
Unlocking Serendipitous Learning by Means of Social Semantic Web
Matteo Gaeta
1
, Vincenzo Loia
2
, Giuseppina Rita Mangione
1
, Sergio Miranda
1
and Francesco Orciuoli
1
1
DIEM, University of Salerno, Via Giovanni Paolo II, 132, Fisciano (SA), Italy
2
DI, University of Salerno, Via Giovanni Paolo II, 132, Fisciano (SA), Italy
Keywords:
Serendipitous Learning, Social Semantic Web, SKOS, SIOC.
Abstract:
Serendipitous Learning is the learning process occurring when hidden connections or analogies are unexpect-
edly discovered, mostly during searching processes (for instance on the Web) which are typical for informal
learning activities, especially accomplished in the workplace context. Moreover, serendipitous processes have
high probability to occur in the contexts where learners have high autonomy, more chances to intervene in
different activities and to interact with resources and people. This paper proposes an approach, based on the
Social Semantic Web, to sustain and foster Serendipitous Learning. The proposed approach considers two con-
nected ontology layers to model knowledge by using several Semantic Web vocabularies like SIOC, Dublin
Core, SKOS, and so on. The SKOS role is particularly relevant because it allows connections among hetero-
geneous resources, also across multiple communities. The proposed approach models the above-mentioned
connections at the conceptual level in order to facilitate learners to discover relevant links, concepts and to
follow unexpected useful paths.
1 INTRODUCTION AND
RELATED WORKS
Technologies and, in particular, ICTs (Information
and Communication Technologies) influence the ed-
ucational practices as well as the redefinition of the
concepts of learning and teaching. This phenomenon
asks educators to review their practices in order to
face new learning/teaching situations in which learn-
ers can access alternative learning resources in ad-
dition to those defined in structured curricula. The
availability of new learning resources is mainly due
to the Web, intended as a boundless field of informa-
tion. The increasing number of learning resources (on
the Web) and the decreasing of teacher presence re-
quire higher autonomy and regulation to learners in
order to master both formal and informal learning en-
vironments. Autonomous and self-directed interac-
tions with available content foster ”[...] unexplored
and unplanned discoveries and fortunate incidents in
the process of exploring something else [...]” (Kop,
2012). In this context, the term serendipitous learning
was coined to point out the learning processes related
to the ”[...] unexpected realization of hidden, seem-
ingly unrelated connections or analogies [...]” (Kop,
2012).
This paper describes how Social Semantic Web, if
opportunely deployed, is able to effectively sustain
serendipitous learning. Social Semantic Web (Bres-
lin et al., 2009) is defined as the synergistic applica-
tion of Semantic Web and Social Web that tries to get
and combine the advantages of both. The work pro-
vides a scalable approach to manage knowledge and
contents created in a specific environment. It mainly
focuses on both the formal description of relevant re-
sources (e.g. Web resources) in the environment and
the modelling of conceptual connections among the
above-mentioned resources. The approach proposes
a knowledge representation architecture based on two
integrated layers of ontologies in order to foster the
emergence of relevant connections among resources
and the agile provisioning of these connections to the
learners, helping them to play a serendipitous learn-
ing experience. The approach could be exploited
also in smaller contexts like, for instance, Small and
Medium-sized Enteprises (SMEs), where the concept
of Web resource is replaced by the concept of digital
resource. Other works in literature deal with the adop-
tion of the Social Semantic Web as a learning plat-
form. In particular, the authors of (Jovanovic et al., ),
(Torniai et al., 2008) and (Jeremic et al., 2013) were
among the first ones to describe the e-learning scenar-
285
Gaeta M., Loia V., Rita Mangione G., Miranda S. and Orciuoli F..
Unlocking Serendipitous Learning by Means of Social Semantic Web.
DOI: 10.5220/0004845102850292
In Proceedings of the 6th International Conference on Computer Supported Education (CSEDU-2014), pages 285-292
ISBN: 978-989-758-020-8
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

ios supported and enhanced by the Social Semantic
Web technologies and methodologies and to discuss
the main issues concerning the realization of these
scenarios:
• development and maintenance of domain ontolo-
gies;
• exploitation of user-generated contents as learn-
ing resources;
• provisioning of new forms of interaction;
• support for interoperability;
• support for adaptation and personalization of e-
learning experiences;
• ubiquitous access to learning resources.
Moreover, the authors of (Brooks et al., ) provide
three main lessons learned by analysing e-learning
applications and tools developed by using Semantic
Web and Web 2.0 technologies:
• testing the defined approaches in real world sce-
narios in order to effectively evaluate systems and
validate models and methodologies;
• tracking large amount of data related to learners’
interactions in order to extract pedagogical pat-
terns;
• extracting implicit knowledge from contents in
order to automatically construct metadata to im-
prove search of learning material.
With respect to the reviewed literature, this paper
mostly focuses on the anatomy of the ontology struc-
tures (two integrated layers of ontologies have been
introduced and modelled) and on the methods for
constructing, maintaining and evolving the aforemen-
tioned ontologies. More details concerning the dis-
covery of links and related resources have been pro-
vided by proposing several approaches. If the Seman-
tic Web technologies provide a great solution for in-
teroperability and integration, discovery is considered
one of the main lever to enable serendipity. This paper
takes care of principles and suggestions of the exist-
ing works and advances by trying to solve some of the
main issues related to the adoption of Social Semantic
Web in e-learning scenarios. Lastly, it is important to
underline that the proposed approach aims at working
in contexts (e.g. Knowledge-Intensive Organizations)
where the ICTs are already exploited to manage and
track (also partially) the work activities.
2 SERENDIPITOUS LEARNING
The idea underlying serendipitous learning is based
on several pedagogical approaches. Among the oth-
ers, it is possible to recognize discovery learning, ex-
ploratory learning, experiential learning, construc-
tivist learning and connectivism (Kop, 2012). Nu-
merous works (Heinstr
¨
om, 2007) address serendipi-
tous learning by taking care mostly of the concept of
surprise and on the accidental nature of information
discovery. On the other hand, some authors (Andr
´
e
et al., 2009) focus on the importance of prior knowl-
edge and sagacity in the serendipitous learning pro-
cesses. Other scientific results affirm that the hidden
connection discovery could not occur instantly but re-
quire an incubation period to the learners (McCay-
Peet and Toms, 2010) (Lu, 2012). These authors as-
sert also that the conditions able to sustain serendipi-
tous connection discovery are those of active learning
and social learning in knowledge building and discov-
ery environments (Scardamalia and Bereiter, 2006)
(McCay-Peet and Toms, 2010). Furthermore, the ef-
fects of serendipity are analysed by the authors in
(Gritton, 2007). They assert that there is not suffi-
cient evidence to affirm that serendipitous learning
is a consequence of intuitive sagacity of learners but
they state that there is no doubt that serendipitous
browsing can reveal hidden connections among con-
cepts and stimulate thinking and, consequently, learn-
ing. Now, the question is: may the new Web technolo-
gies increase and improve serendipitous learning?.
Some ideas are proposed by authors of (Ihanainen
and Moravec, 2011) and (Boyd, 2010). They en-
hance search strategies (e.g. the same adopted by Web
search engines) by moving the control from search en-
gines to learners and by fostering randomness in the
information stream. Authors of (Boyd, 2010) affirm
also that people should find methods for integrating
Web searching into their thinking and reflection pro-
cesses. Technologies have to take care of this integra-
tion and the personal context of the learner by consid-
ering an unfiltered but manageable store of resources.
3 A SOCIAL SEMANTIC WEB
APPROACH TO IMPROVE
SERENDIPITOUS LEARNING
In this Section, an approach that fosters serendipitous
learning is proposed. The approach is based on the
main Social Semantic Web principles in order to pro-
vide Web-based environments to interact (searching,
tagging, rating, recommending, etc.) with digital re-
sources.
CSEDU2014-6thInternationalConferenceonComputerSupportedEducation
286

3.1 The Social Semantic Web
The W3C
1
provides the following brief definition for
Semantic Web: [..] The Semantic Web provides a
common framework that allows data to be shared and
reused across application, enterprise, and community
boundaries [..]. The Semantic Web vision concerns
the provisioning of metadata associated with Web re-
sources to assign machine-interpretable meaning to
them. In order to make this metadata really sharable
and understandable, it requires vocabularies and on-
tologies expressing semantics for terms and values
used in the above-mentioned metadata. Being these
metadata set represented in uniform way, better link-
ing and decentralization of resources are supported.
Among the other issues, the Semantic Web infrastruc-
ture provides concrete answers to the requests for en-
tity identity and explicit relationships. More in de-
tails, with Semantic Web, the entities on the Web,
previously embedded and hidden in HTML pages, be-
come uniquely identifiable and, thus, understandable
and manageable by machines (computers). Moreover,
representing entities is not sufficient, thus identifying
relationships among entities is also needed (Breslin
et al., 2009). In other words, Semantic Web allows the
development of software agents that aim at improv-
ing search and navigation of Web resources, making
new user experiences available. From the technologi-
cal viewpoint, the core of the Semantic Web architec-
ture
2
is represented by: i) RDF (Resource Descrip-
tion Framework), i.e., a data model natively enabling
distribution of data, ii) RDFS (Resource Description
Framework Schema) and OWL/OWL2 (Web Ontol-
ogy Language), i.e., languages for formal description
of data and its semantics. These two main layers,
supported by URIs and XML, allow querying (by us-
ing, for instance, SPARQL) and inference (by using
ontology-based inference enabled by OWL reasoners
or rule-based inference enabled by specific rule en-
gines). On the top of the core layers, a great num-
ber of vocabularies and ontologies, covering different
domains (some more specific, others more general),
have been developed and deployed. FOAF (Friend of
a Friend)
3
for representing knowledge on people and
social relationships, SIOC (Semantically-Interlinked
Online Communities)
4
for representing knowledge on
activities of on-line communities, Dublin Core for de-
scribing metadata for (digital) resources, SKOS (Sim-
ple Knowledge Organization System)
5
for modelling
1
http://www.w3.org/2001/sw/
2
http://www.w3.org/standards/semanticweb/
3
http://www.foaf-project.org
4
http://sioc-project.org
5
http://www.w3.org/2004/02/skos/
thesauri, concept maps and controlled vocabularies,
SCOT (Social Semantic Cloud of Tags)
6
& MOAT
(Meaning of a Tag Ontology) (Passant and Laublet,
2008) for modelling all the entities related to the tag-
ging process, and so on.
In this context, the concept of Social Semantic
Web emerges. Social Semantic Web represents the
ecosystem in which social interactions on the Web
applications lead to the creation of explicit and se-
mantically rich knowledge representations. The So-
cial Semantic Web combines technologies, strategies
and methodologies from Semantic Web, social soft-
ware and the Web 2.0 (Weller, 2010). In other words,
the Semantic Web provides new and better searching
(for people, content, tag, etc.) scenarios for Social
Web applications and, vice-versa, users’ interactions
with Social Web applications extend, update and pop-
ulate the Semantic Web structures.
SIOC (Boj
¯
ars et al., 2008) is one of the most im-
portant and known ontologies for the Social Semantic
Web. It aims at interlinking on-line user-generated
content from applications such as blogs, instant mes-
saging tools, wikis and other Social Web sites, by pro-
viding an ontology to model structures (e.g. posts,
threads, etc.) and activities (e.g. tagging, reply-
ing, etc.) in online communities. Typically, SIOC
is used in combination with the FOAF vocabulary
for describing people and their friends and the SKOS
model for organising knowledge. SIOC lets develop-
ers link discussion posts and content items to other
related discussions, items, people and topics. Authors
of (Boj
¯
ars et al., 2008) introduce also the concept of
food chain (see Fig. 1).
Figure 1: SIOC food chain.
The idea is that semi-structured data is gath-
ered and transformed in SIOC data from different
sources. Subsequently, SIOC data coming from dif-
ferent sources is aggregated (by using the native ca-
pabilities of RDF data model) and indexed (e.g. with
SKOS taxonomies). At the end of the chain, users can
search and navigate integrated SIOC structures also
by surfing the defined indexes.
6
http://scot-project.net/scot/spec/scot.html
UnlockingSerendipitousLearningbyMeansofSocialSemanticWeb
287

3.2 Generalizing the SIOC Approach
It is possible to generalize the SIOC (Breslin et al.,
2006) approach by considering different types of data
source and not only Social Web applications. The
idea is to provide additional ontologies, to integrate
with SIOC, to cover different domains. For instance
it is possible to use Dublin Core to describe docu-
ments in Document Management Systems (DMSs),
IEEE LOM (a binding in RDF
7
) to describe learning
objects in Learning Object Repositories (LORs) and
so on. Fig. 2 shows a generalization of the SIOC food
chain and proposes SKOS as a mechanism to integrate
and index different types of individuals.
Figure 2: Generalizing the SIOC food chain.
Fig. 2 clearly shows two ontology layers, the up-
per layer (in Fig. 2), realized by means of SKOS,
provides classification ontologies, i.e., lightweight se-
mantic structures used to annotate and classify in-
dividuals belonging to the ontologies at the lower
layer. The lower layer provides descriptive ontolo-
gies which model key concepts of the domain of in-
terest. For instance, in a Knowledge-Intensive Orga-
nization (KIO), the key concepts like Project, Task,
Activity, Document, UGC (User-Generated Content)
should be considered and modelled by using the on-
tologies at the lower level (Mangione et al., 2012)
(Gaeta et al., 2013). These ontologies are, relatively,
static in the sense that they do not rapidly evolve and
have to be built and managed by human experts fol-
lowing methodologies like NeON (Su
´
arez-Figueroa,
2010) also by adopting (as suggested in this work)
existing vocabularies. Ontologies at the upper layer
are dynamic, in the sense that they evolve as soon
as new activities (dealing with new topics) start in
the KIO. These ontologies model and structure, for
7
http://ltsc.ieee.org/wg12/
instance, the topics of the projects in the KIO. The
classification ontologies can be constructed by means
of automatic, semi-automatic or non-automatic pro-
cesses. More in details, the automatic process can be
realized by means of Fuzzy Formal Concept Analysis
(FFCA) (Maio et al., 2011) that is used to extract con-
cepts from a set of full-text documents and construct
a Fuzzy Concept Lattice, i.e., a structure that repre-
sents the conceptualization of the document set taken
as input. The same authors define a methodology to
build SKOS ontologies starting from a Fuzzy Con-
cept Lattice. If the considered documents are pack-
aged as structured learning contents it is possible to
adopt approaches like, for instance, those provided
in (Capuano et al., 2009) and (Gaeta et al., 2011),
where the content structure is exploited to construct
lightweight ontologies from the source learning mate-
rial. Definitely, the combination of the two ontology
layers allows interoperability, integration (in particu-
lar descriptive ontologies) and serendipity (in partic-
ular classification ontologies) as we will show in the
next Sections.
3.3 Using SKOS to Link Heterogeneous
Contents
In the Semantic Web, SKOS provides a vocabulary
to define thesauri, taxonomies, controlled vocabular-
ies, concept maps and so on. SKOS provides the
skos:Concept class that can be instantiated in or-
der to define individual concepts (or subjects, top-
ics, tags, etc.) which can be hierarchically related by
means of skos:narrower and skos:broader (Baker
et al., 2013). Other relations among individual con-
cepts can be expressed by means of skos:related
(for weak semantic relations) or by defining sub-
properties of the above mentioned properties, includ-
ing skos:semanticRelation. Moreover, two con-
cepts belonging to two different SKOS taxonomies
can be related by using skos:relatedMatch,
narrowMatch and broadMatch.
According to the need of indexing and integrating
individuals coming from different classes (of different
vocabularies), it is important to introduce two prop-
erties: sl:isSubjectOf and sl:subject. The first
one is the inverse of the second one that is defined as
a subproperty of dct:subject
8
(coming from Dublin
Core vocabulary).
Moreover, sl:subject has range skos:Concept
whilst sl:isSubjectOf has domain skos:Concept.
More in details, as shown in Fig. 3, by means of the
sl:isSubjectOf property it is possible to assert that
8
http://dublincore.org/documents/2012/06/14/
dcmi-terms/?v=terms#terms-subject
CSEDU2014-6thInternationalConferenceonComputerSupportedEducation
288
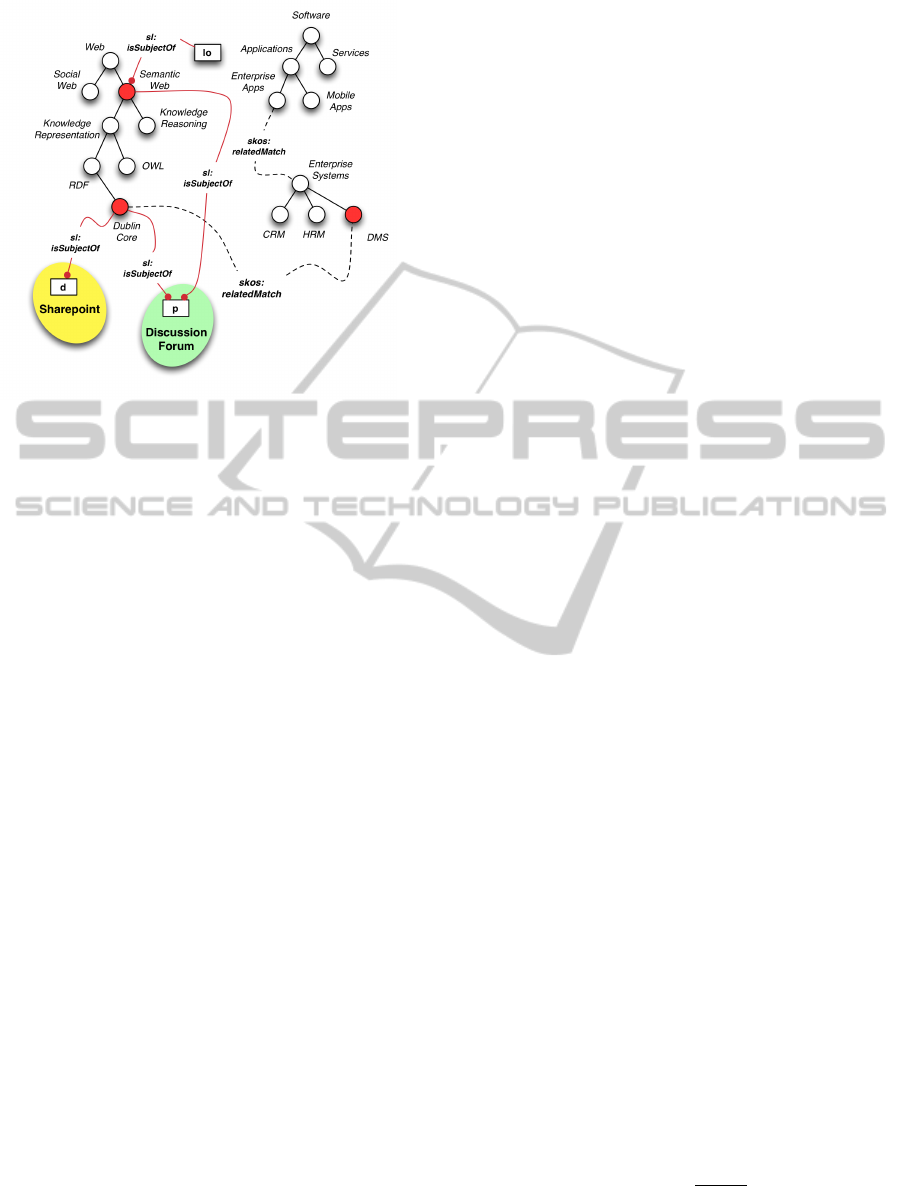
Figure 3: SKOS to link heterogeneous contents.
both the document d and the (forum) post p deal with
the topic Dublin Core. The post p also deals with
the topic Semantic Web. The concept Dublin Core
is related to the concept DMS of a different concept
schema, as well as the concept Enterprise Apps is
related to the same concept DMS.
Definitely, as we will see also in the next Section,
the classification ontologies represent the core struc-
ture enabling the serendipitous discovery.
3.4 Serendipitous Learning in the Social
Semantic Web
According to the example provided in Fig. 3, as-
sume that user A is interested in the concept DMS be-
cause she has to introduce a Document Management
System in the SME (Small and Medium-sized Enter-
prise) she works for. While addressing the DMS con-
cept, Dublin Core concept is signalled to A because
it is related to DMS. Once the attention of A is focused
on Dublin Core, she learns that Dublin Core is re-
lated to DMS (we assume that a standard viewer, for
a SKOS ontology, shows and emphasizes at least all
the concepts directly linked to the concept the user is
currently addressing) and she can see two resources
(coming from two different systems) dealing with the
aforementioned concept. By reading the text docu-
ment d, A goes deep into her knowledge on the con-
nection among Dublin Core and DMS. A learns that
some existing Document Management Systems rep-
resent document metadata by means of Dublin Core
schema.
Moreover, A, by reading the forum post p under-
stands that the use Dublin Core follows the principle
of the Semantic Web, a concept that is unknown for
A until this moment. A acquires knowledge about the
Semantic Web concept by enjoying the learning ob-
ject lo.
This sample flow emphasizes the main principles
of Serendipitous Learning:
• Fostering autonomous interaction of users-
learners with content space;
• Valorizing the users-learners’ prior knowledge (in
the out-of-the-box thinking) by means of SKOS
concept schemas which recall the human mind
model;
• Stimulating surprise (by showing hidden connec-
tions) during exploratory processes;
• Providing active and social learning space aiming
at knowledge building processes.
The relations among concepts (skos:Concept)
and Web resources (i.e. the Aggregating and Index-
ing process of Fig. 2), in the Social Semantic Web
platform could be generated with non-automatic, au-
tomatic and semi-automatic mechanisms. In the first
case, it is possible to exploit the tagging features of
Social Web applications and integrate tagging ontolo-
gies like, for instance, SCOT and MOAT with SKOS.
In the second case, it is possible to exploit knowledge
extraction & discovery methods like, for instance,
FFCA (see Section 3.2) that is able to conceptual-
ize a set of full-text contents and automatically clas-
sify them with respect to the extracted concepts. It
is also possible to recommend some of the connected
resources to the learner, on the basis of his/her pro-
file (Gianforme et al., 2009) in order to foster his/her
discovery process.
A sample result of this process is depicted in
Fig. 3 where the FFCA algorithm extracts the con-
cept Dublin Core from two contents, i.e., docu-
ment d and post p. The relation among the two
contents and the extracted concept is explicitly as-
serted (in the RDF/RDFS/OWL sense) by means of
the sl:isSubjectOf property. The third case fore-
sees the application of the aforementioned methods,
whose results are supervised and revised by means of
human interventions.
An important aspect of the proposed approach is
its capability to link concepts belonging to differ-
ent classification ontologies (cross-ontologies links).
Several methods can be exploited to discover cross-
ontologies links. One of the simplest ones is to calcu-
late the document-oriented word similarity measure
(Terra and Clarke, 2003) among the labels which de-
scribe two different concepts:
rel(c
1
, c
2
) =
d f
c
1
,c
2
N
max
. (1)
In the equation 1, d f
c
1
,c
2
is the number of con-
tents annotated with both concept c
1
and concept c
2
UnlockingSerendipitousLearningbyMeansofSocialSemanticWeb
289

(coming from two different SKOS ontologies, i.e., in-
dividuals of skos:Concept). Whilst N
max
is the total
number of considered contents. An instance of the
property skos:relatedMatch is asserted among c
1
and c
2
if rel(c
1
, c
2
) is bigger than a given threshold.
3.5 Using SPARQL to Access Contents
and Concepts
The proposed approach enables high interoperabil-
ity and integration by laying upon the Semantic Web
stack. This capability allows to navigate on the on-
tology graphs by using the SPARQL language and
obtain useful results (able to concretely realize the
scenario depicted in Section 3.4) by means of simple
queries, like the following one.
. . .
SELECT ? s ? o b j
WHERE
{
? s 1 s ko s : r e l a t e d M a t c h u n i s a :DMS .
? s 1 s l : i s S u b j e c t O f ? ob j .
? s s l : i s S u b j e c t O f ? o b j
}
. . .
The previous query (it is only a sample code) al-
lows to retrieve all concepts related (in the example
we consider only the cross-ontology links) with DMS
and all contents (the result parameter is ?obj) anno-
tated with these concepts. The retrieved contents are
further analysed in order to found other relevant con-
cepts (the result parameter is ?s). This is the way to
discover that Dublin Core follows the principles of
the Semantic Web (see the scenario described in Sec-
tion 3.4).
Lastly, the inference capabilities provided by the
ontology-based reasoners (supporting RDFS, OWL
and OWL2) generate new facts (from existing ones)
which increase the knowledge base and, conse-
quently, enrich learners’ exploration experience.
3.6 Identifying Relevant Paths: A Data
Mining Approach
Suggesting hidden connections (among concepts and,
conseuently, resources) is one of the main chances
to provide surprise to learners during the exploratory
process. The method we propose is based on the
Context-Dependent Sequential Pattern Mining algo-
rithm. The idea of traditional Sequential Pattern Min-
ing (Pei et al., 2004) applied to the domain of this pa-
per is that the exploratory paths of learners, in terms
of visited concepts (on the classification ontologies),
can be analysed in order to find frequent sequences of
visited concepts. For instance, the algorithm can as-
sert something like this: learners who visit concepts
c
x
, c
y
and c
z
also visit concept c
k
. This rule can be
used to recommend c
k
to those learners who have vis-
ited c
x
, c
y
and c
z
. Moreover, the authors of (Rabatel
et al., 2013) add context awareness to the extraction
of frequent sequences. In brief, they suggest finding
frequent sequences in specific contexts. For the aim
of this paper, we can define the context as the prior
knowledge (or/and competencies) of learners. For in-
stance, it is possible to locate frequent sequences for
expert java developers, novice project managers and
so on. This approach requires the definition of rules
able to assign individual learners to one or more con-
texts. During exploration, learners could receive sug-
gestions like, for instance, resource annotated with
concept c
k
could be useful for you on the basis of:
i) known contextualized frequent sequences, ii) con-
texts associated to them, and iii) concepts visited in
the current session.
4 LEARNING DOMAINS AND
SCALABILITY
One of the main advantages of the Social Semantic
Web platform is that we may contextualise them for
different types of communities acting in different en-
vironments and having different sizes. This charac-
teristic is enabled by the numerous existing vocabu-
laries covering different domains. For instance, if the
community we would like to consider is composed by
the employees of a Knowledge-Intensive Organiza-
tion, we need to integrate vocabularies and ontologies
for describing projects, competencies, roles, strate-
gies, tasks, documents, training material and so on.
Otherwise, if the community we would like to con-
sider is composed by consumers related to the world
of cultural heritage, we need to consider ontologies
like CIDOC-CRM
9
, Geonames
10
, etc. Thus, if we
change the domain, Semantic Web mechanisms allow
us to change the vocabularies and ontologies but not
the approach (SKOS-based) presented in Section 3.4.
Furthermore, the Social Semantic Web platform
is highly and natively scalable. Both horizontal and
vertical scalability can be considered. More in de-
tails, horizontal scalability occurs when more than
one communities are considered. This case is il-
lustrated in Fig. 4. A community can be repre-
9
http://www.cidoc-crm.org
10
http://www.geonames.org
CSEDU2014-6thInternationalConferenceonComputerSupportedEducation
290

sented by a set of SKOS concepts schemas, a set
of persons and a set of vocabularies and ontolo-
gies modelling data (coming from software applica-
tions used in that community) which are relevant in
a specific domain. The proposed approach and, in
particular, skos:relatedMatch, skos:broadMatch,
skos:narrowMatch properties can link SKOS con-
cept schemas belonging to different communities and
enable serendipitous learning process among different
communities. Adding a new community is allowed
also at run-time.
Figure 4: Horizontal scalability.
Vertical scalability is allowed by the capability of
Semantic Web to add new information systems and,
thus, new data at run-time.
Lastly, a third type of scalability may be consid-
ered: infrastructure scalability. This means the capa-
bility to handle different and distributed storage sys-
tems for ontologies and, in general, semantic data is
guaranteed by the distributed nature of RDF.
5 EARLY EVALUATION, FUTURE
WORKS AND FINAL REMARKS
The work proposes an approach to exploit the So-
cial Semantic Web platform to support Serendipitous
Learning. The SIOC framework and its food chain
have been generalized in order to support multiple do-
mains. Two interconnected ontology types have been
introduced. The first one is used to describe rele-
vant resources. The second one is used to classify
and connect heterogeneous resources and it is mainly
based on SKOS. Moreover, suitable methods for link
and path discovery, leveraging on classification on-
tologies, have been proposed. The scalability of the
proposed approach has been shown. An early partial
evaluation has already been executed in the context of
the experimentation of an integrated workplace learn-
ing system (developed in the context of another R&D
Project by the same authors). More in details, we de-
ployed SMW+ (Semantic Media Wiki Plus)
11
to allow
users to interact with the ontology layers for a fixed
time interval in order to experience and answer to a
Likert-based questionnaire. In particular, 20 workers
of CRMPA (Centre of Research in Pure and Applied
Mathematics)
12
, involved in four R&D Projects, were
asked to use the deployed system for two months in
order to support their project tasks. At the end of this
period, the 20 workers are asked to answer the ques-
tionnaire consisting in 12 questions. Among these
questions, the item Q10 asked workers to evaluate
their serendipitous learning experience with the de-
ployed system. In a scale from 1 (worst) to 5 (best),
the median was 4, the mode was 5, the variability was
1.2 (for range) and 3 (for iq range). All these values
refer to the item Q10. Of course, the executed exper-
imentation is largely insufficient to evaluate the pro-
posed approach but it has been performed in order to
understand its potential usefulness. Thus, we have al-
ready planned to execute a complete experimentation
in a larger community of users in the context of the
SIRET Project (see Section 5), where we will set two
groups (an experimental group and a control group) of
learners (with the same objectives) and we will try to
analyse the differences in the knowledge acquired in
a group rather than in the other one. Discriminate the
knowledge acquired by means of serendipitous pro-
cesses will be one of the main challenges of the ex-
perimentation methodology. Additional experimen-
tation phases will be executed to evaluate the algo-
rithms proposed to construct and manage ontologies
and to perform link discovery and context-dependent
sequential pattern mining.
ACKNOWLEDGEMENTS
Partially supported by the Italian Ministry of Univer-
sity and Research under the PON 01 03024 SIRET,
Recruiting and Training Integrated System, project
approved by D.D. 721/Ric 2011, October 14 and
started in 2011, November 1. Special thanks to the
other partners involved in these activities: CRMPA,
Centro di Ricerca in Matematica Pura e Applicata,
Fisciano (SA), Italy and MOMA S.p.A., Baronissi
(SA), Italy.
REFERENCES
Andr
´
e, P., Teevan, J., Dumais, S. T., et al. (2009). Discovery
is never by chance: designing for (un) serendipity. In
11
http://www.smwplus.net/
12
http://www.crmpa.it/
UnlockingSerendipitousLearningbyMeansofSocialSemanticWeb
291

Proceedings of the seventh ACM conference on Cre-
ativity and cognition, pages 305–314. ACM.
Baker, T., Bechhofer, S., Isaac, A., Miles, A., Schreiber, G.,
and Summers, E. (2013). Key choices in the design
of simple knowledge organization system (skos). Web
Semantics: Science, Services and Agents on the World
Wide Web.
Boj
¯
ars, U., Breslin, J. G., Finn, A., and Decker, S. (2008).
Using the semantic web for linking and reusing data
across web 2.0 communities. Web Semantics: Science,
Services and Agents on the World Wide Web, 6(1):21–
28.
Boyd, D. (2010). Streams of content, limited attention: The
flow of information through social media. Educause
Review, 45(5):26–28.
Breslin, J. G., Decker, S., Harth, A., and Bojars, U. (2006).
Sioc: an approach to connect web-based communi-
ties. International Journal of Web Based Communi-
ties, 2(2):133–142.
Breslin, J. G., Passant, A., and Decker, S. (2009). Social
Semantic Web. Springer.
Brooks, C., Bateman, S., Greer, J., and McCalla, G. Lessons
learned using social and semantic web technologies
for e-learning.
Capuano, N., Dell’Angelo, L., Orciuoli, F., Miranda, S.,
and Zurolo, F. (2009). Ontology extraction from ex-
isting educational content to improve personalized e-
learning experiences. In Semantic Computing, 2009.
ICSC’09. IEEE International Conference on, pages
577–582. IEEE.
Gaeta, M., Mangione, G., Miranda, S., and Orciuoli, F.
(2013). Adaptive feedback improving learningful con-
versations at workplace. pages 175–182.
Gaeta, M., Orciuoli, F., Paolozzi, S., and Salerno, S. (2011).
Ontology extraction for knowledge reuse: The e-
learning perspective. Systems, Man and Cybernetics,
Part A: Systems and Humans, IEEE Transactions on,
41(4):798–809.
Gianforme, G., Miranda, S., Orciuoli, F., and Paolozzi, S.
(2009). From classic user modeling to scrutable user
modeling. pages 23–32.
Gritton, J. (2007). Of serendipity, free association and aim-
less browsing: do they lead to serendipitous learning.
Retrieved March, 20:2012.
Heinstr
¨
om, J. (2007). Psychological factors behind inci-
dental information acquisition. Library & Information
Science Research, 28(4):579–594.
Ihanainen, P. and Moravec, J. (2011). Pointillist, cyclical,
and overlapping: Multidimensional facets of time in
online education. The International Review of Re-
search in Open and Distance Learning, 12(7):27–39.
Jeremic, Z., Jovanovic, J., and Gasevic, D. (2013). Personal
learning environments on the social semantic web. Se-
mantic Web, 4(1):23–51.
Jovanovic, J., Gasevic, D., and Devedzic, V. E-learning and
the social semantic web.
Kop, R. (2012). The unexpected connection: Serendipity
and human mediation in networked learning. Educa-
tional Technology & Society, 15(2):2–11.
Lu, C.-J. (2012). Accidental Discovery of Information on
the User-Defined Social Web: A Mixed-Method Study.
PhD thesis, University of Pittsburgh.
Maio, C. D., Fenza, G., Loia, V., and Senatore, S. (2011).
Hierarchical web resources retrieval by exploiting
fuzzy formal concept analysis. Information Process-
ing & Management, (0).
Mangione, G. R., Orciuoli, F., Gaeta, M., and Salerno, S.
(2012). Conversation-based learning in the social se-
mantic web. Journal of e-Learning and Knowledge
Society-English Version, 8(2).
McCay-Peet, L. and Toms, E. G. (2010). The process of
serendipity in knowledge work. In Proceedings of the
third symposium on Information interaction in con-
text, pages 377–382. ACM.
Passant, A. and Laublet, P. (2008). Meaning of a tag: A col-
laborative approach to bridge the gap between tagging
and linked data. In LDOW.
Pei, J., Han, J., Mortazavi-Asl, B., Wang, J., Pinto, H.,
Chen, Q., Dayal, U., and Hsu, M.-C. (2004). Mining
sequential patterns by pattern-growth: The prefixspan
approach. Knowledge and Data Engineering, IEEE
Transactions on, 16(11):1424–1440.
Rabatel, J., Bringay, S., and Poncelet, P. (2013). Min-
ing sequential patterns: a context-aware approach. In
Advances in Knowledge Discovery and Management,
pages 23–41. Springer.
Scardamalia, M. and Bereiter, C. (2006). Knowledge build-
ing: Theory, pedagogy, and technology. The Cam-
bridge handbook of the learning sciences, pages 97–
115.
Su
´
arez-Figueroa, M. C. (2010). NeOn Methodology for
building ontology networks: specification, scheduling
and reuse. PhD thesis, Informatica.
Terra, E. and Clarke, C. L. (2003). Frequency estimates for
statistical word similarity measures. In Proceedings of
the 2003 Conference of the North American Chapter
of the Association for Computational Linguistics on
Human Language Technology-Volume 1, pages 165–
172. Association for Computational Linguistics.
Torniai, C., Jovanovic, J., Gasevic, D., Bateman, S., and
Hatala, M. (2008). E-learning meets the social seman-
tic web. In ICALT, pages 389–393. IEEE.
Weller, K. (2010). Knowledge representation in the social
semantic web. Walter de Gruyter.
CSEDU2014-6thInternationalConferenceonComputerSupportedEducation
292
