
The World vs. SCOTT
Synthesis of COncealment Two-level Texture
Julien Gosseaume, Kidiyo Kpalma and Joseph Ronsin
Universite Europeenne de Bretagne, 35000, Rennes, France
INSA, IETR, UMR 6164, F-35708, Rennes, France
Keywords:
COncealment, Two-level Texture, Concealment Texture, Texture Synthesis, Image Analysis, Human Visual
System HVS.
Abstract:
We propose an original method of Synthesis of COncealment Two-level Texture (SCOTT). SCOTT was de-
signed according to the Human Visual System so that the concealment texture is faithful to the visual environ-
ment it will be placed in, in terms of forms and colors. The results of simulation prove that the concealment
texture is efficient although it is made of simple forms and only a few colors. Even if SCOTT has initially
been designed for an application of reducing the visual pollution caused by manmade equipments (antenna,
electrical cabinets, distributor boxes, repeater shelters, etc.), it may be used in many applications, such as
inpainting, and even in image compression.
1 INTRODUCTION
We propose an original method of Synthesis of COn-
cealment Two-level Texture (SCOTT), which pro-
vides a texture faithful to the visual environment it
will be placed in, while having simple forms and only
a few colors. The purpose of a concealment texture
is to be both generic enough to be placed at differ-
ent positions and viewpoints in a scene, and accurate
enough to be efficient, at different scales. It is a trade-
off between genericity and efficiency. Based on the
Human Visual System, SCOTT synthesizes a “two-
level texture” which is a mix between a macro-texture
and a micro-texture. The macro-texture represents the
global aspect of the concealment texture, i.e. its dom-
inant forms. In case of a regular texture, the global
aspect is given by the primitives, like the bricks of
a brick wall. Similarly, the micro-texture represents
the local aspect of the concealment texture, i.e. the
details inside the dominant forms. In case of a reg-
ular texture, the local aspect is given by the random-
like distribution of colors inside the primitives, like
the appearance of “grain” at the surface of a brick.
So the concept of “macro” and “micro” depends of
the scale of observation. A macro-texture becomes a
micro-texture when observed at a longer distance; on
the contrary, a micro-texture becomes a macro-texture
when observed at a shorter distance. This duality can
be found in various natural (e.g. a pebble beach) and
artificial (e.g. a brick wall) structures. In the case
of a computer-generated texture, such a duality gives
the texture a visual richness which makes it more re-
alistic; we can compare the video games issued ten
years ago, and those recently issued: the richness of
the textures make them more “true”. It is important to
keep in mind that our goal is not to synthesize a tex-
ture exactly the same as a given visual environment;
our need requires a trade-off between genericity and
efficiency.
2 PROPOSED METHOD
SCOTT has been designed according to the the Hu-
man Visual System, and synthesizes a two-level tex-
ture, based on a mix of a macro-texture and a micro-
texture. The fusion of these two levels of texture gives
a realistic final texture, faithful to the visual environ-
ment it will be placed in.
2.1 Human Visual System
An object is concealed if it has the same dominant
colors and the same dominant forms as its visual en-
vironment (Julesz, 1999). These two global conceal-
ment rules, having the same dominant colors and the
same spatial frequency spectrum (dominant forms),
257
Gosseaume J., Kpalma K. and Ronsin J..
The World vs. SCOTT - Synthesis of COncealment Two-level Texture.
DOI: 10.5220/0004659502570264
In Proceedings of the 9th International Conference on Computer Vision Theory and Applications (VISAPP-2014), pages 257-264
ISBN: 978-989-758-003-1
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

are defined according how of the Human Visual Sys-
tem receives and processes the visual information.
The visual information is borne by the “color”, as a
sum of visible frequencies. These electro-magnetic
frequencies are received by the retina, and the color
perceived by the brain depends on the frequency re-
sponse of the rods and cones inside the retina. A user-
friendly way to represent the perceivable colors is the
HSV (Hue, Saturation, Value) colorspace. When one
sees an object, the color information is processed in
the primary visual cortex V1 to extract the color con-
trasts. These contrasts allow higher cortical areas to
extract forms, which may finally be identified by even
higher cortical areas (Buduc, 2012).
Then the HSV works like an interpreter, going
from concrete low-level pieces of information, that is
the electro-magnetic spectrum of the light received,
to abstract high-level semantic concepts (e.g.: “a blue
small car”).
So an object may be identified if there exists a con-
trast between this object and its visual environment,
in terms of colors or the distribution of the colors
(forms) (Landragin, 2004; Baumbach, 2010). In other
words, an object will not be identified, nor detected,
if it has the same colors, and the same forms (spatial
frequency spectrum), as its visual environment.
Even if such a representation of the HSV remains
very simplistic, its level of precision is enough for our
need: it is not to create an exhaustive model of the
HSV to make objects invisible (for the concealment
of distributor boxes, it would indeed be difficult to
maintain them if they cannot be located!), but to re-
duce the visual pollution by giving the “polluants” an
aesthetically more pleasing look. For further infor-
mation, the reader is invited to have a “look” at refer-
ences (Julesz, 1999; Buduc, 2012; Landragin, 2004;
Baumbach, 2010).
2.2 Synthesis of COncealment Two-level
Texture
From our study of the Human Visual System, we
defined two general concealment rules: “having the
same dominant colors” and “having the same domi-
nant forms”. SCOTT is then built around these two
components: computing the colors and the forms
(Julesz, 1999).
To make the concealment texture faithful to the
visual environment it will be placed in, it is synthe-
sized according to a two-level concept, like in the
case of a brick wall: the global aspect of the walls,
as a concatenation of bricks, is its macro-texture. So
the macro-texture (coarse texture) corresponds to the
dominant forms and colors of the concealment tex-
ture. And the local aspect of the wall, that is the de-
tails inside one particular brick, is its micro-texture.
So the micro-texture (fine texture) corresponds to the
secondary colors and forms of the concealment tex-
ture. In other words, the duality macro-texture/micro-
texture can be viewed as the duality global/local ap-
pearance of the texture, depending on the scale con-
sidered.
We have to keep in mind that the purpose of a con-
cealment texture is to be both generic enough to be
placed at different positions in a scene, and accurate
enough to be efficient, at different scales. It is a trade-
off between genericity and efficiency.
So SCOTT computes the concealment texture
from two input models: one model for the macro-
texture (coarse texture) and one model for the micro-
texture (fine texture); SCOTT first computes the
macro-texture and the micro-texture independently,
and then mixes them to synthesize the concealment
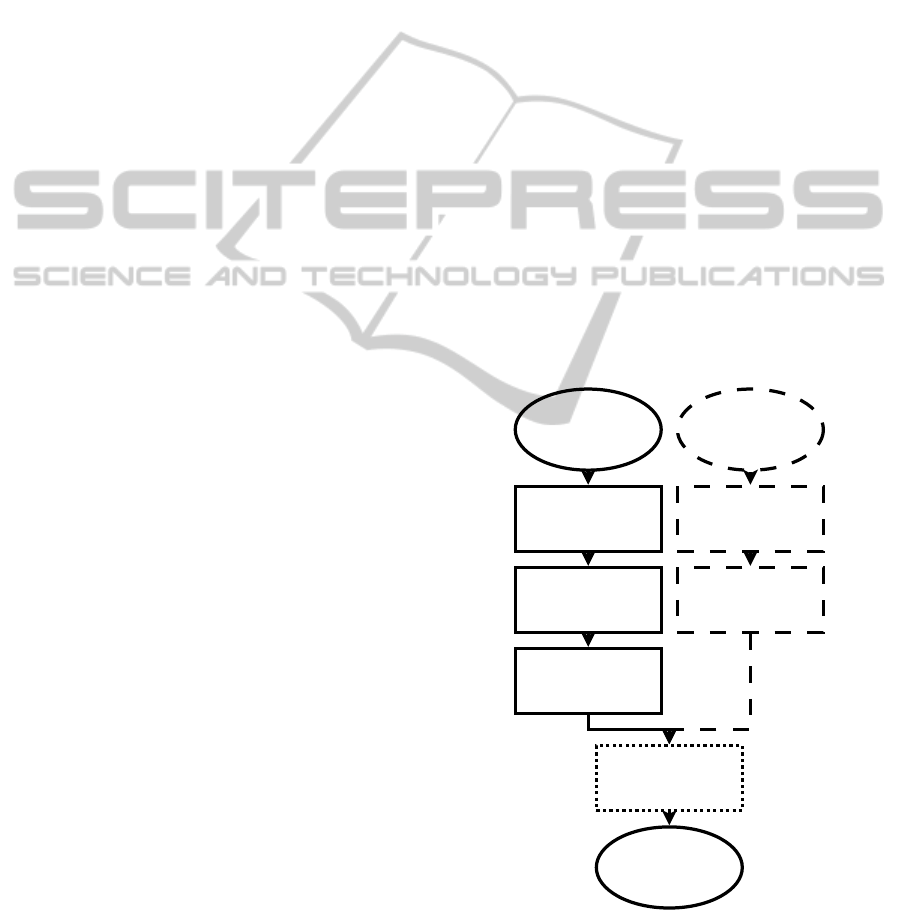
texture (Figure 1). For the moment the two input
models are selected manually, then the choice is sub-
jective.
2.2.1 Synthesis of Macro-texture
The macro-texture, i.e. the dominant colors and forms
of the concealment texture, represents the coarse tex-
ture of the concealment texture. The macro-texture
makes the concealment efficient at long distances of
observation. These colors and forms are computed
from the macro-texture model. This model must be
representative of the global aspect that the user wants
the texture of dissimulation to look like. The com-
putation of the macro-texture is divided into 3 steps
(Figure 1):
1. Extracting Dominant Colors. From the L*a*b*
histogram of the macro-texture model, the domi-
nant colors are extracted. The L*a*b* colorspace
has been chosen because it has been designed so
that a Euclidian distance computated inside this
colorspace corresponds to a visual distance. The
number of dominant colors to extract depends
on the colorimetric content of the macro-texture
model.
2. Extracting Dominant Forms. The forms (re-
gions) are extracted using a segmentation of the
pixels of the same model. To do so, we use
a k-means clustering (MacQueen, 1967) process
based on the L*a*b* components of the pixels
of the macro-texture model. The “clustering” ef-
fect in the L*a*b* colorspace is then equivalent
to a segmentation in the image space, since the
forms are perceived by the Human Visual System
as contrasts of colors.
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
258
3. Combining Colors and Forms The dominant
colors are combined with the dominant forms, by
computing the Euclidian distances between the
dominant colors and the mean colors inside the
dominant forms, in the L*a*b* colorspace. The
combination is done in a way that each dominant
form has a different dominant color and the MSE
of the combination is minimized.
At this step we have a simple macro-texture with
coarse forms and only a few colors, which makes the
concealment efficientat long distances of observation.
2.2.2 Synthesis of Micro-texture
The micro-texture, i.e. the secondary colors and
forms of the concealment texture, represents the fine
texture of the concealment texture. Contrary to the
the macro-texture which makes the concealment ef-
ficient at long distances of observation, the micro-
texture makes the concealment efficient at short dis-
tances of observation. At medium distances, both
macro-texture and micro-texture are efficient in their
own role. This fine texture makes the concealment
texture more faithful to the visual environment. The
idea behind adding a fine texture to the coarse texture
is to make the spatial frequency spectrum of the con-
cealment texture more “rich” by adding high frequen-
cies through random-like small forms; indeed the nat-
ural scenes generally have random-like small forms.
The forms of the fine texutre are computed from the
micro-texture model. The micro-texture model may
be totally independent from the macro-texture model.
The only requirement for this model is that it must be
stochastic: sand, grass, etc. So the name of the game
is to make the fine texture appear at short distances of
observation, while preserving the forms of the macro-
texture at long distances of observation, like in the
case of a brick wall. The computation of the micro-
texture is divided into 2 steps (Figure 1):
1. Resizing the Model. The micro-texture model
is resized to fit the size of the macro-texture. If
the micro-texture model is bigger than the macro-
texture, it is simply cropped. If it is smaller, a new
model is synthesized with a patch-based synthesis
(Finkelstein and Hoppe, 2000) using the micro-
texture model: the model is divided into blocks
called “patches”, and a new texture (whose size is
that of the macro-texture) is synthesized by ran-
domly concatenating thoses patches.
2. Extracting the Dominant Forms. The dominant
forms are extracted from the resized micro-texture
model with the same process as for the macro-
texture: k-means clustering. Theses forms must
be superimposed on those of the macro-texture to
mix both the macro-texture forms and the micro-
texture forms.
2.2.3 Mixture of the Micro-texture with the
Macro-texture
According to the behavior of the Human Visual Sys-
tem, a form is noticeable if its inner color contrasts
with the colors around. So to mix the micro-texture
with the macro-texture, we use this principle the
other way around. Since we want the micro-texture
to be visible above the macro-texture, we make the
macro-texture colors, precisely the L* component
in L*a*b* colorspace, vary according to the micro-
texture forms. The micro-texture is used as a mask
above the macro-texture and increases/decreases the
L* component of the pixels in the macro-texture un-
derneath.
The third step of SCOTT allows the micro-texture
to be superimposed on the macro-texture, giving the
final concealment texture a visual “richness” which
makes it more realistic.
Finally, after the entire SCOTT process (Figure 2),
we obtain a concealment two-level texture which is
faithful to the visual environment it will be placed in,
while having simple forms and only a few colors.
Macro-texture
model
Micro-texture
model
Extracting
dominant
colors
Extracting
dominant
forms
Combining
colors / forms
Resizing
Extracting
dominant
forms
Mixing
micro-texture with
macro-texture
Concealment
two-level
texture
Macro-texture Micro-texture
Figure 1: SCOTT is based on a “two-level” texture concept,
mixing a micro-texture (dashed lines) with a macro-texture
(solid lines), from two input models.
TheWorldvs.SCOTT-SynthesisofCOncealmentTwo-levelTexture
259

(a) Macro-texture model (b) Micro-texture
model
(c) Resized micro-texture model (d) Macro-texture dominant forms
(e) Macro-texture dominant forms
with dominant colors
(f) Resized micro-texture dominant
forms
(g) Final 2-level concealment tex-
ture
Figure 2: The concealment texture is based on a two-level concept. The concealment macro-texture corresponds to the
coarse texture, and is synthesized from the first input sample (a). The dominant forms (d) and colors are combined (e). The
concealment micro-texture corresponds to the fine texture, and is synthesized from the second input sample (b). The sample
is resized (c) to fit the size of the concealment macro-texture. Then the dominant forms (f) are extracted to be mixed with
those of the concealment macro-texture. The mixture is made by using the micro-texture dominant forms as a mask above the
concealment macro-texture, and making the colors of the concealment macro-texture vary (brighter or darker), according to
the micro-texture dominant forms above (g).
3 RESULTS OF SUBSTITUTION
SCOTT will then synthesize a texture faithful to the
visual environment it will be placed in, while having
simple forms and only a few colors. So far, the num-
ber of dominant colors needs to be manually adjusted
according to the color “richness” of the visual envi-
ronment.
To evaluate how faithful the concealment texture
is to its visual environment, we placed the conceal-
ment texture in the visual environment, at the ex-
act same position as that of the sample used for the
macro-texture model. It is a purely qualitative and
subjective evaluation, since we have no quantitative
and objective metrics in line with our need (Section
5).
The results in an application of substitution
demonstrates that the proposed method can synthe-
size a texture using only simple forms and a few col-
ors, with the same visual aspect as its environment
(Figure 3). It is indeed difficult to see the difference
between the textures. These results demonstrate the
two rules defined: “having the same dominant col-
ors” and “having the same dominant forms”. We still
have to keep in mind that our goal here is not to syn-
thesize a texture exactly the same as a given visual
environment; the purpose of a concealment texture is
to be both generic enough to be placed at different po-
sitions in a scene, and accurate enough to be efficient,
at different scales. So our goal is a trade-off between
genericity and efficiency.
A way to evaluate the concealment texture in
terms of colors and forms is to process the original
image and the image with concealment textures with
a Gaussian filter and a Sobel filter (Figure 4) and vi-
sually comparing the results. Indeed, processing an
image with a Gaussin filter gives an overview of its
dominant colors; and processing an image with a So-
bel filter gives an overview of its dominant forms, by
extracting the edges. This way we can subjectively
evaluate if the image with a concealment texture has
the same dominant colors and forms as the original
image (Figure 4).
The results for an application of substitution prove
that SCOTT synthesizes a texture not very salient. For
a concrete application of concealment (Section 4), the
results of simulation prove that SCOTT synthesizes
a concealment texture which can be placed at differ-
ent positions in a given visual environment, in order
to conceal different objects. SCOTT is then a good
trade-off between genericity and efficiency.
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
260

Figure 3: The concealment two-level texture is faithful to the visual environment, while having simple forms and only a few
colors. In the left column is an original image from which have been extracted two samples for the concealment texture
synthesis, i.e. the macro-texture and micro-texture models. In the middle column is the same image with the first input
sample replaced by the corresponding concealment two-level texture. Since the position of those samples is not given in these
images, the results show that it is almost impossible to notice any difference between the original image and the one with the
concealment texture. The position of the concealment texture is only revealed in the right column. An interesting exercise is
to make someone, unaware of such an application of concealment, watch only the images in the left and middle columns to
prove that the concealment texture is unnoticeable.
Figure 4: The concealment two-level texture is faithful to the visual environment because its dominant colors and forms do
not create artificial saliency. In the left column an original image has been processed with a Gaussian filter (top row) and
a Sobel filter (bottom row). In the middle columns the same image with a concealment texture (at the exact same position
as that of the macro-texture model) has been processed with the same filters. A qualitative comparison between the original
images and the same image with a concealment texture shows that the concealment texture has the same dominant forms and
colors as its environment. That is why it does not create any artificial saliency.
(a) (b) (c)
Figure 5: The initial application of SCOTT is the concealment of objects. SCOTT takes two models from a visual environment
(a) and synthesizes a concealment two-level texture. A same texture can conceal several different objects (b). The concealed
objects are hardly detectable because they are not salient anymore (c).
TheWorldvs.SCOTT-SynthesisofCOncealmentTwo-levelTexture
261

Figure 6: SCOTT makes the visual pollution much less salient. In a concrete case of applying a SCOTT-synthesized conceal-
ment texture (middle column), a realistic simulation makes any big “polluant” (left column) much less salient by giving it an
aesthetically more pleasing look (right column).
4 APPLICATIONS
SCOTT may be used in various applications. The ini-
tial application of SCOTT is the concealment of ob-
jects to reduce visual pollution (Dandumont, 2013):
antenna, electrical cabinets, distributor boxes, re-
peater shelters, etc. Results of simulation show that
SCOTT is really efficient by synthetizing a unique
concealment texture which makes different objects
much less salient (Figure 5). To make the simula-
tion simple and fast, the concealment texture has been
computed and placed in the image, superimposed on
the objects to conceal in the image, and then does not
fit their shapes and orientations.
To have a clear idea of what such a conceal-
ment would be in a concrete case, we conducted a
more sophisticated simulation of a concealment using
SCOTT-synthesized concealment texture. Even if the
“polluant” is quite big, the concealment texture makes
it much less salient by giving it an aesthetically more
pleasing look. Once again, by processing the images
with a Gaussian filter and a Sobel filter, we can quali-
tatively evaluate the performance of SCOTT as it de-
creases the saliency of the concealed object (Figure
7).
Another application for SCOTT is inpainting
(Bruno et al., 2000), which consists in repairing a
“hole” in an image. Then the results are the same as in
the case of concealment application. A SCOTT-based
inpainting application could be useful, for example,
in 3D video-mapping technology.
Finally, since SCOTT synthesizes a texture which
has the same visual aspect as its environment, while
having simple forms and only a few colors, SCOTT
could be used in an image compression process, when
only a few details are needed in somes textures: video
games, etc.
5 FUTURE WORK
The results of simulation prove that the concealment
is qualitatively and subjectively efficient. But we
presently have no quantitative and objective metrics
to evaluate its visual impact. Such metrics would au-
tomatically reproduce the subjective assessment of a
viewer in front the visual environment contraining the
SCOTT-synthesized concealment texture. Some met-
rics actually exist to evaluate the visual similarity be-
tween two images, like SSIM (“Structural SIMilar-
ity”) (Wang et al., 2004), which is usually used to
measure the visual quality of an image with distor-
sions, based on an initial distorsion-free image as ref-
erence. Even if SSIM is based on the Human Visual
System (HSV), by considering image degradation as
perceived change in structural information, it is only
applied on the luma, and then does not reproduce the
entire behavior of the HVS. Futhermore, it is not ap-
plicable in our application for two reasons: first SSIM
is applied on the entire images, so the smaller the con-
cealment texture, the better the SSIM value; secondly,
it goes against our goal since the concealment is to
modify the input image structure to make an object
less salient, then the SSIM value would always be
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
262

Figure 7: SCOTT uses the dominant colors and forms of the environment. In a realistic simulation, when we process the
original image of a visual environment, and its version with the concealment texture (left column) with a Gaussian filter
(middle column) and a Sobel filter (right column), we can qualitatively conclude that the concealed object is less salient
because it has the same dominant colors and forms its environment. Indeed it is more difficult to detect the “polluting” with
the concealment texture (first and third rows) than without the concealment texture (second and fourth rows).
small.
The future work will then be the conception of an
objective estimator, based on a HVS model, which
would analyze the scene containing the concealment
texture. A lead is the use of a “saliency map”, which
reveals what is salient to the HVS, i.e. what catches
the attention of an observer in front of a given scene.
Since the purpose of the concealment texutre is to
make an object unnoticeable, a saliency map, cor-
rectly based on the HSV response, would reveal that
the concealment textures in the resulting images (Fig-
ure 6) are not salient, i.e. they would catch no one’s
attention.
6 CONCLUSIONS
Based on the Human Visual System, we propose
an original method of concealment texture synthesis:
SCOTT (“Synthesis of COncealment Two-level Tex-
ture”).
The results prove that the concealment texture is
efficient, evenif it is made of simple forms with only a
few final colors; besides, a same concealment texture
can be used to conceal several different objects.
Next step will be to conceive an objective mea-
sure to evaluate our results, by taking into account the
HVS response to them. This will give us a feedback
on our work.
TheWorldvs.SCOTT-SynthesisofCOncealmentTwo-levelTexture
263

Besides, an application of image compression
could make use of such a texture synthesis method, by
replacing non-salient samples by substitute textures,
in a given image.
REFERENCES
Baumbach, J. (2010). Psychophysics of human vision: the
key to improved camouflage pattern design. In Land
Warfare Conference.
Bruno, E., Sapiro, G., Caselles, V., and Ballester, C. (2000).
Image inpainting. In Proceedings of the 27th an-
nual conference on Computer graphics and interac-
tive techniques, pages 417–424.
Buduc, B. (2012). The brain from top to bottom.
http://thebrain.mcgill.ca/avance.php.
Dandumont, P. (2013). Les oprateurs vont-ils de-
voir camoufler les quipements pour la fibre optique
? http://www.tomshardware.fr/articles/operateurs-
shelter-armoire,1-37709.html.
Finkelstein, E. P. A. and Hoppe, H. (2000). Lapped textures.
In SIGGRAPH 2000, pages 465–470. Citeseer.
Julesz, B. (1999). A theory of preattentive texture discrim-
ination based on first order statisics of textons. Biol.
Cybern, vol. 41, no. 2, pages 131–138.
Landragin, F. (2004). Saillance physique et saillance sogni-
tive. CORELA, vol. 2, no 2.
MacQueen, J. (1967). Some methods for classification and
analysis of multivariate observations. In 5th Berkeley
Symposium on Mathematical Statistics and Probabil-
ity, pages 281–297. University of California Press.
Wang, Z., Bovik, A. C., Sheikh, H. R., and Somoncelli,
E. P. (2004). Image quality assessment: From error
visibility to structural similarity. IEEE Transactions
on Image Processing, vol. 13, no. 4, pages 600–612.
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
264
