
Absolute Spatial Context-aware Visual Feature Descriptors
for Outdoor Handheld Camera Localization
Overcoming Visual Repetitiveness in Urban Environments
Daniel Kurz
1
, Peter Georg Meier
1
, Alexander Plopski
2
and Gudrun Klinker
3
1
metaio GmbH, Munich, Germany
2
Osaka University, Osaka, Japan
3
Technische Universit
¨
at M
¨
unchen, Munich, Germany
Keywords:
Visual Feature Descriptors, Repetitiveness, Camera Localization, Inertial Sensors, Magnetometer, GPS.
Abstract:
We present a framework that enables 6DoF camera localization in outdoor environments by providing visual
feature descriptors with an Absolute Spatial Context (ASPAC). These descriptors combine visual information
from the image patch around a feature with spatial information, based on a model of the environment and the
readings of sensors attached to the camera, such as GPS, accelerometers, and a digital compass. The result is a
more distinct description of features in the camera image, which correspond to 3D points in the environment.
This is particularly helpful in urban environments containing large amounts of repetitive visual features.
Additionally, we describe the first comprehensive test database for outdoor handheld camera localization com-
prising of over 45,000 real camera images of an urban environment, captured under natural camera motions
and different illumination settings. For all these images, the dataset not only contains readings of the sensors
attached to the camera, but also ground truth information on the full 6DoF camera pose, and the geometry
and texture of the environment. Based on this dataset, which we have made available to the public, we show
that using our proposed framework provides both faster matching and better localization results compared to
state-of-the-art methods.
1 INTRODUCTION
Video-see-through Augmented Reality (AR), as the
concept of seamlessly integrating virtual 3D content
spatially registered into imagery of the real world in
real time, is currently becoming ubiquitous. It re-
cently made its way from research labs to the mass
market. A fundamental enabler for AR moving main-
stream is affordable off-the-shelf hardware such as
camera-equipped mobile phones and tablet PCs. The
dense integration of a computer with a display, cam-
eras, different communication interfaces, and a vari-
ety of sensors make these devices interesting for AR.
One of the most important challenges towards the
everyday usage of handheld AR is precise and robust
camera localization outdoors. Pose estimation, which
is based only on information from sensors such as
GPS, compass and inertial sensors, is currently being
used in AR browsers. The precision of this is con-
trolled by environmental conditions and is usually not
enough for pixel-precise registration of overlays in the
camera image, as shown in figure 1 (right).
Visual localization and tracking is very well suited
to provide very accurate registration, and is frequently
used for camera tracking in desktop-sized environ-
ments. In particular, simultaneous tracking and map-
ping (SLAM) systems are commonly used, e.g. (Klein
and Murray, 2009), to reconstruct a sparse 3D map
of the environment whilst tracking. The use case
targeted in this paper, however, requires an offline
learned model of the environment because we need
to work in an absolute and known coordinate system.
This enables overlaying landmarks or signs for pedes-
trian navigation correctly registered with the camera
image, whereas SLAM operates in an arbitrary coor-
dinate system. The difference between SLAM and
our method is not only that we use an offline learned
map, but also that this map might be many weeks old
and the visual appearance of the environment might
have changed since then.
While SLAM applications usually assume a static
environment, there are different challenges to tackle
when going outdoors. Illumination and weather
may be subject to change and parts of the environ-
56
Kurz D., Meier P., Plopski A. and Klinker G..
Absolute Spatial Context-aware Visual Feature Descriptors for Outdoor Handheld Camera Localization - Overcoming Visual Repetitiveness in Urban
Environments.
DOI: 10.5220/0004683300560067
In Proceedings of the 9th International Conference on Computer Vision Theory and Applications (VISAPP-2014), pages 56-67
ISBN: 978-989-758-004-8
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

Façade1
Façade2
Façade3
Façade4
Figure 1: Our framework localizes a camera with respect to sparse feature map and exploits a coarse environment model
together with sensor readings to aid feature detection, description and matching (left). The obtained pose can finally be used
in outdoor AR applications (right).
ment, such as parked cars and pedestrians, frequently
change and might occlude static parts of the environ-
ment. Another very important challenge is handling
repetitive visual structures which are ubiquitous in ur-
ban and man-made environments. This was for exam-
ple discovered in (Arth et al., 2012).
The dataset presented in this paper covers all the
above aspects, for it comprises of real camera images
of a real urban environment taken at different points
in time. Additionally, the proposed methodology for
creating this ground truth evaluation dataset allows
for easy expansion in the future.
Our main contribution in this paper is to tackle the
problem of repetitive visual features by making the
description of these features aware of their Absolute
Spatial Context (ASPAC), i.e. position, orientation
and scale in the world coordinate system. Thereby,
we enable discrimination between visually indistin-
guishable features, which is crucial for visual outdoor
camera localization.
2 RELATED WORK
2.1 Outdoor Camera Localization
A common approach to visual localization is to use
local image feature descriptors, such as SIFT (Lowe,
2004), which describes features in a way that is in-
variant to changes in (in-plane) rotation and scale.
These descriptors can be used for place recognition,
e.g. (Knopp et al., 2010), to determine the coarse po-
sition of what is shown in a query image by finding a
corresponding database image with a known position.
Other approaches use SIFT features to match against
reference descriptors with known 3D positions asso-
ciated to them, e.g. as a result of structure from mo-
tion (SfM) methods on large sets of images (Irschara
et al., 2009) or video sequences taken with an omni-
directional camera (Ventura and H
¨
ollerer, 2012).
One of the most important challenges when us-
ing such local image features in urban outdoor en-
vironments is repetitive features, as also mentioned
in (Knopp et al., 2010), (Ventura and H
¨
ollerer, 2012),
and (Arth et al., 2012). Certain objects, such as trees
or traffic signs, occur at many different locations,
and therefore may lead to confusions in visual place
recognition. (Knopp et al., 2010) propose to iden-
tify such confusing features in their database and sup-
press them, which will significantly improve recogni-
tion performance.
When the dataset mainly consists of building
fac¸ades, there are usually many similar looking fea-
tures spatially close to each other, such as the win-
dows. (Baatz et al., 2012) visually estimate vanish-
ing points in query images under the assumption that
vertical and horizontal edges are predominant. After
rectification of a fac¸ade, they then perform pose esti-
mation separately for the two axes on the fac¸ade. As a
result, features that were matched in the correct story,
but with a wrong window in that row, can still con-
tribute to the correct pose. Additionally, they use up-
right feature descriptors that increase their distinctive-
ness at the expense of invariance to rotation, which
is not needed on rectified images. (Kurz and Benhi-
mane, 2011) proposed to use the measured direction
of gravity for descriptor orientation when inertial sen-
sors are attached to the camera, which has a similar
effect without the need for expensive vanishing point
estimation.
Most current mobile phones are additionally
equipped with a GPS receiver and a digital compass,
which was exploited by (Arth et al., 2012) to parti-
tion 3D reference features according to their position
and orientation (camera heading). They then match
camera features only against those reference features
located in the cell where the camera is according to
GPS. They also only match against reference features
resulting from camera views with a heading similar
to the one currently measured with the attached com-
pass. This increases both the robustness and speed of
their 6DoF localization method.
Not only the position and orientation of visual fea-
tures can add distinctiveness to their representation,
but also their physical scale can as well. (Smith et al.,
AbsoluteSpatialContext-awareVisualFeatureDescriptorsforOutdoorHandheldCameraLocalization-Overcoming
VisualRepetitivenessinUrbanEnvironments
57

2012) make use of combined range-intensity data, al-
lowing the extraction and description of features at
a physical scale. Thereby, confusions between sim-
ilar looking features at different physical scales can
be avoided. (Fritz et al., 2010) use EXIF information
stored with digital images to gain information on the
metric size of objects shown in the image.
Another approach to wide-area localization pro-
posed by (Reitmayr and Drummond, 2007) uses the
coarse pose obtained from GPS, compass and inertial
sensors as a prior for model-based tracking of an ur-
ban environment. However, as their tracker requires
the prior to be much more accurate than the precision
usually obtained from GPS, they attempt initialization
with a set of prior poses sampled around the original
GPS position.
Our proposed method shares some of the concepts
explained above to increase the distinctiveness of vi-
sual feature descriptors. Instead of using a coarse sen-
sor pose to project the reference model into the cam-
era image, as in (Reitmayr and Drummond, 2007),
we use it to project the camera features onto a coarse
model of the environment. Thereby, we gain their
ASPAC comprising of the coarse 3D position, abso-
lute scale, and absolute orientation, making it possi-
ble to constrain the set of reference features to match
against in 3D space. This not only makes it easier
to account for the different accuracies of the differ-
ent sensor readings, but more importantly, the set of
reference features to match against is determined for
every camera feature individually. This then makes it
possible to deal with repetitive visual features. While
all features corresponding to windows on a building
fac¸ade would fall into the same orientation bin, and
most likely the same position bin (according to the
partitioning proposed by (Arth et al., 2012)), our pro-
posed method can help distinguishing them.
2.2 Evaluation Methods and Ground
Truth Datasets
The most reliable way of evaluating a localization
method is to compare its results with ground truth.
However, it is generally a tedious task to determine
the ground truth pose for real camera images – partic-
ularly in wide area outdoor environments.
(Irschara et al., 2009) do not have ground truth in-
formation and therefore measure the effective num-
ber of inliers to rate if a localization succeeded or
not. (Ventura and H
¨
ollerer, 2012) synthesize cam-
era images as unwarped parts of omnidirectional im-
ages. For ground truth, they use the position of the
omnidirectional camera determined in the SfM pro-
cess to create the reference map. Similarly, (Arth
et al., 2012) simulate online-created panoramic im-
ages as subsets of existing full panoramas for evalua-
tion, and manually set the corresponding ground truth
position. There are datasets of real handheld cam-
era images with corresponding 6DoF ground truth
poses, but these either only contain planar tracking
templates (Lieberknecht et al., 2009) or 3D objects
captured indoors (Sturm et al., 2012) and without any
associated sensor readings. Existing datasets for wide
area outdoor environments exist in the robotics re-
search domain, e.g. (Wulf et al., 2007), and conse-
quently do not contain handheld camera motion.
The dataset we explain in this paper has recently
been published as a poster (Kurz et al., 2013) and is
publicly available for research purposes
1
. It contains
sequences of an urban outdoor environment taken
with an off-the-shelf mobile phone, which include the
readings of GPS, compass and the direction of grav-
ity. Most importantly, it comprises of ground truth
information on the geometry and texture of the envi-
ronment, and the full 6DoF ground truth camera pose
for every single frame.
3 PROPOSED METHOD
We propose a visual 6DoF localization framework
that – in addition to the camera image – employs the
auxiliary sensors, which off-the-shelf smartphones
are equipped with, to estimate an accurate camera
pose. A GPS receiver provides a coarse absolute po-
sition, an electronic compass measures the device’s
heading and the direction of gravity is obtained from
inertial sensors. Together with the assumption that the
device is approximately 1.6 meters above the ground
floor, a coarse 6DoF camera pose can be computed.
While this pose usually is not accurate enough for
precisely registered visual augmentations in the cam-
era image, we describe how it can be used to support
computer vision methods that enable a more accurate
camera pose estimation.
Our work is based on a state-of-the-art visual lo-
calization and tracking framework, using local image
features and 2D-3D point correspondences. In this pa-
per, we make contributions to advance state-of-the-art
in feature detection, feature description, and feature
matching for (wide-area) outdoor applications by giv-
ing features an Absolute Spatial Context, which will
be explained in the following.
1
http://www.metaio.com/research
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
58

3.1 Required Environment Model
As this work aims to localize a camera in a known
environment, we require a model that describes the
environment in a way that enables determining corre-
spondences between the model and parts of a camera
image. Our method is based upon a sparse representa-
tion of the environment comprising of 3D points with
associated feature descriptors that will be explained
in more detail in 3.3. Such a kind of model, which
we will refer to as reference feature map, can be ob-
tained by means of structure from motion methods,
e.g. (Arth et al., 2012), or from synthetic views of
dense environment model as explained in section 5.1.
We use a custom feature descriptor based on a simi-
lar approach to SIFT (Lowe, 2004), but optimized to
perform in real-time on mobile devices. This descrip-
tor uses the direction of gravity to normalize an image
patch around a feature before its description, as pro-
posed in (Kurz and Benhimane, 2011). The reference
feature map describes local parts of the environment
in great detail, but does not contain any topological or
global information.
Additionally, our method requires a coarse but
dense polygonal representation of the environment’s
surfaces. Such models can, for example, be obtained
by extruding floor plans. This representation will be
referred to as reference surface model, and neither
needs to contain any details nor does it need to be
accurately registered. As it will be described in the
following, it is only used to aid the process of feature
detection, description and matching, but it’s coordi-
nates are never used for pose estimation.
Figure 1 shows on the left the reference feature
maps of four building fac¸ades in different colors and
the reference surface models in black. The sur-
face models are stored as a set of 3D triangles and
the reference feature maps are stored as sets of 3D
points with associated ASPAC-aware feature descrip-
tors. Since both models do not share any 3D points,
they are stored separately.
All models are required to be in a consistent and
geo-referenced coordinate system. We assume such
data can be made available for the majority of cities
soon.
3.2 Environment Model-guided Feature
Detection
The detection of image features is commonly used to
speed up finding correspondences in images contain-
ing the same object or scene from different views. In-
stead of comparing patches around every pixel, com-
parison and matching is only performed for salient
Figure 2: Comparison of regular feature detection on the
entire image (left) and the proposed environment model-
guided approach (right).
image features. It is crucial to the whole process of
describing and matching features for camera localiza-
tion, that the detected features are well distributed and
that many of them actually correspond to the object or
environment our reference model describes.
In particular in outdoor environments, large parts
of the camera image often contain objects which are
not part of the model. Examples include clouds in
the sky, the floor, trees, cars and pedestrians poten-
tially occluding parts of the model, see figure 2 left.
Therefore, we developed a method to make the fea-
ture detection process focus on the parts of the image
that most likely correspond to something meaningful
for localization.
As described above, we use GPS, compass and
inertial sensors to compute a coarse 6DoF pose of
the camera in a global coordinate system, which we
will refer to as sensor pose. To account for inaccu-
rate GPS, we make sure the pose is not located inside
the surface model and not facing surfaces too close to
the camera. To this end, we push the pose backwards
along the principal axis until the closest intersection
of this axis and the surface model is at least 15 meters
away from the camera.
Based on this pose and the known intrinsic camera
parameters, we project the reference surface model
into the camera image. The resulting mask is used to
only extract features in the camera image where parts
of the model project into the image. Additionally, we
propose to not extract any features in the lower hemi-
sphere centered around the camera, because the parts
of the model located below the horizon line are often
occluded by pedestrians or cars.
Figure 2 compares the distribution of extracted
features from two images using a regular approach
(left) with our proposed method (right).
AbsoluteSpatialContext-awareVisualFeatureDescriptorsforOutdoorHandheldCameraLocalization-Overcoming
VisualRepetitivenessinUrbanEnvironments
59

In all cases, we use the FAST corner detec-
tor (Rosten and Drummond, 2006) and find a thresh-
old that results in 300 corner features. It is appar-
ent that our proposed method leads to a significantly
higher ratio of detected features, which correspond to
parts of the environment model, than in the regular
approach. As a result, the robustness against back-
ground clutter and partial occlusions of the environ-
ment is increased. In section 5.2 we will show that
this also results in significantly increased localization
success rates.
3.3 Absolute Spatial Context-aware
Visual Feature Description
Given a coarse reference surface model and a coarse
sensor pose of the camera, we are not only able to
determine which pixels of the camera image most
likely contain parts of the model, but we also retrieve
a coarse position of the 3D point P(u, v) correspond-
ing to those pixels. The position can for example be
obtained by ray casting or by rendering the surface
model into a position map. Additionally, the sensor
pose provides every feature with an absolute orienta-
tion. In the following, we will describe how this in-
formation can be used to improve feature description
by giving features in the camera image an Absolute
Spatial Context (ASPAC).
As stated earlier, an important challenge for vi-
sual outdoor localization in urban environments is to
deal with repetitive visual features. Not only do the
four corners of a window look the same (except for
their global orientation, which is part of their Abso-
lute Spatial Context), but there are also multiple win-
dows on a fac¸ade side by side and on top of each other
that look exactly the same. Additionally, man-made
environments tend to contain visually similar features
at different physical scales. It is crucial for any vi-
sual camera localization method to distinguish these
repetitive features to be able to determine an accurate
camera pose.
In this work, we use the term Absolute Spatial
Context to describe the absolute scale, the absolute
position, and the absolute orientation of a feature. As
opposed to the common definition of a feature’s scale,
position and orientation, which are defined in the (2D)
coordinate system of the camera image, the Absolute
Spatial Context is defined in a (3D) global world co-
ordinate system.
Awareness of Absolute Scale makes it possible to
distinguish features with similar visual appearance at
different physical scales. Most state-of-the-art cam-
era localization and tracking methods based on local
image features are scale-invariant. A common way
to make feature detection and description invariant to
scale, which is also used in our approach, is to use
image pyramids that represent a camera image at dif-
ferent scales. This makes it possible to detect and de-
scribe visual features of an object in a similar way no
matter if it is 1 meter away from the camera or 5 me-
ters away.
As this scale invariance happens in a projected
space, i.e. the camera image, it is impossible to dis-
tinguish scale resulting from the distance of an ob-
ject to the camera from the actual physical scale of
an object. Invariance to scale resulting from the dis-
tance of the camera to an object is clearly desirable
in many applications, and was the original motivation
for scale-invariance. However, in the presence of sim-
ilar features at different physical scales, invariance to
scale makes them indistinguishable.
In the following, we will use the term feature scale
as a scalar value describing the width and height of
the squarish support region of the feature’s descrip-
tor. Given the coarse sensor pose and the coarse 3D
position P(u,v) of a visual feature located in the cam-
era image at pixel (u,v), the distance from the optical
center of the camera to the feature point d(u,v) can be
easily computed.
Based on this distance, the intrinsic camera pa-
rameters, and the scale of a feature in pixels s
pix
as
described above, we propose to compute an approxi-
mation of its absolute physical scale s(u,v) as
s(u,v) = s
pix
(u,v)
d(u,v)
f
, (1)
where f is the camera’s focal length. This abso-
lute physical scale is computed and stored for every
feature.
Awareness of Absolute Position can help distin-
guishing between repetitive features that are located
at different positions, such as similar windows on a
building fac¸ade. To this end, we simply store the ap-
proximate 3D position of a feature computed from the
sensor pose and the reference surface model as
p(u,v) = P(u,v). (2)
This position is, of course, inaccurate, but we will
discuss in 3.4 how it can aid and speed up the process
of feature matching.
Awareness of Absolute Orientation makes similar
features at different absolute orientations distinguish-
able, as described in (Kurz and Benhimane, 2011).
We use gravity-aligned feature descriptors (GAFD)
that take the measured direction of gravity projected
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
60
into the camera image as feature orientation. This
orientation is then used to normalize an image patch
around a feature before description. Thereby, repet-
itive features at different orientations, e.g. the four
corners of a window, are described in a distinct way
while the description is still invariant to the orienta-
tion of the camera. We denote the visual descriptor,
which is based on a histogram of gradient orientations
in the image patch, as v(u,v).
Additionally, we compute and store the dominant
gradient direction o
gradient
in a patch around the fea-
ture relative to the orientation of the gravity o
gravity
as
an additional part of the Absolute Spatial Context.
o(u,v) =
o
gradient
− o
gravity
angle
(3)
|
α
|
angle
=
α + 2π, if α ≤ −π
α − 2π, if α ≥ π
α, else.
(4)
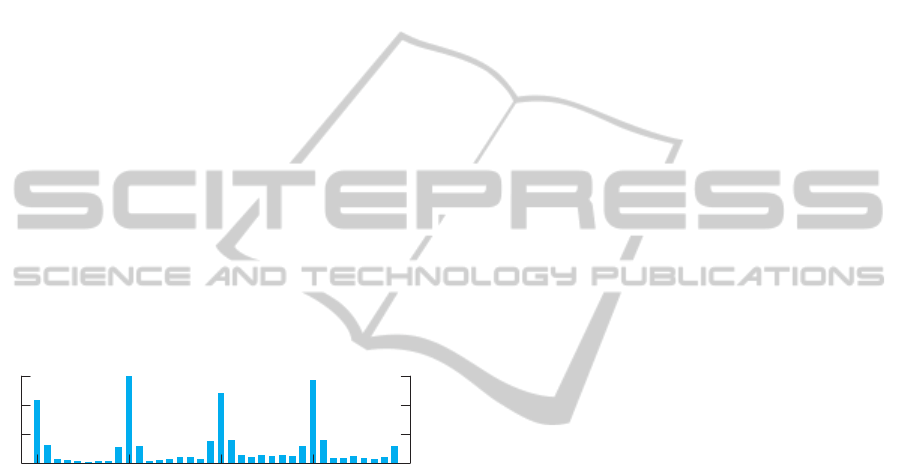
Figure 3 plots an exemplary distribution of abso-
lute orientations of the features located on a building
fac¸ade. We clearly observe peaks at all multiples of
π/2, i.e. 90 degrees, which are very common in man-
made environments.
0.00
0.05
0.10
0.15
0.0 0.5π π 1.5π
Absolute orientation (o)
Frequency
Figure 3: Distribution of the absolute orientation of features
on a building fac¸ade comprising of mainly horizontal and
vertical structures.
All the properties of a feature described above re-
main constant for varying camera positions and orien-
tations. Therefore, they can be used to add distinctive-
ness to visually similar features, as they are very fre-
quent in man-made environments. Additionally, they
can be used to significantly speed up feature match-
ing, which will be explained in the following.
3.4 Matching Absolute Spatial
Context-aware Features
After detecting and describing features from a camera
image, the matching stage is responsible for determin-
ing correspondences between these camera features
and the reference feature map. We do this by finding
for every camera feature the reference feature with the
lowest dissimilarity using exhaustive search. Based
on the resulting 2D-3D correspondences, the 6DoF
pose of the camera can finally be determined.
In this paper, we propose to use the Absolute Spa-
tial Context of visual features to speed up the match-
ing process by precluding potential matches where
the context is not consistent. Thereby, for a major-
ity of combinations of camera and reference features,
the expensive step of computing the distance of their
visual descriptors can be skipped. This not only re-
sults in faster matching, but also provides more cor-
rect matches, because the Absolute Spatial Context
prevents similar looking features that differ signifi-
cantly in their global scale, position, or orientation,
to be matched.
As described in the previous section, our feature
description d is composed of
• the absolute position p,
• the absolute scale s,
• the absolute dominant gradient orientation with
respect to gravity o, and
• and a gravity-aligned visual feature descriptor v.
To compute the dissimilarity of two features, our
method computes intermediate distances δ
i
followed
by a check if these intermediate distances are below
given thresholds. If this condition is fulfilled, the next
intermediate distance is computed. Otherwise, the
dissimilarity of the two features is set to infinity with-
out any further computations.
The dissimilarity is defined as
d
i
− d
j
= ∆
1
(5)
where ∆
1
,∆
2
,∆
3
, and ∆
4
are defined as
∆
k
=
(
∞, if δ
k
>= t
k
∆
k+1
, if δ
k
< t
k
.
(6)
and
∆
5
= δ
5
. (7)
As intermediate distances we use the distance on
the x-y plane
δ
1
(d
i
,d
j
) =
(p
i
− p
j
)[1, 1,0]
>
, (8)
the distance along the z axis (i.e. vertical)
δ
2
(d
i
,d
j
) =
(p
i
− p
j
)[0, 0,1]
>
, (9)
the ratio of absolute scale
δ
3
(d
i
,d
j
) = max(s
i
,s
j
)/min(s
i
,s
j
), (10)
the difference in absolute orientation
δ
4
(d
i
,d
j
) =
(o
i
− o
j
)
angle
, (11)
and the visual descriptor distance
δ
5
(d
i
,d
j
) =
(v
i
− v
j
)
. (12)
AbsoluteSpatialContext-awareVisualFeatureDescriptorsforOutdoorHandheldCameraLocalization-Overcoming
VisualRepetitivenessinUrbanEnvironments
61
(a)
(b)
(c)
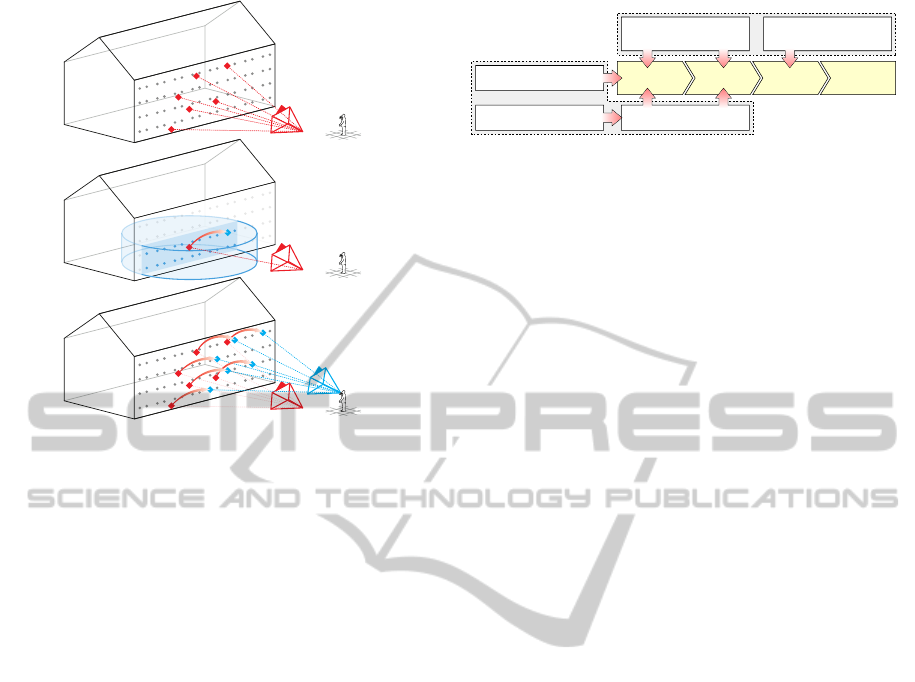
Figure 4: Determining the coarse absolute position of cam-
era features (as part of their Absolute Spatial Context) based
on the sensor pose (a) enables constraining feature matching
to reference features that are located within a cylinder cen-
tered at the coarse position (b). Finally, the accurate camera
pose can be determined based on a set of correct matches
between 2D camera features and 3D reference features (c).
Note, that we treat the spatial distance along the
z-axis, i.e. the altitude, differently than the distance
along the other two axes. This is based on the assump-
tion that the altitude is the most reliable part of the
determined 3D position of a camera feature, because
it is less heavily affected by an inaccurate compass
heading or GPS position, as is also shown in figure 4.
The benefit of the proposed method to project
camera features into the environment over projecting
the reference feature map into the coordinate system
of the camera, is twofold. Firstly, depth is preserved
and avoids matching camera features against refer-
ence features that are occluded or at the backside of
a building. Secondly, the transformation into a dif-
ferent coordinate system and the computation of fea-
ture properties in this coordinate system, which is per-
formed in every frame during localization, is in our
case only done for hundreds of camera features, in-
stead of tens of thousands of reference features.
3.5 6DoF Localization Framework
A flow diagram of our proposed framework for 6DoF
camera localization on mobile devices is shown in fig-
ure 5. It combines the above steps to establish corre-
spondences between features in the camera image and
the reference model with a pose estimation function-
ality. Every live frame consists of a camera image
and a set of sensor readings measured at a time close
Live Frame
Reference Model (offline created)
Camera Image
Sensor Readings
Reference
Surface Model
Reference
Feature Map
Sensor Pose
Feature
Detection
Feature
Description
Feature
Matching
Pose
Estimation
Figure 5: Flowchart of the proposed camera localization
framework for outdoor environments.
to when the image was taken. Based on these sen-
sor readings, we first compute a coarse sensor pose,
which together with the reference surface model is
then used in the feature detection stage, as described
in section 3.2.
Afterwards, the features are described as speci-
fied in section 3.3, which again requires the sensor
pose and the surface model to determine the Abso-
lute Spatial Context (ASPAC) of the features. Even-
tually the features of a live camera image are matched
against those of the reference feature map, according
to the method explained in section 3.4. The result-
ing correspondences serve as a basis for the pose es-
timation step, which performs PROSAC (Chum and
Matas, 2005) followed by a non-linear pose optimiza-
tion based on all inlier matches.
In an outdoor handheld AR application, this lo-
calization step would be followed by frame-to-frame
tracking. This paper, however, focuses on camera lo-
calization (i.e. initialization) only.
4 OUTDOOR 6DoF GROUND
TRUTH DATASET
A quantitative evaluation of a 6DoF localization
framework requires ground truth information. That
is, for a set of given (realistic) input data, i.e. cam-
era image, camera intrinsics, all sensor readings, and
the required reference models, we need the expected
ground truth output data, i.e. a 6DoF pose. As dis-
cussed in 2.2, there are ground truth datasets for vi-
sual localization and tracking available, but none of
them fulfills our requirements to evaluate the frame-
work proposed in this paper.
In the following, we describe our extensive proce-
dure to create the first ground truth dataset for outdoor
6DoF handheld camera localization comprising of:
• a highly accurate, geo-referenced, and textured
3D model of a real urban environment spanning
approximately 10,000 square meters,
• video sequences containing over 45,000 individ-
ual images of the environment with realistic hand-
held camera motion taken from different locations
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
62

with an off-the-shelf mobile phone,
• the sensor readings of GPS, compass, and the
gravity vector for each image of the sequences
mentioned above, and
• a very accurate 6DoF ground truth pose for every
single camera image.
One important aspect of the design of this dataset
is that it allows for easy expansion by adding more
sequences taken with different devices, from different
users, and under different illumination.
4.1 Model Acquisition
We chose an office park as a testing environment,
which comprises of a large parking lot, different
buildings, some parking lanes, and small streets. The
covered area is approximately 100 by 100 meters
wide.
As we aim to create a very precise and detailed
model of the environment, SfM methods that recon-
struct a sparse point cloud based on a multitude of
images taken from different positions, are not suit-
able in this case. Instead, we used a FARO Focus 3D
laser scanner to create nine, high-precision panoramic
laser scans with texture information for different parts
of the environment. The individual scans were then
registered to a common coordinate system using pro-
prietary software based on 3D-3D correspondences
of registration spheres that were placed in the envi-
ronment. The merged model has finally been geo-
referenced based on the latitude and longitude of a set
of building corners obtained from OpenStreetMap
2
.
As a result, we obtain a highly precise, dense and
textured environment model which is referenced with
respect to a global world coordinate system. The full
registered model with color information is shown in
figure 7, rendered from a bird’s-eye view.
4.2 Sequence Recording at Known
Camera Positions
There are two important aspects to keep in mind when
recording sequences for testing. These are relevance
for the targeted application and universality. It is im-
portant to use a capturing device and camera motions
similar to those that can be expected to be used in real
applications. It is crucial, that the dataset comprises
of a high variance in parameters, such as the camera
position, for the data to be considered universal and
representative.
We decided to use an iPhone 4 mobile phone be-
cause it is a very common device and allows to obtain
2
http://www.openstreetmap.com
the GPS position, compass heading and a measure-
ment of the gravity vector for every image. The image
resolution is set to (480 × 360) pixels and the cam-
era’s intrinsic parameters were calibrated offline using
a checkerboard pattern and Zhang’s method (Zhang,
2000). We use a custom-made application to capture
image sequences with all relevant sensor readings at a
frame rate of ∼25 Hz and save them to files.
To ensure a universal and representative set of
camera sequences, it is important to cover many dif-
ferent camera positions distributed over the entire test
area. As this area spans about 10,000 square meters,
installing an external tracking system that measures
the 6DoF pose of the phone with a precision that can
be considered ground truth is very complex, if not im-
possible. Therefore, we limit ourselves to a set of 156
discrete camera positions, which are spread all over
the area and are chosen such that placing a camera to
these positions is easy to achieve.
Our test environment comprises of a large park-
ing lot and two smaller parking lanes, which are di-
vided into individual cells by white markings on the
ground. These serve as constant markers, since they
are unlikely to change in the near future. We use the
crossings and end points of these markings as sur-
vey points, and measure their precise 3D positions
with a total station (Trimble 3603 DR). Based on 3D-
3D correspondences between additionally measured
points on the buildings, and the corresponding points
in our ground truth model, the survey points are fi-
nally converted into the common world coordinate
system. Figure 7 displays these survey points as red
circles.
We then divide the process of obtaining sequences
with 6DoF ground truth poses into two steps. In the
first step we capture sequences at known 3D camera
positions and recover the corresponding 3DoF orien-
tation in a second step. Attaching a lead weighted
string of known length to the phone’s camera, makes
it easy to precisely move the device to a known 3D
position. As shown in figure 6, we hold the mobile
phone directly over a survey point s
i
on the ground
with a string of known length h
i
to be sure the camera
is located at t
i
, which can simply be computed as
t
i
= s
i
+ h
i
· [0,0,1]
>
. (13)
We use strings at lengths of 1 and 1.8 meters,
which can be considered to represent the actual
heights users hold their mobile devices. An inter-
esting property when taking sequences at a height of
1 meter, is that they contain much more occlusions
of the buildings because of the cars on the parking
lot. While capturing and recording sequences (some
frames of two exemplary sequences are shown in fig-
AbsoluteSpatialContext-awareVisualFeatureDescriptorsforOutdoorHandheldCameraLocalization-Overcoming
VisualRepetitivenessinUrbanEnvironments
63

s
i
h
i
Figure 6: Sequence recording at a known camera position using a lead weighted string and survey points on the ground.
ure 6), the camera only undergoes rotational move-
ments and does not change its position. Since (Chit-
taro and Burigat, 2005) found out that users prefer
standing while using the screen of a mobile phone for
information, we believe that our sequences have real-
istic kinds of camera motion for handheld Augmented
Reality applications.
4.3 6DoF Ground Truth Recovery
For the second step of the ground truth acquisition
process, we prepared an edge model of the environ-
ment based on the ground truth model. Using the
coarse camera orientation obtained from the sensor
readings and the accurately known 3D position of the
camera, we project the edges into the camera image.
We then find the orientation for which the model best
fits gradients in the camera image using exhaustive
search in a neighborhood around the initial orientation
estimate. Finally, the recovered 3DoF camera orienta-
tion, together with the 3DoF known ground truth po-
sition, make the 6DoF ground truth pose. To account
for potential errors in labeling or recovery of the rota-
tion, the ground truth poses of all images have been
manually verified by rendering a wireframe model
onto the video stream. Figure 7 displays the recov-
ered 6DoF ground truth pose for three exemplary im-
ages of the dataset, in green.
In total, we recorded 100 sequences from differ-
ent locations and heights imaging fac¸ade1 and an ad-
ditional 25 sequences of fac¸ade4, cf. figure 1. All
sequences comprise over 45,000 images and the cor-
responding sensor information. For every frame, we
recovered the 6DoF ground truth pose. Since we used
parking markings as easily identifiable camera loca-
tions, it was convenient to record sequences at dif-
ferent times of the day and under varying weather
conditions. In future the database can be easily ex-
panded by more sequences comprising of more dras-
tic weather changes, e.g. snow or rain, or to contain
data from other devices and cameras.
5 EVALUATION AND RESULTS
In the following, we evaluate our proposed localiza-
tion framework, described in section 3, using the out-
door 6DoF ground truth dataset, which was explained
in the previous section.
5.1 Ground Truth Localization Test
In order to make use of the detailed ground truth
model of the environment, we first need to convert it
into the model representation required by our method
as described in section 3.1. We define the four differ-
ent building fac¸ades, shown color-coded in figure 1
(left), as objects we are interested in for localization
while the rest of the environment – mainly consist-
ing of the floor, cars and trees – is not relevant. For
each of these objects, we create a localization refer-
ence model as follows.
By rendering the ground truth model from differ-
ent virtual viewpoints, we gain a set of synthetic photo
realistic views of the environment, where for every
pixel the corresponding 3D position is known. We
then detect features with known 3D coordinates from
these views and describe them as elaborated in 3.3.
Note, that instead of using a coarse pose computed
from GPS, compass and inertial sensors, we use the
precisely known pose of the virtual camera used to
render the view to provide the Absolute Spatial Con-
text. Finally, we determine out of the descriptors from
all the views, a representative feature descriptor set
comprising of 2,000 features per object, as explained
in (Kurz et al., 2012). This set of descriptors and fea-
tures is then used as a reference feature map. The
reference surface models have been manually created
for this test and are shown in figure 1 (left).
We run all tests offline on a PC, but use the same
localization framework that runs in real-time on mo-
bile devices.
As we are interested in localization (or initializa-
tion) only, and not tracking, we treat every single
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
64

frame individually. The image and the sensor read-
ings (GPS position, compass heading, and gravity
vector) are read from files and provided to the sys-
tem. We then perform the whole localization pipeline
(as explained in 3.5) on this data as if it was live data.
Eventually, the framework either returns a determined
camera pose or replies that it did not succeed to local-
ize the camera.
In video-see-through Augmented Reality applica-
tions, it is most important that the visualization (ren-
dered with the obtained pose) appears correctly regis-
tered with the camera image. Therefore, we use the
average re-projection error e of a set of 3D vertices
located on the reference model as error measure. This
error can be computed as
e =
1
k
k
∑
i=1
k
K(R
obt
t
obt
)v
i
− K (R
gt
t
gt
)v
i
k
(14)
where v
i
are the 3D vertices, K denotes the cam-
era intrinsic matrix, and (R
obt
t
obt
) and (R
gt
t
gt
) are the
obtained pose and ground truth pose respectively. We
require the re-projection error to be less than a thresh-
old of 4 pixels for the pose to be considered correct.
The framework is run on all captured frames in
three different configurations:
Na
¨
ıve. A na
¨
ıve approach, where feature detection is
performed on the entire image, feature description
uses GAFD, and the matching only compares the
visual descriptors.
Orientation. Similar to the na
¨
ıve approach but with
orientation-aware feature matching that only com-
pares features with a similar heading analog to
what is proposed in (Arth et al., 2012).
Proposed. Our proposed method, where feature de-
tection, feature description, and feature matching
make use of the ASPAC provided by the sensor
values.
To evaluate how the individual approaches scale
with an increasing reference model, we evaluate all
sequences in all configurations with two different ref-
erence models:
Only. Only uses the reference model of the building
fac¸ade, which is imaged in the current sequence.
All. All four reference models shown in figure 1 on
the left are combined to a large reference model.
We chose the following thresholds in our evalua-
tion:
t
1
= 10,000 mm – Spatial distance on the x-y plane.
t
2
= 2,000 mm – Spatial distance along the z axis.
t
3
= 1.3 – Ratio of absolute scale.
t
4
= 120
◦
– Difference in absolute orientation.
The reason for t
4
being large, is that the scene
mainly consist of windows, and the corners of these
windows, which provide a majority of features, usu-
ally have at least two orthogonal dominant gradient
directions in their neighborhood making the absolute
orientation an unreliable parameter in this environ-
ment. The vertical distance threshold t
2
was chosen
as two meters, to ensure discrimination between the
windows of different building stories, which are usu-
ally about 3 meters high.
In the Orientation approach, we use a threshold of
±30
◦
as in the original paper.
5.2 Test Results
First of all, we evaluate for all configurations the ra-
tio of the frames in our ground truth dataset for which
the localization framework determines a correct pose.
The results are given in table 1, and show that the
Orientation approach performs better than the Na
¨
ıve
approach on the large reference model (All). When
dealing with only one fac¸ade (Only), the Na
¨
ıve pro-
vides better results than Orientation. In this case,
the Orientation approach seems to preclude correct
matches due to inaccurate compass heading values.
Our Proposed method clearly outperforms all
other methods in terms of correctly localized frames.
It also is apparent that our Proposed method scales
very well with an increasing reference model. Scaling
the number of reference features by a factor of four
(Only → All) has a minimal effect, while the ratio of
correctly localized frames drops significantly for the
Na
¨
ıve approach.
Table 1: Ratio of correctly localized frames in the outdoor
ground truth dataset.
Sequences\Method Na
¨
ıve Orient. Proposed
Fac¸ade1 (Only) 30.87% 22.91% 50.03%
Fac¸ade4 (Only) 4.98% 3.66% 9.00%
Total (Only) 25.54% 18.95% 41.58%
Fac¸ade1 (All) 16.20% 20.99% 49.98%
Fac¸ade4 (All) 2.80% 3.01% 9.00%
Total (All) 13.44% 17.29% 41.54%
The absolute numbers given above might appear
low compared to the results of other papers (e.g. (Arth
et al., 2012)(Ventura and H
¨
ollerer, 2012)). It is impor-
tant to keep in mind that the dataset we use is realistic,
and therefore, particularly hard compared to tests in
the literature. All reference feature maps are based on
the panoramic images from the laser scanner while
the test sequences were taken with a mobile phone
at different days and weather conditions. Addition-
ally, the scene – particularly fac¸ade4 – contains a sig-
AbsoluteSpatialContext-awareVisualFeatureDescriptorsforOutdoorHandheldCameraLocalization-Overcoming
VisualRepetitivenessinUrbanEnvironments
65

nificant percentage of repetitive visual features, which
are mainly windows that additionally reflect the sky,
resulting in frequent changes in their appearance. An-
other challenge is that the majority of our sequences
contain cars partially occluding the building fac¸ades.
Our proposed method deals well with repetitive
visual features, but still has problems with significant
changes in illumination. For some of the sequences
in the dataset, not a single frame was localized cor-
rectly with any method simply because the illumina-
tion is too different from that in the reference model.
Here, further research on algorithms to compute the
visual descriptor in a fashion invariant to illumination
is needed.
Table 2: Impact of the individual proposed steps and in-
termediate distances on localization cost and quality in
Fac¸ade1 (Only).
Distance\Measurement Computed δ
5
Correct
(a) ∆
1
← δ
5
(Na
¨
ıve) 100.00% 30.87%
(b) ∆
1
← δ
5
+ EMGFD 100.00% 43.56%
(c) ∆
2
← δ
5
43.14% 46.92%
(d) ∆
3
← δ
5
12.89% 47.91%
(e) ∆
4
← δ
5
2.86% 50.39%
(f) ∆
5
← δ
5
(Proposed) 2.16% 50.03%
To evaluate the impact of the steps involved in our
proposed method and the intermediate distances com-
puted in the matching stage, we repeated the experi-
ment above in more different configurations. Begin-
ning from the na
¨
ıve approach, every row in table 2
adds one more of the steps that we proposed before fi-
nally computing the visual descriptor distance. Start-
ing from environment model-guided feature detec-
tion (denoted by EMGFD), we added the constraint
on the distance on the x-y plane, the distance along
the z axis, the ratio of absolute scale, and the dif-
ference in absolute orientation. We observe that the
first four steps of our proposed method (b,c,d,e) re-
sult in a continuously increased ratio of correctly de-
termined poses, while the number of expensive com-
parisons of visual feature descriptors (δ
5
) needed de-
creases monotonically. The configuration (e) local-
izes over 1.6 times as many frames correctly as the
na
¨
ıve approach and requires less than 3% of the vi-
sual descriptor comparisons.
Adding the constraint on the absolute feature ori-
entation (f) results in even less visual descriptors be-
ing compared (factor 0.76) but also slightly decreases
the ratio of correctly localized frames (factor 0.99).
Therefore, depending on the application, it can make
sense to omit this step because the absolute feature
orientation already contributed to the distinctiveness
of the (gravity-aligned) visual descriptors.
6 CONCLUSIONS AND FUTURE
WORK
This paper presented a framework for visual cam-
era localization that utilizes the sensors modern mo-
bile phones are equipped with to provide local vi-
sual feature descriptors with an Absolute Spatial Con-
text (ASPAC). This novel feature description method
overcomes visual repetitiveness in urban environ-
ments, which is one of the most pressing problems for
visual camera localization. Moreover, we presented
the first publicly available dataset comprising of real
camera sequences and sensor readings captured out-
doors using a mobile phone with accompanied 6DoF
ground truth poses. Using this comprehensive dataset,
we showed that our proposed method clearly outper-
forms a na
¨
ıve approach using only the direction of the
gravity and visual information, and an approach simi-
lar to a recently published work (Arth et al., 2012) that
additionally uses the heading orientation to constrain
feature matching.
Our proposed method to detect, describe and
match features shows that the auxiliary sensors of mo-
bile devices can help to not only get better localization
results, but to also speed up matching by precluding
the comparison of visual descriptors of features with a
largely different Absolute Spatial Context. Addition-
ally, the proposed scheme can be very well applied
to feature matching in hardware, which will make
matching against large databases of reference feature
maps virtually free of cost in the future.
While sensor values are clearly helpful as long as
they are reasonably accurate, our proposed method
will not work if some of the sensor readings are very
imprecise. For these cases, we are currently looking
into fallback strategies, e.g. by switching between our
proposed method and a na
¨
ıve method in every other
frame if localization does not succeed for a certain
period of time.
The established outdoor 6DoF ground truth
dataset is not dependent on the proposed localiza-
tion framework but can be used to evaluate any lo-
calization method including those relying on color
features, edge features, or even model-based ap-
proaches that require a dense and textured reference
model. Furthermore, the dataset enables benchmark-
ing frame-to-frame tracking methods as it comprises
image sequences captured with a handheld camera
with different levels of realistic interframe displace-
ment. As capturing additional sequences does not re-
quire any hardware, except a capturing device and a
lead weighted string, we plan to expand the dataset
by more sequences taken with different devices, from
different users, and during different weather.
VISAPP2014-InternationalConferenceonComputerVisionTheoryandApplications
66

Figure 7: Our outdoor ground truth dataset comprises of a precise 3D model of the environment and over 45,000 camera
images with sensor readings and 6DoF ground truth poses. Exemplary images are shown as insets with their ground truth
poses rendered as frustra.
ACKNOWLEDGEMENTS
This work was supported in part by the German Fed-
eral Ministry of Education and Research (BMBF,
reference number 16SV5745, PASSAge) and the
German Federal Ministry of Economics and Tech-
nology (BMWi, reference number 01MS11020A,
CRUMBS). The authors further wish to thank Darko
Stanimirovi
´
c and Marion M
¨
arz for their help on the
ground truth dataset and FARO Europe for providing
us with the laser scans.
REFERENCES
Arth, C., Mulloni, A., and Schmalstieg, D. (2012). Exploit-
ing Sensors on Mobile Phones to Improve Wide-Area
Localization. In Proc. Int. Conf. on Pattern Recogni-
tion (ICPR).
Baatz, G., K
¨
oser, K., Chen, D., Grzeszczuk, R., and Polle-
feys, M. (2012). Leveraging 3d city models for rota-
tion invariant place-of-interest recognition. Int. Jour-
nal of Computer Vision (IJCV), 96(3):315–334.
Chittaro, L. and Burigat, S. (2005). Augmenting audio mes-
sages with visual directions in mobile guides: an eval-
uation of three approaches. In Proc. Int. Conf. on Hu-
man Computer Interaction with Mobile Devices and
Services (Mobile HCI).
Chum, O. and Matas, J. (2005). Matching with PROSAC -
Progressive Sample Consensus. In Proc. Int. Conf. on
Computer Vision and Pattern Recognition (CVPR).
Fritz, M., Saenko, K., and Darrell, T. (2010). Size mat-
ters: Metric visual search constraints from monocular
metadata. In Advances in Neural Information Process-
ing Systems (NIPS).
Irschara, A., Zach, C., Frahm, J.-M., and Bischof, H.
(2009). From structure-from-motion point clouds to
fast location recognition. In Proc. Int. Conf. on Com-
puter Vision and Pattern Recognition (CVPR).
Klein, G. and Murray, D. (2009). Parallel tracking and map-
ping on a camera phone. In Proc. Int. Symp. on Mixed
and Augmented Reality (ISMAR).
Knopp, J., Sivic, J., and Pajdla, T. (2010). Avoiding confus-
ing features in place recognition. In Proc. European
Conf. on Computer Vision (ECCV).
Kurz, D. and Benhimane, S. (2011). Inertial sensor-aligned
visual feature descriptors. In Proc. Int. Conf. on Com-
puter Vision and Pattern Recognition (CVPR).
Kurz, D., Meier, P., Plopski, A., and Klinker, G. (2013). An
Outdoor Ground Truth Evaluation Dataset for Sensor-
Aided Visual Handheld Camera Localization. In Proc.
Int. Symp. on Mixed and Augmented Reality (ISMAR).
Kurz, D., Olszamowski, T., and Benhimane, S. (2012). Rep-
resentative Feature Descriptor Sets for Robust Hand-
held Camera Localization. In Proc. Int. Symp. on
Mixed and Augmented Reality (ISMAR).
Lieberknecht, S., Benhimane, S., Meier, P., and Navab,
N. (2009). A dataset and evaluation methodology
for template-based tracking algorithms. In Proc. Int.
Symp. on Mixed and Augmented Reality (ISMAR).
Lowe, D. G. (2004). Distinctive image features from scale-
invariant keypoints. Int. Journal of Computer Vision
(IJCV), 60(2):91–110.
Reitmayr, G. and Drummond, T. W. (2007). Initialisation
for visual tracking in urban environments. In Proc.
Int. Symp. on Mixed and Augmented Reality (ISMAR).
Rosten, E. and Drummond, T. (2006). Machine learning for
high-speed corner detection. In Proc. European Conf.
on Computer Vision (ECCV).
Smith, E. R., Radke, R. J., and Stewart, C. V. (2012).
Physical scale keypoints: Matching and registration
for combined intensity/range images. Int. Journal of
Computer Vision (IJCV), 97(1):2–17.
Sturm, J., Engelhard, N., Endres, F., Burgard, W., and Cre-
mers, D. (2012). A Benchmark for the Evaluation of
RGB-D SLAM Systems. In Proc. Int. Conf. on Intel-
ligent Robot Systems (IROS).
Ventura, J. and H
¨
ollerer, T. (2012). Wide-area scene map-
ping for mobile visual tracking. In Proc. Int. Symp. on
Mixed and Augmented Reality (ISMAR).
Wulf, O., Nuchter, A., Hertzberg, J., and Wagner, B. (2007).
Ground truth evaluation of large urban 6D SLAM. In
Proc. Int. Conf. on Intelligent Robot Systems (IROS).
Zhang, Z. (2000). A flexible new technique for camera cal-
ibration. Trans. on Pattern Analysis and Machine In-
telligence (TPAMI), 22(11):1330–1334.
AbsoluteSpatialContext-awareVisualFeatureDescriptorsforOutdoorHandheldCameraLocalization-Overcoming
VisualRepetitivenessinUrbanEnvironments
67
