
Observational Learning
Tell Them What They Are about to Watch and They Will Learn Better
Luc Proteau and Mathieu Andrieux
Département de kinésiologie, Université de Montréal, 2100 Édouard-Montpetit, Montréal, Canada
1 OBJECTIVES
Observing a model performing a motor skill
improves the learning of that skill by naïve
observers (see Ste-Marie et al. 2012 for a recent
review on observation learning). Research indicates
that observation enables one to identify the key
spatial and/or temporal features of the task, thereby
obviating the need to create a cognitive
representation of the action pattern through trial and
error (Blandin et al. 1994; Buchanan and Dean 2010;
Carroll and Bandura 1982). This finding is
supported by neurophysiological studies showing
that the observation and production of an action
share a common neural network known as the
“action observation network”, which is activated
both when individuals perform a given motor task
and when they observe others performing that same
motor task (Buccino et al. 2001; Cisek and Kalaska
2004; Cross et al. 2009). Recent research has shown
that optimal observational learning occurs with the
observation of both novice and expert models rather
than either a novice or an expert model alone
(Andrieux and Proteau, 2013; Rohbanfard and
Proteau, 2011).
Considering the advances in video capture
technology, it is very easy to film both expert and
novice athletes and use these films to teach novel
motor skills to children and adults. In the present
study, we assessed whether learning is optimized
when the learner knows beforehand whether he or
she would be observing an expert, an intermediate,
or a novice performance. Advance knowledge of this
information might guide one’s observation (observe
for something to reproduce or for something to
correct/avoid) and improve learning. However,
being uncertain of whether the next demonstration
would be that of a novice or of an expert might
activate more elaborate cognitive processes, thereby
leading to improved learning.
The task that we chose required that the
participants changed the relative timing pattern that
naturally emerged from the task constraints to a new
imposed pattern of relative timing. This is much like
changing one’s tempo when executing a serve in
tennis or a drive in golf (see Rohbanfard and
Proteau, 2011).
2 METHODS
Sixty right-handed university undergraduate students
(30 males and 30 females; mean age = 20.8 years;
SD = 1.7 years) participated in the experiment.
Participants were naive as the purpose of the study
and had no prior experience with the task. The
participants completed and signed an individual
consent form before participation.
The apparatus was similar to that used by
Rohbanfard and Proteau (2011). The task consisted
in hitting successively four targets of equal size in a
clockwise motion. The distances between each
barrier were 15 cm, 32, 18, and 29 cm, respectively.
The participants were required to complete each of
the four segments of the task in an intermediate time
(IT) of exactly 300 ms for a total movement time
(TMT) of 1200 ms.
The participants were randomly assigned to one
of the three groups of 20 participants (10 females per
group): control (C), variable observation +
feedforward (VO+FW) and variable observation +
feedback (VO+FB). All groups performed four
experimental phases.
All participants received verbal instructions
regarding the goal TMT and IT before the first
experimental phase. This first experimental phase
was a pre-test in which all participants performed 20
trials without knowledge of the results (KR) on their
TMT and the ITs. It was immediately followed by
an acquisition phase of 60 trials. In this phase,
participants in the two observation groups (VO+FW,
VO+FB) individually watched a video presentation
of two models performing the experimental task and
for which they were informed of the models
performance (both TMT and ITs) in ms, either
before the demonstration for the VO+FW group or
Proteau L. and Andrieux M..
Observational Learning - Tell Them What They Are about to Watch and They Will Learn Better.
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)
after the demonstration for the VO+FB. The model
was alternated every 5 trials (i.e., model 1: trials 1–5
and model 2: trials 6–10, and so on). For each model
we showed video clips that illustrated performances
in each one five subcategories going from that of an
expert to that of someone who had never practiced
the task before. The resulting 60 trials (2 models x 5
levels of performance x 6 repetitions) were
randomized so that the five levels of performance
were presented once into each consecutive set of
five trials. Participants in the control group did not
take part in the observation protocol and rather read
a provided magazine for the same duration as the
observation phase for the other groups. All
participants completed the third and fourth
experimental phases: 10-min and 24-hour retention
phases, similar in all points to the pre-test.
The data from the pre-test and the two retention
phases were regrouped into blocks of five trials. For
each block, we computed the absolute value of each
participant’s constant error for TMT (|CE|, the
constant error indicates whether a participant
undershot [negative value] or overshot [positive
value] TMT) and the variable error of TMT (VE, or
within-participant variability) to determine the
accuracy and consistency of TMT, respectively. For
IT, we computed a root mean square error (RMSE),
which indicates in a single score how much each
participant deviated from the prescribed relative
timing pattern. For each trial,
RMSE =
∑
Segment 4
Segment1
ITi-target
²
4
(1)
where ITi represents the intermediate time for
segment “i”, and target represents the goal
movement time for each segment of the task (i.e.,
300 ms). The data for each dependent variable were
submitted independently to an ANOVA contrasting
three groups (C, VO+FW, VO+FB) x three phases
(pretest, 10-min retention, 24-hour retention) x four
blocks of trials (1-5, 6-10, 11-15, and 16-20) with
repeated measures on the last two factors.
3 RESULTS
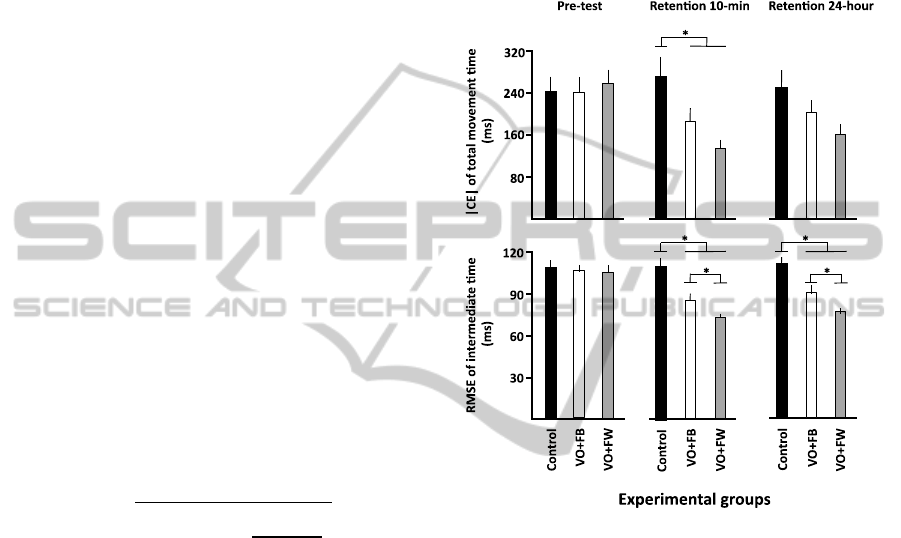
The ANOVA computed for the |CE| (Figure 1, upper
panel) and VE of TMT (not illustrated) revealed that
the three groups did not differ significantly in the
pre-test. Both observation groups significantly
outperformed the control group, but only in the 10-
min retention test: |CE|, F (4, 114) = 3.4, p = .01,
VE, F (4, 114) = 2.48, p = .05). Concerning the
relative timing data, the ANOVA computed for the
RMSE revealed that the three groups did not differ
significantly from one another in the pre-test. In
addition, in both the 10-min and 24-hour retention
tests, although the VO+FB group significantly
outperformed the control group, it was, in turn,
significantly outperformed by the VO+FW group, F
(4, 114) = 7.48, p < .001.
Figure 1: Absolute constant error of TMT and root mean
square error of relative timing as a function of the
experimental phases and experimental groups.
4 DISCUSSION
Live or video observation (Rohbanfard and Proteau,
2012) of a model practicing a motor skill favours the
learning of that skill by the observers. The advance
of video capture technology enables coaches and
educators to film the performance of a variety of
actors/models to help children and adults learn a
new skill. One goal of our laboratory is to determine
the conditions of observation that would optimize
learning.
The results of the present study confirms
previous findings indicating that one can learn a new
relative timing pattern through observation
(Andrieux and Proteau, 2013; Rohbanfard and
Proteau, 2011). In that previous work, it was showed
that the positive effects of observation for motor
learning are significantly larger when one does not

only observe either near perfect performance or the
usually large errors committed by novice
participants. Rather, the results indicated that
learning was optimized when one can observe a
variety of performances. The most important finding
of the present study is that we have showed that the
positive effects of varying the quality of the
observed performance is optimized when one knows
beforehand whether he or she will be watching a
very good, an intermediate or rather a poor
performance. Decety et al. (1997) have shown that
different areas of the brain become more active
when one observes to recognize (for example, when
observing a novice model/poor or intermediate
performance) than when one observes to imitate
(fore example, when observing on expert model).
We suggest that the benefits of informing the
observer of the quality of the performance that will
be presented enables her or him to pre-activate the
recognition/imitation of the brain as a function of
what will be observed, which results in better
learning.
In conclusion, observation is a powerful learning
tool that is now available to anyone with minimal
equipment requirement. The benefits of observation
for learning a new motor skill become larger when
one has access to a variety of models ranging from
novices to experts. These benefits are optimized if
the observer knows beforehand the quality of the
performance she or he is about to observe.
ACKNOWLEDGEMENTS
This research was supported by a Discovery Grant
awarded by the provided by the Natural Sciences
and Engineering Research Council of Canada.
REFERENCES
Andrieux, M., Proteau, L., 2013. Observation learning of a
motor task: who and when? Experimental Brain
Research, vol. 229, pp. 125-137.
Blandin, Y., Proteau, L., Alain, C., 1994. On the cognitive
processes underlying contextual interference and
observational learning. Journal of Motor Behavior,
vol. 26, pp. 18-26.
Buccino, G., Binkofski, F., Fink, G.R., et al., 2001. Action
observation activates premotor and parietal areas in a
somatotopic manner: an fMRI study. European
Journal of Neuroscience, vol. 13, pp. 400-404.
Buchanan, J.J., Dean, N.J., 2010. Specificity in practice
benefits learning in novice models and variability in
demonstration benefits observational practice.
Psychological Research, vol. 74, pp. 313-326.
Carroll, W.R., Bandura, A., 1982. The role of visual
monitoring in observational learning of action
patterns: making the unobservable observable. Journal
of Motor Behavior,vol. 14, pp. 153-167.
Cisek, P., Kalaska, J.F., 2004. Neural correlates of mental
rehearsal in dorsal premotor cortex. Nature, vol. 431,
pp. 993-996.
Cross, E.S., Kraemer, D.J.M., Hamilton, A.F.D., Kelley,
W.M., Grafton, S.T., 2009. Sensitivity of the action
observation network to physical and observational
learning. Cerebral Cortex, vol. 19, pp. 315-326.
Decety, J., Grezes, J., Costes, N., et al., 1997. Brain
activity during observation of actions - Influence of
action content and subject's strategy. Brain, vol. 120,
pp. 1763-1777.
Rohbanfard, H., Proteau, L., 2011. Learning through
observation: a combination of expert and novice
models favors learning. Experimental Brain Research,
vol. 215, pp. 183-197.
Rohbanfard, H., Proteau, L., 2012. Live vs. video
presentation techniques in the observational learning
of motor skills. Trends in Neuroscience and
Education, vol. 2, pp. 27-32.
Ste-Marie, D.M., Law, B., Rymal, A.M., Jenny, O., Hall,
C., McCullagh, P., 2012. Observation interventions for
motor skill learning and performance: an applied
model for the use of observation. International Review
of Sport and Exercise Psychology, vol. 5, pp. 145-176.
