
A Media Tracking and News Recommendation System
Servet Tasci
and Ilyas Cicekli
Department of Computer Engineering, Hacettepe University, Ankara, Turkey
Keywords: Recommendation Systems, Content-based Filtering, Text Summarization, Text Classification.
Abstract: Nowadays, the amount of documents on internet resources is increasing at an unprecedented speed and
users are tired of searching important and related ones among enormous amount of documents. Users
require a personalized support in sifting through large amounts of available information according to their
interests and recommendation systems try to answer this need. In this context, it is crucial to offer user
friendly tools that facilitate faster and more accurate access to articles in digital newspapers. In this paper, a
time-based recommendation system for news domain is presented. News articles are recommended
according to user dynamic and static profiles. User dynamic profiles reflect user past interests and recent
interests play much bigger roles in the selection of recommendations. Our recommendation system is a
complete content-based recommendation system together with categorization, summarization and news
collection modules.
1 INTRODUCTION
The abundance of information with their dynamic
contents is available on the web. As there are many
documents and resources, it is difficult to find what
we need and where we can find them. Besides,
websites and web pages are doubled every year.
People are overwhelmed by the large amount of
information on the web, therefore information
overload problem is worsening at an unprecedented
speed. As a consequence, user modelling and
personalized information access are becoming
crucial. Users require a personalized support in
sifting through large amounts of available
information, according to their interests.
Many search engines have emerged to alleviate
this problem. These search engines use very large
databases to index websites, and reduce information
overload problem by allowing users a centralized
search. But still users are tired of looking which
documents are useful. Research results have shown
that users often give up their search in the first try,
examining no more than ten documents. This shows
us that users want from a web site recommendations
rather than search results.
When visiting a news website, users are looking
for new information that they have not known before
and that information will be an interest for them.
The kind of information that will be an interest for a
user depends on that user’s past activities. User
profiles are created in order to recommend related
items to users. Since user profiles are inferred from
past user activities, it is important to know how
effective they would be to predict user behavior.
The problem of recommending items has been
studied extensively, and two main paradigms have
emerged. Content-based recommendation systems
(Kompan and Graudina, 2010; Li et. al., 2010;
Goossen et. al., 2011) try to recommend items
similar to those that a given user has liked in the
past, whereas collaborative recommendation
paradigm identify users preferences are similar to
those of the given user and recommend items that
they have liked (Balabanovic, and Shoham, 1997).
These two approaches have their own strengths and
weaknesses. Hybrid recommender systems
(Cantador et. al., 2008) combine these approaches.
Li and Li (2013) use hypergraph learning for news
recommendation.
In this paper, we describe a content-based
recommender system for news domain. A content-
based recommender system consists of mainly three
steps: Content analyzer, profile learner and filtering
component. Content-analyzer extracts features from
unstructured text to produce a structured item
representation. Profile learner is the heart of a
recommendation system and it uses user feedbacks
which are usually inferred as explicit or implicit
53
Tasci S. and Cicekli I..
A Media Tracking and News Recommendation System.
DOI: 10.5220/0005072000530060
In Proceedings of the International Conference on Knowledge Discovery and Information Retrieval (KDIR-2014), pages 53-60
ISBN: 978-989-758-048-2
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

feedbacks. Explicit feedbacks are results of explicit
evaluations of items by users and they indicate
whether items are interesting or not to users. Implicit
feedbacks try to extract user interests from user click
behaviors. In our recommendation system, we use
explicit feedbacks and five-level ratings for user
feedbacks in evaluation. Filtering component
implements some strategies to rank interesting items
with respect to user profiles and generates
recommendations.
News domains have some special characteristics
(Saranya and Sadhasivam, 2012) and
recommendation systems have to deal with these
characteristics. Since a news domain contains a
large volume of information and documents are in
unstructured format, recommendation systems
require more computation power. News items
typically have short self-lives and recommendations
should be up-to-date. Since most news articles
describe specific events, recommended articles
should be related with interested events. The user
interest can easily shift from one event to another
event, and selection and ranking of news articles to
be recommended should be done according to this
fact.
In this paper, we present a content-based
recommendation system for news domain named as
HaberAnalizi. The presented recommender system
uses dynamic time-based user profiles that are
automatically updated. Recently read news articles
play more important roles in the creation of user
profiles. The recommender system described here is
a complete web site that collects news articles from
various online Turkish news websites and
recommends articles to its users. Everyday
approximately 1500 news articles are collected.
Then, these news articles are classified into eight
categories: Magazine, Economics, Politics, Culture-
Art, Techno-Science, Health, Sports and Education.
After that, news articles are recommended to users
according to their dynamic and static profiles. An
accurate profile of a user is critical for the success of
news recommendation system. So how we construct
user profiles plays an important role in the success
of the system.
The rest of the paper is organized as follows.
Section 2 presents the related work in news
recommendation domain. Section 3 explains the
details of our news recommendation system. Section
4 presents the performance evaluation of the system
and Section 5 concludes the paper and gives some
possible future work.
2 RELATED WORK
News recommendation has been studied for years
and some methods have been proposed and
evaluated. News-dude (Billsus and Pazzani, 1999) is
a news recommendation system uses TF-IDF values
combining K-Nearest Neighbor (KNN) algorithm
supporting a series of feedback options such as
"interesting", "not interesting", etc. Likewise in our
news recommendation system, we use five
categories to assess recommendations.
Liang and Lai (2002) propose a time-based
approach to build user profiles from browsing. They
calculated the user’s elapsed time while reading an
article and also they took into account the article’s
length and positions of the words in the document.
In contrast to our recommendation system, they do
not use news classification. They also calculate a
time range for document reading and this is not
proper because reader’s reading speed can vary.
They can have the first-rater problem since no static
profiling is used.
Tan and Teo (1998) present a personalized news
recommendation system named PIN. In this system,
users choose a list of keywords to be used in the
creation of their profiles and the system recommends
news according to these profiles. Since user profiles
are not updated, it is hard to make it dynamic, and
user interest changes cannot be reflected in profiles.
Liu et. al. (2010) present that user current
interests are critical for the success of a
recommendation system. Their system is also a
content-based recommendation system and they also
do not use collaborative filtering. In their system,
they construct user profiles automatically on any
interaction that user makes with the system and this
puts extra burden on their system. We update user
profiles daily not on each user interaction. Their
system infers user interests based on user click
behavior on the website. No rating or negative votes
are used for privacy reasons. In addition to the click
distribution of individual users, they calculated the
click distributions of the general public. When we
compare to this method with our approach, we give
more importance to ratings of last seven day clicks
of individual user in the creation of user dynamic
profiles and these profiles are updated daily. Public
trend is not important for our system. Likewise their
system and our system do not take into account of
time spent on the page.
Gong (2010) uses collaborative filtering based on
user clustering and item clustering. First of all, they
divide users into clusters using a clustering
algorithm based on some similarity threshold and a
KDIR2014-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
54

user-item matrix is created. Then item clusters are
created based on similarity measures. In order to
solve sparsity problem, they use expensive Pearson
similarity measure (McLaughlin and Herlocker,
2004) for new items that user has not rated yet.
News items are recommended using KNN algorithm
and the created user-item matrix. In our approach we
categorize news and for each category we use news
items that user has rated last week or user static
profiles if the user has not rated any news article.
Saranya and Sadhasivam (2012) collect
categorized news from news agencies and dump
them into a database. They use only one news
agency articles for categorization of articles and this
means that an article can be categorized differently
depending on which corpus is used. In our system
we use all news articles for categorization. Likewise,
they also use both static and dynamic profiles.
Dynamic user profiles are constructed during every
interactive search session. They use user clicks to
update dynamic profiles every time user reads a
news article. This can be costly to implement and
users do not want to wait for new news items on
online systems.
Li et. al. (2011) especially try to address issues
as news selection, news representation, news
processing, and user profiling. Their system consists
of three major components which are news article
clustering, user profile construction and news item
recommendation. News items are clustered using
hierarchical clustering. In order to build user
profiles, they use three dimensions: news content,
similar access patterns and preferred news entities.
User profiles and news articles are represented using
triplets in the form of <Topic vector, patterns,
entities>. For recommendation, similarity between
news item and user profile is computed. They
assessed their system in 15 days. First 5 days 50
users read news and then successive 10 days they
recommended news items to the volunteers. In our
system we collected the data approximately for
about 5 months.
3 A TIME-BASED
RECOMMENDATION SYSTEM
In this section we explain the details of our time-
based news recommendation system. Our
recommendation system is a complete system which
is designed as a website which collects news articles
from online Turkish newspapers and recommends to
its users. Although our recommendation system
domain is online Turkish news domain, it can be
adaptable to other news domains because the only
specific resource for Turkish language is a Turkish
stemmer. Other parts of the system are not language
dependent.
The major parts of our time-based news
recommendation system are as follows:
Getting News From News Sites
News Classification
Summarization of News
Profile Construction
News Recommendation
First of all, obtaining news from substantial news
sites are explained, and then how categories of news
items are found are explained. Our recommendation
system can also produce summaries of news articles
using a text summarization system (Ozsoy et. al.,
2011). Later we explain the creation of static and
dynamic user profiles. Finally, we explain our news
recommendation approach at the end of this section.
3.1 Getting News from News Sites
Obtaining news contents from online news sites is
not a trivial job. Because news sites publish news
articles as parts of HTML pages and we have to
obtain contents of news articles. An HTML page
contains advertorial part, content part, links part and
other parts, etc. We need just news content of the
page. In order get the content of a news article, we
use XML Path Language (XPath) expressions. Each
news site has its own characteristics and contents of
news articles are extracted using news sites
characteristics and XPath expressions. After the
content part of a news article is extracted, it is feed
into the rest of the recommendation system.
Approximately from twenty online news sites we
obtain approximately 1500 news articles every day.
Lengths of news articles vary from a couple of
sentences to longer documents. Contents of news
articles are extracted and they are prepared for the
rest of the system in order to be recommended to
users.
3.2 News Classification
Most of news sites do not classify news articles.
Even if they classify, classifications of news articles
are so different at each news site. For example while
a news item’s category is politics in a web site, the
other web site could categorize it as economics. So
we have to classify them for standardization and
obtaining better recommendations to users. After
AMediaTrackingandNewsRecommendationSystem
55

news sites are analyzed, we have determined eight
categories for classification: Magazine, Economy,
Politics, Culture-Art, Techno-Science, Health,
Sports and Education.
Most of classification algorithms are based on
the single term analyses of the text, e.g. vector space
model (Salton and McGill, 1986). On this context
every document can be thought as a vector. Each
word in the document can be thought as an attribute
of the document.
Figure 1: Classification of News Articles.
Some main online news sites categorize daily
news, and we used 40,000 articles with known
categories from these sites as our corpus for
categorization. Using these categorized news
articles, we determined subtle words computing their
frequencies. A news article and each category can
be shown as a vector of pairs of words and their
normalized frequencies. The normalized frequency
of a word is computed by dividing its frequency in
document with the total number of words in that
document. After that, we have tested different
similarity measures for classification with our
corpus of 40000 news articles with known
categories. The details of our corpus are given in
Figure 1.
Jaccard Cosine Euclidean SVM
Education 0,65 0,52 0,40 0,60
Economy 0,75 0,47 0,35 0,70
Magazine 0,65 0,50 0,42 0,60
Culture-Art 0,70 0,45 0,40 0,70
Politics 0,67 0,40 0,30 0,72
Health 0,82 0,45 0,60 0,75
Sports 0,80 0,70 0,65 0,70
Techno-Science 0,75 0,55 0,35 0,70
TOTAL 0,75 0,53 0,48 0,70
Figure 2: Accuracy Results of Classification Algorithms.
The classification methods that are tested with our
corpus are Support Vector Machines (SVM),
Euclidean Similarity, Cosine Similarity and Jaccard
Similarity. Precision results of these methods on our
corpus are given in Figure 2 and it can be seen that
Jaccard Method gives better results than other
methods for our corpus. So we have decided to use
Jaccard method for the classification of news articles
in our system. We tried to eliminate the over-fitting
problem using as much as many words as feature
values.
For classification we use stop word elimination
and stemming. We remove approximately 150 stop
words from our news article. We also stem words
using a Turkish stemmer named Zemberek (Akın
and Akın, 2007).
3.3 Summarization of News Articles
News articles generally consist of few topics. These
topics form main contents of news articles and some
of these topics are explained deeply. A good
summary of an article should cover major topics in
that article. Summaries can have different forms
(Hahn and Mani, 2000) and they are commonly
obtained by sentence extraction or abstraction
methods. Although abstraction methods can provide
sophisticated summaries and they are hard to
implement. On the other hand, sentence extraction
approaches are easy to adapt and they can still
produce useful summaries.
Since users want to read more news in short
time, we use a summarizer in our recommender
system to accomplish this need. We adapted a
sentence extraction based summarization system
(Ozsoy et. al., 2011) in order to generate summaries
of news articles. We generate summaries whose
lengths 30% of original news articles using this
summarization system.
3.4 Profile Construction
A personalized recommendation system needs user
characteristics to recommend items. For that reason,
the construction of user profiles is a crucial part of a
recommendation system. In order to construct
individual user profiles, the required information can
be collected explicitly through direct user
intervention, or implicitly through agents that
monitor user activities. Profiles that can be modified
or augmented are considered as dynamic, in contrast
to static profiles that maintain the same information
over time. Most recommender systems use both
static and dynamic profiles. Static profiles are used
KDIR2014-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
56

to solve cold-start problem in recommender systems.
If keywords are given for categories in a static
profile, recommendations are based on these
keywords and this solves some parts of cold-start
problem. If no keywords are given in a static profile,
we recommend most recommended news to that user
in order to solve cold-start problem. As users read
more news articles, their dynamic profiles improve.
In our system, we use both dynamic and static
profiles for recommendation. A comprehensive
survey of various user profile construction
techniques is provided in (Gauch et. al., 2007).
A static or dynamic profile consists of a set of
probabilities for categories and a list of interest
words for each category. Summation of all
probability values in a profile is equal to 1 and the
probability value of a category indicates the
percentage of user’s interest in that category. The
probability value of a category determines the
amount of news articles that will be recommended to
that user. The interest words of a category are a set
of pairs of words together with their normalized
weights. The weight of an interest word is the
normalized frequency of that word and reflects the
amount of user interest to articles containing that
word. The interest words of a category are used to
select news articles in that category for
recommendation to the user. A sample profile will
be as follows:
Profile = {
Magazine : 0.20, MagazineWords,
Economy : 0.15, EconomyWords,
Politics : 0.25, PoliticsWords,
Culture-Art : 0, {},
Techno-Science: 0.12, ScienceWords,
Health : 0.08, HealthWords,
Sports : 0.16, SportsWords,
Education : 0.04, EducationWords
}
In our recommender system, users fill profile
forms and give interest words for categories. This
information is used in the creation of a static profile.
From given information, a static profile is created.
The probability value of each category in a static
profile is the same and this means that same amount
of articles is recommended for each category if a
static profile is used for recommendation. The
interest words of a category are the words given for
that category when the user fills a profile form. If the
user does not give any interest words for a category,
no articles in that category are recommended to that
user when that static profile is used for
recommendation.
Dynamic profiles are constructed according to news
articles read by users. For each user, two dynamic
profiles are created if that user reads news articles
regularly. The first dynamic profile is the last week
dynamic profile and it is constructed if the user has
read news article during last seven days. The second
dynamic profile is the last month dynamic profile
and it is created according to news articles read by
that user during last 30 days.
If a user has rated news items in last seven days
the last week dynamic profile is created using the
news items that are rated as interesting by the user in
the last seven days, and news article
recommendations are done according to this last
week dynamic profile. If a last week dynamic profile
is not constructed for a user, the last month dynamic
profile of that user is used for recommendation if
that profile is available. If no news articles are read
by a user in the last month, no dynamic profiles will
be available for that user and the static profile for
that user is used for recommendation.
Dynamic profiles of a user are updated once
every day. Recently read news articles are more
likely to indicate user’s current interests. For that
reason, news articles read in the last days have more
weights in profile constructions. Thus, the effect
values of words appearing in recent day articles are
multiplied with bigger weights than words in older
day articles. Weights used in the construction of
dynamic profiles decrease gradually towards past.
These weight values are determined using news
reading trends of users.
Category probability values are updated
according to the articles read in that category. Before
category interest words are updated with an
interested article, stop words are eliminated from
article words and article words are stemmed. Interest
words in the profile are updated with these stemmed
words. Frequency values of article words are used
when updating weights of interest words in dynamic
profiles.
3.5 News Recommendation
A typical recommendation system consists of an
object set and a user set (Zhou et al. 2007). The aim
of a recommendation system is to meet the
requirements of users using this object set. In our
recommendation systems, the object set is the set of
daily news articles. Furthermore, a recommendation
system should be able to suggest objects to users,
which users would not discover for themselves
(Zhou et al. 2010) because of huge amount of
objects. Our recommendation system tries to
AMediaTrackingandNewsRecommendationSystem
57

suggest news articles to users from a huge set of
daily news articles.
Our recommendation system collects daily news
articles from online newspaper sites. Everyday
approximately 1500 news articles are collected from
these newspaper sites. Our recommendation system
recommends N daily articles to a user depending on
that user’s profiles where N is set to 50 in our
evaluation sessions. Categories of daily collected
news articles are computed by the categorization
module of our system.
In order to recommend news articles to a user,
first a profile of the user is determined for
recommendation according to the user’s history. If
the user read and rated news articles in last seven
days, the last week dynamic profile is used for
recommendation. If the user has not read any article
in the last week, the last month dynamic profile is
used. If no dynamic profile available for the user, the
static profile is used.
After a profile of a user is selected, news
recommendations are done with respect to that
profile. For each category Ci, the number (N
Ci
) of
news articles that will be recommended for that
category is determined by multiplying the
probability value of that category with the total
number (N) of articles to be recommended. Then
articles in category Ci of daily news articles are
compared with the category interest words in the
profile in order to measure similarities of articles
with the category interest words. The most N
Ci
similar articles are recommended to the user for the
category.
The similarity of a news article with interest
words is measured using the cosine similarity
measure. Stop words are eliminated from article
words and article words are stemmed before they are
compared with interest words. Title words of an
article have more weights in the computation of the
similarity measure than regular article words.
4 EVALUATION
Evaluation of a recommendation system is important
for determining the efficiency of the system There
are many evaluation methods in order to evaluate a
recommendation system such as precision and recall
values, MAE (mean absolute error) value, RMSE
(root mean squared error) value and ROC (receiver
operating characteristic) analysis. For example,
Cinematch system in the Netflix prize competition
evaluates itself using RMSE (Bennett and Lanning,
2007). For our recommendation system, we use
precision, recall, f-measure and accuracy values for
evaluation, and we also give the ROC analysis of
our results.
In order to verify the efficiency of our proposed
recommendation system, we tested it for five months
on 30 users with approximately 1500 news items per
day. Daily 30-50 news articles are recommended to
each user. If a user has a dynamic profile, always 50
articles are recommended. After reading
recommended news, users are asked to evaluate
recommended news by clicking one of five rankings:
not interested, less interested, no comment,
interested, mostly interested. Users are assumed that
they are interested with an article if they select one
of three choices (no comment, interested, mostly
interested) since no-comment choice in our
evaluations reflects some interest in articles.
Then we randomly selected 20 days and 20 users
who rated all of 50 recommended articles daily.
Thus we collected 20,000 rated articles by users. All
recommendations are made according their dynamic
profiles. For these 20,000 rated articles, ratings and
distributions over categories are given in Figure 3.
The average accuracy result for all categories is 0.59
and Magazine category has the highest accuracy
result. According to Figure 3, some interesting
results can be inferred for each category. Users
mostly interested news items in Sports, Magazine
and Politics categories.
Not Interested
Less Interested
No Comment
Interested
Mostly Interested
N
um
b
er o
f
Recommended
Articles
Accuracy Results
Education 210 267 380 193 65 1115 0.57
Economy 343 442 613 435 145 1978 0.60
Magazine 638 815 1103 1006 500 4062 0.64
Culture-Art 345 267 225 295 125 1257 0.51
Politics 575 703 585 897 215 2975 0.57
Health 223 137 145 115 65 685 0.47
Sports 975 1370 1670 1572 820 6407 0.63
Techno-Science 336 610 245 195 135 1521 0.38
TOTAL 3645 4611 4966 4708 2070 20000 0.59
Figure 3: Evaluation Results for Rated Articles.
For any recommendation system it is hard to
determine the number of items to be recommended
to users. If the number of recommended items is
KDIR2014-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
58
high, the recommended items may contain too many
unrelated items and users will be unhappy with this
result. On the other hand, if fewer items are
recommended, users may not be satisfied from this
result either. For this reason, we decided to compute
optimum news count for recommendation in our
system.
In order to compute optimum news count, we
made a detailed analysis on the results given in
Figure 4. According to the accuracy result (0.59) in
Figure 4, users approximately found 29 articles to be
interesting out of 50 recommended articles on the
average. Recommended 50 articles were sorted
according their similarity values and they were
presented users in the decreasing order. We checked
the number of articles found to be interesting in top
10, 20, 30, 40 and 50 recommended articles, and
Precision, Recall and F-Measure results are
presented in Figure 4. According the results in
Figure 4, best precision and f-measure results are
obtained in top 30 recommended articles and this
indicates that optimum news count for our system is
around 30. This means that users approximately find
22 articles interesting out of 30 recommended
articles. Since the precision results for top 10 and 20
are not high enough, our similarity measure can be
improved in order to move interesting articles into
higher ranks.
Number of
Recommended
Articles
Precision
Recall
F-Measure
Accuracy
10
0.60 0.20 0.30 0.44
20
0.70 0.45 0.55 0.60
30
0.73 0.76 0.75 0.70
40
0.63 0.86 0.72 0.62
50
0.59 1.00 0.73 0.59
Figure 4: Computation of the Optimum News Count.
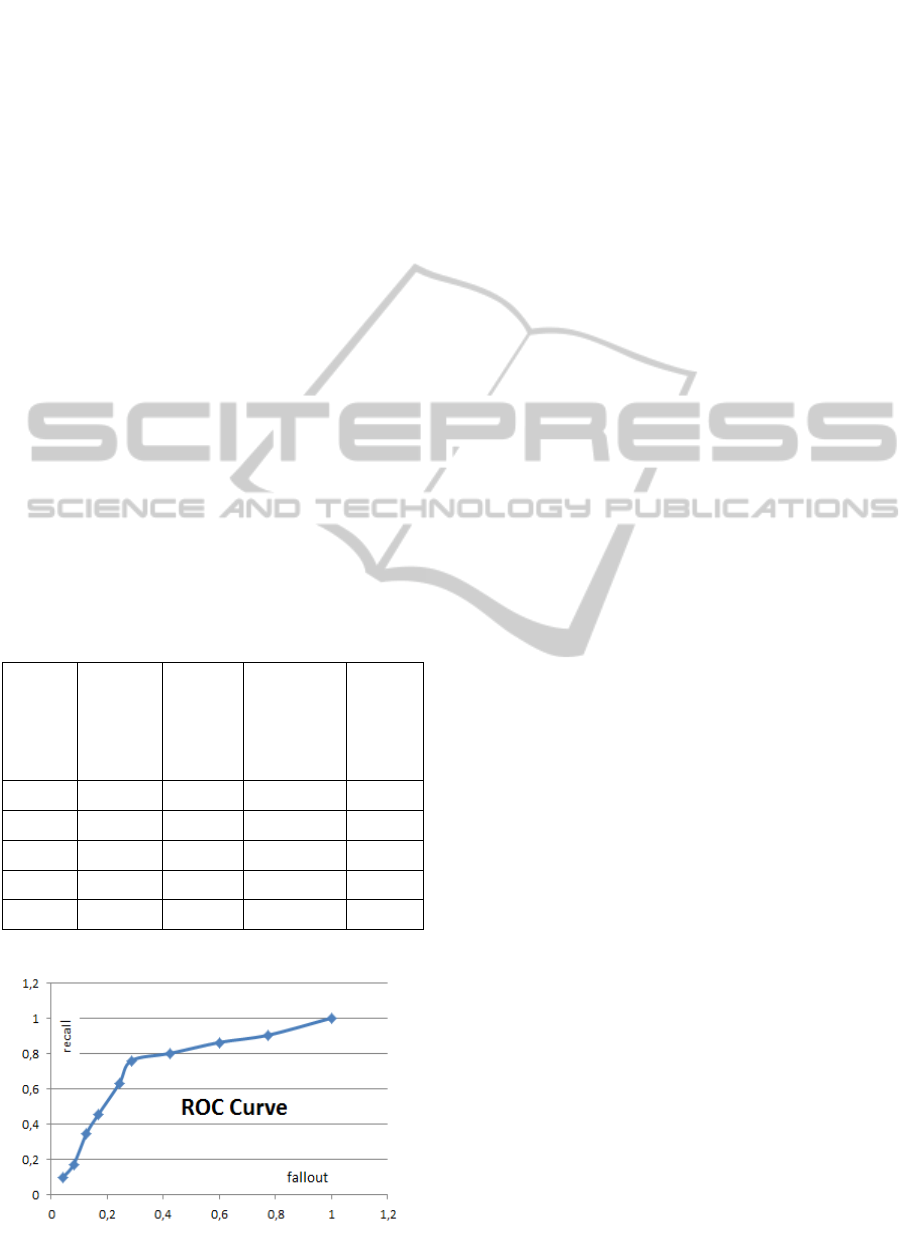
Figure 5: ROC Curve for Optimum News Count.
As seen in the ROC curve graph representing recall
against fallout in Figure 5, recall value increasing
rapidly until news count value reaches 30 then it
increases slowly until value reaches 50. This means
that 30 is the optimum news count for our system.
ROC curves reflect precision/recall optimization for
systems (Davis and Goadrich, 2006; Fisher et. al.,
2004).
5 CONCLUSION
Our news recommendation system is a time-based
recommendation system and selects items for
recommendation with respect user past interests.
User past interests are represented by dynamic
profiles and dynamic profiles reflect user interests
for categories and user interest words for categories.
Articles for recommendation are selected depending
on their similarities with category interest words.
Our recommendation system is a complete
recommendation system together with a news
categorization module, a news summarization
module and collection module for collecting news
articles from online news sites. Users can read
recommended daily news articles or they can browse
all daily news in each category.
Users can rate news articles by explicitly giving
a score between 1 and 5. User interest on article can
be determined by an explicit evaluation by user
same as in our system or user clicks together with
amount of time spent to read that article. We
selected the first approach because of its simplicity
and clear rating mechanism. In bigger systems, user
may not want to explicitly evaluate recommended
articles, so the second approach may more
appropriate for collection user interests.
The performance of our system is affected by the
performance of similarity measurement between
articles and user profiles. Different similarity
methods can be used in order to improve
performance. For example, keyphrases are important
for news recommendation systems and keyphrases
can be used to measure similarity between
documents. So a keyphrase based similarity
algorithm can be used for our system in future.
Our news recommendation system focuses on
selecting most interesting news articles that are
similar news articles read by users before. However,
readers can be burdened by more or less identical
ones among returned news articles. Detection of
news articles with identical contents can be useful to
assist users in further reading and helping readers
skip similar articles.
AMediaTrackingandNewsRecommendationSystem
59

REFERENCES
Akın A.A., Akın, M.D. 2007. Zemberek, an open source
NLP framework for Turkic languages. Available at
http://zemberek.googlecode.com/.
Asanov, D., 2011. Algorithms and Methods in
Recommender Systems. Berlin Institute of
Technology, http://www.snet.tuberlin.
Balabanovic, M., Shoham, Y. 1997. Fab: Content-based,
Collaborative Recommendation. Communications of
the ACM 40(3), pp:66-72.
Bennett, J.. Lanning S. 2007. The netflix prize. In
Proceedings of KKDD cup and workshop, p. 35.
Billsus, D., Pazzani, M. 1999. A hybrid user model for
news story classification. In Proceedings of the
Seventh International Conference on User Modeling.
Banff, Canada, pp. 99-108.
Cantador, I., Bellogín, A., Castells, P.. 2008. Ontology-
Based Personalised and Context-Aware
Recommendations of News Items. In Proceedings of
the 2008 IEEE/WIC/ACM International Conference on
Web Intelligence and Intelligent Agent Technology.
O'Conner, M., Herlocker, J. 1999. Clustering items for
collaborative filtering. In Proceedings of the ACM
SIGIR Workshop on Recommender Systems, Berkeley,
CA.
Davis, J., Goadrich, M. 2006. The relationship between
precision recall and roc curves. In Proceedings of the
23rd international conference on machine learning
(ICML).
Fisher, M. J., Fieldsend, J.E., Everson R. M. 2004.
Precision and recall optimisation for information
access tasks. In first workshop on roc analysis in AL.
European conference on artificial intelligence
(ECAI'2004), Valencia, Spain.
Gauch, S., Speretta, M., Chandramouli, A., Micarelli, A.
2007. User profiles for personalized information
access. In: Brusilovsky, P., Kobsa, A., Nejdl, W. (eds.)
The Adaptive Web: Methods and Strategies of Web
Personalization. LNCS, Vol. 4321, pp. 54–89.
Springer, Heidelberg.
Gong, S. 2010. A Collaborative Filtering
Recommendation Algorithm Based on User Clustering
and Item Clustering. Journal of Software, Vol. 5, No.
7, pp. 745-752.
Goossen, F., IJntema, W. Frasincar, F., Hogenboom, F.,
Kaymak. U. 2011. News personalization using the CF-
IDF semantic recommender. In Proceedings of the
International Conference on Web Intelligence, Mining
and Semantics (WIMS '11).
Hahn, U., Mani, I. 2000. The challenges of automatic
summarization. Computer, 33, pp. 29–36.
Hovy, E., Lin, C-Y. 1999. Automated Text Summarization
in SUMMARIST. I. Mani and M.T. Maybury (eds.),
Advances in Automatic Text Summarization, The MIT
Press, pp. 81-94.
Kompan, M., Graudina, V. 2010. Content-based news
recommendation.
In Proceedings of the 11th
Conference EC-WEB, pp. 61-72.
Li, L., Chu, W., Langford, J., Schapire, R.E. A 2010.
Contextual-Bandit Approach to Personalized News
Article Recommendation. In Proceedings of the 19th
international conference on World wide web, pp. 661-
670.
Li, L., Li, T. 2013. News recommendation via hypergraph
learning: encapsulation of user behavior and news
content. In Proceedings of the sixth ACM international
conference on Web search and data mining. pp. 305-
314
Liang, T.-P., Lai, H-J. 2002. Discovering User Interests
from Web Browser Behavior: An Application to
Internet News Services. In Proceedings of 35th
Annual Hawai'i International Conference on Systems
Sciences. IEEE Computer Society Press.
Li, L., Wang, D., Li, T., Knox, D., Padmanabhan, B. 2011.
SCENE: A scalable two-stage personalized news
recommendation system. In Proceedings of the 34th
Annual International ACM SIGIR Conference on
Research and Development in Information Retrieval,
Beijing, China, pp.124-134.
Liu, J., Dolan, P., Pedersen, E.R. 2010. Personalized News
Recommendation Based on Click Behavior. In
Proceedings of the 14th International Conference on
Intelligent User Interfaces, Hong Kong, China.
McLaughlin, M.R, Herlocker, J.L., 2004. A Collaborative
Filtering Algorithm and Evaluation Metric that
Accurately Model the User Experience, Proceedings
of the 27th annual international ACM SIGIR
conference on Research and development in
information retrieval, Sheffield, United Kingdom.
Ozsoy, M.G., Cicekli, I., Alpaslan, F.N. 2011 Text
Summarization using Latent Semantic Analysis,
Journal of Information Science, Vol. 37, No. 4,
pp:405-417.
Radev, D.R., Fan, W., Zhang, Z. 2001. WebInessence : A
Personalized Web-Based Multi-Document
Summarization and Recommendation System, In
Proceedings of the NAACL-01, pp. 79–88.
Salton, G., McGill, M.J. 1986. Introduction to Modern
Information Retrieval, McGraw-Hill, Inc, New York,
NY.
Saranya, K.G., Sadhasivam, G.S. 2012. A Personalized
Online News Recommendation System. International
Journal of Computer Applications, 57.
Tan, A.-H., Toe. C. 1998. Learning user profiles for
personalized information dissemination. In
Proceedings of 1998 IEEE International Joint
Conference on Neural Networks, Alaska, pp: 183-188.
Zhou, T., Ren, J., Medo, M., Zhang, Y. 2007. Bipartite
network projection and personal recommendation.
Phys. Rev. E 76, 046115.
Zhou, T., Zoltan, K., Liu, J., Medo, M., Wakeling, J. R.,
Zhang, Y. 2010. Solving the apparent diversity-
accuracy dilemma of recommender systems. In
Proceedings of the National Academy of Sciences,
107(10), 4511-4515.
KDIR2014-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
60
