
FOREST
A Flexible Object Recognition System
Julia Moehrmann and Gunther Heidemann
Institute of Cognitive Science, University of Osnabr
¨
uck, Albrechtstr. 28, 49076 Osnabr
¨
uck, Germany
Keywords:
Image Recognition System, Development, Image Recognition, Image Annotation, Ground Truth Annotation.
Abstract:
Despite the growing importance of image data, image recognition has succeeded in taking a permanent role
in everyday life in specific areas only. The reason is the complexity of currently available software and the
difficulty in developing image recognition systems. Currently available software frameworks expect users to
have a comparatively high level of programming and computer vision skills. FOREST – a flexible object
recognition framework – strives to overcome this drawback. It was developed for non-expert users with little-
to-no knowledge in computer vision and programming. While other image recognition systems focus solely
on the recognition functionality, FOREST covers all steps of the development process, including selection
of training data, ground truth annotation, investigation of classification results and of possible skews in the
training data. The software is highly flexible and performs the computer vision functionality autonomously
by applying several feature detection and extraction operators in order to capture important image properties.
Despite the use of weakly supervised learning, applications developed with FOREST achieve recognition rates
between 86 and 99% and are comparable to state-of-the-art recognition systems.
1 INTRODUCTION
While images play an ever more important role in ev-
eryday life, image recognition has only succeeded in
specific areas like, e.g., bar code or fingerprint recog-
nition. A wide application of computer vision tech-
niques by normal Internet users in the near future is
very unlikely. This is mainly due to the complex-
ity of existing image recognition systems. Software
frameworks like MATLAB or OpenCV provide ex-
tensive functionality, but require programming skills
and knowledge about which methods to use for build-
ing a recognition system. While users who are inter-
ested in developing an image recognition system may
already have programming skills, acquiring the nec-
essary computer vision skills requires a lot of time
and effort. A software framework which is applicable
by non-expert users would have to fulfill a series of
requirements. Ideally, the development of a new im-
age recognition system should follow the few simple
steps shown in Figure 1. The user decides on a recog-
nition task, selects an appropriate image data source
for the task, e.g., a webcam, and annotates the train-
ing data. The vision system then learns a classifier
based on the image features and the ground truth data,
without the need for user interaction. Despite the sim-
plicity of this process, it represents exactly the devel-
Get image data for training
Use webcam
www.example.com
Acquire images for 1 week
Calculate
image
features
Calculate
classifier
Annotate training
data
Images with sailboats
vs. images without
sailboats
Think up
recognition task
Recognize
sailboats on
lake
User
Framework
Custom recognition
system
Sailboat classifier
Figure 1: Workflow for development of custom recognition
system, divided by manual tasks (user box) and automatic
tasks (framework box). Text in lower half (italics) provides
and example for the task.
opment process for creating a custom image recog-
nition system with FOREST. In contrast to existing
software frameworks FOREST considers all steps of
the development process, i.e., the selection of train-
ing data, ground truth annotation, calculation of the
recognition system, the investigation of classification
results and the investigation of possible skews in the
training data, not only the vision functionality. The
major contribution of FOREST therefore is the pre-
sentation of a software tool, which is not used as a
collection of algorithms like existing frameworks, but
as an out-of-the-box development tool which is in-
119
Moehrmann J. and Heidemann G..
FOREST - A Flexible Object Recognition System.
DOI: 10.5220/0005175901190127
In Proceedings of the International Conference on Pattern Recognition Applications and Methods (ICPRAM-2015), pages 119-127
ISBN: 978-989-758-077-2
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)
SIFT
Harris-affine
Hessian-affine
MSER
SIFT/SURF/GLOH
Steerable Filter
Color
Shape context
LBP/LPQ
Boosting
UI Annotation
Core
DB
API Access Data Update
Request calculation Status update
Read/Write
Access
Read/Write
Access
Detection Extraction Classification
C o m p u t i n g
S e r v i c e
I n t e r a c t i o n
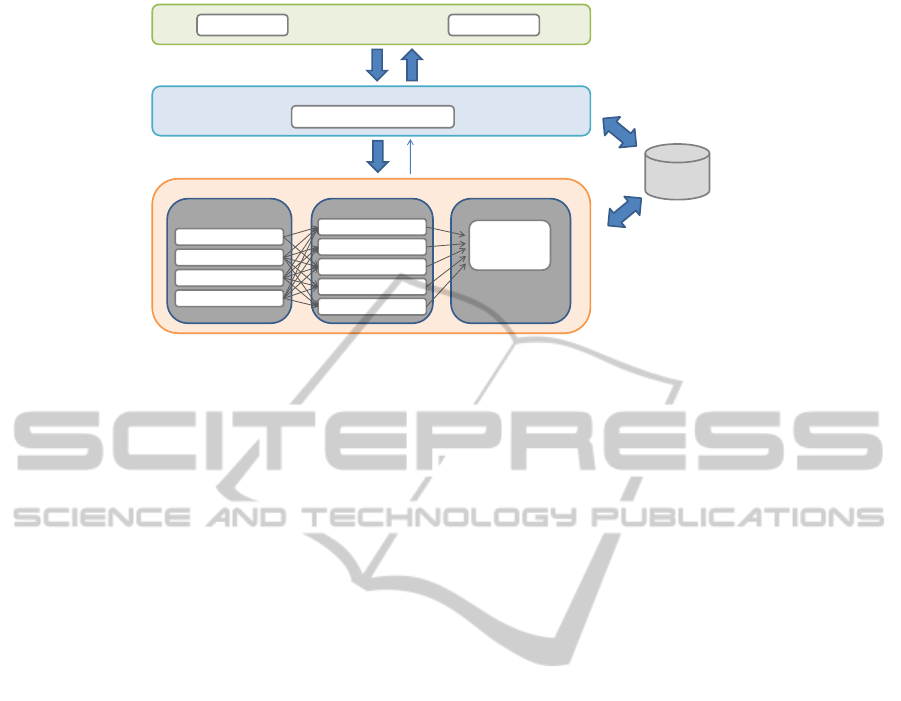
Figure 2: FOREST system design showing three modular layers which represent functionality for user interfaces and user
interaction (interaction layer), management of development processes and scheduling of calculation tasks (service layer), and
image processing, feature extraction and classification functionality (computing layer). Database is used as shared resource by
service and computing layer to avoid transferring data between Java-based service layer and Matlab-based computing layer.
Distribution of layers to different servers is possible and intended.
tuitive to use and guides users through all steps of
the development process. It does not expect users to
have programming skills or any knowledge of com-
puter vision. This leads to certain issues FOREST
has to solve. For one, the recognition task intended
by the user is not known by the system which means
that it has to be able to deal with arbitrary data sets
and recognition tasks. Additionally, the missing ex-
pert knowledge does not allow the integration of any
kind of prior knowledge, e.g., concerning features that
could be useful or concerning the parametrization of
feature extraction methods. FOREST is capable of
achieving high recognition rates on standard and cus-
tom data sets by extracting a large set of image fea-
tures and selecting appropriate features automatically.
The selection of appropriate image features is based
on the ground truth data provided by the user. The
ground truth data is weakly annotated, i.e., each im-
age is annotated as a whole, to enable users to perform
the annotation task as efficiently as possible. Despite
the lack of region based annotations, results are com-
parable to state-of-the-art systems.
For reasons of clarity, we define the terms soft-
ware framework and recognition framework as a soft-
ware for building and developing custom recognition
systems. A custom recognition system in this context
is a recognition system which has been trained on a
specific, i.e., custom or user-defined, task.
2 REQUIREMENTS
There are a series of requirements that a recognition
framework must implement in order to be usable by
non-experts. These requirements can be divided into
soft requirements and hard requirements. Soft re-
quirements consider human factors which influence
the architecture, whereas hard requirements directly
consider technical aspects. We identified the follow-
ing soft requirements for a software framework which
allows non-expert users to develop image recognition
systems:
• The system must not require any expert knowl-
edge about computer vision or machine learning
algorithms. It cannot be expected that users have
this kind of knowledge or are willing to acquire
it. Similarly, it cannot be expected that users un-
derstand the method of using image features and
their structure.
• The system has to be usable instantaneously. It
must require no training. Beside the technical
knowledge the software itself must not present an
obstacle itself. This could be the case if too many
specific features are available or if technical terms
are used.
• The overall time involved for the user in devel-
oping a custom image recognition system should
be minimal. Similarly, necessary user interaction
should be reduced to a minimum.
• Information should be presented to the user in a
visual and intuitive way. Abstract representations
are preferable over exact representations if they
are more intuitive to understand.
Hard requirements are partially derived from these
soft requirements:
• Application of different computer vision methods
ICPRAM2015-InternationalConferenceonPatternRecognitionApplicationsandMethods
120

to compensate for missing expert knowledge and
possible variety in recognition tasks.
• Extensibility of software framework regarding
image data sources and computer vision methods
to allow for future developments. This require-
ment also implies a high modularity of the soft-
ware.
• The software framework must not make strict re-
quirements concerning client-side hardware and
must not require buying software licenses.
Most of these requirements should be obvious when
considering that such a software framework is in-
tended for use by standard Internet users without any
expert knowledge. Requirements concerning the in-
stant usability are necessary to ensure potential users
are not discouraged by a seemingly complex setup.
This also involves that the software framework should
– at least in its basic version – be free to use.
3 SYSTEM DESIGN
The technical requirements discussed above are re-
flected in the system design of FOREST (cf. Fig-
ure 2). The framework consists of three major com-
ponents: the interaction layer, the service layer and
the computing layer. The upper two layers are im-
plemented in Java, whereas the computing layer is
implemented in Matlab. The great advantage of this
design is that multiple Matlab instances may run on
physically distributed servers. Calculations are dis-
tributed to these Matlab Servers by the service layer.
Although the advantage resulting from such a distri-
bution is limited by the database communication this
design is well suited to speed-up calculations without
the need of having developers care about paralleliza-
tion inside their image processing code.
Data is stored inside a database to allow for an ef-
ficient organization, e.g., of extracted image features.
The database setup was chosen to prevent having to
transfer data between the computing and service layer
which could result in conversion problems.
This system design, with the service and compu-
tation layer running on distributed servers was chosen
to provide an easily accessible setup. Users only need
to install components from the interaction layer lo-
cally (although this could be avoided as well) in order
to access the systems functionality. This allows for
a fast access to the framework and a basically non-
existent obstacle for using FOREST.
3.1 Recognition Functionality
The generic recognition functionality of FOREST,
which allows the development of recognition sys-
tems for arbitrary data sets, is achieved by apply-
ing a series of region detection and feature extrac-
tion methods. Currently available methods are shown
in the computing layer in Figure 2. All methods
for ROI detection and feature extraction are applied
to the training image data. This is necessary, since
users cannot be expected to make an educated deci-
sion about which method(s) to use for their specific
data set. The huge amount of potential recognition
tasks requires that possibly interesting image regions
must be detected at this stage. Therefore a larger set
of ROI is extracted here, rather than a smaller one.
Currently available methods for ROI detection are
SIFT (Lowe, 2004), Harris and Hessian affine invari-
ant region detectors (Mikolajczyk and Schmid, 2004),
and MSER (Matas et al., 2002). The resulting set
of ROI are passed on to the feature extraction meth-
ods. Among the currently included feature descrip-
tors are SIFT, color features which comprise Color
Layout Descriptors (CLD), Dominant Color Descrip-
tors (DCD), and color histograms (Manjunath et al.,
2001), and other popular descriptors. In contrast to
recognition systems like (Opelt et al., 2006; Zhang
et al., 2005; Hegazy and Denzler, 2009) the result of
the feature extraction stage does not only consist of
feature sets from two or three feature types, but uses
a larger set of different features.
As indicated by the arrows in Figure 2, the differ-
ent region detection operators are applied to the im-
age and the results are used by the different feature
extraction methods, thereby producing a huge feature
set which contains a variety of features representing
different image properties. The resulting heteroge-
neous feature set is then passed on to the classifier.
The boosting classifier used by FOREST was pro-
posed in (Opelt et al., 2006). The boosting classi-
fier identifies discriminative features from the hetero-
geneous feature set by calculating weak hypotheses
for every positive training feature vector and select-
ing those with the highest discriminative ability. A
weak hypothesis is defined by a feature vector v
wh
t
of
type t ∈ T and a threshold θ. An image I is classi-
fied as positive if min
j=1,..,|v
I
t
|
(||v
wh
t
, v
j
t
||) < θ, i.e., if one
vector of type t from image I is similar enough to the
vector v
wh
t
.
Annotation of the ground truth data for the classi-
fier is described in the next section. It has to be men-
tioned, however, that the framework supports strong
and weak annotation, i.e. the annotation of image re-
gions and the image as a whole. So far the framework
FOREST-AFlexibleObjectRecognitionSystem
121

Figure 3: Graphical user interface which guides users through the development process. Summary of image acquisition setup
(upper left), progress visualization (upper right), summary of acquired image data (lower left), and estimation of classifier
performance (lower right) if available. Webcam data source: http://www.webcam.barca-hamburg.de.
was exclusively used and evaluated with weakly su-
pervised learning, since this greatly reduces the anno-
tation effort for the user.
The extraction of a huge heterogeneous feature set
and the calculation of the boosting classifier are rela-
tively expensive from a computational point of view.
However, this is not considered as a drawback for
FOREST for the following reasons:
• All steps in the development process where the
user has to actively participate/interact with the
system are highly optimized and the time required
by FOREST for automatic processing can be used
otherwise.
• The classifier usually employs a limited number
of different feature types. Therefore it is unnec-
essary to apply all operators in the recognition
phase, which allows for an efficient recognition.
FOREST does provide the functionality to explic-
itly set parameters for region detection and feature
extraction operators, in order to be usable by expert
users also. However, non-expert users are not ex-
pected to tune any parameters. Instead, FOREST uses
the default parameters proposed in the literature.
4 GRAPHICAL DESIGN AND
VISUAL SUPPORT
Users are supported in the development process by an
intuitive user interface. In the initial step, all users
have to do is select an image data source and specify
an image acquisition criterion, e.g., duration, in case
the data source is an online resource. In case of a we-
bcam data source users may specify the location of
the webcam. This results in the acquisition of addi-
tional information for each image, like weather and
visibility information at the specified location. These
additional attributes can be used to filter the training
data and investigate it for possible skews.
After the image acquisition information was spec-
ified users are redirected to a general overview shown
in Figure 3. The overview shows a summary of the
image acquisition specification (upper left), the cur-
rent development step and progress (upper right), the
acquired training image data (lower left), and the clas-
sifier performance estimation (lower right) if it is al-
ready available. The progress panel gives users a
feedback about the current status of the development
process. The overview of the acquired training data
in the lower left panel provides the possibility of dis-
playing all images, filtering for specific attributes, or
displaying the distribution of images. As can be seen
in Figure 3 users can filter the image data by differ-
ent attributes depicted as icons: annotation (+/- icon),
date, time, and weather. If training images are taken
only for similar weather conditions, within the span
of a few days or always at the same time, they will
tend to be very similar and exhibit low variance. An
additional view using a scatterplot matrix of these at-
tributes can also help to detect correlations and skews,
as shown in Figure 4.
The classifier is calculated automatically and eval-
uated using 10-fold cross-validation. The perfor-
mance of the classifier is then estimated by FOREST
based on the average correct recognition rate. In order
to give users an easy-to-understand feedback about
ICPRAM2015-InternationalConferenceonPatternRecognitionApplicationsandMethods
122

the recognition capabilities of their custom recogni-
tion system the assessment is colored green, yellow,
or red, indicating very good, OK, or bad performance.
Users are then given a hint by the system about how
to proceed. In Figure 3, the recognition performance
is assessed to be OK and the user is given the hint
to investigate the training data or to add more train-
ing data. The investigation of the training data can
be started using the provided button. The user is then
directly led to the scatterplot matrix with possibly in-
teresting panels highlighted in red (cf. Figure 4). The
scatterplot matrix visualization shows the histogram
of a single attribute on the diagonal and the scatter-
plots on the upper triangle. In the highlighted up-
per row a skew between positive (1) and negative (-1)
training data can be observed. To be more precise, it
is obvious that the training data set consists of ≈ 95%
negative training samples and less than 50 positive
training images. A data set skewed like this can eas-
ily lead to a degraded recognition performance. Al-
though the effects of skewed raining data sets are well
known, to the best of our knowledge, no attempt has
been made to investigate such skews, especially by
non-expert users.
It is also possible to view more detailed informa-
tion about the classifier performance, e.g., average
and best classification rate over the number of weak
hypotheses used by the boosting classier. This infor-
mation is considered to be too detailed for beginners
and is therefore accessible in a background tab.
Beside the development process, the annotation of
ground truth data is an important task which cannot be
automated. A specialized user interface has been pre-
sented before in (Moehrmann and Heidemann, 2013)
to allow for an efficient annotation of ground truth
data using a semi-supervised process which arranges
images according to similarity.
5 EVALUATION
The recognition ability of custom recognition systems
developed with FOREST is shown in this section.
For the evaluation no manual adaptations took place,
i.e., no preprocessing of the data took place, except
a resizing for high resolution images and all methods
were run with their default parametrization. The setup
therefore corresponds to a non-expert user developing
a recognition system.
The evaluation considers artificial examples, like
the Graz-02 (Opelt et al., 2006) and the Caltech-
101 (Fei-Fei et al., 2004) data sets, however it
also considers real-world examples where recognition
tasks were defined for local webcam data. The re-
Figure 4: Scatterplot matrix of training image data distri-
bution considering annotation and additional attributes like
weather, time, and date. Histograms of single attribute are
shown on diagonal. Panels showing possibly skewed data
are highlighted in red.
sulting recognition performance depends on the num-
ber of weak hypotheses used by the boosting classi-
fier. We calculated the results for wh = 1, .., 300 weak
hypotheses. In general, recognition rates converge
around 20 to 100 weak hypotheses. More hypothe-
ses do not have a negative impact due to the small
weights they are assigned to in the calculation of the
boosting classifier and therefore no overfitting effects
can be observed. we present a compact version of the
results by giving the average recognition rates for 200
to 300 weak hypotheses. We also provide the number
of weak hypotheses at which the results converge, i.e.,
at which the improvement reduces significantly. A
common way to represent the results would be to pro-
vide ROC curves. However, this would involve cal-
culating the error rates for different thresholds of the
strong boosting classifier. Since non-expert users will
not be able to interpret this threshold, FOREST does
not consider a modification. The results are meant to
represent the real performance of custom recognition
systems developed by non-expert users.
5.1 Artificial Data
The evaluation on artificial data sets is intended to
show the general recognition capabilities of FOREST
and the benefit of using a large feature set. For the
Graz-02 data, a custom recognition system was cal-
culated for each of the three categories bike, car, and
person. The calculation was repeated ten times. In
each iteration 150 images from the positive and nega-
tive category were randomly chosen for training. The
evaluation used the remaining images. Results are
given in Table 1. All results range above 86%, with-
out any specific selection of training data samples or
FOREST-AFlexibleObjectRecognitionSystem
123

Table 1: Results for recognition systems on Graz-02 data
set, averaged over ten runs with randomly selected training
data.
Category Avg. rec. rate #wh
Bike 86.34% 16
Car 86.86% 10
Person 86.1% 6
50
55
60
65
70
75
80
85
90
95
100
airplanes
ant
bonsai
Brain
cup
faces
ferry
ketch
llama
motorbike
rhino
scorpion
stegosaurus
stop sign
Recognition rate in %
Figure 5: Recognition rates averaged over ten training
episodes. Each episode used 30 randomly selected positive
and negative images for training.
methods to use. These results are above those re-
ported in (Opelt et al., 2006), especially for the car
category which was reported with 67.2% and the bike
category which was reported to be 73.5%. A detailed
investigation of the selected weak hypotheses shows
that the classification is indeed based on discrimina-
tive structures of the objects and persons.
In order to prove the general recognition capabil-
ity of FOREST, 14 random categories were chosen
from the Caltech-101 data. The overall performance
of FOREST on this data set is limited by the feature
descriptors used since weakly supervised learning is
not expected to have a negative effect with this data
set. The evaluation of all 101 categories is therefore
obsolete in this context. The results of all categories
are considered separately. Each recognition system
was calculated ten times on a different set of randomly
selected training images. For each training episode 30
positive and negative training images were used. For
testing, 50 positive and negative images were used.
The results are given in Figure 5 which shows high
recognition rates for most categories. Weaker cat-
egories correspond to those which contain complex
structures and a high variance as, e.g., ants or scorpi-
ons.
5.2 Real-world Data
The evaluation on real-world data sets is of impor-
tance since weakly supervised learning might have a
stronger effect in such recognition scenarios. Real-
world examples consider the recognition of open win-
90
91
92
93
94
95
96
97
98
99
100
50 100 150 250
0
10
20
30
40
50
Recognition rate in %
# weak hypotheses
# training images per category
Avg. rec rate
Avg. true
positive rate
#wh
Figure 6: Results for recognizing open windows in an office
room using different numbers of training images per cate-
gory. Results are averaged over ten runs.
80
82
84
86
88
90
92
94
96
98
100
50 100 150 250
0
10
20
30
40
50
Recognition rate in %
# weak hypotheses
# training images per category
Avg. rec rate
Avg. true
positive rate
#wh
Figure 7: Results for recognition of sailboats on a lake using
different numbers of training images per category. Results
are averaged over ten runs.
dows, sailboats on a lake, and cars parked in a no-
parking zone. For the windows an internal office web-
cam was used, the image data for the other two exam-
ples was acquired from publicly available webcams.
Recognition of open windows in an office build-
ing is relevant to prevent theft due to neglect. Re-
sults for the recognition of open windows are given
in Figure 6. The evaluation was run ten times with
randomly selected training images and different num-
bers of training images per category. Even for a
small number of training images recognition rates are
very high. However, as the number of training im-
ages is increased it can be seen that the true posi-
tive rate increases significantly, resulting in near-to-
perfect recognition performance.
The evaluation for the recognition of sailboats
uses the same setup. The recognition rate increases
with the number of training images. Here it can also
be seen that the classifier requires less weak hypothe-
ses for a larger number of training images. This is
due to the fact that the training data provided more
detailed information which allows the classifier to se-
lect highly discriminative features. A detailed investi-
gation shows that, for a small number of training im-
ages, features in the water area are used for classifi-
cation, whereas more training images lead to a small
number of weak hypotheses targeting sailboats only.
In contrast to the other systems, the detection of
cars in a no-parking zone was evaluated using a typ-
ical setup. That is, images were acquired over the
course of one week. The recognition system was then
ICPRAM2015-InternationalConferenceonPatternRecognitionApplicationsandMethods
124
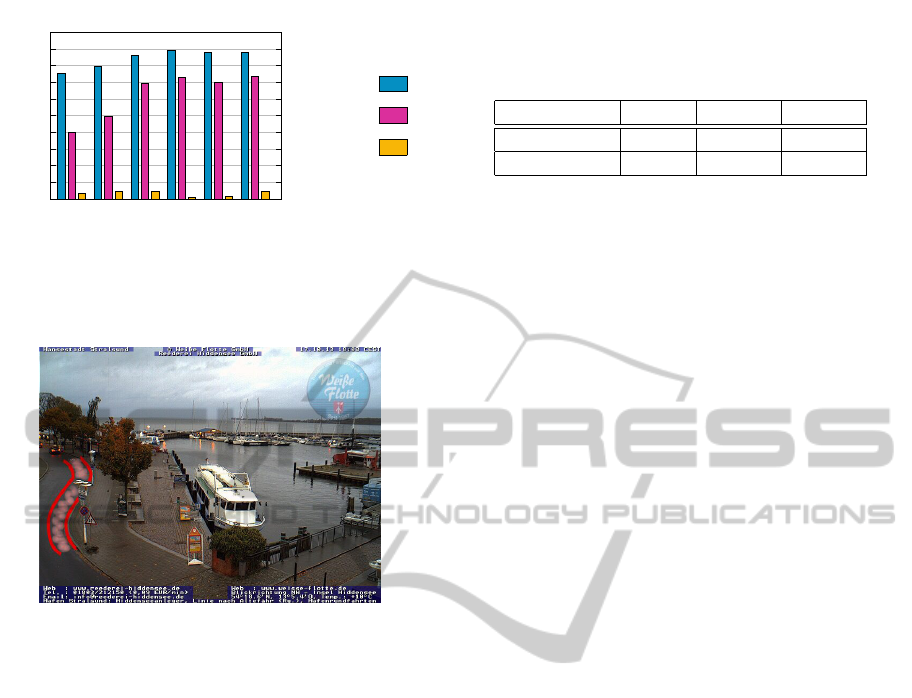
0
10
20
30
40
50
60
70
80
90
100
complete
3
complete
4
complete
5
section
3
section
4
section
5
Recognition rate in %
Avg. rec rate
Avg. true
positive rate
Avg. false
positive rate
Figure 8: Results for recognizing cars in a no-parking zone.
Recognition systems were calculated on all features from
the image over a course of n days (complete
n
) and over an
image region selected by the user (section
n
).
Figure 9: Webcam image of harbor and no-parking
zone (highlighted in red). Webcam data source:
http://www.frs.de/nc/de/frs-webcams/stralsund.html
trained on the images of the first n days and tested
on the images of the following days. We expect this
to be a typical setup since it is expected that users
develop custom recognition systems in this manner.
The data set contained approximately equal numbers
of positive and negative training images. The results
are given for n = 3, 4, 5 days in Figure 8, denoted as
complete
n
. The results show a significant difference
between the average recognition rate and the true pos-
itive rate, which increases with the number of training
images. Since the webcam mainly shows the harbor,
the actual no-parking zone makes up only a small part
of the image, as can be seen in Figure 9. When the
image data source is initially selected by the user he
or she also has the possibility of selecting an image
region for observation. The recognition system then
focuses recognition on this image section only. The
results for image recognition systems for which a se-
lection of the no-parking zone took place are given
as section
n
(the selected image section was a rectan-
gular region around the area showing the street). As
can be seen in Figure 8 the section
n
results basically
exhibit no differences for varying numbers of train-
ing images. Additionally, only very few weak hy-
potheses are required for achieving high recognition
Table 2: Results for multi-class recognition systems.
Recognition of the correct category is given by top
1
. top
n
refers to the correct category being included in the top n
ranked categories.
Data set top
1
top
2
top
3
Flowers17 79% 89% 92%
AT&T Faces 86.6% 92.35% 93.26%
rates. Errors were mainly due to cars driving on the
street, close to the no-parking zone. Unfortunately,
the update rate of the webcam is not high enough
to allow frame by frame comparisons or tracking of
cars. However, we believe the recognition could fur-
ther be improved using more training data, especially
such data that considers more variance in weather and
lighting conditions.
5.3 Multi-class Recognition
FOREST supports the development of multi-class
recognition systems. This evaluation uses the Flow-
ers17 (Nilsback and Zisserman, 2006) and the AT&T
Faces (Samaria and Harter, 1994) data sets, with a
five-fold cross-validation. Average recognition results
over all categories are given in Table 2 as top
n
for
n = 1, 2, 3. These modified recognition rates consider
an image as being classified correctly if it corresponds
to one of the n top-ranked categories by the classi-
fier. As can be seen in the results, recognition rates
are well above 90% if we consider n = 2. A recog-
nition system like the one for flowers is intended for
a certain community which is interested in the name
and type of a flower. Such a system could bene-
fit largely from a visualization of results for the best
matching n categories with probabilities and sample
images given. It would then serve as a decision ba-
sis for users. Due to the large variety in floral repre-
sentations such a setup is most likely to succeed in a
real-world application.
Results on the Flowers data set are comparable
to those reported by (Nilsback and Zisserman, 2006)
with a top
1
recognition rate of 81.3%. Despite the
optimization of parameters by (Nilsback and Zisser-
man, 2006) FOREST reaches almost the same results
with default parametrization only. Results for the face
data set are very high although the data set contains
only a small number of images per person. This sug-
gests, that face recognition on private photo collec-
tions should be possible with high accuracy.
FOREST-AFlexibleObjectRecognitionSystem
125

6 LITERATURE
Generic recognition systems try to solve a similar
problem as FOREST. While generic recognition sys-
tems are able to recognize several object classes, a
flexible recognition system like FOREST is meant to
be adapted to an arbitrary recognition task. Never-
theless, generic recognition systems have been found
to perform better when using multiple feature chan-
nels (Opelt et al., 2006; Zhang et al., 2005; Hegazy
and Denzler, 2009; Varma and Ray, 2007).
The area of tangible user interfaces provides
two examples for systems which require a flex-
ible rather than a generic recognition functional-
ity: Crayons (Fails and Olsen, 2003) and Papier-
M
ˆ
ach
´
e (Klemmer et al., 2004). Both systems pro-
vide the possibility of creating simple gesture recog-
nition systems for interaction purposes. The under-
lying recognition functionality is, however, limited to
very basic color information.
A recognition system which intends to use web-
cams is Eyepatch. It requires no expert knowledge in
the areas of image recognition, but requires that the
user applies and combines predefined classifiers. An-
other system which intends to use existing webcams
is Vision on Tap (Chiu, 2011). It provides specific
processing blocks which implement motion tracking,
skin color recognition or face recognition. These can
be combined in a visual computing application to cre-
ate custom recognition systems. Although a nice va-
riety of applications can be implemented using these
building blocks, the resulting functionality is effec-
tively limited.
7 CONCLUSIONS
A software framework, FOREST, for the develop-
ment of custom, i.e. user-defined, recognition sys-
tems was presented. In order to be usable by non-
expert users such a system has to fulfill a set of re-
quirements which were discussed and implemented.
In contrast to other existing systems FOREST con-
siders all aspects of the development process from
a non-expert users point of view. The image pro-
cessing functionality is fully automated, requiring no
programming skills or expert knowledge. Interactive
steps in the development process were enhanced us-
ing semi-automatic techniques like, e.g., the identifi-
cation of possible skews in the training data set. The
user is even supported in the assessment of the classi-
fier performance.
In contrast to existing software frameworks FOR-
EST does not provide a collection of algorithm but
instead allows the adaption of the recognition func-
tionality to a specific user-defined recognition task.
FOREST achieves this functionality by extracting a
large heterogeneous feature set from the images and
applying a boosting classifier which selects discrim-
inative features based on the ground truth data pro-
vided by the user. The application of such a hetero-
geneous feature set allows the identification of impor-
tant image properties despite the lack of knowledge
about the (type of) recognition task even with weakly
supervised learning.
REFERENCES
Chiu, K. (2011). Vision On Tap : An Online Computer
Vision Toolkit. Master’s thesis, Massachusetts Insti-
tute of Technology. Dept. of Architecture. Program in
Media Arts and Sciences.
Fails, J. and Olsen, D. (2003). A Design Tool for Camera-
based Interaction. In Proceedings of the SIGCHI
Conference on Human Factors in Computing Systems,
pages 449–456. ACM.
Fei-Fei, L., Fergus, R., and Perona, P. (2004). Learning
Generative Visual Models from Few Training Exam-
ples: An Incremental Bayesian Approach Tested on
101 Object Categories. In IEEE CVPR Workshop on
Generative-Model based Vision.
Hegazy, D. and Denzler, J. (2009). Generic Object Recog-
nition. In Computer Vision in Camera Networks for
Analyzing Complex Dynamic Natural Scenes.
Klemmer, S., Li, J., Lin, J., and Landay, J. (2004). Papier-
M
ˆ
ach
´
e: Toolkit Support for Tangible Input. In Pro-
ceedings of the SIGCHI Conference on Human Fac-
tors in Computing Systems, pages 399–406. ACM.
Lowe, D. (2004). Distinctive Image Features from Scale-
Invariant Keypoints. Intl. Journal of Computer Vision,
60:91–110.
Manjunath, B., Ohm, J.-R., Vasudevan, V., and Yamada, A.
(2001). Color and Texture Descriptors. IEEE Trans-
actions on Circuits and Systems for Video Technology,
11(6):703–715.
Matas, J., Chum, O., Urban, M., and Pajdla, T. (2002). Ro-
bust Wide Baseline Stereo from Maximally Stable Ex-
tremal Regions. In British Machine Vision Confer-
ence, volume 1, pages 384–393.
Mikolajczyk, K. and Schmid, C. (2004). Scale and Affine
Invariant Interest Point Detectors. Intl. Journal of
Computer Vision, 60(1):63–86.
Moehrmann, J. and Heidemann, G. (2013). Semi-
Automatic Image Annotation. In Computer Analysis
of Images and Patterns, volume 8048 of Lecture Notes
in Computer Science, pages 266–273.
Nilsback, M.-E. and Zisserman, A. (2006). A Visual Vocab-
ulary for Flower Classification. In IEEE Conference
on Computer Vision and Pattern Recognition (CVPR),
volume 2, pages 1447–1454. IEEE.
ICPRAM2015-InternationalConferenceonPatternRecognitionApplicationsandMethods
126

Opelt, A., Pinz, A., Fussenegger, M., and Auer, P. (2006).
Generic Object Recognition with Boosting. IEEE
Transactions on Pattern Analysis and Machine Intel-
ligence, 28(3):416–431.
Samaria, F. and Harter, A. (1994). Parameterisation of a
Stochastic Model for Human Face Identification. In
Proceedings of the IEEE Workshop on Applications of
Computer Vision, pages 138–142. IEEE.
Varma, M. and Ray, D. (2007). Learning The Discrimina-
tive Power-Invariance Trade-Off. IEEE Intl. Confer-
ence on Computer Vision (ICPR), 0:1–8.
Zhang, W., Yu, B., Zelinsky, G., and Samaras, D. (2005).
Object Class Recognition using Multiple Layer Boost-
ing with Heterogeneous Features. In IEEE Conference
on Computer Vision and Pattern Recognition (CVPR),
volume 2, pages 323–330.
FOREST-AFlexibleObjectRecognitionSystem
127
