
Mapping Text Mining Taxonomies
Katja Pfeifer and Eric Peukert
SAP AG, Chemnitzer Str. 48, 01187 Dresden, Germany
Keywords:
Instance-based Matching, Text Mining, Taxonomy Alignment.
Abstract:
Huge amounts of textual information relevant for market analysis, trending or product monitoring can be found
on the Web. To make use of that information a number of text mining services were proposed that extract and
categorize entities from given text. Such services have individual strengths and weaknesses so that merging
results from multiple services can improve quality.
To merge results, mappings between service taxonomies are needed since different taxonomies are used for
categorizing extracted information. The mappings can potentially be computed by using ontology matching
systems. However, the available meta data within most taxonomies is weak so that ontology matching systems
currently return insufficient results.
In this paper we propose a novel approach to enrich service taxonomies with instance information which
is crucial for finding mappings. Based on the found instances we present a novel instance-based matching
technique and metric that allows us to automatically identify equal, hierarchical and associative mappings.
These mappings can be used for merging results of multiple extraction services. We broadly evaluate our
matching approach on real world service taxonomies and compare to state-of-the-art approaches.
1 INTRODUCTION
Analysts estimate that up to 80% of all business rel-
evant information within companies and on the web
is stored as unstructured textual documents (Grimes,
2008). Being able to exploit such information for ex-
ample for market analysis, trending or web monitor-
ing is a competitive advantage for companies. To sup-
port the extraction of information from unstructured
text, a multitude of text mining techniques were pro-
posed in literature (see Hotho et al., 2005). These
techniques include the classification of text docu-
ments, the recognition of entities and relationships
as well as the identification of sentiments. Recently,
many of these text mining techniques were made pub-
licly available as Web Services (e.g. OpenCalais,
2013; AlchemyAPI, 2013) to simplify their consump-
tion and application integration. Individual services
often have specific strengths and weaknesses. By
combining them the overall extraction quality and
amount of supported features can be increased (Sei-
dler and Schill, 2011).
Unfortunately, merging the results from multi-
ple extraction services is problematic since individ-
ual services rely on different taxonomies or sets of
categories to classify or annotate the extracted infor-
mation (e.g., entities, relations, text categories). To
illustrate the problem we show the results of extract-
ing entities from a news text in Figure 1. Entities have
been annotated by several text mining services (Open-
Calais, 2013; Evri, 2012; AlchemyAPI, 2013; FISE,
2013) that rely on different taxonomies to annotate
found entities. For instance the text sequence Airbus
is annotated with three different entity types: Orga-
nization (by FISE), Company (by AlchemyAPI and
OpenCalais) and AerospaceCompany (by Evri).
To be able to combine and merge extraction re-
sults from multiple services a mapping between dif-
ferent taxonomy types is required. Finding map-
pings between different service taxonomies manu-
ally is not feasible as the taxonomies can be very
large and evolve over time (e.g., AlchemyAPI uses
Figure 1: Analysis of a business news by several named
entity recognition services (retrieved on March 9, 2011).
5
Pfeifer K. and Peukert E..
Mapping Text Mining Taxonomies.
DOI: 10.5220/0004500400050016
In Proceedings of the International Conference on Knowledge Discovery and Information Retrieval and the International Conference on Knowledge
Management and Information Sharing (KDIR-2013), pages 5-16
ISBN: 978-989-8565-75-4
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

a taxonomy with more than 400 entity types). Un-
fortunately applying existing (semi-)automatic ontol-
ogy and schema matching techniques (Euzenat and
Shvaiko, 2007; Rahm and Bernstein, 2001) does not
provide the requested quality since the available meta
data within existing service taxonomies is weak (i.e.,
no descriptions are available, the taxonomies have
a flat structure). Moreover, existing matching ap-
proaches are not able to identify relations between the
taxonomy types (i.e., if two types are equal or just as-
sociated, or if one type is a subtype of the other).
To overcome those limitations, we introduce a novel
taxonomy alignment process that enables the merging
of taxonomies for text mining services. The following
contributions are made within this paper:
• We introduce a novel approach of using instance
enrichment to support taxonomy matching. A ba-
sic enrichment algorithm is used to populate tax-
onomies of text mining services with instance data
by running the services on sample documents and
collecting the produced annotations.
• Based on these instances a new taxonomy align-
ment approach is presented that uses a combined
matching strategy.
• In particular, a novel metric for instance-based
matchers is proposed that is able to identify equal,
hierarchical and associative mappings. The met-
ric is generic and could well be applied for other
instance-based matching tasks.
• The application of the taxonomy alignment pro-
cess is broadly evaluated on a number of real-
world text mining services and their taxonomies.
For that purpose reference mappings were created
through an online survey with numerous partic-
ipants. We compare to state-of-the-art instance-
based alignment methods that are used in ontol-
ogy matching systems.
The remainder of the paper is structured as follows: In
Section 2 we formally describe the problem and intro-
duce the notation being used within this paper. Sec-
tion 3 introduces our taxonomy alignment process and
presents the instance enrichment algorithm, the met-
ric for instance-based matching as well as the com-
bined matching strategy used within our process. The
experimental setup and the results of our evaluation
can be found in Sections 4 and 5. We introduce an ex-
emplary application that makes use of the introduced
taxonomy alignment process in Section 6 before we
review related work in Section 7. Section 8 closes
with conclusions and an outlook to future work.
2 PROBLEM DESCRIPTION
Combining the results of multiple text mining ser-
vices is promising as it can increase the quality and
functionality of text mining. In order to enable the
aggregation of results of various text mining ser-
vices a mapping between the different underlying tax-
onomies is required. However, finding such a map-
ping is challenging even though the names of the tax-
onomy types being presented to the user when an-
notating text are typically clear and easy to under-
stand. A review of existing text mining services and
their taxonomies revealed that the taxonomies differ
strongly in granularity, naming and their modeling
style. Many taxonomies are only weakly structured
and most taxonomy types are lacking any textual de-
scription. Therefore manually defining a mapping be-
tween text-mining taxonomies is a complex, challeng-
ing and time consuming task.
Within this paper we want to apply ontology- and
schema matching techniques (Euzenat and Shvaiko,
2007; Rahm and Bernstein, 2001) to automatically
compute mappings between text mining taxonomies.
Matching systems take a source and a target ontol-
ogy as input and compute mappings (alignments) as
output. They employ a set of so called matchers to
compute similarities between elements of the source
and target and assign a similarity value between 0 and
1 to each identified correspondence. Some matchers
primarily rely on schema-level information whereas
others also include instance information to compute
element similarities. Typically, the results from multi-
ple of such matchers are combined by an aggregation
operation to increase matching quality. In a final step
a selection operation filters the most probable corre-
spondence to form the final alignment result.
Unfortunately existing matching approaches solve
the challenges of matching text mining taxonomies
only partly. Schema-based matchers can only be
applied to identify mappings between equal con-
cepts (e.g., by using a name-matcher) as the scarcity
of broader meta data disables the use of more en-
hanced matchers (e.g., retrieving hierarchical map-
pings through the comparison of the taxonomy struc-
ture). Instance-based approaches are mainly lim-
ited to equal mappings. The few instance-based ap-
proaches that support hierarchical mappings still suf-
fer from limited accuracy as we show in our evalu-
ation (see Section 7 for a complete review of related
work). Furthermore, no instances exist for most of the
text mining taxonomies.
To overcome the aforementioned limitations, we
propose an instance enrichment algorithm that popu-
lates the taxonomy types with meaningful instances.
KDIR2013-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
6

T
1
:
a
d
b
c
T
2
:
i
ii
iii
...
T
n
: ...
-
-
Instance Enrichment
-
inter-matching process T
1
-T
2
Schema-based Matcher
?
Instance-
based
Matcher
a
k
d
i
i
b
ii
g
c
iii
-
a
b
c
d
IRT
i
ii
iii
0.1
1.0
0.1
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.7
0.8
0.6
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.3
0.3
1.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
...
-
inter-matching process T
m
-T
n
-
-
-
intra-matching process T
1
...
-
Mappings
T
1
T
2
Type
a
i
>
b
ii
≡
c
iii
<
Mappings
T
1
T
1
Type
a
d
>
...
-
-
...
Mappings
T
m
T
n
Type
... ... ...
-
Mapping Rewrite
-
Global Taxonomy G
T
1
.a
T
1
.d
T
2
.i
T
1
.b,T
2
.ii
T
2
.iii
T
1
.c
...
Figure 2: taxonomy alignment process.
This allows us to apply instance-based matchers and
smilarity metrics like Jaccard and Dice (Isaac et al.,
2007; Massmann and Rahm, 2008) to identify map-
ping candidates. Since those metrics can only be used
to identify equality mappings we introduce a novel
metric that allows to identify hierarchical and associa-
tive mappings like broader-than, narrower-than or is-
related to. We integrate the instance enrichment and
instance matching together with some optimizations
in a novel taxonomy alignment process that we de-
scribe below.
To sharpen the description of our contributions,
we formalize the problem. The overall goal of the
taxonomy alignment process is to integrate the tax-
onomies T
1
, T
2
, ..., T
n
of the text mining services
S
1
, S
2
, ..., S
n
into one global taxonomy G. We make
the assumption that each service S
i
uses its own tax-
onomy T
i
to classify the text mining results. In or-
der to align two taxonomies T
s
and T
t
mappings be-
tween the types of the taxonomies need to be iden-
tified. A mapping M is a triple (T
s j
, T
tk
, R) in which
R ∈
{
≡, <, >, ∼
}
indicates a relation between a type
T
s j
∈ T
s
and a type T
tk
∈ T
t
. (T
s j
, T
tk
, ≡) means
that the taxonomy types T
s j
and T
tk
are equivalent,
(T
s j
, T
tk
, <) indicates that T
s j
is a subtype of T
tk
(i.e.,
T
s j
is narrower than T
tk
), (T
s j
, T
tk
, >) is the inverse
subsumption relation (i.e., T
s j
is broader than T
tk
).
(T
s j
, T
tk
, ∼) represents an associative relation (e.g.,
car and truck are associated). The set of instances
annotated by a type T
i j
is specified by I(T
i j
), its cardi-
nality by
I(T
i j
)
. When matching two dissimilar tax-
onomies we speak of inter-matching whereas match-
ing the types of a taxonomy with itself (T
s
= T
t
) is
called intra-matching. Since equal mappings are not
relevant in the intra-matching case the set of relevant
relations is R ∈
{
<, >, ∼
}
.
3 TAXONOMY ALIGNMENT
PROCESS
Initially, the overall taxonomy alignment process is
described. The process consists of several new tech-
niques such as the instance enrichment algorithm,
the intersection ratio triple (IRT) metric and several
enhancements of the matching process that are pre-
sented in detail in Section 3.2 to 3.4.
3.1 Overall Alignment Process
The general taxonomy alignment process is depicted
in Figure 2. The overall idea is to retrieve mappings
for the taxonomy types by a matching process. Based
on the mappings a global taxonomy G is derived. This
taxonomy G reflects all types of the individual tax-
onomies T
i
and the relations between the particular
types (expressed in the mappings). Before the map-
pings are integrated they can optionally be cleaned
(e.g., by detecting cycles within the graph) and com-
plemented by new mappings (e.g., by exploiting the
given hierarchical structure) in a mapping rewrite step
as done by existing ontology matching tools like AS-
MOV (Jean-Mary et al., 2009). However, this step is
beyond the scope of this paper and will be described
in future work. In order to integrate n taxonomies
n
2
inter-matching processes and n intra-matching
processes are applied within our taxonomy alignment
process. Each of these inter-matching processes takes
two taxonomies as input and identifies equivalence,
hierarchical and associative mappings between the
types of these taxonomies. The intra-matching pro-
cesses discover hierarchical and associative mappings
within one taxonomy in order to validate and cor-
rect/enhance the existing taxonomy structures.
MappingTextMiningTaxonomies
7

The inter-matching process is implemented by
a combined matcher consisting of a schema-based
and an instance-based matcher. The schema-based
matcher exploits the names of the taxonomy types
(e.g., T
1
.a and T
2
.i in Figure 2) and is able to iden-
tify candidates for equivalence mappings. If suffi-
cient meta data is available for the taxonomies, the
schema-based matcher can be extended with matchers
that additionally take into account the descriptions or
the structures of the input taxonomies. The instance-
based matcher exploits the instances of the taxonomy
types to identify mapping candidates. The instances
of the taxonomy types are retrieved by a new itera-
tive instance enrichment algorithm that we present in
Section 3.2. Furthermore the instance-based matcher
applies a novel similarity metric – the intersection ra-
tio triple (IRT) – that allows to identify equivalence,
hierarchical as wells as associative relations between
the taxonomy types. We will present the metric in
Section 3.3 and give details on the inter- and intra-
matching process in Section 3.4.
The intra-matching process uses a slightly ad-
justed version of the instance-based matcher. A com-
bination with a schema-based matcher is not neces-
sary as equivalence mappings are irrelevant here. The
results of the intra-matching process can be used to
bring structure into flat taxonomies and check and
correct given taxonomy structures.
3.2 Instance Enrichment Algorithm
Usually, no instances are directly available for text
mining taxonomies. To follow an instance-based
matching approach as proposed in Section 3.1 the tax-
onomy needs to be enriched with instance data (if
complete sets of instances are already available for
all services the instance enrichment step can be omit-
ted). In the following we propose an instance enrich-
ment algorithm applicable for named entity recogni-
tion (NER) services and their taxonomies. However,
the general process can be transferred to other text
mining services and their taxonomies.
Instances of an entity type can be obtained by ex-
ecuting the services on text documents and collecting
the extracted information. Depending on the service,
concrete text instances (e.g., the text snippet Barack
Obama) can be assigned to several entity types (e.g.
Person, Politician, USPresident) or to only one of
those types (e.g. USPresident as it is the narrowest
entity type).
The general idea of the instance enrichment algo-
rithm is to enter a number of text documents into each
of the text mining services whose taxonomies are to
be matched. The NER results of the services (i.e., the
Service S
1
-
Service S
2
-
... ...
Service S
n
-
D
start
Text
-
A
A
A
A
AU
Q
Q
Qs
A
h
B
m
C D
g
i
ii
m
iii
a
i
d
b
g
c
@
@R
-
I(T
i j
)
I(T
i j
)
< x
Tokenize T
i j
Search & Select
6
Text
D
iter
3
P
P
Pq
Figure 3: general instance enrichment process.
text snippets with assigned categories) are grouped by
each entity type for each service. In order to consider
the entity disambiguation feature (e.g., Paris is rec-
ognized as City and in another context as Person) the
context of the entity instances (i.e., document name
and position) is attached to the text snippet.
It is obvious that the generated instances are di-
rectly depending on the document set and the quality
of the text mining services. We observed that only
a subset of the entity types from the extraction tax-
onomies we took into account were enriched with in-
stances when taking arbitrary text documents. For
that reason we propose an iterative instance enrich-
ment algorithm for the taxonomies T
i
of the consid-
ered services S
i
(i = 1, 2, ..., n) as follows (see Figure 3
for an illustration of the iterative process):
1. Randomly select a fixed number of documents
D
start
from a document base that covers a huge
amount of different concepts (e.g., articles from
Wikipedia). Set D = D
start
, iter = 0 and cre-
ate empty instance sets I(T
i j
) for each element
T
i j
∈ T
i
for each of the taxonomies T
i
.
2. Enter the documents D into the text mining ser-
vices S
i
and cluster the results on the entity types
T
i j
∈ T
i
for each taxonomy. Add the retrieved in-
stances into the instance sets I(T
i j
).
3. Select the entity types T
i j
without any instances
(optionally: with less than x instances) in the in-
stance sets I(T
i j
) (i.e.,
I(T
i j
)
= 0 or < x). If the
number of those entity types is zero stop the itera-
tion, else tokenize the names of these entity types.
4. Search the document base by using the particu-
lar extracted tokens as search string (e.g., search
Wikipedia). Take the f first results of this search
not yet having been included in D and add these
documents to D
iter
.
5. Set D = D
iter
, increment iter and go on with step
2. Iterate as long as the fixed maximum number
of iterations iter
max
is reached or step 3 aborts the
process.
The process for the generation of a qualified docu-
KDIR2013-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
8

T
t
A
AU
T
s
B
B
BBN
mat
inst
-
Sim
IRT
Trans
-
Sim
trans
mat
schema
-
Sim
-
Sel
t
-
Sim
sel
H
Hj
Agg
max
-
Sel
delta
-
Sim
equal
-
(T
s j
, T
tk
, ≡)
-
?
Di f f
-
Sel
IRT
-
(T
s j
, T
tk
, <)
(T
s j
, T
tk
, >)
(T
s j
, T
tk
, ∼)
Figure 4: Combined Matching Strategy.
ment set described here can be automatically executed
and therefore fits perfectly for a self-acting matching
process. With our adaptive approach we are able to
retrieve a high number of instances with only few ser-
vice calls. This is important since calling services
takes time and is costly.
3.3 IRT Metric
In this section, we present our novel similarity met-
ric for instance-based matchers that is able to indicate
equivalence, hierarchical and associative relations be-
tween the elements of two taxonomies T
s
and T
t
. Ad-
ditionally it allows to identify hierarchical and as-
sociative relations within one taxonomy, when used
with slightly changed parameters.
It is a common technique within instances-based
matchers to rate the similarity of two taxonomy el-
ements T
s j
∈ T
s
and T
tk
∈ T
t
by analyzing instance
overlaps and to represent them by a similarity metric.
We propose a novel metric that consists of three sin-
gle values to represent equivalence, hierarchical and
associative relations. The metric adopts the corrected
Jaccard coefficient presented by Isaac et al. (2007):
JCcorr(T
s j
, T
tk
) =
q
I(T
s j
) ∩ I(T
tk
)
×
I(T
s j
) ∩ I(T
tk
)
− c
I(T
s j
) ∪ I(T
tk
)
In contrast to the original Jaccard coefficient, that
is the ratio of the instance intersection size and the
size of the union of the instances, the corrected
Jaccard coefficient considers the frequency of co-
occurring instances with its correction factor c. It as-
signs smaller similarity scores to element pairs whose
instances co-occur less frequently. That means, that a
smaller score is assigned to one co-occurring instance
in a union set of two instances compared to 100 co-
occurring instances in a 200 instances large union set
(the classical Jaccard coefficient would assign 0.5 to
both cases). For details how to configure c please re-
fer to Isaac et al. (2007).
We rely on this basic metric as it allows us to deal
with possible data sparseness of the instances deter-
mined with our instance enrichment process. Addi-
tionally, the instances retrieved from text mining ser-
vices have some quality restrictions that need to be
handled. Text mining faces the problem of potentially
being inaccurate. Thus, the instances can include
false positives (i.e., instances having been extracted
wrongly) and for some services miss false negatives
(e.g., instances that should be extracted, but having
eventually only been extracted by some services).
In order to handle these quality restrictions, we
propose an extension of the corrected Jaccard met-
ric as follows: We introduce a weakening factor w
that reduces a negative effect of instances only found
by one of the services. The factor is trying to cor-
rect the influence of the false positives and negatives
of the NER process. Therefore the set of distinct in-
stances I
d
(T
s j
) and I
d
(T
tk
) that were only extracted by
one of the services (independent from the entity type
assigned to them) are integrated in the corrected Jac-
card factor weakened by w:
JCcorr
+
(T
s j
, T
tk
) =
q
I(T
s j
) ∩ I(T
tk
)
×
I(T
s j
) ∩ I(T
tk
)
− c
I(T
s j
) ∪ I(T
tk
)
− w
I
d
(T
s j
)
− w
|
I
d
(T
tk
)
|
with I
d
(T
s j
) ⊆ I(T
s j
) \
S
A∈T
t
I(A),
I
d
(T
tk
) ⊆ I(T
tk
) \
S
B∈T
s
I(B) and 0 ≤ w ≤ 1
Figure 5 exemplarily depicts the interrelationships be-
tween the quality restrictions (e.g., “EADS” as false
negative annotation for OpenCalais) and the distinct
instances (data was retrieved from Figure 1).
Figure 5: Example for quality restrictions.
The similarity value retrieved by the JCcorr
+
co-
efficient enables decisions on the equality of two tax-
onomy types. If the value is close to 1 it is likely
that the type T
s j
is equal to T
tk
, if the value is 0, the
two taxonomy types seem to be unequal. However,
the similarity value does not provide an insight into
the relatedness of the two types, when the value is
neither close to 1 nor 0. Let us consider the type
Company and the type AerospaceCompany. The ex-
tended corrected Jaccard value would be very small
– only those company instances of the Company type
MappingTextMiningTaxonomies
9

that are aerospace companies might be in the inter-
section, whereas the union set is mainly determined
by the instance size of the type Company. In order to
detect subtype and associative relations we introduce
two more measures JCcorr
+
T
s j
and JCcorr
+
T
tk
rating the
intersection size per type:
JCcorr
+
T
s j
(T
s j
, T
tk
) =
p
|
I(T
s j
) ∩I(T
tk
)
|
× (
|
I(T
s j
) ∩I(T
tk
)
|
− c)
|
I(T
s j
)
|
− w
|
I
d
(T
s j
)
|
JCcorr
+
T
tk
(T
s j
, T
tk
) =
p
|
I(T
s j
) ∩I(T
tk
)
|
× (
|
I(T
s j
) ∩I(T
tk
)
|
− c)
|
I(T
tk
)
|
− w
|
I
d
(T
tk
)
|
These coefficients are the ratio of the intersection size
of the instance sets of the two elements T
s j
and T
tk
and
the size of one of the instance sets (the instance set
I(T
s j
) and I(T
tk
) respectively). All three intersection
values together (JCcorr
+
, JCcorr
+
T
s j
, JCcorr
+
T
tk
) form
the intersection ratio triple (IRT). We can monitor the
following states for the values of the IRT metric:
• If all three values are very high, it is very likely
that the elements for which the measures were
calculated are equal, i.e., the mapping (T
s j
, T
tk
, ≡)
can be derived.
• If JCcorr
+
T
s j
is high and the difference diff
T
tk
of
JCcorr
+
and JCcorr
+
T
tk
is close to zero, it is an
indication that the element T
s j
is a subtype of T
tk
,
i.e., the mapping (T
s j
, T
tk
, <) can be derived.
• If JCcorr
+
T
tk
is high and the difference diff
T
s j
of
JCcorr
+
and JCcorr
+
T
s j
is close to zero, it is an
indication that the element T
tk
is a subtype of T
s j
,
i.e., the mapping (T
s j
, T
tk
, >) can be derived.
• If none of the three states above yields, but at least
one of the IRT-values is clearly above zero the ele-
ments T
s j
and T
tk
are associated, i.e., the mapping
(T
s j
, T
tk
, ∼) can be derived.
The IRT metric can also be applied for intra-matching
processes. However, the weighting factor is set to 0,
i.e., the corrected Jaccard coefficient (and the modi-
fied corrected Jaccard coefficients for the second and
the third value of the IRT) is used in fact. In the fol-
lowing we show how our novel metric is used within
our combined matcher.
3.4 The Matching Process
As already described we use a complex matching
strategy that combines both schema-based and
instance-based matcher in a single matching process.
The combination strategy is visualized in Figure 4.
The strategy consists of a number of operators that
are commonly used in schema matching such as se-
lection (Sel), aggregation (Agg) and matching (mat).
Moreover two additional operators (Trans and Di f f )
are included that are needed for processing the IRT
matcher results. The process starts by executing the
schema- and our instance-based matcher (mat
schema
and mat
inst
). They take as input the two taxonomies
T
s
and T
t
and calculate a similarity matrix consist-
ing of |T
s
| × |T
t
| entries (Sim and Sim
IRT
). Each
entry of the Sim-matrix is a value between 0 and 1
with 0 representing low and 1 representing high sim-
ilarity between two pairs of elements from the input
taxonomies. The similarity values of this matrix are
calculated by a simple name-matcher as proposed in
COMA++ (Do and Rahm, 2002). In contrast to that,
the entries of the Sim
IRT
-matrix are composed of the
three values computed by our IRT metric (see an ex-
emplary IRT-matrix in Figure 2).
For equal mappings, we trust in the most likely
matching candidates identified by the schema-based
matcher. As discussed, the naming of taxonomy types
is typically clear and precise and therefore name-
matchers tend to have a very high precision. With
a selection operation Sel
t
the most probable matching
candidates are extracted. This operation sets all ma-
trix entries below a given threshold to 0 and all others
to 1. We pick a high selection threshold (0.8) to min-
imize the chance to select wrong mappings.
To simplify the combination of the Sim
IRT
ma-
trix and the Sim
sel
matrix, the Sim
IRT
matrix is trans-
formed by a transformation operation Trans. It maps
the three IRT values to one value that expresses the
probability that the two taxonomy elements are equal.
Different transformation operations are possible. A
trivial transformation operation trans
triv
just takes the
first IRT value (the extended corrected Jaccard coef-
ficient JCcorr
+
) or the average of all three values.
However, such a trivial transformation may lead to
false positive equal mappings since some identified
candidates may rather be subtype mappings. As al-
ready mentioned in Section 3.3 a very low difference
value diff
T
s j
and diff
T
tk
respectively, may indicate a
hierarchical relation. We therefore propose a trans-
formation that lowers the similarity values for such
cases:
trans =trans
triv
− corr
sub
corr
sub
=
0 max diff of IRT values<0.2
z · e
−λ·diff
T
s j
JCcorr
+
T
s j
< JCcorr
+
T
tk
z · e
−λ·diff
T
tk
JCcorr
+
T
s j
> JCcorr
+
T
tk
with λ > 0 and 0 ≤ z ≤ 1
The transformation relies on an exponential function
KDIR2013-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
10

to weight the influence of the difference values (diff
T
s j
or diff
T
tk
) on the transformation result. In particular
when the three IRT values are not very close to each
other (i.e., having a maximal difference greater than
0.2) the exponential function is applied. The subtype
correction corr
sub
has the biggest value if the differ-
ence is zero and then exponentially decreases to zero.
The λ value defines how strong the value decreases.
Example: With λ = 20 and a difference value of 0.05
the value trans
triv
is decreased by 0.368. For λ = 100
the decrease is only 0.007. The correction value can
be further adapted by a weight z that can be based on
the value of JCcorr
+
T
s j
and JCcorr
+
T
tk
respectively.
The selected similarity matrix Sim
sel
is combined
with the transformed similarity matrix Sim
trans
of the
instance-based matcher with a MAX-Aggregation op-
eration Agg
max
. For each pair of entity pairs the max-
imum of the two matrix entries (one entry from the
Sim
sel
and one from Sim
trans
matrix) is taken. The
result of the mapping aggregation still contains up to
|T
s
| × |T
t
| correspondences. From these correspon-
dences the most probable ones need to be selected. A
number of selection techniques have been proposed
in literature (see Do and Rahm, 2002). We apply
the MaxDelta selection from Do and Rahm (2002) in
Sel
delta
since it has shown to be an effective selec-
tion strategy. MaxDelta takes the maximal correspon-
dence within a row (or column) of a similarity matrix.
Additionally, it includes correspondences from the
row (or column) that are within a delta-environment
of the maximal correspondence. The size of the delta
environment depends on the value of the maximal ele-
ment for each row (or column). Both sets of maximal
correspondences for each row and correspondences
for each column are intersected to get the final se-
lection result Sim
equal
. Finally, equality mappings are
created from the selected matrix Sim
equal
for each ma-
trix entry above a given threshold.
Subtype and associative mappings are directly de-
rived from the Sim
IRT
matrix. However, all equal-
ity mapping candidates are eliminated from the ma-
trix (Di f f ) before a fine granular selection operation
Sel
IRT
is applied. Sel
IRT
derives subtype mappings
if JCcorr
+
T
s j
(or JCcorr
+
T
tk
) is above a given thresh-
old and if diff
T
tk
(or diff
T
s j
) is smaller than a distance
threshold. All remaining matrix entries that are not
selected as subtype mappings but indicate a certain
overlap of the instances are categorized as associa-
tive mappings if one of the three IRT values is signif-
icantly above zero.
The presented strategy can be adaptively fine-
tuned by analyzing the results of the schema-based
matcher. Differing strength and performance of the
extraction services for which taxonomies are matched
can be identified. For instance, if the text mining
service S
s
is consistently stronger than the service
S
t
, we can observe the following: The instance set
I(T
tk
) is included in the instance set I(T
s j
) even if the
two taxonomy types T
s j
and T
tk
are identical (i.e., the
schema-based matcher indicates an equivalence rela-
tion). For those cases a transformation which corrects
subtypes is not recommended. Additionally the se-
lection thresholds can be adapted by observing the
instance-matching values for which equivalence rela-
tions hold.
4 EXPERIMENTAL SETUP
Before we present the results of our experiments in
matching entity taxonomies of text mining services
in Section 5, we give an overview of the experimen-
tal setup. The goal of the experiments was to evalu-
ate if our automatic matching approach is applicable
for matching taxonomies of text mining services and
if our novel metric performs better than traditional
approaches. All datasets and manually created gold
standards are available upon request.
4.1 Dataset
We evaluated our approach on three entity taxonomies
of public and well known text mining services, that
are OpenCalais (2013), AlchemyAPI (2013) and Evri
(2012). We only considered the taxonomies that are
provided for English text. The entity taxonomy of
OpenCalais is documented on the service website
and in an OWL ontology. It consists of 39 main
entity types that are partially further specified with
predefined attributes (e.g., the entity Person has the
attributes PersonType, CommonName, Nationality).
The Type-attributes allow to derive entity subtypes
(e.g., Person Sports, Person Entertainment). All in
all the OpenCalais taxonomy consist of 58 entity
types. AlchemyAPI documented its entity types clas-
sified in a two-level hierarchy on the service website.
We observed that not all types AlchemyAPI extracts
are listed on the service website. That is why we
extended the taxonomy with types having been ex-
tracted during the instance enrichment process. All
together the taxonomy then consists of 436 types.
Evri does not provide an overview of the entity types
the service can extract. However, it was possible to
extract information via service calls (by first retriev-
ing facets and then requesting the entities and subenti-
ties for these facets). The Evri taxonomy constructed
from the service calls is made up of 583 types.
MappingTextMiningTaxonomies
11

4.2 Gold Standard
So far no mappings between the taxonomies of text
mining services exist. In order to evaluate the qual-
ity of the mappings retrieved with our approach, we
manually produced a gold standard. To minimize the
matching problem we sampled the more than 180,000
entity type pairs by selecting only those entity pairs,
for which the generated instances overlapped (i.e.,
both entity types had at least one instance in com-
mon). The remaining roughly 4,500 entity type pairs
were used for human evaluation. We assume that the
influence of sampling the entity type pairs is marginal
– if there was no overlap of the instance sets retrieved
by our instance enrichment algorithm it is unlikely
that there will be any overlap of the instances and a
potential relation between the taxonomy types when
using the services on arbitrary text documents.
In an online evaluation the entity type pairs plus
some sample instances and links to the taxonomies
were presented to approximately 40 people. They had
to assign the relations “equivalent to”, “broader than”,
“narrower than”, “related to” and “no link” to each of
the pairs (if unsure they were able to skip the decision)
as long as they liked to go on. The online evaluation
was run as long as a minimum of two ratings per en-
tity type pair were retrieved. All entity pairs with dif-
ferent ratings were manually checked and a decision
for the best rating in consideration of the two entity
types was taken (that had been the case for around
1000 entity pairs). The gold standard was further re-
fined when wrong/missing gold standard mappings
were identified during the evaluation phase. Over-
all the imprecision of the information retrieved by the
online evaluation was surprisingly high and again in-
dicated that a manual matching and integration of the
text mining taxonomies is not feasible.
We use three values to rate the quality of the re-
trieved mappings compared to the gold standard: pre-
cision, recall and F-measure. Precision is the ratio of
accurately identified mappings (i.e., the ratio of the
retrieved mappings being in the gold standard and the
retrieved mappings). Recall marks the ratio of map-
pings within the gold standard that were identified by
the matcher. The F-measure is the harmonic mean of
precision and recall and is a common metric to rate the
performance of matching techniques. We consider a
matcher to be as good as the F-measure is.
4.3 Matcher Configurations
We experimented with different configurations of our
instance-based matcher and determined the best set-
ting - a Jaccard correction factor c = 0.6 and a weight
w to 0.95 (i.e., integrated the instances only retrieved
by one of the services to five percent into the calcu-
lations). We achieved good results with a transforma-
tion operation using the average of the three IRT val-
ues slightly corrected by the exponential function as
given in Section 3.4. We scaled this correction down
or rather ignored it, when observing strongly differ-
ing service strength (that was the case, when match-
ing the taxonomy of the OpenCalais service with the
taxonomies of the weaker services AlchemyAPI and
Evri). The selection threshold for retrieving equal-
ity mappings was set to 0.2 when used stand alone
and to 0.5 when used in the combined matcher. For
the subtype selection operation we used a threshold
of 0.65 and a distance threshold of 0.05 within inter-
matching processes and a threshold of 0.9 and 0.001
within intra-matching processes.
We compared our instance-based matching ap-
proach and the IRT metric to common metrics of
instance-based matching systems: for equality map-
pings we compared against the Dice and the corrected
Jaccard metric, for hierarchical mappings against the
SURD metric. The selection thresholds of Dice and
corrected Jaccard were set to those values for which
the highest average F-measure could be retrieved
(Dice: 0.1, corrected Jaccard with correction factor
0.8: 0.05.). For SURD we used the threshold pro-
posed in (Chua and Kim, 2012) – ratios below 0.5 are
low values, ratios above 0.5 are high values. Indepen-
dent from the used metric the instance intersections
were determined by comparing the strings of the in-
stances and only accepting exact matches for the in-
tersection. Moreover, the Sel
delta
selection techniques
described in Section 3.4 was applied in all cases.
5 EXPERIMENTAL RESULTS
In the following we present our experimental results
proving that our approach is applicable for matching
taxonomies of text mining services. We start with
the evaluation of the instance enrichment algorithm
in Section 5.1 to show that the iterative process can
be applied to retrieve a meaningful set of instances.
Afterwards we compare the IRT metric to state-of-
the-art metrics for instance-based matching in Sec-
tion 5.2. Finally, we rate the performance of the over-
all intra- and inter-matching processes in Section 5.3.
5.1 Instance Enrichment
First of all we evaluated our instance enrichment pro-
cess presented in Section 3.2. We used the English
Wikipedia articles as a document base. Furthermore,
KDIR2013-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
12
we set iter
max
= f = 1 and slightly adapted the itera-
tion process as follows: (1) The start documents were
selected from articles of the Wikipedia category Fea-
tured articles
1
. (2) We split step 4 into step 4a doing
the search with the extracted token as search string
and 4b doing the search among Wikipedia lists. This
extension was implemented as it is more likely to find
instances for the entity type in a list connected to it
(and possibly including an enumeration of instances)
than in an article about it.
Figure 6: Instance enrichment with a) 50 randomly selected
featured Wikipedia articles, b) extension to 100 articles, c)
extension with Wikipedia search of respective tokenized en-
tity types without instances, d) extension with search for the
other services.
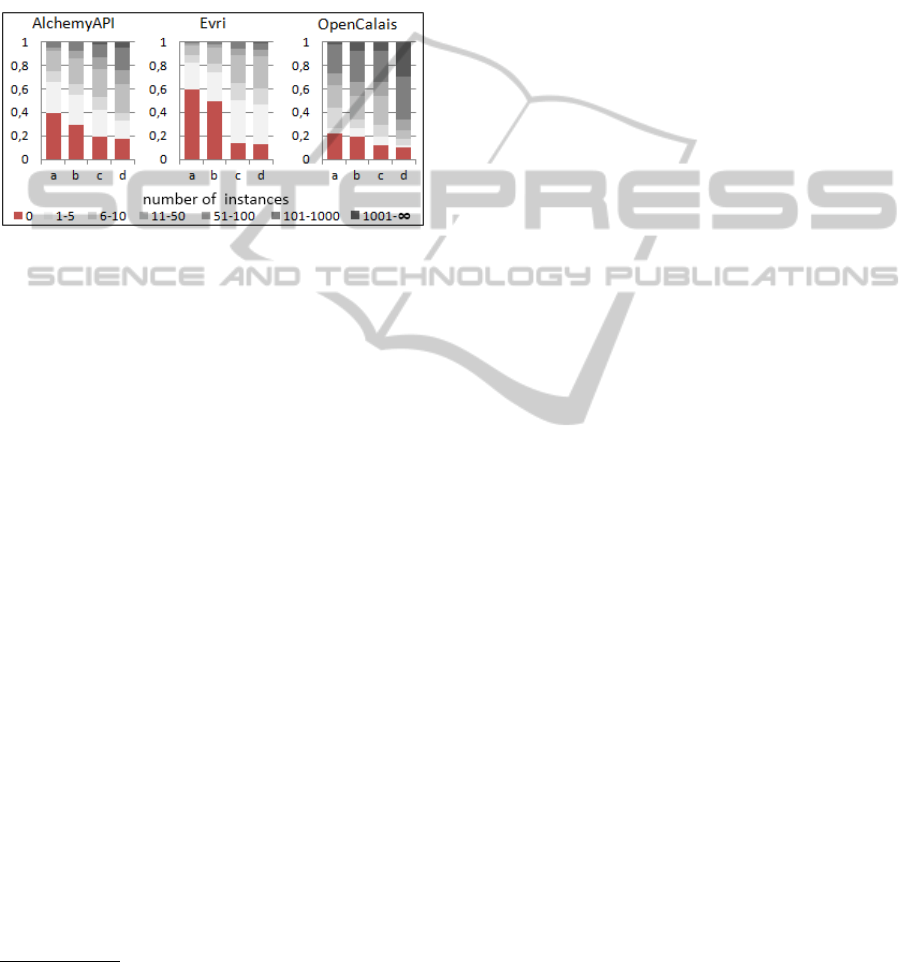
The gains we made with respect to the coverage
rate of the entities when applying the instance enrich-
ment algorithm are outlined in Figure 6. One can see
that the focused extension of the document set im-
proved the coverage rate significantly. However, we
observe that even after this extensive process a lot
of entity types remain with no or few instances. Al-
though it seems to be a trivial process to generate in-
stances for the entity types it is more complex than
expected. Reasons for this are: the partly very com-
plex entity type taxonomies, the occurrence of very
specific types in the hierarchies and apparently also
the inability of the services to extract all the types of
their taxonomy.
5.2 Comparison of Similarity Metrics
We compared the IRT metric to Dice, corrected Jac-
card and SURD and analyzed the performance regard-
ing the identification of equal and subtype mappings
(see Section 4.3 for the matcher configurations). The
results of the comparison are depicted in Figure 7,
in which OC-AA indicates the matching process be-
tween the OpenCalais and the AlchemyAPI taxon-
omy, OC-E between OpenCalais and Evri, E-AA be-
1
Featured articles are articles that are considered to be
the best in Wikipedia. At the time of our evaluation there
had been 3,269 featured articles in the English Wikipedia.
tween Evri and AlchemyAPI and avg the average be-
tween the three values.
Figure 7 a) shows the F-Measure for retrieving
equality mappings. We were able to slightly increase
the average F-measure compared to the classical met-
rics Dice and corrected Jaccard. When individually
setting the threshold (e.g., by using the schema-based
matcher as indicator) the F-measure as well as pre-
cision and recall can be again increased (IRT ideal).
Independent from the specific metric used the per-
formance for the matching process between Evri and
AlchemyAPI is worse than the other two matching
processes. Reasons for this are on the one hand rela-
tively few instances used for the matching and on the
other hand the big performance difference of the two
services. We detected that in average equal types only
have 30% in common and it is therefore very hard to
detect all mappings correctly.
Figure 7 b) presents the results for the identifi-
cation of subtype mappings. One can see, that the
IRT metric can significantly raise the recall (nearly
30%) by keeping the same good precision like the
SURD metric. Thereby the F-measure can be in-
creased by nearly 20% which proves that our IRT met-
ric is suited much better for the matching of text min-
ing taxonomies.
5.3 Overall Matching Process
We applied the instance enrichment algorithm, the
IRT metric and the combined matching strategy for
the intra- and the inter-matching processes. The per-
formance results are given in Figure 8. We com-
pared the mapping results of the intra-matcher to the
relations given within the taxonomy structure. Our
approach covered exactly the relations given within
the OpenCalais taxonomy. On the contrary, the map-
pings retrieved by our matching approach and the re-
lations of the AlchemyAPI and Evri taxonomy dif-
fered. However, this discrepancy is not a result of the
inability of our approach, but rather an indication that
the taxonomies are not structured accurately. Aircraft-
Designer is for example listed as a Person subtype in
the taxonomy used by AlchemyAPI. In practice air-
craft designing companies instead of persons are an-
notated with this type. On the other hand, the flat
structure of the taxonomies ignores relations within
the subtypes of an entity. USPresident and Politician
are both subtypes of Person (which is given in the tax-
onomy) and the former is in addition a subtype of the
latter (this information was retrieved by our approach,
but is not represented in the taxonomy). The results
show that overreliance on the given taxonomy struc-
tures is not reasonable. Instead our approach should
MappingTextMiningTaxonomies
13
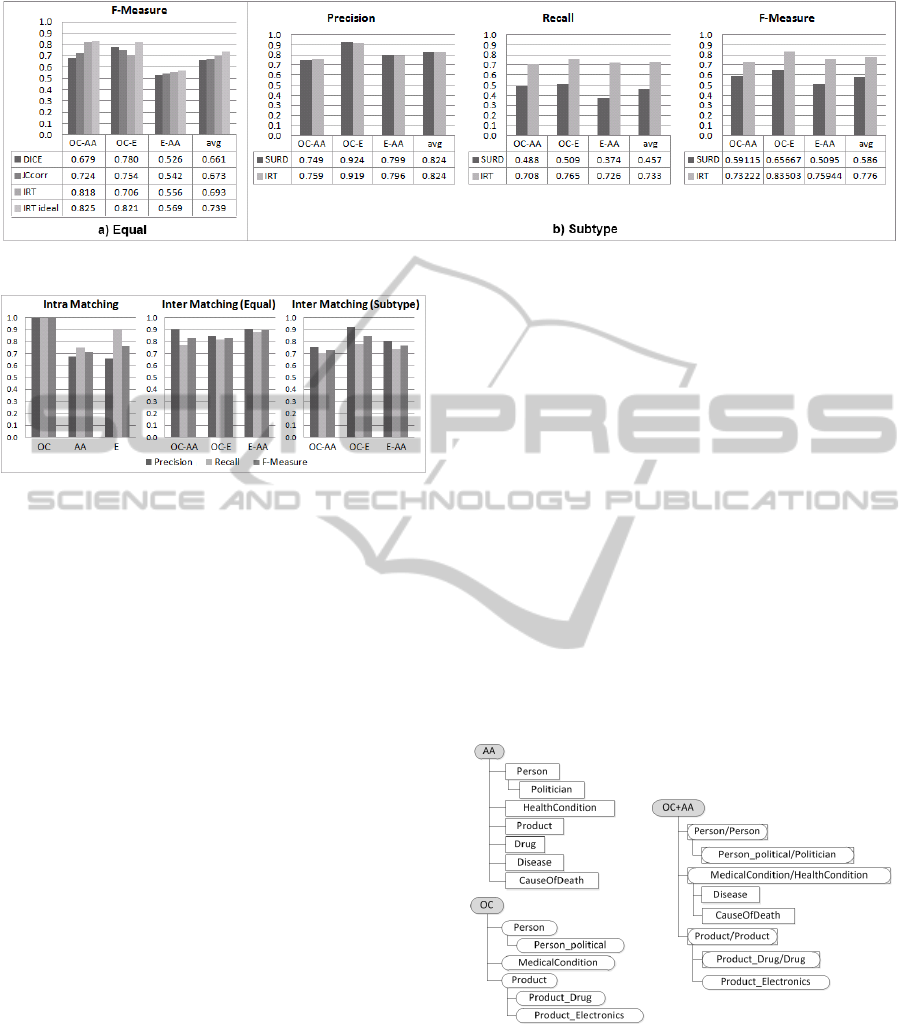
Figure 7: Comparison of similarity metrics.
Figure 8: Performance of our matching approach.
be used to validate and correct the taxonomy struc-
ture.
The results for the inter-matching processes
clearly show that a combination of schema- and
instance-based matcher improves quality. The F-
measure has been raised by more than 15% compared
to the instance-based matcher only approach (see Fig-
ure 7). An average F-measure of 85% for equal and
77% for subtype shows that an automatic matching of
text mining taxonomies is possible. We observed that
in average 63% of the wrong subtype mappings and
16% of the missed subtype mappings can be traced
back to instance scarcity (i.e., have five or less in-
stances in the intersection). One quarter of the missed
equal mappings result from instance scarcity too. In-
creasing the amount of instances (e.g., by allowing
more iterations in the instance enrichment process)
and adapting the parameters for each matching pro-
cess separately (e.g., by using the name-matcher as an
indication for the thresholds) quality can be increased.
6 APPLICATION OF TAXONOMY
ALIGNMENT
In order to illustrate the value of computing taxon-
omy alignments between extraction services we im-
plemented a web news analysis application. We show
that the following issues can be solved by combining
multiple services and their annotation results: (1) The
number of identified entities per category is often very
small for a single service. Merging result from multi-
ple services could increase the number of entities per
category. (2) By combining taxonomies existing cat-
egorizations can be refined. (3) Individual strength of
services are combined.
The computed mappings between OpenCalais and
AlchemyAPI retrieved within our experimental eval-
uation (see Section 5.3) are taken and an integrated
taxonomy/graph of categories is automatically con-
structed. A small subset of entity types from both ser-
vices and the merged taxonomy is shown in Figure 9.
The merged taxonomy consists of categories from
AlchemyAPI(AA) and OpenCalais(OC). For equal
matches the categories were merged. The merged
taxonomy brings structure to flat lists of categories.
For instance in AA Disease, CauseOfDeath, Medical-
Condition were in no special relation. In the merged
taxonomy, Disease and CauseOfDeath are now sub-
types of MedicalCondition.
Figure 9: Merging Taxonomies AA and OC.
By using both services we analyzed web news en-
tries from Reuters Top-News Archives from Septem-
ber and October 2012. All news are annotated and
found entities are collected by day. The number of
found entities per day can be visualized as sparkline
diagrams (see Figure 10) which help to identify inter-
esting, possible hot topics. Peaks point to days where
a specific type of entity was identified particularly
KDIR2013-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
14
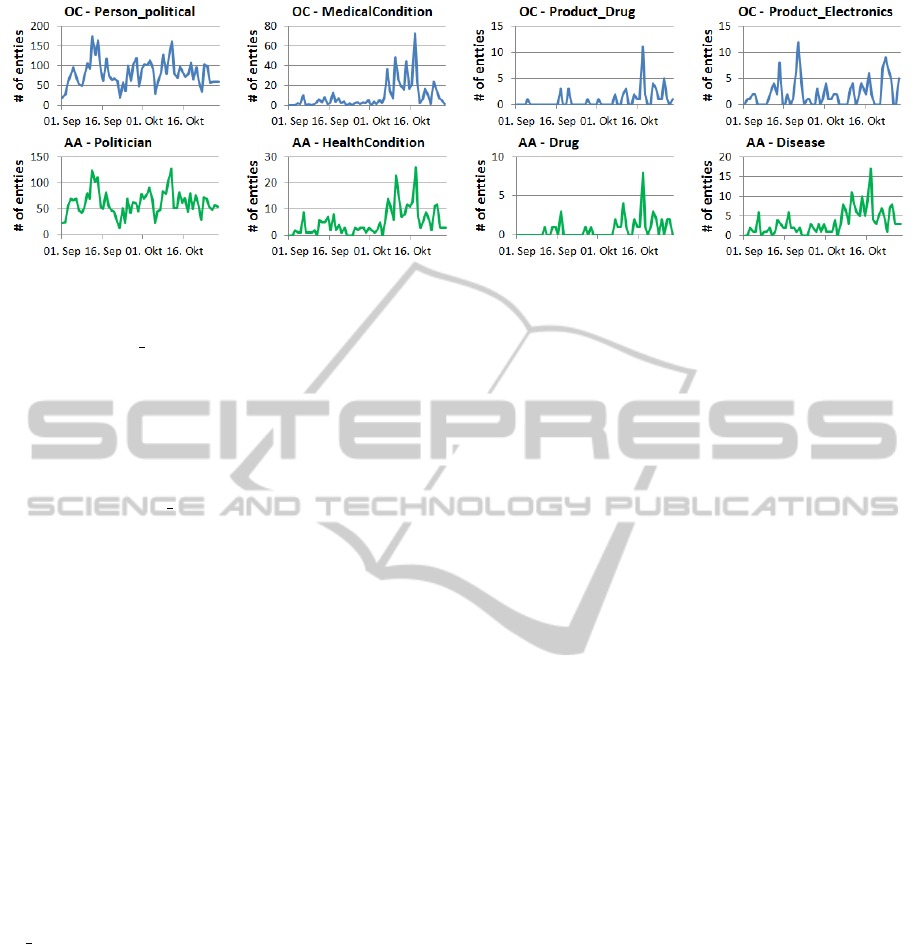
Figure 10: Sparkline diagramms.
often. The automatic taxonomy alignment process
identified Person political (OC) and Polititian (AA)
as well as MedicalCondition (OC) and HealthCon-
dition (AA) as equal matches. That these computed
mappings are correct can now be verified quite well
by the similarity of the generated sparklines of entity
frequencies per day.
Some entity types can only found by one of the
services like Product Electronics (OC). The first peak
on September 21st relates to the Iphone 5 release
whereas on October 24th Apples “Ipad mini” was
presented. Both events could not be observed with
AlchemyAPI due to the missing category. Thus the
combination of both services is reasonable. For the
politicians, both sparklines have similar peaks, one
on September 12 and October 12. For instance, on
September 12 or shortly before, an attack on the
US Embassy in Benghazi (Lybia) took place. Many
news articles referred to comments that were given by
politicians which led to a peak for politicians. Simi-
lar peaks can be observed with MedialCondition and
HealthCondition. These peaks can be explained by a
severe outbreak of meningitis in the US which caused
a number of deaths. The reason for that outbreak
was a drug that was used for patients with back pain.
This also resulted in a peak for Drugs (AA) accord-
ingly. Still, the number of identified entities for Prod-
uct Drug (OC), Drug (AA) are very low. Merging
found entities from both services would increase data
quality and therefore also other events of smaller scale
could possibly automatically be identified.
7 RELATED WORK
A number of matching systems have been devel-
oped that are able to semi-automatically match meta
data structures like taxonomies, ontologies or XSD
schemata (see Shvaiko and Euzenat, 2005; Rahm
and Bernstein, 2001). Most of these systems rely
on schema-based matching techniques, that consider
names, structure or descriptions of elements for
matching. For some test-cases they are able to iden-
tify equal mappings as we show in our evaluation.
However, schema-based techniques are not suited to
generate subtype or associative mappings when deal-
ing with flat taxonomies.
A number of existing matching systems like
QuickMig (Drumm et al., 2007), COMA++ (Do and
Rahm, 2002), RiMOM (Li et al., 2009) or Falcon (Hu
and Qu, 2008) rely on instance-based matching tech-
niques to find further correspondences when schema-
based matchers are not sufficient. Some of them look
for equality of single instances (Drumm et al., 2007;
Hu and Qu, 2008; Li et al., 2009), others employ met-
rics that rely on the overlap of instance sets (Do and
Rahm, 2002). The latter rely on similarity metrics like
Jaccard, corrected Jaccard, Pointwise Mutual Infor-
mation, Log-Likelihood ratio and Information Gain
(see Isaac et al., 2007). Massmann and Rahm (2008)
apply the dice metric to match web directories from
Amazon and Ebay. All of these similarity metrics can
only be applied to retrieve equal mappings. More-
over, they only perform well when instance sets are
quite similar and strongly intersect. They do not con-
sider inaccurate and incomplete instances, like we do
with our IRT metric.
The PARIS system (Suchanek et al., 2011) em-
ploys a probabilistic approach to find alignments be-
tween instances, relations and classes of ontologies.
The system is mainly able to identify equivalence re-
lations but the authors also introduce an approach to
find subclass relations. However, they neither pre-
sented how to apply this approach in order to de-
cide for equivalence or subtype relations of classes
nor have they evaluated the identification of sub-
classes. Chua and Kim (2012) recently proposed a
metric of two coefficients to resolve the question how
to identify hierarchical relationships between ontolo-
gies. This metric is similar to our IRT metric, but does
not consider failures within the instances. Moreover,
due to relying on only two values and basic heuris-
MappingTextMiningTaxonomies
15

tics this metric is more inaccurate than the IRT metric
presented in this paper. By relying on three coeffi-
cients we can further refine relationships and besides
identifying equivalence and hierarchical relations also
identify associative relations between the types of two
taxonomies which can not be done with metrics pro-
posed so far.
Our instance enrichment approach is crucial since
it allows us to apply instance-based matching tech-
niques in the first place. Closest to that idea is the
QuickMig system (Drumm et al., 2007) where in-
stances have to be provided manually in a question-
naire. None of the existing systems is able to gener-
ate instances beforehand to apply instance matching
as we do in this paper. Moreover, we are the first to
apply ontology matching techniques for matching text
mining taxonomies.
8 CONCLUSIONS AND FUTURE
WORK
In this paper we presented a number of contributions
that help to automatically match and integrate tax-
onomies of text mining services and therewith en-
able the combination of several text mining services.
In particular we developed an instance enrichment
algorithm that allows us to apply instance match-
ing techniques in a complex matching strategy. We
proposed a general taxonomy alignment process that
applies a new instance-based matcher using a novel
metric called IRT. This metric allows us to derive
equality, hierarchical and associative mappings. Our
evaluation results are promising, showing that the
instance enrichment and matching approach returns
good quality mappings and outperforms traditional
metrics. Furthermore, the matching process again in-
dicated that the results of different text mining ser-
vices are very different, i.e., the instances of semanti-
cally identical taxonomy types are only partly over-
lapping (partly only 5% of the instances overlap).
This emphasizes the results from Seidler and Schill
(2011) that the quality and quantity of text mining can
be increased through the aggregation of text mining
results from different services. The presented taxon-
omy alignment process will allow us in future to au-
tomate the matching of text mining taxonomies and
subsequently the automatic merging of text mining re-
sults from different services.
REFERENCES
AlchemyAPI (2013). AlchemyAPI Homepage. http://
www.alchemyapi.com/. March 2013.
Chua, W. W. K. and Kim, J.-J. (2012). Discovering Cross-
Ontology Subsumption Relationships by Using On-
tological Annotations on Biomedical Literature. In
ICBO, volume 897 of CEUR Workshop Proc.
Do, H. H. and Rahm, E. (2002). COMA - A System for
Flexible Combination of Schema Matching Approach.
In VLDB Proc.
Drumm, C., Schmitt, M., Do, H.-H., and Rahm, E. (2007).
QuickMig: Automatic Schema Matching for Data Mi-
gration Projects. In CIKM’07 Proc.
Euzenat, J. and Shvaiko, P. (2007). Ontology Matching.
Springer-Verlag.
Evri (2012). Evri Developer Homepage. http://
www.evri.com/developer/. June 2012.
FISE (2013). Furtwangen IKS Semantic Engine project
page. http://wiki.iks-project.eu/index.php/FISE.
March 2013.
Grimes, S. (2008). Unstructured data and the 80 percent
rule. http://breakthroughanalysis.com/2008/08/01/
unstructured-data-and-the-80-percent-rule/.
Clarabridge Bridgepoints.
Hotho, A., N
¨
urnberger, A., and Paaß, G. (2005). A Brief
Survey of Text Mining. LDV Forum, 20(1):19–62.
Hu, W. and Qu, Y. (2008). Falcon-AO: A practical Ontology
Matching System. Web Semantics, 6(3):237–239.
Isaac, A., Van Der Meij, L., Schlobach, S., and Wang, S.
(2007). An Empirical Study of Instance-Based Ontol-
ogy Matching. In ISWC’07 Proc., pages 253–266.
Jean-Mary, Y. R., Shironoshita, E. P., and Kabuka, M. R.
(2009). Ontology Matching with Semantic Verifica-
tion. Web Semantics, 7(3):235–251.
Li, J., Tang, J., Li, Y., and Luo, Q. (2009). RiMOM: A Dy-
namic Multistrategy Ontology Alignment Framework.
TKDE, 21(8):1218–1232.
Massmann, S. and Rahm, E. (2008). Evaluating Instance-
based Matching of Web Directories. In WebDB’08
Proc.
OpenCalais (2013). Calais Homepage. http://
www.opencalais.com/. March 2013.
Rahm, E. and Bernstein, P. A. (2001). A Survey of Ap-
proaches to Automatic Schema Matching. The VLDB
Journal, 10:334–350.
Seidler, K. and Schill, A. (2011). Service-oriented Infor-
mation Extraction. In Joint EDBT/ICDT Ph.D. Work-
shop’11 Proc., pages 25–31.
Shvaiko, P. and Euzenat, J. (2005). A Survey of Schema-
Based Matching Approaches. Journal on Data Se-
mantics IV.
Suchanek, F. M., Abiteboul, S., and Senellart, P. (2011).
Paris: probabilistic alignment of relations, instances,
and schema. Proc. VLDB Endow., 5(3):157–168.
KDIR2013-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
16
