
Integrated Measurement for Pre-Fetching in Mobile Environment
Roziyah Darus, Hamidah Ibrahim, Mohamed Othman and Lilly Suryani Affendey
Faculty of Computer Science and Information Technology, University Putra Malaysia, 43400 Serdang, Selangor, Malaysia
Keywords: User Interestingness, Integrated Measurement, Pre-Fetching.
Abstract: Pre-fetching is used to predict next query of data items before any problems occur due to network
congestion, delays, and latency problems. Lately, pre-fetching strategies become more complicated in which
to support new types of application especially for mobile devices. Sometime the pre-fetched data items are
not interested to the users. Due to this complication, an intelligent technique is introduced where an
integrated measurement using data mining with Bayesian approach is proposed to improve the query
performance. In previous study, the pre-fetched data items were filtered using data driven measurement. The
data was generated based on the data frequency metrics whereby the structure of the query pattern is
quantified using statistical methods. The measurement is not good enough to solve sequence query in
mobile environment. In this paper, a new technique is proposed to generate new and potential pre-fetching
set for the users. A subjective measurement is used to determine the pre-fetching set based on user
interestingness. The integrated measurement generates strong and weak association rules based on the data
and user interestingness criterions. The result shows that the performance is significantly improved whereby
the technique managed to quantify the uncertainty of users' expectation in the next possible query.
1 INTRODUCTION
In mobile environment, pre-fetching is very
tremendous in its functions in terms of providing an
effective technique to improve the availability of the
required data items or to predict next possible
queries for users. Pre-fetching process will pre-fetch
the predicted data items from memory into cache
before any miss hit problems occur due to network
congestion, delays, and latency (Hui and Guohong,
2004; Liqiang and Howard, 2006, Liu et al., 2000).
Pre-fetching prevents mobile users from any delay
of on-going job or any potential of terminating job
due to the disconnection problems. The predicted
data items must be useful and really can help users
to react on their advantage. Users will feel confident
towards the pre-fetched data items that can benefit
them in finishing their job successfully especially
during disconnection.
In order to pre-fetch the most useful data items,
an intelligent technique must consider data driven
and user driven criterion (Osmar, 1999). In this
research, both criterions of data interestingness and
user interestingness are used in determining the
predicted data items. User interestingness criterions
will be taking into consideration after data
interestingness criterions is treated. In previous
research (Wang et al., 2002, Hui and Guohong,
2004) the pre-fetched data items were measured
based on data interestingness only. The predicted
data items are depend on the frequently used items
whereby the structure of (A→B) is quantified using
statistical methods. Another word the quantity and
quality of the data items are controlled by data
frequency using support and confidence metrics.
The generated rule from data interestingness is
more concerned on data driven criterion rather than
user driven criterion. The measurement is not good
enough to solve rule quality problems that involve
users as in answering sequence query problem in
mobile environment (Mary et al., 2009). According
to (Hyeoncheol and Eun, 2005), frequency based
measures can generate uninteresting or incorrect
association rules if the dataset includes un-
informative instances.
However, according to (Hampton, Moore &
Thomas, 1973) a combination of human judgements
and Bayes' Theorem will process the information
more effectively than either one alone. An intelligent
technique is used for data prediction in the pre-
fetching process. The association rules in data
mining technique are used to generate the candidate
sets for the pre-fetching sets. By using the objective
measurement, the candidate set is filtered based on
205
Darus R., Ibrahim H., Othman M. and Suryani Affendey L..
Integrated Measurement for Pre-Fetching in Mobile Environment.
DOI: 10.5220/0004989802050212
In Proceedings of 3rd International Conference on Data Management Technologies and Applications (DATA-2014), pages 205-212
ISBN: 978-989-758-035-2
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

strong association rules using support and
confidence metrics. The criterion of the candidate
set is towards data driven in which it considers the
frequent number of items used only rather than the
user involvement in the transaction.
In our approach, the confidence value will be
treated as the prior probability to get the posterior
probability using Bayesian approach. A prior
probability will be assigned as an initial degree of
belief to the users as their general knowledge
towards the transaction. The pre-fetching set will be
generated from an integration of the objective
measurement and the subjective measurement of
data interestingness and user interestingness. In this
research,
we will prove that the integrated
measurement can give better query performance
than the previous work.
2 RELATED WORK
There are many pre-fetching strategies that have
been introduced in previous works. The trend in pre-
fetching strategy started with semi-automated
hoarding set where they rely on user intervention to
some extent (Geoffrey et al., 1997, James and
Mahadev, 1992). Their works were based on
observing past accessed patterns of users and
involved in maintaining the user’s profiles. Another
pre-fetching approach was designed and operated in
specific environment and focused was on semi-
structured data such as for location dependent web
pages and location dependent data services (Ho and
Hwan, 2004; Mariano and Ana, 2006; Shi et al.,
2005).
Lately, with the advancement of mobile
computing technology the pre-fetching techniques in
mobile systems become more complicated in which
to support new types of applications such as in
mobile environments (Shi et al., 2005, Darus and
Ibrahim, 2010, Darus and Ibrahim, 2011). Due to
this complication, researchers started to introduce
new intelligent technique which requires data
mining process (Yucel et al., 2000). Existing
automated pre-fetching techniques did not focus on
the granularity of mobile databases. They focused on
the files such as web pages (Wang et al., 2002, Hui
and Guohong, 2004). The pre-fetching set was
measured by data driven measurement in which the
data generated were based on the frequent data items
in structure of query patterns. The quantity and the
quality of generated data items are controlled by the
support and confidence metric only.
Other researchers concentrated on mining tuples
in a mobile relational DBMS environment, however
their approach can still be further improved to get
optimal solutions (Abhinav, 2005, Li and Lv, 2007).
They also used data driven measurement where the
pre-fetched data items (A→B) were computed based
on support and confidence in which the items are un-
logically related and sometime meaningless for
certain mobile users.
There are many pre-fetching strategies that have
been introduced but from our knowledge, none of
them are concerned on including user interestingness
by using Bayesian approach to contribute additional
criterion for the pre-fetching set.
3 INTEGRATED
MEASUREMENT
By using a-priori algorithm (Agrawal et al., 1993),
an association rule is used to produce an initial
pattern (X
→Y) for data interestingness. A list of
strong rules is generated in which to satisfy certain
threshold for minimum support (min_sup) and
minimum confidence (min_conf) values. The strong
rules in the objective measurement become the
candidate set in determining the potential of pre-
fetching set.
The candidate sets then are treated in the
subjective measurement. According to (Avi &
Alexander, 1996), they represented α, ξ and E as
degree of belief, previous evidence and new
evidence of knowledge in a belief system, B,
respectively. P (α | ξ) is defined as a conditional
probability that α holds, with some previous
evidence ξ supporting that belief. Then we compute
the subjective probability of the users.
Equation (3.1) refers to the confidence values, α
i
,
with previous evidence and will be treated as the
prior probability in the measurement. The
confidence value is assigned as the initial degree of
belief in a belief system concept (Liqiang &
Howard, 2006).
Confidence (α
i
): Initial degree of Belief = d (α
i
| ξ) = P (α | ξ) (3.1)
Equation (3.2) is introduced as a normalized
weighted support values, w
i
, in which to reduce any
bias occur, as in (Hampton, Moore & Thomas,
1973).
Weight: w
i
= Support (α
i
)/Σ Support (α
i
) (3.2)
According to (Liqiang and Howard, 2006), an
DATA2014-3rdInternationalConferenceonDataManagementTechnologiesandApplications
206

equation (3.3) is used in which the weight, w
i
, and
the confidence values are used to find the value of
user interestingness, I (α
i
, B, ξ).
User Interestingness: I (α
i
, B, ξ) = d (α
i
| α
i
’, ξ) -
d (α
i
| ξ) = ǀ Confidence (α
i
’) – Confidence
(α
i
) ǀ = ǀ P (E | α, ξ) - P (α | ξ) ǀ (3.3)
A new degree of belief denoted as P (α| E, ξ) in
which the belief, α is based on the new evidence E in
the context of the old evidence ξ. It can be computed
using Bayes’ rule, as given in equation (3.4).
New degree of Belief: P (α | E, ξ) = P (E |α, ξ) P
(α | ξ) / {P (E | α, ξ) P (α | ξ) + P (E|
¬
α, ξ)
P (
(
¬
α | ξ) (3.4)
An interestingness of pattern p, relative to
previous evidence ξ can be determined by P (α | p, ξ)
whereby it represents the confidence of rule p, given
belief α as in equation (3.5). It also can be defined as
the user interestingness relative to the difference
between the prior and posterior probabilities in the
belief system.
User Interestingness measurement pattern p: I
(p, B, ξ) =
∑
{| P (α | p, ξ) – P (α | ξ) |}
/ P (α | ξ) (3.5)
By taking the confidence values as the initial
degree of belief in a belief system, a new pattern
using user interestingness values, I (α
i
, B, ξ) will be
generated and the patterns for pre-fetching set and
candidate set will be compared and analysed.
Let us consider Table 1 as a sample of online
customer order information. In this example, we
want to show that the pre-fetched items or products
using the integrated measurement really meaningful
for the user.
First, we generate the list of products from Table
1 for the candidate set using a-priori algorithm. We
specify the minimum support value (min_sup) = 4
and the minimum confidence value (min_conf) =
0.5, to produce the list of strong association rules as
in Table 2. A list consists of the most frequently
ordered products which has been filtered using
support and confidence metrics. In this case, the
objective measurement in which the data
interestingness of the products has been considered.
From Table 2, the highest confidence value is for
products
B#3→B#4, i.e. B#3 and B#4. Then it
followed by B#4 and B#5 and so on. It means that
these are the products which are the most frequently
ordered products by the customer. Based on data
interestingness, these are the products that will be
pre-fetched as the pre- fetching set. This approach
has been used in the previous work
Then we extend the previous work by
introducing our approach called integrated
measurement.
After the objective measurement process has been
carried out, a subjective measurement is introduced
to filter according to the user interestingness
products. After the products from the strong rules
are treated for the candidate set, we then treat the
highest confidence value as the initial belief of user
in a belief system for the transaction. This belief is
important in determining the future products to be
ordered by the user. The initial belief represents
general knowledge of ordering behaviour of the
user.
By using equation (3.1) to (3.5), we compute the
results to determine the pre-fetching set from strong
rules as in Table 3. It consists of nine beliefs, in
which support is used to calculate weights for non-
bias values and confidence value is treated as the
initial confidence for each belief.
Table 1: Sample of a Customer Order information.
Cust
_ID
Order_Date Product_Query
Cust
_ID
Order_Date Product_Query
CO1
2-May-07 B#6,B#8,B#16
CO1
3-October-08 B#12
26-May-07 B#4,B#10,B#15,B#20,B#5,B#8 10-November-08 B#2
2-Jun -07 B#2,B#5,B#3 29-Disember-08 B#8,B#6,B#5,B#4
6-Jul-07 B#6,B#9,B#5,B#4,B#25,B#10 27-Jan-09 B#4,B#12,B#6
3-Jan-08 B#2,B#20,B#6 5-Feb-09 B#3
12-Apr-08 B#5,B#4,B#6,B#3,B#15,B#16 12-Apr-09 B#20,B#2,B#8
9-May-08 B#8,B#2,B#15 15-May-09 B#2,B#1
7-Jun-08 B#4,B#25,B#6,B#5 15-Jun-09 B#8,B#3,B#4,B#5,B#2,B#16,B#5
19-July-08 B#16,B#12,B#4,B#20,B#10 11-July-09 B#9
1-August-
08 B#8,B#4,B#15,B#3,B#12,B#2 14-August-09 B#9,B#20,B#4,B#3,B#15,B#1
15-Sept-08 B#8,B#25,B#3,B#4,B#5,B#20 15-September-09 B#9,B#8,B#3,B#5,B#4,B#15
IntegratedMeasurementforPre-FetchinginMobileEnvironment
207

Table 2: Strong Association Rules as the candidate sets.
Strong Rule Expression Support Confidence
B#2→B#8 4 4/8 = 0.5
B#3→B#5 5 5/8 = 0.6
B#3→B#4 - Based on data
interestingness this is the most
interesting products
6 6/8 = 0.8 - Highest confidence value so it becomes the
initial degree of belief of the user
B#3→B#8 4 4/8 = 0.5
B#4→B#5 8 8/12 = 0.7
B#4→B#8 6 6/12 = 0.5
B#4→B#15 6 6/12 = 0.5
B#5→B#6 5 5/9 = 0.6
B#5→B#8 5 5/9 = 0.6
∑ Support (α
i
) 48
Table 3: Computing User Interestingness for Strong Association Rules.
Belief Expression
Weight, w
i
=
Support(α
i
)
/ Σ
Support(α
i
)
Initial
confidence
for each
belief
d (α
i
| ξ) =
P (α
0
| ξ)
Local
confidence,
d (α
i
|α
i’,
ξ) =
P (E
0
|α
0,
ξ)
I (α
i
’, Y, ξ) =
d (α
i
| α
i’,
ξ) -
d (α
i
| ξ) =
ǀ Confidence (α
i
’)
–Confidence (α
i
) ǀ
Interestingness
for each belief
=
w
i
I (α
i
’, Y, ξ)
α
1
B#2→B#8 4/48 = 0.083 4/8 = 0.5 1/3=0.3 (ǀ0.33 – 0.5ǀ) =
0.17
0.01411
α
2
B#3→B#5 5/48 = 0.104 5/8 = 0.6 3/4=0.8 (ǀ0.75 – 0.625ǀ) =
0.125
0.013
α
3
B#3→B#4 6/48 = 0.125 6/8 = 0.8 2/4=0.5 (ǀ0.5– 0.75ǀ) =
0.25
0.03125
α
4
B#3→B#8 4/48 = 0.083 4/8 = 0.5 2/4=0.5 (ǀ0.5– 0.5ǀ) = 0 0
α
5
B#4→B#5 8/48 = 0.167 8/12 = 0.7 4/5=0.8 (ǀ0.8-0.67ǀ) = 0.13 0.02171
α
6
B#4→B#8
Based on user
interestingness,
i.e. the most
interesting
products
6/48 = 0.125 6/12 = 0.5 4/5 = 0.8 (ǀ0.8-0.5ǀ) = 0.3 0.0375 - The
highest
Interestingness
value
α
7
B#4→B#15 6/48 = 0.125 6/12 = 0.5 3/5 = 0.6 (ǀ0.6-0.5ǀ) = 0.1 0.0125
α
8
B#5→B#6 5/48 = 0.104 5/9 = 0.6 1/5 = 0.2 (ǀ0.2-0.56ǀ) = 0.3 0.0312
α
9
B#5→B#8 5/48 = 0.104 5/9 = 0.6 4/5=0.8 (ǀ0.8– 0.556ǀ) =
0.244
0.025376
New Degree of Belief : P (α | E, ξ) = (0.8x0.8) / (0.8x0.8) + (0.2x(1-0.8)) = 0.9412
Relative Interestingness Measurement: I (p, B, ξ) = |0.9412 – 0.8 |/ 0.8 = 0.1765
By referring to the results from Table 3, the new
degree of belief towards the new pre-fetching set
B#4→B#8 with the initial belief for the new evidence
is 94.12%. Products B#4 and B#8 have the highest
interestingness value then followed by B#3 and B#4
and so on.
It means that these are the products which are the
most interesting products to be ordered by the user
based on user interestingness.
The result also shows that, a relative difference
in terms of interestingness measurement of pattern
towards the new pre-fetching set is 17.65%. Then
we also work on the weak association rules. In this
case we want to show that even though there are
products which are not chosen as the candidate set,
but still the products are useful to users.
In this example, we want to identify, what are the
other possible products that can be chosen as the
potential to be the pre-fetching set for the user in
case of insufficient of pre-fetching set. In this case,
we specify lower minimum values for minimum
support and minimum confidence where min_sup =
2 and min_conf = 0.4 from Table 1 to produce a list
of weak association rules as in Table 4. Again, by
using the equation of (3.1) to (3.5), we compute the
results to determine the other possible to be pre-
fetching set from weak rules as in Table 4
DATA2014-3rdInternationalConferenceonDataManagementTechnologiesandApplications
208
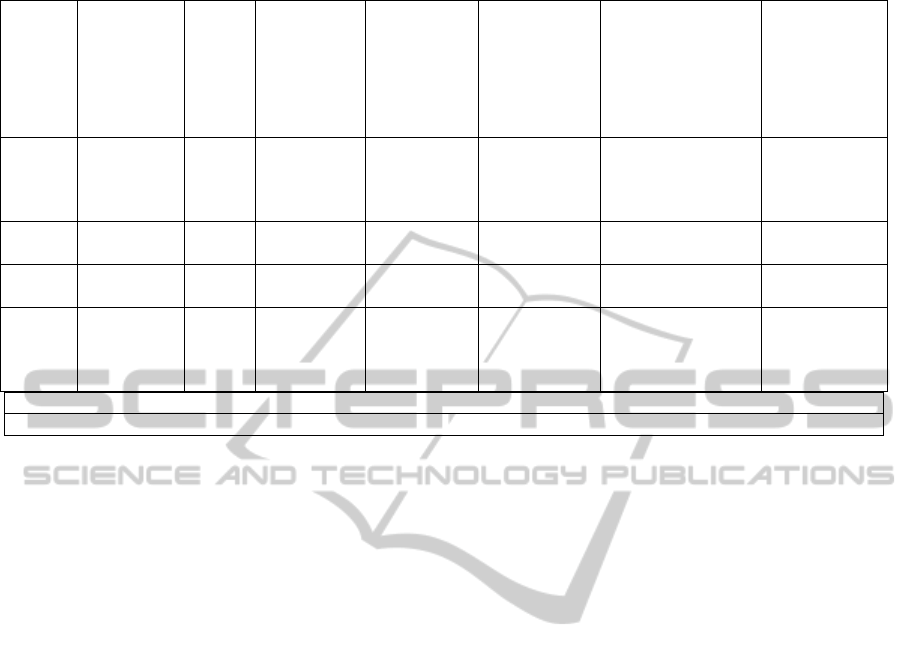
Table 4: The Weak Association Rules - Parameters and their values in a belief system.
Belief
(α
i
)
Rule
Expression
Support
Confidence
value for
each belief,
d (α
i
| ξ) =
P (α
0
| ξ)
Weight, w
i
=
Support (α
i
) /
∑Support (α
i
)
Local
Confidence
for each belief,
d (α
i
| α
i’,
ξ) =
P (E
0
| α
0,
ξ)
I (α
i
, Y, ξ) =
d (α
i
| α
i’,
ξ) -
d (α
i
| ξ) =
ǀ Confidence (α
i
’)
– Confidence (α
i
) ǀ
Interestingne
ss for each
belief =
w
i
I (α
i
’, Y, ξ)
α
1
B#4→B#6 5 5/12=0.421 0.05 4/6 = 0.67 ǀ0.67 – 0.421ǀ =
0.249
0.01245 (The
highest
interestingnes
s value
α
2
B#9→B#1
5
2 2/4=0.5 0.02 2/2 = 1 ǀ1 – 0.5ǀ = 0.5 0.01
α
3
B#9→B#2
0
2 2/4=0.5 0.02 1/2 = 0.5 ǀ0.5 – 0.5ǀ = 0 0
α
4
B#10→B#
20
2 2/3=0.67
(The highest
confidence
value)
0.02 1/1 = 1 ǀ1 – 0.67ǀ = 0.333 0.00666
New Degree of Belief: P (α | E, ξ) = (1x0.67) / (1x0.67) + (0.5x(1-0.67)) = 0.8024
Relative Interestingness Measurement: I (p, B, ξ) = |0.8024 – 0.67 |/ 0.67 = 0. 1976
Based on the results from Table 4, the new
degree of belief towards the new potential to be pre-
fetching set with an initial degree of belief as the
new evidence is 80.2 %. Products B#4 and B#6 have
the highest interestingness value then followed by
B#9 and B#15 and so on. It means that these are
among the products that can be considered as part of
the pre-fetching sets for the user. The relative
difference in terms of Interestingness measurement
pattern towards the new potential to be pre-fetching
set is 19.76%.
In Table 5, we summarize all the pre-fetching set
based on data interestingness and user
interestingness values. First we refer to products
B#4 and B#8 in which these products are very
meaningful from user perspective but not as
meaningful as from data interestingness point of
view. In fact some of the products can be discarded
from the pre-fetching set as in this case we refer to
products B#3 and B#8. These products are
meaningful after the products were treated in
objective measurement but then the products are
meaningless after being treated in subjective
measurement. Lastly, there are many other products
that are not considered as the candidate set, or in
weak association rules, can also be part of the
interesting products and potential to be the pre-
fetching set as for products B#4 and B#6.
4 EXPERIMENTS
We carried out an experiment to identify whether the
pre-fetching set and also the potential to be the pre-
fetching set from strong and weak association rules
can contribute for better query performances. The
integrated measurement is performed by applying
the objective measurement and then the subjective
measurement process. The data set used in the
experiment is taken from TPC-D data schema as in
(Shi et al., 2005). The data set was generated using
random generator given by Transaction Processing
Council, for Decision Making as in the TPC-D
database schema. The data set consists of four main
entities, i.e. regions, nations, customers and
products/items. For analysis purposes we choose a
sample of customers and products from Vietnam.
We treated data region=Asia as global data set and
data nation=Vietnam as local data set.
In this experiment, sequence query pattern is
used as in (Shi, Binshan and Qun, 2005) to identify
the query performance. Comparisons of results by
using pre-fetching set and potential to be the pre-
fetching set from four different cache sizes have
been carried out. We apply the a-priori algorithm
and the equation of (3.1) to equation (3.5) to
generate the pre-fetching set. A sequence query
pattern is used to identify the query performance.
Results are shown in Figure 1 and Figure 2.
IntegratedMeasurementforPre-FetchinginMobileEnvironment
209
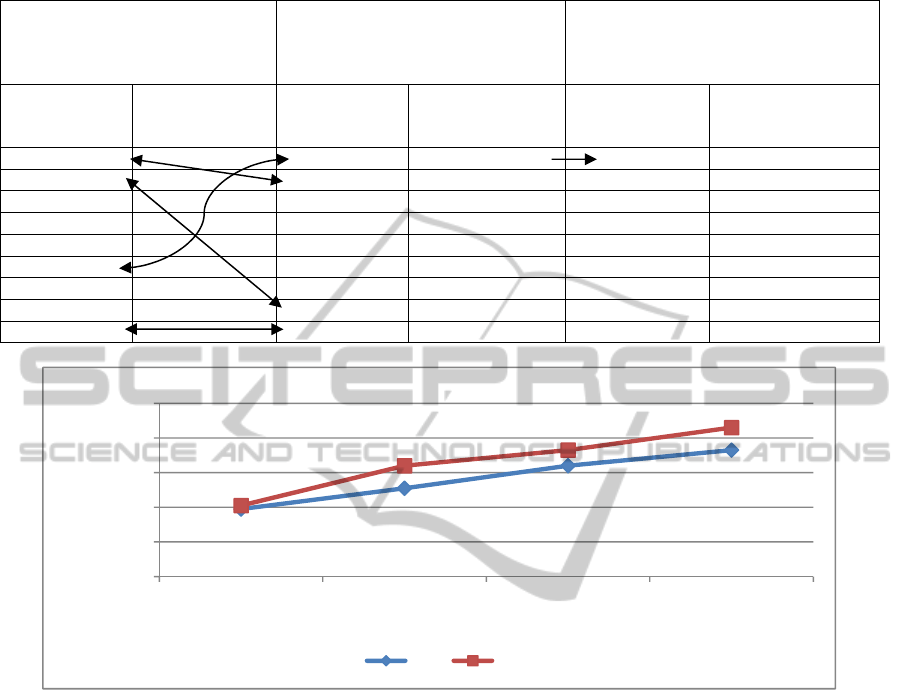
Table 5: Results of Pre-fetching Set using Objective Measurement (OM) and Integrated Measurement (IM) for Strong
Association Rules and Weak Association Rules.
Figure 1: Comparison of Average for Query Performance in Pre-fetching Set from Strong Association Rules between
Objective Measurement (OM) and Integrated Measurement (IM).
5 RESULTS AND DISCUSSION
By using the integrated measurement process, Figure
1 shows that the pre-fetching set from strong rules
contributes a significant difference in query
performance, i.e. by an average of 35%. Even
though the pre-fetched data items are limited in
terms of availability at lower cache size but the pre-
fetched data items are increased tremendously at
higher cache size for the two measurements process.
From the result, it shows that by using IM, the
sequence query pattern performed better than OM
approach.
In Figure 2, the result shows that the pre-
fetching set from weak association rules contributes
slightly difference in query performance, i.e. by an
average of 9.2 % for the two types of measurements.
The pre-fetched data items are limited in terms of
availability at lower cache size compared to higher
cache size in the two measurements process. Again
the results show that by using IM approach, the
sequence pattern query can still performed better
than OM even though from the potential to be pre-
fetching set of weak association rules.
6 CONCLUSIONS
The integrated measurement technique manages to
generate many interesting data items for pre-fetching
set based on user interestingness values. By taking
into consideration the confidence value from data
interestingness as the initial belief of users, we
managed to generate an un-expected pattern for
0,00
20,00
40,00
60,00
80,00
100,00
5% 10% 15% 20%
Cache Hit Ratio (%)
Cache Size
OM IM
Pre-fetching Set from Strong
Association Rules using
Objective Measurement for
Data Interestingness
Pre-fetching Set from Strong
Association Rules using Subjective
Measurement for User
Interestingness
Pre-fetching Set from Weak
Association Rules using Subjective
Measurement for User
Interestingness
Pre-fetching
Set
Confidence
Values, C
Pre-fetching
Set
User
Interestingness
Values, I
Pre-fetching Set
User Interestingness
Values, I
1. B#3→B#4 0.8
1. B#4→B#8 0.038
1. B#4→B#6
0.012
2. B#4→B#5 0.7 2. B#3→B#4 0.031 2. B#9→B#15 0.010
3. B#5→B#6 0.63 3. B#5→B#6 0.031 3. B#2→B#3 0.008
4. B#3→B#5 0.6 4. B#5→B#8 0.025 4. B#10→B#15 0.007
5. B#5→B#8 0.6 5. B#4→B#5 0.022 5. B#10→B#20 0.007
6. B#4→B#8
0.5
6. B#2→B#8 0.014 6. B#4→B#25 0.007
7. B#4→B#15 0.5 7. B#3→B#5 0.013 7. B#3→B#9 0.005
8. B#2→B#8 0.5 8. B#4→B#5 0.013 8. B#4→B#9 0.003
9. B#3→B#8 0.5
9. B#3→B#8
0 9. B#4→B#10 0.003
DATA2014-3rdInternationalConferenceonDataManagementTechnologiesandApplications
210

Figure 2: Comparison of Average for Query Performance in Pre-fetching Set from Weak Association Rules between
Objective Measurement (OM) and Integrated Measurement (IM).
REFERENCES
Abhinav, A. V. 2005. Data Stashing Strategies for
Disconnected and Partially Connected Mobile
Environments. In Doctoral Thesis, RMIT University.
Doi=10.1.1.112.308
Agrawal R., T. Imielinski & A. N. Swami 1993. Mining
Association Rules between Sets of Items in Large
Databases, In Proceedings of the 1993 ACM SIGMOD
Conference, pp. 207–216.Doi>10.1145/170036. 170072
Avi, S. & Alexander,T. (1996). What Makes Patterns
Interesting in Knowledge Discovery Systems. IEEE
Transactions on Knowledge and Data Engineering,
Vol.8, No. 6, pp. 970-974. Doi:10.1109/69.553165
Darus R. & Ibrahim H. 2010. New Prediction Model for
Pre-fetching in Mobile Database. In Proceedings of
the 12th International Conference on Information
Integration and Web-based Applications & Services
(iiWAS), pp. 938-942. Doi>10.1145/1967486.1967653
Darus R. & Ibrahim H. 2011. User Interestingness for Pre-
fetching in Mobile Environment. In Proceedings of the
International Conference on Information Technology
and Multimedia (ICIM), pp. 1-6. Doi:10.1109/
ICIMU.2011.6122738
Geoffrey, H., Kuenning & Gerald, J. P. 1997. Automated
Hoarding for Mobile Computers, SOSP-16 10197
ACM, pp. 264-275. Doi:10.1.1.15.9270
Hampton, J. M., Moore & P. G, Thomas, H. 1973.
Subjective Probability and Its Measurement. In
Journal of the Royal Statistical Society. Series A, Vol.
136, No. 1, pp.21-42. http://links.jstor.org/sici?sici=00
35-238%281973%29136%3AI%3C2I%3ASPAIM%3
E2.0.CO%3B2-P
Ho, S. K. & Hwan, S. Y. 2004. Association Based Pre-
fetching Algorithm in Mobile Environments. In
Proceedings of the International Conference on
Embedded Software and Systems, (ICESS), Springer-
Verlag Berlin Heidelberg, 2005, pp. 243–250.
Doi:10.1007/11535409_34
Hui, S. & Guohong, C. 2004. Cache-Miss-Initiated Pre-
fetch in Mobile Environments. In Proceedings of the
International Conference on Mobile Data Mana-
gement, IEEE. Vol. 28, Issue 7, pp. 741-753. Doi:ieee
computersociety.org/10.1109/MDM.2004.1263086
Hyeoncheol, K. & Eun, Y. K. 2005. Information-Based
Pruning for Interesting Association Rule Mining in the
Item Response Dataset. In Proceedings of the
International Conferences in Knowledge-Based and
Intelligent Engineering & Information Systems (KES
2005), © Springer-Verlag Berlin Heidelberg, pp. 372-
378. Doi:10.1007/11552413_54
James J. K. & Mahadev, S. 1992. Disconnected Operation
in the Coda File System. ACM Transactions on
Computer Systems, Vol. 10, Issue 1, pp. 3-25. Doi=10.
1.1.12.448
Liqiang Geng & Howard J. Hamilton. 2006.
Interestingness Measures for Data Mining: A Survey,
Journal ACM Computing Surveys (CSUR), Vol. 38,
Issue 3, pp.1-32. Doi:1145/1132960.1132963
Li Yi-jun & Lv Ying-jie. 2007. Research on Different
Customer Purchase Pattern Based on Subjective
Interestingness. In Proceedings
of the International
Conference on Management Science & Engineering
(ICMSE 2007), pp. 3-8. Doi:10.1109/ICMSE.2007.
4421816
Liu B., Hsu W., Chen S. & Ma Y. 2000. Analyzing the
Subjective Interestingness of Association Rules. In
Journal Intelligent Systems and their Applications,
IEEE, Sep/Oct 2000, pp. 47-55. Doi:10.
1109/5254.889106
Mariano, C. T. N. & Ana, C. S. 2006. Hoarding and Pre-
fetching for Mobile Databases. In Proceedings of the
5th IEEE/ACIS International Conference on Computer
and Information Science and 1st IEEE/ACIS
International Workshop on Component-Based
Software Engineering, Software Architecture and
Reuse, IEEE, pp. 219-224. Doi:10.1109/ICIS-
COMSAR.2006.44
0,0
20,0
40,0
60,0
80,0
100,0
5% 10% 15% 20%
Cache Hit Ratio (%)
Cache Size
OM IM
IntegratedMeasurementforPre-FetchinginMobileEnvironment
211

Mary, M. J. F., Ilayaraja N. & Nadarajan R. 2009. Cache
Pre-fetch and Replacement with Dual Valid Scopes for
Location Dependent Data in Mobile Environments. In
Proceedings of the 11th International Conference on
Information Integration and web-based Applications
and Services. pp. 364-371. Doi:10.1145/1806338.
1806404
Osmar R. Zaiane, 1999. CMPUT690 Principles of
Knowledge Discovery in Databases.
Shi, M. H., Binshan, L. & Qun, S. D. 2005. Intelligent
Cache Management for Mobile Data Warehouse
Systems. Journal of Database Management, Vol. 16,
No. 2, pp. 46-65. Doi:10.4018/jdm.2005040103
Wang, K., Zhou, S. & Han, J. 2002. Profit Mining: From
Patterns to Actions. In Proceedings of the 8th
Conference on Extending Database Technology, pp.
70–87. Doi=10.1.1.12.7328
Yucel, S., Ozgur. U. & Ahmed, K. E. 2000. Association
Rules for Supporting Hoarding in Mobile Computing
Environments. In Proceedings of the 10
th
International
Workshop on Research Issues in Data Engineering,
IEEE Computing Society Press, pp. 389-401. Doi:ieee
computersociety.org/10.1109/RIDE.2000.836502
DATA2014-3rdInternationalConferenceonDataManagementTechnologiesandApplications
212
