
3D Interaction Assistance in Virtual Reality: A Semantic Reasoning
Engine for Context-awareness
From Interests and Objectives Detection to Adaptations
Yannick Dennemont, Guillaume Bouyer, Samir Otmane and Malik Mallem
IBISC Laboratory, Evry University, 40 rue du Pelvoux, 91020 Courcouronnes, France
Keywords:
Interaction Techniques, Virtual Reality, Context-awareness, Intelligent Systems, Knowledge Representations.
Abstract:
This work aims to provide 3D interaction assistance in virtual environments depending on context. We de-
signed and implemented a generic decision engine that can connect to our existing virtual reality applications
through a set of tools. It uses an ontology and Conceptual Graphs (CGs) to represent knowledge, and First
Order Logic to conduct semantic reasoning. Context information are gathered by virtual sensors in the ap-
plication and interpreted by the engine. Multimodal assistance is provided by virtual actuators. Our first test
scenario is about assistance to selection of objects or navigation towards objects: the engine automatically
detects user’s interests and manages adaptations depending on user’s hand gestures, interactions history and
type of task.
1 INTRODUCTION
Tasks in immersive virtual environments are associ-
ated to 3D interaction (3DI) techniques and devices
(e.g. selection of 3D objects with a flystick using
raycasting or virtual hand). As tasks and environ-
ments become more and more complex, these tech-
niques can no longer be the same for every applica-
tions. A solution can be to adapt the interaction (Bow-
man et al., 2006) to the needs and the context in order
to improve usability, for example:
• to choose other techniques (”specificity”) or make
techniques variations (”flavor”)(Octavia et al.,
2010);
• to add or manage modalities(Irawati et al.,
2005)(Bouyer et al., 2007)(Octavia et al., 2010);
• to perform automatically parts of the task (Celen-
tano and Nodari, 2004).
These adaptations can be done manually by the devel-
oper or the user, or automatically by the system: this
is ”adaptive” or ”context-aware” 3DI. This open issue
enables to:
• speed up the interaction (Celentano and Nodari,
2004);
• diminish the cognitive load (as in ubiquitous com-
puting);
• tailor the interaction (Wingrave et al., 2002) (Oc-
tavia et al., 2010);
• add or manage interaction possibilities (Bouyer
et al., 2007).
In order to go beyond basic interaction (Fig. 1), adap-
tive systems can first provide recognitions from raw
data. Usually they focus on the user and an activ-
ity recognition layer. But to achieve a better adaptiv-
ity, more content is needed: the context. The context
regroups information from potentially every entities
and can be used by the application to react and assist
the interaction. A formal and well recognized defini-
tion is (Dey and Abowd, 2000): Context is any infor-
mation that can be used to characterize the situation
of an entity. An entity is a person, place, or object
that is considered relevant to the interaction between
a user and an application, including the user and ap-
plications themselves. Thus, an ideal system for 3DI
assistance is context-aware as it uses context to pro-
vide relevant information and/or services to the user,
where relevancy depends on the user’s task.
Figure 1: Different layers to reach adaptive interaction.
349
Dennemont Y., Bouyer G., Otmane S. and Mallem M..
3D Interaction Assistance in Virtual Reality: A Semantic Reasoning Engine for Context-awareness - From Interests and Objectives Detection to
Adaptations.
DOI: 10.5220/0004207503490358
In Proceedings of the International Conference on Computer Graphics Theory and Applications and International Conference on Information
Visualization Theory and Applications (GRAPP-2013), pages 349-358
ISBN: 978-989-8565-46-4
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

2 RELATED WORK
Context-awareness emerged from intelligent systems
(Br
´
ezillon, 2011). Some drawbacks were due to fully
abstract reasoning or user exclusion. Intelligent assis-
tance systems can be split in two trends. Systems tend
to stress user assistance on well defined context (e.g.
(Bouyer et al., 2007)) or to stress context identifica-
tion that leads to direct adaptations for each situation
(e.g. (Coppola et al., 2009)(Frees, 2010)). Context-
awareness has different focuses (Fig. 2), though there
is a shared ideal list of properties to handle (Bettini
et al., 2010):
• Heterogeneity and mobility of context;
• Relationships and dependencies between context;
• Timeliness: access to past and future states;
• Imperfection: data can be uncertain or incorrect;
• Reasoning: to decide or to derive information;
• Usability of modelling formalisms;
• Efficient context provisioning.
Figure 2: Different families of context-aware applications.
Our research is mainly in the adaptive 3D inter-
action field. Yet, to achieve wider and better 3DI, a
richer context with semantic information and/or intel-
ligent agents is needed. Also reasoning needs grow
with the available information. So our approach is
generally part of the Intelligent Virtual Environments.
Adaptive 3DI can be implicit with adaptations
embedded in the interaction techniques (Poupyrev
et al., 1996)(Boudoin et al., 2008), or explicit by
using external processes (Lee et al., 2004)(Celen-
tano and Nodari, 2004)(Bouyer et al., 2007)(Oc-
tavia et al., 2010). Semantic virtual worlds can be
considered as a mixed form: explicit processes can
be applied but they are directly embedded into the
rendering loop for the specific semantic description
of the environment. Semantic virtual worlds as a
new paradigm is a discussed issue (Latoschik et al.,
2008). Several approaches offer to build full seman-
tic worlds (Latoschik et al., 2005)(Peters and Shrobe,
2003)(Lugrin and Cavazza, 2007)(Bonis et al., 2008).
Ubiquitous computing offers a lot of frameworks for
reaching context-awareness (Dey et al., 2001)(Ran-
ganathan and Campbell, 2003)(Gu et al., 2004)(Cop-
pola et al., 2009).
Finally how can we achieve a generic interaction
assistance for virtual reality? Firstly, we want to be
able to describe a generic assistance. Therefore we
can not base our project on works that focus on im-
plicit adaptations, on very specific assistances (com-
mand disambiguation (Irawati et al., 2005), recog-
nizing and doing part of the task for the user (Ce-
lentano and Nodari, 2004)), or on one emphasized
aspect of assistance (personalisation (Octavia et al.,
2010)). Secondly, we will not try to build a full se-
mantic world but to gather semantic information to
help the 3DI. This will allow the assistance to be used
by classic applications (which are the most common
for now). Thirdly, we want to be able to both iden-
tify a general context and to modulate our reasoning
(thus our assistance). That limits the reuse of previ-
ous work stressing strongly only one aspect ((Bouyer
et al., 2007)(Coppola et al., 2009)(Frees, 2010)). Fi-
nally, some frameworks are generic enough (exam-
ples and their comparison on Fig. 3) but not able
to describe any situations, to modify their reasoning
or difficult to reuse/to expand (particularly when they
were thought for another domain). The choice of con-
text representation can be restrictive: low level key-
values (Dey et al., 2001); a fixed list of data pairs (Lee
et al., 2004) or a first order logic predicate with a tuple
argument (Ranganathan and Campbell, 2003) (which
Figure 3: Approaches comparisons.
GRAPP2013-InternationalConferenceonComputerGraphicsTheoryandApplications
350

limits the ease to express complex relations and situa-
tions). Ontological approaches have richer and wider
range of representation but do not offer the same pos-
sibilities for reasoning modification(Gu et al., 2004).
Thus, part of the reasoning is usually done by a sec-
ond method (often first order logic).
To sum up, this research aims to model and de-
velop an explicit semantic context-aware engine for
common 3DI which:
• is generic; can represent any context and reactions;
• is usable, extensive and modifiable; performs se-
mantic reasoning with logical rules on an ontology;
• is pluggable; communicates with application tools:
sensors to retrieve the context, and actuators to
manage visual, audio and haptic modalities as well
as interaction modifications.
Users will benefit from an automatic 3D
interaction assistance that can supply support
through modalities, interaction technique choice or
application-specific help depending on the current
situation. Besides, designers could reuse, rearrange
and modify this 3DI adaptivity to share reasoning be-
tween applications or to create application-specificity.
A good adaptive 3DI can also help to release the de-
signers from the prediction of every situations, thus it
should be able to deal with degree of unpredictability.
In the next section, we discuss our choices for
modelling context and reasoning to achieve these
goals. Afterwards the section 4 gives an overview of
the whole engine. The section 5 and 6 respectively
details the representations possibilities and the rea-
soning process to obtain automatic adaptations. The
section 7 presents a test scenario with examples of
adaptations and process parts. Finally the section 8
details our conclusion and perspectives.
3 REPRESENTATION
AND REASONING
We need to manage context and to decide how to re-
act, which is a form of Knowledge Representation and
Reasoning. Actually, our system needs first to retrieve
and represent items of information, then to handle this
context and to define its effects on 3DI (discussed by
(Frees, 2010) for virtual reality). Several criteria led
our choice for the engine core: semantic degrees, ex-
pressiveness (vs efficiency) and usability.
We choose to base our representation on Concep-
tuals Graphs (CGs). They have a strong semantic
founding and are built on an ontology. They provide
a good expressiveness (a universal knowledge repre-
sentation (Sowa, 2008)(Chein and Mugnier, 2009))
equivalent to First Order Logic (FOL) but with a bet-
ter usability since they are also human readable. Se-
mantic networks are often picked to build the full se-
mantic world (Peters and Shrobe, 2003)(Lugrin and
Cavazza, 2007)(Bonis et al., 2008) which reinforces
our conviction for CGs.
The needed expressiveness is an open issue yet
You Can Only Learn What You Can Represent (Ot-
terlo, 2009). Thus, it is a fundamental question for
a sustainable use. FOL is usually the most expres-
sive choice made for context-awareness. Meantime,
semantic reasoning with an ontology is the most used
approach in context-awareness as it provides interop-
erability and a non-abstract representation. Moreover
coupled with the CGs usability, the model may al-
low at some point a welcomed direct users involve-
ment (Br
´
ezillon, 2011). Therefore using CGs, we ob-
tain re-usability and interoperability (ontological ap-
proach), sustainability and generality (FOL expres-
siveness) and the usability (graphs representation).
4 OVERVIEW OF THE ENGINE
The engine uses rules to take decisions regarding a
stored context (knowledge, events etc.). Context and
decisions concern the user, the interaction and the
environment, which communicates with the engine
through a set of tools (Fig. 4). Tools must have a
semantic description of their uses in order to be trig-
gered by the engine. They can be actuators with per-
ceivable effects (environment or interaction modifica-
tions, services presentation etc.) or sensors that re-
trieve information (from the environment, by mon-
itoring the interaction or through direct information
from the user etc.). Those tools can embed other
forms of reasoning than the engine core (e.g Hid-
den Markov Models) to provide information. Fi-
nally, tools can also apply to the engine itself. Meta-
actuators, which have a perceivable effect on the en-
gine, are currently used (parameters or rules modifi-
cations etc.). Meta-sensors could be used to call ex-
ternal reasoning possibilities ( e.g. data treatment).
Figure 4: An external engine - communication through se-
mantic tools.
3DInteractionAssistanceinVirtualReality:ASemanticReasoningEngineforContext-awareness-FromInterestsand
ObjectivesDetectiontoAdaptations
351
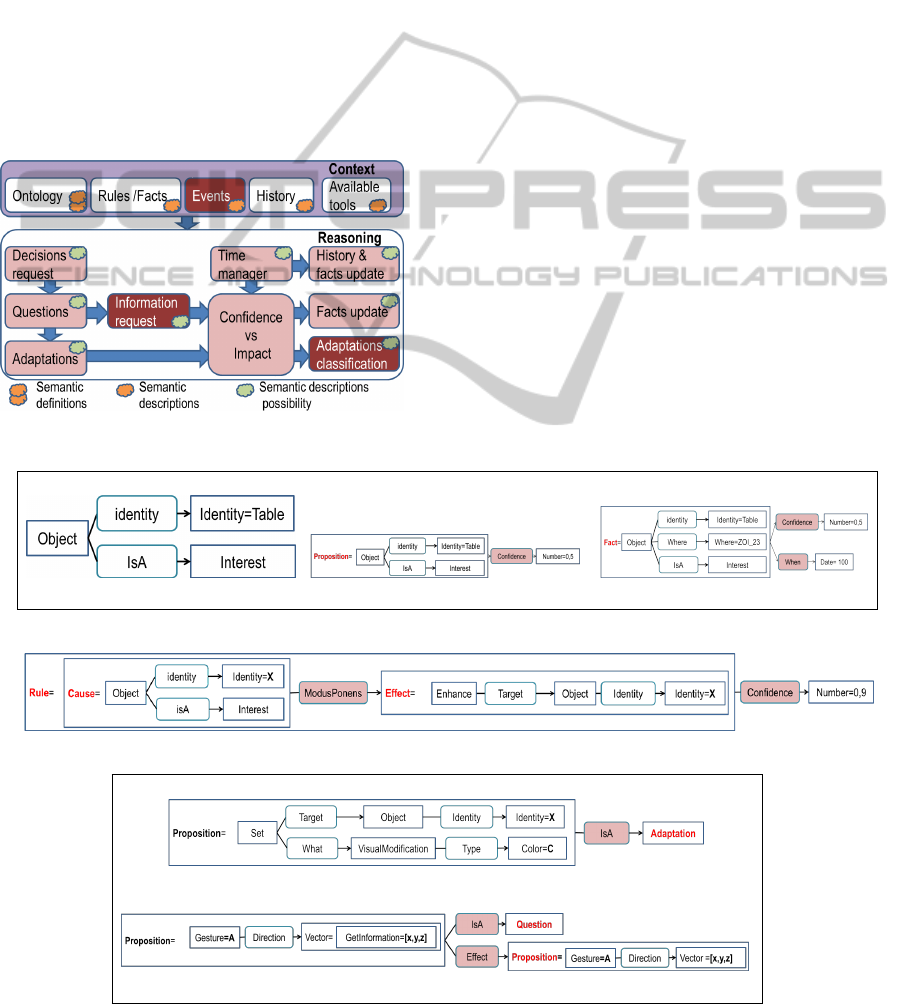
Thus the engine offers meta-adaptations possibilities
(it can modify itself depending on the context).
Context has various forms managed by the deci-
sion process (Fig. 13). First, the ontology lists con-
cepts and relations with underlying semantic, which
are used by CGs in order to describe rules and facts.
Available tools and the past events in history are spe-
cial facts. Events are newly integrated information
and trigger a decision request in an automatic mode.
The time manager checks the validity of the needed
facts. When a decision with an associated tool is true,
the engine aggregates its confidence and impact from
facts, events’ timing and rules. An acceptable total
impact limits the decisions that can be made, which
induces a knapsack problem as a last classification.
Figure 5: The engine - forms of context and reasoning.
We use Virtools as our scene graph manager and
the Amine platform (Kabbaj, 2006) (a Java open-
source multi-layer platform for intelligent systems)
for the engine. It offers an ontology manager and FOL
backward chaining that handles CGs: Prolog+CG
(PCG). Open Sound Control protocol (OSC) is used
for communication between the scene and the engine.
5 CONCEPTS USE IN THE
ENGINE
5.1 The Ontology
The specification of the engine is to be easily modifi-
able, reusable, and expanded by designers and users.
Therewith, we want to reason with ideas and situa-
tions rather than formulas. This is where the ontol-
ogy is important as it defines our semantic vocabulary
(written in italic afterwards). Next is a rough taxon-
omy of currently used concepts.
Reasoning Concepts. They are used to state what
is true (fact) and what is just a matter of discussion
(proposition); rules (effects depending on causes); de-
gree of confidence in those concepts (e.g. Fig. 6 and
Fig. 7). But also what decisions can actually be made
(reactions like adaptations or questions, e.g. Fig. 8);
(a) CG fact (b) A general confidence (c) Event with confidence and time
Figure 6: Facts examples.
Figure 7: Rule example: the enhancement will of an interest.
(a) An adaptation to color an object
(b) A question to ask for a gesture direction
Figure 8: Reaction possibilities examples.
GRAPP2013-InternationalConferenceonComputerGraphicsTheoryandApplications
352

Reification Concepts. They are used to manage
tools, like sensors or actuators. Descriptions include
commands to be sent for specific uses and their im-
pacts (e.g. Fig. 9) depending on cases (e.g. Fig. 10);
3D Interaction Concepts. They are the main focus
of the overall generic engine. So we need to describe
various modalities, tasks etc.
Time Concepts. They are used to manage new
facts, events (fact with a date and a duration) (e.g.
Fig. 6), historyof previous events and reactions.
Spatial Concepts. They are used to manage posi-
tion, direction etc. In virtual environment, a lot of the
spatial issues are in fact handled by the scene graphs
manager. But zones like auras or focuses are useful to
understand the current activity.
General Concepts. They are a base vocabulary to
describe situations. For example to manipulate at-
tributes like identity or express active states.
Application Specific Concepts. Applications can
expand the knowledge base with their own concepts.
For example gestures that can be named (’Z’), and/or
classed (right and up are also rectilinear gestures).
Let focus more on two concepts used to classify
reactions (detailed in the section 6). We use confi-
dence that represents the degree of sureness of an in-
formation. For a reaction, it thus reflects the degree
of certainty that this decision can be applied in the
current situation. Impact is specific to reactions and
represents the degree of their perceived repercussion
for the user. The initial value of impact is supplied by
the tool used to reify the reaction (an intrinsic degree
of repercussion). Then the actual impact can be mod-
ified depending on the current situation, which leads
to the expression of influential cases.
5.2 Conceptual Graphs
Situations and reactions to situations can now both be
described using CGs, built on those concepts and clas-
sified using CGs theory. In a final form, every logical
combinations in a CG (that a user could enter) should
be handled. Next are some examples illustrating dif-
ferent categories of context and reasoning:
Facts. Fig. 6 represents different information re-
garding a similar situation, about an object of interest
with the identity ”table”. On figure 6a the situation is
currently true. Figure 6b is an expression of the gen-
eral confidence about this type of situations (without
assuming its realization). Fig. 6c is an event (send by
a sensor) with a date and an initial confidence.
Rules. Fig. 7 represents a general rule: if an object
is a known interest then the engine will try to enhance
(a) The color actuator
(b) The gesture direction sensor
Figure 9: Tools examples.
Figure 10: Impact increase case example: to avoid activation/reactivation cycle.
3DInteractionAssistanceinVirtualReality:ASemanticReasoningEngineforContext-awareness-FromInterestsand
ObjectivesDetectiontoAdaptations
353

this object. This rule is associated with a high confi-
dence; the situation is most probably true regardless
of the remaining context.
Reactions. Fig. 8a is an example of general adapta-
tion describing the action of modifying the color of an
object, which is a type of visual modification. Fig. 8b
is an application specific question to obtain the direc-
tion of a gesture.
Tools. Fig. 9a and Fig. 9b are tools able to imple-
ment the previous reactions. In fact, their descriptions
of use are here exactly the reaction descriptions (they
are relatively general tools). Nevertheless they could
be more specific (e.g. a special tool to color a specific
subtype of objects etc.). Impact of the color actuator
is low (compared to an attraction for example) and the
impact of the sensors is null (as completely transpar-
ent for the user).
Cases E.g Fig. 10 shows a situation that can mod-
ify the impact of reactions: the impact of a decision
already in the history will increase. This will help to
avoid activation/deactivation cycles.
6 REACTIONS PROCESS
How are those concepts and conceptual graphs used
by the engine to obtain fitting reactions? They are
handled by our Prolog meta-interpreter. It uses con-
cepts definitions to be able to deal with forms of truth
(as a PCG element, as a fact description, as a CG rules
effect etc.), degree of truth (confidence) and times (du-
ration validity, history etc.). At any time, the engine
stores context elements (facts, events, etc.). When an
application needs a fitting reaction (after a new event,
when ordered by the user, etc.), it sends a decision
request. The engine then uses the meta-interpreter to
seek eligible reactions. Those are true adaptations
and questions (e.g Fig. 8) with an available associated
tool (e.g. Fig 9).
In order to classify those decisions, we calculate
both the confidence and the impact of each decision.
For any CGs, and thus also for reactions, a list of con-
fidence is obtained by considering all paths leading to
them. Each path can combine different confidence ex-
pressions:
• A direct corresponding PCG fact (e.g. Fig 6a) has
the maximum confidence: 1;
• A CG with a supplied confidence or expressing
generic knowledge confidence (e.g. Fig. 6b);
• An event confidence (e.g. Fig. 6c). Its confidence
is time dependant as the initial confidence is multi-
plied by the ratio of remaining validity.
• A CG rule induced confidence (e.g. Fig. 7). If
true, the effects confidence are the average causes
confidences times the rule confidence (0 instead).
It is an iterative process.
We use a confidence fusion function to convert this
list into a single scalar. We consider that the more
facts and rules led to a reaction, the more the confi-
dence in it should increase, while kept bounded be-
tween 0 and 1. So for n confidences with Mean
as average value: Globalconfidence = (1 − Mean) ×
(1 −
1
n
) × Mean + Mean. The global confidence
is still 0 (respectively 1) in case of absolute false
when Mean = 0 (respectively absolute true when
Mean = 1) and singletons are not modified.
Next, the engine aggregates the decisions im-
pact. Each tool has an initial impact which is mod-
ified given specific cases. Initial impact equals to
0 (without any impacts) or 1 (with the most im-
pact) are not modified. Otherwise, at each n appli-
cable case, the impact is altered with a weight (W ,
25% if not valued in the CG) while kept bounded:
impact(n) = impact(n − 1) − W × impact(n − 1) for
a lower impact or impact(n) = impact(n − 1) +W ×
(1 − impact(n − 1)) for a greater impact . Thus
smaller steps are made for already extreme values
(e.g. keeping very effective adaptations reachable).
Finally, decisions with a confidence on impact ra-
tio greater than a threshold (1 by default) are eligible.
Then, eligible decisions are selected to fill the limit
of the total amount of impact usable. Thus this last
classification is a knapsack problem. The available
impact is the initial user impact total (a first step into
profiling the user) minus the active decisions impact.
7 CASE STUDY
7.1 Scenario Examples
We test the engine with a case study: to try to auto-
matically acquire some user’s interests and enhance
them. The interests are here linked to the user’s hand.
We use the fly-over interaction technique (Boudoin
et al., 2008). It is an implicit adaptive technique
which offers a continuous interaction by detecting au-
tomatically the current task based on the cursor posi-
tion. We use it as our 3D interaction base conjunc-
tively to the engine. Besides, the task information
is retrieved from fly-over which thus becomes a task
sensor for the engine. The application tools are pre-
sented in Fig 11. The engine uses general rules as to:
1. Define possible interests:
a) inside of a Zones Of Interest (ZOI);
GRAPP2013-InternationalConferenceonComputerGraphicsTheoryandApplications
354

b) a previous interest in history.
2. Define possible objectives :
a) selection of an object.
b) navigation towards an object.
3. Define the will to enhance interests:
a) a general will for all interests (Fig. 7 ).
b) exceptions when an interest is part of a accom-
plished objective (e.g object selected).
4. Define possible enhancements:
a) object visual modifications: color change.
b) interaction modifications: visual/haptic force.
5. Define possible objectives assistances :
a) select an object for a selection objective.
b) Move toward an object for a selection or a nav-
igation objective.
6. Manage adaptations states:
a) remove visual modification for past interests;
b) remove a currently applied force if the move-
ment is abnormal (e.g local+high=the user is
”stuck”).
7. Manage decisions impacts:
a) increase impact for some concepts: haptic
impact> visual impact; interaction modifica-
tion impact > visual modification impact;
b) increase decision’s impact if present in history
(Fig. 10);
c) decrease interaction modification’s impact for
local movement.
8. Define engine meta-adaptation:
a) switch between engine configurations on the
type of request (manual if the decision request
came from the user)
b) increase the total impact and decrease the de-
cisions threshold for manual configuration.
c) decrease the total impact and increase the de-
cisions threshold for automatic configuration.
Finally, the application specific rules are:
9. Monitor the hand movement;
10. Ask for detected gesture attributes ;
11. Activate or deactivate a ZOI around the hand if a
circular gesture occurred;
12. Activate a ZOI in the direction of the gesture if a
rectilinear gesture occurred;
13. Deactivate this direction ZOI after 3s.
14. Deactivate every adaptations if the ”Z” gesture is
detected.
7.2 Discussion
As a result, the rules combine themselves as expected
(adaptations examples Fig. 12), but with supplemen-
tary outcomes which were not fully planned. Those
Type Name Aims
Sensor ZOISens Add and report the con-
tent of 3D zones
PtFocus Report the current ob-
jects beneath the pointer
as interests
SelSens Report selected objects
FOTaskSens Report the current task
GestureSens Send recognized ges-
tures name and attributes
MvtSens Qualify movement
speed as high or low
and movement scope as
local or global
AutoSens Report if the decision is
requested by the user or
automatically
Actuator ColorActu Change the color of an
object
ForceActu Add a haptic or a visual
force to an object
ZoomActu Center the camera/zoom
on an object
SelActu Add an object to the ac-
tive selection
Meta-
Actuator
ConfUser Modify user attributes
(e.g the total impact
available, the confidence
on impact ratio threshold
etc.)
Figure 11: Applications available tools.
results depend on the initial impact, confidence and
total admissible impact values.
Interests and Objective Detection. In fact, there
are several interest types: explicit, by creating
voluntarily a ZOI (rules 1.a, 11, 12) or by centering
the pointer on an object (PtFocus sensor), or implicit,
either by moving rectilinearly toward an object (thus
creating a ZOI: rules 1.a, 12) or by considering
previous interest (rule 1.b). Confidence fusion of
those information leads to the detection of the major
interests, which should be the ones enhanced (rules
3). Objectives are specific recognized activities
usually implicating an interest in a defined situation
(rules 2). Objectives confidence depends on interests
confidence but they have their own adaptations (rules
5).
Reactive Adaptations: Interest Enhancements
A Single Interest: Movement Influence. With an
activated ZOI around the hand (rule 11), passing by
3DInteractionAssistanceinVirtualReality:ASemanticReasoningEngineforContext-awareness-FromInterestsand
ObjectivesDetectiontoAdaptations
355

Figure 12: Illustration of some automatic adaptations depending on the context.
an object colors it red (rules 4.a, 7.a), while standing
next to it makes it also attractive (as movement is then
local, diminishing the attraction impact rules 4.b, 7.c).
Colors are reset when the user moves far away while
attraction is removed when the user tries to resist it
(rules 6). When pointing an object or when mov-
ing toward an object during a global movement (rule
12), the object is colored red (rules 4.a, 7.a). When
pointing an object from a rest position or starting a
new movement directly toward an object (rule 12), it
makes it also attractive (rules 4.b, 7.c: not intended at
first, this primary intention can be highlighted due to
the latency of the movement scope sensor, which still
points the movement as local). Colors are reset after
this ZOI deactivation (rule 13).
History Influence. In both previous cases, when
pointed several times as an interest (thus present as
several current facts or history facts, rule 1.b) at-
traction can be activated regardless of the movement
scope (global or local). When it has been deactivated,
attraction usually cannot be reactivated for a time cor-
responding to history memory (rule 7.b). Some reacti-
vations occur for coloring as the decision has initially
less impact. Moreover depending on the color actu-
ator impact and the history, the coloration time can
vary and can even flash for a while (not intended at
first). Indeed an object can be simultaneously inter-
esting enough to trigger the coloring adaptation (rule
4.a) and not enough to avoid the color reset (rule 6.a).
In result, if an object has at a time a sufficient inter-
est and then seems abandoned by the user, the ob-
ject flickers for a while before its interest confidence
reaches lower level. This is also a (unplanned) mean
to attract the user attention.
Several Interests. More complex situations occur
when several objects are close to the hand: e.g only
adaptation with the less impact (coloring, rule 4.a)
is applied to a maximum of objects (even if for now
there is no specific treatment for groups, the most fit-
ting adaptations is applied until there is no more ad-
missible impact thus a group logic emerged). Situa-
tions are very various when several interests are spot-
ted with more different confidences.
Pro-active Adaptations: Tasks Shortcuts. With
the current task known (e.g selection or navigation),
objects of interest can be interpreted as objectives (re-
spectively to select an object or to navigate toward
it, rules 2). Then if the interest confidence is high
enough, a zoom on an object can occur (rule 5.b). In
GRAPP2013-InternationalConferenceonComputerGraphicsTheoryandApplications
356

the case of the selection task, the object automatic se-
lection can happen (rule 5.a). Those adaptations are
pro-active as parts of the supposed intended task is ac-
tually done for the user. But those decisions are scarce
since a lot of rules are involved. Thus the remaining
confidence is usually low whereas the decisions im-
pact is relatively high. Finally, a selected object is no
longer the target of enhancement (as we can assume
that the user is then well aware of it or has achieved
this sub-objective, rule 3.b)
Meta-adaptations. The easiest way to obtain the
previous pro-active adaptations is to switch to the
manual mode. This reduces the engine requirement
for adaptation through the meta-actuators (rules 8).
Indeed if a user is the source of the adaptation re-
quest, the assistance need and a possible objective are
very likely. With lower requirement in this context,
a medium confidence is enough to obtain those assis-
tances (a fulfilment of parts of the task, rules 5) .
Scenario Conclusion. Using the engine, we have
successfully obtained an adaptations manager. The
engine context and reasoning parts can also be
grouped by their current role for the adaptations (Fig-
ure 13). The situation progresses with two inter-
laced processes: decision and comprehension. The
decision process goes from representing the situation
to reasoning, and transforms simple facts confidence
into the best reaction bet. The comprehension pro-
cess goes from identifying the situation to understand-
ing how to assist (thus managing the two context-
awareness trends) and transforms simple data to a po-
tential full plan of the situation. The decision set is
extended as the comprehension progresses. Based on
the current events and knowledge, more information
can be requested. Then adaptations are unlocked as
the situation identification progresses. Reactive adap-
tations are available when an interest is acquired (e.g.
the enhancement reactions). While still progressing
Figure 13: The adaptations manager realized with the en-
gine (planning is not available yet).
through our reasoning and comprehension (e.g. fus-
ing the interest information), objectives can be de-
ducted and pro-active reactions obtained (e.g. the se-
lection of a specific object). Meta-adaptations can be
applied at each level (e.g. ease the reactions require-
ment based on the automatic mode information). All
those reactions choices, parametrisation and reifica-
tion depend on the current activity context. By having
a semantic engine, it is easy to interfere on each con-
cept. For example, a tool to retrieve the interests and
their confidence from the engine can be used in order
to benefit directly from the identification part. And
the user can specify his objective to the engine and
benefit directly from the assistance (without using au-
tomatic interest sensors to identify his intention).
8 CONCLUSIONS
The engine aims to allow a semantic reasoning and
the reuse of tools in a non-semantic environment to
help the 3DI. We propose an engine core with a se-
mantic base to achieve adaptation, which could be
directly addressed by designers or users. Context-
awareness properties (page 2) are almost all tackled
but need deepening. The engine response delay is not
well suited for a full automatic mode yet, but rather
for punctual helps. This drawback can be lessened
but is an inherent part of our approach.
By adding a planning block later, we could refine
the adaptations and allow more tools combinations.
Indeed active decisions could be replaced by better
ones in a new context. This currently can be done
by freeing the currently used ”impact” and rethinking
all adaptations at each decision process. However, it
is a particular case of a more complex resources and
world states planning.
Besides, we have started adding direct control
of the engine. This part emphasizes the engine tai-
lorability since changing the control from a gesture
to another, or to any events, can easily be done di-
rectly into the engine (rather that remodelling applica-
tion parts). And as a 3DI rules set can be reused, any
applications can add their own rules set and controls
possibilities. Also, the gestures recognition can be
used to monitor the user activity and to deduce hints
of intention. A possibility is to use our HMM recog-
nition module on other data (than the 3D position) in
order to learn and classify interesting situations.
Moreover, we can also enhance the task detection
based on more context information than the fly-over
position information. In fact this is a reinterpretation
of this technique by splitting it in two and by insert-
ing the engine in the middle. We use the sensor part
3DInteractionAssistanceinVirtualReality:ASemanticReasoningEngineforContext-awareness-FromInterestsand
ObjectivesDetectiontoAdaptations
357

which deduces the task based on the cursors position
(within the control model) and the actuator part which
is the selection of the control model (based on the
task). Nevertheless, we will keep fly-over fully func-
tional and allow the engine to force the control model
through a specific actuator. In this case we benefit
from both side: the good response time of fly-over
and the ability to detect and manage more complex
task recognition situations when needed.
Our next steps are: to continue to explore con-
text, to make better tools descriptions and to allow
more combinations (thus to further exploit the avail-
able context ) and finally to proceed to engine evalua-
tions.
REFERENCES
Bettini, C., Brdiczka, O., Henricksen, K., Indulska, J.,
Nicklas, D., Ranganathan, A., and Riboni, D. (2010).
Pervasive and Mobile Computing.
Bonis, B., Stamos, J., Vosinakis, S., Andreou, I., and
Panayiotopoulos, T. (2008). A platform for vir-
tual museums with personalized content. Multimedia
Tools and Applications, 42(2):139–159.
Boudoin, P., Otmane, S., and Mallem, M. (2008). Fly
Over , a 3D Interaction Technique for Navigation in
Virtual Environments Independent from Tracking De-
vices. Virtual Reality, (Vric).
Bouyer, G., Bourdot, P., and Ammi, M. (2007). Supervi-
sion of Task-Oriented Multimodal Rendering for VR
Applications. Communications.
Bowman, D. A., Chen, J., Wingrave, C. A., Lucas, J., Ray,
A., Polys, N. F., Li, Q., Haciahmetoglu, Y., Kim, J.-s.,
Kim, S., Boehringer, R., and Ni, T. (2006). New Di-
rections in 3D User Interfaces. International Journal,
5.
Br
´
ezillon, P. (2011). From expert systems to context-based
intelligent assistant systems : a testimony. Engineer-
ing, 26:19–24.
Celentano, A. and Nodari, M. (2004). Adaptive interac-
tion in Web3D virtual worlds. Proceedings of the
ninth international conference on 3D Web technology
- Web3D ’04, 1(212):41.
Chein, M. and Mugnier, M. (2009). Graph-bases Knowl-
edge Representation: Computational Foundations of
Conceptual Graphs. Springer.
Coppola, P., Mea, V. D., Gaspero, L. D., Lomuscio, R.,
Mischis, D., Mizzaro, S., Nazzi, E., Scagnetto, I., and
Vassena, L. (2009). AI Techniques in a Context-Aware
Ubiquitous Environment, pages 150–180.
Dey, A. and Abowd, G. (2000). Towards a better under-
standing of context and context-awareness. In CHI
2000 workshop on the what, who, where, when, and
how of context-awareness, volume 4.
Dey, A., Abowd, G., and Salber, D. (2001). A conceptual
framework and a toolkit for supporting the rapid pro-
totyping of context-aware applications. HumanCom-
puter Interaction, pages 1–67.
Frees, S. (2010). Context-driven interaction in immer-
sive virtual environments. Virtual Reality, Volume
14(4):1–14.
Gu, T., Wang, X., Pung, H., and Zhang, D. (2004). An
ontology-based context model in intelligent environ-
ments. In Proceedings of Communication Networks
and Distributed Systems Modeling and Simulation
Conference, volume 2004. Citeseer.
Irawati, S., Calder
´
on, D., and Ko, H. (2005). Seman-
tic 3D object manipulation using object ontology in
multimodal interaction framework. In Proceedings of
the 2005 international conference on Augmented tele-
existence, pages 35–39. ACM.
Kabbaj, A. (2006). Development of Intelligent Systems and
Multi-Agents Systems with Amine Platform. Intelli-
gence, pages 1–14.
Latoschik, M. E., Biermann, P., and Wachsmuth, I. (2005).
Knowledge in the Loop : Semantics Representa-
tion for Multimodal Simulative Environments (2005).
pages 25 – 39.
Latoschik, M. E., Blach, R., and Iao, F. (2008). Semantic
Modelling for Virtual Worlds A Novel Paradigm for
Realtime Interactive Systems ? In ACM symposium
on Virtual reality software and technology.
Lee, S., Lee, Y., Jang, S., and Woo, W. (2004). vr-UCAM:
Unified context-aware application module for virtual
reality. Conference on Artificial Reality.
Lugrin, J.-l. and Cavazza, M. (2007). Making Sense of Vir-
tual Environments : Action Representation , Ground-
ing and Common Sense. In 12th International confer-
ence on intelligent user interfaces.
Octavia, J., Coninx, K., and Raymaekers, C. (2010).
Enhancing User Interaction in Virtual Environments
through Adaptive Personalized 3D Interaction Tech-
niques. In UMAP.
Otterlo, M. (2009). The logic of adaptive behavior.
Peters, S. and Shrobe, H. E. (2003). Using Semantic Net-
works for Knowledge Representation in an Intelligent
Environment. In 1st International Conference on Per-
vasive Computing and Communications.
Poupyrev, I., Billinghurst, M., Weghorst, S., and Ichikawa,
T. (1996). The go-go interaction technique: non-linear
mapping for direct manipulation in VR. In Proceed-
ings of the 9th annual ACM symposium on User inter-
face software and technology, pages 79–80. ACM.
Ranganathan, A. and Campbell, R. H. (2003). An in-
frastructure for context-awareness based on first order
logic. Personal and Ubiquitous Computing, 7(6):353–
364.
Sowa, J. F. (2008). Conceptual Graphs, pages 213–217.
Elsevier.
Wingrave, C. A., Bowman, D. A., and Ramakrishnan, N.
(2002). Towards Preferences in Virtual Environment
Interfaces. Interfaces.
GRAPP2013-InternationalConferenceonComputerGraphicsTheoryandApplications
358
