
A Constraint-based Mining Approach for Multi-attribute Index Selection
B. Ziani
1
, F. Rioult
2
and Y. Ouinten
1
1
LIM, Computer Science Department, University of Laghouat, Laghouat, Algeria
2
GREYC (CNRS - UMR 6072), Universit
´
e de Caen, Caen, France
Keywords:
Data Warehouse Physical Design, Bitmap Join Index Selection, Data Mining, Constraint Mining.
Abstract:
The index selection problem (ISP) concerns the selection of an appropriate indexes set to minimize the total
cost for a given workload under storage constraint. Since the ISP has been proven to be an NP-hard problem,
most studies focus on heuristic algorithms to obtain approximate solutions. The problem becomes more dif-
ficult for indexes defined on multiple tables such as bitmap join indexes, since it requires the exploration of
a large search space. Studies dealing with the problem of selecting bitmap join indexes mainly focused on
proposing pruning solutions of the search space by the means of data mining techniques or heuristic strategies.
The main shortcoming of these approaches is that the indexes selection process is performed in two steps. The
generation of a large number of indexes is followed by a pruning phase. An alternative is to constrain the input
data earlier in the selection process thereby reducing the output size to directly discover indexes that are of
interest for the administrator. For example, to select a set of indexes, the administrator may put limits on the
number of attributes or the cardinality of the attributes to be included in the indexes configuration he is seek-
ing. In this paper we addressed the bitmap join indexes selection problem using a constraint-based approach.
Unlike previous approaches, the selection is performed in one step by introducing constraints in the selection
process. The proposed approach is evaluated using APB-1 benchmark.
1 INTRODUCTION
Data Warehousing and On-line Analytical Processing
(OLAP) are becoming critical components of deci-
sion support. They are especially designed to enable
executives, managers, and analysts to take better and
faster decisions. Data warehouses are generally mod-
elled according to a star schema that contains a cen-
tral, large fact table, and several dimension tables that
describe the facts (Inmon, 2002), (Kimball and Ross,
2007).
Queries defined on a star schema are called star
join queries. They are complex and use several
join operations that are very costly. Such queries
will be performed on tables having potentially bil-
lions of records. As a result, it becomes crucial
to accelerate query evaluation. Among the tech-
niques adopted in relational data warehouses to im-
prove query performance, materialized views and in-
dexes are presumably the most effective ones (Chaud-
huri and Narasayya, 2007). Data warehouses admin-
istrators then handle the fastidious task of choosing an
advantageous configuration of indexes to enhance the
system performance.
For a given data warehouse, the total number of dis-
tinct indexes can be extremely large; hence it is not
always practicable to create all the indexes due to the
limited amount of storage space that we can physi-
cally maintain. The approaches dealing with the in-
dex selection problem are composed of two steps:
1. Generation of candidate indexes for a given work-
load;
2. Selection of a final configuration that minimizes
the cost of the workload, while observing the stor-
age space limit.
The first step reduces the space of potential in-
dexes by eliminating non relevant attributes. The final
configuration (step 2) is mostly selected using greedy
algorithms (Agrawal et al., 2000). The proposed ap-
proaches prune the set of generated indexes so that the
constraint space is satisfied. However, this pruning
process is performed after the generation of a large
number of candidate indexes.
An alternative is to constrain the generation of in-
dexes in order to produce fewer and more relevant
outputs. In this paper we propose a constraint-based
mining approach to solve the index selection problem.
We believe that constraint-based mining will enable
93
Ziani B., Rioult F. and Ouinten Y..
A Constraint-based Mining Approach for Multi-attribute Index Selection.
DOI: 10.5220/0003964600930098
In Proceedings of the 14th International Conference on Enterprise Information Systems (ICEIS-2012), pages 93-98
ISBN: 978-989-8565-10-5
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

administrators to focus on a subset of most advanta-
geous indexes and that it avoids the generation of un-
wanted indexes.
The remainder of this paper is organized as fol-
lows: in Section 2 we present existing works re-
lated to bitmap join indexes selection problem and
constraint-based mining. Section 3 describes the pro-
posed approach for the bitmap join indexes selec-
tion. We experimentally study the efficiency of our
approach in Section 4. We conclude the paper and
present future directions in Section 5.
2 RELATED WORK
2.1 Bitmap Join Index Selection
The index selection problem has been studied first
in traditional databases context (Chaudhuri and
Narasayya, 1997), (Agrawal et al., 2000), (Chaudhuri
et al., 2004), (Feldman and Reouven, 2003), (Frank
et al., 1992), (Valentin et al., 2000). With the ad-
vent of data warehouse, indexation has become an im-
portant option in physical design and its importance
is well recognized (Golfarelli et al., 2002). The in-
dex selection problem has been proven to be NP-hard
(Chaudhuri et al., 2004). Thus, most studies in the
literature have focused on finding approximate solu-
tions using greedy strategies or heuristics-based ap-
proaches.
The aim of the proposed approaches is to deter-
mine a set of candidate indexes from a given work-
load of queries, then to propose a final indexes config-
uration providing the best profit, under storage space
constraint. However, considered indexes usually con-
cern one table. Bitmap join indexes are multi-attribute
indexes involving several tables. Selecting a suitable
configuration of Bitmap join indexes is more compli-
cated than the classical mono-table indexes, since it
requires the exploration of a large search space. To
the best of our knowledge, only few studies dealing
with the problem of selecting bitmap join indexes are
carried out (Aouiche et al., 2005), (Bellatreche et al.,
2007), (Bellatreche and Boukhalfa, 2010), (Ziani and
Ouinten, 2011). Due to the large number of can-
didate indexes, the proposed approaches mainly fo-
cused on pruning the search space of potential in-
dexes. They have used frequent itemsets (Aouiche
et al., 2005), (Bellatreche et al., 2007), (Ziani and
Ouinten, 2011) or heuristic strategies (Bellatreche and
Boukhalfa, 2010) to perform the pruning process. In
(Aouiche et al., 2005), (Bellatreche et al., 2007) the
Close algorithm (Pasquier et al., 1999) for mining
closed frequent itemsets is used to prune the search
space of candidate indexes. Due to the large number
of indexes generated as closed frequent itemsets, the
authors in (Ziani and Ouinten, 2011) propose a max-
imal frequent itemsets based approach to perform the
selection.
In (Bellatreche and Boukhalfa, 2010), the authors
propose an intuitive algorithm for bitmap join indexes
selection. As an initial configuration, the algorithm
selects an index for each query having indexable at-
tributes. When the size of the configuration exceeds
the storage capacity S , some selected indexes should
be reduced until the satisfaction of S.
The principal weakness of the proposed ap-
proaches is the large number of generated indexes,
that is very difficult to manage, according to the sys-
tem limitations (number of indexes per table and stor-
age space constraint). Indeed, the pruning is done af-
ter the generation of the indexes configuration.
An alternative is to constrain the input data earlier
in the selection process, thereby reducing the output
size to directly discover indexes that are of interest
for the administrator. We believe that a constraint-
based approach will help to mine a reduced and more
relevant indexes configuration.
2.2 Constraint-based Pattern Mining
Mining frequent itemsets (FI) in datasets is a de-
manding task common to several important data min-
ing applications, that look for interesting patterns
within databases (e.g., association rules, correlations,
sequences, episodes, classifiers, clusters). It was
originally proposed in (Agrawal and Srikant, 1994),
(Agrawal et al., 1993) with the Apriori algorithm.
The drawback of mining frequent itemsets is that,
if there is a large frequent itemset with size s, then
almost all 2
s
candidate subsets of the itemset might
be generated and tested. Furthermore, the number of
frequent itemsets grows very quickly as the minimum
support threshold decreases.
Moreover, the huge size of the output compli-
cates the task of the analyst, who has to extract use-
ful knowledge from a very large amount of frequent
patterns. To overcome this problem, the paradigm of
pattern discovery based on constraints was introduced
with the aim at providing a tool for driving the discov-
ery process towards potentially interesting patterns.
Using constraints can be of a great help to purge a
lot of patterns that are irrelevant for the user.
Constraint-based mining has then been widely ad-
dressed, with really different approaches. The mostly
used constraints are the minimum or maximum sup-
port threshold, including (or being included in) some
specific itemset, aggregated computation (sum, aver-
ICEIS2012-14thInternationalConferenceonEnterpriseInformationSystems
94
age, min, max, when items are associated to a mea-
sure). As this paper does not specifically contribute
to the field of constraint-based mining, we just briefly
recall below the main contributions.
Most of them combine anti-monotone constraints
and monotone one (Pei and Han, 2000; Bucila et al.,
2003). A constraint is monotone (resp. anti-) if it
preserved while itemset specialization (resp. gener-
alization). Many useful constraints fall within the
anti-monotone category, such as the minimum sup-
port threshold or uper-bounding the aggregated sum.
This allows for powerful pruning of the search space,
because this space is built through specialization. The
maximum support threshold is a typical monotone
constraint.
Other approaches directly prune the
dataset (Bonchi et al., 2003) or consider the problem
as an inductive database issue and formalize the
constraints as queries, in a dedicated constraint-base
mining environment (Boulicaut et al., 2005),(Jeudy
and Boulicaut, 2002).
3 CONSTRAINT-BASED INDEX
SELECTION
To illustrate the motivation of our approach, let us see
an example. Suppose that a given approach recom-
mends a set C
idx
= {I
1
, I
2
, . . . , I
k
} of k indexes. The
administrator may keep an index I
j
knowing that it
needs acceptable storage space, or reject it because it
has previously shown negligible improvement for the
system performance.
Indeed, depending on the cardinality of the at-
tributes, the indexing process may be more or less ef-
ficient. If the cardinality is very large or very small, an
index might not bring a very significant improvement
(Vanichayobon and Gruenwald, 1999). On the other
hand, it is not beneficial to create an index on a small
table. Hence, table size is another parameter which
can be taken into account. The administrator decides
whether a table is large or not, and only the indexes
on attributes belonging to large tables are selected.
More formally, let A = {a
1
, a
2
, . . . , a
n
} be the
set of indexable attributes and D the extraction con-
text (Query/Attributes) for a given workload W . If
C = {C
1
, C
2
, . . . , C
k
} is a set of k functions, denoting
the properties of interest (constraints) for each index
I ⊆ A, our approach to solve the index selection prob-
lem requires to compute all the itemsets (indexes) oc-
curring in the extraction context D and satisfying the
set of constraints C , i.e:
{I ⊆ A|C
1
(I ) ∧C
2
(I ) ∧· ·· ∧ C
k
(I )}
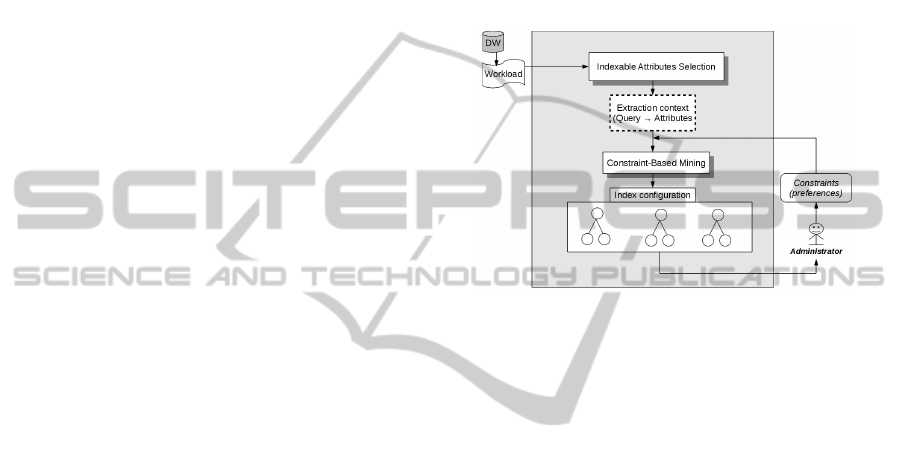
The architecture of our approach is illustrated in
Figure 1. As data mining based approaches, it con-
structs an extraction context by identifying the in-
dexable attributes from a given workload. Then, it
performs a constraint-based extraction (involving ad-
ministrator expertise) to generate the desired indexes.
Unlike the classical frequent itemsets mining based
approaches, we do not built an initial indexes config-
uration and we do not need to use a greedy algorithm
to recommend a final configuration.
Figure 1: Constraint-based indexes selection.
4 EXPERIMENTAL STUDY
4.1 Description of the Experiment
The aim of our experiments is to evaluate our ap-
proach by observing the impact of using various con-
straints on the selected indexes. In the first experiment
we study the impact of including constraints in the
mining process on the number of generated indexes
and the corresponding storage space. In the second
expriments, we compare the performance of our ap-
proach with the baseline case where no indexes are
created as well as the approaches using classical fre-
quent itemsets mining, where the attributes frequency
is the unique parameter used to generate a configura-
tion of indexes. To evaluate the interestingness of the
indexes generated by our approach, we use the same
cost models proposed in similar works (Aouiche et al.,
2005).
To perform a constraint-based selection, we have
used the MUSIC-dfs tool (Mining with a User-
SpecifIed Constraint, Depth-First Search approach)
(Soulet et al., 2006). This tool provides a flexible and
rich constraint query language. The user can itera-
tively develop complex constraints integrating various
knowledge types.
In this study we are more interested in the qual-
ity of the generated indexes. Thus, our comparisons
AConstraint-basedMiningApproachforMulti-attributeIndexSelection
95

are performed with no restrictions on available disk
space. We have used the APB-1 Benchmark of the
OLAP Council (OLAP-Council, 1998). The APB-1
Benchmark simulates a star schema data warehouse.
It consists of one fact table Actvars and four di-
mension tables ProLevel, TimeLevel, CustLevel, and
ChanLevel. We have considered 12 indexable at-
tributes (Table 1).
Table 1: Characteristics of the indexable attributes.
Code Attribute Cardinality Size of the di-
mension table
A Class Level 605 9
B Quarter Level 4 900
C Group Level 300 9
D Family Level 75 9
E Line Level 15 9
F Division Level 4 9
G Year Level 2 900
H Month Level 12 900
I Retailer Level 99 9000
J Gender Level 2 9000
K All Level 5 24
L City Level 4 9000
We have also used the same workload used in
(Bellatreche and Boukhalfa, 2010). It consists of
60 star join queries involving aggregation operations
and multiple joins between the fact table and dimen-
sion tables. We considered the following constraints:
• the support (frequency) of the generated indexes.
This support shows the representativity of the in-
dex in the workload of queries;
• the length (number of attributes) of the generated
indexes. It directly impacts on the width of the
space needed for storing the index;
• the cardinality of the attributes in the generated
indexes. This factor also impacts on the storage
space width;
• the size of the dimension table to which an at-
tribute belongs, that impacts on the height to the
index.
4.2 Experimental Results
Experiment 1: Number and Size of Indexes vs
Constraints. We begin with a baseline experiment
where the frequency is the unique parameter taken
into account (as classical approaches). Then, we con-
ducted several experiments using the MUSIC-dfs to
compute the generated configurations, for different
combinations of constraints. The experiments de-
picted here are performed with a minimum support
of 5% (3 queries). Using this threshold, the workload
basically generates 56 indexes. This represents a very
high value when compared to the size of the workload
(60 queries).
Consequently, constraints are added to improve
the number of generated indexes. Figures 2 and 3
show respectively the number and the total size occu-
pied by the generated indexes for different constraint
combinations. We applied different constraints to ex-
amine their impact on the generated configurations. It
is interesting to observe that the characteristics of a
generated configuration (i.e, number of indexes and
total indexes size) depends on the complexity of the
constraint (i.e., the number of combinations). This
behavior allows the administrator to experiment with
a broad set of configurations to select the most inter-
esting one.
Experiment 2: Workload Cost vs Constraints.
We compare the performance of our approach with
the baseline case where no indexes are created as well
as the approaches using classical frequent itemsets
technique. For each constraint, we evaluate the work-
load cost using the generated indexes. The results
we obtained are ploted in Figure 4. They show that
we achieve a better performance using constraints on
both the support (frequency) of indexes and the cardi-
nality of the attributes. For complex constraints, there
are very few or no generated indexes and thus the cost
of the workload increases.
5 CONCLUSIONS
In this paper we have proposed a constraint-based
framework for the index selection problem. Our ap-
proach leverages and extends principled methods of
mining frequent itemsets for the index selection prob-
lem. The key contribution is that we show how
constraint-based mining can be adapted in a flexible
way that balances the characteristics of the workload
and the administrator preferences for the index selec-
tion problem.
The existing approaches consist of a fully auto-
matic procedure. Like any conventional process of
data mining, this can lead to obvious, unhelpful, or
undesirable knowledge (indexes). Our approach as-
sociates, on the one hand the high capacity of auto-
matic selection mining frequent itemsets, and in the
other hand, the necessary expertise of the administra-
tor. Experimental results show that our approach is
effective because it allows for more directly comput-
ing the useful indexes with precisely describing the
requirements.
ICEIS2012-14thInternationalConferenceonEnterpriseInformationSystems
96
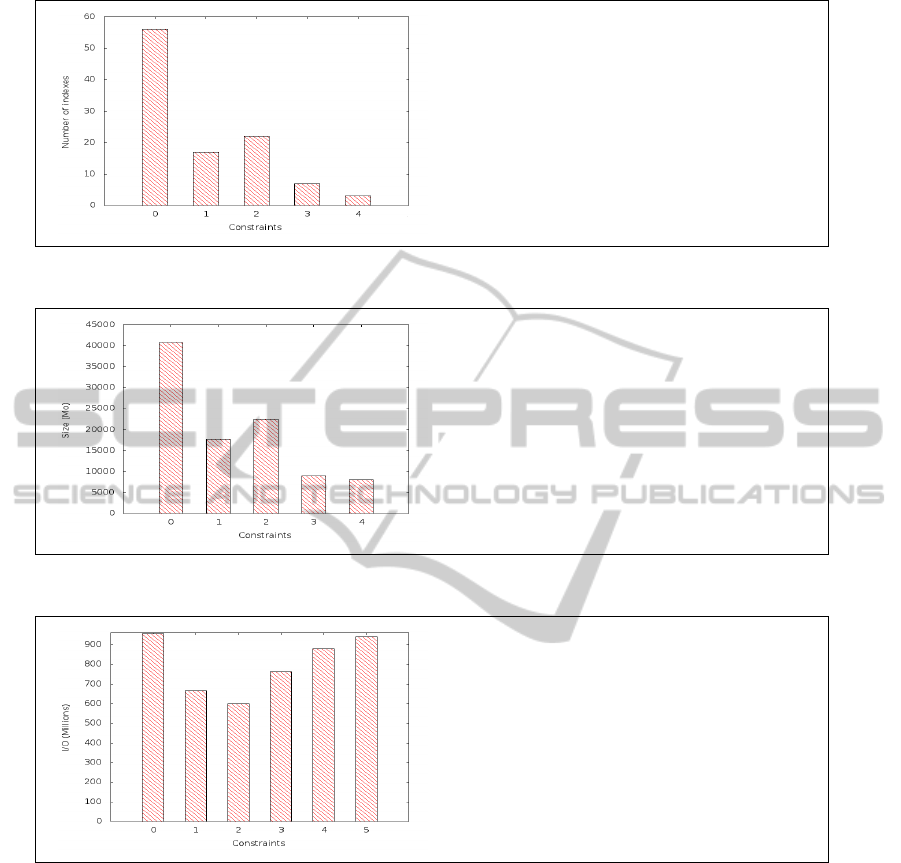
0. Support Only
1. Support and Cardinality
2. Support and Length
3. Support and Dimension Tables Size
4. Support and Cardinality and Length
Figure 2: Number of generated indexes vs constraints.
0. Support Only
1. Support and Cardinality
2. Support and Length
3. Support and Dimension Tables Size
4. Support and Cardinality and Length
Figure 3: Size of generated indexes vs constraints.
0. Without indexes
1. Support Only
2. Support and Cardinality
3. Support and Length
4. Support and Dimension Tables Size
5. Support and Cardinality and Length
Figure 4: Workload cost vs constraints.
REFERENCES
Agrawal, R., Imielinski, T., and Swami, A. (1993). Min-
ing association rules between sets of items in large
databases. In ACM SIGMOD International Con-
ference on Management of Data, Washington, D.C,
pages 207–216.
Agrawal, R. and Srikant, R. (1994). Fast algorithms for
mining association rules in large databases. In Inter-
national Conference on Very Large Data Bases, San-
tiago de Chile, Chile, pages 487–499.
Agrawal, S., Chaudhuri, S., and Narasayya, V. (2000). Au-
tomated selection of materialized views and indexes
in sql databases. In VLDB, pages 496–505.
Aouiche, K., Darmont, J., Boussaid, O., and Bentayeb, F.
(2005). Automatic selection of bitmap join index in
data warehouses. In 7th International Conference,
DaWaK, Copenhagen, Denmark, pages 64–73.
Bellatreche, L. and Boukhalfa, K. (2010). Yet another algo-
rithms for selecting bitmap join index. In 12th Inter-
national Conference, DAWAK , Bilbao, Spain, pages
105–116.
Bellatreche, L., Missaoui, R., Necir, H., and Drias, H.
(2007). Selection and pruning algorithms for bitmap
index selection problem using data mining. In 9th
International Conference, DaWaK, Regensburg, Ger-
many, pages 221–230.
Bonchi, F., Giannotti, F., Mazzanti, A., and Pedreschi, D.
AConstraint-basedMiningApproachforMulti-attributeIndexSelection
97

(2003). Exante: Anticipated data reduction in con-
strained pattern mining. In Conference on Principles
and Practice of Knowledge Discovery in Databases
(PKDD’03), Cavtat-Dubrovnik, Croatia, pages 47–
58.
Boulicaut, J.-F., Raedt, L. D., and Mannila, H., ed-
itors (2005). Constraint-Based Mining and In-
ductive Databases, European Workshop on Induc-
tive Databases and Constraint Based Mining, Hin-
terzarten, Germany, March 11-13, 2004, volume 3848
of Lecture Notes in Computer Science. Springer.
Bucila, C., Gehrke, J. E., Kifer, D., and White, W. (2003).
Dualminer: A dual-pruning algorithm for itemsets
with constraints. Data Mining and Knowledge Dis-
covery, 7(4):241–272.
Chaudhuri, S., Datar, M., and Narasayya, V. (2004). Index
selection for databases: A hardness study and a prin-
cipled heuristic solution. IEEE Trans. Knowl. Data
Eng, 16:1313–1323.
Chaudhuri, S. and Narasayya, V. (1997). An efficient cost-
driven index selection tool for microsoft sql server.
In 23rd International Conference on Very Large Data
Bases, pages 146–155.
Chaudhuri, S. and Narasayya, V. (2007). Self-tuning
database systems: a decade of progress. In 33rd inter-
national conference on Very large data bases, pages
3–14.
Feldman, Y. A. and Reouven, J. (2003). A knowledge-based
approach for index selection in relational databases.
Expert Syst. Appl., 25:15–37.
Frank, M., Omiecinski, E., and Navathe, S. (1992). Adap-
tive and automated index selection in rdbms. In 3rd In-
ternational Conference on Extending Database Tech-
nology, Vienna, Austria, pages 277–292.
Golfarelli, M., Rizzi, S., and Saltarelli, E. (2002). Index
selection for data warehousing. In 4th Intl. Workshop
DMDW, Toronto, Canada.
Inmon, W. (2002.). Building the Data Warehouse. John
Wiley & Sons, Inc., New York, NY, USA, 2nd edition.
Jeudy, B. and Boulicaut, J.-F. (2002). Constraint-based dis-
covery and inductive queries: Application to associa-
tion rule mining. In Hand, D. J., Adams, N. M., and
Bolton, R. J., editors, Pattern Detection and Discov-
ery, volume 2447 of LNCS, pages 110–124. Springer.
Kimball, R. and Ross, M. (2007). The Data Warehouse
Toolkit: The Complete Guide to Dimensional Model-
ing. John Wiley & Sons, Inc., New York, NY, USA,
2nd edition.
OLAP-Council (1998). Apb-1 olap benchmark, release ii.
http://www.olapcouncil.org/.
Pasquier, N., Bastide, Y., Taouil, R., and Lakhal, L. (1999).
Discovering frequent closed itemsets for association
rules. In 7th International Conference on Database
Theory, pages 398–416.
Pei, J. and Han, J. (2000). Can we push more constraints
into frequent pattern mining? In Proceedings of
the 6th International Conference on Knowledge Dis-
covery and Data Mining (KDD’00), pages 350–354,
Boston, USA. New York : ACM Press.
Soulet, A., Klema, J., and Crmilleux, B. (2006). Effi-
cient mining under flexible constraints through several
datasets. In Workshop on Knowledge Discovery in In-
ductive Databases co-located with PKDD’06.
Valentin, G., Zuliani, M., Zilio, D., Lohman, G., and Skel-
ley, A. (2000). Db2 advisor: An optimizer smart
enough to recommend its own index. In ICDE, pages
101–110.
Vanichayobon, S. and Gruenwald, L. (1999). Indexing tech-
niques for data warhouses queries. Technical report,
University of Oklahoma, School of computer science.
Ziani, B. and Ouinten, Y. (2011). Enhancing multi-attribute
indexes selection using maximal frequent itemsets. In
EGCM, Tanger, Morocco, pages 65–77.
ICEIS2012-14thInternationalConferenceonEnterpriseInformationSystems
98
