
Actors and Factors in IS Process Innovation Decisions
Erja Mustonen-Ollila
1
, Jukka Heikkonen
2
and Philip Powell
3
1
Software Engineering and Information Management Department,
Lappeenranta University of Technology, P.O. Box 20, Lappeenranta, Finland
2
Joint Research Centre, Unit JRC.G1 Scientific Support to Financial Analysis, European Commission, Ispra, Italy
3
School of Business, Economics and Informatics, University of London, Malet Street, London, U.K.
Keywords: Information Systems, Process Innovation, IS Development, Decision Making, Longitudinal Case Study,
Dependency.
Abstract: Information system process innovation (ISPI) describes new ways of developing, implementing, and
maintaining information systems. This paper investigates ISPI decisions in three organisations over four
development generations. The analysis reveals dependencies between the actors and factors in the decision
processes; it shows how the actors employ different combinations of factors, and how the factors influence
the actors’ decision making. Self-Organizing Map clustering demonstrates that in the three organisations,
the combinations of ISPI and actors vary over time, and these variations may be partly explained by power
dependency between the organisations. The dependencies identified here are novel. The actors and factors
found in past research are validated, and the dependencies between the actors and factors enhance
confidence in the validity of the concepts and dependencies, as well as in expanding and emerging theory.
1 INTRODUCTION
Information System Process Innovation (ISPI) is a
new way of developing, implementing, and
maintaining information systems in an
organisational context (Swanson, 1994). In the
context of IS Development (ISD), a specific ISPI is
chosen for a specific development project. This
decision implies that there is an intention to use the
innovation and that the use is recorded. Thus,
information system innovation decisions (Rogers,
1995) and research on the decision processes (Turk
et al., 2005; Howlett, 2007) contribute to the
understanding of how organisations make decisions
about process innovations. The need for a deeper
understanding of ISPI decision making, its actors,
factors and their dependencies, is not, however,
widely recognised in the literature. Rather, the
literature has focused on decision making in general,
including how resources or role networks are
mobilised and brought to bear on particular
developments (Davis, 2006), or the role position has
a leadership status in decision making (Kadushin,
1968). Past studies emphasise several factors that
actors use in decision making, such as political
tactics, rules and regulations concerning power,
personal or internal control, and personal goals
(Mintzberg, 2009), or the importance of professional
knowledge (termed ‘expert power’) held by those in
power (Howlett, 2007). Past studies also view
decisions as outcomes of negotiations generated by a
single actor and a single factor at different
organisational levels where the actors are dependent
upon one another (Fomin and Lyytinen, 2000), even
though decision making tends to be a social activity
generated by the interaction of multiple factors.
Thus, such decisions resemble the outputs of large
organisational decisions as products of combinations
of factors linking different planes of reality, known
as organisational learning (Fomin and Lyytinen,
2000). Decision making is claimed to be a rational
choice with resource constraints and known
parameters (Howlett, 2007). (Safir et al., 1993)
argue that decision making is both a bounded
rational and political process, and decision makers
resolve conflicts by selecting the ‘best’ alternative.
(Xue et al., 2008) state that in decision processes,
the actors share governance in organisations by
collective decision making, and an IT department
can influence the decisions of other units through its
IT functional power. The prime focus of previous
studies is on a single time period, and in a small
202
Mustonen-Ollila E., Heikkonen J. and Powell P..
Actors and Factors in IS Process Innovation Decisions.
DOI: 10.5220/0005070902020209
In Proceedings of the International Conference on Knowledge Discovery and Information Retrieval (KDIR-2014), pages 202-209
ISBN: 978-989-758-048-2
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

number of organisations, involving a limited number
of actors. Further, the impact of decision making at
different organisational levels has been largely
ignored. Most studies consider a single decision
maker and ignore the dependencies between the
actors (Fomin and Lyytinen, 2000). They also lack
insight into the ‘real’ actors making decisions in
information system development and into the ‘real’
factors affecting decision making in ISD. Finally, no
studies explore the dependencies between actors and
factors of ISPI decision making in ISD projects.
Given the richness of past research, but
acknowledging its shortcomings, this paper
investigates the actors and factors affecting ISPI
decision making. The study seeks answers to two
questions: 1) What actors and factors affect decision
making over ISPIs?; and 2) How do the actors
depend on each other and the factors and vice versa?
The study analyses 208 separate ISPIs decisions
comprising 263 ISPI decision events, and uncovers 9
actors and 13 factors affecting ISPI decision making.
We found that there is an important dependency
between the actors in decision making at firm,
department, IS project and individual designer
levels. Actors belonging to the same category are
similar, and IS project groups make decisions based
on different factors than those at the firm and
department level. Firms, business units, and boards
of directors in the business units make decisions in a
similar way, whereas IS project groups and IS
working groups make decisions based on different
factors than those of IS steering groups supervising
IS projects. Further, department level and individual
level decision making is based on different factors,
even if the same individuals belong to the same
department. In the decision events, groups in
departments behave differently than in individual
decision making. The paper is structured as follows.
Section two describes the research method. Section
three justifies the main concepts, and data collection.
Section four introduces the results of analyses
employing data mining methods. Finally, section
five discusses the contribution, implications,
limitations, and future research directions and draws
conclusions about the results.
2 RESEARCH METHOD
This study takes a qualitative historical, descriptive,
and longitudinal multi-case (Xue et al., 2008;
Menard, 2002) perspective over a 43-year time
period in which ISPI decision making is studied in
three firms. From these firms, the cases have been
selected so that they either predict similar outcomes
(i.e. literal replication) or produce contrasting results
but for predictable reasons (i.e. theoretical
replication) (Yin, 1994). Theory triangulation is
applied by interpreting a single data set from
multiple perspectives, and methodological
triangulation is sought by using multiple methods to
understand the research problem (Denzin, 1978).
The concepts and their dependencies are validated
with the grounded theory approach (Eisenhardt,
1989; Glaser, 1992). The emergent theory, the
various concepts, and their dependencies, offer new
theoretical constructs for understanding the ISPI
decision phenomenon from different perspectives.
During the research, theoretical background
knowledge (Glaser, 1992) was gained, which
increases the credibility of the study. The data
collection involved three Finnish firms that were
part of the same ‘parent’ company. Firm A is a big
paper-producer, whereas B specialises in designing,
implementing and maintaining information systems.
Firm C evolved from B in 1995, and until the end of
1997, C formed a division within B. Since their
founding, 1984 for B and 1995 for C, B and C have
co-operated closely with A. The ISPI definition
formed the basis for the interviews and data
collection in the study. To address the research
questions, 27 tape-recorded semi-structured
interviews were conducted, investigating
experiences of ISPI decision making in IS projects.
The interviewees included project managers, IS
department managers, systems analysts, vice-
presidents, and programmers, who had been
involved in multiple ISPI processes and decisions
during their working careers that extended over 10
to 30 years in the case firms. Archival data
encompassing the period 1960-1997 was studied,
and it represented a secondary source of data.
Published news about changes in the firms’
environments and documentation of developed
systems, system development handbooks, minutes of
meetings etc. were gathered. Triangulation involved
checking different data sources simultaneously to
improve the reliability and validity of the data.
3 OPERATIONALIZATION
Based on Swanson’s (1994) terminology, ISPIs
cover both technological (Type Ia) and
administrative innovations (Type Ib). Management
innovations (M) include project management
guidelines or organisational arrangements (Swanson,
1994). Description innovations (D) include the use
ActorsandFactorsinISProcessInnovationDecisions
203

of standardised modelling techniques. Tool
innovations (TO) include capital-intensive software
assets. Core technologies (T) consist of
improvements in technical platforms that are critical
to delivering IS products.
One recurring aspect of ISPI concerns how the
technologies, skills and routines used in delivering
information systems change in a set of
organisational sites (Friedman and Cornford, 1989) -
called a locale. ISPI decisions influence the specific
scope of technologies, skills and routines that need
to change as a result of the decision. A locale is an
empirical environment, an organisational unit, where
the specific actors learn to understand and make
decisions about ISPIs. A locale consists of
information system development (ISD) and ISPI
decisions. In this study the locale was affected by
the IS department outsourcing of firm A in 1984.
Based on an extensive empirical analysis of the
historical evolution of IS development, (Friedman
and Cornford, 1989) point out that the four types of
ISPI innovations are often ‘horizontally’ closely
related, and they can thus be classified into a set of
evolutionary generations. The first generation (from
the late 1940s until the mid-1960s) was largely
hampered by ‘hardware constraints’, i.e., hardware
costs and limitations in capacity and reliability (lack
of T innovations). The second generation (mid-
1960s until early 1980s), in turn, was characterised
by ‘software constraints’, i.e., poor productivity of
systems developers and difficulties in delivering
reliable systems on time and within budget (lack of
D, M, and TO innovations). The third generation
(early 1980s to the start of the 1990s), was driven by
the challenge to overcome ‘user relationship
constraints’, that is, system quality problems arising
from inadequate perception of user demand and
resulting inadequate service (lack of M, D, and TO
innovations). Finally, the fourth generation (from the
beginning of the 1990s) is affected by
‘organisational constraints’ (lack of M, and D
innovations). In this case, constraints arise from
complex interactions between computing systems
and specific organisational agents, including
customers and clients, suppliers, competitors, co-
operators, representatives and public bodies
(Friedman and Cornford, 1989).
Studying ISPI requires the identification of those
who actually make choices concerning changes in
development practices. The decision authority of an
ISPI refers to a collective or individual decision
where a group of actors, or a single actor, has direct
or indirect influence on the decision. The decision
actors were hare determined inductively from the
data and classified according to three decision
authority levels: centralised (CEN), distributed
(DIS), and situational (SIT) (Table1, available by
separate request).
3.1 Data Collection and Categorisation
The data was gathered for the period 1954-1997 and
arranged in a manuscript, which included
descriptions of all ISPI events, ISPI decision actors,
and the factors affecting decision making,
technological platforms, organisational structures,
and changes in business organisations. These events
were arranged in chronological order and written
into a base-line manuscript that identified all ISPI
events in the firms. As the analysis contained several
important omissions, more data was gathered and a
second version of the manuscript written. This
manuscript was divided into two parts: the first part
covered the years 1954-1990 (in firms A and B) and
the second part included the years of 1984-1997 (in
firms B and C). The new manuscript was again
amended for errors and omissions. Using this base-
line data set, all recognised ISPI events were
arranged into a chronological table - one row for
each ISPI event. Each row included a description of
the firm, the ISPI, the year the event decision was
made, and the actor(s) involved. Each ISPI event
was then categorised into four time generations
(time generation 1 had no data, and it was omitted
from the analysis), three firms, and four ISPI
categories. Finally, the ISPI events were categorised
into three decision authority levels. The main
concepts in the data are as follows: four ISPI
categories (M, T, TO, and D); three locales (ComA,
ComB, and ComC); three time generations (Gen2,
Gen3, and Gen4); and three decision authority levels
(CEN, DIS, and SIT). The decision authority levels
were further classified into nine sublevels (CEN1,
CEN2, CEN3; DIS1, DIS2; SIT1, SIT2, SIT3, SIT4)
to clarify the different actor types, such as firm level
(CEN1), business level (CEN2), and board of
directors (CEN3). The final data for analysis
contained 208 separate ISPIs decided in decision
events, as some ISPIs were decided upon in the
organisations several times, and some ISPIs were
decided upon in more than one locale. When several
types of ISPIs were observed to be part of the same
decision event, these were split into separate ISPI
decision events.
KDIR2014-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
204

4 ANALYSIS
4.1 Dependencies Between ISPI
Categories, Locales, Time
Generations, and Actors
To discover data characteristics, such as regularities
and dependencies, and to get ideas/hypotheses for
further analysis, the data was first visualised by a
Self-Organizing Map (SOM) (Kohonen, 1989)
clustering method. Historical studies in information
systems research have characteristics that support
the use of SOM, which has been applied
successfully in many exploratory data analysis tasks.
The gathered data has typically rather high
dimensionality, i.e. each sample consists of several
independent variables, such as factors, and the data
itself in a table form does not easily show its actual
contents and is only partly understandable. In
addition, when the SOM results are consistent with
the further analysis results, additional confirmation
for the findings is achieved. SOM is a clustering and
visualisation method that projects original data onto
a lower dimensional map space so that the
topological dependencies between the data points
are preserved. This means that data points that are
close to each other in the dataset tend to be
represented by units close to each other on the map
space - which is typically a one- or two-dimensional
discrete lattice of units (clusters) determined by
codebook vectors. SOM-based exploratory data
analysis involves typically training a 2D SOM, and
after training, the resulting mapping is visualised
and analysed. If there are clear similarities and
regularities or variable dependencies within the data,
these can be observed by the pronounced clusters on
the resulting map.
To carry out this type of exploratory analysis, a
typical visualisation step is component plane
plotting (Kohonen, 1989), where the components of
codebook vectors are drawn in the shape of a map
lattice. A 2D SOM of 10x10 units (codebooks) was
trained with the collected data consisting of 208 data
points of 19 variables: Gen2, Gen3, Gen4; M, T,
TO, D; Com(A), Com(B), Com(C), CEN1, CEN2,
CEN3; DIS1, DIS2; SIT1; SIT2; SIT3, and SIT4.
Figure 1 presents the resulting SOM component
planes (the colouring of the component planes and
the corresponding colour bars show the values of the
variables in the different units (clusters).
Figure 1: Component plane presentation of the Self-Organizing Map trained by the collected data.
ActorsandFactorsinISProcessInnovationDecisions
205

The figure 1 shows that there are visible
dependencies between the three locales (A, B, and
C) and time generations (2, 3, and 4); A goes almost
hand-in-hand with the second time generation
(Gen2), whereas B and C consist of third (Gen3) and
fourth generations (Gen4). In addition, as firms A, B
and C have high values (close to 1) in separate and
almost non-overlapping map areas (see component
planes Com (A), Com (B) and Com (C)), it can be
deduced that the other data variables are able to
separate the firms. This means that the firms have
used their own combinations of ISPI categories, time
generations, and actors. This is interesting, as the
three firms are related and their roots are in the
internal information IS department of firm A. As to
the actors, it is demonstrated that A is not involved
with the centralised actors (CEN1, CEN2, or CEN3)
or distributed actor 2 (DIS2) as much as B and C. A
utilizes distributed actor 1 (DIS1) more than B and
C. The situational actors seem to be spread over all
the firms. As regards ISPI categories, A seems to
differ from B and C by category M; the other
categories (T, TO, and D) are represented by all
firms. Also, though less obviously, the dependency
between A and Gen 2 is the history of A, because it
outsourced its IS department to B in 1984.
Therefore, the decision power balance was shifted
from A’s internal IS department to B, and they have
now both the IT knowledge and the business
knowledge. A power dependency between the actors
engenders a political perspective to IS development
and ISPI decisions.
4.2 Factors Affecting Decisions Over
ISPIs
On the basis of the literature and the interviews and
archival material, 13 different factors affect ISPI
decisions (Table 3, available by separate request).
The factors were identified by comparing the
literature and the empirical data. For each actor, the
data set was converted manually into a binary matrix
based on the factors affecting its decision making.
The presence of a factor was denoted by 1 and its
absence by 0 (c.f. Ein-Dor and Segev 1993), and for
a single actor the minimum and maximum number
of factors were 1 and 13. The factors were as
follows. (1) Decision authority and position, (2)
Political tactics, (3) Expert power, (4) Power, (5)
Personal control, (6) Internal control, (7) Rationality,
(8) Governance, (9) Dependencies between decision
makers, (10) Resource constraints, (11)
Organisational learning, (12) Organisational setting
and centralisation, and (13) IT function power. The
actors of centralised decision making and the factors
(F1 to F13) affecting decision making in locales A,
B, and C are shown in Table 4 (available by separate
request). The table highlights that the factors
affecting decision making are the same in A, B and
C. This is novel and can be explained by the fact that
the decision makers in A became the decision
makers of B and C after the outsourcing. Table 5
shows that the most important factors affecting
decisions at the distributed level are F4 (power), F5
(personal control), F6 (internal control), F8
(governance), and F13 (IT function power) when
counting the factor occurrences (Table 5, available
by separate request). Table 6 shows that the most
important factors affecting decisions at the
situational level are personal control (F5),
organisational learning (F11), expert power (F3),
governance (F8), and internal control (F6). (Table 6,
available by separate request).
4.3 Dependencies Between Actors and
Factors
In ISPI decision making it is necessary to validate
the dependencies between the actors and factors.
This is clearly a so called unsupervised learning
problem, where the goal is to find an unknown
hidden structure in unlabelled data. For this, two
different data mining methods were used: Sammon
mapping (Sammon, 1969) for data projection and
UPGMA (Unweighted Pair Group Method with
Arithmetic mean) (Fitch and Margoliash, 1967), also
known as the average linkage method, for generating
a hierarchical binary cluster tree from the data. The
results of the methods are finally validated by
reflecting on them with the understanding of the
organisations and the related literature. A natural
choice for the analysis is to project the actors and the
factors represented by binary vectors to a lower-
dimensional 2D space in a manner that preserves the
topological dependency between the actors as well
as possible. Topology preservation means that those
actors that are close to each other by the given
factors can be observed as neighbours in the 2D
projection. Sammon mapping (Sammon, 1969)
belongs to a class of multi-dimensional scaling
(MDS) methods and has been used for this task
previously. Sammon mapping calculates the
distances of the original actors and tries to produce a
2D plot on the 2D plane of the actors in such a
manner that the corresponding distances between the
projected actors are as similar as possible with
respect to their original distances. When the data is
binary (factors exist (1) or not (0)) it is natural to use
KDIR2014-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
206
city block distances in measuring similarities. City
block distances give the number of different 1s and
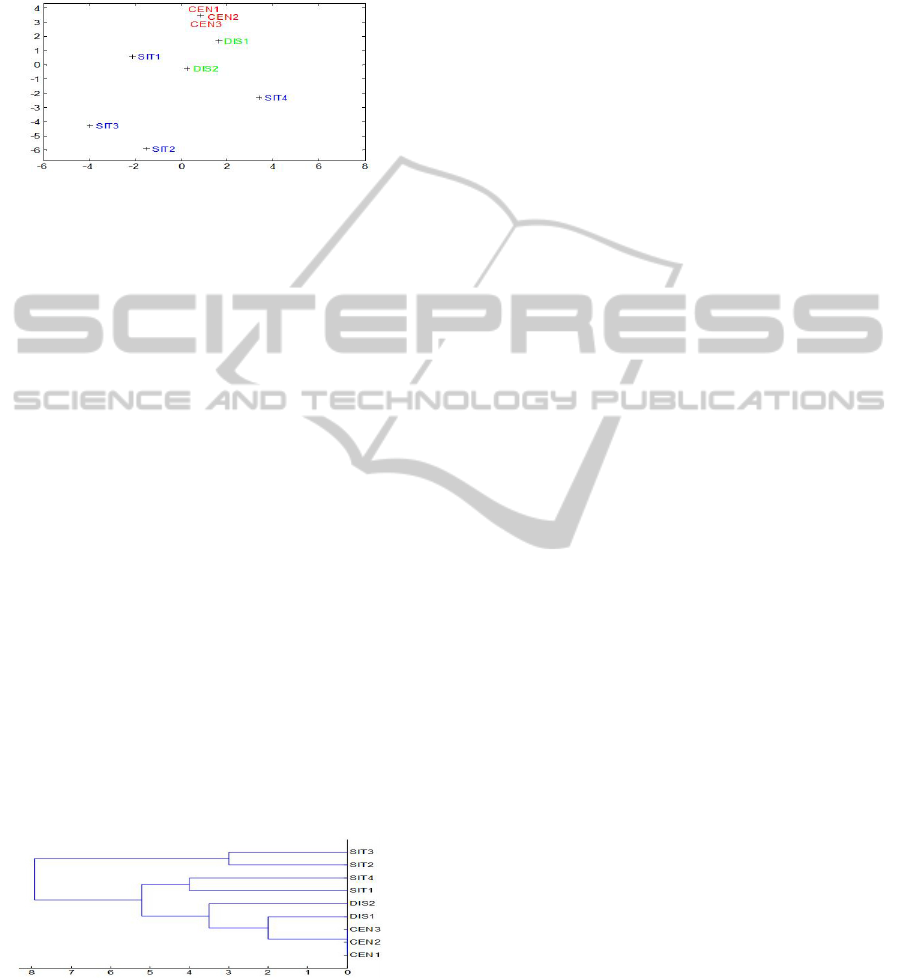
0s between two actors. Figure 2 shows the result of
the Sammon mapping method.
Figure 2: Sammon mapping of the 9 actors based on their
corresponding factors affecting the decisions. The closer
the actors, the more common are their decision factors.
In the figure, the names of the actors are
coloured according to their predefined categories.
The red-green-blue colouring schema reveals that
the within-group variation of the actors is lower than
the between-group variation. The centralised
decision actors are closer to the distributed ones than
to the situational ones. Moreover, the distributed
decision actors are in the ‘middle’ of the other two
actor groups. The city block distances of the actors
defined by their factors can also be measured on the
basis of figure 2. The UPGMA method (Fitch and
Margoliash, 1967) is a popular and widely used
method for linkage analysis. The method uses a pair-
wise distance matrix of actors as the input and
produces a hierarchical cluster tree showing the
distance dependency of the actors. The tree consists
of a root, branches, nodes, and leaves. In the
dendrogram plot of the tree, both the grouping of the
actors according to the labelled leaves (similar actors
are near each other) and the distances between the
actor groups can be observed. As in Sammon
mapping, city block distances are used between the
actors. Figure 3 provides a dendrogram plot of the
hierarchical UPGMA cluster tree for the actors.
Figure 3: Hierarchical cluster tree produced by an
UPGMA linkage algorithm and city block pairwise
distances between the actors. The horizontal axis shows
the calculated mean city block distances of the grouped
actors.
The length of each branch represents the mean
distance between the two connected (grouped)
actors, and the distances are computed according to
their factors. The calculated mean distances between
the actors and group of actors are given in the
horizontal axis. For instance, the mean distance of
actor DIS1 to actor group CEN1, CEN2 and CEN3
is 2 in the city-block distance measure. The names
of the actors are coloured according to their
categories. Similar observations as for the Sammon
mapping results are apparent: the within-group
variation of the actors is lower than the between-
group variation, meaning that the actors belonging
to the same category are most similar to each other.
The situational decision making actors 2 (SIT2) and
3 (SIT3) are furthest away from the other actors.
SIT2 refers to the IS project group, and SIT3 refers
to the IS work group or development group in a
chosen project area. The firm, the business units, and
the board of directors in the business units make
decisions in a similar way. Firm A and firms B and
C, on the other hand, are not too far from each other.
The IS project steering group is closer to the
distributed decision makers - that is the departments
inside A, B and C. The IS project steering group is,
however, far away from the IS project group and the
IS work group or development group in a chosen IS
project area. This means that the IS project group
and the other smaller groups working with it make
decisions based on different factors than the IS
steering group. An individual designer sits between
the IS steering group and project group when
making decisions based on some factors.
The same type of analysis was conducted for the
13 factors, i.e., by Sammon mapping and a
hierarchical cluster tree by the UPGMA linkage
algorithm based on the distances between the factors
defined by their corresponding actors (see Figures 4
and 5). This way each factor is a vector where each
vector item (total of 9 items) is either 0 or 1
according to the actors where the factor exists. So,
for instance, factor F1 is given by a vector
(1,1,1,1,1,1,0,0,1). City block pairwise distances
were utilised.
The figures 4 and 5 show that the factors form
two separate groups where the actors are closer to
each other: in the first groups there are factors F1,
F2, F4, F5, F8, F9, and F13, and the other group
consists of the rest of the factors, i.e. F3, F6, F7,
F10, F11, and F12. The majority of the left hand side
factors are related to ISD projects resources, tools,
knowledge, and project control, and the majority of
the right hand factors are related to department and
organisational issues, such as the department’s
ActorsandFactorsinISProcessInnovationDecisions
207

power and decisions over single individuals (Figure
4). This means that the ISD projects and departments
and individuals clearly make decisions based on
different factors, even if the individuals belong to
the same departments. In the decision event the
project groups in the organisations behave
differently to individual decision making.
Figure 4: Sammon mapping of the 13 factors based on
their corresponding actors. The closer the factors, the more
common are their actors.
Figure 5: A hierarchical cluster tree produced by UPGMA
linkage algorithm and city block pairwise distances
between the factors. The horizontal axis shows the
calculated mean city block distances of the grouped
factors.
5 CONCLUSIONS AND
DISCUSSION
The results of the study show that the actors in the
three firms used their own combinations of ISPIs
over time. Firm (locale) A went almost hand in hand
with the second ISPI time generation (from mid-
1960s until early 1980s), whereas B and C consisted
of third (early 1980s to the beginning of the 1990s)
and fourth (from the beginning of the 1990s) ISPI
time generations. The dependency between A and
time generation two was the history of A, as it
outsourced its internal IS department functions to B
in 1984. The outsourcing turned the internal IS
department into a separate profit centre (independent
firm B), which necessitated greater emphasis on A’s
needs and infrastructure. In 1989 B established a
new software house, firm C, to serve the needs of A
by concentrating on applying object-oriented
technologies in A. In A, B and C, decision making
groups were developed during the IS projects in
response to time and resource pressures. The
empirical findings of the study also validated several
factors in past studies and their dependencies. These
factors included decision authority (Howlett, 2007;
Mintzberg, 2009), political tactics (Mintzberg,
2009), expert power (Howlett, 2007), power
(Mintzberg, 2009), personal control (Mintzberg,
2009), internal control (Mintzberg, 2009), rationality
(Howlett, 2007), governance (Xue et al., 2008),
dependencies between decision makers (Fomin and
Lyytinen, 2000), resource constraints (Howlett,
2007), organisational learning (Fomin and Lyytinen,
2000), organisational setting and centralisation
(Safir et al., 1993), and IT function power (Xue et
al., 2008). The theoretical implications in this study
were new concepts and dependencies uncovered in
the ISPI decision making. The several managerial
and practical implications were as follows. First, the
Self-Organizing Map (SOM) clustering method
revealed that within the three organizations, the
combinations of ISPIs and actors varied
over time.
The variation could be partly explained by a power
dependency between the organisations over time in
ISPI decisions. Second, the analysis showed that the
factors depended on the actors and vice versa in ISPI
decision making. A dependency means that an actor
needs another actor’s approval, control, or support.
The dependencies were also a new discovery not
found in previous studies. SOM has been used
successfully in explorative data analysis where
characteristics such as conditional probabilities
between the variables and their properties should be
observed where the data is too difficult to
comprehend to extract relevant information. The
uncovered dependencies between the different
factors and actors were novel, and the figures in this
study may act as models of ISPI decision making.
Third, dependencies between A, B and C, ISPI
categories, and ISPI development generations and
actors were found. Furthermore, the study showed
that the factors influenced the actors’ decision
making in ISPIs to a specific direction based on the
implemented information systems. Fourth, in ISPI
decision making, it is necessary to validate the
dependencies between the actors and factors also
with other analyzing methods. For this, two different
data mining methods were used: Sammon mapping
(Sammon, 1969) for data projection and UPGMA
(Unweighted Pair Group Method with Arithmetic
mean) (Fitch and Margoliash, 1967), also known as
the average linkage method, for generating a
hierarchical binary cluster tree from the data. We
showed how UPGMA, Sammon mapping and Self-
KDIR2014-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
208

Organizing Maps together were suitable for studying
our research problems because the identified
concepts and dependencies were validated, and the
data mining methods validated the dependencies.
Finally, methodological triangulation was sought by
using multiple qualitative methods in data collection
and analysis, such as historical, descriptive,
longitudinal multi-case, and grounded theory
approaches (Eisenhardt, 1989; Glaser, 1992) to
understand the research problems.
As knowledge
discovery is a research area which focuses on
methodologies in order to find out valid, novel,
useful and meaningful patterns from large data sets,
our research fulfilled its requirements because
knowledge discovery uses data mining methods in
data analysis, and we used Sammon mapping for a
data projection and UPGMA as the data mining
methods.
Information retrieval, on the other hand,
gathers relevant information for example from
unstructured and semantically varied data in texts,
which is in line with our study, as we gathered a
large number of textual interview data and used the
Self-Organizing Map in analyzing the data. We
claim that it is important for the knowledge
discovery and information retrieval community to
see how its methods can be applied to information
systems science, innovation literature and decision
making studies when a great amount of
qualitative
and longitudinal empirical data is converted to
quantitative data. A limited number of case firms
affects the generalisability of the findings. The
amount of data concerning ISPI decisions and actors
and factors could be considered small, which
reduced the accuracy of the analysis. In the future it
is important to study other organisations in the same
manner, and to compare the results as a next step in
generalisability. Finally, the longitudinal data was
important, as a horizontal survey would not have
addressed the research questions as to the
dependencies between ISPI actors and factors and
vice versa over time, the factors influencing ISPI
decisions, and the actors who dominated ISPI
decisions during the ISPI development time periods.
REFERENCES
Fomin, V. & K. Lyytinen (2000) ‘How to Distribute a
Cake Before Cutting it into Pieces: Alice in
Wonderland or Radio Engineers’ gang in the Nordic
Countries?‘ Information Technology Standards and
Standardisation: A Global Perspective‘, Hershey: Idea
Group Publishing.
Davis, S.E. (2006) ‘Identifying Opinion Leaders and
Elites: A Longitudinal Design‘, Library Trends, vol.
55, pp. 140-157.
Denzin, N.K. (ed.) (1978) ‘The research act: A theoretical
introduction to sociological methods’, New York:
McGraw-Hill.
Ein-Dor, P. and Segev, E. (1993) ‘A Classification of
Information Systems: Analysis and Interpretation’,
Information Systems Research, vol. 4, pp. 166-204.
Eisenhardt, K.M. (1989) ‘Building theories from case
study research’, Academy of Management Review, vol.
14, pp. 532-550.
Fitch, W. M. and Margoliash, E. (1967) ‘Construction of
Phylogenetic Trees’, Science, vol. 155, pp. 279-284.
Friedman, A. and Cornford, D. (1989) ‘Computer Systems
Development: History, Organization and
Implementation, New York: John Wiley & sons.
Glaser, B.G. (1992) ‘Emergence vs. Forcing: Basics of
Grounded Theory, Mill Valley, CA: Sociology Press.
Howlett, M. (2007) ‘Analyzing Multi-Actor, Multi-Round
Policy Decision-making processes in Government:
Findings from Five Canadian Cases’, Canadian
Journal of Political Science, vol. 40, pp. 659-684.
Kadushin, C. (1968) ‘Power, influence, and social circles:
A new methodology for studying opinion leaders’,
American Sociological Review, vol. 33, pp. 685-698.
Kohonen, T. (1989) ‘Self-Organization and Associative
Memory’, Heidelberg, Berlin: Springer-Verlag.
Menard, S.W. (2002) ‘Longitudinal research. Series:
Quantitative Applications in the Social Sciences’,
USA: Sage Publications.
Mintzberg, H. (2009) ‘From Management Development to
Organization Development with Impact‘, OD
Practitioner, vol. 43, no. 3.
Rogers, E.M. (1995) ‘Diffusion of Innovations’, New
York: The Free Press.
Safir. E., Simonson, I. and Tversky, A. (1993) ‘Reason-
based choice’, Cognition, vol. 49, pp. 11-36.
Sammon JW (1969) ‘A nonlinear mapping for data
structure analysis’, IEEE Transactions on Computers,
vol. 18, pp. 401–409.
Swanson, E.B. (1994) ‘Information Systems Innovation
Among Organizations’, Management Science, vol. 40,
pp. 1069-1088.
Turk, D., France, R. and Rumpe, B. (2005) ‘Assumptions
underlying agile development processes’, Journal of
database management, vol. 16, pp. 62-87.
Xue, Y., Liang, H. and Boulton, W.R. (2008) ‘Information
technology governance in information technology
investment decision processes: the impact of
investment characteristics, external environment, and
internal context’, MIS Quarterly, vol. 32, pp. 67-96.
Yin, R.Y. (1994) ‘Applications of Case Study Research’,
Applied Social Research Methods series 34, London:
Sage Publications.
ActorsandFactorsinISProcessInnovationDecisions
209
