
BeeAdHocServiceDiscovery
A MANET Service Discovery Algorithm based on Bee Colonies
Gianmaria Arenella, Filomena de Santis and Delfina Malandrino
Dipartimento di Informatica, University of Salerno, Via Giovanni Paolo II, Fisciano, Italy
Keywords:
Swarm Intelligence, Routing, MANET Auto-configuration, Web Service Discovery.
Abstract:
In a mobile ad-hoc network, nodes are self-organized without any infrastructure support: they move arbi-
trarily causing the network to experience quick and random topology changes, have to act as routers as well
as forwarding nodes, some of them do not communicate directly with each other. Routing, IP address auto-
configuration and Web service discovery are among the most challenging tasks in the MANET domain. Swarm
Intelligence is a property of natural and artificial systems involving minimally skilled individuals that exhibit
a collective intelligent behaviour derived from the interaction with each other by means of the environment.
Colonies of ants and bees are the most prominent examples of swarm intelligence systems. Flexibility, robust-
ness, and self-organization make swarm intelligence a successful design paradigm for difficult combinatorial
optimization problems. This paper proposes BeeAdHocServiceDiscovery a new service discovery algorithm
based on a bee swarm labour that may be applied to large scale MANET with low complexity, low communi-
cation overhead, and low latency. Eventually, future research directions are established.
1 INTRODUCTION
A mobile ad-hoc network (MANET) is a set of mobile
nodes that communicate over radio and operate with-
out the benefit of any infrastructure; nodes continu-
ously enter and leave the network according to their
mobility needs. The limited transmission range of
wireless interfaces makes the source-destination com-
munication multi-hop. Nodes accomplish the func-
tionality of hosts, as well as that of routers forward-
ing packets for other nodes. MANETs are very flexi-
ble and suitable for several situations and applications
since they allow establishing temporary connections
without pre-installed resources. Remarkable uses of
mobile ad-hoc networks are in calamity and military
scenario; with the increasing diffusion of radio tech-
nologies, many multimedia applications take also ad-
vantages from running over them. MANETs suffer
from a variety of questions: the routing and the IP (In-
ternet Protocol) address auto-configuration problems
are among the most challenging ones. Many different
approaches dealing with them do exist, even though
there are not algorithms that fit in all cases (Royer and
Toh, 1999; Nesargi and Prakash, 2002). The num-
ber and variety of services provided by MANETs are
constantly increasing with the expansion of their ap-
plications; thus, services offered by single nodes are
accordingly spreading as well as the need of shar-
ing useful facilities among nodes. To get benefit
from such a practice a device must be able to lo-
cate the service provider in the network and to in-
voke the service itself. Since different nodes provid-
ing different services may enter and leave the network
at any time, many research efforts aim at improv-
ing MANETs usability by means of an efficient and
timely service management and discovery, that is to
say by means of a suitable Service Discovery Proto-
col (SDP) (Choudhury et al., 2011). In this paper, we
present BeeAdHocServiceDiscovery, a novel swarm
intelligence SDP based on BeeAdHoc, a well-known
routing algorithm for MANET derived from the bee
colony optimization meta-heuristic (Wedde and Fa-
rooq, 2005a; Wedde and Farooq, 2005b; Wedde,
Horst F. at al., 2005; Dorigo and Blum, 2005). Swarm
Intelligence (SI) is a well-known distributed paradigm
for the solution of hard problems taking insight from
biological scenario such as colonies of ants, bees, and
termites, schools of fish, flocks of birds. The most
interesting property of SI is the involvement of mul-
tiple individuals that interact with each other and the
environment, exhibit a collective intelligent behavior,
and are able to solve complex problems. Many appli-
cations, mainly in the contexts of computer networks,
distributed computing and robotics exploit algorithm
244
Arenella G., de Santis F. and Malandrino D..
BeeAdHocServiceDiscovery - A MANET Service Discovery Algorithm based on Bee Colonies.
DOI: 10.5220/0005045902440251
In Proceedings of the 11th International Conference on Informatics in Control, Automation and Robotics (ICINCO-2014), pages 244-251
ISBN: 978-989-758-039-0
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

designs using SI. The basic idea behind this paradigm
is that many tasks can be more efficiently completed
by using multiple simple autonomous agents instead
of a single sophisticated one. Regardless of the im-
provement in performance, such systems are usually
much more adaptive, scalable and robust than those
based on a single, highly capable, agent. An arti-
ficial swarm can be generally defined as a decen-
tralized group of autonomous agents having limited
capabilities. Due to the adaptive and dynamic na-
ture of MANETs, the swarm intelligence approach
is considered a successful design paradigm to solve
the routing, the IP address auto-configuration and the
service discovery problems (Bonabeau et al., 1999;
Wedde and Farooq, 2005a; Pariselvam and Parvathi,
2012). The remainder of this paper is organized as
follows. Section 2 reviews the basics of the bee
colony optimization meta-heuristic and routing and
auto-configuration algorithms derived from it. Sec-
tion 3 introduces the fundamentals of service discov-
ery as well as a short review of the literature about
it. Section 4 describes the new proposed algorithm
and its computational complexity. Finally, Section 5
sketches conclusions and ideas for future works.
2 THE SWARM PARADIGM
2.1 BeeAdHoc Routing Algorithm
Bee colonies (Apis Mellifera) and the majority of ant
colonies (Argentine ant, Linepithema humile) show
similar structural characteristics, such as the presence
of a population of minimalist social individuals, and
must face analogous problems for what is concerned
with distributed foraging, nest building and mainte-
nance. A honeybee colony consists of morpholog-
ically uniform individuals with different temporary
specializations. The benefit of such an organization
is an increased flexibility to adapt to the changing
environments. There are two types of worker bees,
namely scouts and foragers. The scouts start from the
hive in search of a food source randomly keeping on
this exploration process until they are tired. When
they return to the hive, they convey to the foragers in-
formation about the odor of the food, its direction, and
the distance with respect to the hive by performing
dances. A round dance indicate that the food source is
nearby whereas a waggle dance indicate that the food
source is far away. Waggling is a form of dance made
in eight-shaped circular direction and has two compo-
nents: the first component is a straight run and its di-
rection conveys information about the direction of the
food; the second component is the speed at which the
dance is repeated and indicates how far away the food
is. Bees repeat the waggle dance repeatedly giving in-
formation about the food source quality. The better is
the quality of food, the greater is the number of for-
agers recruited for harvesting. The Bee Colony Opti-
mization (BCO) meta-heuristic has been derived from
this behavior and satisfactorily tested on many com-
binatorial problems (Teodorovic et al., 2006). BeeAd-
Hoc is a reactive source routing algorithm based on
the use of four different bee-inspired types of agents:
packers, scouts, foragers, and bee swarms, (Wedde
and Farooq, 2005b). Packers mimic the task of a
food-storekeeper bee, reside inside a network node,
receive and store data packets from the upper trans-
port layer. Their main task is to find a forager for the
data packet at hand. Once the forager is found and
the packet is handed over, the packer will be killed.
Scouts discover new routes from their launching node
to their destination node. A scout is broadcasted to
all neighbors in range using an expanding time to live
(TTL). At the start of the route search, a scout is gen-
erated; if after a certain amount of time the scout is
not back with a route, a new scout is generated with
a higher TTL in order to incrementally enlarge the
search radius and increase the probability of reaching
the searched destination. When a scout reaches the
destination, it starts a backward journey on the same
route that it has followed while moving forward to-
ward the destination. Once the scout is back to its
source node, it recruits foragers for its route by danc-
ing. A dance is abstracted into the number of clones
that could be made of the same scout. Foragers are
bound to the beehive of a node. They receive data
packets from packers and deliver them to their des-
tination in a source-routed modality. To attract data
packets foragers use the same metaphor of a waggle
dance as scouts do. Foragers are of two types: delay
and lifetime. From the nodes they visit, delay foragers
gather end-to-end delay information, while lifetime
foragers gather information about the remaining bat-
tery power. Delay foragers try to route packets along
a minimum delay path, while lifetime foragers try to
route packets in such a way that the lifetime of the
network is maximized. A forager is transmitted from
node to node using a unicast, point-to-point modal-
ity. Once a forager reaches the searched destination
and delivers the data packets, it waits there until it can
be piggybacked on a packet directed to its original
source node. In particular, since TCP (Transport Con-
trol Protocol) acknowledges received packets, BeeAd-
Hoc piggybacks the returning foragers in the TCP ac-
knowledgments. This reduces the overhead generated
by control packets, saving at the same time energy.
Bee swarms are the agents that are used to transport
BeeAdHocServiceDiscovery-AMANETServiceDiscoveryAlgorithmbasedonBeeColonies
245

foragers back to their source node when the applica-
tions are using an unreliable transport protocol like
UDP (User Datagram Protocol). The algorithm reacts
to link failures by using special hello packets and in-
forming other nodes through Route Error Messages
(REM). In BeeAdHoc, each MANET node contains
at the network layer a software module called hive. It
consists of three parts: the packing floor, the entrance
floor, and the dance floor. The entrance floor is an in-
terface to the lower MAC layer, the packing floor is an
interface to the upper transport layer while the dance
floor contains the foragers and the routing informa-
tion. BeeAdHoc has been implemented and evalu-
ated both in simulation and in real networks. Results
demonstrate a very substantial improvement with re-
spect to congestion handling, for example due to hello
messages overhead and flooding, and prove the algo-
rithm far superior to common routing protocols, both
single and multipath. Moreover, for BeeAdHoc math-
ematical tools have been utilized in order to over-
come shortcomings of simulation-based studies such
as their scenario specificity, scalability limitations and
time consume. In (Saleem et al., 2008) mathemati-
cal models of two key performance metrics, routing
overhead and route optimality, have been presented
providing valuable insight about the behaviour of the
protocol.
2.2 BeeAdHocAutoConf Algorithm
BeeAdHocAutoConf is an IP address allocation algo-
rithm based on the bee metaphor (De Santis, 2012).
When a node wishes to join a network, it randomly
picks up an address, starts setting up a local alloca-
tion table, and broadcasts a scout to all neighbours in
its range using an expanding TTL. The TTL controls
the number of times a scout may be re-broadcasted.
Each scout is uniquely identified with a key based on
its source node identifier (ID) and a sequence number.
The task of the scout is twofold: it checks whether or
not other nodes on its route are using the same address
of its source node, and brings back useful information
either if it finds a duplicate address occurrence or not.
The source node broadcasts the scout after assigning a
small TTL to it and setting up a timer for itself. When
the TTL expires, the scout might increment it in order
to enlarge the search radius and increase the proba-
bility of reaching a node that might use a duplicate
address. A maximum TTL is also established with
respect to a reasonable size for an ad hoc network.
Scouts with exceeded TTL might be killed or not de-
pending on the information, they have gathered un-
til then. This mechanism helps ensuring the address
uniqueness when the TTL expires and useful address
information has not been collected meaning that the
source node is a network initiator. Scouts that on their
route have been seen already are deleted in order to
limit the overhead.
3 MANET SERVICE DISCOVERY
3.1 Web Services & SOA
Web services is an evolving collection of standards,
specifications, and implementation technologies in
the areas of application integration and distributed
computing. As defined by the W3C: “A Web Ser-
vice is a software system designed to support inter-
operable machine-to-machine interaction over a net-
work. It has an interface described in a machine-
processable format (specifically WSDL). Other sys-
tems interact with the Web service in a manner pre-
scribed by its description using SOAP messages, typ-
ically conveyed using HTTP with an XML serial-
ization in conjunction with other Web-related stan-
dards”. Web services do not necessarily need to ex-
ist on the World Wide Web (i.e., they can be located
in an intranet) while implementation details about
the distribution platform can be ignored by the pro-
grams that invoke the service. A Web service is ac-
cessible through its APIs and a specific invocation
mechanisms. The service-oriented computing offers
a new model for distributed application development,
obtained through the integration of different applica-
tions, offered as services. A key element of this ap-
proach is SOA (Service Oriented Architecture), an ar-
chitectural style that is flexible enough to allow the
design of distributed applications from a set of func-
tional units (services) available on the net and acces-
sible through well-defined interfaces. The main goal
of SOA is to ensure interoperability between different
applications in order to build software systems based
on loosely coupled components, which are combined
dynamically. Applications are available on the net-
work as services or integrated with other services. Fi-
nally, Web Services are the most suitable technology
to implement SOA. A SOA architecture is based on
three fundamental elements: the “Service Requestor”,
the “Service Provider”, and the “Service Registry”.
The Service Provider provides a service via a standard
middleware, makes it available to others over a net-
work and, finally, manages its implementation. The
Service Provider is responsible of creating a descrip-
tion of the service and of publishing it in one or more
registries. It also receivesall invocations for a specific
service, providing the corresponding responses. The
service description (a WSDL document) must contain
ICINCO2014-11thInternationalConferenceonInformaticsinControl,AutomationandRobotics
246

all the information needed to use the service. The Ser-
vice Requestor invokes the service to ask for a specific
functionality. It must firstly retrieve the description
of the needed service and then use it to implement
the binding process. The search operation in the Reg-
istry is a name-based search: each service is uniquely
identified by a specific name. The Service Requestor
is responsible of the translation of the description of
the service into the data structures needed to carry out
the binding. The Service Registry is the component
that advertises the service descriptions published by
the Service Providers and allows Service Requestors
to look for the requested functionality among the pub-
lished descriptions. Each of these three roles can be
played by any program or node in the network. In
some circumstances, a single program may play more
than one role, e.g., a program could be both a Service
Provider, providing a Web service to different appli-
cations, both a Service Requestor, by invoking a Web
service offered by others. According to the aforemen-
tioned roles, SOA supports three types of operations:
(1) publish (service description and publication), (2)
find (search for services that match the provided cri-
teria), (3) bind (connection with a Service Provider).
The “Service Discovery” process establishes the rela-
tionship between the Service Requestor and the Ser-
vice Providers: it defines, in fact, the mechanism for
locate service providers and retrieve the published
service descriptions.
3.2 Universal Description Discovery
and Integration
UDDI (Universal Description, Discovery, and Inte-
gration) is an XML-based centralized registry, in-
dependent from the platform, which allows to pub-
lish and to query service descriptions. The goal of
UDDI is to facilitate the discovery of services both
in the process of designing a service, and dynami-
cally, at runtime. In the Web Services scenario, Ser-
vice Providers publish in the Service Registry the in-
formation about where to retrieve the WSDL doc-
uments of the services. Service Requestors query
the Service Registry to find out where to retrieve the
WSDL documents, in order to invoke the services
providing the needed functionalities. Due to a va-
riety of reasons, service discovery in MANETs is a
more challenging task. First, it has to allow wire-
less resource-constrained devices to discover services
dynamically, while minimizing the traffic and toler-
ating the irregular connectivity of the network. Sec-
ondly, it has to provide service delivery to any other
heterogenous device, regardless of its hardware and
software platforms. Eventually, it has to enable ser-
vice requesters to differentiate service instances ac-
cording to provided nonfunctional properties, so that
services match against the application quality of ser-
vice requirements. In the sequel, we briefly review
the literature main results.
3.3 Cross Layer based Service
Discovery
The service selection in MANETs requires the cross-
layer integration of service discovery and selection
with MANET routing mechanisms. The advantages
of such a cross-layer approach over the traditional
application layer implementation that preserves the
modularity of the protocol stack are twofold. First,
clients learn about available services and routes to
servers offering them at the same time with obvious
cost reduction and accuracy increase of service selec-
tion. Secondly, the existence of explicit routing in-
formation about path breaks or updates allows clients
to efficiently detect changes in network topology and
switch to nearby servers without additional cost. In
(Varshavsky et al., 2005) it has proved that the net-
work performance maximization requires that service
selection decisions must be continuously reassessed
to offset the effects of topology changes. It is also
argued that, when multiple entries in the service ta-
ble match a client’s service description, a cross-layer
approach allows the client to make a choice based on
the lowest hop count and some service specific met-
rics like load and CPU usage. In (Shao et al., 2009) a
multi-path cross-layer service discovery (MCSD) for
mobile ad hoc networks has been proposed that takes
advantage from the network-layer topology informa-
tion and the routing message exchange. The algo-
rithm focuses on double-path cross-layer service dis-
covery (DCSD), a special and most important case of
MCSD. The iDCSD heuristic is also presented: from
a number of candidate paths it finds the optimal routes
from a client to a server and from a client to two
servers by minimizing the hop count in the network
layer. The MCSD protocol, however, selects multi-
path by considering only the lowest total hop count
from a client to one or more servers without taking
into account QoS metrics like available bandwidth
and residual energy. The service update in multiple
servers becomes difficult too. In (Pariselvam and Par-
vathi, 2012) SISDA (Swarm Intelligence Based Ser-
vice Discovery Architecture) has been developed, a
swarm intelligence based service discovery architec-
ture for MANETs. It is based on AntNet, an adap-
tive agent-based routing algorithm that has outper-
formed the best-known routing algorithms. It pro-
vides the service requestor (SR) to specify the oper-
BeeAdHocServiceDiscovery-AMANETServiceDiscoveryAlgorithmbasedonBeeColonies
247
ating context. For a set of mobile hosts, which are
parts of the context defined, a cost effective routing
tree is constructed and maintained dynamically. For
a client’s service request, the service discovery com-
ponent (SDC) lookup for the service providers with
most relevant QoS entries matching the QoS request
of the service requester.
3.4 Hierarchical Service Discovery
In (Tsai et al., 2009) SGrid, a service discovery pro-
tocol based on a hierarchical grid, has been presented.
The network geographical area is divided into a two
dimensional hierarchical grid. The information about
the available services is stored in directory nodes,
one for each cell, along a trajectory properly defined
with the aim of improving the efficiency of registra-
tion and discovery. Service providers register their
services along the trajectory; requestors discover ser-
vices along it and acquire the available information.
The sparse node network topology is also avoided by
means of a suitable process. In (Chen and Mi, 2007)
the Service Discovery Area (SDA) is spontaneously
set up and managed by a Service Discovery Area
Manager (SDAM) responsible for centralized service
repository and service request processing. The pro-
tocol provides scalability to large MANET and can
work efficiently without manual monitoring and man-
agement. Unfortunately, the SDAM and the central-
ized nature of it produce a considerable amount of
overhead.
3.5 Routing Layer based Service
Discovery
In (Ververidis and Polyzos, 2005) the concept of
service discovery provided with routing layer sup-
port was first introduced. For a proactively routed
MANET a service reply extension added to topology
updating messages provides both service and route
discovery. For a reactively routed MANET the ser-
vice discovery process follows the traditional route
discovery process by means of the route request pack-
ets (RREQ) and the route reply packets (RREP). It
further extends the idea by carrying a service request
or reply in their respective areas by invoking the hy-
brid Zone Routing Protocol (ZRP).
4 BeeAdHocServiceDiscovery
BeeAdHocServiceDiscovery (BAHSD) is a novel ser-
vice discovery and selection algorithm based on hon-
eybee foraging behaviour. It uses a decentralized
cross-layer approach starting from the reactive rout-
ing algorithm BeeAdHoc.
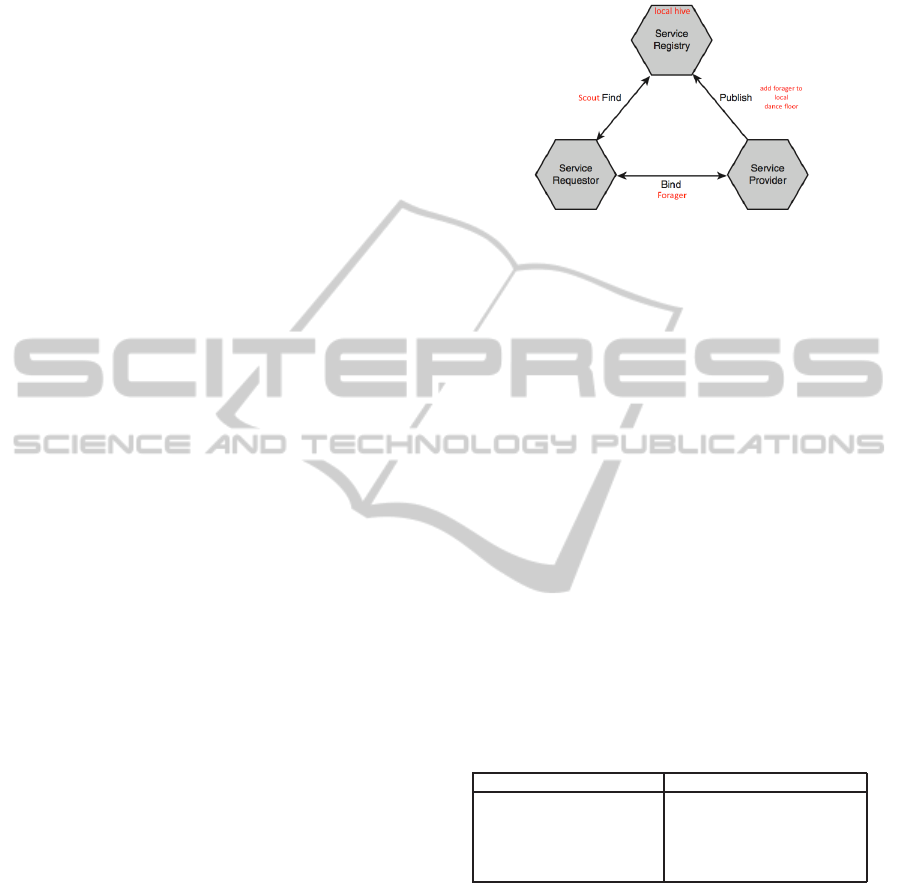
Figure 1: Mapping scout-forager into find-bind-publish op-
erations.
BAHSD combines SOA architecture, namely the
Service Discovery phase, with BeeAdHoc and BeeAd-
HocAutoConf. Fig. 1 illustrates such a mechanism.
Each node has a hive ready to store services offered
by it (Service Registry). The hive architecture is
the base routing mechanisms that BAHSD uses in
its cross-layer approach each time a service requestor
needs to look for a service and to invoke it soon af-
ter. Scouts realize the find operation when looking for
food (source-destination path search); foragers real-
ize the bind operation when collecting nectar (packet
transmission); new foragers added to the dance floor
of the hive realize the publish operation (forager re-
cruited in order to specify the Web service descrip-
tion). Table 1 maps the key concepts of the IP address
auto-configuration problem into the main components
of the service discovery process for MANETs.
Table 1: BeeAdHocServiceDiscovery main components
mapping from IP address auto-configuration into service
discovery.
IP Address Auto-configuration Service Discovery
Allocation Table Service Registry UDDI
IP Address Business Service
Duplicate Address Search API Inquiry UDDI Specification
IP Address Assignment API Publish UDDI Specification
Node leaving the MANET API Delete UDDI Specification
More precisely, each MANET node accomplishes
the Service Registry functionality, when is either Re-
questor or Provider. The hive is a local Service Reg-
istry, namely the UDDI registry that publish descrip-
tions of services provided by neighbour nodes in the
form of businessService entities. An extension of
the dance floor definition in BeeAdHoc allows imple-
menting the local Service Registry. Each entry of the
dance floor is indeed a different forager for each dif-
ferent pair (destination, businessService) and it con-
tains a Routing Frame as well as a Service Frame.
Two main components constitute the architec-
ture of BAHSD: the Service Description Publication
ICINCO2014-11thInternationalConferenceonInformaticsinControl,AutomationandRobotics
248

(SDP) and the BeeSwarmServiceDiscovery (BSSD).
In SDP each hive configures its local UDDI, by pub-
lishing by means of a “save
service” (API Publish)
operation, the Web Service descriptions offered by
itself to all close nodes. BSSD exploits the BeeAd-
Hoc routing operations to gather descriptions and lo-
cations about the requested service.
4.1 The Algorithm
The algorithm description will be done by means
of the three logical blocks that correspond to the
operations in the Dance Floor, Packing Floor, and
the Entrance Floor, respectively. For each of them
new functions have been implemented with respect to
those of BeeAdHoc in order to support the service dis-
covery mechanisms. Table 2 provides an explanation
of the symbols used in the code.
Table 2: Symbols used in the code.
Symbol Description
s Packet source node
d Packet destination node
i Current node
j Any MANET node
S
sd
Scout bee sent from s to d
F
sd
Forager bee sent from s to d
D
sd
Data packet sent from s to d
P
sd
Any packet received at i with source s and dest. d
h
next
Next hop address
SF Service Frame, find service/businessService datatype
L
SF
Forager list for a given SF
Dance Floor: it implements the addForager and get-
Forager functions. The first of them is equivalent to a
save
service operation into the local UDDI Registry;
the second of them is equivalent to a find
service op-
eration into the local UDDI Registry. The addFor-
ager function computes the number of packers wait-
ing for F
sd
and the values of the path quality metrics;
it also checks whether a list L
SF
of foragers does al-
ready exists for the SF corresponding to F
sd
in order
to possibly create it and update the dance number. The
getForager function makes a lookup into the Dance
Floor with the aim to search for at least one forager
matching the SF input service description; it might
return a random chosen forager or a null value.
Algorithm 1: Services provided by Dance Floor.
/∗ add a for a ge r on dance f l oor ∗ /
void addForager (F
sd
)
{
var w a it i n g Pa c ke r s = getPackerInQueueForThisForager (F
sd
) ;
var q ua l i t y M et r i c = getParameterCollectFromForager (F
sd
) ;
i f (L
SF
not e x i st f o r F
sd
. SF )
cre a t e L
SF
;
add F
sd
to L
SF
;
updateDanceNumber(F
sd
, w a i t i n g P a ckers , qu a l i ty M et ri c ) ;
}
/∗ lookup a s p e c i fi c f o r a g e r on dance f l o o r ∗ /
match i n g F o r ag e r getForager (SF )
{
var tmp = NULL;
i f (F
sd
e x is t s in L
SF
) {
while ( tmp == NULL && F
sd
e x is t s in L
SF
) {
choose randomly a F
sd
among m ul ti p l e f o ra g e rs in L
SF
;
i f (F
sd
. l i f e t im e > currentTi m e )
i f (F
sd
. danceNumber > 0) {
tmp = copy (F
sd
) ;
decrease danceNumber ;
}
e l s e {
tmp = F
sd
;
de l et e F
sd
from dance f lo o r ;
}
el se
k i l l F
sd
;
}
}
return tmp ;
}
Packing Floor: it implements the service requests
entailed from the upper layer and takes care of packets
attained from the Entrance Floor with different oper-
ations whether the incoming packet is either a forager
or a scout. For each received SF from the upper layer,
the local registry UDDI might already have the re-
quested information (getForager returns F
sd
) or might
not have it (getForager returns a null value) requiring
a new scout creation.
For each received packet P
sd
from the Entrance
Floor, either a forager is added into the Dance Floor
(addForager) or a different forager F
sj
is created for
each Service Frame that the scout collected on the
path s-j. However, in both cases, for each forager
F
sj
added into the Dance Floor, the presence of data
packet D
sj
in the send buffer waiting for it will be
verified.
Algorithm 2: Actions taken at Packing Floor.
/∗ s e rv i c e r e q u e s ts r e c ei v ed from hi g h e r l a y e r s ∗ /
for each (SF r ec e iv ed from higher l ay e r s ) {
var F
sd
= d a nceFloor . getForager (SF ) ;
i f (F
sd
!= NULL) {
enca p su l a t e D
sd
in t o the payload of F
sd
;
send F
sd
to en tr a n c e F l oo r ;
}
e l s e {
in ser t D
sd
in t o the pack e t queue ;
cre a t e a new sc o u t S
sd
with ID , i n i t i a l TTL;
enca p su l a t e SF i nt o the heade r of S
sd
;
set timer of S
sd
;
send S
sd
to e nt r a n ce F lo or ;
}
}
/∗ packet s coming from e nt ra n ce f lo o r ∗ /
for each (P
sd
r e c ei ve d from e n t r a n c e ) {
i f (P
sd
i s a f o r ag e r ) {
danc e F l o o r . addForager (P
sd
) ;
extrac t D
sd
from th e payload of f or ag e r ;
de l i v er D
sd
to h i g h er l a y er s ;
}
el s e i f ( P
sd
i s a sco u t ) {
for each (SF j g a t h e r e d by P
sd
) {
cre a t e a f o r ag e r F
sj
foreach SF
j
;
danc e F l o o r . addForager ( F
sj
) ;
}
k i l l P
sd
;
}
for each (F
sj
add to dance f lo o r ) {
var packer s = getNumberPacketInQueueForForager (F
sj
) ;
while ( pack e r s > 0 && F
sj
. danceNumber > 0) {
enca p su l a t e D
sj
in t o payload of F
sj
;
send F
sj
to en tr a n c e ;
BeeAdHocServiceDiscovery-AMANETServiceDiscoveryAlgorithmbasedonBeeColonies
249

decrease packer s ;
}
}
}
/∗ check sco u t r e t ur n ∗ /
i f ( t i m e r e x p i r e d and scout S
sd
not r et ur n e d ) {
compute newTTL of S
sd
and assi g n i t a newID ;
set timer of S
sd
;
send i t t o e n tr an c e ;
}
Entrance Floor: it manages the foragers and the
scouts coming from the MAC layer. A forager might
be sent to the Packing Floor or to the next hop (af-
ter having measured quality metrics), whether it has
reached its destination or not. A scout might flight
towards its source node s or the destination d. If is
coming back to the source s (Service Requestor) in
each intermediate node will be forwarded to the next
hop by means of the function sendPacketToNextHop,
whereas in s will be forwarded to the Packing Floor.
If the scout is flying towards the destination d (Ser-
vice Provider) in each node i it will arrive, it will call
the function getForager from the Dance Floor; if the
function returns a forager F
sd
the search ends success-
fully (i.e., the UDDI registry of the node i knows the
path toward the desired Service Provider d). At this
point the scout will become a backward scout, coming
back to the source by bringing the following informa-
tion: (1) the description of the requested service; (2)
the description of the other services gathered during
the path; (3) the complete route toward the Service
Provider d, built by concatenating the path until i with
the route from i to d. Conversely, if the getForager
returns a null value, it means that there are not for-
agers for the required service. Now, if the TTL is not
expired and the scout is not present in the list of the
scouts seen by the node i, it will be retransmitted in
broadcast to all nodes neighbours of i. Finally, if (1)
the TTL is expired, (2) the scout is not available in
the list of scouts seen by the node i, and (3) the list
of SF gathered along the path is not empty, then the
scout will be not discarded, but returned to the source
in order to update the Local UDDI registry with all
SF description collected along the taken path.
Algorithm 3: Actions taken at Entrance Floor.
/∗ f o r ag e r r ec e i v e d from MAC l a ye r ∗ /
for each (F
sd
r e c ei ve d from MAC la ye r ) {
i f (F
sd
ar r ive d a t d )
send F
sd
to packingFloor ;
e l s e {
c o ll e c t o pt i m i za t i o n parameter from t h e node ;
sendPacketToNextHop(F
sd
) ;
}
}
/∗ scou t r ec e iv e d from MAC l ay e r ∗ /
for each (S
sd
r e c ei ve d from MAC l a ye r ) {
i f (S
sd
i s on return p ath toward s ) {
i f (S
sd
i s a t s)
send S
sd
to packingFloor ;
e l s e {
sendPacketToNextHop (S
sd
) ;
}
}
e l s e i f ( S
sd
is on forward p a t h toward d ) {
var F
id
= d a nceFloor . ge t F o ra g er (S
sd
. SF );
i f ( F
id
!= NULL) {
in ser t in payload of S
sd
F
id
.SF ;
in ser t in payload of S
sd
ot h e r f or a ge rs in danceFloor ;
complete the r o ut e by c o nc a te n a t in g S
si
+ F
id
;
change S
sd
to a backward sc o u t ;
rev e rse the source r o u t e i n the header ;
sendPacketToNextHop (S
sd
) ;
}
el s e {
i f (TTL expired | | S
sd
e x i s t s in s een Sc o ut Li s t )
i f (SF l i s t c o ll e c t ed from S
sd
i s empty )
k i ll S
sd
;
e l s e {
in ser t in payload of S
sd
f o ra g e r s from danceFloor ;
change S
sd
to a backward sco u t ;
rev e rse the source r o u t e in the header ;
sendPacketToNextHop(S
sd
) ;
}
el se {
in ser t in payload of S
sd
f o r ag e r s from danceFloor ;
in ser t address i in the source r ou t e header ;
in ser t ID and source of S
sd
in t o s ee n Sc o u t Li s t ;
decrease TTL;
broadcast S
sd
to a ll nei g h b o r s of i ;
}
}
}
}
/∗ f o r ag e r r ec e i v e d from packing f l oo r ∗ /
for each (F
sd
r e c ei ve d from Packing f l oo r ) {
c o ll ec t o p t i mi zat io n par am et e r from t h e node ;
sendPacketToNextHop(F
sd
) ;
}
/∗ scou t r ec e iv e d from packing f l o or ∗ /
for each (S
sd
r e c ei ve d from Packing f lo or ) {
in ser t address i i n the source r ou t e h e a d er ;
in ser t ID and sour ce of S
sd
in t o s e en S co u t L i st ;
decrease TTL;
broadcast S
sd
to a l l n e i g h b o r s of i ;
}
void sendPacketToNextHop (P
sd
)
{
find h
next
in the sour ce r o ut e header ;
send P
sd
to MAC I n t e r fa c e of h
next
;
}
In Fig. 2 we show a concise representation of the
BeeAdHocServiceDiscovery working principles, with
all steps required to make the final SOAP service in-
vocation.
Figure 2: BeeAdHocService Discovery working principles.
ICINCO2014-11thInternationalConferenceonInformaticsinControl,AutomationandRobotics
250

5 CONCLUSIONS
BeeAdHocService Discovery is a new protocol of ser-
vice discovery and selection for MANET based on the
foraging behaviour of honeybees that totally benefits
of results discussed in (Saleem et al., 2008). It uses a
cross layer mechanisms that allows gathering routing
information, such as path breaks and updates, in order
to minimize the number of control messages and the
node energy consumption with interesting advantages
for the Web service accuracy and the network load
balancing. BeeAdHocService Discovery maps the key
concept of the MANET auto-configuration algorithm
BeeAdHocAutoConf into the main components of a
MANET service discovery process. Moreover, by us-
ing the overall functionality of a reactive multipath
routing algorithm such as BeeAdHoc, it saves all fea-
tures of efficiency, scalability, robustness, decentral-
ization, adaptivity and auto-organization of it. The
next step in the development of BeeAdHocService
Discovery will be the extension of the Web Service
selection criterions that should include performance
parameters, such as CPU load, available RAM mem-
ory, server workload and so on (Grieco et al., 2005;
Grieco et al., 2006a; Grieco et al., 2006b). Both
the energy and privacy constraints (Malandrino et al.,
2013; Malandrino and Scarano, 2013; D’Ambrosio
et al., 2014) will be also taken into account. Perfor-
mance and simulation experiments will be performed
accordingly. Eventually, different forms of swarms
might be exploited.
REFERENCES
Bonabeau, E., Dorigo, M., and Theraulaz, G. (1999).
Swarm intelligence: from natural to artificial systems.
Oxford University Press, Inc.
Chen, Y. and Mi, Z. (2007). A Novel Service Discovery
Mechanism in MANET Using Auto-Configured SDA.
In WiCom 2007., pages 1660–1663.
Choudhury, P., Sarkar, A., and Debnath, N. (2011). Deploy-
ment of Service Oriented architecture in MANET: A
research roadmap. In INDIN, pages 666–670.
D’Ambrosio, S., De Pasquale, S., Iannone, G., Malandrino,
D., Negro, A., Patimo, G., Petta, A., Scarano, V.,
Serra, L., and Spinelli, R. (2014). Phone batteries
draining: is GWeB (Green Web Browsing) the solu-
tion? In 2014 International Green Computing Con-
ference, IGCC’14. Dallas, Texas, USA.
De Santis, F. (2012). An Efficient Bee-inspired Auto-
configuration Algorithm for Mobile Ad Hoc Net-
works. International Journal of Computer Applica-
tions, 57(17):9–14.
Dorigo, M. and Blum, C. (2005). Ant Colony Optimiza-
tion Theory: A Survey. Theor. Comput. Sci., 344(2-
3):243–278.
Grieco, R., Malandrino, D., Mazzoni, F., and Riboni, D.
(2006a). Context-aware provision of advanced Inter-
net services. In Fourth Annual IEEE International
Conference on Pervasive Computing and Communi-
cations Workshops, 2006., pages 4 pp.–603.
Grieco, R., Malandrino, D., and Scarano, V. (2005). SEcS:
Scalable Edge-computing Services. SAC ’05, pages
1709–1713.
Grieco, R., Malandrino, D., and Scarano, V. (2006b).
A scalable cluster-based infrastructure for edge-
computing services. World Wide Web, 9(3):317–341.
Malandrino, D., Petta, A., Scarano, V., Serra, L., Spinelli,
R., and Krishnamurthy, B. (2013). Privacy Aware-
ness About Information Leakage: Who Knows What
About Me? WPES ’13, pages 279–284.
Malandrino, D. and Scarano, V. (2013). Privacy leakage on
the web: Diffusion and countermeasures. Computer
Networks, 57(14):2833 – 2855.
Nesargi, S. and Prakash, R. (2002). MANETconf: Config-
uration of Hosts in a Mobile. In INFOCOM, pages
1059–1068.
Pariselvam, S. and Parvathi, R. (2012). Swarm Intelli-
gence Based Service Discovery Architecture for Mo-
bile Ad Hoc Networks. In Europ. Jour. Scient. Res.,
volume 74, pages 205–216.
Royer, E. and Toh, C.-K. (1999). A review of current rout-
ing protocols for ad hoc mobile wireless networks.
Personal Communications, IEEE, 6(2):46–55.
Saleem, M., Khayam, S., and Farooq, M. (2008). Formal
Modeling of BeeAdHoc: A Bio-inspired Mobile Ad
Hoc Network Routing Protocol. In Ant Colony Opti-
mization and Swarm Intelligence, volume 5217, pages
315–322.
Shao, X., Ngoh, L. H., Lee, T. K., Chai, T., Zhou, L., and
Teo, J. (2009). Multipath cross-layer service discov-
ery (MCSD) for mobile ad hoc networks. In APSCC
2009, pages 408–413.
Teodorovic, D., Lucic, P., Markovic, G., and Dell’ Orco,
M. (2006). Bee Colony Optimization: Principles and
Applications. In NEUREL 2006, pages 151–156.
Tsai, H.-W., Chen, T.-S., and Chu, C.-P. (2009). Ser-
vice Discovery in Mobile Ad Hoc Networks Based on
Grid. Vehicular Technology, IEEE Transactions on,
58(3):1528–1545.
Varshavsky, A., Reid, B., and de Lara, E. (2005). A cross-
layer approach to service discovery and selection in
MANETs. In Mobile Adhoc and Sensor Systems Con-
ference, 2005. , pages 8 pp.–466.
Ververidis, C. and Polyzos, G. (2005). Extended ZRP: a
routing layer based service discovery protocol for mo-
bile ad hoc networks. In Mobile and Ubiquitous Sys-
tems: Networking and Services, 2005, pages 65–72.
Wedde, H. and Farooq, M. (2005a). BeeHive: Routing
Algorithms Inspired by Honey Bee Behavior. KI,
19(4):18–24.
Wedde, H. and Farooq, M. (2005b). The wisdom of the hive
applied to mobile ad-hoc networks. In SIS 2005, pages
341–348.
Wedde, Horst F. at al. (2005). BeeAdHoc: An Energy Effi-
cient Routing Algorithm for Mobile Ad Hoc Networks
Inspired by Bee Behavior. GECCO ’05, pages 153–
160.
BeeAdHocServiceDiscovery-AMANETServiceDiscoveryAlgorithmbasedonBeeColonies
251
