
A Generation Method of Reference Operation using Reinforcement
Learning on Project Manager Skill-up Simulator
Keiichi Hamada
1
, Masanori Akiyoshi
2
and Masaki Samejima
1
1
Graduate School of Information Science and Technology, Osaka University, 2-1 Yamadaoka, Suita, Osaka, Japan
2
Department of Information Systems and Management, Hiroshima Institute of Technology, 2-1-1 Miyake saeki-ku,
Hiroshima, Japan
Keywords:
Project Management, Skill-up Simulator, Reinforcement Learning, Decision Tree.
Abstract:
This paper addresses generating reference operation that a manager should carry out for improving a result of
a certain project based on the project principle. The project principle is a group of rules to indicate what to do
in situations of a project, and also necessary to generate the reference operation. First, the proposed method
generates the project principle from optimal operations derived by reinforcement learning on automatically
generated operations. And, the reference operation is generated by applying the project principle to a certain
project model. Experimental results show that the proposed method can automatically generate the reference
operation as well as manual generation.
1 INTRODUCTION
Along with increase of difficult projects where a
complicated IT system is developed in a short time,
it becomes important to educate project managers
that have enough skills to manage the projects.
Many project managers learn project management
skills through PMBOK(Project Management Body Of
Knowledge)(PMI, 2009) and literatures which indi-
cate success and failure factors of projects(Horine,
2005). In addition, in order to make project man-
agers acquire skills of planning and carrying out
the project, it is important for them to face actual
projects and solve issues of projects. Thus, many
educational methods have been proposed such as
OJT(On the Job Training), PBL(Project Based Learn-
ing)(Thomas, 2000), and RP(Role Playing)(Henry
and LaFrance, 2006). But, effects of their methods
depend on trainers and they take a lot of time to edu-
cate learners.
Recently, the efficient educational meth-
ods using simulators have been proposed such
as SESAM(Drappa and Ludewig, 2000) and
PMT(Davidovitch et al., 2007). Thus, we have
developed a project manager skill-up simulator
which can interact with a learner in order to take an
action against issues such as explosive occurrence of
bugs(Iwai et al., 2011). In this simulator, the learner
can input actions such as “overtime directive” and
“collaborative work with expert members” based on
the simulated situations in a project model. After fin-
ishing the simulation of the project model, this sim-
ulator outputs QCD(Quality, Cost, Delivery) as a re-
sult of an “operation” defined as a sequence of the
actions. But, this simulator can not give feedback to
the learner about whether each action in the operation
was good or not. Since trainers can not investigate the
reference operation in order to evaluate each learner’s
operation from practical viewpoints, there exists no
way to strengthen his/her skills.
This paper addresses a generation method of such
reference operation to support the evaluation. First,
the proposed method generates the project principle
based on operations that are automatically generated
on various projects. Applying the generated project
principle to a certain project model, the proposed
method generates the reference operation.
2 PROBLEMS ON PROJECT
MANAGER SKILL-UP
SIMULATOR
2.1 Project Manager Skill-up Simulator
The target of this research is a project manager skill-
up simulator that a learner can input actions and
15
Hamada K., Akiyoshi M. and Samejima M..
A Generation Method of Reference Operation using Reinforcement Learning on Project Manager Skill-up Simulator.
DOI: 10.5220/0004131700150020
In Proceedings of the International Conference on Knowledge Management and Information Sharing (KMIS-2012), pages 15-20
ISBN: 978-989-8565-31-0
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

Simulator
Project status
data
(progress, bugs)
Action
input
Learner
Input
Status
display
Event firing
control
Event rules
Refer
Event
input
Output
Project model
(project, module,
person)
Figure 1: Outline of project manager skill-up simulator.
shows the result by the simulation of the operation as
a sequence of the actions. Figure 1 shows the outline
of the project manager skill-up simulator.
2.1.1 Project Model
When this simulator starts, this simulator shows the
learner a project model. The project model mainly
consists of “Project”, “Module”, and “Person” as
they exist in the real project. “Project” is defined
as a set of modules to be developed and members
to be assigned to the project. “Module” is defined
with a technical domain to develop, its difficulty
ranked with {A(difficult), B(normal), C(easy)}, esti-
mated man-hour, parents modules, and children mod-
ules. For example, Module 1 is shown as “DOMAIN:
database, DIFFICULTY: A, MAN-HOUR: 10, PAR-
ENTS MODULE: Module 2, CHILDREN MOD-
ULE: Module 3, Module 4”. “Person” is defined with
a skill on technical domains ranked with {A(expert),
B(normal), C(novice)}. For example, Person 1 is
shown as “database: A, interface: A, server: A, se-
curity: C, editorAP: B”.
2.1.2 Project Status Data
While simulating the project, this simulator calculates
parameters of the project status such as progress and
bugs. Figure 2 shows user interface of the simulator
to input a user’s actions and to output the project sta-
tus. The module status is displayed with “Gantt chart”
including two bars that represent initial planned dura-
tion and changed duration from starting date to com-
pletion date. In fact, mismatching between a module
difficulty and a programmer’s skill is a main cause
of schedule delays and quality losses of a project.
And the most important task as a project manager is
to detect and predict such schedule delays and qual-
ity losses. The learner can take “check progress”
Buttons for actions
Gantt Chart
Project Status
Project Model
Figure 2: An interface of simulator.
to check the number of existing bugs and whether
the schedule is delayed or not. If project managers
judge to improve the delay, project managers can in-
put the actions of “overtime directive” and “collabo-
rative work with expert members” after taking “check
progress”. To take “overtime directive” increases
working hours, and to take “collaborative work with
expert members” debugs detected bugs and does not
generate new bugs.
After finishing all modules in the project model,
this simulator outputs QCD as a result of the sim-
ulation. Q(Quality) is influenced by the quality
losses including latent bugs. C(Cost) is an additional
cost calculated from days spent for “overtime direc-
tive” and “collaborative work with expert members”.
D(Delivery) is influenced by the schedule delay.
2.1.3 Events
In order to adjust difficulty to a learner’s performance,
this simulator causes “Events” which harm the project
status such as sudden bug explosion, sudden man-
hour increase. These events happen when “Event fir-
ing control” detects the project to go smoothly based
on the current project status.
2.2 Problem on Generating Reference
Operation for Feedbacks of
Evaluation
A learner gets the result of the operation, but can not
know whether each action in the operation is good or
not. So, it is required that the simulator shows feed-
backs of the evaluations of the actions. Here, excel-
lent project managers do not fail to conduct a opera-
tion based on the project principle that is a group of
rules to improve the status of projects. The status is
KMIS2012-InternationalConferenceonKnowledgeManagementandInformationSharing
16

shown by QCD, and the project principle sets which
targets of QCD is improved. So, the rule in the project
principle is a set of a status to be improved and a
necessary action to improve the target of QCD called
“learning target” for projects. A learning target is
defined which viewpoints the learner should acquire.
The decision making by project managers consists of
two stages of operations: project managers check the
progress and take actions based on the progress. From
this viewpoint, there are two kinds of project princi-
ples: “check progress” and “take action”.
This simulator can give feedback to the learner
whether the learner’s operation follows the project
principle or not. But the learner’s operation can not
be compared directly with a project principle because
situations and actions for them vary with projects. In
order to compare the learner’s operation, it is neces-
sary to generate the reference operation which is an
operation following the project principle.
So, the project principle needs to generate the ref-
erence operation. But, to generate the project prin-
ciple takes a lot of time because trainers simulate
and analyze many operations to get a good result for
each project in order to generate the project principle
which must be useful for various projects. This paper
addresses how to generate such project principle and
reference operation.
3 GENERATION METHOD OF
REFERENCE OPERATION
USING REINFORCEMENT
LEARNING
3.1 Outline of Automatic Generation
Method
We propose a generation method of reference oper-
ation using reinforcement learning and decision tree.
Figure 3 shows the outline of the generation method.
In order to generate the reference operation based
on the project principle, this method uses optimal op-
erations which lead to the best results corresponding
to a learning target set in advance. The optimal oper-
ations can be considered to include correct judgments
and actions to improve the status of the project. Be-
cause QCD should be kept smaller by project man-
agement, an optimal operation is defined as the oper-
ation to minimize the objective function f (operation)
defined as follows:
f(operation) =
∑
i∈LearningTarget
f
i
(operation) (1)
Trainer
Reward
output
Set learning
target
Optimal operation
generating system
Project principle
generating system
Decision tree
learning
Output as
rule format
Reinforcement learning
history
Project
principle
execution
program
Project
model
Project model,
operation input
Project simulator
Optimal operations
Optimal operations
Optimal operation
Project
principle
Reference operation
Project
model
Input
(e.g.)
1. IF on critical path, delay
1. THEN do “overtime directive”
2. IF lack of skill of person, not “progress
2. check” more than 3 days
2. THEN do “progress check”
Simulation
program of
operations
Figure 3: Outline of proposed method of the reference op-
eration.
where LearningTarget includes Q, C or D, operation
is a learner’s operation, and f
i
(operation) is i out-
putted by a simulator after executing operation. For
example, when a learning target is “Q and D”, the
objective function f(operation) = f
Q
(operation) +
f
D
(operation).
First, this method generates results for operations
by using the simulation program of operations to sim-
ulate various types of operations automatically. Sec-
ond, this method generates the optimal operations
from the results by reinforcement learning that can
calculate faster than brute force search. Third, this
method generates the project principle as a group
of rules based on optimal operations by using deci-
sion tree learning. Finally, the reference operation is
generated by the project principle execution program
which takes action following the project principle.
3.2 Optimal Operation Generating
System
It is necessary for generating a project principle to
use optimal operations for various types of projects.
In order to generate an optimal operation, it is nec-
essary to minimize the objective function as formula
(1). But it takes a lot of time to generate the optimal
operation using brute force search. So, the proposed
method searches an operation to improve the status of
the project. This search uses reinforcement learning
which determines future actions so as to maximize re-
ward based on past actions. The reinforcement learn-
ing, project state s
t
(t as time) is a set of QCD given
by simulator, action a is one of selectable actions in
simulator, and reward r(s
t
, a) is defined as formula (2)
AGenerationMethodofReferenceOperationusingReinforcementLearningonProjectManagerSkill-upSimulator
17
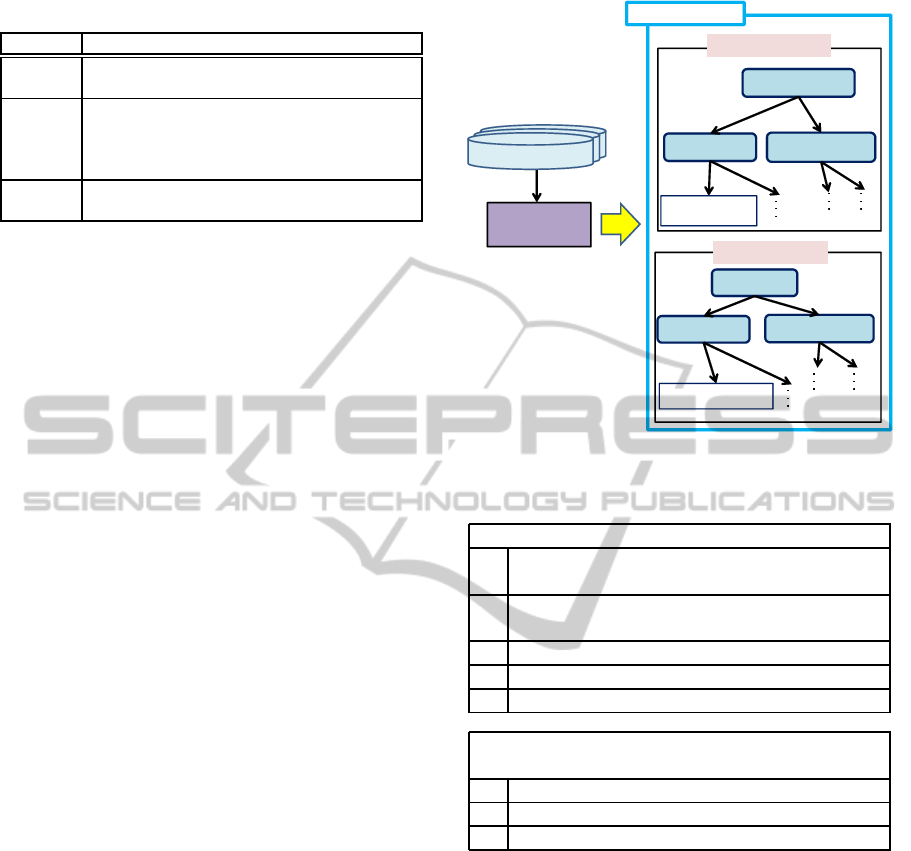
Table 1: Description h
i
(s
t
, a).
h
i
(s
t
, a) Description
h
Q
(s
t
, a) Variation of bugs based on s
t−1
divided by
bug rate per day in taking no action
h
C
(s
t
, a) Variation of costs based on s
t−1
divided by
costs per day in taking “overtime directive”
and “collaborative work with expert mem-
bers”
h
D
(s
t
, a) Expected finishing dates on s
t
divided by ex-
pected finishing dates in taking no action
and Table 1.
r(s
t
, a) = −
∑
i∈LearningTarget
h
i
(s
t
, a) (2)
In the reward, h
Q
(s
t
, a) or h
D
(s
t
, a) is given in
comparison with Q or D in taking no action, and
h
C
(s
t
, a) is given in comparison with costs per day in
taking “overtime directive” and “collaborative work
with expert members”. This formula means that the
reward r(s
t
, a) gets better when the value of bugs
or costs in s
t
is smaller than one in s
t−1
, or the ex-
pected finishing dates on s
t
is early. For example,
when learning target is “Q and D”, reward r(s
t
, a) =
−(h
Q
(s
t
, a) + h
D
(s
t
, a)).
3.3 Project Principle Generating
System
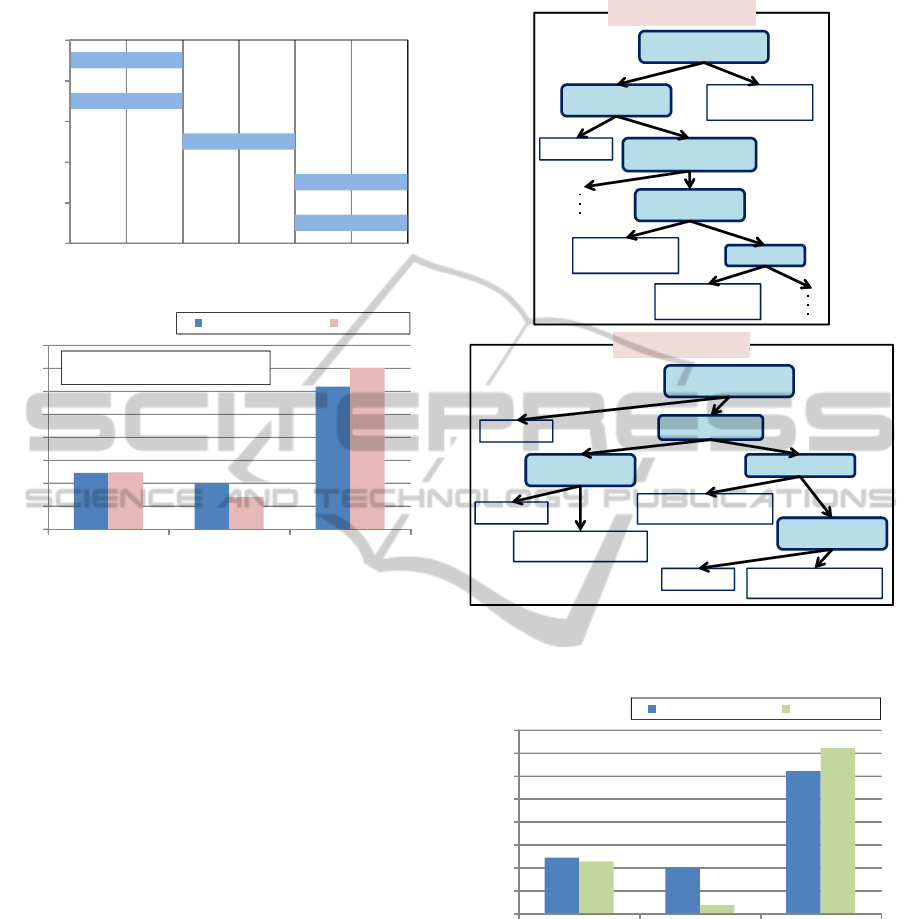
Figure 4 shows the outline of the project principle
generating method. In order to generate the project
principle corresponding to all aspects, the proposed
method uses decision tree learning based on opti-
mal operations. The proposed method generates the
project principle from two decision trees, “check
progress” and “take action”, which are stages of the
learner’s decision-making in project management.
From the decision tree, a learner gets the informa-
tion of class labels (leaf nodes shown in Figure 4) as
actions and attributes(nodes in Figure 4) as shown Ta-
ble 2. By using these decision trees, the project prin-
ciple execution program written by Java codes is gen-
erated automatically to decide reference operation.
4 EVALUATION
4.1 Results of Experiment
In order to generate a project principle, we used 10
project models that have 4.5 modules in average,
manpower of 4 people, 10 days for each module, and
30 days for development. We set the learning target to
Decision tree
Learning
Project principle
Optimal operations
Optimal operations
Optimal operation
Check progress
Already
collaborative work?
On critical path?
Already
overtime directive ?
no
yes
yes no
yes
no
Take
check progress
Input
Already delay?
On critical path?
Already
overtime directive ?
yes no
yes
no
Take
overtime directive
Take action
yes
no
Figure 4: Outline of project principle generating method.
Table 2: The information a learner gets.
The getting information before “check progress”
1. The number of days since the last “Check
progress”
2. The difference between a module’s difficulty
and a programmer’s skill
3. Whether the module is on critical path
4. Has “collaborative work” been taken?
5. Has “overwork” been taken?
The getting information after “check progress”
with one before “check progress”
6. Is the project delayed?
7. Whether additional man-hour exist
8. The number of bugs
“Q and D” because we assumed that a learner is expe-
rienced the project contained high standards for qual-
ity and delivery. And we experimented to compare
the reference operation by manually generated project
principle to one by the proposed method. For deci-
sion tree learning, we used WEKA which is one of
the open source data mining tools(Hall et al., 2009).
Figure 5 shows the project model includes diffi-
culty and skill of person assigned for each module,
and Figure 6 shows the result of experiment. Figure
6 shows the result with the project principle gener-
ated by the proposed method is better than one with
manually generated project principle. To generate the
project principle manually took 360 minutes, while to
generate one by the proposed method took 240 min-
utes. So, this experimental result showed the pro-
KMIS2012-InternationalConferenceonKnowledgeManagementandInformationSharing
18
1 6 11 16 21 26 31
Task5
Task4
Task3
Task2
Task1
Difficult:B/Skill:A
Difficult:C/Skill:A
Difficult:A/Skill:A
Difficult:B/Skill:A
Difficult:B/Skill:B
(days)
Module1
Module2
Module3
Module4
Module5
Figure 5: Detail of project model.
12.2
10
31
12.3
7
35
0
5
10
15
20
25
30
35
40
The num of bugs Additional costs Delivery
Num/Man-
day/Day
Proposed method Manually
<Plan>
Due date:30 days, Standard bugs:10
Figure 6: Result of experiment.
posed method generated the project principle and ref-
erence operation in reasonable time.
4.2 Discussion
In this experiment, the project principle generated
manually has 13 rules, while the project principle gen-
erated by the proposed method has 24 rules. Figure 7
shows a part of the project principle by the proposed
method.
The manually generated project principle shows
that “check progress” is necessary every three days.
However the project principle by the proposed
method reflects project status in detailed manner. Ex-
pert project managers confirmed that it is possible to
apply the project principle by the proposed method to
various types of projects. But, they said that an oper-
ation for a real project does not contain many “check
progress”. On the other hand, the reference oper-
ation by the proposed method indicates that “check
progress” should be taken many times, which may be
improper actions in the operations. Here, we con-
firmed the result for the modified project principle
that the number of “check progress” is decreased. The
result in decreasing “check progress” is shown in Fig-
ure 8. Figure 8 shows that the result in applying the
project principle generated by the proposed method is
Already
overtime directive?
Check progress
interval
Is mismatched?
Take
overtime directive
Continue
Continue
Already delay?
Take
overtime directive
Check progress
interval
Take
overtime directive
Continue
<=0
>0
yes
no
Take action
yes
no
yes
no
<=0
>0
Match rank
Already
overtime directive?
Take
check progress
Check progress
interval
Continue
Already
collaborative work?
Check progress
interval
Take
check progress
Take
check progress
Check progress
no
yes
<=0
>0
yes
no
<=1
>1
=-2,-1,1
=0,2
Figure 7: Project principle generated by the proposed
method.
12.2
10
31
11.4
1.9
36
0
5
10
15
20
25
30
35
40
The num of bugs Additional costs Delivery
Num/Man-
day/Day
Proposed method Modification
Figure 8: The result in decreasing “check progress”.
better than one manually in terms of Q and C. Thus, it
is confirmed that the project principle arranged man-
ually is more useful.
5 CONCLUSIONS
This paper addressed a generation method of refer-
ence operation to improve project results using rein-
forcement learning. The proposed method generates
AGenerationMethodofReferenceOperationusingReinforcementLearningonProjectManagerSkill-upSimulator
19

the project principle which is a group of rules to in-
dicate what to do in situations of the project automat-
ically. And the reference operation is generated by
applying the project principle to project models. The
project principle is generated by optimal operations
using reinforcement learning and decision tree learn-
ing. The experimental result with the project principle
generated by the proposed method is better than one
with manually generated project principle. To gener-
ate the project principle manually took 360 minutes,
while to generate one by the proposed method took
240 minutes. So, this result showed that the proposed
method generated the project principle and reference
operation efficiently. Our future work is how to gen-
erate more useful project principle.
ACKNOWLEDGEMENTS
This work was partially supported by KAKENHI;
Grant-in-Aid for challenging Exploratory Research
(23650537).
REFERENCES
Davidovitch, L., Shtub, A., and Parush, A. (2007). Project
Management Simulation-Based Learning For Systems
Engineering Students. In Proceedings of Interna-
tional Conference on Systems Engineering and Mod-
eling 2007, ICSEM ’07, pp.17–23.
Drappa, A. and Ludewig, J. (2000). Simulation in software
engineering training. In Proceedings of the 22nd in-
ternational conference on Software engineering, ICSE
’00, pp.199–208.
Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reute-
mann, P., and Witten, I. H. (2009). The WEKA Data
Mining Software: An Update. SIGKDD Explorations,
11(1):pp.10–18.
Henry, T. R. and LaFrance, J. (2006). Integrating role-
play into software engineering courses. Consortium
for Computing Sciences in Colleges, 22(2):pp.32–38.
Horine, G. (2005). Absolute Beginner’s Guide to Project
Management (Absolute Beginner’s Guide). Que
Corp., Indianapolis, IN, USA.
Iwai, K., Akiyoshi, M., Samejima, M., and Morihisa, H.
(2011). A Situation-dependent Scenario Generation
Framework for Project Management Skill-up Simula-
tor. In Proceedings of the 6th International Confer-
ence on Software and Data Technologies, 2:pp.408–
412.
PMI (2009). The PMBOK Guide. Project Management In-
stitute, fourth edition.
Thomas, J. W. (2000). A Review of Research on Project-
Based Learning. Technical report, San Rafael, CA.
KMIS2012-InternationalConferenceonKnowledgeManagementandInformationSharing
20
