
Event Recommendation in Social Networks with Linked Data
Enablement
Yinuo Zhang
1
, Hao Wu
1
, Vikram Sorathia
2
and Viktor K. Prasanna
2
1
Department of Computer Science, University of Southern California, Los Angeles, CA, U.S.A.
2
Ming Hsieh Department of Electrical Engineering, University of Southern California, Los Angeles, CA, U.S.A.
Keywords:
Recommendation, Linked Data, Social Networks.
Abstract:
In recent years, social networking services have gained phenomenal popularity. They allow us to explore the
world and share our findings in a convenient way. Event is a critical component in social networks. A user
can create, share or join different events in their social circle. In this paper, we investigate the problem of
event recommendation. We propose recommendation methods based on the similarity of an event’s content
and a user’s interests in terms of topics. Specifically, we use Latent Dirichlet Allocation (LDA) to generate
a topic distribution over each event and user. We also consider friend relationship and attendance history to
increase recommendation accuracy. Moreover, we enable linked data as our data sources to collect contex-
tual information related to events and users, and build an enhanced profile for them. As reliable resource,
linked data is used to find structured knowledge and linkages among different knowledge. Finally, we conduct
comprehensive experiments on various datasets in both academic community and popular social networking
service.
1 INTRODUCTION
People live socially and keep connected in various
ways. Social event is one of the essential components
for networking. Celebrations, inaugurations, com-
mencements, fund raising are all social events that
serve for different purposes. People tend to refer to
their friends or media for information of upcoming
events. Nowadays, its main channel has shifted from
newspaper, bulletin board and television to the inter-
net, especially popular online social networks. For
instance, users like to use the interactive interface of
Facebook Events
1
to create events, invite friends and
accept invitations. Significant portion of those events
on Facebook are about parties and any other informal
celebrations. Eventseer
2
represents another example
that serve as an news forum for notifications of aca-
demic events, which are mainly conferences, work-
shops and seminars in various disciplines. Last.fm
3
is another example which contains various event in-
formation related to music, such as festivals, singer or
band performance and fan party.
1
http://www.facebook.com/events/
2
http://eventseer.net/
3
http://www.last.fm/events
The offer of events is enormous online and there
are usually many co-occurring activities even at the
same location. Consequently, people find it difficult
to keep track of the events that are of interest to them
or worth spending time. To address this problem, rec-
ommendation models (Cornelis et al., 2005; Kayaalp
et al., 2009; Klamma et al., 2009; Konstas et al.,
2009; Coppens et al., 2012; Minkov et al., 2010; Li
et al., 2010; Daly and Geyer, 2011; De Pessemier
et al., 2011) are designed to select relevant events that
are most likely of interest to each individual user. A
general approach of event recommendation is content
based (Cornelis et al., 2005; De Pessemier et al.,
2011), which aims to capture descriptive features of
an event such as location, time and theme to match
user interests. To characterize user interests, content-
based approach leverage the past event attendance
records of a user, as well as the user feedback such
as the rating of events. The keywords that charac-
terize user interests are then used as query to search
on the future events for recommendation. One major
problem of the keyword-based search is that it can-
not fully capture the rich semantics of event content
and how it matches user interests. Moreover, the suc-
cess of content-based approach largely depend on the
user history records and user feedback. In this sense,
371
Zhang Y., Wu H., Sorathia V. and K. Prasanna V..
Event Recommendation in Social Networks with Linked Data Enablement.
DOI: 10.5220/0004443903710379
In Proceedings of the 15th International Conference on Enterprise Information Systems (ICEIS-2013), pages 371-379
ISBN: 978-989-8565-60-0
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

the approach may suffer from data sparsity problem
(Minkov et al., 2010) when dealing with new users
who have inadequate history records and the user
feedback of events is scarce.
In this paper, we adopt topic modeling method to
bridge the semantic gap between events and user pref-
erences. People tend to attend events with themes that
match their personal interests. Therefore, the users’
preferences of future events rely on underlying top-
ics rather than word descriptions. In particular, La-
tent Dirichlet Allocation (LDA) (Blei et al., 2003) is
used to discover the underlying latent topics, in or-
der to find events that best match user preferences
in semantics. The influence of a user’s connections
is also considered. We look at the event attendance
history of one’s friends to find events that the user
may be interested in. It is based on the intuition that
friends with common interests are more likely to at-
tend the same events. In an integrated manner, we
learn a model to rank the future events by using the
user attendance history for personalized recommen-
dation. We also present a hybrid model combining
the three topic modeling based approaches. We con-
duct comprehensive experiments on various datasets
of academic community and popular social networks.
The results show that our methods consistently out-
perform the baseline algorithm. The main contribu-
tions of our work can be summarized as:
• We present three event recommendation ap-
proaches based on topic modeling of event
content and user profile.
• We propose a hybrid learning framework for rec-
ommendation which integrates topic similarity,
user connection and attendance history.
• We enable linked data in constructing event and
user profiles, as well as event history records.
The rest of the paper is organized as follows. We
continue with discussion of related work in Section 2.
We present our methodology in details In Section 3.
We show a brief overview of linked data and the ex-
periment setup in Section 4. Experimental results are
presented in Section 5. Finally, we conclude our work
and briefly discuss future work in Section 6.
2 RELATED WORK
Event recommendation as a means of personalizing
event information acquisition in social networks, has
attracted increasing research attention in recent years.
Most existing methods borrowed the ideas from in-
formation recommendation of other domains such as
e-commence (Linden et al., 2003), book (Guan et al.,
2009), music (Chen and Chen, 2001) and photo shar-
ing (Sigurbj¨ornsson and Van Zwol, 2008) websites.
Content-based and collaborative filtering approaches
which based on two mechanisms are employed for
recommending future events. Daly and Geyer (Daly
and Geyer, 2011) consider location and social in-
formation to filter events for recommendation. Cor-
nelis et al. (Cornelis et al., 2005) propose an hy-
brid conceptual approach which leverages the merits
of content-based and collaborative filtering. The ap-
proach recommends future events if they are similar
to past ones that similar users have liked, which is
an extension of Perny and Zucker’s work (Perny and
Zucker, 1999). However, the approach is only con-
ceptual and the authors do not provide validation of
the approach on experiments. Minkov et al. (Minkov
et al., 2010) present a collaborative method called
LowRank, which decomposes user parameters into
shared and individual components for event recom-
mendation in the setting of academic seminars. The
method uses topic modeling to represent the past at-
tendance activities of individual users and descrip-
tions of the events as topic features. The experimental
results demonstrate its superiority over basic content-
based recommendation. However, the approach is
only limited to one domain and it requests user feed-
backs. In this paper, we aim to design a general and
user feedback independent algorithms which can be
applied to different settings of event recommendation.
Previous work also focuses on the aggregation,
enrichment as well as personalized distribution of
events from various web sources. Kayaalp et al.
(Kayaalp et al., 2009) examine a social activity rec-
ommendation system for concert event. Concerts in-
formation is harvested from web sources using web
services and scrapers. Recommendations are gener-
ated based on various features including user profiles,
concert ratings, a social network structure, and ac-
tivity properties. They build a complete event track-
ing system which is open to the integration of het-
erogeneous information resources. De Pressemier et
al. (De Pessemier et al., 2011; Coppens et al., 2012)
focus on representation of events as structured data.
They build a highly-scalable event recommendation
platform for cultural events, which are collected and
published as Linked Open Data with an RDF/OWL
representation using the EventsML-G2 standard. This
allows the incorporation of content-based filters for
event distribution. However, those explorations do
not capture the underlying topic of different events
or activities quite well, and topics usually can pro-
ICEIS2013-15thInternationalConferenceonEnterpriseInformationSystems
372

vide a better description of an evetn in order to match
user preferences. Also, their methods request user
feedbacks which can affect flexibility. Moreover,
the datasets they used are isolated which are in the
form of XML. Sometimes the linkages among dif-
ferent datasets are quite critical for recommendation
since one data source cannot contribute enough in-
formation. Different from their work, our methods
explores both content and underlying topics to build
event profiles. Also linked data is used as data source
which is more flexible and inter-linkable. Further-
more, our methods only request the attendance his-
tory from users with any other feedbacks owing to the
variety of linked data.
Social influence has great impact on a user’s deci-
sions and actions. A user is likely to followthe actions
of his/her friends with which they share common in-
terest. This idea is embedded into various recommen-
dation systems to improve the performance, includ-
ing item recommendation in music sharing website
(Konstas et al., 2009), product review rating predic-
tion (Au Yeung and Iwata, 2011), interest targeting
and friendship prediction (Yang et al., 2011). Based
on the same idea, Klamma et al. (Klamma et al.,
2009) explore academic events such as conferences
and workshops and identify ones that might be of in-
terest to individual researchers and can motivate co-
operation between them. They propose a similarity
measure based on the attendance records to generate
recommendation. However, the content information
such as conference name and description are not con-
sidered. In our work, we consider variety of datasets
to evaluate our approaches. We also utilize the friend-
ship which is the most influential relationship in so-
cial networks for event recommendation.
3 METHODOLOGY
In this section, we go into full exploration of event
recommendation modeling. We begin with setting up
the problem. Suppose there are m users and n events
in the network, the goal is to find relevant events that
are of interest to a user u
i
. We use similarity metrics
to measure how likely a user u
i
will attend an event
e
j
. The information we can use is the set of friends
that u
i
has, which is denoted by F(u
i
), and A(e
j
), the
set of users who have attended e
j
. We also summarize
the notations used in this paper in Table 1.
Each event or user profile is usually represented
as a text document with word descriptions. The ways
of extracting word descriptions vary in different con-
texts. In general, meaningful properties such as ti-
tle, description and location are extracted for events,
Table 1: Notations used in this paper.
Notation Description
u
i
, i = 1...m the ith user in a set of m users
e
j
, j = 1...n the jth event in a set of n events
F(u
i
) the set of user u
i
’s friends
A(e
j
) the set of users who have attended e
j
while words from interests, description and activity
history are used for users. To find events with co-
herent semantics that match user interests, we adopt
topic modeling to uncover the underlying topics of
each event, and user interests as well. We generate
topic proportion of each documentexpressed by those
words using Latent Dirichlet Allocation (LDA) (Blei
et al., 2003). In LDA, a document is considered as
a mixture of latent topics, and each word observation
in the document is sampled from a multinomial dis-
tribution (the word mixture for a topic). Each topic
is drawn from a multinomial distribution generated
using the Dirichlet prior. LDA can capture the un-
derlying structure of a document and reveal the latent
topics.
We first present three event recommendation ap-
proaches based on semantic similarity, relationships
between users, and attending history. In the first ap-
proach, we simply calculate the similarity between
topic distributions over an event and a user profile,
and the most similar events are recommended to cor-
responding users. In the second approach, friend re-
lationships are considered for recommendation. The
intuition is that users with same interests have large
chance to attend same events. In the third approach,
event attendance history is used to build a classifier
for recommendation. Logistic regression is adopted
in the classification phase. Finally, we present an
hybrid approach that combine the above three ap-
proaches. The hybrid approach uses weighted sum
for calculating the similarity between an event and a
user. Next, we elaborate each method.
3.1 Similarity Based Approach (SBA)
The basic idea for this approach is to capture the se-
mantic similarity between a user and an event. Based
on the topic distribution similarity, those events with
the highest similarity to a specific user are recom-
mended.
Specifically, we generate topic distribution for
each document using LDA. The topic distribution is
in the form of a normalized vector denoted as
−→
θ . In
order to find the events that are of interest to a spe-
cific user, the similarity between
−→
θ of an event and a
user is calculated. To compute the similarity between
two vectors, we adopt cosine similarity (Equation 1)
EventRecommendationinSocialNetworkswithLinkedDataEnablement
373

in this paper for its simplicity, although various alter-
natives can be used.
S
1
(u
i
, e
j
) = cos(
−→
θ
u
i
,
−→
θ
e
j
) =
−→
θ
u
i
·
−→
θ
e
j
||
−→
θ
u
i
||||
−→
θ
e
j
||
, (1)
In Equation 1, S
1
(u
i
, e
j
) is the recommendation score
of event e
j
for user u
i
. Here we use cosine similar-
ity between the topic distribution vectors of user u
i
and event e
j
. Once the score S
1
is calculated, all the
events w.r.t. a user are ranked in descending order ac-
cording to the scores. In practice, only top-k events
are returned for recommendation, where k can be pre-
defined as a query parameter (e.g., an option for user
to choose k value).
3.2 Relationship Based Approach
(RBA)
In this approach, we consider social influence that
may have impact on uses’ attending an event. Users
usually follow their friends to attend an event because
of common interests or just for networking. We hence
recommend a user with the events attended by his/her
“friends”. “Friendship” may refer to different rela-
tions in different contexts. For example, it is simply
the friend relationship in general social networks such
as Facebook. And it refers to co-authorship in aca-
demic social networks. In order to quantify the de-
gree of sharing same interests, the similarity between
the topic distributions of two users u
i
and u
i
′
is calcu-
lated (Equation 2).
S
uu
(u
i
, u
i
′
) = cos(
−→
θ
u
i
,
−→
θ
u
i
′
) =
−→
θ
u
i
·
−→
θ
u
i
′
||
−→
θ
u
i
||||
−→
θ
u
i
′
||
(2)
Based on the similarity, the recommendationscore
of event e
j
to user u
i
is calculated as
S
2
(u
i
, e
j
) =
Σ
u
k
∈F(u
i
)∩A(e
j
)
S
uu
(u
i
, u
k
)
|F(u
i
) ∩ A(e
j
)|
, (3)
where F(u
i
) ∩ A(e
j
) represent user u
i
’s friends who
attend event e
j
. Similar to the first approach, all
events u
i
’s friends attend are ranked in descending or-
der of the score S
2
, and only top-k results are returned.
3.3 History Based Approach (HBA)
In this third approach, we consider recommendation
as a classification problem based on event attendance
history of each user. We train a logistic regression
model for each user using the topic distributions of
past attend events. As shownin Equation 4, the output
of logistic function f
u
i
on a future event is used as the
recommendation score S
3
.
S
3
(u
i
, e
j
) = f
u
i
(e
j
) =
1
1+ e
−z
(4)
where
z = β
0
+ β
1
θ
(1)
e
j
+ ... + β
k
θ
(k)
e
j
(5)
In Equation 5, k is the number of topics, θ
e
j
repre-
sents the topic distribution vector for event e
j
, θ
(t)
e
j
is the value for topic t in the vector, and
−→
β =
[β
0
, β
0
, ..., β
k
]
⊤
are the parameters for the logistic re-
gression model of a specific user. Finally, top-k re-
sults are recommended to user u
i
based on the value
of S
3
(u
i
, e
j
) which is between 0 to 1.
3.4 A Hybrid Approach (SRH)
Each of the above three methods has its own pros and
cons. When users in a social network are well con-
nected and has strong ties between each other, RBA
is favored in recommendation. When past event atten-
dance history is adequate, HBA is better applicable. If
neither conditions are true but the social network can
provide rich user and event profiles, SBA may work
best. In order to provide a satisfying recommenda-
tion in different social networks, we propose a hybrid
approach which integrate all three methods with dif-
ferent weights. A hybrid score S(u
i
, e
j
) is generated
as shown in Equation 6.
S(u
i
, e
j
) = ω
1
S
1
(u
i
, e
j
) + ω
2
S
2
(u
i
, e
j
) + ω
3
S
3
(u
i
, e
j
)
(6)
where
−→
ω = [ω
1
, ω
2
, ω
3
]
⊤
are the weights for the three
approaches proposed in previous sections. In order
to set
−→
ω for different social networks, 10-fold cross-
validation can be used to decide
−→
ω . Specifically, the
dataset can be partitioned into 10 equal size subsets.
One subset is used as the validation data and the other
9 subsets are used as training data for learning the
weights. The process is repeated 10 times with each
subset as the validation data. In the experiments, data
from different social networks are used to illustrate
how the weights are affected.
The base of all four approaches is topic modeling,
and the results of topic modeling highly depend on the
amount of document profiles and their keywords. In
next section, we will introduce linked data to discover
new events and enrich the profile for users and events.
4 LINKED DATA ENABLEMENT
Using latent topics modeling techniques such as
LDA, implicit semantics of documents (i.e., users and
ICEIS2013-15thInternationalConferenceonEnterpriseInformationSystems
374

events) are extracted from the raw text in order to
build a better recommender. Another way to improve
the performance and accuracy for recommendation is
to use semantic web techniques. Specifically, com-
prehensive ontologies and semantic queries are the
common approaches. However, for domain like event
recommendation, it is not possible to compute ev-
erything in a single ontology. It is also not efficient
to store all related knowledge in one place. To ad-
dress this issue, linked data provides a good alterna-
tive. Nowadays, the amount of information increases
drastically on the web. Linked data is a type of struc-
tured data which are interlinked. It covers almost ev-
ery subject(i.e., Geographic information, social net-
works, publications et al.) on the web. Linked data
is also easy to be retrieved so that it can be used as a
part of knowledge base.
For event recommendation domain,
EventSeer2RDF
4
represents linked data version
of the information on Eventseer.net. This enables
easy access to the information related to variety of
academic events including conferences and work-
shops using SPARQL queries. Most importantly,
it not only stores past events records, but also
provides future events information which can be
recommended. Moreover, all academic profiles for
users can also be retrieved. Besides eventseer, DBLP
is also a good resource for academic information.
Different from eventseer which provides event
description in the form of “call for papers”, DBLP
stores the information about past publications and
co-authorship for papers. Fortunately, there is a
linked data version of DBLP
5
on the semantic web.
All publication records related to a author can be
retrieved through its SPARQL endpoint.
Figure 1: Event Representation in Linked Eventseer Data.
Figure 1 shows the partial graph structure of
an example “
event
”(i.e. event 16594) in eventseer
4
http://linkeddata.few.vu.nl/eventseer
5
http://www4.wiwiss.fu-berlin.de/dblp
linked data. Information in linked data is repre-
sented as rdf triples <subject, predicate, object>.
In this example, four triples exist in the partial rdf
graph. As can be seen, predicates “
based near
” and
“
dtstart
” show location and starting time for that
event. “
Persons
” related to that event can be ex-
tracted from “
involvedAgent
” predicate. Moreover,
predicate “
subject
” provides the related “
topics
”
of that event. In this example, person Rick Rabiser is
involved in event 16594 while the event is related to
topic data integration.
Similar to “
event
”, “
person
” also has several
properties. As shown in Figure 2, “
Topic interest
”
provides the topics related to that person, while
“
knows
” lists all persons who share the same inter-
ests with that person. In our context, “
knows
” is a
way to identify friendship relations among academic
persons.
Figure 2: Person Representation in Linked Eventseer Data
Another example is enrich user profile using
DBLP linked data. The detailed publications for
a specific person can be found through “
creator
”
property. All meaningful keywords in his/her publi-
cation titles then contribute to his/her profile. In next
section, we will evaluate our methods on academic
event recommendation with linked data enablement.
5 EXPERIMENTS AND RESULTS
In this section, we conduct comprehensive experi-
ments to compare the four methods proposed in Sec-
tion 3. Specifically, two sets of data are used. The
first dataset is for academic event recommendation.
Open linked version of Eventseer and DBLP data are
the sources for academic events and users. In total,
profiles consisting of 10020 events and 26508 user
are generated. To our best knowledge, we are the
first to use open linked data for dynamic event recom-
mendation. The second dataset comes from the most
popular social network - Facebook. The reason we
use Facebook is that it has explicit representation of
social events which does not appear in other social
EventRecommendationinSocialNetworkswithLinkedDataEnablement
375

networks such as Twitter or LinkedIn. In total, 1088
users and 4040 events are crawled through Facebook
Graph API Explorer
6
to recommend social network
events for Facebook users. In Section 5.1 and 5.2, the
results on two datasets are presented sequentially.
5.1 Academic Event Recommendation
Our proposed methods are firstly evaluated on aca-
demic event dataset. Each event to recommend can be
a future conference or a future workshop. Eventseer
is such a resource that provides detailed information
of future events and prospective attendees. In order to
generate latent topic models on events and users, each
of them is viewed as a document for LDA process.
Topic distribution over document is considered as the
feature space. In our experiments, linked eventseer
data is used to extract keywords for each event and
user. It is also the resource to find friendship relation-
ship and participation information. Moreover, linked
DBLP data provides more keywords for users since
it has all publication records. Mean Average Preci-
sion(MAP) (Manning et al., 2008) is the metrics for
evaluating four proposed methods. Average Precision
for each user is defined as
AP =
1
n
n
∑
i=1
prec(k
i
) (7)
where prec(k
i
) is the precision at rank k. It is defined
as the number of correct records up to rank k, then di-
vided by k. And n is the number of correct answers,
while k
i
represents the rank of each correct answer.
For example, given a ranked list in which 1,3,4 are
correct answers while 2,5 are not. The average preci-
sion for this list is (1 +
2
3
+
3
4
).
According to the definition of average precision,
the value is highly related to the query context. For
example, the worst case and random result for rec-
ommending N records with only one correct are
1
N
and the inverse of harmonic mean of N. In order to
be consistent, a fixed number of records (i.e., 20) are
returned for different sets of experiments. Recall is
not used in the experimental evaluation because the
dataset does not contain all the attended events for
each user. As a result, the absolute recall value cannot
be calculated.
5.1.1 SBA
Each event and user is represented as a docu-
ment. Keywords for events are extracted from
EventSeer2RDF, a linked data repository for
eventseer. Keywords for users are extracted from
6
http://developers.facebook.com/tools/explorer
both EventSeer2RDF and D2R DBLP Bibliography
Database. A topic distribution for each user and
event is calculated. Based on the distribution, cosine
similarity between each event and user pair is calcu-
lated. In this experiment, two sets of data are used.
The first set consists of 20 events and 140 users,
while the second set consists of 5000 events and
26508 persons. LDA is processed on both datasets
separately. For the first set, all events are returned
in the recommendation results. For the second set,
the similarities between the topic distributions over
the same set of events and users as in the first set are
computed. All 20 events are ranked for each user in
descending order of the similarity. Figure 3 shows
the performance of SBA on these two datasets. Each
point is the averaged MAP over 140 users. We also
vary the parameters for topic modeling. In detail, the
number of latent topics is set as 6 values (25, 50, 75,
100, 125, 150) and the number of Gibbs sampling
iterations is empirically set as 500.
25 50 75 100 125 150
0.2
0.25
0.3
0.35
0.4
Number of Topics
Mean Average Precision
SBA (20 events, 140 persons)
SBA (5000 events, 26580 persons)
Random
Figure 3: MAP of SBA.
As observed from Figure 3, SBA outperforms ran-
dom method on both datasets. Also SBA using large
dataset has higher precision than that with small one.
It is because large dataset has more “documents” and
keywords for LDA to process. As a result, LDA has
sufficient training set to provide a good topic model
on each user and event. Another observation is that
MAP does not differ much as the number of topics
for LDA varies. The performance of topic modeling
is relatively stable as the number of topics increase
from 25 to 150.
5.1.2 RBA
Friendship also plays an important role for recom-
mendation. Now we investigate how it affects the pre-
cision of recommendingacademic events. The second
data set generated in SBA is used for topic modeling.
Top 20 eventsare returned for 140 users based on their
RBA scores.
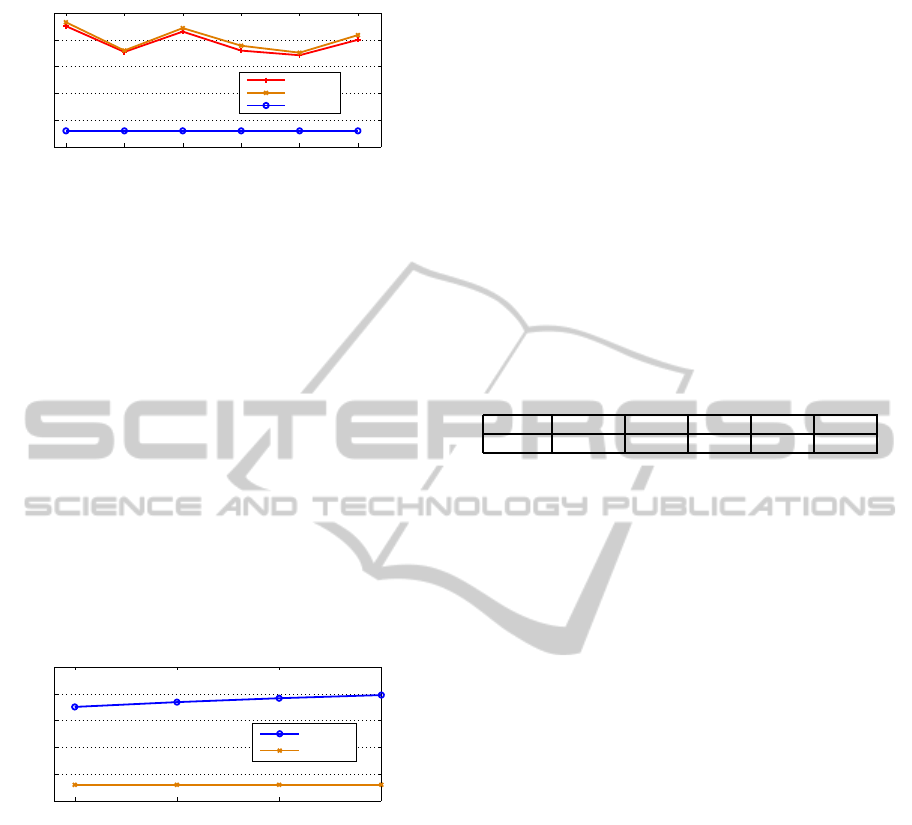
Figure 4 shows that RBA always has higher preci-
sion than the random method regardless of the num-
ber of topics for LDA process. However, SBA per-
forms slightly better than RBA under the same set-
ICEIS2013-15thInternationalConferenceonEnterpriseInformationSystems
376
25 50 75 100 125 150
0.2
0.25
0.3
0.35
0.4
Number of Topics
Mean Average Precision
RBA
SBA
Random
Figure 4: MAP of RBA.
ting. This can be explained by the property of the aca-
demic dataset. The friendship relations in eventseer
are not as dense as that in the tradition social net-
works. As a result, friendship is not a good indicator
for recommending events under this context.
5.1.3 HBA
Logistic regression is adopted in the third method.
Specifically, recommendation is considered as a clas-
sification problem. The feature space is the topic dis-
tribution over each event. The whole data set (10020
events and 26508 users) with 25 topics is used in LDA
process. Figure 5 shows the performance of HBA
compared with random method. The number of train-
ing events varies from 5000 to 10000. The test set is
a fixed set of 20 events. They are ranked in the de-
scending order of HBA scores. MAP is also used to
measure the precision of both approaches.
2500 5000 7500 10000
0.2
0.25
0.3
0.35
0.4
Number of Training Events
Mean Average Precision
HBA
Random
Figure 5: MAP of HBA.
As can be seen in Figure 5, HBA always outper-
forms the random method under different numbers of
training event sets. In detail, HBA is twice more pre-
cise than the random method as the number of training
events reaches 10000. Another observation is that the
result of HBA becomes more precise as the number
of training events increases. However, the improve-
ment on the precision is only 0.03 when the size in-
creases from 2500 to 10000. This is also caused by
the property of dataset itself. Specifically, each user
only participates a few events. As a result, the ground
truth matrix for training is very sparse. In most case,
training negatives are received.
5.1.4 SRH
Finally, the hybrid approach SRH is evaluated on the
academic dataset. In this experiment, the second data
set in SBA experiment is used to generate latent topic
models with the number of topics as 50. Same query
semantics is adopted as top 20 events are returned in
the answer set. Three combinations of weight for ω
1
,
ω
2
and ω
3
(0.2, 0.3, 0.5; 0.5, 0.2, 0.3; 0.3, 0.5, 0.2)
are selected in the experiments. The MAP value for
SRH in Table 2 uses the setting of 0.2, 0.3, 0.5 which
has the highest precision among the three sets. As can
be seen from the table, the hybrid method SRH with
a proper set of weights outperforms all other three
methods as well as the random method. The reason
is that with tuning the weights, the hybrid method can
best fit its sub-method to the properties of the dataset
in order to provide a better recommendation than any
of them.
Table 2: MAP of all methods.
Method Random SBA RBA HBA SRH
MAP 0.1799 0.3308 0.3274 0.3416 0.3664
5.2 Facebook
Apart from academic events, we also applied our
methods to event recommendation in one general and
popular social network - Facebook. Facebook pro-
vides a very useful tool - Graph API. It is the core of
Facebook Platform, enabling developers to read from
and write data into Facebook. It presents a simple,
consistent view of the Facebook social graph, uni-
formly representing objects in the graph (e.g., peo-
ple, photos, events, and pages) and the connections
between them (e.g., friend relationships, shared con-
tent, and photo tags).
Specifically, an access token is generated on
Graph API Explorer. One token corresponds to
one user. Given this token, the information of
all friends of a specific user as well as all events
which his/her friends attend are crawled. The key-
words for topic modeling are extracted from such
information to build the profiles for both users and
events. Two ways are exploited to generate event
sets. Starting from a user, the events list of her/him
is retrieved using Graph API. The words contribut-
ing the event profile can be extracted based on
the event id. Second method is based on the
search function provided by Graph API. For exam-
ple, all events related to keyword “USC” can be re-
trieved through the link https://graph.facebook.com/
search?q=USC&type=event
The second method significantly enlarges the
dataset since it does not depend on specific users.
For the experimental setting, 1088 users and 4040
events are crawled from Facebook Graph API. In to-
tal, 16499 unique keywords are extracted from those
EventRecommendationinSocialNetworkswithLinkedDataEnablement
377

users and events raw texts. Same as academic event
recommendation, LDA is used to generate topics and
distributions over each user and event. Specifically,
300 iterations are adopted. For the parameters, β =
0.01 and α = 1. Figure 6 shows MAPs of SBA, RBA,
HBA and SRH (ω
1
= 0.3, ω
2
= 0.5, ω
3
= 0.2). Each
point is generated using the average MAP over 100
users. The recommendation result includes 20 events
related to those 100 users. For HBA, the number of
training events are 4000.
25 50 75 100 125
0.2
0.25
0.3
0.35
0.4
0.45
0.5
Number of Topics
Mean Average Precision
SBA
RBA
HBA
SRH
Figure 6: MAP on Facebook dataset.
As can be seen from Figure 6, SRH with
−→
ω =
[0.3, 0.5, 0.2]
⊤
outperforms all three other methods
using Facebook data. Among the three methods, RBA
has the highest precision. This is because Facebook
has a more well-developed friendship relation net-
work which can be utilized to find potential com-
mon interests among different users. HBA has low-
est precision because the attendance history matrix
is still quite sparse. Most friends of the user used
in the experiments are not so active in terms of at-
tending events. However, the precision is still over
twice higher than the random method (with precision
as 0.1799). Another observation is MAP for all meth-
ods are not so sensitive to the number of topics. As
a result, 25 topics are enough for recommendation in
order to reduce computational cost.
6 CONCLUSIONS
In this paper, we investigate the problem of event rec-
ommendation. We propose four methods involving
two machine learning techniques (i.e., LDA and lo-
gistic regression) which can extract implicit seman-
tics from the raw data of events and users. We also re-
trieved the explicit semantics by enabling open linked
data (e.g., linked eventseer and linked DBLP) in the
recommendation process. Finally, we conduct com-
prehensive experiments both academic events (i.e.,
conference and workshops) and social networking
events (i.e., social activities on Facebook). The re-
sults show that the hybrid approach SRH outperforms
all other three methods with a proper selection of
weights. Moreover, all four methods have higher rec-
ommendation precisions than the random method on
both datasets.
One future direction is to automate the process
of choosing weights for SRH. Some machine learn-
ing techniques such as n-fold cross-validation can be
adopted. Another direction is to focus on the com-
putational aspect of the recommendation algorithms.
The reason is that dynamism exists everywhere in the
social networks and the recommended events should
be updated with the times. How to provide not only
accurate but also prompt recommendations is a chal-
lenging problem to investigate.
ACKNOWLEDGEMENTS
This work is supported by Chevron Corp. under the
joint project, Center for Interactive Smart Oilfield
Technologies (CiSoft), at the University of Southern
California.
REFERENCES
Au Yeung, C. and Iwata, T. (2011). Strength of social in-
fluence in trust networks in product review sites. In
Proceedings of the fourth ACM international confer-
ence on Web search and data mining, pages 495–504.
ACM.
Blei, D., Ng, A., and Jordan, M. (2003). Latent dirichlet al-
location. The Journal of Machine Learning Research,
3:993–1022.
Chen, H. and Chen, A. (2001). A music recommendation
system based on music data grouping and user inter-
ests. In Proceedings of the tenth international con-
ference on Information and knowledge management,
pages 231–238. ACM.
Coppens, S., Mannens, E., De Pessemier, T., Geebelen, K.,
Dacquin, H., Van Deursen, D., and Van de Walle, R.
(2012). Unifying and targeting cultural activities via
events modelling and profiling. Multimedia Tools and
Applications, pages 1–38.
Cornelis, C., Guo, X., Lu, J., and Zhang, G. (2005). A
fuzzy relational approach to event recommendation.
In Proceedings of the Indian International Conference
on Artificial Intelligence.
Daly, E. M. and Geyer, W. (2011). Effective event discov-
ery: using location and social information for scoping
event recommendations. In Proceedings of the fifth
ACM conference on Recommender systems, RecSys
’11, pages 277–280, New York, NY, USA. ACM.
De Pessemier, T., Coppens, S., Geebelen, K., Vleugels,
C., Bannier, S., Mannens, E., Vanhecke, K., and
Martens, L. (2011). Collaborative recommendations
with content-based filters for cultural activities via a
scalable event distribution platform. Multimedia Tools
and Applications, pages 1–47.
ICEIS2013-15thInternationalConferenceonEnterpriseInformationSystems
378

Guan, Z., Bu, J., Mei, Q., Chen, C., and Wang, C. (2009).
Personalized tag recommendation using graph-based
ranking on multi-type interrelated objects. In Pro-
ceedings of the 32nd international ACM SIGIR con-
ference on Research and development in information
retrieval, pages 540–547. ACM.
Kayaalp, M.,
¨
Ozyer, T., and
¨
Ozyer, S. T. (2009). A collab-
orative and content based event recommendation sys-
tem integrated with data collection scrapers and ser-
vices at a social networking site. In ASONAM, pages
113–118.
Klamma, R., Pham, M. C., and Cao, Y. (2009). You never
walk alone: Recommending academic events based
on social network analysis. In Complex (1), pages
657–670.
Konstas, I., Stathopoulos, V., and Jose, J. M. (2009). On so-
cial networks and collaborative recommendation. In
Proceedings of the 32nd international ACM SIGIR
conference on Research and development in informa-
tion retrieval, SIGIR ’09, pages 195–202, New York,
NY, USA. ACM.
Li, H., Tian, Y., Lee, W.-C., Giles, C. L., and Chen, M.-
C. (2010). Personalized feed recommendation service
for social networks. In SocialCom/PASSAT, pages 96–
103.
Linden, G., Smith, B., and York, J. (2003). Amazon. com
recommendations: Item-to-item collaborative filter-
ing. Internet Computing, IEEE, 7(1):76–80.
Manning, C. D., Raghavan, P., and Schtze, H. (2008). In-
troduction to Information Retrieval. Cambridge Uni-
versity Press, New York, NY, USA.
Minkov, E., Charrow, B., Ledlie, J., Teller, S. J., and
Jaakkola, T. (2010). Collaborative future event rec-
ommendation. In CIKM, pages 819–828.
Perny, P. and Zucker, J. (1999). Collaborative filtering
methods based on fuzzy preference relations. Pro-
ceedings of EUROFUSE-SIC, 99:279–285.
Sigurbj¨ornsson, B. and Van Zwol, R. (2008). Flickr tag
recommendation based on collective knowledge. In
Proceedings of the 17th international conference on
World Wide Web, pages 327–336. ACM.
Yang, S., Long, B., Smola, A., Sadagopan, N., Zheng, Z.,
and Zha, H. (2011). Like like alike: joint friend-
ship and interest propagation in social networks. In
Proceedings of the 20th international conference on
World wide web, pages 537–546. ACM.
EventRecommendationinSocialNetworkswithLinkedDataEnablement
379
