
Explaining Unintelligible Words by Means of their Context
Bal
´
azs Pint
´
er, Gyula V
¨
or
¨
os, Zolt
´
an Szab
´
o and Andr
´
as L
˝
orincz
Faculty of Informatics, E
¨
otv
¨
os Lor
´
and University, P
´
azm
´
any P. s
´
et
´
any 1/C, H-1117 Budapest, Hungary
Keywords:
Unintelligible Words, Wikification, Link Disambiguation, Natural Language Processing, Structured Sparse
Coding.
Abstract:
Explaining unintelligible words is a practical problem for text obtained by optical character recognition, from
the Web (e.g., because of misspellings), etc. Approaches to wikification, to enriching text by linking words to
Wikipedia articles, could help solve this problem. However, existing methods for wikification assume that the
text is correct, so they are not capable of wikifying erroneous text. Because of errors, the problem of disam-
biguation (identifying the appropriate article to link to) becomes large-scale: as the word to be disambiguated
is unknown, the article to link to has to be selected from among hundreds, maybe thousands of candidate
articles. Existing approaches for the case where the word is known build upon the distributional hypothesis:
words that occur in the same contexts tend to have similar meanings. The increased number of candidate
articles makes the difficulty of spuriously similar contexts (when two contexts are similar but belong to dif-
ferent articles) more severe. We propose a method to overcome this difficulty by combining the distributional
hypothesis with structured sparsity, a rapidly expanding area of research. Empirically, our approach based on
structured sparsity compares favorably to various traditional classification methods.
1 INTRODUCTION
Many common types of errors can occur in free text
that produce unintelligible words. A word may be
misspelled. Errors can be introduced by Optical Char-
acter Recognition (OCR) because of imperfect scans
or errors committed by the algorithm. Automatic
speech recognition can also introduce errors. Explain-
ing these unintelligible words with Wikipedia articles
could help users and computer algorithms alike to un-
derstand them.
Enriching text documents with links to Wikipedia
articles, wikification, has been in the focus of much
attention recently. Starting from the work of (Mihal-
cea and Csomai, 2007) wikification consists of two
phases: link detection and link disambiguation. The
detection phase identifies the terms and phrases from
which links should be made. The disambiguation
phase identifies the appropriate article for each de-
tected term to link to. For example, the term bank
could link to an article about financial institutions, or
river banks.
We consider link disambiguation as our starting
point to approach explaining unintelligible words.
The words to be disambiguated are assumed given:
they are the erroneous words in the text. They can be
selected by the user, or detected automatically by
methods such as (Kukich, 1992; Leacock et al., 2010).
Current approaches to link disambiguation do not
handle text with errors because of a tacit assump-
tion: the disambiguation of different word types
1
are
treated as independent problems. This constraint is
essential to reduce the complexity of the disambigua-
tion problem: without it, the article the target word
2
will link to has to be selected from among hundreds,
maybe thousands of candidate articles. If an error
makes the surface form
3
of the target word unusable,
the problem cannot be decomposed to disambiguation
on different word types: the vast number of candidate
articles yields a large-scale problem. Due to the large
scale, an additional difficulty appears.
Typical methods to disambiguate known target
words apply the distributional hypothesis. Accord-
ing to the distributional hypothesis, words that occur
in the same contexts tend to have similar meanings
(Harris, 1954). Because the disambiguation problem
with unknown target words is intrinsically large-scale,
exceptions to the distributional hypothesis can occur
1
In “A rose is a rose is a rose”, there are three word types
(a, rose, is), but eight word tokens.
2
The word to be explained with a Wikipedia article.
3
The form of a word as it appears in the text.
382
Pintér B., Vörös G., Szabó Z. and Lõrincz A. (2013).
Explaining Unintelligible Words by Means of their Context.
In Proceedings of the 2nd International Conference on Pattern Recognition Applications and Methods, pages 382-387
DOI: 10.5220/0004267003820387
Copyright
c
SciTePress

more frequently. Particularly, let us call two contexts
spuriously similar if they are similar but belong to dif-
ferent articles. The amount of spuriously similar con-
texts tends to increase inherently with the number of
candidate articles. This makes the learning problem
considerably hard.
In this paper, we propose a method to explain
unintelligible words with Wikipedia articles that ad-
dresses this problem by using the distributional hy-
pothesis in a novel way. Structured sparse coding
(Bach et al., 2012) is introduced to diminish the ef-
fect of spurious similarities of contexts by utilizing
the structure of semantic space (Section 3).
The contributions of the paper are summarized as
follows: (i) we propose a method to disambiguate un-
intelligible words to Wikipedia articles. (ii) We show
that structured sparsity reduces the effect of spurious
similarities of contexts. (iii) We perform large-scale
evaluations where we disambiguate from among 1000
Wikipedia articles at once.
In the next section we review related work. Our
method and results are described in Section 3 and 4.
We discuss our results in Section 5 and conclude in
Section 6.
2 RELATED WORK
The main difference between previous methods in the
literature and ours is that they consider the disam-
biguation problems of different word types indepen-
dently. In our case, as the word type is unintelligible,
this would be unfeasible.
(Mihalcea and Csomai, 2007) introduced the con-
cept of wikification: they proposed a method to auto-
matically enrich text with links to Wikipedia articles.
They used keyword extraction to detect the most im-
portant terms in the text, and disambiguated them to
Wikipedia articles with supervised learning using the
contexts. The same task was solved in (Milne and
Witten, 2008) more efficiently. Here, contexts were
taken into account also for the detection phase. Dis-
ambiguation was done using sense commonness and
sense relatedness scores.
Unlike the previously mentioned works, which in-
troduce links to important terms in the text to achieve
better readability, the goal of (Kulkarni et al., 2009)
was to add as many links as possible to help index-
ing for information retrieval. The terms were disam-
biguated by assuming that coherent documents refer
to entities from one or a few related topics or domains.
(Ratinov et al., 2011) proposed a similar disambigua-
tion system called GLOW (global wikification), which
used several local and global features to obtain a set
of disambiguations that are coherent in the whole text.
In information retrieval and speech recognition,
unintelligible words pose a practical problem. The
TREC-5 confusion track (Kantor and Voorhees, 2000)
studied the impact of data corruption introduced by
scanning or OCR errors on retrieval performance.
In the subsequent spoken document retrieval tracks
(Garofolo et al., 2000), the errors were introduced by
automatic speech recognition.
Structured sparsity has been successfully applied
to natural language processing problems different
from ours in works such as (Jenatton et al., 2011) and
(Martins et al., 2011). (Jenatton et al., 2011) apply
sparse hierarchical dictionary learning to learn hierar-
chies of topics from a corpora of NIPS proceedings
papers. In a more recent application (Martins et al.,
2011), structured sparsity was used to perform effec-
tive feature template selection on three natural lan-
guage processing tasks (chunking, entity recognition,
and dependency parsing).
3 THE METHOD
We start from a list of candidate articles the unintel-
ligible word could be linked to. For each candidate
article, we collect a number of contexts. A context
of a candidate article consists of the N non-stopword
words occurring before and after the anchor of the
link that points to the article. There can be at most
2N words in a context.
The presented method makes use of a collection
of such contexts arranged in a word-context matrix
D (Turney and Pantel, 2010) (Figure 1). In this ma-
trix, each context is a column represented as a bag-of-
words vector v of word frequencies, where v
i
is the
number of occurrences of the ith word in the context.
The article is determined in two steps. First, we
formulate an inverse problem, and compute a repre-
sentation vector α
α
α. In the second step, a single can-
didate article is selected based on the weights in this
vector.
To compute the representation vector α
α
α, the con-
text x ∈ R
m
of the target word is approximated lin-
early with the columns of the word-context matrix
D = [d
1
, d
2
, . . . , d
n
] ∈ R
m×n
, called the dictionary in
the terminology of sparse coding. The columns of
the dictionary contain contexts, each labeled with the
candidate article l
i
∈ L the context was collected for.
Please note that multiple contexts can be, and in many
cases are, tagged with the same candidate article:
l
i
= l
j
is possible. There are m words in the vocab-
ulary, and n contexts in the dictionary.
ExplainingUnintelligibleWordsbyMeansoftheirContext
383

computer
leg
shoe
modern
Boot Foot
Booting
0
1
0
0
0
0
2
1
0
0
0
0
0
1
1
1
0
0
0
0
0
1
0
0
0
3
0
0
0
0
1
1
1
0
0
0
0
0
0
1
2
0
0
2
1
0
0
1
...
...
Figure 1: The word-context matrix D. Each column is a context of a candidate article (e.g., Boot, Foot). Each element D
i j
of
the matrix holds the number of occurences of the ith word in the jth context. For example, the word leg occurs three times in
the 7th context, which is the 3rd context labeled with Foot.
The representation vector α
α
α consists of the coeffi-
cients of a linear combination
x = α
1
d
1
+ α
2
d
2
+ . . . + α
n
d
n
. (1)
For each target word, whose context is x ∈ R
m
, a rep-
resentation vector α
α
α = [α
1
;α
2
;. . . ;α
n
] ∈ R
n
is com-
puted.
To diminish the effect of spurious similarities, we
introduce a structured sparsity inducing regularization
by organizing the contexts in D into groups. Each
group contains the contexts annotated with a single
candidate article. As only a single candidate is se-
lected for each target word, ideally only a single
group should be active in each representation vector
α
α
α. Sparsity on the groups is realized by computing α
α
α
with a group Lasso regularization (Yuan et al., 2006)
determined by the labels.
The groups are introduced as a family of sets
G = {G
l
}
l∈L
⊆ 2
{1,...,n}
. There are as many sets in G
as there are distinct candidate articles in L. For each
article l ∈ L, there is exactly one set G
l
∈ G that con-
tains the indices of all the columns d
i
tagged with l.
G forms a partition.
The representation vector α
α
α of the target word
whose context is x is defined as the minimum of the
loss function
min
α
α
α∈R
n
1
2
∥x − Dα
α
α∥
2
2
+ λ
∑
l∈L
w
l
||α
α
α
G
l
||
2
, (2)
where α
α
α
G
l
∈ R
|G
l
|
denotes the vector where only the
coordinates present in the set G
l
⊆ {1, . . . , n} are re-
tained.
The first term is the approximation error, the sec-
ond one realizes the structured sparsity inducing reg-
ularization. Parameter λ > 0 controls the tradeoff be-
tween the two terms. The parameters w
l
> 0 denote
the weights for each group G
l
.
If each group is a singleton (i.e., G =
{{1}, {2}, . . . , {n}}) the Lasso problem (Tibshi-
rani, 1994) is recovered:
min
α
α
α∈R
n
1
2
∥x − Dα
α
α∥
2
2
+ λ
n
∑
i=1
w
i
|α
i
|. (3)
Setting λ = 0 yields the least squares cost function.
For the sake of simplicity, we represent each can-
didate article with the same number of contexts: there
are an equal number of columns in D for each label
l ∈ L (|G
1
| = |G
2
| = ·· · = |G
|L|
|). The weights w
l
of
the groups are set to 1.
In the second step, the link is disambiguated to a
single article based on the weights in this vector. We
utilize the group structure to condense the vector α
α
α
to a single article. The weights are summed in each
group G
l
∈ G, and the article l
∗
∈ L whose group con-
tains the most weight is selected:
l
∗
= arg max
l∈L
∑
i
(α
α
α
G
l
)
i
.
In this group Lasso formulation, whole groups are
selected. Each group G
l
∈ G contains contexts tagged
with the same candidate article l ∈ L, and only a few
groups can be selected. A context similar to the con-
text of the target word, x, only by accident has a
smaller chance to be selected: as it is in a group la-
beled with a candidate article that is less related in
meaning to the target word than the correct candidate,
its group contains mainly contexts less similar to x.
Therefore, errors introduced by spurious similarities
of contexts can be effectively diminished (Section 4).
4 RESULTS
To evaluate the method, we solve the disambiguation
task of wikification, with a significant difference: we
assume that the surface form of the target word is un-
known.
ICPRAM2013-InternationalConferenceonPatternRecognitionApplicationsandMethods
384

4.1 The Datasets
The datasets used in our experiments are obtained
by randomly sampling the links in Wikipedia. Each
dataset consists of contexts labeled with candidate ar-
ticles (c
1
, l
1
), (c
2
, l
2
), . . . . Each labeled context is ob-
tained by processing a link: the bag-of-words vector
generated from the context of the anchor text is anno-
tated with the target of the link.
We use the English Wikipedia database dump
from October 2010
4
. Disambiguation pages, and ar-
ticles that are too small to be relevant (i.e., have less
than 200 non-stopwords in their texts, or less than 20
incoming and 20 outgoing links) are discarded. In-
flected words are reduced to root forms by the Porter
stemming algorithm (Porter, 1997).
To produce a dataset, a list of anchor texts are gen-
erated that match a number of criteria. These criteria
have been chosen to obtain (i) words that are frequent
enough to be suitable training examples and (ii) are
proper English words. The anchor text has to be a
single word between 3 and 20 characters long, must
consist of the letters of the English alphabet, must
be present in Wikipedia at least 100 times, and must
point to at least two different Wikipedia articles, but
not to more than 20. It has to occur at least once in
WordNet (Miller, 1995) and at least three times in the
British National Corpus (BNC Consortium, 2001).
A number of anchor texts are selected from this
list randomly, and their linked occurrences are col-
lected along with their N-wide contexts. Each link is
processed to obtain a labeled context (c
i
, l
i
).
To ensure that there are an equal number of con-
texts tagged with each article l ∈ L, d randomly se-
lected contexts are collected for each label. Labels
with less than d contexts are discarded. We do not
perform feature selection, but we remove the words
that appear less than five times across all contexts, in
order to discard very rare words.
4.2 Evaluations
The task we proposed is a disambiguation problem
where the algorithm has to decide between all candi-
date articles at once, because the surface form of the
target word is not available. Given a context x ∈ R
m
of
a word, the goal is to determine the appropriate candi-
date article l ∈ L. The performance of the algorithms
is measured as the accuracy of this classification.
We compare our group Lasso based method to
three baselines: two different regularizations (least
squares and the Lasso) of the inverse problem de-
scribed in Section 3, and a Support Vector Machine
4
Downloaded from http://dumps.wikimedia.org/enwiki/.
(SVM). The SVM is a multiclass Support Vector Ma-
chine with a linear kernel, used successfully for wik-
ification in previous works (Milne and Witten, 2008;
Ratinov et al., 2011).
10 20 30 40 50
0.35
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
accuracy vs d, |L| = 500
d
accuracy
Group Lasso
Support Vector Machine
Lasso
Figure 2: Dependency of the accuracy on the number of
contexts per candidate article. There are d − 1 such con-
texts in each step of the cross-validation, as there is one test
example for each article. The data points are the mean of
values obtained on the five datasets. The error bars denote
the standard deviations. The results of least squares are not
illustrated as the standard deviations were very large. It per-
forms consistently below the Lasso.
For least squares and the Lasso, the link is disam-
biguated to the article that corresponds to the largest
coefficient in α
α
α. For the SVM, a classification prob-
lem is solved using the labeled contexts (c
i
, l
i
) as
training and test examples.
The minimization problems of both the Lasso and
the group Lasso (Eq. 2) are solved by the Sparse
Learning with Efficient Projections (SLEP) package
(Liu et al., 2009). For the support vector machine, we
use the implementation of LIBSVM (Chang and Lin,
2001).
The algorithms are evaluated on five disjoint
datasets generated from Wikipedia (Section 4.1), each
with different candidate articles. The mean and
standard deviation of the accuracy across these five
datasets are reported.
There are |L| = 1000 different articles in each
dataset, and d = 50 contexts tagged with each article.
The algorithms are evaluated on datasets of different
sizes (i.e., d and |L| are different), generated from the
original five datasets by removing contexts and their
labels randomly .
In accord with (Lee and Ng, 2002; Sch
¨
utze, 1998),
and others, we use a broad context, N = 20. We found
that a broad context improves the performance of all
four algorithms.
Before evaluating the algorithms, we examined
the effect of their parameters on the results. We
ExplainingUnintelligibleWordsbyMeansoftheirContext
385
100 200 300 400 500 600 700 800 900 1000
0.35
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
accuracy vs |L|, d = 10
number of candidate articles (|L|)
accuracy
Group Lasso
Support Vector Machine
Lasso
(a)
100 200 300 400 500 600 700 800 900 1000
0.35
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
accuracy vs |L|, d = 20
number of candidate articles (|L|)
accuracy
Group Lasso
Support Vector Machine
Lasso
(b)
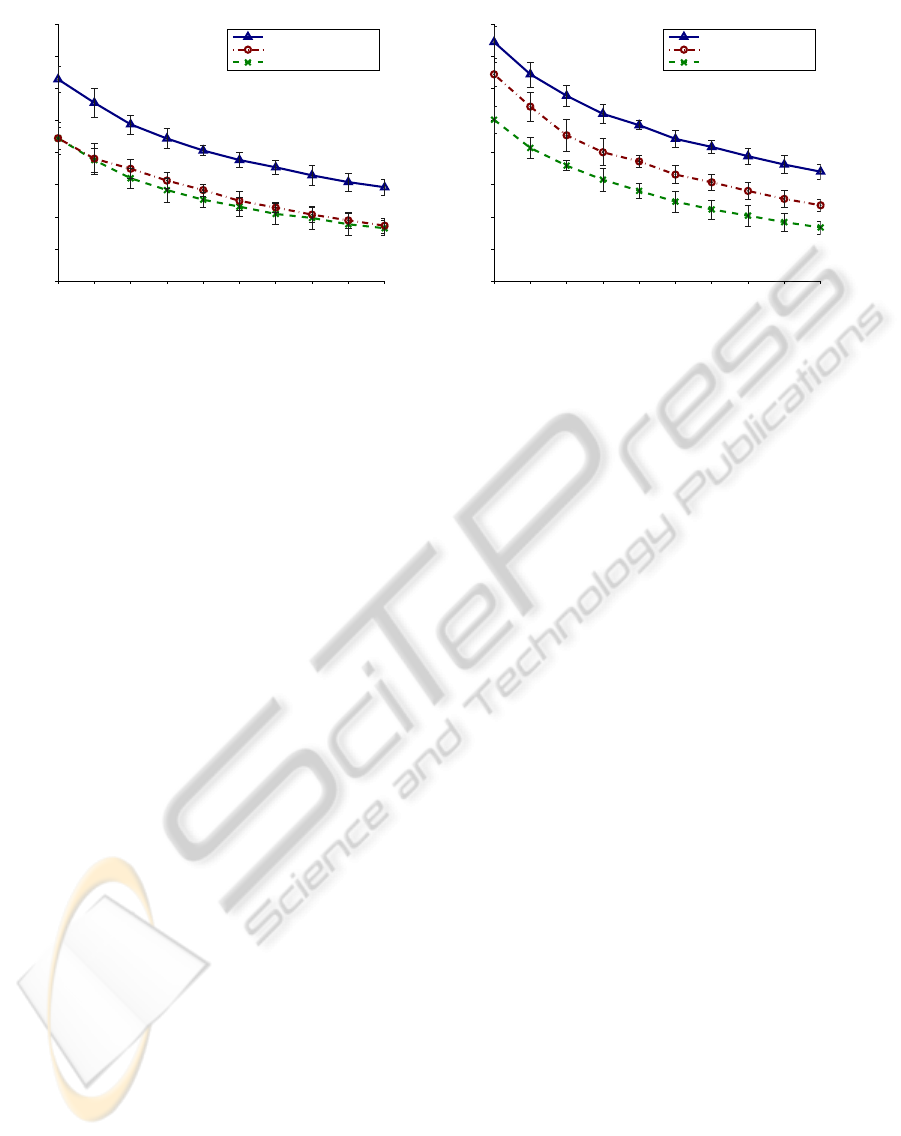
Figure 3: Dependency of the accuracy on the number of candidate articles, |L|. The data points are the mean of values
obtained on the five datasets. The error bars denote the standard deviations. The results of least squares are not illustrated, as
the standard deviations were very large. It performs consistently below the Lasso.
found that the algorithms are robust: for the Lasso,
λ = 0.005, for the group Lasso, λ = 0.05, and for the
SVM, C = 1 was optimal in almost every validation
experiment.
In the first evaluation, we examine the effect of
the number of training examples per candidate arti-
cle on the accuracy of the four algorithms. The start-
ing datasets consist of |L| = 500 articles with d = 10
contexts (or examples) each. Stratified 10-fold cross-
validation is used to determine the accuracy of the
classification. The dataset is partitioned into 10 sub-
sets (the same as d), where each subset contains ex-
actly |L| examples – one annotated with each article.
In one iteration, one subset is used for testing, and the
other 9 subsets form the columns of D: there are |L |
test examples and n = (d −1)|L| columns in D in each
iteration. For the SVM, the columns of D are used as
training examples.
To examine the effect of additional contexts, we
add contexts to D for each candidate article, and ex-
amine the change in accuracy. In order to evaluate the
effect correctly (i.e., to not make the learning problem
harder), the test examples remain the same as with
d = 10. In other words, we perform the same cross-
validation as before, only we add additional columns
to D in each step. In Figure 2, we report the results
for d = 10, 20, 30, 40, 50.
In the second evaluation, the accuracy of the algo-
rithms is examined as the number of candidate articles
|L| increases. As in the first evaluation, there are d =
10 examples per candidate article, and stratified 10-
fold cross-validation is performed. Then, the number
of examples is raised to d = 20 in the same way (i.e.,
the new examples are not added to the test examples).
We report the results for |L| = 100, 200, . . . , 1000 can-
didate articles in Figure 3.
5 DISCUSSION
The results are very consistent across the five disjoint
datasets, except in the case when the representation
vector was computed with least squares. The perfor-
mance of least squares was the worst of the four algo-
rithms, and it was so erratic that we did not plot it in
order to keep the figure uncluttered.
For group Lasso and the SVM, additional train-
ing examples help up to 20 examples per article (Fig-
ure 2), but only small gains can be achieved by adding
more than 20 examples.
In sharp contrast, the Lasso-based representation
does not benefit from new training examples at all
when there are many candidate articles. This may be
the effect of spurious similarities. As more and more
candidate articles are added, the less chance Lasso has
to select the right article from among the candidates.
Representation vectors computed with structured
sparsity inducing regularization significantly outper-
form the other methods, including SVM (Figure 3).
This illustrates the efficiency of our method: struc-
tured sparsity decreases the chance of selecting con-
texts spuriously similar to the context of the target
word.
6 CONCLUSIONS
We proposed a method to explain unintelligible words
with Wikipedia articles. In addition to explaining un-
ICPRAM2013-InternationalConferenceonPatternRecognitionApplicationsandMethods
386

intelligible words, the method can also be used to
help wikify possibly erroneous text from real-world
sources such as the Web, optical character recogni-
tion, or speech recognition. The numerical evalu-
ations demonstrated that the method works consis-
tently even in large-scale experiments, when disam-
biguating between up to 1000 Wikipedia articles.
A possible future application of the presented
method is the verification of links to Wikipedia. The
method can assign a single weight to each candidate
article: the sum of the weights in its group in the rep-
resentation vector α
α
α. If the weight corresponding to
the target of the link is small in contrast to weights of
other articles, the link is probably incorrect.
The presented method can be generalized, as it
can work with arbitrarily labeled text fragments as
well as contexts of Wikipedia links. This more gen-
eral framework may have further applications, as the
idea of distributional similarity offers solutions to
many natural language processing problems. For ex-
ample, topics might be assigned to documents as
in centroid-based document classification (Han and
Karypis, 2000).
ACKNOWLEDGEMENTS
The research has been supported by the ‘European
Robotic Surgery’ EC FP7 grant (no.: 288233). Any
opinions, findings and conclusions or recommenda-
tions expressed in this material are those of the au-
thors and do not necessarily reflect the views of other
members of the consortium or the European Commis-
sion.
REFERENCES
Bach, F., Jenatton, R., Mairal, J., and Obozinski, G. (2012).
Optimization with sparsity-inducing penalties. Foun-
dations and Trends in Machine Learning, 4(1):1–106.
BNC Consortium (2001). The British National Corpus, ver-
sion 2 (BNC World).
Chang, C.-C. and Lin, C.-J. (2001). LIBSVM: a library for
support vector machines.
Garofolo, J. S., Auzanne, C. G. P., and Voorhees, E. M.
(2000). The TREC Spoken Document Retrieval
Track: A Success Story. In RIAO, pages 1–20.
Han, E.-H. and Karypis, G. (2000). Centroid-based doc-
ument classification: Analysis and experimental re-
sults. In PKDD, pages 116–123.
Harris, Z. (1954). Distributional structure. Word,
10(23):146–162.
Jenatton, R., Mairal, J., Obozinski, G., and Bach, F.
(2011). Proximal methods for hierarchical sparse cod-
ing. Journal of Machine Learning Research, 12:2297–
2334.
Kantor, P. B. and Voorhees, E. M. (2000). The TREC-5
Confusion Track: Comparing Retrieval Methods for
Scanned Text. Information Retrieval, 2:165–176.
Kukich, K. (1992). Techniques for automatically correcting
words in text. ACM Computing Surveys, 24(4):377–
439.
Kulkarni, S., Singh, A., Ramakrishnan, G., and
Chakrabarti, S. (2009). Collective annotation of
Wikipedia entities in web text. In KDD, pages 457–
466.
Leacock, C., Chodorow, M., Gamon, M., and Tetreault, J.
(2010). Automated Grammatical Error Detection for
Language Learners. Synthesis Lectures on Human
Language Technologies. Morgan & Claypool Publish-
ers.
Lee, Y. K. and Ng, H. T. (2002). An empirical evaluation of
knowledge sources and learning algorithms for word
sense disambiguation. In EMNLP, pages 41–48.
Liu, J., Ji, S., and Ye, J. (2009). SLEP: Sparse Learning
with Efficient Projections. Arizona State University.
Martins, A. F. T., Smith, N. A., Aguiar, P. M. Q., and
Figueiredo, M. A. T. (2011). Structured Sparsity in
Structured Prediction. In EMNLP, pages 1500–1511.
Mihalcea, R. and Csomai, A. (2007). Wikify!: linking doc-
uments to encyclopedic knowledge. In CIKM, pages
233–242.
Miller, G. A. (1995). WordNet: A lexical database for En-
glish. Communications of the ACM, 38:39–41.
Milne, D. and Witten, I. H. (2008). Learning to link with
Wikipedia. In CIKM, pages 509–518.
Porter, M. F. (1997). An algorithm for suffix stripping, pages
313–316. Morgan Kaufmann Publishers Inc.
Ratinov, L., Roth, D., Downey, D., and Anderson, M.
(2011). Local and global algorithms for disambigua-
tion to Wikipedia. In ACL-HLT, pages 1375–1384.
Sch
¨
utze, H. (1998). Automatic word sense discrimination.
Computational Linguistics, 24(1):97–123.
Tibshirani, R. (1994). Regression shrinkage and selection
via the lasso. Journal of the Royal Statistical Society,
Series B, 58:267–288.
Turney, P. D. and Pantel, P. (2010). From frequency to
meaning: vector space models of semantics. Journal
of Artificial Intelligence Research, 37(1):141–188.
Yuan, M., Yuan, M., Lin, Y., and Lin, Y. (2006). Model
selection and estimation in regression with grouped
variables. Journal of the Royal Statistical Society, Se-
ries B, 68:49–67.
ExplainingUnintelligibleWordsbyMeansoftheirContext
387
