
iRep3D: Efficient Semantic 3D Scene Retrieval
Xiaoqi Cao and Matthias Klusch
German Research Center for Artificial Intelligence, Saarbr
¨
ucken, Germany
Keywords:
Semantic 3D Scene Retrieval, Semantic Indexing.
Abstract:
In this paper, we present a new repository, called iRep3D, for efficient retrieval of semantically annotated
3D scenes in XML3D, X3D or COLLADA. The semantics of a 3D scene can be described by means of
its annotations with concepts and services which are defined in appropriate OWL2 ontologies. The iRep3D
repository indexes annotated scenes with respect to these annotations and geometric features in three different
scene indices. For concept and service-based scene indexing iRep3D utilizes a new approximated logical
subsumption-based measure while the geometric feature-based indexing adheres to the standard specifications
of XML-based 3D scene graph models. Each query for 3D scenes is processed by iRep3D in these indices in
parallel and answered with the top-k relevant scenes of the final aggregation of the resulting rank lists. Results
of experimental performance evaluation over a preliminary test collection of more than 600 X3D and XML3D
scenes shows that iRep3D can significantly outperform both semantic-driven multimedia retrieval systems
FB3D and RIR, as well as the non-semantic-based 3D model repository ADL in terms of precision and with
reasonable response time in average.
1 INTRODUCTION
For the success of 3D Web applications in many
domains like virtual 3D product engineering both a
highly precise and reasonably fast retrieval of rele-
vant 3D scenes modelled in X3D
1
, XML3D
2
or COL-
LADA
3
is of paramount importance. Research on ef-
ficient retrieval of semantically annotated 3D scenes
gained momentum in the past years. For example,
the ISReal platform for intelligent and web-based 3D
simulation of realities (Kapahnke et al., 2010) allows
users to annotate XML3D scene objects with descrip-
tions of their conceptual meaning and functional be-
havior with formal concepts, services and hybrid au-
tomata, and leverages these hybrid semantic annota-
tions for simulations of virtual 3D worlds with in-
telligent avatars. Current scene retrieval systems like
FB3D (Camossi et al., 2007), RIR (Alvez and Vecchi-
etti, 2011) and the open-source 3D repository ADL
4
leverage in particular advanced methods of matching
textual descriptions, geometric features and RDF
5
-
based semantic annotations of 3D scenes.
However, syntactic-based 3D scene retrieval ap-
1
http://www.web3d.org/x3d/
2
http://www.xml3d.org/
3
https://collada.org/
4
http://3dr.adlnet.gov/Default.aspx
5
http://www.w3.org/RDF/
proaches (Gao et al., 2011; Gong et al., 2011; Leif-
man et al., 2005; Hou et al., ; Koutsoudis et al., 2011;
Qi et al., 2011) offer fairly fast response times in av-
erage but almost always suffer from a relatively low
average precision due to syntactic mismatches. Alter-
natively, current RDF(Laborie et al., 2009; Alvez and
Vecchietti, 2011) and strict logic-based approaches
of 3D scene retrieval(Kalogerakis et al., 2006; Hois
et al., 2007a; Hois et al., 2007b; Pittarello and
De Faveri, 2006; Yang, 2010) were shown to be ca-
pable of alleviating this problem to some extent but at
the cost of higher response times and without consid-
ering 3D scenes geometric features.
In iRep3D, an annotated 3D scene in XML3D,
X3D or COLLADA is indexed not only with respect
to its geometric features but referenced concepts and
services which formally describe the conceptual and
functional semantics of the scene in standard OWL2.
The semantic indexing of scenes utilizes, in particu-
lar, a new approximated concept similarity measure
based on weighted logical abduction, while B+ tree-
based scene indices are built for geometric features
of scenes. A query for top-k relevant 3D scenes is
processed by iRep3D in its three scene indices for
concepts, services, and geometric features in parallel.
The resulting scene relevance rank lists are then ag-
gregated with Fagin’s threshold algorithm (TA) (Fa-
gin, 2002) before the final answer set to the query is
19
Cao X. and Klusch M..
iRep3D: Efficient Semantic 3D Scene Retrieval.
DOI: 10.5220/0004295600190028
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2013), pages 19-28
ISBN: 978-989-8565-48-8
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

returned to the user.
The remainder of the paper is structured as fol-
lows: Semantic annotations of 3D scenes and cor-
responding scene indices are described in section 2
while the hybrid semantic retrieval by iRep3D is ex-
plained in section 3. Results of experimental perfor-
mance evaluation and related work are presented in
sections 4 and 5. We conclude the paper in section 6.
2 SEMANTIC SCENE
ANNOTATION AND INDICES
The annotation of 3D scene graphs in X3D, XML3D,
or COLLADA with concepts, services, and geo-
metric features can be embedded in the respective
XHTML files with standard RDFa. Inspired by (Ka-
pahnke et al., 2010), iRep3D leverages such machine-
understandable descriptions of conceptual, functional
or behavior-based, and geometric feature-based scene
semantics for a more informed retrieval of relevant
3D scenes. In the following, we introduce the differ-
ent kinds of annotations and corresponding scene in-
dices which are created by iRep3D off line for a given
collection of annotated 3D scenes.
2.1 3D Scene Annotation and Query
A simple example of an annotated X3D scene named
Toledo Car 001 of a special car model is shown
in figure 1. The scene annotation includes a scene
concept ”Toledo”, a semantic service ”transport”, and
the color of the car as one of its geometric features.
In addition, a free-text description of this 3D scene
model is given in its meta-tag. As stated above, the
semantic annotations can be embedded with standard
RDFa in any XML-based 3D scene description.
Annotation with Scene Concepts. For example, the
scene concept ”Toledo” describes the overall seman-
tics of the 3D scene of the respective car model. In
the figure the concept is shown together with its log-
ical expression which is derived by iRep3D from the
formal definition of this concept in a referenced on-
tology in standard OWL2. Such concept expressions
contain only logical operators (conjunction u, nega-
tion ¬) and quantifiers (universal ∀, exists ∃) over a
set of primitive concepts or terms (·
P
). For exam-
ple, the logical expression of scene concept ”Toledo”’
contains the primitive concepts Vehicle
P
and Car
P
as well as quantified and cardinality restricted (prim-
itive) roles in the clauses ∀canCarry.Passenger
P
,
¬∀onwership.Private
P
and = 4hasW heels.W heel
P
.
Figure 1: Annotated X3D model Toledo Car 001.
For the sake of simplicity, in the following we as-
sume ontologies O and O
S
in OWL2-DL which are
used by 3D scene designers or third-party users for
semantic annotation of 3D scenes stored in a given
iRep3D repository with concepts and services, and an
ontology O
req
for scene requests. The set of primitive
terms is the shared basic minimal vocabulary of these
ontologies out of which more complex concepts can
be individually defined.
Definition 1: Annotated 3D Scene
Let X the set of 3D scenes stored in an iRep3D
repository r, O the 3D scene concept ontology. A
3D scene x ∈ X is defined by the tuple: x = [id, sd,
τ(C, O), SS, GF, da] where id denotes the UUID
of x; sd the (syntactic, textual) description of the
meaning of x; τ(C, O) the logical unfolding of the
scene concept C of x in the scene concept ontology
O in OWL2-DL; SS the set of semantic services in
OWL-S provided by x (cf. Def. 2); GF the set of
geometric features of x (cf. Def. 3); and da the data
of scene x including the XML-based description file
and its referenced resources like images, animations,
sounds.
Annotation with Semantic Services. The function-
ality of 3D scene objects like the transport of passen-
gers and goods by a car, or the opening or closing
of its doors can be described in terms of appropri-
ate services which semantics are formally defined in
OWL-S
6
. A semantic service profile (IOPE) describes
the semantics of service signature (I/O) parameters
in terms of an appropriate conjunctive list of (I/O)
concepts defined in OWL2-DL. In addition, the pre-
6
http://www.w3.org/Submission/OWL-S/
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
20

condition (P) and effect (E) of the service execution
is described in terms of logical expressions in stan-
dard PDDL. Each semantic service of a 3D scene is
grounded in an executable service program such as a
3D animation script (Kapahnke et al., 2010).
For example, the functionality of the car model
Toledo Car 001 in figure 1 is partly described in
the profile of the semantic service ”transport” with
the concepts Passenger, Location of the service (pro-
gram) input variables pg,lc which semantics are de-
fined in a referenced OWL2 ontology. In addition, the
service precondition requires that the car should be
available for the Passenger and the Location should
be reachable, while the effect at(psg, lc) of executing
this transport service means that the Passenger even-
tually will be at the given Location. There is a variety
of tools for efficient selection of semantic services for
a given service request available (Klusch, 2012) like
the currently most precise service matchmaker iSeM
(Klusch and Kapahnke, 2012).
Definition 2: Semantic Services of a 3D Scene
A semantic service ss ∈ x.SS of an annotated 3D
scene x ∈ X is defined by the tuple: ss = [URI, In,
Out, Prec, E f f ] where U RI denotes the URI of the
service description file of ss in OWL-S; In (Out)
the set of input (output) parameter concepts of ss
in OWL2-DL; Prec (E f f ) the logical expression of
the precondition (effect) of ss in PDDL or SWRL.
The concepts in In, Out, Prec and E f f are defined
in a service parameter ontology O
sp
. For sake of
simplicity, without loss of generality, we assume
one O
sp
for all semantic services of 3D scenes
x ∈ X stored in the considered iRep3D repository.
Denote A
s
the set of predicates that are used in the
services of any 3D scene x ∈ X . Let ss.In, ss.Out,
ss.Prec and ss.E f f denote ss[i], ss[o], ss[p] and
ss[e], respectively, and SS =
S
x ∈x.SS the set of
all semantic services of annotated 3D scenes x ∈ X .
Geometric Features of Scenes. Any geometric
feature g f of a given scene x is an instance of some
feature type f which is defined in the specification of
X3D, XML3D or COLLADA.
Definition 3: Geometric Features of a 3D Scene
Let F denote the space of all types of geometric fea-
tures of 3D scenes in X3D, XML3D and COLLADA.
A geometric feature g f ∈ GF of a 3D scene x ∈ X is
defined by the tuple: g f = [name, f , {(k, v)}] where
name denotes the feature name of g f in the context
of x; f ∈ F the feature type of g f ; and {(k,v)} the
set of attribute-value pairs which assigns values v(k)
to each attribute k of the geometric feature type f
with a proper data structure according to the X3D,
XML3D or COLLADA specifications. Let K
f
the
set of attributes of feature type f , and GF the set of
geometric features of all scenes x ∈ X stored in the
considered repository; x.v( f .k) denotes the value of
attribute k of feature f in scene x.
Semantic Query for 3D Scenes. The repository al-
lows users to issue semantic queries for relevant 3D
scenes, in particular, by means of specifying the de-
sired conceptual, functional and geometric features.
Definition 4: Semantic 3D Scene Query
Let O
req
denote an ontology used by a requester
req to formulate a request q for relevant 3D scenes.
Such a query q for 3D scenes is defined by the tuple:
q = [sd, τ(C, O
req
), SS, GF, A] where sd denotes the
syntactic (textual) description of the desired scene;
τ(C, O
req
) the logical unfolding of requested scene
concept C in O
req
; SS the set of semantic services
that the desired scene should provide; GF the set of
geometric feature instances that the desired scene
should have; and A the total number of the most
relevant scenes requested by req.
For example, the user query for a 3D scene of
a yellow colored car which is capable of car-
rying passengers and goods to a given destina-
tion is transformed by iRep3D into the query tu-
ple q = {”yellowcar”; τ(YC, O
req
) = Vehicle
P
u
Car
P
u ∀canCarry. (Goods
P
u Passenger
P
); SS =
{[URI; haveFun; In(Passenger psg, Goods gds,
TargetLocation tl); Out(); Prec(availableFor(psg));
Eff(at(psg,tl)∧ at(gds,tl))]} GF = {[name : color; f :
Material;{(0.8, 0.9, 0.15)}]}}.
2.2 Building of Scene Indices
A 3D scene x ∈ X is indexed by an iRep3D repos-
itory with respect to its different kinds of semantic
annotation. In particular, iRep3D is creating three
inverted scene indices for (a) scene concepts C ∈ O,
(b) semantic services ss ∈ SS, and (c) geometric
features g f ∈ GF , and stores the indexed scenes in
an XML database.
7
Scene Index for Concepts. The scene concept
index I
SC
of the repository is a set of ranked lists
R(C
0
) of scenes x ∈ X for all concepts C
0
in the
scene ontology O. Each of these lists R(C
0
) ∈ I
SC
contains pairs (x.id,d(x,C
0
)) of scenes x together
7
Each annotated 3D object of the XML-based structure
of an annotated scene in XML3D, X3D or COLLADA is
indexed by iRep3D as an individual 3D scene with a unique
(XPATH) scene identifier. We omit the details of subscene
identification for reasons of space.
iRep3D:EfficientSemantic3DSceneRetrieval
21

with their relevance scores d(x,C
0
) for the considered
(list) concept C
0
∈ O. The scene relevance score is
computed as weighted degree d(x,C
0
) of the approx-
imated logical subsumption relation s
ab,v
(x.C,C
0
)
between the list concept C
0
and the scene concept of
x. Finally, each of these lists R(C
0
) of scenes of the
scene concept index I
SC
is sorted in descending order
of the computed scene relevance scores.
Approximated Concept Subsumption. The above
mentioned degree s
ab,v
(C,C
0
) ∈ [0, 1] of approxi-
mated logical concept subsumption between concepts
C,C
0
, where C is approximately subsumed by C
0
,
bases on the process of structured logical concept
(contraction and) abduction. That is, the incompat-
ible part G, the compatible and the missed parts K
and M of the logical definition of concept C com-
pared with the one of concept C
0
are first identified
(C = GuK) by means of concept contraction (Di Noia
et al., 2009). These identified parts are then used by
the process of logical abduction to rewrite the origi-
nal concept definition of C such that the resulting ap-
proximated concept C
app
is logically subsumed by the
target concept C
0
.
Definition 5: Approximated Logical Concept Sub-
sumption
Let C
P
a primitive term in C, which conflicts with a
primitive term
¯
C
P
(named as the counter-part of C
P
)
in C
0
; |C| the number of conjunctive primitive terms
in C; PC(C) the set of primitive concepts of C; PR(C)
the set of primitive roles of C; PRE(C) the set of prim-
itive numeric restrictions of C. The approximated
concept subsumption score s
ab,v
(C,C
0
) is computed
as follows:
s
ab,v
(C,C
0
) =
|K|
|C
0
|
· (1 − s
ac f
(C,C
0
)),
s
ac f
(C,C
0
) =
∑
C
P
in G or M
(s
c f
(C
P
,C
0
)·w(C
P
,C
0
))
|C|
,
s
c f
(C
P
,C
0
) = 1, if C
P
in M or C
P
in PC(C) ∪ PR(C)
s
c f
(C
P
,C
0
) =
rg(C
P
)\rg(
¯
C
P
)
rg(C
P
)
, else (C
P
∈ PRE(C)) .
w(C
P
,C
0
) =
1
∑
C
0P
in G or M
impt(
¯
C
P
,C
0
)
· impt(
¯
C
P
,C
0
).
where
|K|
|C
0
|
denotes the proportion of the compatible
part K of C w.r.t. C
0
; s
ac f
the averaged strength of
logical conflicts between C and C
0
; s
c f
(C
P
,C
0
) the
strength of an (atomic) logical conflict on C
P
in C
w.r.t. C
0
. The latter is computed as follows: If C
P
is
in M then C
P
will surely appear in the abduced (new)
concept C
app
of C w.r.t. C
0
; while in case of C
P
being a
primitive concept or role in G, any logical conflict on
C
P
will cause the full rewriting of C
P
during concept
abduction. If C
P
is a primitive numeric restriction in
G, the conflict strength is the fraction of uncovered
range of C
P
w.r.t. its counter-part
¯
C
P
in C
0
. The func-
tion rg(C
P
) computes the restricted numeric range of
C
P
∈ PRE(C).
Each atomic conflict strength s
c f
(C
P
,C
0
) is
further weighted with a weight w(C
P
,C
0
)
((
∑
C
P
in G or M
w(C
P
,C
0
) = 1, w(C
P
,C
0
) > 0) which
estimates the importance of this conflict on C
P
w.r.t. C
0
for the corresponding approximated logical
subsumption relation. Let C
0
l p
the direct parent
concept of C
0
in O (O
s
); C
00
the rewritten (abduced)
concept of C
0
which is generated by replacing
¯
C
P
with C
P
if C
P
is in G, or removing C
P
from C
0
if C
P
is in M. The binary function impt(
¯
C
P
,C
0
) ∈ {a,b}
(0 < a < b ≤ 1) determines the importance of
¯
C
P
in
terms of keeping the hierarchy of C
0
in O (O
s
): It
returns b if C
00
v C
0
l p
is false; a otherwise. In other
words, if the replacement of
¯
C
P
(in C
0
) with C
P
or
the removal of C
P
makes C
00
no longer a subsumee of
C
0
l p
, the conflict on C
P
between C and C
0
then has a
greater negative impact on C being subsumed by C
0
.
Example 1: Consider the example of an annotated 3D
scene x ∈ X in figure 1. The indexing of x in the scene
index for scene concepts starts with computing the
similarity score s
ab,v
(Toledo,C
0
) between scene con-
cept Toledo and each concept C
0
in the given ontology
O. Let the logical unfolding of the defined concept
FamilyCar ∈ O (abbr. FC) τ(FC) := Vehicle
P
uCar
P
u ≤ 4hasWheels.W heel
P
u∀canCarry.Goods
P
u∀canCarry.Passenger
P
u∀ownership.Private
P
u
∀hasNickname.Name
P
. Further, let PrivateCar ∈ O
(abbr. PC) the direct parent concept of FC with
τ(PC) = Vehicle
P
uCar
P
u∀ownership.Private
P
u∀hasNickname.Name
P
. For indexing x in R(FC),
the relevance score d(x,R(FC)) = s
ab,v
(Toledo,
FC) of x is computed based on approximated
logical subsumption as follows: The determined
incompatible part G = ¬∀onwership.Private
P
and the missed part M = ∀canCarry.Goods
P
u
∀hasNickname.Name
P
of scene concept Toledo
w.r.t. list concept FC lead to the respective
conflict strengths: s
c f
(¬∀onwership.Private
P
,
FC) = 1, s
c f
(∀canCarry.Goods
P
, FC) = 1 and
s
c f
(∀hasNickname.Name
P
, FC) = 1. Then,
in very brief, the abduction of FC
0
from FC
based on these conflicts of Toledo w.r.t. FC is
done as follows. Let impt(·,·) ∈ {0.1, 0.9}. If
we replace ∀onwership.Private
P
in τ(FC) with
¬∀onwership.Private
P
, then the abduced con-
cept FC
0
is no longer subsumed by PC which
implies impt(∀onwership. Private
P
, FC) = 0.9,
therefore: w(∀onwership.Private
P
, FC) =
w(∀hasNickname.Name
P
, FC) =
0.9
0.9+0.1+0.9
=
0.47, w(∀canCarry.Goods
P
, FC) = 0.06. Sub-
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
22

sequently, the averaged conflict strength is s
ac f
=
1
|Poledo|
·
∑
C
P
in GuM
(s
c f
(C
P
,FC) · w(C
P
,FC))
=
1
5
(1 · 0.9 + 1 · 0.1 + 1 · 0.9) = 0.38. Fi-
nally, s
ab,v
(Toledo, FC) =
|K(Poledo,FC)|
|FC|
·
(1 − s
ac f
(Poledo, FC)) =
3
7
· (1 − 0.38) = 0.26.
A pair (x,0.26) is inserted into R(FC) ∈ I
SC
. ♦
Scene Index for Services. The scene index I
SS
for
semantic services consists of two (sub-)indices: the
scene index I
IO
for semantic service I/O concepts,
and the scene index I
PE
for semantic service pre-
conditions and effects. Similar to the scene index
for scene concepts, we create the first index I
IO
as a
set of two ranked lists R(C
s
)[i] = {(x.id,d
s
(x,C
s
)[i])}
and R(C
s
)[o] = {(x.id, d
s
(x,C
s
)[o])} of scenes x ∈ X
for each concept C
s
in the given service ontology
O
s
of the repository. Each entry of the list R(C
s
)[i]
(R(C
s
)[o]) states that some scene x is annotated with a
semantic service ss ∈ x.SS which has an input (out-
put) parameter concept C
0
s
∈ O
s
that is sufficiently
and maximally similar with the list concept C
s
∈
O
s
: d
s
(x,C
s
)[l] = max
C
0
s
∈ss[l],ss∈x.SS
d
c
(C
0
s
,C
s
)[l], l ∈
{i,o} where d
c
(C
0
s
,C
s
)[l] = f r(C
0
s
)[l]·s
ab,v
(C
0
s
,C
s
) de-
notes the approximated concept similarity subject to
s
ab,v
(C
0
s
,C
s
) ≥ θ ∈ [0,1]. The weight f r(C
0
s
)[l] =
|x.SS
C
0
s
[l]|
|x.SS|
· max
ss∈x.SS
C
0
s
n(C
0
s
,ss[l])
|ss|
is the frequency of oc-
currence of concept C
0
s
in x.SS with n(C
0
s
,ss[l]) the
number of occurrences of C
0
s
in the input (l = i) or
output (l = o) parameter set and |ss| the total number
of parameters of service x.ss. Each list R(C
s
)[l], l ∈
{i,o} of scenes is sorted in descending order of their
relevance scores d
s
(x,C
s
)[l].
The second index I
PE
consists of ranked lists R(α)[p]
and R(α)[e] of scenes x ∈ X for each defined pred-
icate α ∈ A
s
which appears in the logical precondi-
tion or effect of annotated services of these scenes.
Each scene x is ranked in the lists R(α)[l],l ∈ {p, e}
of pairs (x.id,d
a
(x,α[l])) according to its relevance
score d
a
(x,α)[l] = pl(α,x)[l] which denotes the plau-
sibility of α over the preconditions (effects) of all ser-
vices of x. In particular, let l
0
∈ {p,e}; A
s
(x)[l
0
] the
set of non-negative predicates that appear in the pre-
conditions or effects of services provided by x; and H
= 2
A
s
(x)[l
0
]
:
pl(α, x)[l
0
] = 1 − Bel
A
s
(x)[l
0
]\α
(x),
Bel
H
(x)[l
0
] =
∑
h⊆H
v(h),
v
H
(x)[l
0
] =
n
H
(x)[l
0
]
n
H
(x)[l
0
]
, subject to:
v(
/
0) = 0,
∑
H⊆H
v(H) = 1,
n
H
(x)[l
0
] =
∑
H⊆H
n
H
(x)[l
0
],
n
H
(x)[l
0
] =
∑
α∈H
n
α
(x)[l
0
],
n
α
(x)[l
0
] =
∑
ss∈x.SS
P
α
(x.ss[l
0
]|α).
where P
α
(x.ss[l
0
]|α) is the probability that the logical
precondition or effect x.ss[l
0
] is evaluated to true given
that α is true according to the truth table of x.ss[l
0
].
Example 2: Consider the Scene x in Example 1. Let
the semantic service transport (abbr. tr) the only one
provided by scene x, and θ = 0.25. The process of in-
dexing x in the scene index I
SS
starts with the subindex
I
IO
. Assume that the degree s
ab,v
(Passenger, People)
of approximated subsumption relation between ser-
vice input concept Passenger and requested concept
People in the service ontology O
s
of the repository
is 0.5. The frequency of occurrence of Passenger
in x.SS is f r(Passenger)[i] =
|1|
|1|
· max
ss∈x.SS
Passenger
[i]
{
1
2
} = 0.5. The weighted and maximal approxi-
mated similarity between Passenger and People ∈ O
s
then is d
c
(Passenger, People)[i] = f r(Passenger)[i] ·
s
ab,v
(x, People) = 0.5 · 0.5 = 0.25. Note that
d
c
(Location, People)[i] is ignored since their similar-
ity score s
ab,v
(Location, People) = 0.1 is smaller
than θ. Finally, d
s
(x,People)[i] = d
c
(Passenger,
People)[i] = 0.25. Assume that d
s
(x,Place)[i] = 0.63.
The pair (x,0.25) ((x,0.63)) is inserted into the rank
list of scenes R(People)[i] (R(Place)[i]). For indexing
x in the second subindex I
PE
, the plausibilities of the
predicates availableFor, reachable and at (denoted
as ava, rea and at, respectively) are computed. For
this purpose, we consider the truth tables for the ser-
vice precondition tr[p] and effect tr[e], respectively:
ava(psq) T T F F
rea(lc) T F T F
tr[p] T F F F
,
at(psg,lc) T F
tr[e] T F
Based on these truth tables the indexing process
estimates the probabilities Pa(tr[p]|ava(psg)) = 0.5,
Pa(tr[p]|rea(lc)) = 0.5 and Pa(tr[e]|at(psg,at)) =
1.0. Regarding the power set H = 2
{ava,rea}
of the
predicates, we obtain the plausibility values pl(ava,
x)[p] = pl(rea, x)[p] = 0.9 and pl(at, x)[e] = 1. As a
result, the pairs (x, 0.9), (x,0.9) and (x,1) are inserted
into the rank lists R(ava)[p], R(rea)[p] and R(at)[e]
of the subindex I
PE
. ♦
Scene Index for Geometric Features. In contrast to
the scene indices for concepts and services, the scene
index I
GF
is concerned with the geometric features
of a scene x. Each such feature g f ∈ GF of type
f ∈ GF (cf. Def. 3) consists of a set K
f
of attributes
k with numeric or string data type. The scene index
I
GF
is the set of B+ trees bt( f , k) of scenes which is
built for every attribute f .k of each feature f ∈ F . The
scenes x ∈ X are maintained in these trees according
to the feature attribute values v( f .k), if x has such val-
ues: Each leaf node of bt( f ,k) points to the address
of a ranked list R
j
( f , k) of pairs (x.id, x.v( f .k)) in the
descending order of x.v( f .k).
iRep3D:EfficientSemantic3DSceneRetrieval
23

Let M
l
the maximum number of scenes that a ranking
can accommodate; M
n
the maximum fanout (the
number of child nodes) of each node; X
f
⊆ X the
subset of scenes containing a value of k ∈ K
f
: The
construction of bt( f ,k) is performed in the following
steps: (i) sort scenes in X
f
in the descending order of
v( f .k); (ii) compute the number n
l
of needed ranked
lists: n
l
= d
|X
f
|
M
l
e; (iii) create d
n
l
M
n
e leaf-nodes; (iv)
initialize the pointers from leaf-node to rankings and
label each pointer with the attribute value of the first
entry in the corresponding ranking; (v) compute the
number of needed non-leaf-nodes in each level from
bottom to top and create their pointers and labels.
If a scene x contains multiple instances of the same
feature type attribute, then x has multiple entries in
bt( f , k). Each of these entries are additionally labeled
with the specific name g f .name of the geometric
feature f of x.
Example 3: Consider the scene x in Example 1. For
indexing x in the geometric index I
GF
, the B+ tree
bt(Material, di f f useColor) is created since x has a
geometric feature of type f = Material and x has a
value x.v(Material.di f f useColor) = (1.0, 0.9,0.0)
for the feature attribute k = di f f useColor.
Thus, (x, (1.0, 0.9,0.0)) is inserted into a ranked
list R
j
( f , k) of scenes refered to by the tree
bt(Material,di f f useColor). ♦
3 HYBRID SEMANTIC SCENE
RETRIEVAL
Once the semantic indices have been created off line
for a given collection of 3D scenes by the repository,
the user can make requests q (cf. Def. 4) for relevant
3D scenes based on concepts, services, and geometric
features. Key idea of answering a scene request with
high precision and fairly fast is (a) to process the
respective subqueries in the corresponding indices
I
SC
, I
SS
and I
GF
in parallel, and (b) to aggregate the
resulting rank lists R
sc
, R
ss
and R
g f
of scenes that
are relevant for q with Fagin’s threshold algorithm.
Finally, the iRep3D repository returns and displays
the top-k relevant scenes to the user. As mentioned
above, iRep3D’s preprocessing of annotated 3D
scenes allows the indexing of annotated scenes that
are part of others. If indexed scenes are relevant
but part of non-relevant scenes, only the first will
be displayed together with meta-information on the
latter. For example, if a scene model of a yellow car
is requested and such an indexed scene is found to
be part of another indexed scene of a parking garage
with tens of different cars, only the first scene is
returned to the user with a link to the overall scene.
Scene Concept-based Query Processing. If the
query q includes a request for scenes about some con-
cepts C
0
defined by the logical expression τ(C
0
,O
req
)
then iRep3D classifies this concept into the current
scene ontology O and returns the corresponding rank
list R
SC
of scenes which are relevant to q with respect
to the approximated logical similarity of their scene
concepts with the requested one C
0
.
Scene Service-based Query Processing. If the query
q contains the description of desired scene services
(ss ∈ q.SS) then iRep3D processes the respective sub-
queries in the scene index for services. Firstly, for
each ss ∈ q.SS, a rank list R(ss) of scenes that are rel-
evant to ss is computed. For this purpose, the indices
I
IO
and I
PE
are searched in parallel. The resulting
ranked lists R(ss)[io] and R(ss)[pe] are further merged
into the list R(ss) of scenes which are relevant to ss.
Finally, all lists R(ss) of ss ∈ q.SS are merged, which
leads to the ranked list R
SS
of scenes which are rele-
vant to q in terms of the requested semantic services.
Searching Index I
IO
for Scenes with Service ss: For
each ss ∈ q.SS, iRep3D first retrieves in parallel a set
{R(C
0
s
)[l], l ∈ {i,o}} of ranked lists of scenes each
of which relevant to a distinct service signature pa-
rameter concept C
0
s
[l] in ss[l]. In particular, the logi-
cal expression of each concept C
0
s
in ss[i] (ss[o]) gets
classified into the ontology O
s
, and the corresponding
ranked list with suffix [i] ([o]) is eventually retrieved.
Subsequently, the aggregation with TA(Fagin, 2002)
is performed on {R(C
0
s
)[l]} to compose a ranked list
R(ss)[io] of scenes relevant to q with respect to the
I/O parameters of the requested service ss.
In particular, the TA performs a sorted scan of all its
input rank lists in {R(C
0
s
)[l]} from top to bottom in
parallel. The i-th scan fetches the score values at the i-
th positions of all lists in {R(C
0
s
)[l]}, and then employs
a m-ary (m the cardinality of {R(C
0
s
)[l]} for ss) func-
tion t that computes the aggregated relevance score
and threshold. The general form of t is given in (Fa-
gin, 2002) and can be further customized for any ap-
plication. In our context, we define t as the weighted
average of the vector of scores
~
s fetched from each
rank list in {R(C
0
s
)[l]} per scan. The weight v
j
of the
j-th list in {R(C
0
s
)[l]} refers to the number of occur-
rences of C
0
s
in either ss[i] or ss[o]:
t(
~
s) =
∑
m
j=1
v
j
· s
j
∑
m
j=1
v
j
Each scan performed by the TA may find a new scene
x
n
that does not exist in the current R(ss)[io]. To insert
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
24

x
n
into R(ss)[io], iRep3D computes the aggregated
relevance score s(x
n
,ss)[io] of scene x
n
to q w.r.t. the
I/O concepts of ss ∈ q.SS: From each ranked list in
{R(C
0
s
)[l]}, TA collects (possibly by random access)
the so far missed d
s
(x
n
.id,C
0
s
) of x
n
; and further ap-
plies the t function on all d
s
(x
n
.id,C
0
s
) in order to
compute s(x
n
,ss)[io]. Then TA maintains a thresh-
old value T for determining its termination, which
is updated with the t function value over the latest
scanned values after each scan. TA terminates, if
T ≤ s(x,ss)[io] for all the ranked objects x in R(ss)[io].
Searching index I
PE
for scenes with service ss: For
each ss ∈ q.SS, the searching of I
PE
for ss results
in two sets of ranked lists {R(α)[l
0
]} (l
0
∈ {p, e})
for every non-negative predicate α in ss[l
0
]. In ad-
dition, it merges the ranked lists in each set into a list
R(ss)[l
0
] of scenes that are relevant to ss in terms of
ss[l
0
]. For this purpose, multiple pairs of the same
scene x in different lists are merged; pairs in different
lists are merged if they have the same scene id. The
score value s(x,ss[l
0
]) of x in R(ss)[l
0
] of each result
pair is computed by applying the G
¨
odel minimum t-
norm and maximum t-conorm functions according to
the conjunctive, respectively disjunctive relations be-
tween the predicates in ss[l
0
]:
s(x,ss[l
0
]) = min
cla∈ss[l
0
]
(s(x,cla[l
0
])),
s(x,cla[l
0
]) = max
α∈cla
(d
a
(x,α)[l
0
]).
where cla[l
0
] denotes a clause of disjunctive predi-
cates. Finally, the search process merges R(ss)[p]
and R(ss)[e] in order to compute R(ss)[pe] of scenes
which are relevant to ss in terms of the precondition
and effect. The completion of the parallel computa-
tions of R(ss)[io] and R(ss)[pe] triggers their merging
and yields the ranked list R(ss) of scenes relevant to q
in terms of ss ∈ q.SS. The relevance score s(x, ss) of x
in R(ss) is the convex combination of the correspond-
ing scores in R(ss)[io] and R(ss)[pe]:
s(x,ss) = φs(x,ss[io]) + ψs(x, ss[pe]),
where the real positive values φ and ψ (φ+ψ = 1) are
the weights of IO and PE matching respectively. They
can vary in specific systems with different concerns.
Merging of scene rank lists R(ss) for all ss ∈ q.SS: In
a next step, the resulting ranked lists R(ss) for all ss ∈
q.SS are merged, if (some of) their entries in different
lists share the same id. The relevance score s(x,q.SS)
for x with respect to q.SS is the average of the scores
s(x,ss) of x in R(ss) for each service ss:
s(x,q.SS) =
1
|q.SS|
∑
ss∈q.SS
s(x,ss).
Finally, the merged list are resorted in descending
order of s(x, q.SS) yielding the ranked list R
SS
of
scenes partially relevant to q with respect to q.SS.
Geometric Feature-based Query Processing. If the
query q contains the description of desired geomet-
ric features g f ∈ q.GF of a scene then iRep3D pro-
cesses the respective subqueries in the scene index
I
GF
as follows. Firstly, for each g f ∈ q.GF, a par-
allel search is performed in the B+ trees bt(g f . f , k)
where each search results in a ranked list R(g f . f .k)
of scenes relevant to q in terms of g f . f .k. Please
note that R(g f . f .k) does not have similarity scores
but the feature attribute values. Secondly, for each
entry (x.id,x.v( f .k)) ∈ R(g f . f .k), iRep3D computes
the degree of geometric feature attribute similarity
s
k
(q.v( f .k),x.v( f .k)) between the requested and ex-
isting feature attributes based on its values q.v( f .k)
and x.v( f .k). This results in a new rank list
R(q,g f . f .k) of scenes that are relevant to q for the re-
quested value of g f . f .k. Thirdly, all lists R(q,g f . f .k)
of attributes which belong to the same feature type
g f . f are further merged (by scene id) into a ranking
R(q,g f ) of scenes that are relevant to q with respect
to the g f . Finally, all feature-level rankings R(q,g f )
for all g f ∈ q.GF are merged into one which yields
the overall ranking of scenes relevant to q.
The data types of geometric feature attributes de-
fined in the X3D, XML3D and COLLADA specifica-
tions include the following primitive data types: (i)
single number, string or boolean (e.g. SFDouble,
SFString); (ii) 2-, 3- or 4-ary tuple of numbers
or strings (e.g. SFVec2d, SFVec3f, float4 type);
(iii) vector of values of the types in (i) and (ii) (e.g.
MFDouble, MFVec3d). Let t p(k) denote the primitive
data type of feature attribute k. iRep3D computes the
geometric feature attribute similarity score as follows:
s
k
(v
1
,v
2
) =
• xor(v
1
,v
2
), if t p(k) is single boolean;
• EDS(v
1
,v
2
) = 1 −
ED(v
1
,v
2
)
max(|v
1
|,|v
2
|)
, if t p(k) is single
string, where |v
1
| denotes the length of v
1
;
• min(
v
1
v
2
,
v
2
v
1
), if t p(k) is single number;
•
1
|v
1
|
∑
|v
1
|
i=1
xor(v
1i
,v
2i
), if t p(k) is a boolean vector,
where |v
1
| denotes cardinality of v
1
;
• cos sim(v
1
,v
2
), if t p(k) is a pair, triple or a vector
of numbers;
• V EDS(v
1
,v
2
) =
1
|v
1
|
∑
|v
1
|
i=1
EDS(v
1i
,v
2i
), if t p(k) is a
pair, triple or a vector of strings;
•
1
|v
1
|
∑
|v
1
|
i=1
cos sim(v
1i
,v
2i
), if t p(k) is a vector of pairs
or triples of numbers;
•
1
|v
1
|
∑
|v
1
|
i=1
V EDS(v
1i
,v
2i
, if t p(k) is a vector of pairs
or triples of strings;
where nor(v
1
,v
2
) is the exclusive OR of v
1
and v
2
;
EDS(v
1
,v
2
) the Levenstein edit distance of v
1
and
v
2
; cos sim(v
1
,v
2
) the cosine distance of v
1
and v
2
.
We omit the data types SFImage, MFImage, SFTime
iRep3D:EfficientSemantic3DSceneRetrieval
25

and MFTime of the X3D specification since they are
not considered as geometric data types.
The geometric feature-based retrieval of relevant
scenes computes the rank lists R(g f . f .k) each of
which entries contain the identifiers of scenes and
their values v( f .k) for the requested feature attribute
k. Instead of directly retrieving a pointed ranking
by a leaf node of the B+ tree, R(g f . f .k) is com-
puted by applying a window tolerant strategy which
retrieves at most N entries from both parts of the
entry (x.id, x.v(g f . f .k)) whose feature attribute value
has a minimum distance to q.v(g f . f .k) (N is called
half-window width value).
Final Aggregation of Relevance Rank Lists of
Scenes. In the end, the computed three different rel-
evance rank lists R
sc
, R
ss
and R
g f
of 3D scenes for
q are merged by, again, leveraging Fagin’s TA algo-
rithm as described above. If the score of a scene x is
missing in some of these rank lists, the lowest score
in the respective list is used by default. The TA termi-
nates if the threshold is not larger than the least score
of the A-th (cf. Def.4) entry in the total ranking, or all
three lists above are scanned over.
4 EXPERIMENTAL EVALUATION
The repository iRep3D has been fully implemented
in Java and stores its 3D scenes in the XML database
BaseX. We conducted an experimental evaluation
of the performance of iRep3D in comparison with
three other representative open-source repositories
for 3D scenes. For this purpose, we selected (a)
the FB3D system for functional and behavioral
ontology-based semantic retrieval of 3D scenes
(Camossi et al., 2007), (b) the RIR system for RDF
index-based scene retrieval approach (RIR) (Alvez
and Vecchietti, 2011), and (c) the syntactic-based 3D
model repository ADL.
Experimental Settings. Since there is, to the best of
our knowledge, no 3D scene retrieval test collection
publicly available yet, we built a first version of it,
called 3DS-TC, which consists of 616 manually an-
notated scene graphs (591 in X3D
8
, 25 in XML3D).
The respective scene ontology O in OWL2 contains
260 concepts, 48 roles and 7 role restrictions, and the
scenes in 3DS-TC are also annotated with references
to 33 services in OWL-S in total. The precondition
and effect of services are encoded in RDF plain liter-
als. As mentioned above, all annotations are embed-
8
http://www.web3d.org/x3d/content/examples
Table 1: AP, DCG
10
and AQRT of iRep3D and competitors.
iRep3D FB3D RIR ADL
AP 0.721 0.490 0.633 0.408
DCG
10
2.133 0.952 1.370 0.767
AQRT (sec) 0.166 1.887 0.059 0.042
ded into the scene graphs with standard RDFa. Fur-
ther, the test collections consists of a set Q of 20 scene
queries together with relevance sets each of which
containing 10 relevant scene graphs with relevance
scores rel ∈ {1.0, 0.9, .. . , 0.1}), while non-relevant
scenes were assigned a score of 0 by default. Further,
we set A = 10 for all q ∈ Q; θ = 0.5; φ = ψ = 0.5;
a = 0.1, b = 0.9 for the importance function; and the
half-tolerance window width N = 10.
In order to enable FB3D reasoning on functional
descriptions of scenes, we added 12 concepts and 4
roles extracted from the annotated scene services to
our scene ontology. Besides, we let FB3D pre-load
the scene concepts before its query processing in
order to eliminate the loading and parsing time of
3D scenes. For the RIR system, we (i) created the
required RDF triples for the scene concepts and ser-
vice parameter concepts of annotated 3D scenes with
the Jena OWL analyzer
9
, (ii) employ the indexing
facilities of MySQL database to index the generated
RDF triples in terms of their subject, predicate and
object, and (iii) constructed one SPARQL query for
each query q ∈ Q. For the ADL system, we store the
syntactic descriptions of scene semantics provided in
the meta-tags in a MySQL database.
Performance Evaluation Measures. We use the
following standard retrieval performance evaluation
metrics for our comparative experimental evaluation
of scene retrieval by the 3D scene repositories
iRep3D, FB3D, RIR and ADL: Macro-average pre-
cision (MAP
λ
) at 11 recall levels (RE
λ
) (MAP@RE)
with equidistant steps of 0.1; average precision (AP);
Averaged discounted cumulative gain (DCG
10
) at
rank position 10; and average query response time
(AQRT) in seconds.
Evaluation Results. The experimental results reveal,
among other, that for the given collection 3DS-TC the
iRep3D repository significantly outperforms its com-
petitors in terms of retrieval precision (MAP@RE,
AP and DCG
10
): In particular, its average precision
is 34%, 13%, and 55% higher than that of FB3D,
RIR, and ADL, respectively. Compared with FB3D,
the main reason of this improvement in precision is
that iRep3D avoids misclassifications caused by strict
logic-based matching of scene concepts and due to
9
http://jena.apache.org/
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
26
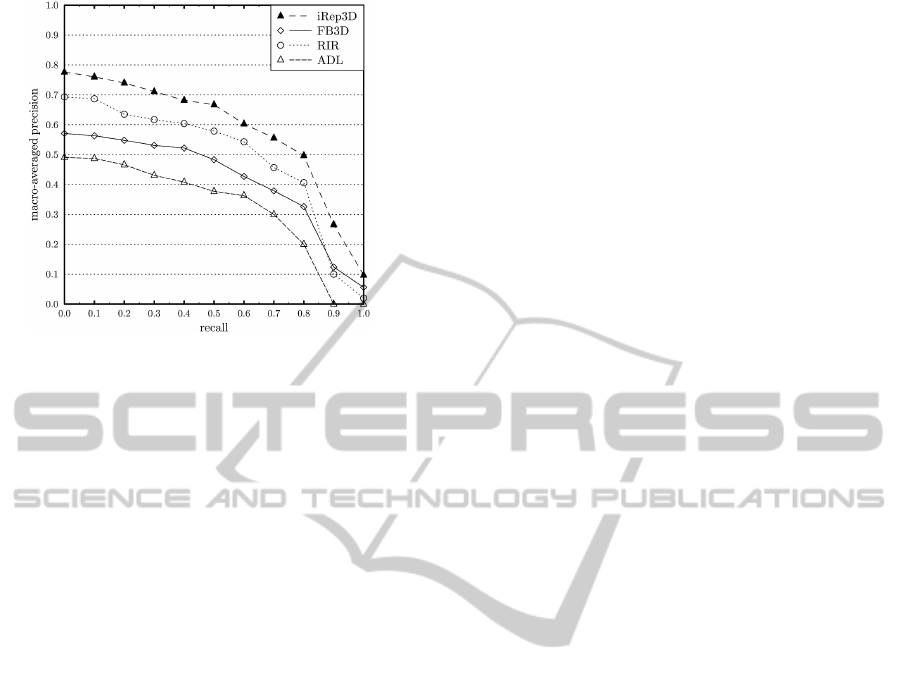
Figure 2: MAP@recall of iRep3D, FB3D, RIR, and ADL.
its hybrid semantic matching of scenes tolerates more
parameter mismatches than the one-shot functional
concept matching performed by FB3D. The RIR sys-
tem alleviates the problem of text similarity-based
classification failures of ADL by exploiting RDF-
based scene descriptions but due to its exact SPARQL
query pattern matching it still remains much less ac-
curate than iRep3D. Given some conjunctive keyword
query, ADL directly queries its underlying database
by wildcard SQL and limits its search for relevant
scenes by ignoring text segmentation.
On the other hand, the high precision of hybrid se-
mantic retrieval of scenes by iRep3D is not achieved
at the cost of extremely high response times. In
fact, the average query response of iRep3D appears
reasonably fast (0.166 secs) compared to those of
FB3D (1.887 secs), RIR (0.059 secs) and ADL (0.042
secs). However, iRep3D is slower than RIR and ADL
since it requires more time for logical classification
of requested scene and service parameter concepts
into its scene (and service concept) ontology than
the SPARQL query processing by RIR and keyword
matching by ADL.
5 RELATED WORK
Many content and geometric feature-based ap-
proaches to 3D model retrieval have been proposed
in the past decade such as (Tangelder and Veltkamp,
2004; Bustos et al., 2007; Paquet et al., 2000) but their
mutually incompatible geometric feature definitions
and formalisms limit their usage. The majority of 3D
scene retrieval systems still relies on merely syntactic-
based classification of scenes based on their geomet-
ric or non-geometric descriptive properties. For ex-
ample, (Gao et al., 2011) proposes a probabilistic
classification of 3D objects based on a Gaussian pro-
cess while (Leifman et al., 2005) refines geometric-
topological feature matching with unsupervised off-
line learning and subsequent on-line supervised fea-
ture extraction from scenes. The approaches pre-
sented in (Gong et al., 2011) and (Hou et al., ) perform
SVM-based (off line) learning of 3D object classifica-
tion based on their non-geometric features and label
each grounded object with the category in a prede-
fined universe of discourse. Similarly, (Akguel et al.,
2010) proposes SVM-based learning of a geometric
feature-based classifier of 3D object descriptions off-
line, and then estimates a probabilistic similarity be-
tween a given query and candidate objects on line.
In contrast to iRep3D, the average precision of these
adaptive approaches to 3D scene retrieval essentially
depends on the chosen type of kernel function and the
training set used by the SVM for learning the binary
relevane classifier of 3D scenes.
On the other hand, the leveraging of semantic
technologies for 3D scene annotation and retrieval has
gained some momentum recently. For example, the
work presented in (Alvez and Vecchietti, 2011; La-
borie et al., 2009) utilizes RDF stores with efficient
SPARQL query processing for indexing and retriev-
ing RDF-annotated 3D scenes. In these cases, how-
ever, the query answering requires exact matches of
scene graph patterns and attribute labels. In (Hois
et al., 2007b) an approach for 3D image recogni-
tion is proposed based on a logic-based scene on-
tology for object recognition during the planning of
robot actions; and (Camossi et al., 2007) presents a
knowledge-based system for a semantic annotation
and retrieval of 3D models based on an a specific on-
tology in OWL-DL about scene formation, function-
ality and behavior. In contrast to these approaches,
iRep3D leverages approximated logical reasoning on
ontology-based conceptual semantics of annotated
scenes which shows to be less prone to be affected
by syntactic and strict pattern mismatches, and may
avoid strict logic-based misclassifications of scene an-
notations. (Yang, 2010) proposes to use high-level
content signatures and linguistic extensions of mul-
timedia contents for being able to handle imprecise
queries for 3D scenes but at the cost of potential
loss of information about the original scene seman-
tics. M
¨
oller et. al. (Peraldi et al., 2009) apply rule-
based abduction on the extracted low-level seman-
tic descriptions of multimedia objects for answering
grounded conjunctive queries in the fact base of a
given scene ontology. Unlike iRep3D, these retrieval
approaches do not rely on efficient scene indexing,
hence might not as well scale to very large and dis-
tributed settings of scene retrieval.
iRep3D:EfficientSemantic3DSceneRetrieval
27

6 CONCLUSIONS
We presented a new approach, called iRep3D, for
efficient semantic indexing and retrieval of XML-
based annotated 3D scenes. Results of experimen-
tal performance evaluation over a given preliminary
test collection of X3D and XML3D scenes shows that
iRep3D can significantly outperform representative,
open-source and state of the art multimedia retrieval
systems in terms of average precision and with rea-
sonable response time.
REFERENCES
Akguel, C., Sankur, B., Yemez, Y., and Schmitt, F. (2010).
Similarity learning for 3d object retrieval using rele-
vance feedback and risk minimization. International
Journal of Computer Vision, 89(2):392–407.
Alvez, C. and Vecchietti, A. (2011). Efficiency analysis in
content based image retrieval using rdf annotations.
Advances in Soft Computing, pages 285–296.
Bustos, B., Keim, D., Saupe, D., and Schreck, T. (2007).
Content-based 3d object retrieval. Computer Graphics
and Applications, IEEE, 27(4):22–27.
Camossi, E., Giannini, F., and Monti, M. (2007). Deriving
functionality from 3d shapes: Ontology driven anno-
tation and retrieval. Computer-Aided Design & Appli-
cations, 4(6):773–782.
Di Noia, T., Di Sciascio, E., and Donini, F. (2009). A
tableaux-based calculus for abduction in expressive
description logics: Preliminary results. In Proc. of
DL09 Workshop.
Fagin, R. (2002). Combining fuzzy information: an
overview. ACM SIGMOD Record, 31(2):109–118.
Gao, B., Zhang, S., and Pan, X. (2011). Semantic-oriented
3d model classification and retrieval using gaussian
processes. Journal of Computational Information Sys-
tems, 7(4):1029–1037.
Gong, B., Liu, J., Wang, X., and Tang, X. (2011). 3d object
retrieval with semantic attributes. In Proc. of the 19th
ACM international conference on Multimedia, pages
757–758. ACM.
Hois, J., Schill, K., and Bateman, J. (2007a). Integrating
uncertain knowledge in a domain ontology for room
concept classifications. Research and Development in
Intelligent Systems XXIII, pages 245–258.
Hois, J., W
¨
unstel, M., Bateman, J., and R
¨
ofer, T. (2007b).
Dialog-based 3d-image recognition using a domain
ontology. Spatial Cognition V Reasoning, Action, In-
teraction, pages 107–126.
Hou, S., Lou, K., and Ramani, K. Svm-based semantic clus-
tering and retrieval of a 3d model database. Computer
Aided Design and Application, 2(2).
Kalogerakis, E., Moumoutzis, N., and Christodoulakis, S.
(2006). Coupling ontologies with graphics content for
knowledge driven visualization. In Proc. of the IEEE
Virtual Reality Conference 2006.
Kapahnke, P., Liedtke, P., Nesbigall, S., Warwas, S., and
Klusch, M. (2010). Isreal: an open platform for
semantic-based 3d simulations in the 3d internet. The
Semantic Web–ISWC 2010, pages 161–176.
Klusch, M. (2012). The s3 contest: Performance evaluation
of semantic service matchmakers. In Semantic Web
Services Advancement through Evaluation. Springer.
Klusch, M. and Kapahnke, P. (2012). The isem match-
maker: A flexible approach for adaptive hybrid se-
mantic service selection. Web Semantics: Science,
Services and Agents on the World Wide Web.
Koutsoudis, A., Stavroglou, K., Pavlidis, G., and Chamzas,
C. (2011). 3dsse–a 3d scene search engine: Exploring
3d scenes using keywords. Cultural Heritage.
Laborie, S., Manzat, A., and Sedes, F. (2009). Managing
and querying efficiently distributed semantic multime-
dia metadata collections. Multimedia, IEEE, (99):1–1.
Leifman, G., Meir, R., and Tal, A. (2005). Semantic-
oriented 3d shape retrieval using relevance feedback.
The Visual Computer, 21(8):865–875.
Paquet, E., Rioux, M., Murching, A., Naveen, T., and
Tabatabai, A. (2000). Description of shape informa-
tion for 2-d and 3-d objects. Signal Processing: Image
Communication, 16(1):103–122.
Peraldi, S., Kaya, A., and M
¨
oller, R. (2009). Formalizing
multimedia interpretation based on abduction over de-
scription logic aboxes. In Proc. of DL09 Workshop,
Oxford, UK.
Pittarello, F. and De Faveri, A. (2006). Semantic description
of 3d environments: a proposal based on web stan-
dards. In Proc. of the 11th international conference
on 3D web technology, pages 85–95. ACM.
Qi, G., Aggarwal, C., Tian, Q., Ji, H., and Huang, T. (2011).
Exploring context and content links in social media:
A latent space method. Pattern Analysis and Machine
Intelligence, IEEE Transactions on, (99):1–1.
Tangelder, J. and Veltkamp, R. (2004). A survey of content
based 3d shape retrieval methods. In Shape Modeling
Applications, 2004, pages 145–156. IEEE.
Yang, B. (2010). Dsi: A model for distributed multime-
dia semantic indexing and content integration. ACM
Transactions on Multimedia Computing, Communica-
tions, and Applications (TOMCCAP), 6(1):3.
VISAPP2013-InternationalConferenceonComputerVisionTheoryandApplications
28
