
Constructing a Non-task-oriented Dialogue Agent using Statistical
Response Method and Gamification
Michimasa Inaba
1
, Naoyuki Iwata
2
, Fujio Toriumi
3
, Takatsugu Hirayama
2
, Yu Enokibori
2
,
Kenichi Takahashi
1
and Kenji Mase
2
1
Graduate School of Information Sciences, Hiroshima City University,
3-4-1 Ozukahigashi, Asaminami-ku, Hiroshima, Japan
2
Graduate School of Information Sciences, Nagoya University, Furo-cho, Chikusa-ku, Nagoya, Japan
3
School of Engineering, University of Tokyo, 7-3-1 Hongo, Bunkyo-ku, Tokyo, Japan
Keywords:
Non-task-oriented, Dialogue Agent, Crowdsourcing, Gamification.
Abstract:
This paper provides a novel method for building non-task-oriented dialogue agents such as chatbots. The
dialogue agent constructed using our method automatically selects a suitable utterance depending on a context
from a set of candidate utterances prepared in advance. To realize automatic utterance selection, we rank the
candidate utterances in order of suitability by application of a machine learning algorithm. We employed both
right and wrong dialogue data to learn relative suitability to rank the utterances. Additionally, we provide
a low-cost and quality-assured learning data acquisition environment using crowdsourcing and gamification.
The results of an experiment using learning data obtained via the environment demonstrate that the appropriate
utterance is ranked on the top in 82.6% of cases and within the top 3 at 95.0% of cases. Results show that
using context information that is not used in most existing agents is necessary for appropriate responses.
1 INTRODUCTION
A great demand exists for computerized dialogue
agents. They are increasingly used in many differ-
ent areas. Dialogue agents are categorizable into
two types according to their task perspective: task-
oriented dialogue agents and the non-task-oriented di-
alogue agents(Isomura et al., 2009). Task-oriented di-
alogue agents are used to accomplish particular tasks
such as reservation services (Zue et al., 1994), supply-
ing specific information (Chu-Carroll and Nickerson,
2000), etc. Non-task-oriented dialogue agents have
no such tasks and only chat with us.
Non-task-oriented dialogues play a critical role in
human society because they are an important tool for
building relationships. Robots and other anthropo-
morphic agents are expected to participate increas-
ingly in our daily lives. Therefore, much more inves-
tigation is needed on how non-task-oriented dialogue
agents can be designed so that they can develop good
relationships with people.
Even a task-oriented dialogue agent can accom-
plish a task more efficiently using non-task-oriented
dialogues. For example, a study by Bickmore showed
that when dialogue agents that supported the buying
and selling of real estate initially chatted about sub-
jects not pertinent to real estate such as the weather,
people were much more motivated to buy real estate
through them than through agents that did not engage
in non-task-oriented dialogues (Bickmore and Cas-
sell, 2001).
As described in this paper, we propose a construc-
tion method for non-task-oriented dialogue agents
that are based on the statistical response method. In
fact, two major response methods exist for non-task-
oriented dialogue agents.
The first of these are rule-based methods that pro-
duce utterances in accordance with response rules.
Well-known dialogue agents which use this strategy
are ELIZA (Weizenbaum, 1966) and A.L.I.C.E. (Wal-
lace, 2009). Mitsuku (Worswick, 2013) which the
Loebner prize contest
1
(non-task-dialogueagent com-
petition) winner of 2013 also used this strategy. The
problem of this strategy is their substantial cost be-
cause the rules are developed by hand work.
The other is example-based method (Murao et al.,
1
http://www.loebner.net/Prizef/loebner-prize.html
14
Inaba M., Iwata N., Toriumi F., Hirayama T., Enokibori Y., Takahashi K. and Mase K..
Constructing a Non-task-oriented Dialogue Agent using Statistical Response Method and Gamification.
DOI: 10.5220/0004722000140021
In Proceedings of the 6th International Conference on Agents and Artificial Intelligence (ICAART-2014), pages 14-21
ISBN: 978-989-758-015-4
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

2003; Banchs and Li, 2012). A dialogue agent em-
ploying this strategy searches a large database of di-
alogue by user input (a user’s utterance) using cosine
similarity and selects an utterance that follows after
the most similar one as a response. The problem is
how it acquires a large quantity of good quality dia-
logues efficiently because the performance depends
on the quality of dialogues in the database. A re-
sponse method based on statistical machine transla-
tion (Ritter et al., 2011) has been proposed. It treats
last user’s utterance as input sentence and translates
it into the response utterance. This method is cate-
gorized as the example-based method and has same
problem.
The mutual problem of the two is that it cannot
use a context (sequence of utterances) but a given last
user’s utterance. According to the rule-based method,
necessary rules and the costs of creating them are ex-
tremely increased. Regarding example-based meth-
ods, if it searches the database by a context, in many
cases, then it cannot find a similar one because of the
diversity of non-task-oriented dialogues. When the
method cannot find a similar one, it has no choice but
to use random selection.
Our statistical response method belongs to the cat-
egory of example-based method because it uses dia-
logue data. However, our method, which uses no co-
sine similarity but statistical machine learning, is able
to use contexts. Our method prepares candidate ut-
terances in advance. It learns which utterances are
suitable for context by the data. Therefore, a dia-
logue agent that is constructed using our method au-
tomatically selects a suitable utterance depending on
a context from candidate utterances. Additionally,
we provide a low-cost and quality assurance method
of learning data acquisition using crowdsourcing and
gamification.
2 STATISTICAL RESPONSE
METHOD
2.1 Selection of Candidate Utterances
As described in this paper, we define “utterance” as
a one-time statement and “context” as an ordered set
consisting of utterances from the conversation’s be-
ginning to the specific point in time. Here, “an utter-
ance is suitable to a context” means the utterance is
a “humanly” and semantically appropriate answer to
the context.
First, we define a state of a point of time in a di-
alogue as context c = { u
1
, u
2
, . . . , u
l
}. Each u
i
(i =
Table 1: Example of context c.
No. Speaker Utterance
u
4
Agent Are you good at English?
u
3
Human No I am not.
I love Japanese.
u
2
Agent It is said that experience is
important to enhance English
communication skills.
u
1
Human I see! It might be a good idea to
travel abroad during summer
vacation.
u
0
(Agent) (Select an utterance from Table2)
Table 2: Example of candidate utterance set A
c
.
No. Utterance
a
c
1
Are you good at English?
a
c
2
[r
c
1
] Where do you want to go?
a
c
3
I think dogs are trustworthy and intelligent
animals.
a
c
4
[r
c
2
] That would be nice.
...
a
c
20
[r
c
3
] Travel can make a person richer inside.
...
a
c
130
A link exists between mental and
physical health.
1, 2, . . . , l) denotes an utterance appearing in the con-
text and l denotes a number of utterances. Herein, u
1
is the last utterance; u
l
is the first utterance in context
c. As a matter of practical convenience, u
0
represents
a response utterance to context c.
Second, we define a candidate utterance set A
c
=
{a
c
1
, a
c
2
, . . . , a
c
|A
c
|
}, where a
c
i
(i = 1, 2, . . . , |A
c
|) denotes
a candidate utterance. Here, A
c
contains suitable and
unsuitable utterances to context c. |A
c
| represents a
number of candidate utterances. We define the cor-
rect utterance set R
c
= {r
c
1
, r
c
2
, . . . , r
c
|R
c
|
} ⊆ A
c
, where
r
c
i
(i = 1, 2, . . . , |R
c
|) denotes a correct utterance. |R
c
|
represents a number of correct utterances to context c.
The utterance selection means acquiring a correct ut-
terance set R
c
from a candidate utterance set A
c
, given
a context c. Here, we assume that c and A
c
fulfill the
following requirements.
• A
c
can be generated by any context c.
• A
c
has at least one correct utterance r
c
i
for context
c.
Table 1 and 2 present examples of c, A
c
, and R
c
(R
c
is shown by the darker-shadedarea). In this exam-
ple, a suitable utterance to context c shown in Table 1
is selected from the candidate utterance set A
c
shown
in Table 2. The utterance should be selected from the
correct utterance set R
c
= {a
c
2
, a
c
4
, a
c
20
} in this case.
ConstructingaNon-task-orientedDialogueAgentusingStatisticalResponseMethodandGamification
15

2.2 Ranking Candidate Utterances
We describe the method used in our study to select
candidate utterances automatically.
By specifically processing c and a
c
i
(∈ A
c
), we
generate n-dimensional feature vector Φ(c,a
c
i
) =
x
1
(c, a
c
i
), x
2
(c, a
c
i
), . . . , x
n
(c, a
c
i
)
that represents rela-
tions between the context and the candidate utterance.
Each x
j
(c, a
i
)( j = 1, 2, . . . , n) is a feature represent-
ing a binary value. For instance, when particularly
addressing the last utterance u
1
in c and a
i
, a feature
x
j
(s, a
c
i
) is represented if it contains a specific word, a
word class, or a combination of the two.
We then defined f as a function that will return the
evaluated value of a feature vector. In the following
passages, we expressed the feature vector Φ(c, a
i
) as
Φ
i
. Here it can be denoted using a linear function,
which can be expressed as follows:
f (Φ
j
) =
n
∑
j=1
w
j
x
j
(c, a
c
i
). (1)
Therein, w
j
is a parameter representing the weight of
x
j
(c, a
c
i
)
Using the evaluation function above, optimum ut-
terance ˆa in response to the context is obtainable by
the following equation:
ˆa = argmax
a∈A
c
f(Φ
j
). (2)
Therefore, the candidate utterances can be ranked
by sorting the value from the above evaluation func-
tion.
To estimate the parameter w
w
w = (w
1
, w
2
, . . . , w
n
)
in evaluation function f, we use a learning to rank
method ListNet(Cao et al., 2007) algorithm.
2.3 Parameter Estimation
ListNet is constructed for ranking objects. It uses
probability distributions for representing the ranking
lists of objects. Then, minimizing the distance be-
tween learning data and distribution of the model, it
learns suitable parameters for ranking.
We define Y
c
= {y
c
1
, y
c
2
, . . . , y
c
|A
c
|
} as a score list to
candidate utterance set A
c
= {a
c
1
, a
c
2
, . . . , a
c
|A
c
|
}. Each
score y
c
i
(i = 1, 2, . . . , |A
c
|) denotes the score of a can-
didate utterance a
c
i
with respect to context c. Score
y
c
i
represents the degree of correctness a
c
i
to c and is
an evaluated value given by humans. For instance, if
a candidate utterance is a suitable response to a con-
text, the score is 10. Alternatively, if an utterance is
unsuitable, the score is 1.
ListNet parameter estimation algorithm uses pairs
of X
c
=
Φ
1
, Φ
2
, . . . , Φ
|A
c
|
which is a list of feature
vectors and Y
c
as learning data which are ranked cor-
rectly.
Here, for the list of feature vectors X
c
, us-
ing function f, we obtain a list of scores Z
c
=
f(Φ
1
), f(Φ
2
), . . . , f(Φ
|A
c
|
)
. The objective of learn-
ing is to minimize difference between Y
c
and Z
c
in
respect to their rankings. We then formalize it using a
loss function.
G(C) =
∑
∀c∈C
L(Y
c
, Z
c
) (3)
Therein, C means all contexts in learning data and L
is loss function. In ListNet, the cross entropy is used
as a loss function.
H(p, q) = −
∑
x
p(x)logq(x) (4)
In that equation, p(x) and q(x) are probability distri-
butions. When p(x) and q(x) show an equal distribu-
tion, cross entropy H(p, q) takes a minimum value.
Therefore, the lists of scores Y
c
and Z
c
are
converted into probability distributions using the
Plackett–Luce model (Plackett, 1975; Luce, 1959).
The distribution of Y
c
using the Plackett–Luce model
for the top rank utterance is expressed as follows.
P
Y
c
(Φ
i
) =
pow(α, y
c
i
)
∑
|A
c
|
j=1
pow(α, y
c
j
)
(5)
In that equation, pow(α, y) denotes α to the power of
y. This equation represents the probability distribu-
tion of a candidate utterance being ranked on the top.
The higher the candidate utterance score is, the higher
the probability becomes. For instance, when a list of
feature vectors X
c
is (Φ
1
, Φ
2
, Φ
3
) and a list of scores
Y
c
is (1, 0, 3), then the probability of Φ
3
being ranked
on the top is calculated as follows (α = 2).
P
Y
c
(Φ
3
) =
pow(2, y
c
3
)
pow(2, y
c
1
) + pow(2, y
c
2
) + pow(2, y
c
3
)
=
pow(2, 3)
pow(2, 1) + pow(2, 0) + pow(2, 3)
= 0.727
(6)
Instead, the probability of Φ
1
being ranked on the top
is 0.182 and Φ
2
is 0.091, which is the lowest.
Similarly, the distribution of Z
c
can be converted
into a probability distribution as follows.
P
Z
c
(Φ
i
) =
pow
α, f(Φ
i
)
∑
|A
c
|
j=1
pow
α, f(Φ
j
)
(7)
Using Eq. (4), (5) and (7), then the loss function
L(Y
c
, Z
c
) becomes
L
Y
c
, Z
c
= −
|A
c
|
∑
i=1
P
Y
c
(Φ
i
)log
P
Z
c
( f)
(Φ
i
)
(8)
Optimum parameter ω
ω
ω is obtainable using Gradient
Descent.
ICAART2014-InternationalConferenceonAgentsandArtificialIntelligence
16

Figure 1: Context and candidate utterances on our crowd-
sourcing website.
3 DATA ACQUISITION
3.1 Crowdsourcing
Human work is important for acquiring data. To ac-
quire data, we used crowdsourcing and opened a web-
site for it.
The crowdsourcing website shows a context c and
5 candidate utterances (6 options) as shown in Fig-
ure 1 to participants. They select suitable candidate
utterances to the context or “(There is no suitable ut-
terance)”. Then, we can acquire the pair of c and the
selected utterance as a correct pair, or acquire c and
these five utterances as an incorrect pair for learning.
If a participant selects the option “Having strong com-
munication skills is paramount if you want to be suc-
cessful.” as shown in Figure 1, then the pair of the
context and the utterance are acquired as correct data.
When participants select “(There is no suitable ut-
terance)”, they must write a suitable utterance manu-
ally in the textbox. This way, we can acquire new can-
didate utterances. However, we do not use these utter-
ances in crowdsourcing and subsequent experiments
in this paper because they entail some problems such
as spelling errors, phraseology, etc. We will use this
function to collect new utterances continuously and
produce a dialogue agent to handle even the newest
topics in the future.
3.2 Confidence Estimation
When we use crowdsourcing, quality control of ac-
quired data is necessary. We offer this to the gen-
eral public. Therefore, quality gaps are unavoidable.
In this study, we prepare several evaluated questions
that comprise a context c, unsuitable utterances, and
one or more suitable utterances. The suitability and
unsuitability are judged in advance by four evalua-
tors. We adopt the utterances which reach a consensus
on the suitability or unsuitability among evaluators as
evaluated ones.
The website measures the degree of confidence p
by these evaluated questions. The degree of confi-
dence p is calculated by counting how many times the
suitable utterance is selected within N
p
trials. Conse-
quently, the range of p is 0 ≤ p ≤ N
p
.
Our crowdsourcing website presents 10 questions
in a row: 5 questions for data acquisition and 5 ques-
tions for measuring the degree of confidence (N
p
= 5).
We decide whether the acquired data are available or
not according to the degree of confidence p because,
if p is small, then the possibility exists that the par-
ticipant did not work seriously. To let participants an-
swer seriously for all questions, the website does not
tell participants which question is intended for data
acquisition.
3.3 Gamification
One of the most important considerations with crowd-
sourcing is rewards to participants. If we set high
rewards, then we can gather many participants and
acquire much data. To construct a better non-task-
oriented dialogue agent that can accommodate top-
ics of many kinds, it is desirable to acquire new data
continuously. Although the agent requires many new
data, setting high rewards increases the cost of con-
struction and the unserious users who don’t address
the task properly.
In this study, we bring game mechanics to data
acquisition to gather participants with no rewards.
Bringing game mechanics, participants enjoy the task
like game play. Such a method brings game me-
chanics to accomplish an objective called “gamifica-
tion”(Von Ahn and Dabbish, 2004; Deterding et al.,
2011).
3.4 Gamified Data Acquisition
Environment
We opened a website “The diagnosis game of di-
alogue skills“
2
(Japanese text only) as a gamified
crowdsourcing data acquisition environment. At this
site, participants answer 10 questions and finally ob-
tain a score for dialogue skills. The score goes up to
100 points. The score becomes higher if a participant
2
http://beta.cm.info.hiroshima-cu.ac.jp/DialogCheck/
ConstructingaNon-task-orientedDialogueAgentusingStatisticalResponseMethodandGamification
17
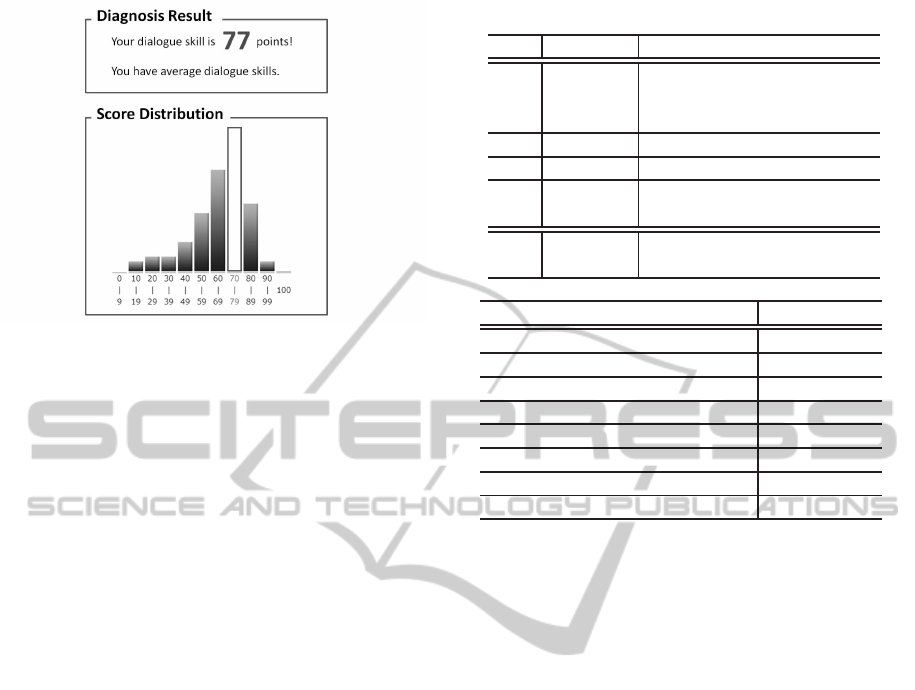
Figure 2: Diagnosis game result.
selects a candidate utterance that many other partici-
pants selected. At the same time, the website shows a
graph of score distribution for comparison with other
participants. Figure 2 portrays an example of a game
result.
Scoring the results of selection and comparison
with those of the other participants stimulates partici-
pants’ retrial motivation,by which they want to obtain
a higher score. Additionally, by posting the score on
SNS or micro blogs by themselves, we expect adver-
tising effects for other people (the website has a tweet
button to tweet their score easily).
4 EXPERIMENTS
4.1 Experimental Methodology
To underscore the effectiveness of the statistical re-
sponse method that learns data acquired through the
gamified data acquisition environment, we checked
the ranking of suitable utterances that were estimated
automatically.
For comparison, we used a classification method,
support vector machine (SVM). In general, SVM pro-
vides binary classification results and no direct means
to obtain scores or probabilities for ranking. Never-
theless, Piatt proposed transforming SVM predictions
to posterior probabilities by passing them through a
sigmoid (Platt et al., 1999). We then classified candi-
date utterances by SVM, selected correctly classified
ones and ranked them by posterior probabilities using
the sigmoid method. We used this method as a base-
line without the use of the learning to rank method.
4.2 Features
To rank the utterances, we converted pairs of a con-
Table 3: Feature vector generation (noun feature).
No. Speaker Utterance
u
4
Agent Enjoy this season fully
because it’s long-awaited
summer vacation.
u
3
Human Yes, I will.
u
2
Agent Do you plan to travel?
u
1
Human No. However, I would like
to go.
u
0
( Agent ) Why don’t you go on a trip
overseas?
Noun pair Vector value
u
1
: travel & u
0
: Europe 0
u
1
: summer & u
0
: trip 0
u
2
: part-timer & u
0
: overseas 0
u
2
: travel & u
0
: trip 1
u
2
: travel & u
0
: overseas 1
u
3
: friends & u
0
: trip 0
u
4
: summer & u
0
: overseas 1
u
4
: vacation & u
0
: trip 1
text and a candidate utterance into a feature vector.
We used features of 11 types to represent relations be-
tween a context and an utterance. Here, we describe
one of these, the noun feature, as the most basic one.
In the noun feature, we use a combination of a
noun in a context and an utterance. Using this feature,
we expect that a candidate utterance that includes
words related to words in a context ranks higher. We
only use u
1
, u
2
, u
3
, and u
4
in a context for this fea-
ture because it is often the case that semantic rela-
tions between old utterances in a context and suitable
candidate utterances are small. The usage range of
utterances in context differs according to the type of
feature. In the noun feature, whether a particular noun
pair exists between utterances represents a binary fea-
ture value. We use noun pairs that appear three or
more times in learning data.
Table 3 shows the example. The upper table shows
an example of the context and candidate utterances.
The lower shows part of a feature vector generated
from them. As the table shows, we distinguish noun
pairs by the number of utterances in the context. For
instance, the vector value of “u
2
: travel & u
0
: over-
seas” is 1 because u
2
includes the word “travel” and
u
0
includes “overseas”. Similarly, the vector value of
“u
1
: summer & u
0
: trip” is 0 because u
0
includes
“trip” but u
1
does not include “summer”.
The features should be designed to represent vari-
ous aspects of relations between contexts and utter-
ances, such as sentence structures, discourse struc-
tures, semantics, and topics.
ICAART2014-InternationalConferenceonAgentsandArtificialIntelligence
18
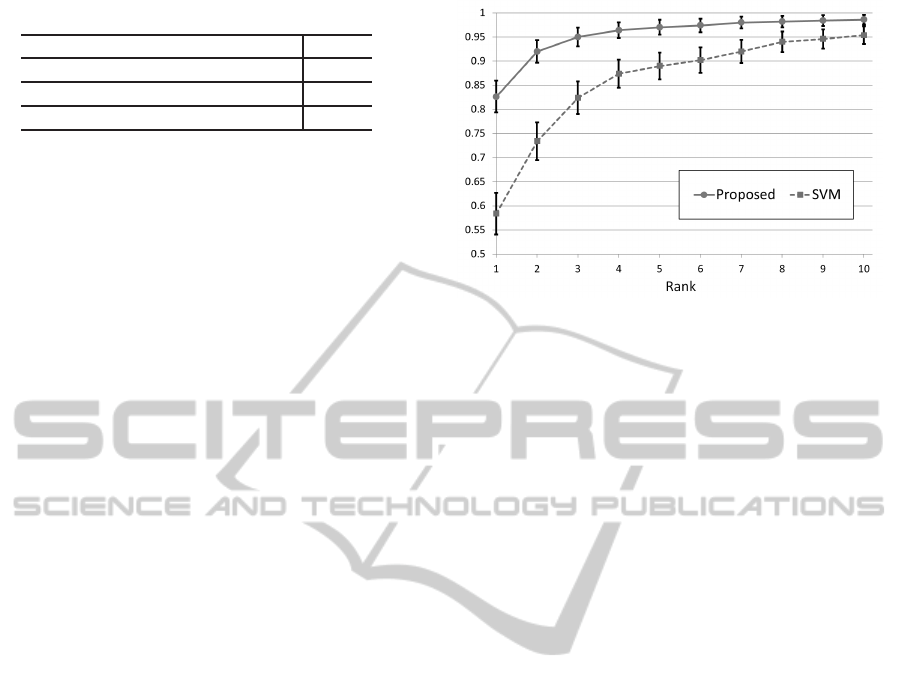
Table 4: Data acquisition result.
Number of participants 460
Number of Evaluated contexts 320
Number of Evaluated utterances 4694
Average of the confidence p 4.215
4.3 Data Set
4.3.1 Candidate Utterances
We made 980 utterances by hand for crowdsourcing
and the experiment. The topics of utterances were se-
lected to interest as many people as possible such as
healthcare, marriage, travel, sport, etc. We also pro-
duced versatile utterances such as “I think so.” and
“It’s wonderful!”.
4.3.2 Learning Data
To acquire the data, we opened the gamified website
for crowdsourcing. Table 4 shows the results of data
acquisition.
We used 4520 evaluated utterances for which con-
fidence p is p > 3.0 for the experiment.
Additionally, we used other data produced by 50
part-time participants intended to compensate for data
deficiency. The modes of producing data were about
the same, with the exception of using the game me-
chanics. As a result, we obtained 239,897 evaluated
utterances to 14,900 contexts. We used these data all
together as learning data.
The scores of utterances are given depending on
the evaluation. If an utterance is suitable to a context,
then the score is 30. If unsuitable, the score is 1. The
values of score are decided on an empirical basis.
4.3.3 Test Data
We prepared 500 contexts as test data. The ranked ut-
terances using the proposed method and SVM were
evaluated manually. Each utterance was evaluated by
three evaluators. They judged whether each utterance
was semantically suitable or unsuitable to the con-
text. The eventual judge was decided using a majority.
Therefore, when two evaluators judge an utterance as
suitable and one evaluator judge as unsuitable, the ut-
terance is determined to be suitable.
4.4 Results
Figure 3 shows the experiment result and 95% confi-
dence interbals obtained using the proposed method
and SVM.
Figure 3: Rate of appropriate candidate utterance.
The x-axis represents the rank of the first appear-
ance of a suitable utterance. The y-axis shows the cu-
mulative frequency. In other words, the figure shows
the rate of the contexts that include at least one appro-
priate utterance within each rank.
In the figure, the proposed method ranked a suit-
able utterance on the top at 82.6%, within the top 3 at
95.0%, and the top 10 at 98.6%. However, SVM was
ranked on the top at 58.4%, within the top 3 at 82.4%,
and at the top 10 at 95.4%. As shown in the result,
the proposed method outperformedSVM overall. The
above shows that the proposed method is effective for
the selection of candidate utterances.
When we implement the proposed method to dia-
logue agents, the rate of replying to a suitable utter-
ance (82.6%) is inadequate for smooth communica-
tion. Note that the set of candidate utterances has at
least one correct utterance for each context (test data).
This may not always be the case and the rate may
drop when the agent talks to human actually. How-
ever, the proposed method produced rankings within
the top 3 at over 90% to use new effective features. To
improve the ranking algorithm, it seems that we can
improve the performance of the statistical response
method further.
4.5 Discussion
A great benefit of the proposed method is that it can
use contexts for responses. To demonstrate that ef-
fectiveness, we created feature vectors using the last
user’s utterance (u
1
) only and conducted an experi-
ment.
Figure 4 portrays the results. The rate of the top 1
was 69.2%, 13.4% lower, and all results in the figure
are lower by at least 1.6% than that using contexts
(Fig. 3). This result is, so to say, the natural result
because a context has more hints than an utterance
for selecting a suitable utterance.
ConstructingaNon-task-orientedDialogueAgentusingStatisticalResponseMethodandGamification
19
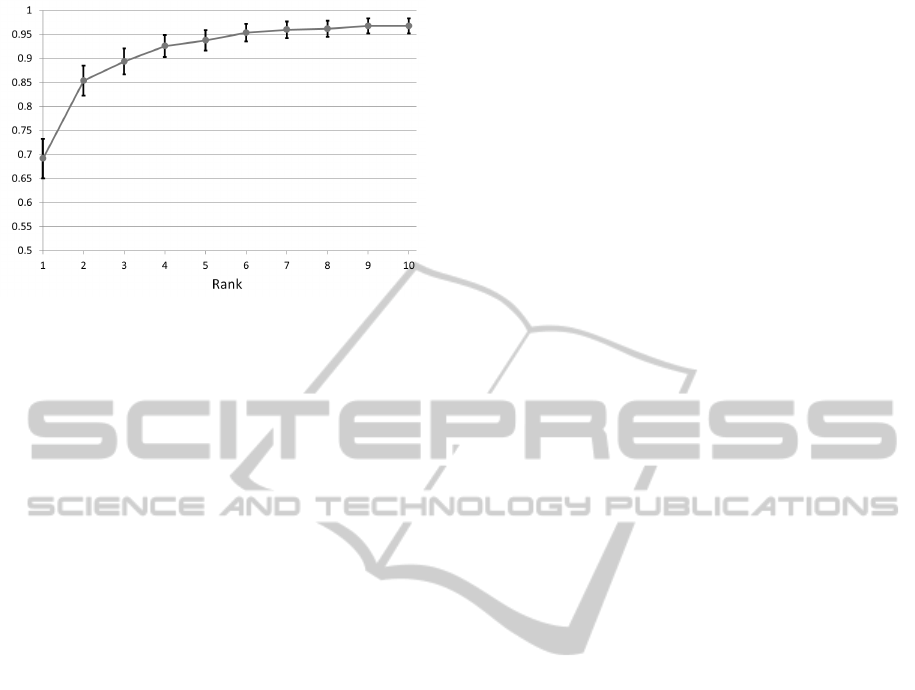
Figure 4: Rate of appropriate candidate utterance without
use of contexts.
However, as described at the beginning of this pa-
per, existing response methods cannot use contexts
for response generation. Various problems exist be-
cause of such information loss. For instance, a dia-
logue agent broaches a topic that was discussed previ-
ously or makes contradictory comments to what it had
said before. In fact, this experimentally obtained re-
sult indicates that using not only the last utterance but
also contexts are necessary for realizing superior non-
task-oriented dialogue agents. Therefore, in terms of
the availability of contexts, the effectiveness of the
statistical response method was clarified.
5 CONCLUSIONS
As described in this paper, we proposed a statistical
response method that automatically ranks previously
prepared candidate utterances in order of suitability
to the context by application of a machine learning
algorithm. Non-task-oriented dialogue agents that ap-
plied the method use the top utterance from the rank-
ing result for carrying out their dialogues. To col-
lect learning data for ranking, we used crowdsourc-
ing and gamification. We opened a gamified crowd-
sourcing website and collected learning data through
it. Thereby, we achieved low-cost and continuous
learning data acquisition. To prove the performance
of the proposed method, we checked the ranked ut-
terances to contexts and conclude that the method is
effective because a suitable utterance is ranked on the
top at 82.6% and within the top 10 at 98.6%.
The non-task-oriented dialogue agents are basi-
cally evaluated by hand work and the task requires a
tremendous amount of time and effort. By using pro-
posed gamified crowdsourcing platform, we can eval-
uate the performance of non-task-oriented dialogue
agents in a low-cost way. We prepare several types
of agents which we want to evaluate and each agent
generates a response to the given context. The plat-
form shows the context and the generated responses
to participants in the same way as our website. The re-
sponses which ware generated by a high-performance
agent should be selected more than others.
The candidate utterances are created manually.
Future work includes automatic candidate utterance
generation. Our crowdsourcing website has a func-
tion that collects new utterances. However, these ut-
terances present some problems such as spelling er-
rors, phraseology, etc. because they are written by
users in free description format. We need to fix them
to use the new utterances. As an alternative utterance
generation method, using microblog data is promis-
ing. Using microblog data, it can be expected to gen-
erate a new utterances set that includes numerous or
newest topics.
We also intend to improve the feature vector. It
is important to devise new effective features because
the performance of our method depends heavily on
the features. The features used in the experiment (not
illustrated in detail here) did not deeply consider the
semantics of contexts and utterances. Realizing ap-
propriate responses requires semantical features. We
are now deliberating on such features.
REFERENCES
Banchs, R. E. and Li, H. (2012). Iris: a chat-oriented di-
alogue system based on the vector space model. In
Proceedings of the ACL 2012 System Demonstrations,
pages 37–42. Association for Computational Linguis-
tics.
Bickmore, T. and Cassell, J. (2001). Relational agents: a
model and implementation of building user trust. In
Proceedings of the SIGCHI conference on Human fac-
tors in computing systems, pages 396–403.
Cao, Z., Qin, T., Liu, T., Tsai, M., and Li, H. (2007). Learn-
ing to rank: from pairwise approach to listwise ap-
proach. In Proceedings of the 24th international con-
ference on Machine learning, pages 129–136.
Chu-Carroll, J. and Nickerson, J. (2000). Evaluating auto-
matic dialogue strategy adaptation for a spoken dia-
logue system. In Proceedings of the 1st North Ameri-
can chapter of the Association for Computational Lin-
guistics conference, pages 202–209.
Deterding, S., Sicart, M., Nacke, L., O’Hara, K., and Dixon,
D. (2011). Gamification. using game-design elements
in non-gaming contexts. In Proceedings of the 2011
annual conference extended abstracts on Human fac-
tors in computing systems, pages 2425–2428. ACM.
Isomura, N., Toriumi, F., and Ishii, K. (2009). Statistical
Utterance Selection using Word Co-occurrence for a
Dialogue Agent. Lecture Notes in Computer Science,
5925/2009:68–79.
ICAART2014-InternationalConferenceonAgentsandArtificialIntelligence
20

Luce, R. (1959). Individual choice behavior: A theoretical
analysis. New York: Wiley.
Murao, H., Kawaguchi, N., Matsubara, S., Yamaguchi, Y.,
and Inagaki, Y. (2003). Example-based spoken dia-
logue system using woz system log. In SIGdial Work-
shop on Discourse and Dialogue, pages 140–148.
Plackett, R. (1975). The analysis of permutations. Applied
Statistics, pages 193–202.
Platt, J. et al. (1999). Probabilistic outputs for support vec-
tor machines and comparisons to regularized likeli-
hood methods. Advances in large margin classifiers,
10(3):61–74.
Ritter, A., Cherry, C., and Dolan, W. B. (2011). Data-
driven response generation in social media. In Pro-
ceedings of the conference on empirical methods in
natural language processing, pages 583–593. Associ-
ation for Computational Linguistics.
Von Ahn, L. and Dabbish, L. (2004). Labeling images
with a computer game. In Proceedings of the SIGCHI
conference on Human factors in computing systems,
pages 319–326. ACM.
Wallace, R. (2009). The anatomy of alice. Parsing the Tur-
ing Test, pages 181–210.
Weizenbaum, J. (1966). ELIZA-a computer program for
the study of natural language communication between
man and machine. Communications of the ACM,
9(1):36–45.
Worswick, S. (2013). Mitsuku Chatbot.
http://www.mitsuku.com/.
Zue, V., Seneff, S., Polifroni, J., Phillips, M., Pao, C., Goo-
dine, D., Goddeau, D., and Glass, J. (1994). Pegasus:
A spoken dialogue interface for on-line air travel plan-
ning. Speech Communication, 15(3-4):331–340.
ConstructingaNon-task-orientedDialogueAgentusingStatisticalResponseMethodandGamification
21
