
Serious Game based on Virtual Reality and Artificial Intelligence
Kahina Amokrane
1
, Domitile Loudeaux
1
and Georges Michel
2
1
Heudiasyc Laboratory UMR CNRS 7253, Universit de Technologie de Compiegne, BP205, Compiegne, France
2
AFPA, AFPA - INMF, ISTRES, France
Keywords:
Virtual Reality, Knowledge Representation, Scenario Adaptation, Plan Recognition, Serious Game.
Abstract:
Virtual reality is a very interesting technology for professional training. We can mention in particular the
ability to simulate the activity without real danger, the flexibility in the informations’ presentation, or the exact
control parameters of the simulation allows to reproduc specific situations. Today, technological maturity
allows to plan increasingly a complex applications. However, in one hand, this complexity increases the
difficulty, at the same time, to propose a pedagogical and narrative control (to ensure a given learning and
narrative structure) and some freedom of actions (to promote the emergence of various, unique and suprised
situations in order to ensure a learning-by-doing/errors). In other hand, this complexity makes difficult the
tracking and understanding of learner’s path. In this paper, we propose 1- a scripting model for training virtual
environment combining both a pedagogical control and the emergence of pertinent learning situations and 2-
tracking of the learner’s actions, but also analysis and automatic diagnosis tools of the learner’s performances.
1 INTRODUCTION
Our goal is to propose models to control the dynamic
adaptation of a training system, whose objective is
twofold. On the one hand, it allows learners to freely
explore the Virtual Environment (VE) and learn from
their errors without constraints or activity guidance.
On the other hand, it allows the system to dynamically
control the learning situations and the total coherence
of the scenario.
To adapt the scenario to the learner’s behaviors,
it is necessary to be able to finely understand what
they are doing. Therefore, we propose a learner track-
ing system based on plan recognition techniques. It is
based on the finalized activity that contains mainly the
observed procedure in situ, the compromises made by
the operators and frequent errors. Our system allows
to determine the task performed by the learner and
committed errors, from observable actions and the ef-
fects left in the VE, based on a reference model. In
return, our system scripts the VE basing on pedagogi-
cal and contextual rules and on two calculated param-
eters: complexity and severity. These two parameters
allow us to select virtual characters behaviors. Note
that the application consists of training of babysitters.
2 PROBLEM AND MOTIVATION
Our goal is to propose models to control the dynamic
adaptation of a serious game, allowing one side to the
learner to freely explore the VE and learn from their
errors without constraint or activity’s guidance and on
the other hand to the system to control dynamically
the learning situations and the total coherence of the
scenario. In previous work (Amokrane et al., 2008c),
we proposed an activity description language called
HAWAI-DL, which allows to describe all the possi-
ble of reference activities. This description favors the
emergence of situations and learning by errors. How-
ever, it does not ensure a precise sequence or a con-
trol of scenario consistency. Thus, in this paper we
will see how we added to our system pedagogical and
contextual rules based on the activity consistency to
adapt dynamically the scenario according to learner
progress, context and learning objectives.
The AFPA
1
has identified a set of learning situ-
ations based on the professional didactic. However,
the professional didactic imposes situations precisely
identified to allow the acquisition of specific skills. If
the scenarios were less rich, a deterministic scripting
including all possible cases and all possible interac-
tions of the learner would have been conceivable.
In the serious games, there are several motivating
1
http://www.afpa.fr/
679
Amokrane K., Lourdeaux D. and Michel G..
Serious Game based on Virtual Reality and Artificial Intelligence.
DOI: 10.5220/0004919206790684
In Proceedings of the 6th International Conference on Agents and Artificial Intelligence (ICAART-2014), pages 679-684
ISBN: 978-989-758-015-4
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

factors, the ones witch interest us are all that is related
to the story. We aim to have consistent, non-boring
scenarios. This point raises the problem of what mo-
tivating factors to consider in our system and how.
As we are in highly complex and dynamic sys-
tems, the learner does not have the time to understand
everything that happens in real time. So, it is useful to
comeback on it in debriefing, even if the trainer had
all informations in real time. To do this, we added to
each session a trace of performed activity. This point
raises the problem of trace content and its replay.
3 CONTEXT AND RELATED
WORK
3.1 Pedagogical Scenario Control in
Virtual Environments
Most virtual environments designed for training pur-
poses are used in training sessions as part of a peda-
gogical scenario. These scenarios are the sequences
of learning activities. In some cases, several learning
activities are simulated inside the VE. The transposi-
tion of the subsequence of the pedagogical scenario
in the VE generally consists in branching tree struc-
tures, containing predetermined sequences of scenes
(Magerko et al., 2005), or tasks the user has to exe-
cute (Mollet and Arnaldi, 2006). Yet, in order to stay
within these paths, these VEs offer a strong guidance
to the trainee, often stopping them whenever they de-
viate from the training scenario.
On the other hand, some environments are used
in pedagogical scenarios as a single learning activity.
These environments opt for the “sandbox” approach,
letting the user act freely as the simulation evolves
and reacts to their actions, like in (Shawver, 1997).
However, without any real-time pedagogical control,
the efficiency of the training is not guaranteed.
One approach for ensuring both user agency and
pedagogical control is to define a multilinear graph of
all possible scenarios, In (Delmas et al., 2007), the set
of possible plots is thus explicitely modelized through
a Petri Network. However, when the complexity of
the work situation scales up, it becomes difficult to
predict all possible courses of actions.
3.2 Scenario Adaptation
Adaptative scenarisation is the process of reacting to
users actions to provide content fitted to their need.
In videogames, it might be used to adjust difficulty
according to learners level without using typical dis-
crete mode such as Easy,Hard, etc. With adaptive fea-
tures, learners are always in the flow (Csikszentmiha-
lyi, 1991): the difficulty remains high enough to pro-
pose a suitable challenge, yet, learner can overcome it
so that they do not get bored or frustrated. The adap-
tation can be made at different level of granularity. A
first approach is to have a global adaptation : a whole
scenario has been written (Marion, 2010) or generated
(Niehaus et al., 2011) and the outcomes of the events
were scripted beforehand.
The simulation where the adaptation take place
can be run with opposite approaches : the controlled
approaches versus the emergent approaches. The con-
trolled approach aims to provide a very efficient learn-
ing by orchestrating each part of the simulation : state
of the object, virtual character, action possibilities of
the learner, etc. It make possible Pedagogical control
(Gerbaud et al., 2008). Moreover, such an approach
demands an exhaustive modeling of the world func-
tionment which handicap the evolutivity of the sys-
tem. The whole modeling has to be reconsidered to
avoid incoherence each time an author add new con-
tents. By a clever modelling of small behaviors of the
world, emergent approaches allow new situations to
arise (Shawver, 1997). The issue with emergent ap-
proachs is the lack of pedagogical control.
3.3 Motivation’s Factors
There are several motivation models in video game.
These range from expectancy/valence approaches
(Mathieu et al., 1992) to Kellers (1983) Attention,
Relevancy, Confidence, and Satisfaction (ARCS)
model. Behavior can be intrinsically or extrinsically
motivated. Most models have emphasized intrinsic
motivation, focusing on the motives to perform a task
that are derived from the participation itself (Malone,
1981). Malone (1981) proposed that the primary fac-
tors that make an activity intrinsically motivating are
challenge, curiosity, and fantasy and specifically ap-
plied this framework to the design of computer games.
Others have examined extrinsic motivation, in which
someone engages in an activity as a means to an end
(Vallerand et al., 1997).
4 OUR TROPOSAL
4.1 General Architectur
For each observable action or effect in the VE, a
message is send to our tracking and scripting sys-
tem. Thanks to task recognition technique, our sys-
ICAART2014-InternationalConferenceonAgentsandArtificialIntelligence
680
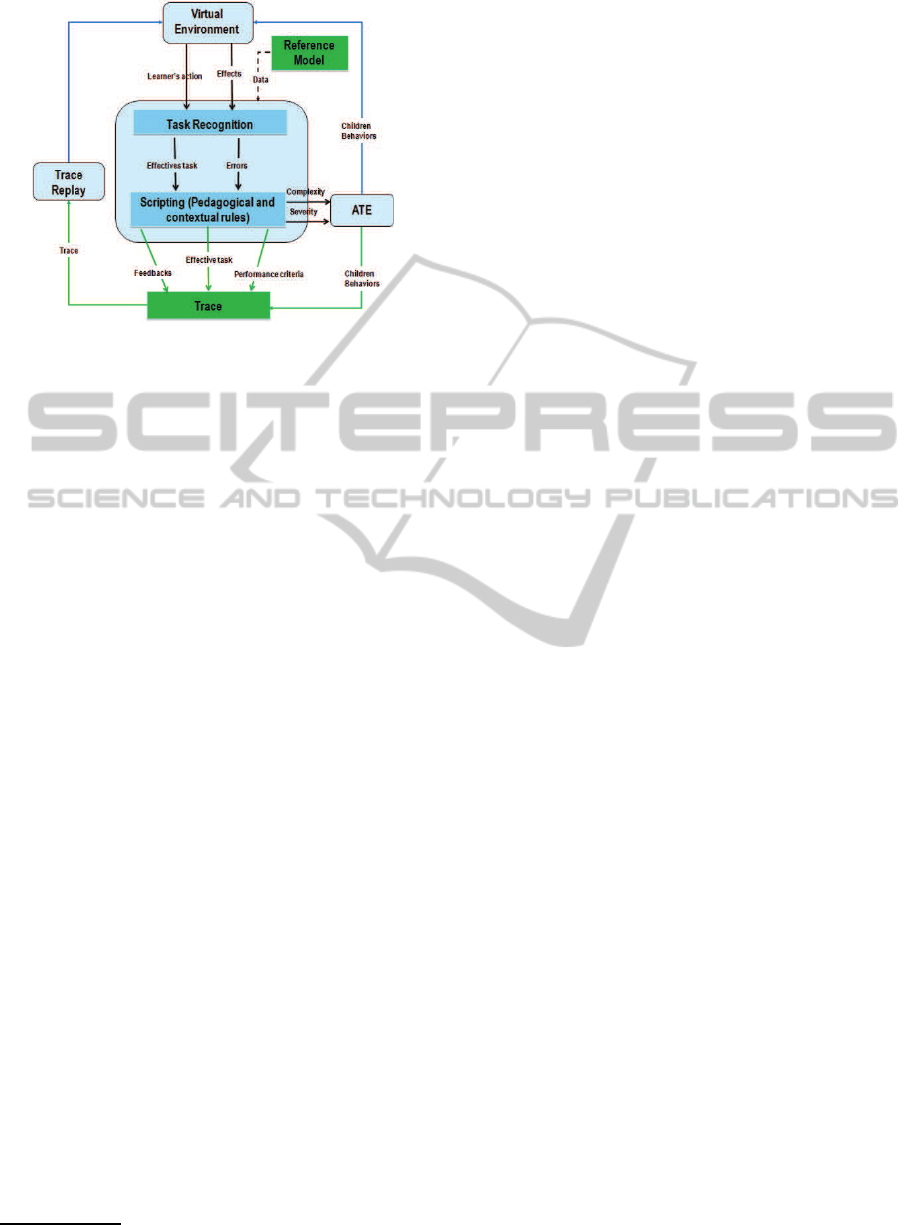
Figure 1: Global architecture of our system.
tem determines the effective task and committed er-
rors. These last, are analyzed to determine the feed-
backs, performance criteria, complexity and severity
based on a set of pedagogical and contextual rules. At
the laste time, a trace is recorded in xml Forme.
4.2 Task Recognition and Reference
Model
Our approach consists in proposing an emergence
of relevant learning situations and allows to put the
learner in front of varied and controlled situations.
We prefer to guide the learner through a non-intrusive
scripting, to favor an exploratory approach and learn-
ing by trial and error. Therefore, the reference model
must contain the finalized activity (not only the pre-
scribed procedure but also the compromises made by
the operators is situ and frequent errors).
To describe such activity, we proposed, with
LATI
2
ergonomists, HAWAI-DL, an activity descrip-
tion language, inspired principally by GTA (van der
Veer et al., 1996). Even if the activity is described
previously, but thanks to the hierarchical representa-
tion of the activity and the concept of hyperonymous
tasks, the learner has the freedom to choose his path
to reach his goal, crossing from one branch of this
tree to another or from one hyperonymous task to an-
other. To recognize the task performed by the learner
and the committed errors, we based on formal plan
recognition techniques (Cohen et al., 1981). On an
heuristics based approach, proposed in (El-Kecha and
Desprs, 2006). This recognition system takes as input
the actions or observable effects in the VE and the ref-
erence model. Our system detects several type of er-
rors, thus, we distinguished errors and violations. The
errors concern those of CREAM model (Hollnagel,
2
http://recherche.parisdescartes.fr/LATI
1993). The violations concern safety related errors,
action errors, target object errors and condition errors
(Amokrane et al., 2008b).
4.3 Scripting using Pedagogical,
Contextual and Motivation
Concepts
As mentioned in the previoussub-section, our system,
allows, to the learner, the freedom in the choice of his
actions. However, giving the learner a total freedom
in his choices makes the serious game more attrac-
tive, but it does not ensure learning. Thus, the control
of situations is necessary. To do this, we added a set
of pedagogical and contextual rules that are based on
learning situations defined by the AFPA, according to
professional didactics. But these situations are very
limited and constrained; do not allow creating unex-
pected and surprising situations. To overcome such
a limitation, we took into account the main learning
situations. Then, we identified several complexity
levels of situations and events which may disturb the
main activity of the learner. So, if the learner is do-
ing well his task, the complexity is equal to three, and
then in addition to nominal task, the learner is con-
fronted to important disturbances that require imme-
diate reaction. If he is doing less well his task, the
complexity is equal to two, and then in addition to the
nominal task, the learner is confronted to some weak
disturbance that do not require immediate reactions.
And if the learner does not come out at all his nomi-
nal task, the complexity is equal to one, so the system
let the learner doing his nominal task without any dis-
turbance.
To create unique and unexpected game situations,
we identified several severity levels of actions and
events consequences. This severity levels depend on
the historical of learner’s actions and errors. So, if
the learner did not do yet the scenario, the severity is
equal to one, and then, even if the learner done errors,
consequences are not showing. If the learner commits
the same error at the second time, the severity is equal
to two, and then the system show just not serious con-
sequences. And if he commits the same error several
times, the severity is equal to three, and then serious
consequences of learner’s error are shown.
These complexity and severity levels are recal-
culated dynamically during the session according to
learner’s activity and learning situations. These two
elements allow to control the generation of virtual
characters behaviors. Complexity and severity allow
to increase his commitment in history and allow also
to play on learners intrinsic motivation.
One of the intrinsic motivation factors on which
SeriousGamebasedonVirtualRealityandArtificialIntelligence
681

we worked is the severity variation of situations. In
order to do not loose motivation to the learner, we
chose to prevent the learner from a serious danger
by causing a minor accident, at the first time, that he
commits the error (e.g. the child has a bump) and ex-
plain him the situation at trace replay by an attention
message. The second time, the AFPA has proposed
to cause more serious consequences, or irremediable:
the child can have a cranial traumatism, or he can die.
Another factor of intrinsic motivation on which
we worked is the dynamic adaptation of the com-
plexity level. The goal is to create situations always
unique and increasingly difficult to avoid the boredom
of the learner. Even we are not in a controlled story-
telling plan such as the interactive storytelling or nar-
rative video games, and that the tragedy here is not the
heart of the story, we can compare the level of diffi-
culty (complexity and severity) progressive useful for
learning at a level of dramatic tension. It concerns es-
sentially to modulate gradually the dramatic tension
by creating situations more or less complex and more
or less urgent. The creation of situations with a strong
dramatic tension allows the learner to learn how to re-
act quickly but calmly in emergency situation.
Combining intrinsic and extrinsic motivation, we
worked on the feeling of achievement, satisfaction
and self confidence of the learner. This feeling
of achievement can be created 1) by increasing his
scores via the performance criteria (Figure 2), 2) by
congratulations messages during trace replay when
the learner is successful (Figure 2) and mostly. 3) by
the success of his actions.
Figure 2: VE with congratulations messages and perfor-
mance criteria.
4.4 Trace and Its Replay
As we are in the case of very complex activities, and
which require to react quickly, the learner has not the
time to analyze and understand in real time. Natu-
rally, our system provides a trace which allows the
trainer and the learner to go back on what have been
done, to analyze it and understand all the cause and
effect relationships. To model these relationships, we
based on Bayesian networks, that allows to represent
the causal relationships between human errors, envi-
ronmental conditions and risks as well as risks propa-
gation and compute the occurrence probability of po-
tential risks in real time (Figure 3) (Amokrane and
Lourdeaux, 2009).
Figure 3: Exemple of Bayesian netWork.
The trace does not only contain the activity per-
formed by the learner, but also all the committed er-
rors, feedbacks and all Performance Criteria (PC) and
their values. For each session, a trace is saved and at
the trace replay time, the learner can revise everything
he did during a session (Amokrane et al., 2008a).
4.5 The Childern’s Generation
Behaviors
The learner shares his universe with virtual charac-
ters, which represent in our case children between 6
months to 7 years. These children represent either
the disturbing elements or support elements for the
learner, depending on his activity (if he does well or
not, if he commit a lot of errors or not, etc.) and de-
pending on the world state.
For the generation of children’s behaviors, we in-
tegrated a module named ATE based on rules. It in
input the complexity and severity calculated by our
learner tracking and scripting module and the state
of the world to determine the children’s behaviors.
Among a set of possible situations, ATE eliminates
situations / responses that are not valid according to
the context, eliminating those that have already oc-
curred, and determined, basing on severity and com-
plexity, those that are more appropriate. If still more,
it chooses one at random. For example, if the com-
plexity is 2 (commits errors that are independent on
the main learning situations), and severity is 2 (sce-
nario already done, and the learner forgot to close the
stairs barrier for the first time), and the child is outside
of the view field of the learner, the child throws him-
self from the stairs and as a result he will have only
a small bump. on the other hand, for the same ex-
ample, if severity is 3 (scenario already done, and the
learner forgot to close the stairs barrier for the second
ICAART2014-InternationalConferenceonAgentsandArtificialIntelligence
682
time) the child throws himself from the stairs and as a
consequence he will have a cranial traumatism.
5 RESULTS
The evaluationof our approach is performedby AFPA
learners for real training sessions. The tests were per-
formed in two sessions, with 14 learners for each and
during one week. The methodology used is the one
which compares two groups: one used our system
to learn (experimental group), another learn without
our system (Control group). The evaluation consid-
ers principally the usability of the feedbacks that we
proposed and the PC. At the end of the experiments, a
satisfaction questionnaire is filled out by each learner
of the group.
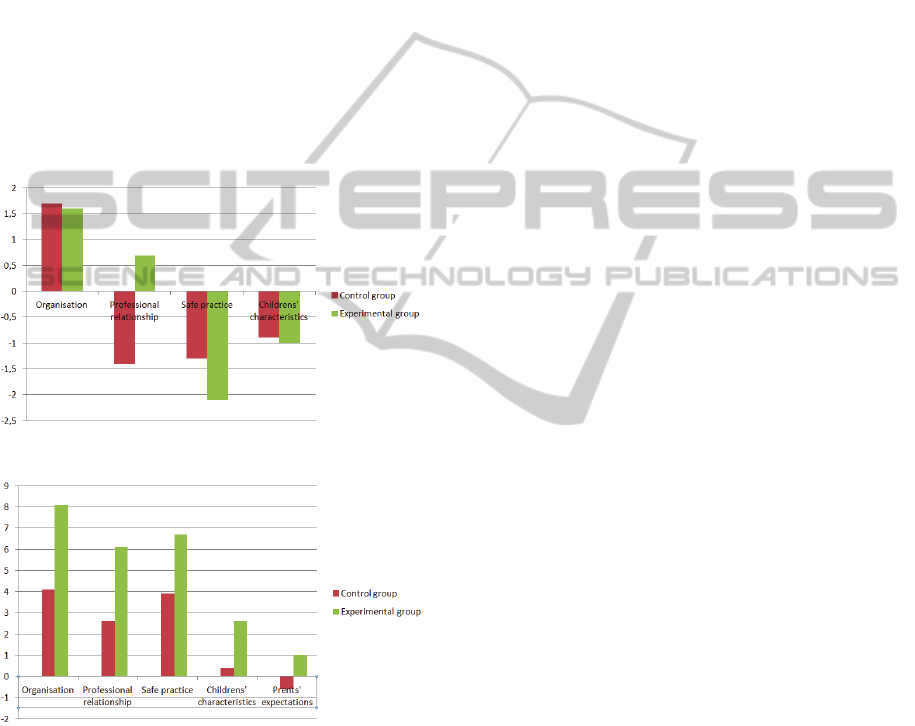
Figure 4: PC evolution (pres test).
Figure 5: PC evolution (post test).
The Figure 1 and 2 summarize some comparison
results between the two groups regarding the evolu-
tion of PC before and after using our system by exper-
imental group and the results of control group, respec-
tively. The results of this experiment show positive ef-
fects after the use of our system for learning skills re-
lated to child safety. If we consider the differences be-
tween the pre-test and post-test results, which means
the learning gain at the end of the training week, posi-
tive tendency appears in the experimental group. This
last gets a larger learning gain for all the criteria and
a significant difference occurs on the ”Safe Practice”
criterion which is fundamental to the child Safety.
The questionnaire shows that learners are very sat-
isfied by using our system to learn. They testified to
the fact that: our system allow them to make errors
without repercussions; that the virtual allow to project
them into the reality; the replay mode allows them to
see their errors, and feedbacks (comments) are useful
to understand these errors in order to not do it again;
our system allows to confront them to various and
changing situations,and to understand new situations
6 CONCLUSIONS
In our work, we proposed a serious game equiped
with a learner tracking and dynamic scenario adapta-
tion system, which allows to: 1) infer the task per-
formed by the learner, 2) determine committed er-
rors and necessary feedbacks (consequences and sce-
nario adaptation), 3) calculate the Performance Crite-
ria, and 4) produce the trace.
Our reference model is tree-based one, which
gives the learner the freedom to choose paths to
achieve his objectives. Furthermore, we added a set
of pedagogical and contextual rules based on the pro-
fessional didactic, which represent key points of our
system. To maintain the motivation of the learner, we
added two concepts: complexity and severity. Dy-
namic adaptation of the complexity allows to learn
concepts in a progressive manner. Thus, the dynamic
adaptation of the severity level allows to prevent con-
sequences and to punish the learner if he committed
this error previously.
For the generation of children’s behaviors, our
system relies on the world state, the complexity and
severity. To allow the learner and the trainer to go
back on what have been done, a replay of the trace of
each session is possible. During this replay, feedbacks
and Performance Criteria are displayed.
ACKNOWLEDGEMENTS
We should like to thank DGCIS which funded this
project; D. Dufour, J. Thiery from UTC, M. Andribet
and trainer of AFPA and C. Le Maitre, K. Guennoun
from Virtuofacto. Our thought is especially dedicated
to Regis Courtalon who unfortunately left us.
SeriousGamebasedonVirtualRealityandArtificialIntelligence
683

REFERENCES
Amokrane, K. and Lourdeaux, D. (2009). Virtual Reality
Contribution to Training and Risk Prevention. In Pro-
ceedings of the International Conference of Artificial
Intelligence (ICAI’09), Las Vegas, Nevada, USA.
Amokrane, K., Lourdeaux, D., Barths, J., and Burkhardts,
J. (2008a). An intelligent tutoring system for train-
ing and learning in a virtual environment for high-risk
sites. In ICTAI 2008: The 20th International Confer-
ence Tools with Artificial Intelligent, pages 185–193,
Dayton, Ohio, USA.
Amokrane, K., Lourdeaux, D., and Burkhardt, J. (2008b).
HERA: Learner Tracking in a Virtual Environment.
International Journal of Virtual Reality, 7(3):23–30.
Amokrane, K., Lourdeaux, D., and Burkhardt, J. (2008c).
Learner Behavior Tracking in a Virtual Environment.
In Proceedings of Virtual Reality International Con-
ference, Laval, France.
Cohen, P., Perrault, C., and Allen, J. (1981). Be-
yond Question-Answering. DTIC Research Report
ADA100432.
Csikszentmihalyi, M. (1991). Flow: The psychology of op-
timal experience. Technical report. Harper Perennial.
Delmas, G., Champagnat, R., and Augeraud, M. (2007).
Plot monitoring for interactive narrative games. In
Proceedings of the international conference on Ad-
vances in computer entertainment technology.
El-Kecha, N. and Desprs, C. (2006). A plan recognition
process, based on a task model, for detecting learner’s
erroneous actions. Intelligent Tutoring Systems ITS,
pages 329–338.
Gerbaud, S., Mollet, N., Ganier, F., Arnaldi, B., and Tis-
seau, J. (2008). Gvt: a platform to create virtual en-
vironments for procedural training. In IEEE Virtual
Reality, Reno, USA. pages 225-232.
Hollnagel, E. (1993). The phenotype of erroneous ac-
tions. International Journal of Man-Machine Studies,
39(1):1–32.
Magerko, B., Wray, R. E., Holt, L. S., and Stensrud, B.
(2005). Improving interactive training through indi-
vidualized content and increased engagement. In Pro-
ceedings of Interservice Industry Training, Simulation
and Education Conference.
Malone, T. (1981). What makes computer games fun?
Technical Report 2.
Marion, N. (2010). Modlisation de scnarios pda-
gogiques pour les environnements de ralit virtuelle
d’apprentissage humain. PhD thesis, European Uni-
versity of Brittany, France.
Mathieu, J., Tannenbaum, S., and Salas, E. (1992). Influ-
ences of individual and situational characteristics on
measures of training effectiveness. Academy of Man-
agement Journal, 35:828–847.
Mollet, N. and Arnaldi, B. (2006). Technologies for E-
Learning and Digital Entertainment, volume 3942,
chapter Storytelling in virtual reality for training.
Springer Berlin Heidelberg, Berlin, Heidelberg.
Niehaus, J., Li, B., and Riedl, M. (2011). Automated sce-
nario adaptation in support of intelligent tutoring sys-
tems. In Murray, R. C. and McCarthy, P. M., edi-
tors, Proceedings of the Twenty-Fourth International
Florida Artificial Intelligence Research Society Con-
ference, Florida. AAAI Press.
Shawver, D. (1997). Virtual actors and avatars in a flexible
user-determined-scenario environment. In Proceed-
ings of the IEEE Virtual Reality Annual International
Symposium, pages 170–171.
Vallerand, R., Fortier, M., and Guay, F. (1997). Self-
determination and persistence in a real-life set-
ting: Toward a motivational model of high school
dropout. Journal of Personality and Social Psychol-
ogy, 72:1161–1176.
van der Veer, G., Lenting, B., and Bergevoet, B. (1996).
GTA: Groupware Task Analysis - modeling complex-
ity. Acta Psychologica, 91(3):297–322.
ICAART2014-InternationalConferenceonAgentsandArtificialIntelligence
684
