigma-delta background subtraction
and the zipf law. In Progress in Pattern Recognition,
Image Analysis and Applications.
Manzanera, A. and Richefeu, J. (2007). A new mo-
tion detection algorithm based on [sigma]-[delta]
background estimation. Pattern Recognition Letters,
28(3):320–328.
Richefeu, J. and Manzanera, A. (2006). A new hy-
brid differential filter for motion detection. In Wo-
jciechowski, K., Smolka, B., Palus, H., Kozera, R.,
Skarbek, W., and Noakes, L., editors, Computer
Vision and Graphics, volume 32 of Computational
Imaging and Vision, pages 727–732. Springer Nether-
lands.
Sigal, L., Balan, A. O., and Black., M. J. (2010). Hu-
maneva: Synchronized video and motion capture
dataset for evaluation of articulated human motion. In-
ternational Journal of Computer Vision (IJCV), 87.
Viola, P. and Jones, M. (2001). Robust real-time object de-
tection. In International Journal of Computer Vision.
Zhao, G., Chen, L., and Chen, G. (2009). A speeded-up
local descriptor for dense stereo matching. In Im-
age Processing (ICIP), 2009 16th IEEE International
Conference on, pages 2101–2104.
A ROBUST BACKGROUND SUBTRACTION ALGORITHM USING THE A ∑-∆ ESTIMATION - Applied to the
Visual Analysis of Human Motion
489
