
Optimal Object Categorization under Application Specific Conditions
Steven Puttemans and Toon Goedem
´
e
EAVISE, KU Leuven, Campus De Nayer, Jan De Nayerlaan 5, 2860 Sint-Katelijne-Waver, Belgium
ESAT/PSI-VISICS, KU Leuven, Kasteelpark Arenberg 10, Heverlee, Belgium
1 STAGE OF THE RESEARCH
The main focus of this PhD research is to create a
universal object categorization framework that uses
the knowledge of application specific scene and ob-
ject variation to reach detection rates up to 99.9%.
This very high detection rate is one of the many re-
quirements of industrial applications, before the in-
dustry will even consider using object categorization
techniques. Currently the PhD research has been run-
ning for one year and has initially focussed on an-
alyzing existing state-of-the-art object categorization
algorithms like (Viola and Jones, 2001; Gall and Lem-
pitsky, 2013; Doll
´
ar et al., 2009; Felzenszwalb et al.,
2010). Besides that, scene and object variation were
used to apply pre- and postprocessing on the actual
detection output, to reduce the occurance of false pos-
itive detections. The next step will be to actually cre-
ate a new universal object categorization framework
based on the experience gathered during the first year
of research, using the selected technique of (Doll
´
ar
et al., 2009) as a backbone for further research.
2 RESEARCH PROBLEM
The focus of this research lies in industrial computer
vision applications that want to perform object de-
tection on object classes with a high intra-class vari-
ability. This means that objects have varying size,
color, texture, orientation, ... Examples of these spe-
cific industrial cases can be seen in Figure 1. These
day-to-day industrial applications, such as product in-
spection, counting and robot picking, are in desper-
ate need of robust, fast and accurate object detec-
tion techniques which reach detection rates of 99.9%
or higher. However, current state-of-the-art object
categorization techniques only guarantee a detection
rate of ±85% when performing in the wild detections
(Doll
´
ar et al., 2010). In order to reach a higher detec-
tion rate, the algorithms impose very strict restrictions
on the actual application environment, e.g. a con-
stant and uniform lighting source, a large contrast be-
Figure 1: Examples of industrial object categorization ap-
plications: robot picking and object counting of natu-
ral products. [checking flower quality, picking pancakes,
counting micro-organisms, picking peppers]
tween objects and background, a constant object size
and color, ... Compared to these more complex object
categorization algorithms, classic thresholding based
segmentation techniques require all of these restric-
tions to even guarantee a good detection result and are
thus unable to cope with variation in the input data.
Looking at the state-of-the-art object categoriza-
tion techniques, we see that the evolution of these
techniques is driven by in the wild object detection
(see Table 1). The main goal exists in coping with
as many variation as possible, achieving a high detec-
tion rate in very complex scenery. However, specific
industrial applications easily introduce many con-
straints, due to the application specific setup of the
scenery and the objects. Exploiting that knowledge
can lead to smarter and better object categorization
techniques. For example, when detecting apples on
a transportation system, many parameters like the lo-
cation, background and camera position are known.
Current object categorization techniques don’t use
this information because they do not expect this kind
of known variation. However exploiting this infor-
mation will lead to a new universal object detection
framework that yields high and accurate detection
rates, based on the scenery specific knowledge.
25
Puttemans S. and Goedemé T..
Optimal Object Categorization under Application Specific Conditions.
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

Table 1: Evolution in robustness of object recognition and object detection techniques trying to cope with object and scene
variation as mentioned in (Puttemans and Goedem
´
e, 2013) ([1] Illumination differences / [2] Location of objects / [3] Scale
changes / [4] Orientation of objects / [5] Occlusions / [6] Clutter in scene / [7] Intra-class variability).
Technique Example Degrees of freedom
1 2 3 4 5 6 7
NCC - based pattern matching (Lewis, 1995) X X – – – – –
Edge - based pattern matching (Hsieh et al., 1997) X X X X – – –
Global moment invariants for recognition (Mindru et al., 2004) X X X X – – –
Object recognition with local keypoints (Bay et al., 2006) X X X X X X –
Object categorization algorithms (Felzenszwalb et al., 2010) X X X – X X X
Industrial Applications – – – – X X – X
3 STATE OF THE ART
Object detection is a widly spread research topic, with
large interest in current state-of-the-art object catego-
rization techniques. (Doll
´
ar et al., 2009) suggested a
framework based on integral channel features, where
all object characteristics are captured into feature de-
scriptions which are then used as a large pool of train-
ing data in a boosting process (Freund et al., 1999).
In contrast to the original boosted cascade of weak
classifiers approach, suggested by (Viola and Jones,
2001), this technique incorporates multiple sources of
information to guarantee a higher detection rate and
less false positive detections.
In the following years of research, this technique
has been a backbone for many well performing ob-
ject detection techniques, mainly for into the wild de-
tections of pedestrians (Benenson et al., 2012; Be-
nenson et al., 2013; Doll
´
ar et al., 2010) and traffic
signs (Mathias et al., 2013). All these recently devel-
opped techniques profit from the fact that the integral
channel features framework allows to integrate ex-
tra application-specific knowledge like stereo vision
information, knowledge of camera position, ground
plane assumption, ... to obtain higher detection rates.
The concept of using application specific scene con-
straints to improve these state-of-the-art object cate-
gorization techniques was introduced in (Puttemans
and Goedem
´
e, 2013). The paper suggests using the
knowledge of the application specific scene and ob-
ject conditions as constraints to improve the detec-
tion rate, to remove false positive detections and to
drastically reduce the number of manual annotations
needed for the training of an effective object model.
Aside from effectively using the scene and object
variation information to create a more accurate appli-
cation specific object detector, the PhD research will
focus on reducing the amount of time needed for man-
ually annotating gigantic databases of positive and
negative training images. This will be done using the
technique of active learning, on which a lot of recent
research was performed (Li and Guo, 2013; Kapoor
et al., 2007). This research clearly shows that inte-
grating multiple sources of information into an active
learning strategy can help to isolate the large problem
of outliers giving reason to include the wrong exam-
ples.
4 OUTLINE OF OBJECTIVES
During this PhD existing state-of-the-art object cat-
egorization algoritms will be reshaped into a sin-
gle universal semi-automatic object categorization
framework for industrial object detection, which ex-
ploits the knowledge of application specific object
and scene variation to guarantee high detection rates.
Exploiting this knowledge will enable three objec-
tives, each focussing on another aspect of object de-
tection that is important for the industry.
1. A High Detection Rate of 99.9% or Even
Higher. Classic techniques reach detection rates
of 85% during in the wild detections, but for in-
dustrial applications a rate of 99.9% and higher is
required. By integrating the knowledge of the ob-
ject and scene variation, the suggested approach
will manage to reach this high demands. Us-
ing the framework of (Doll
´
ar et al., 2009) as a
backbone for the universal object categorization
framework that will be created, these characteris-
tics will be used to include new feature channels
to the model training process, focussing on this
specific object and scene variation.
2. A Minimal Manual Input During the Training
of an Object Model. Classic techniques demand
many thousands of manual annotations during the
collection of training data. By using an inno-
vative active learning strategy, which again uses
the knowledge of application specific scene and
VISIGRAPP2014-DoctoralConsortium
26

object variation, the number of manual annota-
tions will be reduced to a much smaller number
of input images. By iteratively annotating only a
small part of the trainingset and using that to train
a temporary detector based on the already anno-
tated images, the algorithm will decide which new
examples will actually lead to a higher detection
rate, only offer those for a new annotation phase
and omit the others.
3. A Faster and More Optimized Algorithm. By
adding all of this extra functionality, resulting in
multiple new feature channels, into a new frame-
work, a large portion of extra processing is added.
Based on the fact that the original algorithm is
already time consuming and computational ex-
pensive, the resulting framework will most likely
be slower than current state-of-the-art techniques.
However, by applying CPU and GPU optimaliza-
tions wherever possible, the aim of the PhD is to
still provide a framework that can supply real time
processing.
The use of all this application specific knowledge
from the scene and the object, with the aim of reach-
ing higher detection rates, is not a new concept. Some
approaches already use pre- and postprocessing steps
to remove false positive detections based on appli-
cation specific knowledge that can be gathered to-
gether with the training images. For example, (Be-
nenson et al., 2012), use the knowledge of a stereo vi-
sion setup and ground plane assumption, to reduce the
area where pedestrian candidates are looked for. This
PhD research however will take it one step further and
will try to integrate all this knowledge into the actual
object categorization framework. This leads to sev-
eral advantages over the pre- and postprocessing ap-
proaches:
• There will be no need for manual defining or cap-
turing features that are interesting for this pre- and
postprocessing steps.
• Multiple features will be supplied as a large pack-
age to the framework. The underlying boosting
algorithm will then decide which features are ac-
tually interesting to use for model training.
• The algorithm can seperate the input data better
than human perception based on combination of
features.
• Each possible scene and object variation will be
transformed into a new feature channel, in order
to capture as much variation as possible. Once a
channel is defined, it can be automatically recal-
culated for every possible application.
Besides not being able to reach top level detec-
tion rates, state-of-the-art object categorization tech-
niques face the existence of false positive detections.
These detections are classified by the object detector
model as actual objects, because they contain enough
discriminating features. However they are no actual
objects in the supplied data. By adding a larger set
of feature channels to the framework, and thus inte-
grating a larger knowledge of scene and object vari-
ation during the training phase, the resulting frame-
work will effectively reduce the amount of false posi-
tive detections.
5 METHODOLOGY
In order to ensure a systematic approach, the overal
research problem of the PhD is divided into a set
of subproblems, which can be solved one by one in
an order of gradual increase in complexity, in order
to guarantee the best results possible. Section 5.1
will discuss the integration of the application specific
scene and object variation during the model training
process, by highlighting different variation aspects of
possible applications and how they will be integrated
as feature channels. Section 5.2 will illustrate how the
use of an innovative active learning strategy can help
out with reducing the time consuming job of manual
annotation. Finally section 5.3 will discuss how the
resulting framework can be optimized using CPU and
GPU optimalizations wherever possible.
5.1 Integration of Scene and Object
Variation During Model Training
Different properties of application specific scene and
object variation allow to design a batch of new feature
channels in a smart way, that can be used for a uni-
versal object categorization approach. During train-
ing the generation of as many extra feature channels
(see Figure 3) as possible is stimulated, in order to
capture as many variation and knowledge of the ap-
plication as possible from the image data. This is no
problem, since the boosting algorithm of the training
will use all these features to determine which feature
channels capture the most variation, in order to prune
channels away and only keep the most descriptive fea-
ture channels. This immediately ensures that the algo-
rithm won’t become extremely slow during the actual
detection phase because of the feature channel gener-
ation. By integrating all these extra feature channels
into the actual object model training process, a bet-
ter universal and more accurate object categorization
framework will be supplied, which works very appli-
cation specific to reach the highest performance and
detection rate possible.
OptimalObjectCategorizationunderApplicationSpecificConditions
27
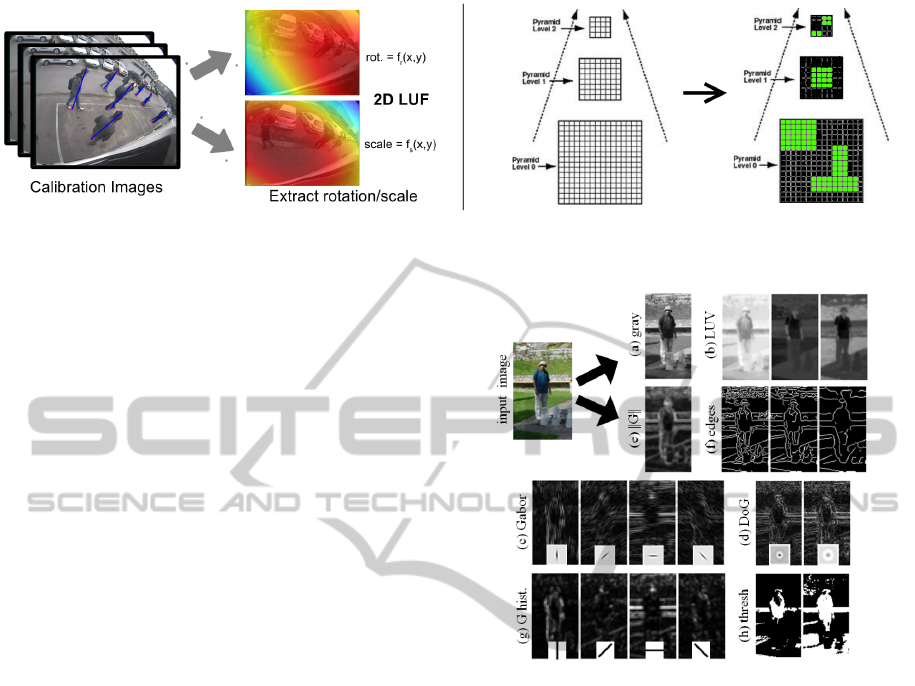
Figure 2: [Left] Example of a scale-location-rotation lookup function for pedestrians in a fixed and lens deformed camera
setup [Right] Example of a fragmented scale space pyramid.
In subsection 5.1.1 the influence of the object
scale and position in the image will be discussed.
Subsection 5.1.2 discusses the influence of lighting,
color and texture. Subsection 5.1.3 addresses the in-
fluence of background clutter and occlusion. Finally
subsection 5.1.4 will handle the object rotation and
orientation knowledge.
5.1.1 Influence of Object Scale and Position
In state-of-the-art object categorization an object
model is trained, by rescaling all provided training
images towards a fixed scale, which results into a sin-
gle fixed scale model. Using a sliding window ap-
proach, with the window size equal to the size of the
resulting model, an object detection is performed at
each image position. However, there is only a lim-
ited number of applications that have fixed scale ob-
jects. In order to detect objects of different scales
in all those other applications, an image scale space
pyramid is generated. In this scale space pyramid the
original image is down- and upsampled and used with
the single scale model. This will generate the possi-
bility to detect objects at different scales, depending
on the amount of scales that are tested. The larger the
pyramid, the more scales that will be tested but the
longer the actual detection phase will take. Reducing
this scale space pyramid effectively is a hot research
topic. (Doll
´
ar et al., 2010) interpolates between sev-
eral predefined images scales, while the detector of
(Benenson et al., 2012) uses an approach that inter-
polates between different trained scales of the object
model. These multiscale approaches are frequently
used because the exact range of object scales is un-
known beforehand in many applications.
However, many industrial applications have the
advantage that the position of the complete camera
setup is fixed and known beforehand (e.g. a camera
mounted above a conveyor belt). Taking this knowl-
edge into account, the scale and position of the objects
can actually be computed and described fairly easy as
seen in Figure 2). Using this information, new fea-
Figure 3: Example of different image channels used in the
integral channel features approach of (Doll
´
ar et al., 2009).
(a) Grayscale image (b) LUV color space (c) Gabor orien-
tation filters (d) Difference of Gaussians (e) Gradient mag-
nitude (f) Edge detector (g) Gradient histogram (h) Thresh-
olded image.
ture channels can be created. Based on manual anno-
tation information, a 2D probability distribution can
be produced over the image giving a relation between
the scale and the position of the object in the image.
(Van Beeck et al., 2012) discusses a warping window
technique that uses a lookup function defining a fixed
rotation and a fixed scale for each position in the im-
age. However reducing the detection to a single scale
for each position limits the intra-class variability that
object categorization wants to maintain. To be sure
this is not a problem, instead of using a fixed scale, a
probability distribution of possible scales for each po-
sition can be modelled. The use of these distribution
functions can lead to a serious reduction of the scale
space pyramid, resulting in a fragmented scale space
pyramid, as seen in Figure 2. This fragmented scale
space pyramid can again be used as a seperate feature
channel for object model training.
VISIGRAPP2014-DoctoralConsortium
28

Figure 4: Texture variation based on the Fourier powerspectrum of an orange and a strawberry.
5.1.2 Influence of Lighting, Color and Texture
State-of-the-art object categorization ensures a certain
robustness by making training samples and new input
images invariant for color and lighting variations. To
do so they use a color invariant image form, like a his-
togram of oriented gradient representation. Another
possible approach is to use Haar-like features, like
suggested by (Viola and Jones, 2001). Making the
images invariant to lighting and color has a twofold
reason. First of all the color variation in academic ap-
plication is too large (e.g. the colors of clothing in
pedestrian detection). On the other hand the color is
too much influenced by the variation in lighting con-
ditions. Therefore, academic applications try to re-
move as many of this variation as possible by apply-
ing techniques like histogram equalization and the use
of gradient images.
By choosing a color and light invariant image
form, all the information from the RGB color spec-
trum is lost which is in fact quite usefull in the in-
dustrial applications suggested by this PhD research.
In many of these applications a uniform and constant
lighting is used, leading to fixed color values. This
information cannot be simply ignored when detecting
objects with specific color properties like strawber-
ries. The advantage of adding this color information
has already been proven in (Doll
´
ar et al., 2009), where
color information of the HSV and LUV space is added
to optain a better and more robust pedestrian detector.
Besides focussing on the color information, it
can be interesting to focus on multispectral color
data. It is possible that objects cannot be seper-
ated in the visual RGB color spectrum, but that
there are higher multispectral frequency resolutions
that make the seperations of objects and background
rather easy. Academic research (Conaire et al., 2006;
Yu et al., 2006; Shackelford and Davis, 2003) has al-
ready shown great interest in these multispectral ap-
proaches, where most of the applications are located
in remote sensing and mobile mapping.
Another parameter that is not widely spread for
object categorization is the use of relevant texture
information in the training objects. Texture can be
described as a unique returning pattern of gradients,
which will almost never occur in the background in-
formation. In order te derive these patterns from the
input data, techniques like Fourier transformations
(Cant et al., 2013) (see Figure 4) and Gabor filters
(Riaz et al., 2013) are used. These transformations
show which frequencies are periodically returning in
the image to define application and object specific tex-
tures.
5.1.3 Influence of Background Clutter and
Occlusion
State-of-the-art object categorization approaches al-
ways attempt to detect objects in the wild which
means that it can occur in every kind of situation,
leading to an infinite number of possible background
types, ... In order to build a detector that is robust
to all this scene background variation, an enormous
amount of negative images samples is needed during
model training. This is required to try to model the
background variation for correct classification and to
ensure that the actual object model will not train back-
ground information. Besides that, it is necessary to
collect as much positive examples as possible in those
varying environments. Doing so ensures that only ob-
ject features get selected that describe the object un-
related to the background behind it. This variation in
the background is referred to as clutter.
Many industrial applications however have a
known background, or at least a background with
minimal variation. Combined with occlusion, where
the object is partially or completely covered, clutter
seems to happen much less frequent than in in the
wild detection tasks. Take for example the taco’s on
the conveyor belt in Figure 5. The conveyor belt is
moving and changes maybe slightly, but it stays quite
constant during processing. Making a good model
of that background information, can help to form an
extra feature channel defining foreground and back-
ground information.
Other cases, like the picking of pears, will have
much more variation in background, and will not give
the possibility to simply aplly foreground-background
OptimalObjectCategorizationunderApplicationSpecificConditions
29

Figure 5: Example of background variation and occlusion in (a) academic cases and (b) industrial cases.
segmentation (see Figure 6).
A technique that is widely used for this kind of
information is foreground-background segmentation,
like in (Yeh et al., 2013). This technique helps us
identify regions in the image that can be classified
as foreground and thus regions of interest for possi-
ble object detections. The masks created by this seg-
mentation can be applied as an extra feature channel.
Using a dynamic adapting background model (Ham-
mami et al., 2013), the application specific back-
ground will be modelled and a likelihood map of a
region belonging to the foreground will be created.
These are referred to as heat maps.
Due to the context of application specific algo-
rithms, one can state that the only negative images
that need to be used as negative training samples, are
images that contain the possible backgrounds. This
leads to the conclusion that many case specific ob-
ject models can be reduced to having a very lim-
ited amount of negative training images, based on the
applications scene and background variation, maybe
even reducing the negative training images to a single
image, if a static background occurs.
5.1.4 Influence of Rotation and Orientation
Most state-of-the-art object categorization ap-
proaches, e.g. detecting pedestrians, assume that
there is no rotation of the actual object, since
pedestrians always appear more or less upright.
Figure 6: Example of pear fruit in an orchard, where more
background clutter and occlusion occurs.
However this is not always the case, like shown in
(Van Beeck et al., 2012), where pedestrians occur in
other orientations due to the lens deformation and the
birdseye viewpoint of the camera input.
Many industrial applications however contain dif-
ferent object orientations, which leads to problems
when having a fixed orientation object model. Adding
all possible orientations to the actual training data for
a single model, will lead to a model that is less de-
scriptive and which will generate tons of extra false
positive detections. A second approach is to test all
possible orientations, by taking a fixed angle step, ro-
tating the input image and then trying the trained sin-
gle orientation model. Once a detection is found, it
can be coupled to the currect angle and then used to
rotate the detection bounding box, like discussed in
(Mittal et al., 2011). However, in order to reach real-
time performance using this approach, a lot of GPU
optimalizations will be needed, since the process of
rotating and performing a detection on each patch is
computationally intensive. A possible third approach
trains a model for each orientation, as suggested in
(Huang et al., 2005). However, this will lead to an
increase of false positive detections.
The currently used approaches to cope with differ-
ent orientations do not seem to be the best approaches
possible. In this PhD research we want to create an
automated orientation normalization step, where each
patch is first put through a series of orientation fil-
ters that determine the orientation of the current patch
and then rotates this patch towards a standard model
orientation. A possible approach is the dominant gra-
dient approach as illustrated in Figure 7. However,
preliminary test results have shown that this approach
doesn’t work in every case. Therefore a combina-
tion of multiple orientation defining techniques will
be suggested in our framework. Other techniques that
can be included into this approach are eigenvalues
of the covariance matrix (Kurz et al., 2013), calcu-
lating the geometric moments of a colour channel of
the image (Leiva-Valenzuela and Aguilera, 2013) or
even defining the primary axis of an ellipse fitted to
foreground-background segmentation data (Ascenzi,
2013).
Our suggested orientation normalization filter will
VISIGRAPP2014-DoctoralConsortium
30

Figure 7: Example of rotation normalization using a dominant gradient technique. From left to right: original image (road
marking), gradient image, dominant orientation and rotation corrected image.
use the combination of multiple orientation features
to decide which one is the best candidate to actually
define the patch orientation. In order to create this ex-
tra filter, all manual positive annotations are given an
extra parameter, which is the object orientation of the
training sample. From that data a mapping function is
learned to define a pre-filter that can output a general
orientation for any given window. Part of this general
idea, where the definition of the orientation is seper-
ated from the actual detection phase, is suggested in
(Villamizar et al., 2010).
5.2 Innovative Active Learning Strategy
for Minimal Manual Input
Limited scene and object variation can be used to put
restrictions on the detector, by supplying extra feature
channels to the algorithm framework, as previously
explained. However, we will take it one step further.
The same information will be used to optimize the
complete training process and to drastically reduce
the actual amount of training data that is needed for
a robust detector. For state-of-the-art object catego-
rization algorithms, the most important way to ob-
Figure 8: Example of viewpoint and lens deformation,
changing the natural orientation of objects. (Van Beeck
et al., 2012).
tain a detector with a high detection rate is increasing
the amount of positive and negative training samples
enormously. The idea behind it is simple, if you add a
lot of extra images, you are bound to have those spe-
cific examples that lie close to the decision boundary
and that are actually needed to make an even better
detector. However, since several industrial applica-
tions have a smaller range of variation, it should be
possible to create an active learning strategy based
on this limited scene and object variatiation, that suc-
ceeds in getting a high detection rate with as less ex-
amples as possible, by using the variation knowledge
to look for those specific examples close to the deci-
sion boundary.
Like described in the conclusion of (Mathias et al.,
2013), using immense numbers of training samples is
currently the only way to reaching the highest pos-
sible detection rates. Since all these images need to
be manually annotated, which is very time consum-
ing job, this extra training data is a large extra cost
for industrial applications. Knowing that the industry
wants to focus more and more on flexible automati-
zation of several processes, this extra effort to reach
high detection rates is a large downside to current
object categorization techniques, since companies do
not have the time to invest all this manual annotation
work. The industry wants to retrieve a robust object
model as fast as possible, in order to start using the
detector in the actual detection process.
5.2.1 Quantization of Existing Scene and Object
Variation
In order to guarantee that the suggested active learn-
ing approach will work, it is necessary to have a
good quantization of the actual variation in object and
scene. These measurements are needed to define if
new samples are interesting enough to add as extra
training data. The main focus is to define how much
intra-class variation there is, compared to the amount
of variation in the background. Many of these varia-
tions, like scale, position, color, ... can be expressed
OptimalObjectCategorizationunderApplicationSpecificConditions
31

Figure 9: Workflow of the suggested active learning strategy. [ = manual input, F = knowledge of scene and object
variation is used, TP = true positive detection, TN = true negative detection, FP = false positive detection, FN = false negative
detection].
by using a simple 1D probability distribution over all
different training samples. However, some variations
are a lot harder to quantize correctly. If it is impor-
tant to guarantee the intra-class variability, then it can
even be extended to a 2D probability distribution, to
allow multiple values for a single point in the distribu-
tion. However, features like texture and background
variation cannot be modelled with a simple 1D prob-
ability distribution. A main part of the PhD research
will thus go into investigating this specific problem
and trying to come up with good quantizations for all
these scene and object variations.
5.2.2 Active Learning During Object Model
Training
Initial tests have shown that it is possible to build ro-
bust object detectors by using only a very limited set
of data, as long as the training data is chosen based
on application specific knowledge. However, figuring
out which examples are actually needed, sometimes
turns out to be more time consuming than just simply
labeling large batches of training data, if the process is
not automated. Therefore we suggest using an active
learning strategy which should make the actual train-
ing phase more simple and more interactive. Eventu-
ally the algorithm optimizes two aspects: first being
a minimal manual intervention and second an as high
as possible detection rate. This research will be the
first of its kind to integrate the object and scene varia-
tion into the actual active learning process, combining
many sources of scene and object specific knowledge
to select new samples, that can then be annotated in a
smart and interactive way.
Figure 9 shows how the suggested active learn-
ing strategy based on application specific scene and
object variation should look like. As a start a lim-
ited set of training data should be selected from a
large database of unlabeled images. Since capturing
many input images is not the problem in most cases,
the largest problem lies in annoting the complete set,
which is very time consuming. Once this initial set of
data is selected, they are given to the user for anno-
tation and a temporarily object model is trained using
this limited set of samples. After the training a set
of test images is smartly selected from the database
using the scene and object variations that are avail-
able. By counting the true positives, false positives,
true negatives and false negatives, the detector perfor-
mance is validated on this test data, by manually su-
pervising the output of the initial detector. Based on
this output and the knowledge of the variation distri-
butions in the current images, an extra set of training
images is selected cleverly. The pure manual anno-
tation is now splitted into a part where the operator
needs to annotate a small set of images, but after the
detection step, needs to validate the detections in or-
der to compute the correctness of the detection output.
This process is iteratively repeated until the desired
detection rate is reached and a final object model is
trained.
The above described innovative active learning
VISIGRAPP2014-DoctoralConsortium
32

strategy will yield the possibility to make a well fun-
damented guess on how many positive and negative
training samples there will actually be needed to reach
a predefined detection rate. In doing this, the ap-
proach will drastically reduce the amount of manual
annotations that need to be provided, since it will only
propose to annotate new samples that actually im-
prove the detector. Training images that describe fre-
quently occuring situations, and are thus being classi-
fied as objects with a high certainty are not interesting
in this case. On the contrary, it will be more interest-
ing trying to select those positive and negative train-
ing samples that lie very close to the decision bound-
ary, in order to make sure that the boundary will be
more stable, more supported by good examples and
thus leading to higher detection rates.
It is important to mention that classic active learn-
ing strategies are often quite sensitive to outliers (Ag-
garwal, 2013) that get selected in the learning process
and that lead to overfitting of the training data. How-
ever by adding multiple sources of information, being
different application specific scene and object varia-
tions, the problem of single outliers can be countered,
since their influence on the overal data distribution
will be minimal. The suggested approach will filter
out these outliers quite effectively, making sure that
the resulting detector model will not overfit to the ac-
tual training set.
5.3 CPU and GPU Optimalization
Towards a Realtime Object
Categorization Algorithm
Once the universal object categorization framework,
combined with an innovative active learning strategy,
will be finished it will produce a better and more ac-
curate detection system for industrial applications and
in general, for all applications where the variation in
scene and/or object is somehow limited. However ex-
panding a framework to cope with all these applica-
tion specific scene and object variations will lead to
more internal functionality. This will result in a com-
putationally more expensive and thus a slower run-
ning algorithm.
Since real time processing is essential for most
industrial applications, this problem cannot be sim-
ply ignored. The longer the training of a specific ob-
ject model takes, the more time a company invests in
configuration and not in the actual detection process
that generates a cash flow. This is why during this
PhD research each step of the processing will be opti-
mized using CPU and GPU optimalization. Classical
approaches like parallelization and the use of multi-
core CPU’s can improve the process (De Smedt et al.,
2013), while the influence of general purpose graph-
ical processing units (GPGPU) will also be investi-
gated. The CUDA language will be used to imple-
ment these GPU optimalizations, but the possibility
of using OpenCL will be considered.
6 EXPECTED OUTCOME
At the end of this PhD research a complete new inno-
vative object categorization framework will be avail-
able that uses industrial application specific object
and scene constraints, in order to obtain an accurate
and high detection rate of 99.9% or higher. The re-
sult will be a stimulation for the industry to actively
use this technology for robust object detection. The
research will lead to new insights in general for ob-
ject detection techniques. If this is proved to be
successfull, the same approach will be introduced in
other frameworks like the deformable parts model of
(Felzenszwalb et al., 2010), to reach higher perfor-
mances without increasing the number of training ex-
amples.
ACKNOWLEDGEMENTS
This work is supported by the Institute for the Promo-
tion of Innovation through Science and Technology
in Flanders (IWT) via the IWT-TETRA project TO-
BCAT: Industrial Applications of Object Categoriza-
tion Techniques.
REFERENCES
Aggarwal, C. C. (2013). Supervised outlier detection. In
Outlier Analysis, pages 169–198. Springer.
Ascenzi, M.-G. (2013). Determining orientation of cilia in
connective tissue. US Patent 8,345,946.
Bay, H., Tuytelaars, T., and Van Gool, L. (2006). Surf:
Speeded up robust features. ECCV, pages 404–417.
Benenson, R., Mathias, M., Timofte, R., and Van Gool, L.
(2012). Pedestrian detection at 100 frames per second.
In Computer Vision and Pattern Recognition (CVPR),
2012 IEEE Conference on, pages 2903–2910. IEEE.
Benenson, R., Mathias, M., Tuytelaars, T., and Van Gool,
L. (2013). Seeking the strongest rigid detector. In
Proceedings of IEEE Conference on Computer Vision
and Pattern Recognition.
Cant, R., Langensiepen, C. S., and Rhodes, D. (2013).
Fourier texture filtering. In UKSim, pages 123–128.
Conaire, C. O., O’Connor, N. E., Cooke, E., and Smeaton,
A. F. (2006). Multispectral object segmentation and
retrieval in surveillance video. In Image Processing,
OptimalObjectCategorizationunderApplicationSpecificConditions
33

2006 IEEE International Conference on, pages 2381–
2384. IEEE.
De Smedt, F., Van Beeck, K., Tuytelaars, T., and Goedem
´
e,
T. (2013). Pedestrian detection at warp speed: Ex-
ceeding 500 detections per second. In Proceedings
of IEEE Conference on Computer Vision and Pattern
Recognition.
Doll
´
ar, P., Belongie, S., and Perona, P. (2010). The fastest
pedestrian detector in the west. In BMVC, volume 2-3,
page 7.
Doll
´
ar, P., Tu, Z., Perona, P., and Belongie, S. (2009). Inte-
gral channel features. In BMVC, volume 2-4, page 5.
Felzenszwalb, P., Girshick, R., and McAllester, D. (2010).
Cascade object detection with deformable part mod-
els. In CVPR, pages 2241–2248.
Freund, Y., Schapire, R., and Abe, N. (1999). A short in-
troduction to boosting. Journal-Japanese Society For
Artificial Intelligence, 14(771-780):1612.
Gall, J. and Lempitsky, V. (2013). Class-specific hough
forests for object detection. In Decision Forests for
Computer Vision and Medical Image Analysis, pages
143–157. Springer.
Hammami, M., Jarraya, S. K., and Ben-Abdallah, H.
(2013). On line background modeling for moving
object segmentation in dynamic scenes. Multimedia
Tools and Applications, pages 1–28.
Hsieh, J., Liao, H., Fan, K., Ko, M., and Hung, Y. (1997).
Image registration using a new edge-based approach.
CVIU, pages 112–130.
Huang, C., Ai, H., Li, Y., and Lao, S. (2005). Vector boost-
ing for rotation invariant multi-view face detection. In
Computer Vision, 2005. ICCV 2005. Tenth IEEE In-
ternational Conference on, volume 1, pages 446–453.
IEEE.
Kapoor, A., Grauman, K., Urtasun, R., and Darrell, T.
(2007). Active learning with gaussian processes for
object categorization. In Computer Vision, 2007.
ICCV 2007. IEEE 11th International Conference on,
pages 1–8. IEEE.
Kurz, G., Gilitschenski, I., Julier, S., and Hanebeck,
U. D. (2013). Recursive estimation of orientation
based on the bingham distribution. arXiv preprint
arXiv:1304.8019.
Leiva-Valenzuela, G. A. and Aguilera, J. M. (2013). Auto-
matic detection of orientation and diseases in blueber-
ries using image analysis to improve their postharvest
storage quality. Food Control.
Lewis, J. (1995). Fast normalized cross-correlation. In Vi-
sion interface, volume 10, pages 120–123.
Li, X. and Guo, Y. (2013). Adaptive active learning for im-
age classification. In IEEE Conf. on Computer Vision
and Pattern Recognition (CVPR).
Mathias, M., Timofte, R., Benenson, R., and Gool, L.
(2013). Traffic sign recognition-how far are we from
the solution? In Proceedings of IEEE International
Joint Conference on Neural Networks.
Mindru, F., Tuytelaars, T., Gool, L., and Moons, T. (2004).
Moment invariants for recognition under changing
viewpoint and illumination. CVIU, 94:3–27.
Mittal, A., Zisserman, A., and Torr, P. (2011). Hand detec-
tion using multiple proposals. BMVC 2011.
Puttemans, S. and Goedem
´
e, T. (2013). How to exploit
scene constraints to improve object categorization al-
gorithms for industrial applications? In Proceedings
of the international conference on computer vision
theory and applications (VISAPP 2013), volume 1,
pages 827–830.
Riaz, F., Hassan, A., Rehman, S., and Qamar, U.
(2013). Texture classification using rotation-and
scale-invariant gabor texture features. IEEE Signal
Processing Letters.
Shackelford, A. K. and Davis, C. H. (2003). A combined
fuzzy pixel-based and object-based approach for clas-
sification of high-resolution multispectral data over
urban areas. Geoscience and Remote Sensing, IEEE
Transactions on, 41(10):2354–2363.
Van Beeck, K., Goedem
´
e, T., and Tuytelaars, T. (2012). A
warping window approach to real-time vision-based
pedestrian detection in a truck’s blind spot zone. In
ICINCO, volume 2, pages 561–568.
Villamizar, M., Moreno-Noguer, F., Andrade-Cetto, J., and
Sanfeliu, A. (2010). Efficient rotation invariant object
detection using boosted random ferns. In Computer
Vision and Pattern Recognition (CVPR), 2010 IEEE
Conference on, pages 1038–1045. IEEE.
Viola, P. and Jones, M. (2001). Rapid object detection using
a boosted cascade of simple features. In CVPR, pages
I–511.
Yeh, C.-H., Lin, C.-Y., Muchtar, K., and Kang, L.-W.
(2013). Real-time background modeling based on a
multi-level texture description. Information Sciences.
Yu, Q., Gong, P., Clinton, N., Biging, G., Kelly, M., and
Schirokauer, D. (2006). Object-based detailed vegeta-
tion classification with airborne high spatial resolution
remote sensing imagery. Photogrammetric Engineer-
ing and Remote Sensing, 72(7):799.
VISIGRAPP2014-DoctoralConsortium
34
