
A Routing Algorithm based on Semi-supervised Learning for Cognitive
Radio Sensor Networks
Zilong Jin
1
, Donghai Guan
1
, Jinsung Cho
1
and Ben Lee
2
1
Dept. of Computer Engineering, Kyung Hee University, 446-701, Yongin, Korea
2
School of Electrical Engineering and Computer Science, Oregon State University, 97331, Corvallis, OR, U.S.A.
Keywords:
Machine Learning, Semi-supervised Learning, Routing Algorithm, Cognitive Radio Sensor Networks.
Abstract:
In Cognitive Radio Sensor Networks (CRSNs), the cognitive radio technology enables sensor nodes to occupy
licensed bands in a opportunistic manner and provides advantages in terms of spectrum utilization and system
throughput. This paper proposes a routing scheme based on semi-supervised learning, which jointly considers
energy efficiency, context-awareness, and optimal path configuration to enhance communication efficiency. A
context-aware module is developed to collect and learn context information in an energy-efficient way and a
new semi-supervised learning algorithm is proposed to estimate dynamic changes in network environment. A
novel routing metric is used to select the most reliable and stable path. Our simulation study shows that the
proposed routing algorithm enhances the reliability and stability for CRSNs, and at the same time, significantly
improves the packet delivery ratio.
1 INTRODUCTION
In the foreseeable future, tens of billions of electronic
devices will be expected to communicate with each
other and require a huge amount of radio resources.
However, the current radio resources is lack of due
to inflexible spectrum sharing rules. In particular,
existing wireless networks, such as WLANs, mesh
networks, body area networks, and sensor networks,
which operate in unlicensed band will suffer from se-
rious spectrum overcrowding problem. The cogni-
tive radio technology that exploits dynamic spectrum
sharing techniques is a promising solution to solve
this problem (Cesana et al., 2011).
Application of the cognitive radio technology in
wireless sensor networks (WSNs) can open up new
and unexplored network configuration possibilities
and also enable researchers to explore new services.
In Cognitive Radio Sensor Networks (CRSNs), the
sensor devices are capable of sensing a wide spec-
trum range, dynamically identifying available chan-
nels, and intelligently accessing them. Unlike WSNs,
CRSNs can operate in licensed bands. Cognitive Ra-
dio Sensor Devices (CRSDs), which are also referred
to as secondary users, share the licensed band with
primary users (PUs) who have higher priorities in oc-
cupying the bands in a non-interfered manner. This
indicates that the topology of CRSN is changing un-
predictably due to PUs’ activities and causes consid-
erable difficulty in guaranteeing stable and efficient
communications (Cesana et al., 2011; Akan et al.,
2009; Ali et al., 2011).
There are many excellent prior research focused
on the lower layers (PHY/MAC) of cognitive radio
technologies. However, routing, which is an im-
portant requirement for efficient communication in
multi-hop based CRSNs, has not been well explored.
Most of prior work on routing solutions are provided
in ad-hoc based cognitive radio networks (Sampath
et al., 2008; Cheng et al., 2007; Pefkianakis et al.,
2008; Wang et al., 2009). These approaches employ
spectrum-aware schemes to support routing module
in the path selection process. However, these meth-
ods do not take into account energy restriction of sen-
sor networks, and thus cannot be directly applied to
CRSN. There is only a limited work that focus on
routing issues in CRSNs. Parvin and Fujii (2011)
and Shah et al. (2013) proposed spectrum-aware rout-
ing solutions to guarantee network QoS requirements.
In their proposed algorithms, the optimal path is se-
lected to minimize end-to-end delays, but the impact
of unpredictable link failure on QoS and communica-
tion performance is not considered. In order to dy-
namically predict the available spectrum resources in
CRSN, a machine learning based routing algorithm is
proposed in (Yu et al., 2010). The authors employ
188
Jin Z., Guan D., Cho J. and Lee B..
A Routing Algorithm based on Semi-supervised Learning for Cognitive Radio Sensor Networks.
DOI: 10.5220/0004712401880194
In Proceedings of the 3rd International Conference on Sensor Networks (SENSORNETS-2014), pages 188-194
ISBN: 978-989-758-001-7
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

Bayesian Learning to estimate the amount of avail-
able resources, and then, the most reliable path that
contains the largest number of available channels is
selected. Unfortunately, this routing scheme is not
feasible because a large amount of labeled data, which
are used to train their learning algorithm, is difficult
to obtain in CRSN.
This paper proposes a new energy efficient routing
algorithm that provides reliable communication per-
formance in CRSN. One of the important features of
the proposed routing scheme is that it can predict the
PUs’ influence on spectrum usability and efficiently
evaluate link stability. In order to achieve this, a
context-aware module was developed to perceive con-
text information such as PUs’ activity and varying ra-
dio resources. A semi-supervised learning algorithm
that can provide good accuracy under limited labeled
data is developed to learn the context information, and
then predict the available radio sources in the future.
Finally, a novel routing metric is defined to indicate
end-to-end link stability, and a stable and reliable path
is selected based on a semi-Dijkstra algorithm.
The contribution of this paper can be summarized
as follows:
• Development of an energy-efficient context-aware
module that integrates context information with a
context learning function.
• Development of a feasible learning method that
can be applied to CRSNs where the available la-
beled data are limited.
• Derivation of a novel routing metric to provide
stable and reliable paths.
The rest of the paper is organized as follows: Sec-
tion 2 discusses the most relevant related work. Sec-
tion 3 presents the proposed semi-supervised based
routing algorithm. Section 4 validates the perfor-
mance of our proposed algorithm through extensive
simulations. Finally, Section 5 concludes the paper.
2 RELATED WORK
Due to opportunistic channel access nature of the cog-
nitive radio technology, routing techniques for tradi-
tional WSNs are unable to satisfy the performance re-
quirements of CRSNs.
There exist many routing techniques for ad-hoc
based cognitive radio networks (CRNs). Sampath
et al. (2008) and Cheng et al. (2007) proposed
an AODV based spectrum-aware routing protocol for
CRNs. Sampth et al. (2008) aim to guarantee end-to-
end performance by integrating flow-based approach
with a link-based one. A routing metric is also derived
based on the number of available channels. Cheng,
et al. (2007) propose an on-demand routing pro-
tocol that selects suitable spectrums for each node
along the path. According to spectrum availability,
Pefkianakis et al. (2008) presented a routing solution
called SAMER to provide long-term and short-term
route, and Wang et al. (2009) proposed multi-path
based routing protocol in order to improve connection
stability. These efforts mainly focused on route and
spectrum selection and considered expected perfor-
mance including throughput, delay, and robustness.
However, these methods cannot be directly applied to
CRSNs because the energy efficiency is not consid-
ered as a design goal.
There is only limited work that focuses on routing
issues in CRSNs. Parvin and Fujii (2011) proposed a
spectrum-aware routing scheme with the goal of guar-
anteeing network QoS. More specially, they define a
utility function which is used to evaluate the end-to-
end delay, and a route with the maximum value is se-
lected. Similar research is addressed by Shah et al.
(2013). The authors design a distributed control algo-
rithm to improve communication performance. Their
primary goal is to guarantee the QoS requirements by
optimizing an objective function, which is derived to
minimize queueing delay (Shah et al., 2013). How-
ever, these routing schemes neglect the impact of un-
predictable link failures on QoS.
In order to predict link failure and dynamically
changing spectrum resources, a machine learning
based routing solution is proposed in (Yu et al., 2010).
Yu et al. (2010) employ the Bayesian learning, which
is one of the supervised learning methods to estimate
the total number of neighboring PUs. The estimated
result is used to reflect the amount of available ra-
dio resources. Based on the estimation, the most reli-
able path that contains the largest number of available
channels is selected. The major shortcoming of this
routing scheme is that the requirement of the super-
vised learning based algorithm is ignored. In order
to make an accurate estimation, the Bayesian learning
needs a large amount of labeled data to train the learn-
ing algorithms. Unfortunately, labeled data is hard
to be obtained in most of CRSNs’ application sce-
narios because the network environment dynamically
changes. Furthermore, their route configuring scheme
neglects dynamic link failures in CRSNs. Therefore,
their routing scheme cannot guarantee reliable end-
to-end communications.
In contrast to the aforementioned related work, the
proposed routing algorithm predicts the PUs’ influ-
ence and evaluates link stability to guarantee reliable
and stable communications.
ARoutingAlgorithmbasedonSemi-supervisedLearningforCognitiveRadioSensorNetworks
189

3 PROPOSED SCHEME
The proposed routing algorithm consists of two parts:
the Context-Aware module and Optimal Path Config-
uration module. The responsibility of the context-
aware module is to learn the characteristics of the
varying environment and predict the stability of
routes. Based on that, the optimal path configuration
module is used to estimate and select the most stable
path to guarantee end-to-end communication reliabil-
ity. The following subsections discuss these parts in
detail.
3.1 Context-aware Module
In order to feasibly estimate the variations in the net-
work environment, semi-supervised learning, which
is a subcase of Machine Learning, is employed in
our routing algorithm. Recently, Machine Learning
has become one of the most efficient and practical
solutions to solve several routing issues (Yu et al.,
2010; Wang et al., 2006; Ahmed and Kanhere, 2010).
Supervised and unsupervised learning methods are
particular cases that perform learning tasks with la-
beled and unlabeled data, respectively. Wang et al.
(2006), and Ahmed and Kanhere (2010) applied the
supervised learning method to their research. How-
ever, their algorithms require a large amount of la-
beled data to train estimate functions. In most of
CRSNs application scenarios, the labeled data are dif-
ficult and/or expensive to obtain. In contrast, the
unsupervised learning method trains it’s estimation
function based on unlabeled data, which are readily
available. However, the unsupervised method is more
complex than its counterpart. Furthermore, the es-
timation accuracy cannot satisfy the communication
requirements of CRSNs. These shortcomings can be
alleviated by semi-supervised learning, which bene-
fits from tactfully utilizing both labeled data and un-
labeled data. The semi-supervised learning method
can provide good learning accuracy even when there
are only a few labeled data. Thus, it is more feasible
than supervised or unsupervised method based one in
CRSNs.
In order to learn the context information of
CRSNs, the routing algorithm needs to gather some
information as labeled data. To predict the link con-
nectivity to sink nodes, each node needs to maintain
the following context features:
• Neighbor node IDs (D
1
,D
2
,...,D
n
), and sink node
IDs (S
1
,S
2
,...,S
m
).
• Current time slots (t
1
,t
2
,...,t
k
) assuming that time
of day T is divided into k slots.
• Currently available channel set (Ch
1
,Ch
2
,...,Ch
c
)
assuming a set of locally available channels.
In order to guarantee energy efficiency, the con-
text information collection is performed in a passive
manner. In the network initialization step, the sink
node broadcasts HELLO message using a common
control channel (CCC). In addition to the initializa-
tion step, the message is broadcast repeatedly with a
period (T + ε)/k. During this period, ε is randomly
selected within a time interval δ (δ T /k) to pre-
vent congestion. The HELLO message is one of the
control packets that contains sink nodes’ IDs, locally
available channel set, and a connectivity label Y (Yes)
or N (No) field. A sink node sends the message af-
ter setting the connectivity label as Y . This message
is identified by the sink node ID and the current time
slot. A CRSD may receive many copies of the same
message from one of the neighbors. In this case,
the CRSD only forwards the first one to downstream
neighbors.
When a node receives a HELLO message, it
checks its label and the available channel set of the
sender. If the label is Y and they have the common
available channels, the node retains the label. Oth-
erwise, the node changes the label to N. Before for-
warding the message, the node stores the context in-
formation, which consists of sink ID, sender ID, the
current time slot, and the label in local memory. Then,
the localized context information is updated to the
message. The node stops the forwarding until there
are no downstream neighbors.
Through HELLO message forwarding, every
CRSD can maintain the labeled context information
and should know whether it is successfully connected
to a sink node. For example, a context information
hS
1
,t
2
,D
5
,{Ch
2
,Ch
3
,Ch
4
},Yi indicates that the node
can successfully communicate with sink S
1
at time
slot t
2
using the relay node D
5
, and the available chan-
nel set {Ch
2
,Ch
3
,Ch
4
}.
The pseudo-code description of the proposed al-
gorithm is given in Fig. 1. Let L
i
denote the labeled
context information and U
i
denote all possible com-
bination of the unlabeled context information in D
i
.
Two classifiers h
1
and h
2
are initially trained from L
i
.
Then, the classifiers are used to label U
i
· u
k
i
, which
indicate k
th
unlabeled context information in D
i
can
be labeled if both of the classifiers agree on the label-
ing. When one of classifier disagree with the other
one, the decision is made after comparing with a con-
fidence threshold value τ. After labeling u
k
i
, the node
adds it to labeled context information and then obtains
L
new
i
= L
i
∪u
k
i
. Then, the algorithm picks up u
k+1
i
and
repeats this procedure. This process is repeated un-
til there are no more confident unlabeled data to be
SENSORNETS2014-InternationalConferenceonSensorNetworks
190
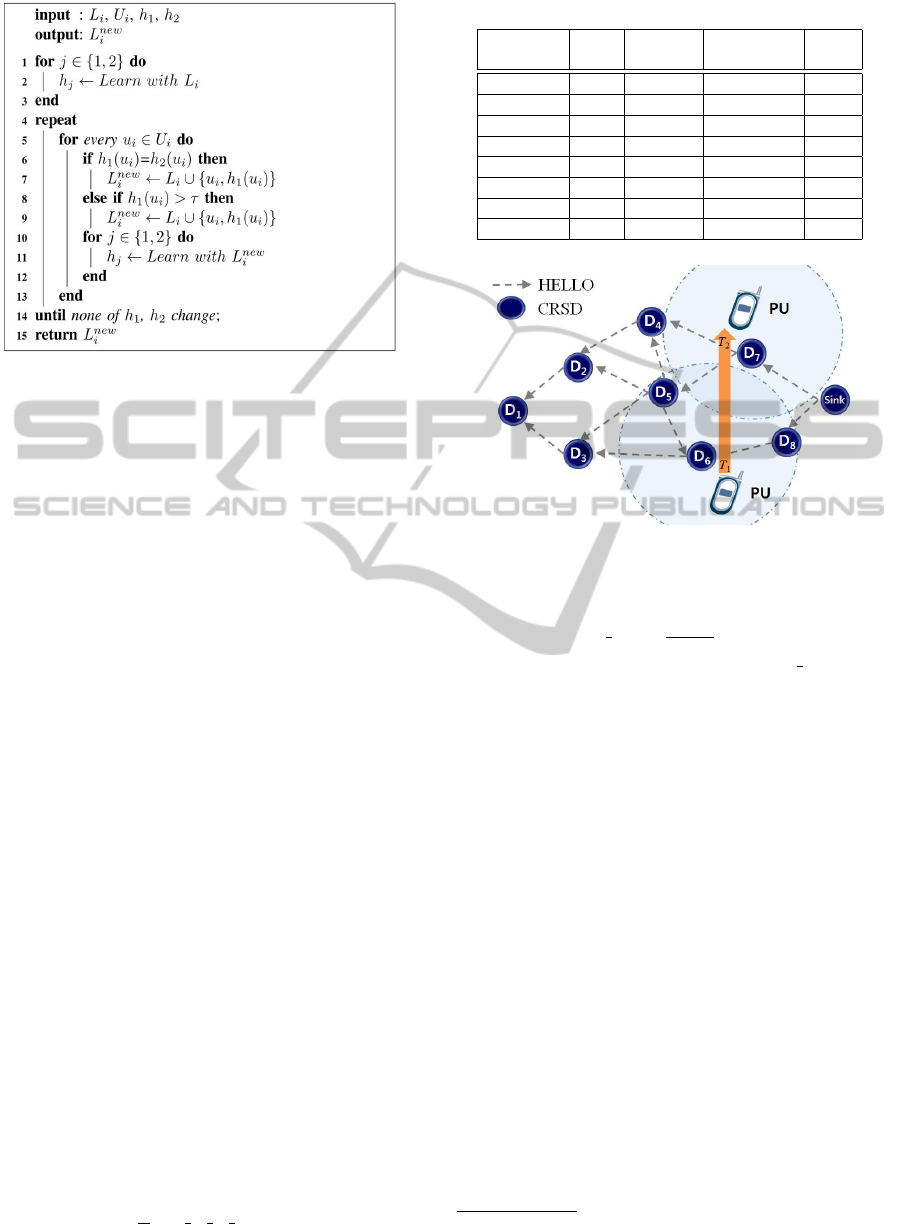
Figure 1: Pseudo-code for the learning algorithm.
selected.
In this paper, we employ the naive-Bayes classi-
fier and decision tree learning as the classifiers h
1
and
h
2
, respectively. The naive-Bayes classifier, which is
based on the Bayes rule, is widely employed in pos-
terior probability calculation with priori information.
The naive-Bayes classifier is defined by the following
equation:
h
1
(u
k
i
) = argmax
l∈{Y,N}
P(l)
∏
j
P(X
j
|l), (1)
where X
j
represents the context information value and
l denotes the labels (l ∈ {Y,N}).
The decision tree learning makes decision by di-
viding the classification into a set of choices, and
starting at the root of the tree and progressing down
to the leaves (Marsland, 2009). Usually, the attribute
that has the highest information gain for the label is
selected as the root node and the parent nodes. The
information gain can be calculated using the entropy
of the attribute (Marsland, 2009).
The following example illustrates the proposed al-
gorithm. Fig. 2 shows a CRSN where CRSDs oc-
cupy four licensed channels. We assume that a PU
is moving through the CRSN during t
1
to t
2
. With
the HELLO message traverses the entire network, D
2
collects the localized context information as shown in
Table 1, which shows both the labeled and unlabeled
context information. After training the classifiers with
the labeled data, they are used to classify the unla-
beled data (the last four rows of the table). When the
algorithm selects an unlabeled data hS,t
1
,D
4
,Ch
4
i,
which is obtained form the 5
th
row in the table, the
inference results is shown as follows:
P(Y )
∏
j=4
P(X
j=4
|Y ) =P(Y )P(S|Y )P(t
1
|Y )P(D
1
|Y )P(Ch
4
|Y )
=
8
10
×1×
3
8
×
5
8
×
1
8
=0.023,
(2)
Table 1: Labeled and unlabeled data in the CRSD.
Destination
Time
slot
Neighbor
Available
channels
Label
S t
1
D
4
Ch
1
,Ch
2
,Ch
3
Y
S t
1
D
5
Ch
2
,Ch
4
N
S t
2
D
4
Ch
1
,Ch
3
Y
S t
2
D
5
Ch
2
,Ch
3
,Ch
4
Y
S t
1
D
4
Ch
4
?(N)
S t
2
D
4
Ch
2
?(Y )
S t
2
D
4
Ch
4
?(Y )
S t
2
D
5
Ch
1
?(Y )
Figure 2: Context information gathering.
P(N)
∏
j=4
P(X
j=4
|N) =P(N)P(S|N)P(t
1
|N)P(D
1
|N)P(Ch
4
|N)
=
1
4
×1×1×
0+mp
D
2
1+m
×1
=0.042, where m=10, p
D
2
=
1
2
.
(3)
Eq. (2), and Eq. (3) indicate the packet de-
livery probability in Y and N cases, respectively.
By substituting the results to Eq. 1, there is
P(N)
∏
j=4
P(X
j=4
|N) > P(Y )
∏
j=4
P(X
j=4
|Y ), and then
the algorithm obtains the inference result as:
h
1
(u
1
2
) = N. (4)
The other inference result can be obtained after
constructing a decision tree
1
as shown in Fig. 3.
Based on the decision tree, the inference decision be-
comes:
h
2
(u
1
2
) = N. (5)
Note that the intersection of the inference results is
not empty; therefore, the unlabeled data is labeled as
h
1
(u
1
2
) ∩ h
2
(u
1
2
) = N. Then, the labeled data set L
2
is
updated with the labeled data u
1
2
=
h
S, t
1
, D
4
, Ch
4
,N
i
,
and a new set of labeled data is L
new
2
= L
2
∪ u
1
2
. The
augmented labeled set can then be used to retrain the
classifiers in an iterative manner until the termination
condition is satisfied.
1
We skip derivation process of the decision tree. Read-
ers can refer to Chapter 6 in (Marsland, 2009).
ARoutingAlgorithmbasedonSemi-supervisedLearningforCognitiveRadioSensorNetworks
191
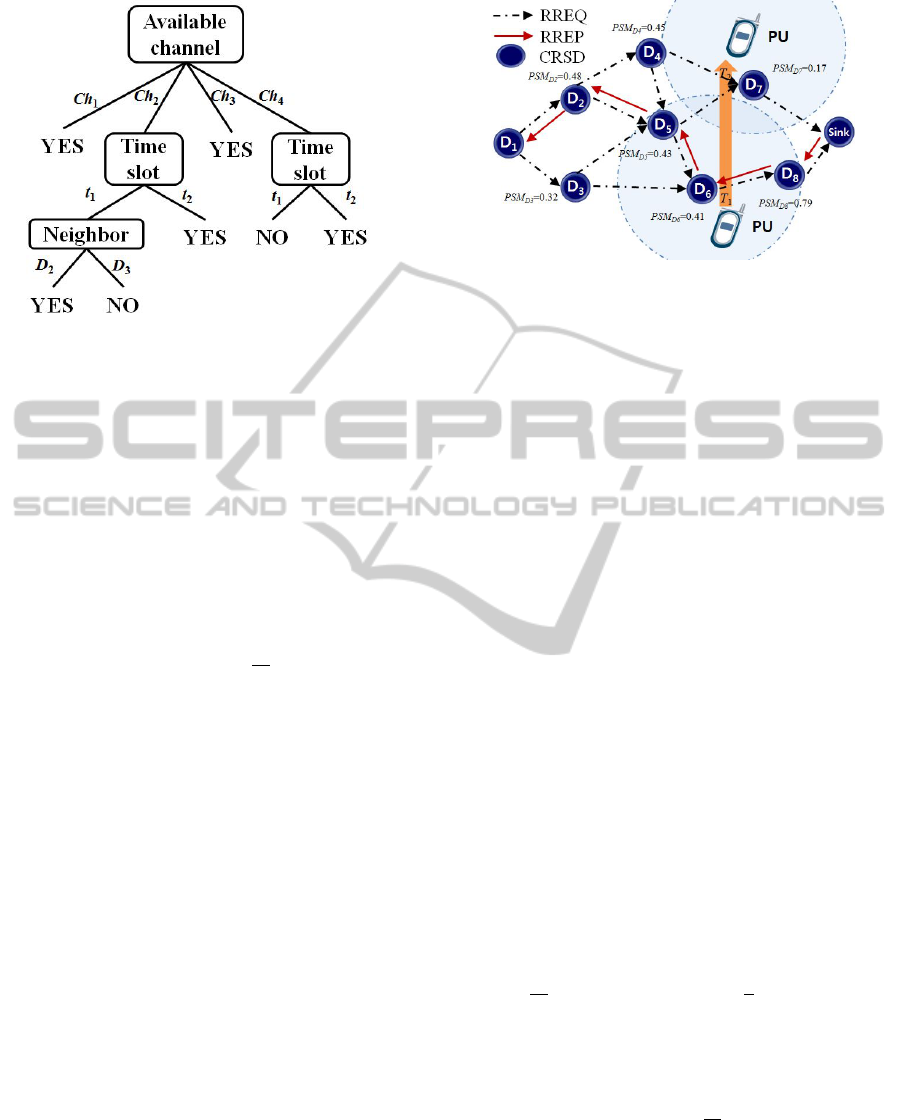
Figure 3: The decision tree.
Finally, the labeled context information is stored
in local memory to further predict the stability of
routes, and also is used to derive a novel routing met-
ric for selecting optimal path as discussed in the fol-
lowing subsection.
3.2 Optimal Path Configuration
In order to evaluate the benefit of an intermediate
node for path stability, a new routing metric called
Path Stable Metric (PSM) is defined as follows:
PSM = θ
∑
j∈c
h
1
(u
new
i
) +(1 −θ)
1
n
c
∑
j∈c
h
2
(u
new
i
),
(6)
where c and n
c
denote the available channel set and
the number of channels in c, respectively, and θ (0 ≤
θ ≤ 1) is a weighted parameter for controlling the pro-
portion of the two classifiers.
In this paper, we assume that only one channel can
be occupied at a time. This indicates that any chan-
nel in the available channel set is independent of the
others. Therefore, the routing metric must be derived
by cumulating each channel’s stability. The first term
in the right side of the equation is obtained by h
1
(·).
The other one is obtained from h
2
(·). If the label is Y ,
h
2
(·) = 1; otherwise, h
2
(·) = 0.
When a CRSD receives a routing request from
the upper layer, it broadcasts route request (RREQ)
packets (Perkins and Royer, 1999) on CCC. The mes-
sage contains sink node ID and its currently avail-
able channel set. If the neighbors who receive this
message have the common available channels with
the sender, the nodes calculate local PSMs. Before
forwarding the RREQ, intermediate nodes add its ID
and PSM, and update available channel information
with locally available channels. Finally, when the sink
node receives the RREQ, a connectivity diagram is
constructed based on contained intermediate nodes’
Figure 4: Optimal path selection.
ID and PSM information. Note that the sink node can
receive multiple copies of the same RREQ packets
from different neighbor nodes. In that case, the con-
nectivity diagram should be updated only if a mes-
sage contains a new PSM information. Every up-
dated topology will trigger the semi-Dijkstra algo-
rithm to find the path with the highest PSM. Then, the
sink node sends a route reply (RREP) packet through
the selected path. The RREP packet contains all the
nodes’ IDs along the path; therefore, the source node
can send data packets to the sink node along the most
stable path.
In order to illustrate the optimal path configura-
tion, consider again the context data learning exam-
ple discussed in Subsection 3.1 and shown in Fig.
4. Suppose that node D
1
broadcasts a RREQ mes-
sage, which consists of the current context informa-
tion hS,t
2
,{Ch
1
,Ch
2
}i, at time slot t
2
. When the
neighbor node D
2
receives the message, it checks the
intersection of available channel set. If they have
a common set of available channels (In this case,
their common available channel set is {Ch
1
,Ch
2
} ∩
{Ch
1
,Ch
2
,Ch
3
,Ch
4
} = {Ch
1
,Ch
2
}, and θ = 0.7 ),
then the PSM is calculated as follows:
θ
∑
j∈c
h
1
(u
new
1
) = θ(P(Y )P(S|Y )P(t
2
|Y )P(Ch
1
|Y )
+ P(Y )P(S|Y )P(t
2
|Y )P(Ch
2
|Y ))
= 0.182,
(7)
(1 −θ)
1
n
c
∑
j∈c
h
2
(u
new
1
) = (1 −0.7)
1
2
(1 +1) = 0.3.
(8)
By substituting the results to Eq. (9), PSM for D
2
is
given by
PSM
D
2
= θ
∑
j∈c
h
1
(u
new
1
) + (1 − θ)
1
n
c
∑
j∈c
h
2
(u
new
1
) = 0.482.
(9)
PSMs for the other nodes in Fig. 4 are derived in
the same manner.
After receiving the RREQ message, the sink node
can construct a network topology as shown in Fig.
SENSORNETS2014-InternationalConferenceonSensorNetworks
192
4. Using the semi-Dijkstra’s algorithm, the sink node
can find the most reliable and stable path and then re-
ply to D
1
with a RREP.
4 PERFORMANCE EVALUATION
In this section, we evaluate the performance of the
proposed scheme through simulation. We randomly
deploy 100 CRSDs in a simulated area 100 × 50 m
2
.
The packet size is set to 100 bytes, and one CCC and
four licensed channels are available in the simulation
environment. We assume that the transmission range
of CRSD is 5 m and the interference rage is 10 m. The
activity of PUs is a Poisson process with arrival rate λ.
We also assume that CRSD stops transmission imme-
diately if it suffers from PUs’ interference. Since the
naive-Bayes classifier has been shown to be more sta-
ble and provide better performance than decision tree
based methods (Marsland, 2009), the proposed rout-
ing algorithm uses θ=0.7 indicating that more trust is
given to the naive-Bayes classifier.
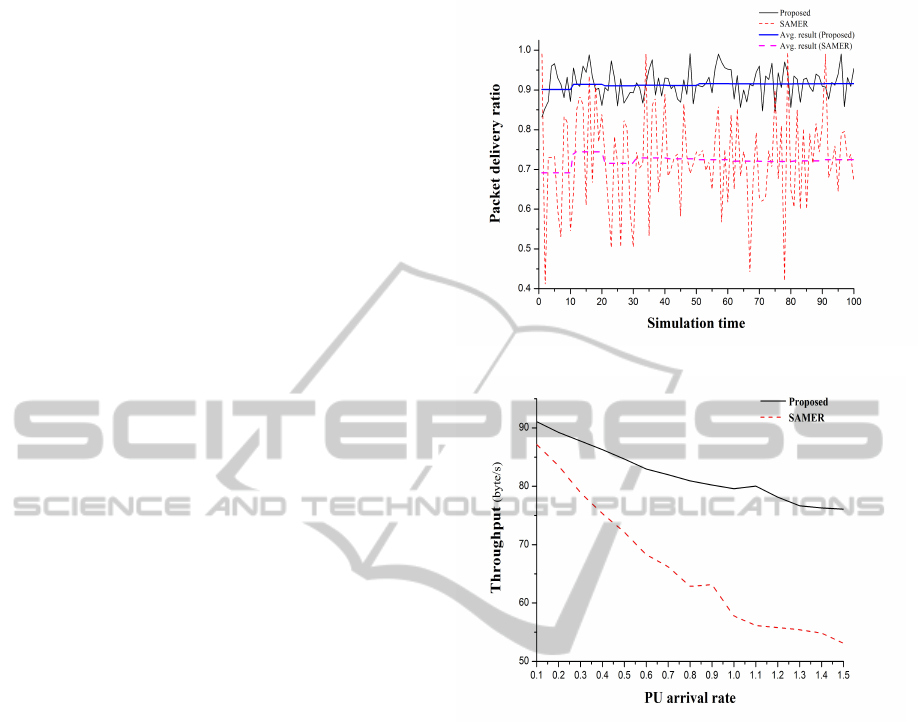
The proposed routing algorithm is compared with
SAMER (Pefkianakis et al., 2008), which uses the
minimum hop count as the route selection metric. Fig.
5 compares the communication reliability of the two
routing algorithms. For each simulation run, the ar-
rival rate λ is randomly selected in the interval of
0.15−0.5. We can observe from Fig. 5 that the packet
delivery ratio is not stable when the network employs
minimum hop-count as the routing metric. This is be-
cause the performance of SAMER is significantly af-
fected by how often the minimum hop-count path is
interrupted by PUs. As the simulation proceeds, the
average packet delivery ratio of SAMER converges
to 72% which cannot satisfy most QoS requirements.
In comparison, the proposed semi-supervised based
routing algorithm shows more stable packet delivery
ratio and the average performance converged to 92%.
More specifically, the proposed routing protocol pro-
vides 28% performance gain over SAMER. There are
two main reasons for this. First, the proposed Context
Aware module can intelligently estimate the scalabil-
ity of the path. Second, the most stable path, which
has the lowest possibility of interruption, can be ef-
fectively established based on the proposed routing
metric. Furthermore, the proposed method can effi-
ciently avoid PUs’ influence; therefore, extra energy
consumption caused by frequent retransmissions can
also be efficiently avoided.
Fig. 6 shows that the proposed method clearly
outperforms SAMER in terms of throughput. As
the arrival rate of PUs increases, the throughput for
SAMER drastically decreases. This is because the ac-
Figure 5: Packet delivery ratio.
Figure 6: The network throughput
tive behavior of PUs has a significant impact on the
system throughput. Although SAMER has benefits in
terms of minimum hop routing and low transmission
delay, it cannot provide satisfactory throughput due
to the influence of PUs. The proposed routing algo-
rithm shows more stable performance than SAMER,
even when the arrival rate of PUs is increased. This is
due to the fact that the proposed routing algorithm re-
duces the probability of route failure by learning and
estimating the activity and channel utilization of PUs.
5 CONCLUSIONS
This paper presented a semi-supervised learning
based routing algorithm that predicts and minimizes
the influence of PUs. The proposed routing algorithm
consists of Context-Aware and Optimal Path Config-
uration modules, and uses a feasible semi-supervised
learning algorithm to perceive variation of the net-
ARoutingAlgorithmbasedonSemi-supervisedLearningforCognitiveRadioSensorNetworks
193

work connectivity. In addition, a novel routing metric
is derived to estimate end-to-end connection stabil-
ity. The optimal path, which is the most stable in the
network topology, is selected using the semi-Dijkstra
algorithm. Finally, our simulation study shows that
the proposed method effectively provides reliable and
stable paths, and improves system throughput. We
are currently in the progress of designing an energy-
efficient cross-layer routing algorithm, which com-
bines spectrum selection with route configuration by
applying a feasible machine learning method.
ACKNOWLEDGEMENTS
This work was supported by the MSIP(Ministry of
Science, ICT & Future Planning), Korea, under the
ITRC(Information Technology Research Center) sup-
port program supervised by the NIPA(National IT
Industry Promotion Agency) (NIPA-2013-(H0301-
13-2001)) and by Mid-career Researcher Program
through NRF grant funded by the MEST (No. 2011-
0015744).
REFERENCES
Ahmed, S. and Kanhere, S. (2010). A bayesian routing
framework for delay tolerant networks. In Proc. of
WCNC’10.
Akan, O. B., Karli, O. B., and Ergul, O. (2009). Cogni-
tive radio sensor networks. IEEE Network Magazine,
23(4).
Ali, A., Iqbal, M., Baig, A., and Wang, X. (2011). Rout-
ing techniques in cognitive radio networks: A survey.
International Journal of Wireless & Mobile Networks,
3(3).
Cesana, M., Cuomo, F., and Ekici, E. (2011). Routing in
cognitive radio network: Challenges and solutions. In-
ternational Journal on Ad Hoc Networks, 9(3).
Cheng, G., Liu, W., and Cheng, W. (2007). Spectrum aware
on-demand routing in cognitive radio networks. In
Proc. of DySPAN’07.
Marsland, S. (2009). Machine Learning: An Algorithmic
Perspective. A Chapman & Hall.
Pefkianakis, I., Wong, S. H. Y., and Lu, S. (2008). Samer:
Spectrum aware mesh routing in cognitive radio net-
works. In Proc. of DySPAN’08.
Perkins, C. E. and Royer, E. M. (1999). Ad-hoc on-demand
distance vector routing. In Proc. of WMCSA’99.
Sampath, A., Yang, L., Cao, L., and Zhao, B. Y. (2008).
High throughput spectrum-aware routing for cognitive
radio networks. In Proc. of CROWNCOM’08.
Shah, G., Gungor, V., and Akan, O. (2013). Routing in cog-
nitive radio network: Challenges and solutions. IEEE
Tran. on Industrial Informatics.
Wang, X., Kwon, T., and Choi, Y. (2009). A multipath rout-
ing and spectrum access framework for cognitive ra-
dio systems in multi-radio networks. In Proc. of ACM
Workshop on Cognitive Radio Networks.
Wang, Y., Martonosi, M., and Peh, L. S. (2006). Super-
vised learning in sensor networks: new approaches
with routing, reliability optimizations. In Proc. of
SECON’06.
Yu, R., Zhang, Y., Yao, W. Q., Song, L. Y., and Xie, S. L.
(2010). Spectrum-aqare routing for reliable end-to-
end communications in cognitive sensor networks. In
Proc. of IEEE Globecom’10.
SENSORNETS2014-InternationalConferenceonSensorNetworks
194
