
Feature Extraction and Classification of Biosignals
Emotion Valence Detection from EEG Signals
A. M. Tom
´
e
1
, A. R. Hidalgo-Mu
˜
noz
2
, M. M. L
´
opez
3
, A. R. Teixeira
3
, I. M. Santos
4
, A. T. Pereira
4
,
M. V
´
azquez-Marrufo
2
and E. W. Lang
5
1
DETI/IEETA, University of Aveiro, 3810-193 Aveiro, Portugal
2
Dept. Experimental Psychology, University of Seville, 41018 Seville, Spain
3
IEETA, University of Aveiro, 3810-193 Aveiro, Portugal
4
Dept Ci
ˆ
encias de Educac¸
˜
ao, University of Aveiro, 3810-193 Aveiro, Portugal
5
Biophysics, CIML Group, University of Regensburg, 93040 Regensburg, Germany
Keywords:
Valence Detection, Random Forest, ERD/ERS.
Abstract:
In this work a valence recognition system based on electroencephalograms is presented. The performance of
the system is evaluated for two settings: single subjects (intra-subject) and between subjects (inter-subject).
The feature extraction is based on measures of relative energies computed in short time intervals and certain
frequency bands. The feature extraction is performed either on signals averaged over an ensemble of trials or
on single-trial response signals. The subsequent classification stage is based on an ensemble classifier, i. e. a
random forest of tree classifiers. The classification is performed considering the ensemble average responses of
all subjects (inter-subject) or considering the single-trial responses of single subjects (intra-subject). Applying
a proper importance measure of the classifier, feature elimination has been used to identify the most relevant
features of the decision making.
1 INTRODUCTION
During the last decades, information about the emo-
tional state of users has become more and more im-
portant in computer based technologies. Several emo-
tion recognition methods and their applications have
been addressed, including facial recognition, voice
recognition and electrophysiology - based systems
(Calvo and D’Mello, 2010). Concerning the ori-
gin of the signals of the latter systems, they can
be divided into two categories: those originating
from the peripheral nervous system (e.g. heart rate,
Electromyogram - EMG, galvanic skin resistance-
GSR), and those coming from the central nervous sys-
tem (e.g. Electroencephalograms-EEG). Tradition-
ally, EEG-based technology has been used in medical
applications but nowadays it is spreading to other ar-
eas like entertainment and brain-computer interfaces
(BCI). With the emergence of wearable and portable
devices, developing systems based on EEG signals at-
tracted much interest. Therefore, with the availability
of vast amounts of digital data, there is an increasing
interest in the development of machine learning soft-
ware applications. Emotion recognition systems,
dealing with biological signals, exhibit performances
ranging from 40% to 90% depending on the num-
ber of emotion categories of the study. However,
it is not easy to compare them since they differ in
the way emotions are elicited, and in the underlying
model of emotions (e.g. emotional categories). Psy-
chologists represent emotions in a 2D valence/arousal
space (Bradley and Lang, 2007). By dividing the va-
lence (horizontal axis) - arousal (vertical axis) space
into four quadrants, several discrete emotions are usu-
ally identified (Russell, 1980). The most widely used
categories are the following : Joy (high valence , high
arousal); Pleasure (high valence, low arousal); Anger
(Low valence, High arousal); Sadness (low valence,
low arousal). Some studies include a fifth category
assigned as Neutral which is represented in the region
close to the origin of the 2D valence/arousal space.
Some studies concentrated on one of the dimensions
of the space like identifying the arousal intensity (high
versus low) or the valence (low/ negative versus high
/positive), and eventually a third class neutral state.
Normally, emotions are elicited by (i) presenting an
54
M. Tomé A., R. Hidalgo-Muñoz A., M. López M., R. Teixeira A., M. Santos I., T. Pereira A., Vázquez-Marrufo M. and W. Lang E..
Feature Extraction and Classification of Biosignals - Emotion Valence Detection from EEG Signals.
DOI: 10.5220/0004233100540060
In Proceedings of the International Conference on Bio-inspired Systems and Signal Processing (BIOSIGNALS-2013), pages 54-60
ISBN: 978-989-8565-36-5
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

external stimulus (picture, sound, word or videos) re-
lated to different emotions at some predefined inter-
val, or by (ii) simply asking subjects to imagine dif-
ferent kinds of emotions. Concerning external visual
stimuli, one may resort to the International Affec-
tive Picture System (IAPS) collection which is freely
available (Lang et al., 2008), and is composed of
pictures classified by a large number of participants
in terms of Arousal and Valence. The picture set is
widely used in experimental psychology as well as in
automatic emotion recognition systems. Most of the
work in automatic recognition can be considered pi-
lot studies where all experiments are conducted under
laboratory settings where experiments are prepared to
induce emotions. But like in any other classification
system, it is needed to establish which signals and
how they are acquired, extract relevant features from
these input signals, and finally train a classifier. In
this work, a valence recognition system is presented,
the feature extraction module of which is inspired on
brain studies, and its classification module is based on
a random forest of decision trees. The latter module
is also applied recursively to achieve feature elimi-
nation. Moreover, the classification performance is
measured with respect to inter- and intra-subject clas-
sification. To achieve such goals, different types of
signals are applied as inputs to the feature extraction
module: either single-trial or ensemble average sig-
nals.
1.1 Classification Systems and Emotion
The pioneering work of Picard (Picard et al., 2001) on
affective computing reports a recognition rate of 81%
, achieved by collecting blood pressure, skin conduc-
tance, and respiration information from one person
during several weeks. The subject, an experienced
actor, tried to express eight affective states with the
aid of a computer controlled prompting system (Pi-
card et al., 2001). In (Haag et al., 2004), using the
IAPS data set as stimulus reportoir, peripheral biolog-
ical signals were collected from a single person dur-
ing several days and at different times of the day. By
using a neural network classifier, they consider that
the estimation of the valence value (63.8%) is a much
harder task than the estimation of arousal (89.3%). In
(Kim et al., 2004), a study with 50 participants, aged
from seven to eight years old, is presented. The visual
stimulation with the IAPS data set was considered in-
sufficient, hence they proposed a sophisticated sce-
nario to elicit emotions. It consisted of visual stimuli
using controlled illumination, and additional auditory
stimuli using background music. Simultaneously, an
actress narrated a story (with emotional contents, like
sadness) that was carefully prepared to evoke the sym-
pathy of the subjects. The latter were also requested
to look at a toy in front of them, and it seemed as if
the toy was telling the sad story to the subjects. Only
peripheral biological signals were recorded, and the
measured features were the input of a classification
scheme based on a support vector machine (SVM).
The results showed accuracies of 78.4% and 61% for
3 and 4 categories of different emotions, respectively.
In (Schaaff and Schultz, 2009), the data collection
was performed with stimulus pictures taken from the
IAPS repository thus inducing three emotional states
in five male participants: pleasant, neutral, and un-
pleasant. They obtained, using SVMs, an accuracy of
66.7% for these three classes of emotion, solely based
on features extracted from EEG signals. A similar
strategy was followed by (Macas et al., 2009), where
the EEG data was collected from 23 subjects during
an affective picture stimuli presentation to induce four
emotional states in arousal/valence space. The auto-
matic recognition of the individual emotional states
was performed with a Bayes classifier. The mean ac-
curacy of the individual classification was about 75%.
In (Frantzidis et al., 2010), four emotional categories
of the arousal/valence space of the IAPS picture set
were used to elicit emotions of 28 participants and
their EEG signals were recorded. The ensemble aver-
age was computed for each stimulus category and per-
son. Several characteristics (peaks and latencies) as
well as frequency related features (event related syn-
chronization) were measured on a signal ensemble en-
compassing three channels located along the anterior-
posterior line. Then a classifier (a decision tree, C4.5
algorithm) was applied to the set of features to iden-
tify the affective state. An average accuracy of 77.7%
was reported.
1.2 Event Related Potentials and
Emotion
Most of the recognition systems referred above ex-
tract features in segments of the signal defined af-
ter the stimulus presentation. Those features were
found relevant in brain studies and are generally ad-
dressed in studies of event-related potentials (ERP).
ERPs represent transient components in the electroen-
cephalogram (EEG) generated in response to a stim-
ulus, e.g. a visual or auditory stimulus. Studies of
event-related potentials deal with signals that repre-
sent different levels of analysis: signals from single-
trials, ensemble averaged signals where the ensem-
ble encompasses several trials, and signals resulting
from a grand-average over different trials as well as
subjects. The segment of the time series contain-
FeatureExtractionandClassificationofBiosignals-EmotionValenceDetectionfromEEGSignals
55

ing the single-trial response signal is centered on the
stimulus: t
i
(negative value) before and t
f
(positive
value) after stimulus. The ensemble average, over tri-
als of one subject, eliminates the spontaneous activity
of brain maintaining the activity that is phase-locked
with stimulus. And the grand-average is the aver-
age, over participants, of ensemble averages and it is
used mostly to illustrate the outcomes of the study.
In experimental psychology studies, ERP is usually
the ensemble average computed with all single-trials
belonging to one condition (stimulus type). Those
works show that the event-related potentials (ERP)
have characteristics (amplitude and latency) of the
early waves which change according to the nature of
the stimuli (Olofsson et al., 2008). Other investiga-
tions studied the effect of the stimulus in the char-
acteristics frequency bands. Hence, these measures
reflect changes in α -, β -, θ - or δ - bands. One
of the most popular, simple and reliable measures
is the event related desychronization/synchronization
(ERD/ERS). It represents a relative decrease or in-
crease in the power content in time - intervals defined
after the stimulus onset when compared to a refer-
ence interval defined before the stimulus onset (Kla-
dos et al., 2009). Usually this measure is computed
for the different characteristic bands of the EEG (Kla-
dos et al., 2009).
2 METHODOLOGY
In this work a valence recognition system is pre-
sented. The performance of the system is evalu-
ated for both single subjects (intra-subject) and be-
tween subjects (inter-subject). The feature extraction
is based on ERD/ERS measures computed in short in-
tervals. The subsequent classification stage is based
on an ensemble classifier, i. e. a random forest of tree
classifiers. The feature extraction is performed either
on signals averaged over an ensemble of trials or on
single-trial response signals. Accordingly, the clas-
sification is performed considering the ensemble av-
erage responses of all subjects (inter-subject) or con-
sidering the single-trial responses of single subjects
(intra-subject). Furthermore, feature elimination, ap-
plying a proper importance measure of the classifier,
has been used to identify the most relevant features of
the decision making.
2.1 The Dataset
A total of 26 female volunteers participated in the
study. A total of 21 channels of EEG, positioned
according to the 10 −20 system, and 2 Electroocu-
lograms (EOG) channels (vertical and horizontal)
were sampled at 1kHz and stored. The signals were
recorded while the volunteers were viewing pictures
selected from the IAPS picture repository. A total of
24 high-arousal images, corresponding to an arousal
score s > 6, with positive valences (v = 7.29 ±0.65)
and negative valences (v = 1.47±0.24) were selected.
Each image was presented three times in a pseudo-
random order and each trial lasted 3500ms: during the
first 750ms, a fixation cross was presented, then one
of the images was shown during 500ms, and finally a
black screen followed for a period of 2250ms. The
signals were pre-processed (filtered, eye-movement
corrected, baseline compensated and segmented into
epochs) using the NeuroScan software package. The
single-trial signal length is 950
ms
, with 150
ms
before
the stimulus onset.
2.2 Feature Extraction
The features are extracted from the segmented signals
(either ensemble averaged or single-trial), measuring
the desychronization/synchronization (ERD/ERS) in
four frequency bands. Then the signals are filtered by
four 4th order bandpass Butterworth filters. The four
characteristic pass-bands are defined as: δ −band :
0.5 −4Hz, θ −band : 4 −7Hz, α −band : 8 −12 Hz
and β −band : 13 − 30Hz. The K = 4 filters are
applied following a zero-phase forward and reverse
digital filter methodology not including any transient
(see filtfilt MATLAB function (Mathworks, 2012)).
For each filtered signal, the ERD/ERS is estimated in
I = 9 intervals following the stimulus onset and with
a duration of 150ms and 50% of overlap between con-
secutive intervals. The reference interval corresponds
to the 150ms pre-stimulus period. For each interval,
the ERD/ERS is defined as
f
ik
=
E
rk
−E
ik
E
rk
= 1 −
E
ik
E
rk
i = 1, 2 . . . 9; k = 1, . . . 4
where E
rk
represents the energy within the reference
interval, while E
ik
is the energy in the i −th inter-
val after stimulus in the k −th band. Note that when
E
rk
> E
ik
, the f
ik
is positive otherwise it is negative.
And furthermore notice that the measure has an up-
per bound f
ik
≤ 1 because energy is always a posi-
tive value. In this work, energies E
ik
are computed
by adding up instantaneous energies within each of
the I = 9 intervals of 150ms duration. The energy
E
rk
is estimated in an interval of 150ms duration de-
fined in the pre-stimulus period. Figure 1 represents
the features computed for two ensemble signals of
channel F7 of one subject. In summary, each va-
lence condition can be characterized by f
ikc
, where
i stands for the time interval, k for the characteristic
BIOSIGNALS2013-InternationalConferenceonBio-inspiredSystemsandSignalProcessing
56

0 100 200 300 400 500 600 700
−6
−5
−4
−3
−2
−1
0
1
time(ms)
ERD/ERS− beta
0 100 200 300 400 500 600 700
−6
−5
−4
−3
−2
−1
0
1
timne(ms)
ERD/ERS−alpha
0 100 200 300 400 500 600 700
−1.5
−1
−0.5
0
0.5
1
time(ms)
ERD/ERS−theta
0 100 200 300 400 500 600 700
−1.5
−1
−0.5
0
0.5
1
time(ms)
ERD/ERS−delta
Figure 1: Features in ensemble average signals of F7 channel of one subject: negative valence (⋄) versus positive valence (+).
band and c for the channel. A total of M = I ×K ×C =
9
×
4
×
21
=
756 features is computed for the multi-
channel segments related with one condition. Follow-
ing, the features f
ikc
will be concatenated into a fea-
ture vector with components f
m
, m = 1, . . . , M = 756.
2.3 Random Forest
Random forest is an ensemble classifier where train-
ing is based on bootstrapping techniques. The random
forest algorithm, developed by Breiman (Breiman,
2001), is a set of binary decision trees, each perform-
ing a classification and the final decision is taken by
majority voting. Each tree is grown using a bootstrap
sample from the original data set and each node of the
tree randomly selects a small subset of features for a
split. An optimal split separates the set of samples
of the node into two more homogeneous (pure) sub-
groups with respect to the class of its elements. A
measure for the impurity level is the Gini index. By
considering that ω
c
, c = 1 . . .C are the labels of the
classes, the Gini index of node i is given by
G(i) = 1 −
C
∑
c=1
(P(ω
c
))
2
where the P(ω
c
) is the probability of class ω
c
in
the set of examples that belong to node i. Note that
G(i) = 0 when node i is pure, e.g, if its data set con-
tains only examples of one class. To perform a split,
one feature f
m
is tested f
m
> f
0
on the set of samples
with n elements which is then divided into two groups
(left and right) with n
l
and n
r
elements and the change
in impurity is computed as
△G(i) = G(i) −
(
n
l
n
G(i
l
) +
n
r
n
G(i
r
)
)
The feature and value that results in the largest de-
crease of the Gini index is chosen to perform the split
at node i. Each tree is grown independently using ran-
dom feature selection to decide the splitting test of the
node. The grown trees are not pruned.
The main steps of the algorithm are
1. Given a data set T with N examples, each with
F features. Select the number T of trees, the di-
mension of the subset L < F of features and, the
parameter that controls the size of the tree (it can
be the maximum depth of the tree, the minimum
size of the subset in a node to perform a split).
2. Construct the t = 1 . . . T trees.
(a) Create a training set T
t
with N examples by
sampling with replacement the original data set.
The out-of-bag data set O
t
is formed with the
remaining examples of T not belonging to T
t
.
(b) Perform the split of node i by testing one of the
L = ⌊
√
F⌋ randomly selected features.
(c) Repeat step 2b up to the tree t is complete. All
nodes are terminal nodes (leafs) if the number
n
s
of examples is n
s
≤ 0.1N.
3. Repeat step 2 to grow next tree if t ̸= T .
After training, the importance r
m
of each fea-
ture f
m
in the ensemble of trees can be computed by
adding the values of △G(i) of all nodes i where the
feature f
m
is used to perform a split. Sorting the val-
ues r
m
by decreasing order, it is possible to identify
the relative importance of the features. In this work
T = 500 decision trees were employed.
2.4 Classification and Feature
Elimination
In (Guyon et al., 2002) a recursive feature elimination
scheme is proposed based on the values of the param-
eters of the classifier. In this work a similar strategy
using the variable importance r
m
is applied according
to the following scheme:
1. Initialize: create a set of indices M = {1, 2, . . . M}
relative to the available features and set F ≡ M
2. Organize data set X by forming the feature vectors
with the feature values whose index is in set M
3. Compute the accuracy of the classifier using either
leave-one-out or k-fold cross-validation.
4. Compute the global model of the classifier using
the complete data set X .
5. Compute r
m
of the features set and eliminate from
set M the indices relative to the twenty least rele-
vant features.
FeatureExtractionandClassificationofBiosignals-EmotionValenceDetectionfromEEGSignals
57

6. Update the number of features accordingly, i. e.
F ← F −20
7. Repeat steps 2 to 6 while set M is not empty.
The leave-one-out strategy was followed in the
intra-subject experiments and in inter-subject exper-
iments when the ensemble averages were computed
with all available trials of each subject and each con-
dition. The k-fold cross-validation strategy was used
in inter-subject experiments otherwise. Each fold is
formed with the data of each subject, e.g. the classi-
fier is trained with features extracted from 25 subjects
leaving the data of the remaining subject to estimate
the accuracy.
0 100 200 300 400 500 600 700 800
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
# of removed features
accuracy
Figure 2: The inter-subject accuracy versus feature selec-
tion. Features extracted from Ensemble-average signals
with: + with at least 30 single-trials, ⋄ 10 consecutive
single-trials;∗ of 3 consecutive single-trials ;and O single-
trial signal.
Accuracy is the proportion of true results (either
positive or negative valence) in the test set. The leave-
one-out strategy assumes that only one example of the
data set forms the test set while all the remaining be-
long to the training set. But this training and test pro-
cedure is repeated such that all the elements of the
data set are used as test set. Therefore the accuracy is
the proportion of correct decisions taken by classifier
during the execution of the leave-one-out loop strat-
egy. In the intra-subject study the accuracy can be
estimated as the average of the estimates within each
subject.
3 RESULTS AND DISCUSSION
The system was implemented in MATLAB using also
some facilities of open source software tools like
EEGLAB (Delorme and Makeig, 2004) and the ran-
dom forest package (Jaiantilal, 2010). Considering
feature elimination and the concomitant number of
relevant features, as can be seen from fig. 2 and fig.
3, the accuracy of the classifier improves with a de-
creasing number of relevant features in both an inter-
subject or an intra-subject classification strategy. In
every case, the accuracy achieves 80% when the clas-
sifiers have less than 100 relevant features as input.
3.1 Inter-subject Classification
Figure 2 shows the accuracy versus the number of fea-
tures eliminated. The accuracy was computed with a
leave-one-out strategy and a total of 52 feature vec-
tors were involved. The highest accuracy is achieved
having as input the ensemble average of all trials. An
average accuracy of 79% is achieved if roughly 500
irrelevant features are removed from the input fea-
ture set. The other traces represent the mean accu-
racy when the ensemble averages are computed with
3, 5, 10 consecutive trials for each condition meaning
that the number of feature vectors for each subject is
roughly 24, 14, 6, respectively. Note that the differ-
ences in accuracy between the various cases consid-
ered might not be statistically significant rather ap-
pear as a consequence of the sample size of the test
sets. However notice that the curves follow a similar
trend corroborating the positive effect on the decision
making of eliminating irrelevant features, i. e., dis-
tracting information.
The tables 1 and 2 describe the spatial and tem-
poral location of the relevant selected features when
the input of the classifier is the data set formed by 52
feature vectors. These feature vectors represent the
ensemble average positive and negative response of
all volunteers investigated. Concerning spacial loca-
tions, the largest number of features happens to occur
in the frontal and parietal regions of the brain. Con-
sidering the localization of the response in time, most
of the features display Medium and Long latencies.
These results confirm related brain studies performed
with ensemble average signals (Olofsson et al., 2008).
Table 1: Space Localization of the 36 selected features
within each band: frontal (Fr), central-temporal (CT) and
parietal-occipital (PO).
Channels Beta Alpha Theta Delta Total
Fr. 7 2 4 5 18
CT 6 0 3 0 9
PO 5 2 0 2 9
3.2 Intra-subject Classification
Figure 3 shows the mean accuracy when the classifier
is trained with data of one subject. The features were
extracted from single-trial signals as described before.
The training set for each subject is formed by a total
BIOSIGNALS2013-InternationalConferenceonBio-inspiredSystemsandSignalProcessing
58
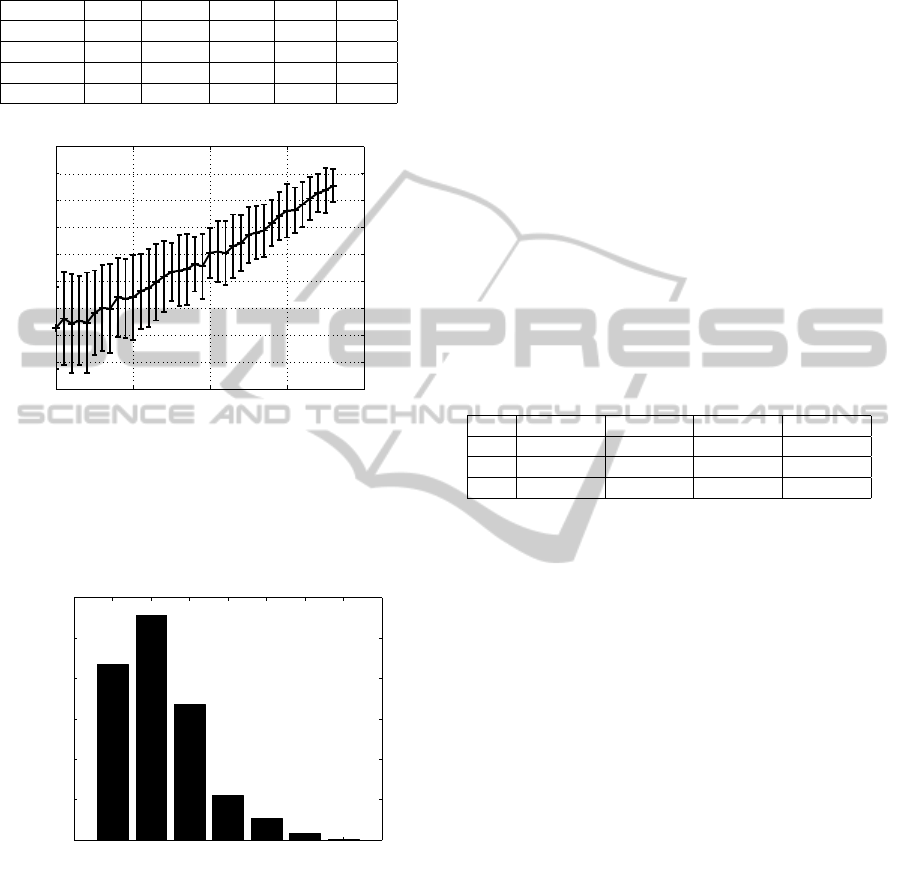
Table 2: Time Localization of the 36 selected features
within each band. Time intervals: Short (i = {1, 2}),
Medium (i = {3, 4}), Long I (i = {5, 6}) and Long II (i =
{7, 8, 9}).
Time Beta Alpha Theta Delta Total
Short 0 1 0 0 1
Medium 6 1 0 2 9
Long I 12 0 1 3 16
Long II 0 2 6 2 10
0 200 400 600 800
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
# number of removed features
accuracy
Figure 3: Average and standard deviation accuracy of intra-
subjects accuracies versus number of features removed. The
last point corresponds to a removal of 720 features.
of 65 −72 single trials for both classes of emotions.
Again a leave-one-out strategy was employed.
0 1 2 3 4 5 6
0
50
100
150
200
250
300
# number of subjects
# number of features
Figure 4: Within the 36 features selected from each indi-
vidual training the histogram counts the number of times a
feature was selected.
A comparison of the outcomes of the individual
training sessions with respect to the features that re-
main after performing the same number of iterations
reveals a large inter-subject variability. Figure 4 dis-
plays this comparison when all individual training
sessions had 36 features as input. It can be seen
that 218 features turn out to be completely irrelevant
and have been eliminated from all classification ses-
sions. Another 275 features appear as relevant fea-
tures for the decision making in one of the subjects
under study. Remarkably, only one feature appears
consistently as a relevant feature in at least 6 out of
26 subjects confirming a high inter-subject variability.
A similar conclusion has been drawn in (Macas et al.,
2009) by using a feature selection block before per-
forming classification. However notice that a compa-
rable accuracy is achieved whether decision making
is based on a set of 52 feature vectors which represent
ensemble averages over trials and subjects or whether
decision making is based on training classifiers indi-
vidually with 65 −72 feature vectors for each subject.
As can be seen in table 3, on average, the most rele-
vant features are appearing again in the frontal region.
Note, however, that this time the parietal-occipital re-
gion seems more relevant than the central-temporal
region.
Table 3: Spatial location versus Frequency: frontal (Fr),
central-temporal (CT) and parietal-occipital (PO). Average
and standard deviation values of number of features within
the 36 selected on each subject.
Ch. Beta Alpha Theta Delta
Fr. 4.6 ±2.9 3.5 ±4.1 2.9 ±2.6 4.0 ±3.1
CT 3.0 ±2.9 2.5 ±2.2 1.2 ±1.6 1.6 ±2.3
PO 2.8 ±2.3 2.8 ±2.7 2.9 ±2.7 4.1 ±3.4
4 CONCLUSIONS
A valence recognition system has been presented and
applied to EEG signals. The latter were recorded from
volunteers subjected to emotional states elicited by vi-
sual stimuli drawn from IAPS repository. The recog-
nition system encompasses a feature extraction stage
and a classification module including feature elimina-
tion. A cohort of 26 female volunteers (age 18 −62
years; mean=24.19; std=10.46) has been investigated.
Feature extraction was based on an inter-subject and
an intra-subject methodology. Both methodologies
showed similar performance with regard to the accu-
racy of the random forest classifier. However from
the related Gini index measuring feature importance
no consistent set of features could be identified sup-
porting the decision making. This points towards a
large biological variability of the set of relevant fea-
tures corresponding to the valence of the emotional
states involved. The classification accuracy achieved
compares well with or is even superior to related sys-
tems reported in literature.
Although inter-subject and intra-subject method-
ologies show a similar performance they yet have
different application scenarios. The inter-subject is
mostly suitable for off-line applications like brain
FeatureExtractionandClassificationofBiosignals-EmotionValenceDetectionfromEEGSignals
59

studies in order to complement the statistical meth-
ods. For instance, in (Hidalgo-Munoz et al., 2012)
an SVM-RFE scheme was applied to identify scalp
spectral dynamics linked with the affective valence
processing. While intra-subject might be interesting
for personalized studies, where subjects need to be
followed over a couple of sessions. Because of the
biologically variability observed intra-subject studies
cannot generalized easily across a cohort of subjects.
ACKNOWLEDGEMENTS
This work is partially funded by FEDER through
the Operational Program Competitiveness Factors -
COMPETE and by National Funds through FCT -
Foundation for Science and Technology in the con-
text of the project FCOMP-01-0124-FEDER-022682
(FCT reference PEst-C/EEI/UI0127/2011). The Fi-
nancial support by the DAAD - FCT is also gratefully
acknowledged.
REFERENCES
Bradley, M. M. and Lang, P. J. (2007). The International Af-
fective Picture System (IAPS) in the Study of Emotion
and Attention. In Bradley, M. M. and Lang, P. J., edi-
tors, Handbook of emotion elicitation and assessment ,
Series in Affective Science, chapter 2, pages 29–46.
Oxford University Press.
Breiman, L. (2001). Random forests. Mach. Learn., 45:5–
32.
Calvo, R. A. and D’Mello, S. (2010). Affect Detection:
An Interdisciplinary Review of Models, Methods, and
Their Applications. IEEE Transactions on Affective
Computing, 1(1):18–37.
Delorme, A. and Makeig, S. (2004). EEGLAB: an open
source toolbox for analysis of single-trial EEG dy-
namics including independent component analysis.
Journal of Neuroscience Methods, 134:9–21.
Frantzidis, C. A., Bratsas, C., Klados, M. A., Konstan-
tinidis, E., Lithari, C. D., Vivas, A. B., Papadelis,
C. L., Kaldoudi, E., Pappas, C., and Bamidis, P. D.
(2010). On the classification of emotional biosig-
nals evoked while viewing affective pictures: An inte-
grated data-mining-based approach for healthcare ap-
plications. Information Technology in Biomedicine,
IEEE Transactions on, 14(2):309–318.
Guyon, I., Weston, J., Barnhill, S., and Vapnik, V. (2002).
Gene selection for cancer classification using support
vector machines. Mach. Learn., 46(1-3):389–422.
Haag, A., Goronzy, S., Schaich, P., and Williams, J. (2004).
Emotion recognition using bio-sensors: First steps to-
wards an automatic system. In Andr
´
e, E., Dybkjæ r,
L., Minker, W., and Heisterkamp, P., editors, Affective
Dialogue Systems, volume i, pages 36–48. Springer.
Hidalgo-Munoz, A., L
´
opez, M., Santos, I., Pereira, A.,
V
´
azquez-Marrufo, M., Galvao-Carmona, A., and
Tom
´
e, A.M. (2012). Application of SVM-RFE on
EEG signals for detecting the most relevant scalp re-
gions linked to affective valence processing. Expert
Systems with Applications, in press(0).
Jaiantilal, A. (2010). http://code.google.com/p/randomforest-
matlab/
Kim, K. H., Bang, S. W., and Kim, S. R. (2004). Emo-
tion recognition system using short-term monitoring
of physiological signals. Medical & Biological Engi-
neering & Computing, 42(3):419–427.
Klados, M. A., Frantzidis, C., Vivas, A. B., Papadelis, C.,
Lithari, C., Pappas, C., and Bamidis, P. D. (2009). A
Framework Combining Delta Event-Related Oscilla-
tions (EROs) and Synchronisation Effects (ERD/ERS)
to Study Emotional Processing. Computational intel-
ligence and neuroscience, 2009:549419.
Lang, P., Bradley, M., and Cuthbert, B. (2008). Interna-
tional affective picture system (IAPS): Affective rat-
ings of pictures and instruction manual.
Macas, M., Vavrecka, M., Gerla, V., and Lhotska, L. (2009).
Classification of the emotional states based on the
EEG signal processing. In 2009 9th International
Conference on Information Technology and Applica-
tions in Biomedicine, number November, pages 1–4.
IEEE.
Mathworks (2012). http://www.mathworks.com/help/signal
/ref/filtfilt.html
Olofsson, J. K., Nordin, S., Sequeira, H., and Polich, J.
(2008). Affective picture processing: an integra-
tive review of ERP findings. Biological Psychology,
77(3):247–265.
Picard, R. W., Vyzas, E., and Healey, J. (2001). Toward
machine emotional intelligence: analysis of affec-
tive physiological state. IEEE Transactions on Pat-
tern Analysis and Machine Intelligence, 23(10):1175–
1191.
Russell, J. A. (1980). A circumplex model of affect. Journal
of Personality and Social Psychology, 39(6):1161–
1178.
Schaaff, K. and Schultz, T. (2009). Towards emotion recog-
nition from electroencephalographic signals. In 2009
3rd International Conference on Affective Computing
and Intelligent Interaction and Workshops, pages 1–6.
IEEE.
BIOSIGNALS2013-InternationalConferenceonBio-inspiredSystemsandSignalProcessing
60
