
Towards Identification of Operating Systems from the Internet Traffic
IPFIX Monitoring with Fingerprinting and Clustering
Petr Matouˇsek, Ondˇrej Ryˇsav´y, Matˇej Gr´egr and Martin Vyml´atil
Brno University of Technology, Boˇzetˇechova 2, Brno, Czech Republic
Keywords:
Operating Systems, Identification, Fingerprinting, Clustering, Monitoring, IPFIX.
Abstract:
This paper deals with identification of operating systems (OSs) from the Internet traffic. Every packet injected
on the network carries a specific information in its packet header that reflects the initial settings of a host’s
operating system. The set of such features forms a fingerprint. The OS fingerprint usually includes an initial
TTL time, a TCP initial window time, a set of specific TCP options, and other values obtained from IP
and TCP headers. Identification of OSs can be useful for monitoring a traffic on a local network and also
for security purposes. In our paper we focus on the passive fingerprinting using TCP SYN packets that is
incorporated to a IPFIX probe. Our tool enhances standard IPFIX records by additional information about
OSs. Then, it sends the records to an IPFIX collector where network statistics are stored and presented
to the network administrator. If identification is not successful, a further HTTP header check is employed
and the fingerprinting database in the probe is updated. Our fingerprinting technique can be extended using
cluster analysis as presented in this paper. As we show the clustering adds flexibility and dynamics to the
fingerprinting. We also discuss the impact of IPv6 protocol on the passive fingerprinting.
1 INTRODUCTION
Knowledge of operating systems can be an impor-
tant information for network security and monitoring.
From the point of view of an attacker, the knowledge
of the targeting system helps him to choose his strat-
egy and identify where critical files or resources are
stored and how can be weaknesses of the system ex-
ploited (Sanders, 2011).
Detecting connected hosts and identifying oper-
ating systems is also useful for maintaining a site
security policy (Lippmann et al., 2013). The pol-
icy may specify the types of hosts that are allowed
to connect to the local network (LAN). OS finger-
printing can help a network administrator to detect
unexpected devices like smart-phones, WiFi access
points, or routers using fingerprints of their OSs (An-
droid, Cisco IOS). The knowledge of OSs in the LAN
can help a network administrator to find out how
many operating systems are currently employed in
the LAN, if there are potential vulnerabilities related
to unpatched software, which hosts use obsolete sys-
tems and should be updated, etc. OS fingerprint-
ing techniques can be also used for NAT detection
(Krmicek, 2011).
OS fingerprintingcan be defined as ”an analysis of
certain characteristics and behaviors in network com-
munication in order to remotely identify an OS and
its version without having direct access to the sys-
tem itself” (Allen, 2007). The technique relies on dif-
ferences among implementations of OSs and TCP/IP
stacks that have an impact on certain values in IP
or TCP headers of packets generated by these sys-
tems. Having a database of typical OS features (called
OS signatures), we are able to identify with a certain
probability by which OS a packet was sent.
There are two types of OS fingerprinting: passive
and active. Passive fingerprinting only listens to the
packets on the networks. When a packet is received,
passive fingerprinting extracts needed values of TCP
or IP header fields in order to detect an OS using a OS
fingerprint database. If a host does not send an ex-
pected type of data like TCP SYNs, DHPC requests,
HTTP requests, or does not communicate at all, pas-
sive fingerprinting cannot be used. Active fingerprint-
ing is a complementary technique that actively sends
special packets to a targeted host in order to elicit
replies that will reveal an operating system of the tar-
get. In comparison to the passive fingerprinting, the
active fingerprinting is not transparent from the point
of view of network communication. There are sev-
eral tools implementing both the passive fingerprint-
21
Matoušek P., Ryšavý O., Grégr M. and Vymlátil M..
Towards Identification of Operating Systems from the Internet Traffic - IPFIX Monitoring with Fingerprinting and Clustering.
DOI: 10.5220/0005099500210027
In Proceedings of the 5th International Conference on Data Communication Networking (DCNET-2014), pages 21-27
ISBN: 978-989-758-042-0
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

ing like
p0f
,
ettercap
, or the active fingerprinting,
e.g.,
nmap
.
Key factors for successful classification of an OS
using the fingerprinting includes a proper selection
of OS features to be compared, an up-to-date OS
signatures database, and a technique that is used
to classify features obtained from a packet header
with a fingerprinting database. Common fingerprint-
ing features used for OS identification can be ex-
tracted, for example, from a IP header (TTL, Don’t
Fragment bit, Packet Size), or a TCP header (TCP
Windows size, Max Segment Size, Options, etc.)
(Lippmann et al., 2013).
Classification can be based on a perfect match-
ing when packet features must exactly match one of
the OS signatures in database. It is also possible to
use an approximate matching where only few fea-
tures match an OS signature and the best possible
(but imprecise) selection of OS is returned. There are
also advanced classification methods using machine
learning algorithms (Caballero et al., 2007), cluster-
ing (Jain, 2010), or fractal geometry and neural net-
works (Zelinka et al., 2013).
In our work we focus on the passive finger-
printing that is incorporated into IPFIX frame-
work (Claise et al., 2013; Claise and Trammel, 2013)
where an IPFIX probe scans incoming packets, ex-
tracts relevant features from IP, TCP, or even ap-
plication headers, and creates an extended IPFIX
record (Claise, 2004) with additional information
about senders’ OSs. Because an IPFIX probe is a
passive monitoring device, we are interested only in
passive fingerprinting methods. For monitoring pur-
poses, fast on-line processing of incoming packets
is preferred over accuracy of the classification. In
this paper, we present our technique for fast on-line
OS identification using passive fingerprinting. This
method was implemented as a plugin into the IP-
FIX probe. Our classifier uses a special OS signa-
ture database where eight OS features of a packet are
tested. The database contains signature classes of ma-
jor operating systems (Windows, Linux, BSD, Mac
OS, Android, Palm OS). Classification is made if the
perfect match of at least six SYN packet features is
found. If the matching is not successful, further check
is done using HTTP header. If such header is a part
of TCP communication, HTTP User-agent field is ex-
tracted. Based on these data, a new signature contain-
ing current packet features is generated and automat-
ically added to the OS signature database.
Our results show that this approach is feasible and
give good results. During our test we observed that
small variations of observed features can causes the
system to be classified as unknown because the per-
fect match is required. This can be improved using
classification based on cluster analysis. This tech-
nique is not dependent on a fixed OS fingerprinting
database and perfect matching since the clustering
measures similarity between classified objects. This
paper shows a proposal of this architectures and dis-
cusses its pros and cons.
1.1 Contribution
Main contribution of this positional paper is de-
sign and implementation of the passive fingerprinting
within a scheme of IPFIX monitoring. We present
our classification database and discuss our first re-
sults that are compared with
p0f
. Further, we pro-
pose an extension of the system using cluster analysis
that helps to decrease false negatives. We also discuss
an impact of IPv6 protocol on passive fingerprinting
because IPv6 and IPv4 headers differ and the same
features cannot be used without additional tests and
observation of different IPv6 implementations. To our
best knowledge, we are not aware of studies describ-
ing implementation of OS fingerprinting within IP-
FIX framework and application of the cluster analysis
in OS classification.
1.2 Structure of the Paper
The paper is structured as follows. Section 2 dis-
cusses current fingerprinting techniques and results
published in recent years. It also proposes open ques-
tions and areas to be explored, especially in IPv6 OS
fingerprinting. Section 3 shows an architecture of our
tool and presents the first results. Section 4 describes
a concept of the cluster analysis applied on the area
of OS fingerprinting and future steps in our research.
The last section summarizes our current work.
2 STATE OF THE ART
Passive and active fingerprinting techniques and tools
were explored in previous years. The main motiva-
tion of that research was network security and con-
figuration of network-based intrusion detection sys-
tems using information about OSs from incoming
packets. General principles of OS fingerprinting and
common fingerprinting techniques are described in
(Allen, 2007).
(Lippmann et al., 2013) focuses on accuracy of
passive OS fingerprinting and the evaluation of com-
mon tools like
nmap
,
siphon
,
p0f
, and
ettercap
.
It discusses quality of different features, the number
DCNET2014-InternationalConferenceonDataCommunicationNetworking
22

of features to be used for classification and the struc-
ture of OS signature databases. This paper also talks
about reliability of commonly used features and how
can be changed by intermediate network devices or an
attacker.
The main limitation of techniques based on OS
signatures is to keep database up-to-date when new
versions and implementations of OSs appear. Other-
wise, modern operating systems remain unrecognized
during classification. To overcome this issues, ad-
vanced methods for automated generation of OS sig-
natures were explored. One of the first attempt was
FiG tool presented by (Caballero et al., 2007). This
tool automatically explores a set of candidate queries
and applies a machine learning technique to identify
the set of valid queries. A similar approach was also
proposed by (Schwartzenberg, 2010) where a classi-
fier based on neural networks was introduced. How-
ever, these techniques have their limits as proved by
(Richardson et al., 2010). In their work, the authors
argue that OS signatures that are generated automati-
cally using machine learning techniques are not viable
because of over-fitting, indistinguishability, biases in
the training data, and missing semantic knowledge of
protocols. The authors recommend to add an expert
knowledge or manual intervention in the process of
putting new OS signatures into the OS database. Oth-
erwise, the accuracy of detection is very low.
Our goal is similar to the previous authors—to
automatically update an OS signature database with-
out human intervention based on incoming packets.
However, our technique is different. First, we ex-
plore HTTP application header for OS type specifi-
cation and if it is found, a set of features from IP and
TCP headers is used to form a new OS fingerprint en-
try that is added to the database. Seconds, the cluster
analysis can be applied to identify the best possible
match of an OS.
Another part of work concerns on the
impact of migration from IPv4 to IPv6
(S.Deering and R.Hinden, 1998). There are sev-
eral studies describing differences between these
two protocols and challenges for OS fingerprint-
ing over IPv6 (Nerakis, 2006). Most of these
studies, e.g., (Beck et al., 2007), employ the ac-
tive fingerprinting using Neighbor Discovery
Protocol (T.Narten et al., 2007) for OS identi-
fication. However, most of these approaches
does not reflect recent changes in standardiza-
tion of IPv6 extended headers defined by RFC
7045 (Carpenter and Jiang, 2013) and RFC 6564
(Krishnan et al., 2012). (Eckstein, 2011) describes
major challenges and limitation of IPv6 OS finger-
printing only theoretically. To our best exploration,
there are no thorough experiments showing how IPv6
passive fingerprinting works in real systems. Thus,
we decided to extent our tool with IPv6 and to show
how IPv6 features in combination with TCP and
cluster analysis can be employed for successful OS
identification.
3 FINGERPRINTING AND IPFIX
In our research, we apply a technique of the passive
fingerprinting on the area of network monitoring us-
ing IPFIX framework. The main concept we used
is derived from Michal Zalewski’s approach imple-
mented in
p0f
1
that identifies OSs using TCP SYN
or SYN+ACK packets. The tool checks selected val-
ues from IP headers (TTL, DF bit, ToS), TCP head-
ers (Window size, options), or HTTP headers (User-
Agent field) and comparesthem with OS signaturesin
a database that currently contains about 300 entries.
P0f
database is composed of TCP signatures, HTTP
signatures and MTU signatures. It uses TCP SYN,
TCP SYN+ACK, HTTP request, or HTTP response
for classification. The result of classification is (i) a
perfect match, (ii) a fmatch (small deviation in some
values), or (iii) unknown.
3.1 OS Signatures
We decided to implement a lightweightversion of
p0f
approach. We use only SYN packets and HTTP head-
ers to obtained OS features. Since we are not in-
terested in minor differences between OSs (like ver-
sions, kernel numbers, etc.) our database contains
only several classes of major OSs. Our set of features
includes three IP fields (TTL, DF bit, packet size) and
five TCP fields (Max segment size, Selective ACK,
Window size, number of NOPs—No operation bytes,
and Window scale). Since TTL is decremented by ev-
ery L3 device, we don’t look at a certain value but for
an interval. Our signature database was based on
p0f
database, observations published in (Sanders, 2011),
and our experiments. The database values for major
OS classes are shown in Table 1. Linux values were
tested on Ubuntu and Red Hat distributions. We can
see that the most important features where OSs differ
at most are SYN packet size, number of NOPs, and
Win Scale.
We test eight features for OS identification,but the
perfect match on all features is not required. Table 2
shows that the higher number of perfectly matched
1
p0f stands for Passive OS Fingerprinting, see
http://lcamtuf.coredump.cx
TowardsIdentificationofOperatingSystemsfromtheInternetTraffic-IPFIXMonitoringwithFingerprintingand
Clustering
23
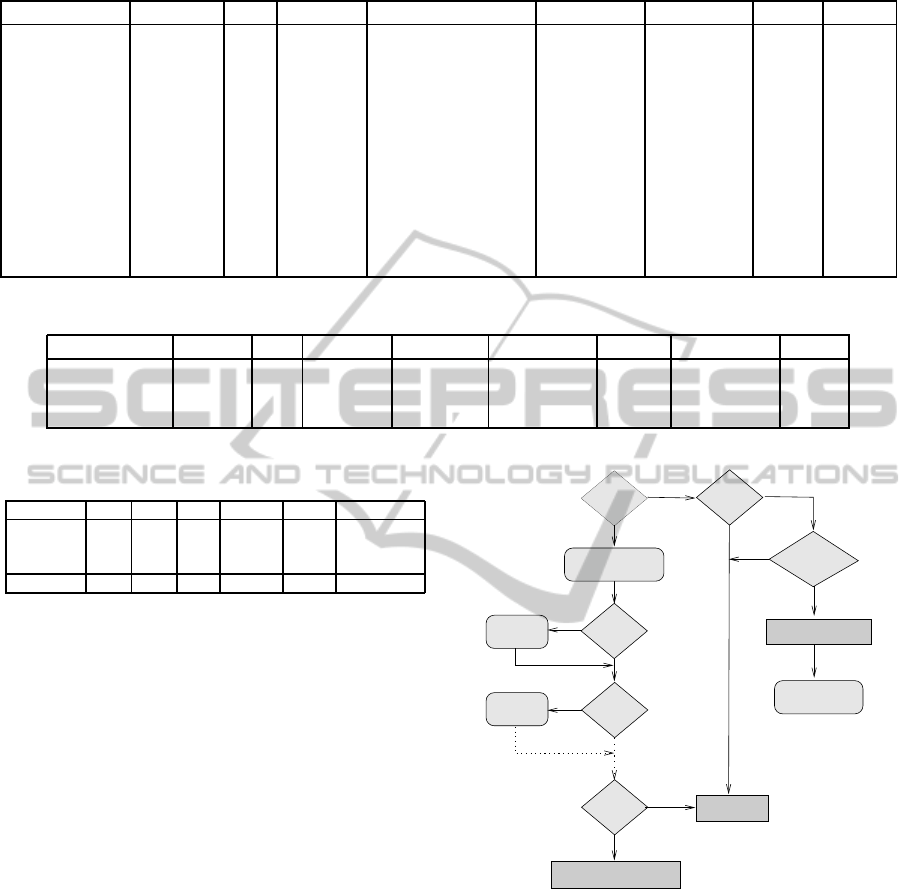
Table 1: OS signature database.
OS TTL DF Pkt size Win Size Win Scale MSS SAck NOPs
Windows XP 64–128 Set 48 variable 0 1440,1460 Set 2
Windows 7 64–128 Set 52 variable 2 1440,1460 Set 3
Windows 8 64–128 Set 52 variable 8 1440,1460 Set 3
Linux 0–64 Set 60 2920–5840,14600 3 1460 Set 1
FreeBSD 0–64 Set 60 65 550 7 1460 Set 1
Mac OS 0–64 Set 64 65 535 4 1460 Not 3
Android 4.x 0–64 Set 52,60 65 535 6 1460 Set 3
Symbian 128–255 Not 44 8 192 0 1460 Not 0
Palm OS 128–255 Not 44 16 348 0 1350 Not 0
NetBSD 0–64 Set 64 32 768 0 1416 Not 5
Open BSD 0–64 Set 64 32 768 0 1440 Set 5
Table 3: Comparison of Win 7 and Win 8 features.
OS TTL DF Pkt size Win size MSS NOPs Win Scale SAck
Win 7 Home 128 Set 52 8192 1440,1460 3 8 Set
Win 7 others 64,128 Set 52 8192 1440,1460 3 2 Set
Win 8 128 Set 52 8192 1440,1450 3 2 Set
Table 2: Impact of the number of comparisons.
Matches W7 W8 XP Linux BSD Unknown
5 10 46 7 43 17 1
6 7 42 6 43 17 9
7 4 16 4 43 14 43
Sample 30 21 9 43 17 4
features is, the higher number of false negatives oc-
curs. It means that some OS remains unidentified if
their features differ in one of eight comparisons. In
Table 2 we can see the results of comparison when
five, six, or seven features were required for the per-
fect match. The last row shows the real distribution
of OSs in our sample. We can see that Window 7
features can be confused with Windows 8 features:
in rows 1 and 2 the total count is almost the same
but the ratio between these two OSs varies. If we re-
quire seven features to be matched, there is a lot of
false negatives, mostly for Windows systems. Further
analysis showed that differences between Windows 7
and Windows 8 are minimal, especially for Windows
7 Home Edition (32 bits) and Windows 8, see Table
3. This is the reason why classification using cluster
analysis can give better results.
3.2 Classification
The classification algorithm is depicted in Figure 1.
The algorithm starts with testing a packet type. If it
is a SYN packet, the OS features are extracted one
by one from the packet header and compared with the
OS database. If there is a match, counter cnt
i
of each
of the matched OSs is increment. After all features
SYN?
Update DB
cnt_i++
cnt_i++
cnt_i> 6
Get highest cnt_i
Get User−Agent
Unknown
GET/POST?
DF?
HTTP?
No
Yes
Yes
Yes
Yes
Yes
No
No
No
No
Yes
No
cnt_i−0, i−1..N
TTL?
Figure 1: Classification algorithm.
are tested, the best match with the highest score of
the counter is selected. If the highest counter score is
lower than six, an OS is not identified.
In case of a HTTP packet, its header is examined
if it contains GET or POST method. Then, an OS
name is retrieved from User-Agent field. Further, a
new OS signature is generated and added to the OS
fingerprinting database to keep the database updated.
The output of our classification tool is showed in Fig-
ure 2.
Despite the fact that our plugin uses simple OS
signature database in comparison to
p0f
, we can see
DCNET2014-InternationalConferenceonDataCommunicationNetworking
24
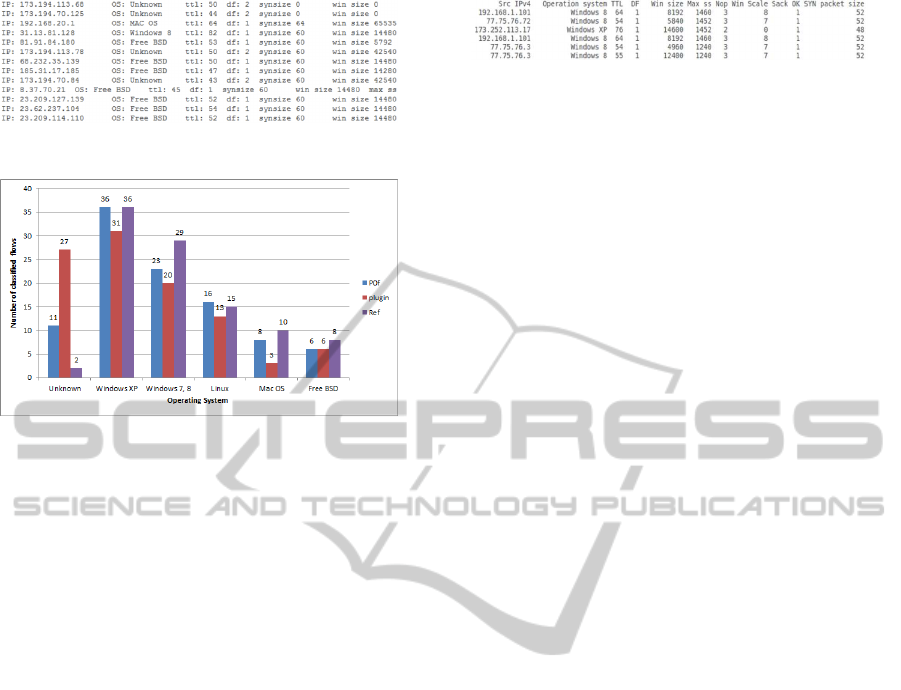
Figure 2: Example of classification of our tool.
Figure 3: Comparing p0f and our plugin.
that the results are quite similar, see Figure 3. This
graph presents the results of OS classification using
p0f
and our tool
plugin
. The third columnrepresents
a reference dataset (Ref) with known OSs. The total
number of classified flows was 100. As we can see,
our plugin has a large number of unclassified flows
(false negatives) due to the perfect feature matching
that can be enhanced using clustering.
Nevertheless, our first results prove the hypothe-
sis that even small number of signatures classes can
help to identify OSs using the passive fingerprinting.
In that case we loose more precise information about
detected OSs. However, this is not crucial for on-line
network monitoring.
3.3 IPFIX Monitoring
The main purpose of this research was to extend the
current framework of IPFIX monitoring by informa-
tion about the operating system. Our classifier is a
part of IPFIX probe that collects information about
flows (Claise, 2004). Flow records include (i) iden-
tification of the flow (source and destination IP ad-
dress, source and destination port, ToS, protocol, and
interface ID), and (ii) statistics about the flow: num-
ber of packets, bytes, starting and ending time of the
flow, etc. Standard IPFIX supports dynamic structur-
ing of flow records using templates where additional
data can be attached.
In our case, we extend IPFIX records by a set spe-
cific features extracted from IP or TCP headers, and
the name of an identified OS. After a flow expires in
the probe cache, an IPFIX record is sent to an IP-
FIX collector. The collector stores incoming data in
Figure 4: Output of the IPFIX collector.
its monitoring database. These data can be automat-
ically or manually processed and visualized. A sim-
ple example of extended IPFIX records processed by
fbitdump
(Velan, 2012) is shown in Figure 4.
4 FUTURE WORK
The main drawbacks of OS passive fingerprinting are
(i) a need of up-to-date signature database and (ii)
the number of false negatives caused by classification
based on perfect matching. The first drawback can be
minimized using automatic generation of signatures
from HTTP headers. The second drawback can be
solved using advanced classification methods. Meth-
ods based on training neural networks can give good
results, however they need to be trained repeatedly for
every new OS. From this point of view, an application
of the cluster analysis seems to be more promising.
4.1 Data Clustering Using K-means
The cluster analysis is a technique of classifying
data into classes called clusters based on unsu-
pervised learning. Unlike machine learning that
uses supervised classification based on given train-
ing data, clustering uses unlabeled data and tries
to classify them to clusters based on similarities
(Duda et al., 2001). There can be also a hybrid ap-
proach called semi-supervised learning that uses only
a small portion of training data for cluster definition
(Chapelle et al., 2006). The goal of data clustering is
to discover the natural grouping of a set of objects. An
operation of clustering can be described as follows:
Given a representation of n objects, find K groups
based on a measure of similarity such that the similar-
ities between objects in the same group are high while
the similarities between objectsin different groupsare
low (Jain, 2010).
In our work, we decided to explore an application
of non-hierarchical clustering using K-means method
to the OS identification. K-means algorithm finds a
partition on a set of n d-dimensional objects such that
the squared error between the empirical mean of a
cluster and objects in the cluster is minimized. Let
X = {x
1
,x
2
,... ,x
n
} be a set of d-dimensional objects
that needs to be clustered into setC = { c
1
,c
2
,... ,c
K
}
of K clusters where µ
a
is a mean of cluster c
a
. Then
the squared error between µ
a
and the points of clus-
TowardsIdentificationofOperatingSystemsfromtheInternetTraffic-IPFIXMonitoringwithFingerprintingand
Clustering
25

ter c
a
is E(c
a
) =
∑
x
i
∈C
a
kx
i
− µ
a
k
2
(Jain, 2010). The
method requires three parameters for its operation: a
number of clusters, a set of initial cluster centers (cen-
troids), and metrics.
In OS identification, the number of clusters and
their centers can be extracted from the OS signature
database. In our case, signatures from Table 1 can be
used. As we see, the table contains the wide range of
values for each feature. This would not work properly
for euclidean metric because the square error of each
dimension (feature) should have the same weight.
In this case, features with the small range of values
(Set/Unset bits, WinScale, NOPs) would be discrim-
inated against Windows Size or Maximum Segment
Size. So, before computing square error, normaliza-
tion of feature values should be done so that they have
the same weight despitethe rangeof their values. Pos-
sibly, an additional weight coefficient could be added
to some of the most distinguish features.
The OS identification using K-means method can
be described as follows:
1. Initialize cluster centroids using OS signature
database in Table 1,
p0f
database, or any other
OS fingerprinting database.
2. For each incoming SYN packet:
(a) Compute an square error for every cluster.
(b) Find out the nearest centroid and select an OS.
(c) Re-compute the mean value of the cluster.
(d) Update the database.
3. If a HTTP packet is detected:
(a) Extract a feature set from the packet.
(b) Check is such OS cluster exists.
(c) If the cluster exists, update the mean value of
the cluster. Otherwise, create a new cluster.
4.2 Preliminary Results of K-means
Machine learning methods are sensitive to feature se-
lection. As a part of preliminary work on application
of machine learning algorithms to OS detection and
classification, we have performed an experiment with
feature selection for K-means algorithm in order to
examine relevance of the proposed feature set used in
the previously described fingerprinting method. The
experiment consists of evaluating fitness of K-means
computed clusters for an exhaustive collection of se-
lected features. The best results are shown in Table
4. The evaluation is based on computation of over-
all fitness value. For each TCP flow, the operating
system is determined using the fingerprintingmethod.
The K-means algorithm computes clusters from these
flows according to the selected features. An operat-
ing system is identified by finding the most frequent
OS label among the flows in the cluster. Each clus-
ter thus corresponds to one of the operating systems.
We denote p being the number of flows labeled with
the same OS and n being the number of flows with
a different OS label, respectively. The fitness is then
computed as follows: fit = p/(p+ n).
Table 4: Results of K-means clustering experiment.
Feature Set Fitness
{TTL,SynLen,WinSize,NOPs} 92 %
{TTL,WinSize,NOPs,WinScale} 86 %
{TTL,WinSize,WinScale} 83 %
{TTL,SynLen,WinSize,WinScale} 83 %
{WinSize,NOPs,WinScale} 81 %
{TTL,SynLen,WinSize,NOPs,WinScale} 79 %
As can beseen fromthe table, the best results were
obtained when using four features out of eight pro-
posed for the fingerprinting. Certain combinations of
three features give also remarkable results. Neverthe-
less, feature sets with more than five and less than
three items provide poor results. Although these find-
ings representpreliminaryresults theygivea notewor-
thy hint on finding relevant features for the domain of
OS classification.
Our future work will focus on further testing and
improvement of our approach using clustering algo-
rithms. It involves following research questions:
• How is this approach accurate in comparison with
the first approach and
p0f
?
• Does this approach help to decrease the number
of false negatives?
• What kind of features should be preferred in order
to receive more precise results?
• How will clusters change in time? Do centroids
converge to a stable value?
• Is this approach feasible for special device like
routers, printers, etc.?
• What IPv6 features are more suitable for OS iden-
tification?
As a part of our future work is the creation of a
reference dataset of current OSs under both IPv4 and
IPv6.
5 CONCLUSION
The paper applies a method of passive fingerprinting
on the area of IPFIX monitoring. This application re-
quires the fast on-line processing of incoming packets
DCNET2014-InternationalConferenceonDataCommunicationNetworking
26

and flexible OS fingerprinting database with minimal
intervention of a network administrator. Our first tests
show that this approach is feasible. We also imple-
mented cluster analysis using K-means algorithm in
order to show that this technique can be successfully
applied on the passive OS fingerprinting.
Our future work will focus on implementation of
different cluster analysis algorithms and their evalua-
tion on real data and comparison with existing passive
approaches. In addition, we will apply this approach
on IPv6 communication to show how to identify OSs
using the passive fingerprinting from IPv6/TCP com-
munication.
ACKNOWLEDGMENTS
Acknowledgment will be completed in the camera-
ready version of the paper due to the blind review.
Research in this paper was supported by project
”Modern Tools for Detection and Mitigation of Cy-
ber Criminality on the New Generation Internet”, no.
VG20102015022 granted by Ministry of the Interior
of the Czech Republic and project ”Research and ap-
plication of advanced methods in ICT”, no. FIT-S-14-
2299 supported by Brno University of Technology.
REFERENCES
Allen, J. M. (2007). OS and Application Fingerprinting
Techniques. Infosec reading room, SANS Institute.
Beck, F., Festor, O., and Chrisment, I. (2007). IPv6
Neighbor Discovery Protocol based OS fingerprint-
ing. Technical report, INRIA.
Caballero, J., Venkataraman, S., Poosankam, P., Kang,
M. G., Song, D., and Blum, A. (2007). FiG: Auto-
matic fingerprint generation. Department of Electrical
and Computing Engineering, page 27.
Carpenter, B. and Jiang, S. (2013). Transmission and Pro-
cessing of IPv6 Extension Headers. IETF RFC 7045.
Chapelle, O., Sch¨olkopf, B., and Zien, A., editors (2006).
Semi-Supervised Learning. MIT Press, Cambridge,
MA.
Claise, B. (2004). Cisco Systems NetFlow Services Export
Version 9. IETF RFC 3954.
Claise, B. and Trammel, B. (2013). Information Model
for IP Flow Information Export (IPFIX). IETF RFC
7012.
Claise, B., Trammel, B., and Aitken, P. (2013). Specifica-
tion of the IP Flow Information Export (IPFIX) Proto-
col for the Exchange of Flow Information. IETF RFC
7011.
Duda, R., Hart, P., and Stork, D. (2001). Pattern classi-
fication. Pattern Classification and Scene Analysis:
Pattern Classification. Wiley.
Eckstein, C. (2011). OS fingerprinting with IPv6. Infosec
reading room, SANS Institute.
Jain, A. K. (2010). Data clustering: 50 years beyond k-
means. Pattern Recognition Letters, 31(8):651–666.
Krishnan, S., Woodyatt, J., Kline, E., Hoagland, J., and
Bhatia, M. (2012). A Uniform Format for IPv6 Ex-
tension Headers. IETF RFC 6564.
Krmicek, V. (2011). Hardware-Accelerated Anomaly
Detection in High-Speed Networks. PhD. Thesis,
Masaryk University, Brno, Czech Republic.
Lippmann, R., Fried, D., Piwowarski, K., and Streilein, W.
(2013). Passive Operating System Identification from
TCP/IP Packet Headers. In Proceedings Workshop on
Data Mining for Computer Security (DMSEC).
Nerakis, E. (2006). IPv6 Host Fingerprint. Thesis, Naval
Postgraduate School, Monterey, California.
Richardson, D. W., Gribble, S. D., and Kohno, T. (2010).
The Limits of Automatic OS Fingerpritn Generation.
In Proceedings of AISec’10, Chicago, Illinois, USA.
Sanders, C. (2011). Practical Packet Analysis. No Starch
Press, 2nd edition.
Schwartzenberg, J. (2010). Using machine learning tech-
niques for advanced passive operating system finger-
printing. Msc. theses.
S.Deering and R.Hinden (1998). Internet Protocol, Version
6 (IPv6) Specification. RFC 2460.
T.Narten, E.Nordmark, W.Simpson, and H.Soliman (2007).
Neighbor Discovery for IP version 6 (IPv6). RFC
4861.
Velan, P. (2012). Processing of a Flexible Network Traffic
Flow Information. Msc. thesis, Masaryk University,
Fakulty of Informatics, Brno, Czech Republic.
Zelinka, I., Merhaut, F., and Skanderova, L. (2013). In-
vestigation on operating systems identification by
means of fractal geometry and os pseudorandom num-
ber generators. In International Joint Conference
CISIS’12-ICEUTE’12-SOCO’12 Special Sessions Ad-
vances in Intelligent Systems and Computing, volume
189, pages 151–158. Springer.
TowardsIdentificationofOperatingSystemsfromtheInternetTraffic-IPFIXMonitoringwithFingerprintingand
Clustering
27
