
A Holistic, Semantics-aware Approach to Spatial Data Infrastructures
Cristiano Fugazza, Monica Pepe, Alessandro Oggioni, Fabio Pavesi and Paola Carrara
IREA-CNR, via Bassini 15, 20133 Milano, Italy
Keywords:
Spatial Data Infrastructures, Semantic Web, Marine Research, RDF.
Abstract:
We present a novel approach to the management of Spatial Data Infrastrutures that leverages semantics-aware
context information to model the distinct aspects involved in the management of geospatial data. RDF-based
schemata are employed for encoding information about the user community, the terminologies in use in a
specific research domain, gazetteer information representing the physical landscape underpinning data and,
last but not least, resource metadata. The data structures are then interconnected to enable seamless exploita-
tion for metadata creation and resource discovery, which we demonstrate through a worked-out example of
SPARQL query on RDF graph data. The methodology is being applied by the National Research Council of
Italy (CNR) to support creation of a distributed infrastructure for marine data in the context of the RITMARE
Flagship Project.
1 INTRODUCTION
Spatial Data Infrastructures (SDIs) represent one of
the most challenging areas in data management. In
fact, the variety of data and metadata formats, the dif-
ferent workflows in use, and the manifold expecta-
tions from the user community make it difficult to ap-
ply widely acknowledged design patterns. Moreover,
the ever-changing landscape of data sources - think of
the emergence of sensor data (Na and Priest, 2007) -
and the evolution of data access methodologies - e.g.
the Linked Open Data (LOD) movement (Dodds and
Davis, 2012) - prevent data management practices to
easily coalesce into generally applicable standards.
Recourse to semantics in the management of
geospatial data is typically intended to address het-
erogeneity in resource description, to achieve multi-
lingualism in resource discovery functionalities, and
in general to compensate for the lack of the effi-
cient search paradigms of generalized information re-
trieval. However, no existing infrastructure employs
semantics as the trait d’union between the distinct
components of the context information involved in
SDIs. Also, no state-of-the-art solution applies this
approach throughout the life cycle of geospatial in-
formation, from metadata production to resource re-
trieval. Instead, it is our opinion that only by adopt-
ing an all-round approach encompassing all the as-
pects of SDIs it is possible to fully exploit the po-
tential of the expressive descriptions enabled by on-
tologies, thesauri, and RDF-based data structures in
general
1
.
With this in mind, IREA-CNR
2
tackled the chal-
lenge of providing an infrastructure to the RITMARE
Flagship Project
3
, which aims at bringing all the dis-
tinct contributions to Italian marine research under the
same umbrella. In doing this, RDF-based data struc-
tures are exploited to model the distinct aspects of
the SDI. These range from the categorization of re-
searchers and institutions involved in the project to the
collection of the terminologies in use by the distinct
communities; from the organization of a gazetteer
system supporting geospatial information retrieval to
the encoding of metadata as Linked Data records. The
latter component will contribute to the LOD cloud
4
with a “bubble” constituted by the metadata collected
by RITMARE.
In this paper, we report on the activities that are
carried out for the establishment of the RITMARE
infrastructure with regard to semantics. Section 2
describes the project’s generalities and presents some
related work that is relevant to our research. Section 3
describes the RDF-based data structures that support
the front- and back-office functionalities of the infras-
1
Resource Description Framework: http://www.w3.org/
RDF/
2
Institute for Electromagnetic Sensing of the Environ-
ment - National Research Council of Italy: http://irea.cnr.it/
3
RITMARE (Ricerca ITaliana per il MARE - Italian re-
search for the sea): http://www.ritmare.it/
4
Linked Open Data cloud: http://lod-cloud.net/
349
Fugazza C., Pepe M., Oggioni A., Pavesi F. and Carrara P..
A Holistic, Semantics-aware Approach to Spatial Data Infrastructures.
DOI: 10.5220/0004997603490356
In Proceedings of 3rd International Conference on Data Management Technologies and Applications (DATA-2014), pages 349-356
ISBN: 978-989-758-035-2
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

tructure. Section 4 provides a preliminary eval-
uation of the approach that is presented. Finally,
Section 5 draws conclusions and outlines future
work.
2 CONTEXT
The building of the data sharing infrastructure in RIT-
MARE (a Flagship Project by the Italian Ministero
dell’Istruzione, dell’Universit
`
a e della Ricerca) re-
quires integration of all state-of-the-art contributions
to Italian marine research into a coherent SDI. A
coarse-grained categorization of SDIs distinguishes
between centralized and decentralized infrastructures,
according to whether data and metadata is stored in
a single repository or distributed among the distinct
data providers. The RITMARE infrastructure belongs
to the second kind, featuring:
• a set of peripheral nodes that expose standards-
compliant metadata and services;
• a centralized catalog service that provides a single
point of access to the resources made available by
the project as a whole.
The project involves a heterogeneous set of data
providers (public research bodies and inter-university
consortia) as well as a variety of stakeholders (pub-
lic administrations, private companies, and citizens).
These entities envisage a varied corpus of heteroge-
neous data, metadata, workflows, and requirements.
Besides this, data providers feature different degrees
of maturity with regard to the provisioning of re-
sources according to the mandated standards. In fact,
the RITMARE SDI is bound to the requirements set
by the INSPIRE (INfrastructure for SPatial InfoR-
mation in Europe) Directive (European Commission,
2007), as well as by RNDT
5
, the Italian enforcement
of the former.
The development activity can be roughly divided
into three incremental phases. The first one consists
of empowering the data providers with standards-
compliant services for the provisioning of geospatial
data. This has been achieved by providing a virtual
appliance, a “starter kit” (Fugazza et al., 2014), that
is capable of kickstarting an autonomous node in the
SDI for the collection, annotation, and deployment of
both geographic and sensor data. The data sources
that already expose standard services will be inte-
grated in the second phase. Finally, the third phase
will consist of the building of the centralized portal
5
Repertorio Nationale dei Dati Territoriali:
http://www.rndt.gov.it
integrating the distinct peripheral nodes and exposing
the metadata records as Linked Data.
In the first two phases, the data structures de-
scribed in this work allow to weave into the workflow
for resource registration advanced functionalities for
the enrichment of metadata. In the third phase, the
centralized repository will exploit them for articulat-
ing resource discovery in a more effective way as re-
gards to existing geoportals (the front-end of SDIs).
2.1 Related Framework
INSPIRE-compliant, XML-based metadata and
OGC-based services (European Commission, 2008;
IOC Task Force for Network Services, 2011a; Initial
Operating Capability Task Force, 2012; IOC Task
Force for Network Services, 2011b) seem to find it
hard to keep pace with more recent LOD initiatives,
even those sponsored by the EU itself, such as its
Open Data Portal
6
. However, an extension to the
DCAT
7
application profile for data portals in Europe
(European Commission, 2013) is expected to ease
transition to RDF-based metadata representation
for INSPIRE metadata. The paper (Fugazza and
Luraschi, 2012) proposes an indexing process for
INSPIRE metadata based on SKOS thesauri. The
methodology is applied to harvested metadata records
and hence is likely to be error-prone, while our ap-
proach in this worst-case scenario (that is, when
harvesting metadata from existing infrastructures)
envisages supervised amelioration of metadata in
order to obtain RNDT-compliant metadata, providing
a more reliable indexing as by-product.
In extra-European contexts, such as the GEO Sys-
tem of Systems
8
, semantics is intended as the primary
means to overcome the generalized hetereogeneity of
formats (Khalsa et al., 2007; Nativi et al., 2011). In
particular, in (Santoro et al., 2012) the authors pro-
pose a query expansion mechanism that is applied to
the search string entered by the user, rather than to
the metadata records themselves. On the one hand,
this approach is valuable because it is applicable when
metadata records are not known in advance. On the
other hand, precision and recall in discovery is in-
evitably hampered by the scarce information associ-
ated with the user executing the search (e.g., the lan-
guage the query is expressed in is not known in ad-
vance).
Another important issue that we wanted to address
is the inclusion in our marine infrastructure of Sen-
6
EU Open Data Portal: https://open-data.europa.eu
7
Data Catalog Vocabulary (DCAT): http://www.w3.org/
TR/vocab-dcat/
8
GEOSS: https://www.earthobservations.org/geoss.shtml
DATA2014-3rdInternationalConferenceonDataManagementTechnologiesandApplications
350

sor Web Enablement
9
(SWE) functionalities, partic-
ularly the Sensor Observation Service (SOS) com-
ponent (Oggioni et al., 2014; Jiang et al., 2013).
Ontology-based representation of sensors and obser-
vations is featuring noteworthy results, as in (Bar-
naghia et al., 2011; Compton et al., 2012; Wang,
2012; Taylor et al., 2011; Taylor and Leidinger,
2011), that are inspiring our approach to the rep-
resentation of this category of data sources within
our RDF-based SDI. However, the challenge of har-
monizing sensor networks, particularly observations
(that is, the actual data produced by sensors), with tra-
ditional geographic data remains. Ideally, one should
transparently access sensor data alongside the other
categories of geospatial data and exploit the specifici-
ties, characteristics, and history of sensors (e.g. mea-
sured parameters, gain, accurancy, offset, calibration
features) when needed. Instead, Sensor Web devel-
opment relies on specific standards and practices that
make it difficult to achieve this degree of integration
(Havlik et al., 2011).
3 THE RITMARE LOD BUBBLE
Figure 1 depicts the individual components of the
RDF data structures that are being populated for de-
veloping the RITMARE infrastructure. The size of
each circle is proportional to the expected number of
entities in each data structure. Also, in order to exploit
these data structures in a seamless way, it is neces-
sary to provide the appropriate relations between en-
tities from distinct schemata. The following of this
Section will describe the specificities of the individ-
ual components with regard to i) the schemata that
are employed, ii) the data that are stored, and iii) the
relations that are created for connecting the distinct
domains. Section 3.5 provides some implementation
details on the two data bases that are conjunctively
employed. Finally, Section 3.6 describes an actual
discovery scenario, which is a worked-out example of
geospatial query interrogating all the data structures
to obtain a list of prospective results.
3.1 Project Description
Researchers and institutions involved in the project
are modeled as Friend Of A Friend (FOAF) data struc-
tures
10
. The rationale for this approach is the follow-
ing: Firstly, FOAF is a widely-acknowledged data
9
Sensor Web Enablement: http://www.opengeospatial.org/
ogc/markets-technologies/swe
10
FOAF Vocabulary Specification 0.99: http://xmlns.com/
foaf/spec/
format for establishing a Web of Trust among the
participants to the project. Also, FOAF descriptions
can refer to terms in controlled vocabularies repre-
senting the research field of individual persons and
whole institutions: As an example, Figure 1 shows
the FOAF entity corresponding to researcher “Mon-
ica Pepe” linked to the SKOS concept corresponding
to “Geophysics” by property topic interest from the
FOAF vocabulary. This semantic link is the primary
means we adopted to provide advanced metadata cre-
ation functionalities, enable profiled discovery of re-
sources, and tailor the selection of components to be
included in the infrastructure’s geoportal on the user’s
specificities.
The categorization of the entities involved in RIT-
MARE has been derived from documents provided
by the administration of the project as a spreadsheet.
The documents have been exported as XML and pro-
cessed with an XSLT stylesheet in order to obtain the
raw RDF/XML data structures. In this phase, human
supervision was required in order to prune duplicate
individuals, remove typos, etc. Finally, the workflow
for creating links between FOAF entities and terms of
the knowledge base is twofold: For testing purposes,
an ad-hoc backoffice application has been created; in-
stead, when the centralized geoportal will be avail-
able, the research field associated with a given indi-
vidual will be one of the preferences that the user can
specify and modify.
3.2 Knowledge Base
The second component is constituted by a collection
of terminologies in the SKOS format. These include
the multilingual codelists that are employed in the cre-
ation of INSPIRE- and RNDT-compliant metadata,
a selection of thesauri whose terms can be used as
keywords, and the categorization of the RITMARE
research areas. An activity that may be required in
the future is the harmonization of distinct controlled
vocabularies, that is, the drawing of correspondences
between related terms in independent terminologies.
For instance, in Figure 1 the SKOS concepts corre-
sponding to “Elevation” and “Altitude” are related to
each other by semantic property closeMatch from the
SKOS ontology. This aspect is a fundamental en-
abling factor for query expansion functionalities that,
given the inter-disciplinary vocation of RITMARE,
may be an important component for the usability of
the infrastructure.
Whenever a suitable SKOS representation is avail-
able, thesauri have been downloaded from the author-
itative sources and inserted in the knowledge base
with little or no modification. Instead, most of the
AHolistic,Semantics-awareApproachtoSpatialDataInfrastructures
351
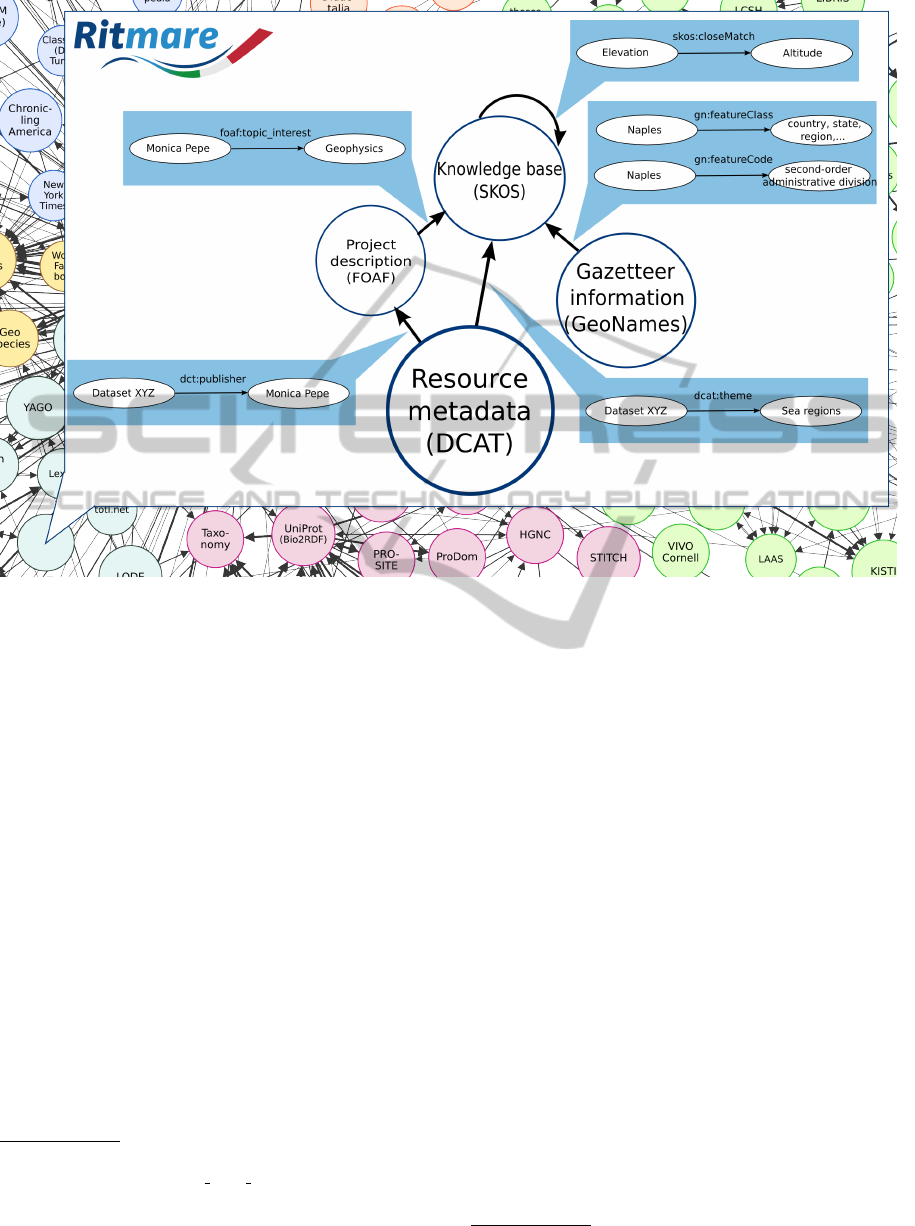
Figure 1: Components of the RITMARE LOD bubble.
codelists that are used in INSPIRE metadata had to
be created from scratch by referring to INSPIRE and
ISO documentation. The same for the list of research
fields in RITMARE. As for the selection of thesauri
to be supported for keyword selection, consultation
with domain experts inside and outside of the project
recommended some of the thesauri provided by Sea-
DataNet
11
(particularly, those categorizing observa-
tion parameters, units of measure, sensor platforms,
and sensor instruments) and the GCMD Science Key-
words
12
provided by NASA. We deliberately avoided
including some thesauri that are typically used in the
geospatial domain, such as GEMET
13
, as they were
deemed as too general by this specific user commu-
nity. However, since referring to thesauri is a fun-
damental component in RITMARE metadata, we en-
courage the project partners to provide feedback on
new terminologies to be included in the knowledge
base.
11
SeaDataNet BODC webservices:
http://seadatanet.maris2.nl/v bodc vocab/welcome.aspx
12
Global Change Master Directory: http://gcmd.nasa.gov/
13
GEneral Multilingual Environmental Thesaurus:
http://www.eionet.europa.eu/gemet/
3.3 Gazetteer Information
Another adopted data structure is a fine-grained rep-
resentation of the geographic features that may be re-
ferred to in user queries. For the time being, we only
included some of the toponyms provided by GeoN-
ames
14
in order to be able to express query patterns
like “100km West of Naples” and reduce recourse to
maps, bounding boxes, and other widgets that typi-
cally distinguish geographic data discovery from gen-
eralized search. Gazetteer data structures are already
referring to controlled vocabularies, also included in
the knowledge base, for categorizing toponyms. As
an example, Figure 1 shows two SKOS concepts (de-
scribed by literals “country, state, region, ...” and
“second-order administrative division”) that are re-
ferred to by the toponym corresponding to “Naples”
as values for, respectively, properties featureClass
and featureCode defined by the GeoNames ontology.
In the future, it is possible that the GeoNames on-
tology could be complemented by (or directly repur-
posed for expressing) a custom RITMARE maritime
gazetteer.
The GeoNames RDF dump (around 3GB) is too
large for direct usage and too large for DOM and
14
GeoNames: http://www.geonames.org/
DATA2014-3rdInternationalConferenceonDataManagementTechnologiesandApplications
352

XSLT processing tools. We then developed a Python
script that extracted from the original file the Italian
toponyms. The thesaurus categorizing GeoNames’
toponyms also allowed to prune the toponyms that
were clearly of no interest to the project (e.g., those
corresponding to hotels, parks, etc.) so that the data
actually inserted in the triple store was just around
50MB.
3.4 Resource Metadata
Finally, the largest proportion of the RDF data em-
ployed by the RITMARE infrastracture is constituted
by resource metadata harvested from the peripheral
nodes. For their encoding, we rely on the Data Cat-
alog Vocabulary (DCAT) and its profile tailored on
the requirements of the EU Open Data Portal. Un-
til a proper extension for expressing INSPIRE meta-
data is made available, we rely on the RDF repre-
sentation of ISO 19115 metadata provided by the
Australian CSIRO
15
. In the example in Figure 1, the
dataset “Dataset XYZ” has been related to the IN-
SPIRE Theme “Sea regions” and to the publisher
“Monica Pepe” by properties theme and publisher
from the DCAT vocabulary, respectively.
The enrichment of metadata records may follow
two distinct directions; in both cases, we essen-
tially annotate metadata items with the identifiers (the
URIs) of the RDF entities described above. When
these entities are already provided by sources in the
LOD cloud (e.g., GeoNames toponyms), they refer to
the corresponding Linked Data structures. The meta-
data produced via the tool that we developed in the
first phase of the project (see Section 2) already con-
tain this information. Otherwise, when metadata is
harvested from an existing data source, indexing tech-
niques will be applied to complement the language-
dependent textual descriptions with the corresponding
language-neutral identifiers.
3.5 Implementation Details
The first three components that are described above
are stored in an instance of the Virtuoso Universal
Server
16
(although only the triple store capabilities
are employed). This platform provides all the func-
tionalities that are required for the management of
RDF data and is accessed by the distinct components
of the architecture through the SPARQL
17
endpoint
15
ISO 19115 RDF representation:
http://def.seegrid.csiro.au/static/isotc211/iso19115/2003/
16
Virtuoso: http://virtuoso.openlinksw.com/
17
SPARQL Protocol And RDF Query Language:
http://www.w3.org/TR/rdf-sparql-protocol/
that is provided. The choice of the solution to be used
for the deployment of the fourth component, the meta-
data of the resources aggregated by the infrastructure,
is currently not definitive. For the time being, we are
evaluating CKAN
18
, the mainstream solution for the
implementation of open-data portals. Besides sup-
port for the provision of resource metadata as Linked
Data, this platform natively exploits the DCAT meta-
data format, which is the basis for the RDF-based re-
source description that we employ.
The motivations for using two distinct platforms
are manifold. Firstly, Virtuoso offers a wide set of
tools specifically aimed at database administration
and this feature has been dramatically important in
the beginning of the project, when multiple schemata,
thesauri, and prospective data representations were
evaluated. On the other hand, CKAN may constitute a
more scalable solution for the category of data that is
likely to grow in size, that is, resource metadata. Sec-
ondly, the distinct components may feature a different
status with regard to access control or authoritative-
ness of the source. For instance, user details involve
privacy issues that we wanted to keep under control.
Also, some components that constitute the knowledge
base (say, the SeaDataNet thesauri) already have their
authoritative sources and then providing them through
a second endpoint would be redundant. Finally, in
the future, some components of the context informa-
tion described in this Section, such as thesauri and
code lists, could be drawn directly from the respec-
tive SPARQL endpoints or Linked Data facilities. For
the time being, these data structures are materialized
in the local repository for performance and direct con-
trol.
3.6 Worked-out Example
The combined expressiveness of the four components
described above support the discovery capabilities ex-
emplified in this Section, in which the metadata cat-
alog is interrogated by means of the SPARQL query
language. Queries are composed on the basis of pa-
rameters specified by the user through a discovery in-
terface (a web form) hinged on four elements:
WHO: This parameter is used for ranking results ac-
cording to the properties topic interest that are
specified for a given researcher (if authenticated).
The effect of this parameter is otherwise transpar-
ent to the end user.
WHAT: Describes the observation parameter of in-
terest to the user. When no match is found in the
18
CKAN The open source data portal software:
http://ckan.org/
AHolistic,Semantics-awareApproachtoSpatialDataInfrastructures
353

Listing 1: Example of SPARQL query for discovery of datasets.
1 PREFIX foaf : < http :// xmlns . com / foaf /0.1/ >
2 PREFIX vcrd : < http :// www . w3 . org / 2 0 0 6 / vcard / ns #>
3 PREFIX skos : < htt p :// w ww . w3 . org / 2 0 0 4/ 0 2 / s kos / co re # >
4 PREFIX dcat : < htt p :// w ww . w3 . org / ns / dc at # >
5 PREFIX dtc : < h t tp :// purl . org / dc / te rms / >
6 PREFIX ext : < h t tp :// def . s e e g r id . c s iro . au / isotc2 1 1 / i so 1 9 1 15 / 2 0 0 3 / extent # >
7
8 SELECT ? da t as e t ? title ? abstra c t
9 WH E R E {
10 ? dataset r df : type d cat : Datas e t ;
11 dct : tit l e ? title ;
12 dct : d e s c ri pt i on ? a b st r a c t ;
13 dca t : theme < http : // vocab . ner c . ac . uk / col l e c ti o n / P02 / c u r r e nt / PSAL /> ;
14 dca t : p u bl i s he r ? p ub l i sh e r .
15 ? publ i s h er vcrd : org < ht t p :// ri t m a r e . it / rd f d a ta / p r o je c t # ISMAR > .
16 {
17 ? dataset ext : s p a t ia lE xt en t ? bbox .
18 ? bb ox ext : no r th Bo un dLa t i tu de ? nl at ;
19 ext : s o ut hB ou ndL a t it ude ? sla t ;
20 ext : w e st Bo un dLo n g it ude ? wlong ;
21 ext : e a st Bo un dLo n g it ude ? elong .
22 FILTER ( (? nl at > 4 0. 9 6 4 2) && (? s lat < 4 0 .8 5 2 8 ) &&
23 (? w l o n g > 13.15 7 3 ) && (? e l o n g < 12.95 6 7 ) )
24 }
25 }
related controlled vocabulary, a free-text search is
triggered by the application.
WHERE: Specifies the geographic context of the
search as a free-text parameter to be interpreted
by the application.
WHEN: Determines the temporal extent of interest
to the user.
Also, the user is given the option to refine the search
parameters by specifying facet values for some meta-
data items. These are the fields whose possible values
are known in advance (such as the INSPIRE Theme,
the topic category, the language used in metadata,
etc.) or that can be statically computed and clustered.
In the example, the user has selected, in a text field
that is autocompleted by leveraging the SeaDataNet
thesaurus for observation parameters, the term corre-
sponding to “Salinity of the water column”. She also
specified the free-text value “100km west of Naples”
as the geographic location of interest. It is up to the
application to guess (in a Google Maps-style) the dis-
tance, direction, and origin expressed in the text field.
Moreover, she also selected, among the data providers
in project RITMARE, the facet value corresponding
to the “ISMAR” institute.
Executing SPARQL queries amounts to searching
the graph data whose components have been intro-
duced in Section 3 for triple patterns. These are se-
quences of subject-property-object patterns (subjects
and objects like the ellipses in Figure 1, the proper-
ties like the directed arcs) inducing a graph that can
then be matched against the data graph. User queries
are translated into SPARQL queries: In particular, the
parameters described above translate into Listing 1.
The explanation of the listing is the following.
Lines 1-6 define namespace prefixes that allow to
shorten the triple patterns in the listing. Namely, the
prefixes identify the namespaces of the following vo-
cabularies: FOAF, vCard (used in FOAF), SKOS,
DCAT, and Dublin Core Terms (used in DCAT). Also,
prefix ext identifies the data structures that compen-
sate for the lack of proper DCAT data structures for
expressing some INSPIRE metadata items. The SE-
LECT clause on line 8 defines the three variables that
shall be returned by the query, that is, the URI, ti-
tle, and abstract of the resources matching the query.
The WHERE clause defines the triple patterns that are
searched in the RDF data structures of RITMARE and
which data shall be bound to variables. Lines 10-12
retrieve the data requested in the projection clause on
line 8, while lines 13-15 is where the actual match-
ing starts. Specifically, the first line matches metadata
records that are related to the observation parameter
that has been requested by the user. The remaining
two require that the point of contact that is provided
for data belongs to the institute that has been selected
by the user for the corresponding facet.
Finally, lines 17-23 express the tricky part of the
query, that is, the matching of the bounding box spec-
ified by the user with the free-text parameter “100km
DATA2014-3rdInternationalConferenceonDataManagementTechnologiesandApplications
354

west of Naples”. Here, the geographic coordinates
corresponding to Naples (40.88333N, 14.41667E ac-
cording to the toponym specified by GeoNames) are
applied the offset corresponding to 100km westwise
(obtaining 40.90802N, 13.05750E). Then, a bound-
ing box has been computed from this position (the
four values in the FILTER clause on lines 22 and 23
of Listing 1). Here, we assume that the user is fine
with the default dimensions of the bounding box pro-
vided by the discovery application, 16km wide and
11km high. The (possibly multiple) geographic ex-
tents of each candidate dataset are matched against
the search bounding box. Here, we assume the more
conservative approach, requiring the latter to be fully
contained in the former. However, a range of different
interpretations are possible. Particularly, in the future
we will aim at providing the user with the capability
of modulating the degreee of overlapping of bounding
boxes according to the number of results that would
be returned by the query.
4 DISCUSSION
In the current phase of the project, when the cen-
tralized geoportal is still work in progress, an overall
evaluation of the proposed solution is not easy. How-
ever, we are already collecting feedback on the ca-
pacity building of data providers envisaged in the first
phase of the project (see Section 2), that is, we can
report on the efficacy of our “starter kit”. In particu-
lar, we can evaluate the features that we are providing
for the assisted editing of metadata, which are heav-
ily dependent on the data structures described in this
paper.
With respect to these, recourse to the RDF data
structures presented in Section 3 allows to dramati-
cally reduce the number of the data items to be ac-
tually provided by the user. As an example, the
RNDT specification is featuring 34 mandatory meta-
data items, too high a number for an accurate editing
of metadata records. Moreover, some of these, such as
the 4 distinct contact points to be provided, are com-
posite items that require more than one value to be
entered by the user. Instead, by combining i) the auto-
matic assignment of metadata items, ii) the provision
of default values extracted from the dataset itself, and
iii) the exploitation of the RDF information described
in this paper, the number of required values can be
narrowed down to 10.
Particularly, by referring to the project structure,
the editing interface is capable of providing data
items that are otherwise tedious to provide or error-
prone. Also, autocompleting keywords from the se-
lected thesauri configures a win-win situation where
the user is relieved of the burden of writing key-
words in their entirety and the application is capable
of associating unique identifiers with the keywords
that are provided. These advanced editing capabili-
ties can be applied to generic metadata schemata en-
coded as XML. In fact, we currently support the edit-
ing of sensor metadata in the SensorML format with
the same autocompletion facilities of RNDT meta-
data. Also, support for sensor metadata in the alterna-
tive *FL (Starfish Fungus Language) format (Simonis
and Malewski, 2011) is under testing.
5 CONCLUSIONS
This work presents our approach to semantic charac-
terization of the data structures that are involved in
the management of SDIs. We believe that, by creating
the appropriate relations between data items encoded
according to the heterogeneous RDF schemata pre-
sented in Section 3, it is possible to provide end users
with advanced functionalities. These span from back-
to front-office capabilities, from metadata creation by
the peripheral nodes of the RITMARE infrastructure
to resource discovery by the centralized catalog, and
permeate the whole life cycle of geospatial resources
as semantic annotations to INSPIRE-compliant meta-
data.
The proposed methodology is supporting the de-
velopment of the user-oriented infrastructure of the
RITMARE Flagship Project and constitutes the first
example of decentralized management of Italian ma-
rine research data. The novelty of the approach also
resides in the all-round application of semantics in
the modeling of the data structures that describe re-
sources, end users, research fields, and physical lo-
cations. The example provided in Section 3.6 only
scratches the surface of the possible applications of
this multi-tiered knowledge base in the enactment of
Spatial Data Infrastructures.
ACKNOWLEDGEMENTS
The activities described in this paper have been
funded by the Italian Flagship Project RITMARE.
REFERENCES
Barnaghia, P., Ganza, F., and Abangara, H. (2011).
Sense2Web: A Linked Data Platform for Semantic
AHolistic,Semantics-awareApproachtoSpatialDataInfrastructures
355

Sensor Networks. semantic-web-journal.net, 0(0):1–
11.
Compton, M., Barnaghi, P., Bermudez, L., Garca-Castro,
R., Corcho, O., Cox, S., Graybeal, J., Hauswirth, M.,
Henson, C., Herzog, A., Huang, V., Janowicz, K.,
Kelsey, W. D., Phuoc, D. L., Lefort, L., Leggieri,
M., Neuhaus, H., Nikolov, A., Page, K., Passant, A.,
Sheth, A., and Taylor, K. (2012). The SSN ontology
of the W3C semantic sensor network incubator group.
Web Semantics: Science, Services and Agents on the
World Wide Web, 17(0):25 – 32.
Dodds, L. and Davis, I. (2012). Linked Data Patterns,
http://patterns.dataincubator.org/book/.
European Commission (2007). “Establishing an Infrastruc-
ture for Spatial Information in the European Commu-
nity (INSPIRE)” Directive 2007/2/EC.
European Commission (2008). Commission regulation
(EC) no 1205/2008 of 3 December 2008 implement-
ing Directive 2007/2/ec of the European Parliament
and of the Council as regards metadata.
European Commission (2013). DCAT Appli-
cation Profile for data portals in europe,
https://joinup.ec.europa.eu/asset/dcat application pro
file/home.
Fugazza, C. and Luraschi, G. (2012). Semantics-Aware
Indexing of Geospatial Resources Based on Multilin-
gual Thesauri : Methodology and Preliminary Results.
International Journal of Spatial Data Infrastructures
Research, 7:16–37.
Fugazza, C., Menegon, S., Pepe, M., Oggioni, A., and Car-
rara, P. (2014). The RITMARE Starter Kit: Bottom-
up capacity building for geospatial data providers. In
9th International Conference on Software Paradigm
Trends (ICSOFT-PT).
Havlik, D., Schade, S., Sabeur, Z. a., Mazzetti, P., Watson,
K., Berre, A. J., and Mon, J. L. (2011). From Sen-
sor to Observation Web with environmental enablers
in the Future Internet. Sensors (Basel, Switzerland),
11(4):3874–3907.
Initial Operating Capability Task Force (2012). Technical
guidance for the implementation of inspire download
services.
IOC Task Force for Network Services (2011a). Technical
guidance for the implementation of inspire discovery
services.
IOC Task Force for Network Services (2011b). Technical
guidance for the implementation of inspire view ser-
vices.
Jiang, Y., Guo, Z., Hu, K., Shen, F., and Hong, F. (2013).
Using Sensor Web to Sharing Data of Ocean Observ-
ing Systems. In Wang, R. and Xiao, F., editors, Ad-
vances in Wireless Sensor Networks, pages 137–156.
Springer-Verlag Berlin Heidelberg, Berlin Heideberg.
Khalsa, S. J. S., Nativi, S., Ahern, T., Shibasaki, R., and
Thomas, D. (2007). The GEOSS interoperability pro-
cess pilot project. In IGARSS, pages 293–296.
Na, A. and Priest, M. (2007). OGC Sensor Observation
Service (OGC 06-009r6). OpenGIS Implementation
Standard.
Nativi, S., Craglia, M., Vaccari, L., Santoro, M., and
Fugazza, C. (2011). Searching the New Grail: Inter-
Disciplinary Interoperability. In Claramunt, C., Lev-
ashkin, S., and Bertolotto, M., editors, GeoSpatial Se-
mantics, Proceedings of the 4th International Confer-
ence, Geos 2011, number 1, pages 1–15. Springer-
Verlag.
Oggioni, A., Bastianini, M., Carrara, P., Minuzzo, T., and
Pavesi, F. (2014). Sensing Real-time Observatories
in Marine Sites A Proof-of-Concept. In SensorNets
2014, 3rd International Conference on Sensor Net-
works, pages 111–118, Lisbon Portugal 7-9 January
2014.
Santoro, M., Mazzetti, P., Nativi, S., Fugazza, C., Granell,
C., and D
´
ıaz, L. (2012). Methodologies for aug-
mented discovery of geospatial resources. In D
´
ıaz,
L., Granell, C., and Huerta, J., editors, Discovery of
Geospatial Resources: Methodologies, Technologies,
and Emergent Applications, chapter 9.
Simonis, I. and Malewski, C. (2011). *FL Starfish Fungus
Language for sensor description. OGC discussion pa-
per 11-058r1.
Taylor, K., Compton, M., and Laurent, L. (2011).
Semantically-enabling the web of things: The W3C
semantic sensor network ontology. In Proc. of 5th
eResearch Australasia Conference.
Taylor, K. and Leidinger, L. (2011). Ontology-driven com-
plex event processing in heterogeneous sensor net-
works. In Antoniou, G., Grobelnik, M., Simperl, E.,
Parsia, B., Plexousakis, D., Leenheer, P., and Pan,
J., editors, The Semanic Web: Research and Appli-
cations, volume 6644 of Lecture Notes in Computer
Science, pages 285–299. Springer Berlin Heidelberg.
Wang, P. (2012). Semantically enabling next generation en-
vironmental informatics portals. PhD thesis, Rensse-
laer Polytechnic Institute.
DATA2014-3rdInternationalConferenceonDataManagementTechnologiesandApplications
356
