
3D INTERACTION ASSISTANCE THROUGH
CONTEXT-AWARENESS
A Semantic Reasoning Engine for Classic Virtual Environment
Dennemont Yannick, Guillaume Bouyer, Samir Otmane and Malik Mallem
IBISC Laboratory, Evry University, 40 Rue du Pelvoux, 91020 Courcouronnes, France
Keywords:
Interaction Techniques, Virtual Reality, Context-awareness, Intelligent Systems, Knowledge Representations.
Abstract:
This work focuses on 3D interaction assistance by adding adaptivity depending on the tasks, the objectives, and
the general interaction context. The context is modelled with Conceptual Graphs (CG) based on an ontology.
Including CG in our scene manager (Virtools) allows us to add semantic information and to describe the
available tools. Adaptation result from rules handled with a logic programming layer (Prolog+CG) included
in the Amine platform. This project is a step towards Intelligent Virtual Environments, which proposes a hybrid
solution by adding a separate semantic reasoning to classic environments. The first experiment automatically
manages few modalities depending on the distance to objects, user movement, available tools and modalities.
1 INTRODUCTION
3D interaction (3DI) immersion and usability are re-
inforced by the use of natural schemes. Meantime,
adaptivity based on context is natural in human com-
munication. Thus, we are designing a context and de-
cision manager that focuses on expressiveness and us-
ability in order to add adaptivity to 3DI. Through ex-
ploiting the context, we plan to best determine means
to effectively help the user. We start by introducing
some interests to achieve adaptative 3DI in the sec-
tion 2, then by positioning our work in the section 3.
We present in the section 4 a quick survey of meth-
ods for modelling and reasoning that motivates our
approach. Afterwards sections 5 and 6 present our
work in progress and perspectives.
2 3D INTERACTION
ADAPTATION INTERESTS
3DI adaptation is an approach suggested by many
researches (Wingrave et al., 2002)(Celentano and
Nodari, 2004)(Bowman et al., 2006)(Octavia et al.,
2010). As the ”perfect” 3D interaction technique has
yet to be found, a solution can be to adapt the in-
teraction to a task, a device, etc., by adding speci-
ficity. Flavors, i.e known techniques variations, to
improve usability are another form of adaptation. Ap-
plying automatically those kind of adaptations when
needed defines an adaptative 3DI (see (Paramythis,
2009) for details about automatic adaptations types).
Adaptative 3DI can be implicit with adaptations em-
bedded in the interaction techniques (Poupyrev et al.,
1996)(Boudoin et al., 2008), or explicit by using
external processes (Lee et al., 2004)(Celentano and
Nodari, 2004)(Bouyer et al., 2007)(Octavia et al.,
2010). 3DI adaptation is an open issue which some
advantages are:
• To speed up the interaction (Celentano and Nodari,
2004);
• To diminish the cognitive load (as in ubiquitous
computing );
• To tailor the interaction (Wingrave et al., 2002)
(Octavia et al., 2010);
• To add or manage interaction possibilities (Bouyer
et al., 2007).
To achieve such adaptations, we can:
• Choose other techniques (Octavia et al., 2010) as
the specificity idea;
• Make techniques variations (Octavia et al., 2010)
as the flavor idea;
• Add/manage modalities (Irawati et al.,
2005)(Bouyer et al., 2007)(Octavia et al., 2010);
• Perform automatically parts of the task (Celentano
and Nodari, 2004).
562
Yannick D., Bouyer G., Otmane S. and Mallem M. (2012).
3D INTERACTION ASSISTANCE THROUGH CONTEXT-AWARENESS - A Semantic Reasoning Engine for Classic Virtual Environment.
In Proceedings of the International Conference on Computer Graphics Theory and Applications, pages 562-567
DOI: 10.5220/0003946205620567
Copyright
c
SciTePress

3 TOWARDS
CONTEXT-AWARENESS
In order to go beyond basic interaction, adaptive sys-
tems can first provide recognition of higher level in-
formation from raw data (on an activity recognition
layer, Figure 1). But to achieve a better adaptivity, we
need more content description: the context.
Figure 1: Different layers to reach adaptive interaction.
A context formal and well recognized definition is
(Dey and Abowd, 2000): Context is any information
that can be used to characterize the situation of an
entity. An entity is a person, place, or object that is
considered relevant to the interaction between a user
and an application, including the user and applica-
tions themselves. Thus, our system for 3DI is context-
aware as it uses context to provide relevant informa-
tion and/or services to the user, where relevancy de-
pends on the user’s task.
Context-awareness is a multidisciplinary field that
uses similar tools than the knowledge representation
and reasoning field. But it also requires computer sci-
ence, physical sensors, cognitive sciences, etc. Intel-
ligent systems have evolved (Br
´
ezillon, 2011) toward
context-awareness and some encountered drawbacks
can be explained by full abstract reasoning or user ex-
clusion. Intelligent assistance systems can be split in
two trend. Systems tend to stress user assistance on
well defined context, e.g. (Bouyer et al., 2007), or to
stress context identification that leads to direct adap-
tations for each situation, e.g. (Coppola et al., 2009).
Context-aware applications have different main fo-
cuses (Figure 2) although they share an ideal list of
properties to handle (Bettini et al., 2010):
• Heterogeneity and mobility of context;
• Relationships and dependencies between context;
• Timeliness: access to past and future states;
• Imperfection: data can be uncertain or incorrect;
• Reasoning: to decide or to derive information;
• Usability of modelling formalisms;
• Efficient context provisioning.
Figure 2: Different families of context-aware applications.
Ubiquitous computing tries to improve and soften
the use of our surrounding chips and computers. Main
focuses are communication between devices, possi-
bilities of erroneous measurements and platforms lim-
itations. Applications are numerous, like MoBe (Cop-
pola et al., 2009) on smart phones.
Intelligent agents can be embodied in physical
world (e.g. robot), virtual world (e.g. autonomous
character) or can be hidden (e.g. genius loci (Celen-
tano and Nodari, 2004)). Main features are commu-
nication issues, agent memory, ability to manage and
reason on a local context, credibility or ability to re-
produce a human behaviour.
Semantic environment stores its own description
(e.g. the semantic web). Main focuses are: mak-
ing environment comprehensive by machine (Peters
and Shrobe, 2003), dealing with large scale environ-
ment, serving as a base for intelligence, automatic
world construction (Bonis et al., 2008) or introduc-
ing semantic on the rendering loop core (Lugrin and
Cavazza, 2007)(Soto et al., 1997).
Adaptative interaction tries to assist the user in his
interaction with a virtual environment. A very spe-
cific localisation of adaptation like Go-Go (Poupyrev
et al., 1996) or Fly-over (Boudoin et al., 2008) tech-
niques (where interaction depends on the position of
the user’s hand) are good adaptative 3DI examples.
Intelligent Virtual Environments (Aylett and Luck,
2000) mix artificial intelligence, artificial life and
virtual reality. It overlaps all classes and empha-
sises their reasoning capabilities. Applications often
process semantic information from the environment
(Celentano and Nodari, 2004)(Lugrin and Cavazza,
2007)(Latoschik et al., 2005)(Soto et al., 1997).
Ambient intelligence (Preuveneers, 2009) is a
multidisciplinary area based on ubiquitous comput-
ing, artificial intelligence and semantic objects. It is
basically the Intelligent Virtual Environments physi-
cal world version. Both overlap: e.g. intelligent phys-
ical sensors used in virtual reality, intelligent environ-
ments displayed on smart phones or mixed reality.
Our research is mainly in the adaptive 3D interac-
tion field. Yet, to achieve wider and better 3D interac-
tion, a richer context provided by adding or extracting
3D INTERACTION ASSISTANCE THROUGH CONTEXT-AWARENESS - A Semantic Reasoning Engine for Classic
Virtual Environment
563

semantic information in the environment and/or in-
telligent agents is needed. And reasoning needs will
grow with the available information. So our approach
is more generally a part of Intelligent Virtual Envi-
ronment. Next, we discuss our choices for modelling
context and reasoning to achieve these goals.
4 KNOWLEDGE
REPRESENTATION AND
REASONING
We need to manage context and to decide how to re-
act, which is a form of Knowledge Representation
and Reasoning (KR & R). More precisely, our system
needs first to retrieve and represent items of informa-
tion, possibly specific to an application, then to handle
this context and to define its effect on 3DI (discussed
by (Frees, 2010) for virtual reality).
However representation and reasoning are not to-
tally independent (e.g fuzzy logic reasoning needs a
membership function). Besides, expressive represen-
tations are usually less reasoning efficient. Expres-
siveness is a measurement of the complexity of the
expressible ideas, regardless of ease. Ease of expres-
sion and readability are included in usability.
Representations are various. Key-values are effi-
cient but do not have real semantic. Markup-models
typically introduce a fixed structure that brings se-
mantic as an information hierarchy. Further, ontolo-
gies are definitions of concepts and relations that are
interrelated. Graphical models like Unified or Con-
text Modelling Language (UML and CML) and se-
mantic networks have different level of expressive-
ness and efficiency but tend to usability. Conceptual
Graphs (CG) are semantic networks interpreted on an
ontology and achieve a better expressiveness.
For reasoning in bi-valued logic, ontology repre-
sentation often uses Description logic (DL). First Or-
der Logic (FOL) is more expressive but only semi-
decidable. Higher Order Logic (HOL) is interesting
(some HOL functions are implemented in FOL en-
gine) but has not an effective, sound and complete
proof theory with standard semantic. Handling im-
perfection is useful. Multi-valued logic (like three-
valued in CML) introduces alternatives from true or
false. Further, fuzzy logic allows a simultaneous clas-
sification quantification with membership functions.
Probability and probabilistic models like Bayesian
Networks (BN) or Hidden Markov Models (HMM)
quantify several hypotheses. Belief theory offers
more quantification distribution possibilities. Neural
Networks are deterministic but can also handle imper-
fection. As HMM, BN and machine learning meth-
ods, they classify situations without explicit semantic
since trained on examples’ bases. Determining rele-
vant features leading to situations classification is the
core of case-based reasoning. Hybrid systems mix
reasoning methods e.g. ontological applications often
combine DL and a FOL engine.
Several criteria led our choice for the engine core:
semantic degrees, expressiveness (vs efficiency) and
usability. We choose to base our representation on
CG. They have a strong semantic founding and are
built on an ontology. They provide a good expressive-
ness (a universal knowledge representation (Sowa,
2008)(Chein and Mugnier, 2009)) equivalent to FOL
but with a better usability since they are also human
readable. The needed expressiveness is an open is-
sue nevertheless You Can Only Learn What You Can
Represent (Otterlo, 2009). Thus, it is a fundamen-
tal question for a sustainable use. FOL is usually the
most expressive choice made for context-awareness.
Meantime, semantic reasoning with an ontology is the
most used approach in context-awareness as it pro-
vides interoperability and a non-abstract representa-
tion. Moreover coupled with the CG usability, the
model may allow at some point a welcomed direct
users involvement (Br
´
ezillon, 2011). Semantic vir-
tual worlds as a new paradigm is a discussed issue
(Latoschik et al., 2008). Several approaches offer
frameworks to build full semantic worlds (Latoschik
et al., 2005) (Lugrin and Cavazza, 2007). Lot of those
works use semantic networks (Peters and Shrobe,
2003)(Lugrin and Cavazza, 2007)(Bonis et al., 2008)
which reinforce our conviction for CG. However we
will not try to build a full semantic world but to gather
semantic information to help the 3D interaction. We
aim at context-awareness in classic applications with
an external representation and reasoning engine.
5 CURRENT WORK
As shown in Figure 3, the engine manages context
and decisions concerning the user, interaction and en-
vironment and communicates through different tools.
Those tools must have a semantic description of their
uses in order to be triggered by the engine. They
can be actuators with visible effects or sensors that
retrieve information. Those tools can embed other
forms of reasoning than the engine core (e.g HMM)
to provide information.
Context can have various forms as illustrated in
Figure 4. First, the ontology lists concepts and rela-
tions with underlying semantic, which are used by CG
in order to describe rules and facts. Available tools
GRAPP 2012 - International Conference on Computer Graphics Theory and Applications
564

Figure 3: A parallel engine: communication though seman-
tic tools.
and the past events in history are special facts. Events
are newly integrated information and trigger a deci-
sion request in an automatic mode. The time manager
role is to check the validity of the needed facts. When
a decision with an associated tool is true, the engine
aggregates its belief and risk from facts, events’ tim-
ing and rules. The user cognitive load is represented
by an acceptable total risk, which induces a knapsack
problem as a last classification.
Figure 4: The engine: forms of context and reasoning.
Context and reasoning blocks (Figure 4) can also
be grouped by their role in the engine (Figure 5). The
situation progresses with two roughly separated inter-
laced processes: decision and comprehension. The
decision process goes from representing the situation
to reasoning (KR & R), and transforms simple facts
beliefs into the best reaction bet. The comprehen-
sion process goes from identifying the situation to un-
derstanding how to assist (the two context-awareness
trends) and transforms simple data to a full plan of the
situation. The decision set is extended as the compre-
hension progresses (e.g an acquired interest can un-
lock a reactive adaptation)
We use Virtools as our scene graph manager and
the Amine platform (Kabbaj, 2006) (a Java open-
source multi-layer platform for intelligent systems)
for the engine. This platform offers an ontology man-
ager and a FOL engine that handles CG: Prolog+CG.
We are testing the engine on a small scenario.
Figure 5: Hierarchy of concepts in the engine: towards an
assistance plan bet.
However, even simple cases pose several open ques-
tions: What items of information are pertinent? How
to balance decisions risk and belief? How to best ex-
press a rule? How to monitor the user’s intention?
The engine core combines general rules with
scene tools and specific rules. We test the engine and
those rules with a first case study: to try to automati-
cally acquire some user’s interests and enhance them.
We first focus on interests linked to the user’s hand.
Thus the only specific rule is to monitor the ”hand”
object and to set a cognitive load. Then, several tools
may help. We started by defining:
• a Zones Of Interest (ZOI) sensor that attaches auras
to objects and reports their content;
• an object’s movement sensor (movement is
high/low, local/global);
• an actuator to change the color of an object;
• an actuator to add a haptic/visual gain to an object.
The engine’s first reaction is to activate the sensors
on the target ”hand”. Those sensors send events to the
engine, e.g an event that describes an object inside
the hand’s ZOI. Events trigger a reaction request that
finds adaptations with corresponding available tools:
e.g both precedent actuators, with two uses for activa-
tion and deactivation. Engine’s adaptation decisions
use general rules like:
• Define interests (e.g in a ZOI);
• Try to enhance an interest;
• Associate possible enhancements in this situa-
tion: e.g object visual modifications through
color change, as well as interaction modifications
through gain (visual or haptic);
• Manage adaptations states :
– remove added visual modification if the object is
not an interest;
– remove added gain if an object is an interest and
the movement is abnormal (e.g local+high=the
3D INTERACTION ASSISTANCE THROUGH CONTEXT-AWARENESS - A Semantic Reasoning Engine for Classic
Virtual Environment
565
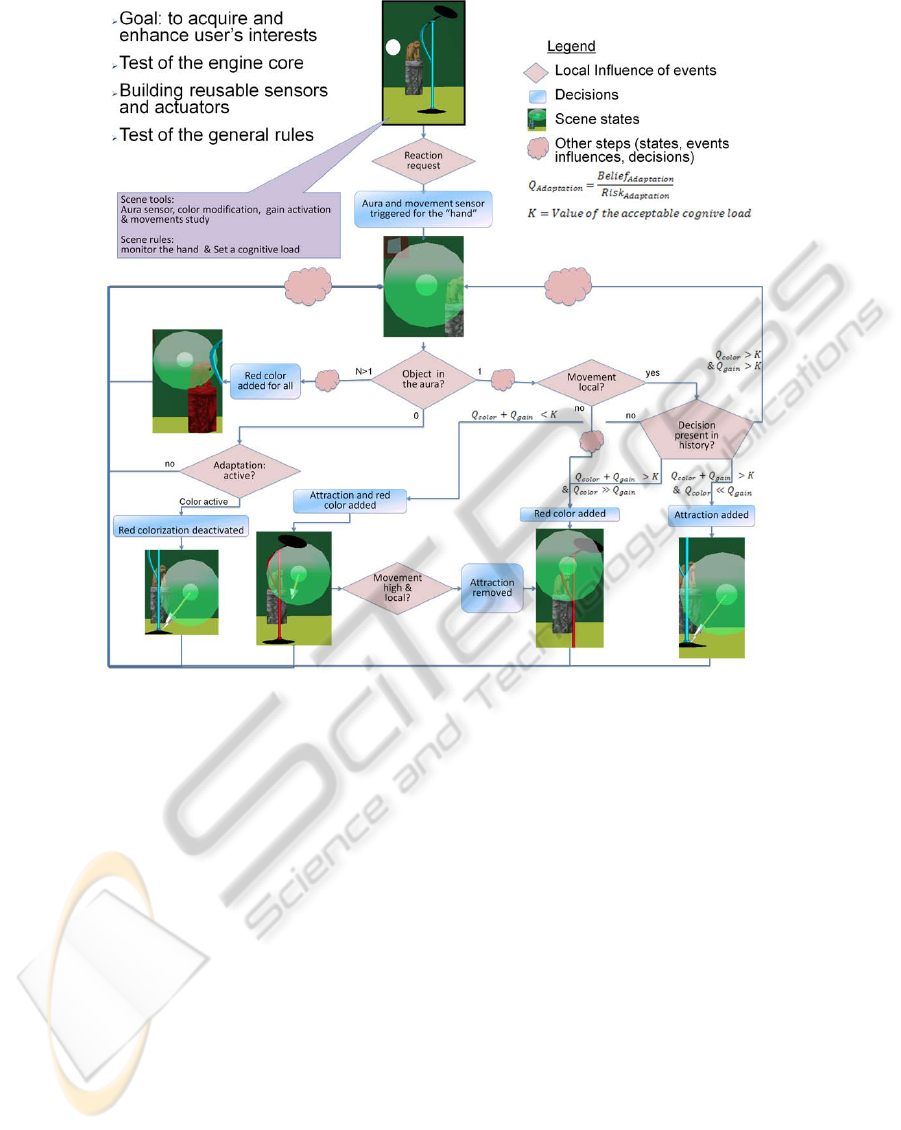
Figure 6: Case study: the engine automatically apply different adaptations depending on the context.
user is ”stuck”).
Next, the engine calculates the decisions belief
and risk from the initial risk supplied by the tools and
possibly beliefs for sensors events. Each rule has a
belief transfer rate. This rate for a color change is
greater than the one for a visual gain, as it is usually
more suited with only the ”enhancement will” con-
text. Finally, other rules focuse on risk management:
• increase decision risk if some concepts are used
(e.g haptic gain risk> visual gain risk> object vi-
sual modification risk);
• increase decision’s risk if present in history (e.g
avoid activation/deactivation cycle);
• decrease interaction modification’s risk if move-
ment is local.
As a result, the rules combine themselves as ex-
pected (Figure 6). Passing by an object makes its
color red, while standing next to it makes it also at-
tractive. Colors are reset when we move far away,
while attraction is removed when we try to resist it.
When it has been deactivated, gain cannot be reac-
tivated for a time corresponding to history memory.
Some reactivations can occur for coloring as the de-
cision is initially less risky. Those results depend
on the initial risk, belief and cognitive load values.
More complex situations occur when several objects
are close to the hand: e.g only the less risky adapta-
tion is applied to a maximum of objects.
6 CONCLUSIONS
The setting up and implementation of an intelligent
3D interaction assistance and context manager with
Amine platform and Conceptual Graphs is promising,
and we are now improving it by reflections on exam-
ples. The engine aims to allow a semantic reason-
ing and the reuse of tools in a non-semantic environ-
ment to help the 3D interaction. We propose an en-
gine core with a semantic base to achieve adaptation,
which could be directly addressed by sensors, design-
ers or users. Context and adaptations to be considered
GRAPP 2012 - International Conference on Computer Graphics Theory and Applications
566

for virtual reality along with the user’s degrees of ap-
preciation and control are open questions which will
guide the engine evolution. The significant engine
prototype response delay is not suited for a full au-
tomatic mode yet, but rather for punctual helps. This
drawback will be lessen but is an inherent part of our
approach. Ultimately the engine core will be tested
on more complex scenario. However, the next major
step is to obtain enhanced user’s intention hints.
ACKNOWLEDGEMENTS
This work is supported by the IBISC laboratory and
the FP7 DigitalOcean project.
REFERENCES
Aylett, R. and Luck, M. (2000). Applying artificial intel-
ligence to virtual reality: Intelligent virtual environ-
ments. Applied Artificial Intelligence, 14(1):3–32.
Bettini, C., Brdiczka, O., Henricksen, K., Indulska, J.,
Nicklas, D., Ranganathan, A., and Riboni, D. (2010).
A survey of context modelling and reasoning tech-
niques. Pervasive and Mobile Computing, 6.
Bonis, B., Stamos, J., Vosinakis, S., Andreou, I., and
Panayiotopoulos, T. (2008). A platform for vir-
tual museums with personalized content. Multimedia
Tools and Applications, 42(2):139–159.
Boudoin, P., Otmane, S., and Mallem, M. (2008). Fly
Over , a 3D Interaction Technique for Navigation in
Virtual Environments Independent from Tracking De-
vices. Virtual Reality.
Bouyer, G., Bourdot, P., and Ammi, M. (2007). Supervi-
sion of Task-Oriented Multimodal Rendering for VR
Applications. Communications.
Bowman, D. A., Chen, J., Wingrave, C. A., Lucas, J., Ray,
A., Polys, N. F., Li, Q., Haciahmetoglu, Y., Kim, J.-s.,
Kim, S., Boehringer, R., and Ni, T. (2006). New Di-
rections in 3D User Interfaces. International Journal,
5.
Br
´
ezillon, P. (2011). From expert systems to context-based
intelligent assistant systems : a testimony. Engineer-
ing, 26:19–24.
Celentano, A. and Nodari, M. (2004). Adaptive interac-
tion in Web3D virtual worlds. Proceedings of the
ninth international conference on 3D Web technology
- Web3D ’04, 1(212):41.
Chein, M. and Mugnier, M. (2009). Graph-bases Knowl-
edge Representation: Computational Foundations of
Conceptual Graphs. Springer.
Coppola, P., Mea, V. D., Gaspero, L. D., Lomuscio, R.,
Mischis, D., Mizzaro, S., Nazzi, E., Scagnetto, I., and
Vassena, L. (2009). AI Techniques in a Context-Aware
Ubiquitous Environment, pages 150–180. Mendeley.
Dey, A. and Abowd, G. (2000). Towards a better under-
standing of context and context-awareness. In CHI
2000 workshop on the what, who, where, when, and
how of context-awareness, volume 4.
Frees, S. (2010). Context-driven interaction in immer-
sive virtual environments. Virtual Reality, Volume
14(4):1–14.
Irawati, S., Calder
´
on, D., and Ko, H. (2005). Seman-
tic 3D object manipulation using object ontology in
multimodal interaction framework. In Proceedings of
the 2005 international conference on Augmented tele-
existence, pages 35–39. ACM.
Kabbaj, A. (2006). Development of Intelligent Systems and
Multi-Agents Systems with Amine Platform. Intelli-
gence, pages 1–14.
Latoschik, M. E., Biermann, P., and Wachsmuth, I. (2005).
Knowledge in the Loop: Semantics Representation
for Multimodal Simulative Environments. In Smart
Graphics, pages 25 – 39.
Latoschik, M. E., Blach, R., and Iao, F. (2008). Semantic
Modelling for Virtual Worlds A Novel Paradigm for
Realtime Interactive Systems ? In ACM symposium
on Virtual reality software and technology.
Lee, S., Lee, Y., Jang, S., and Woo, W. (2004). vr-UCAM:
Unified context-aware application module for virtual
reality. Conference on Artificial Reality.
Lugrin, J.-l. and Cavazza, M. (2007). Making Sense of Vir-
tual Environments : Action Representation , Ground-
ing and Common Sense. In 12th International confer-
ence on intelligent user interfaces.
Octavia, J., Coninx, K., and Raymaekers, C. (2010).
Enhancing User Interaction in Virtual Environments
through Adaptive Personalized 3D Interaction Tech-
niques. In UMAP.
Otterlo, M. (2009). The logic of adaptive behavior. Mende-
ley.
Paramythis, A. (2009). Adaptive Systems: Development,
Evaluation and Evolution. PhD thesis.
Peters, S. and Shrobe, H. E. (2003). Using Semantic Net-
works for Knowledge Representation in an Intelligent
Environment. In 1st International Conference on Per-
vasive Computing and Communications.
Poupyrev, I., Billinghurst, M., Weghorst, S., and Ichikawa,
T. (1996). The go-go interaction technique: non-linear
mapping for direct manipulation in VR. In Proceed-
ings of the 9th annual ACM symposium on User inter-
face software and technology, pages 79–80. ACM.
Preuveneers, D. (2009). Support for context-driven applica-
tions in Ambient Intelligence environments. PhD the-
sis, KUL.
Soto, M., Allongue, S., Lip, L., Place, C., Cedex, P., Soto,
M., and Allongue, S. (1997). A Semantic Approach of
Virtual Worlds Interoperability. In Proceedings Sixth
IEEE workshops on Enabling Technologies: Infras-
tructure for Collaborative Enterprises.
Sowa, J. F. (2008). Conceptual Graphs, pages 213–217.
Elsevier.
Wingrave, C. A., Bowman, D. A., and Ramakrishnan, N.
(2002). Towards Preferences in Virtual Environment
Interfaces. Interfaces.
3D INTERACTION ASSISTANCE THROUGH CONTEXT-AWARENESS - A Semantic Reasoning Engine for Classic
Virtual Environment
567
