
Stream-based Active Learning in the Presence of Label Noise
Mohamed-Rafik Bouguelia, Yolande Bela
¨
ıd and Abdel Bela
¨
ıd
Universit
´
e de Lorraine LORIA, UMR 7503, Vandoeuvre-les-Nancy, F-54506, France
Keywords:
Label Noise, Active Learning, Classification, Data Stream.
Abstract:
Mislabelling is a critical problem for stream-based active learning methods because it not only impacts the
classification accuracy but also deviates the active learner from querying informative data. Dealing with label
noise is omitted by most existing active learning methods. We address this issue and propose an efficient
method to identify and mitigate mislabelling errors for active learning in the streaming setting. We first pro-
pose a mislabelling likelihood measure to characterize the potentially mislabelled instances. This measure is
based on the degree of disagreement among the predicted and the queried class label (given by the labeller).
Then, we derive a measure of informativeness that expresses how much the label of an instance needs to be
corrected by an expert labeller. Specifically, an instance is worth relabelling if it shows highly conflicting infor-
mation among the predicted and the queried labels. We show that filtering instances with a high mislabelling
likelihood and correcting only the filtered instances with a high conflicting information greatly improves the
performances of the active learner. Experiments on several real world data prove the effectiveness of the
proposed method in terms of filtering efficiency and classification accuracy of the stream-based active learner.
1 INTRODUCTION
In usual supervised learning methods, a classifica-
tion model is built by performing several passes over
a static dataset with sufficiently many labelled data.
Firstly, this is not possible in the case of data streams
where data is massively and continuously arriving
from an infinite-length stream. Secondly, manual la-
belling is costly and time consuming. Active learning
reduces the manual labelling cost, by querying from
a human labeller only the class labels of data which
are informative (usually uncertain instances). Ac-
tive learning methods (Settles, 2012) are convenient
for data stream classification. Several active learning
methods (Settles, 2012; Kremer et al., 2014; Huang
et al., 2014; Kushnir, 2014) and stream-based active
learning methods (Zliobaite et al., 2014; Bouguelia
et al., 2013; Goldberg et al., 2011) have been pro-
posed. Most of these methods assume that the queried
label is perfect. However, in real world scenarios this
assumption is often not satisfied. Indeed, it is diffi-
cult to obtain completely reliable labels, because the
labeller is prone to mislabelling errors. Mislabelling
may occur for several reasons: inattention or acci-
dental labelling errors, uncertain labelling knowledge,
subjectivity of classes, etc.
Usually, the active learner queries labels of in-
stances that are uncertain. These instances are likely
to improve the classification model if we assume that
their queried class label is correct. Under such as-
sumption, the active learner aims to search for in-
stances that reduce its uncertainty. However, when the
labeller is noisy, mislabelling errors cause the learner
to incorrectly focus the search on poor regions of
the feature space. This represents an additional diffi-
culty for active learning to reduce the label complex-
ity (Dasgupta, 2005). If the potential labelling errors
are not detected and mitigated, the active learner can
easily fail to converge to a good model. Therefore,
label noise is harmful for active learning and dealing
with it is an important issue.
Detecting label noise is not trivial in stream-based
active learning, mainly for two reasons. Firstly, in
a data stream setting, the decision to filter or not a
potentially mislabelled instance should be taken im-
mediately. Secondly, because the learning is active,
the mislabelled instances are necessarily among those
that the classifier is uncertain about their class.
Usual methods to deal with label noise like those
surveyed in (Fr
´
enay and Verleysen, 2013), assume
that a static dataset is available beforehand and try
to clean it before training occurs by repeatedly re-
moving the most likely mislabelled instances among
all instances of the dataset. A method proposed in
(Zhu et al., 2008) is designed for cleansing noisy data
streams by removing the potentially mislabelled in-
stances from a stream of labelled data. However, the
25
Bouguelia M., Belaïd Y. and Belaïd A..
Stream-based Active Learning in the Presence of Label Noise.
DOI: 10.5220/0005178900250034
In Proceedings of the International Conference on Pattern Recognition Applications and Methods (ICPRAM-2015), pages 25-34
ISBN: 978-989-758-076-5
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

method does not consider an active learning setting
where the mislabelling errors concern uncertain in-
stances. Moreover, they divide the data stream into
large chunks and try to detect mislabelled instances in
each chunk, which makes the method partially online
and reduces the importance of its streaming nature.
The method in (Rebbapragada et al., 2012) considers
an active label correction, but the learning itself is not
active. Rather, the method iteratively selects the top
k likely mislabelled instances from a labelled dataset
and presents them to an expert for correction rather
than discarding them. Some other methods like (Fang
and Zhu, 2013; Tuia and Munoz-Mari, 2013) are de-
signed for active learning with label noise and are in-
tended only for label noise whose source is the un-
certain labelling knowledge of the labeller. Generally
speaking, they try to model the knowledge of the la-
beller and avoid asking for the label of an instance if it
belongs to the uncertain knowledge set of the labeller.
However, this may lead to discarding many informa-
tive data. Moreover, the method implicitly assumes
that the labeller is always the same (since his knowl-
edge is modelled). Methods like (Sheng et al., 2008;
Ipeirotis et al., 2014) can be applied to active learn-
ing but they try to mitigate the effect of label noise
differently: rather than trying to detect the possibly
mislabelled instances, they repeatedly ask for the la-
bel of an instance from noisy labellers using crowd-
sourcing techniques (Yan et al., 2011). However, all
these methods require multiple labellers that can pro-
vide redundant labels for each queried instance and
are not intended to be used with a single alternative
labeller.
The method we propose is different. We con-
sider a stream-based active learning with label noise.
The main question we address is whether some pos-
sibly mislabelled instances among the queried ones
are worth relabelling more than others. A potentially
mislabelled instance is filtered as soon as it is received
according to a mislabelling likelihood. An alternative
expert labeller can be used to correct the filtered in-
stance. The method is able to select (for relabelling)
only those instances that deserve correction according
to an informativeness measure.
This paper is organized as follows. In Section 2
we give background on stream-based active learning
with uncertainty and its sensibility to label noise. In
Section 3 we firstly propose two measures to charac-
terize the mislabelled instances. Then, we derives an
informativeness measure that determines to which ex-
tent a possibly mislabelled instance would be useful if
corrected. In Section 4 we present different strategies
to mitigate label noise using the proposed measures.
In Section 5 we present the experiments. Finally, we
conclude and present some future work in Section 6.
2 BACKGROUND
2.1 Active Learning with Uncertainty
Let X be the input space of instances and Y the out-
put space. We consider a stream-based active learn-
ing where at each time step t, the learner receives
a new unlabelled instance x
t
∈ X from an infinite-
length data stream and has to make the decision (at
time t) of whether or not to query the corresponding
class label y
t
∈Y from a labeller. Each x ∈ X is pre-
sented in a p-dimensional space as a feature vector
x
def
= (x
f
1
, x
f
2
, ..., x
f
p
), where x
f
i
∈ R and f
i
is the i’th
feature.
If the label y
t
of x
t
is queried, the labelled in-
stance (x
t
, y
t
) is used to update a classification model
h. Otherwise, the classifier outputs the predicted label
y
t
= h(x
t
). In this way, the goal is to learn an effi-
cient classification model h : X →Y using a minimal
number of queried labels. In order to decide whether
or not to query the label of an instance, many active
learning strategies have been studied (Settles, 2012).
The most common ones are the uncertainty sampling
based strategies. The instances that are selected for
manual labelling are typically those for which the
model h is uncertain about their class. If an uncer-
tain instance x is labelled manually and correctly, two
objectives are met: (i) the classifier avoids to output
a probable prediction error, and (ii) knowing the true
class label of x would be useful to improve h and re-
duce its overall uncertainty (x is said to be informa-
tive). A simple uncertainty measure that selects in-
stances with a low prediction probability can be de-
fined as ∆
h
x
= 1 −max
y∈Y
P
h
(y|x), where P
h
(y|x) is the
probability that x belongs to class y. A general stream-
based active learning process is described by Algo-
rithm 1. Any base classifier can be used to learn the
model h. The algorithm queries labels of instances
with an uncertainty beyond a given threshold δ.
Algorithm 1: Stream-based active learning (δ).
1: Input: uncertainty threshold δ, underlying clas-
sification model h
2: for each new data point x from the stream do
3: if the uncertainty ∆
h
x
> δ then
4: query y the label of x from a labeller
5: train h using (x, y)
6: else output the predicted label y = h(x)
ICPRAM2015-InternationalConferenceonPatternRecognitionApplicationsandMethods
26

Figure 1: A stream-based active learning with different lev-
els of label noise (σ). The data set used is optdigits (UCI
repository). SVM is used as a base classifier.
2.2 Impact of Label Noise
As mentioned previously, we are not always guaran-
teed to obtain a perfectly reliable label when querying
it from a human labeller. We consider a random label
noise process where the noisy labeller has a probabil-
ity σ for giving a wrong answer and 1 −σ for giving
the correct answer, each time a label is queried.
Fig. 1 shows the results obtained using Algorithm
1 in the presence of label noise with different inten-
sities σ and compared to the noise-free setting σ = 0.
Fig. 1 (A) shows the accuracy of the model h on a
test set, according to the number of instances from
the stream. As for the usual supervised learning, it
is not surprising to see that in active learning, label
noise also reduces the overall classification accuracy.
Fig. 1 (B) shows the accuracy according to the num-
ber of queried labels (manually labelled instances).
We can see that in addition to achieving a lower ac-
curacy, more label noise also causes the active learner
to make more queries. This is confirmed in Fig. 1
(C) that shows the number of instances whose label
is queried, according to the number of instances seen
from the stream. This is explained by the fact that
the most uncertain instance can be informative if we
obtain its true class label, but may easily become the
most misleading one if it is mislabelled. Therefore,
mislabelled instances causes the active learner to in-
correctly focus the query on poor regions of the fea-
ture space, and deviates it from querying the truly in-
formative instances.
In summary, stream-based active learning is very
sensitive to label noise since it not only impacts the
predictive capabilities of the learned model but also
leads it to query labels of instances which are not nec-
essarily informative. This results in more queried in-
stances and represents a bottleneck for minimizing the
label complexity of active learning (Dasgupta, 2005).
3 CHARACTERIZING
MISLABELLED INSTANCES
In this section we propose measures for characteriz-
ing mislabelled instances and their importance. First,
we present in Section 3.1 a disagreement coefficient
that reflects the mislabelling likelihood of instances.
Then, we derive in Section 3.2 an informativeness
measure that reflects the importance of the instance,
which is later used to decide if the instance merits to
be relabelled.
Let x be a data point whose label is queried. The
class label given by the labeller is noted y
g
. Let
y
p
= argmax
y∈Y
P
h
(y|x) be the class label of x which is
predicted by the classifier. If y
p
= y
g
then the label
given by the labeller is trusted and we consider that it
is not a mislabelling error. Otherwise, a mislabelling
error may have occurred.
3.1 Mislabelling Likelihood
Assume that y
p
6= y
g
. We express how likely x is
mislabelled by estimating the degree of disagreement
among the predicted class y
p
and the observed class
y
g
, which is proportional to the difference in probabil-
ities of y
p
and y
g
. Let p
p
= P(y
p
|x) and p
g
= P(y
g
|x).
Stream-basedActiveLearninginthePresenceofLabelNoise
27

As in the silhouette coefficient (Rousseeuw, 1987)
and given that p
p
≥ p
g
, we define the degree of dis-
agreement D
1
(x) ∈ [0, 1] as:
D
1
(x) =
p
p
−p
g
max(p
p
, p
g
)
=
p
p
−p
g
p
p
= 1 −
P(y
g
|x)
P(y
p
|x)
The higher the value of D
1
(x), the more likely that
x has been incorrectly labelled with y
g
, because the
probability that x belongs to y
g
would be small rela-
tively to y
p
.
Inspired by multi-view learning (Sun, 2013), we
present a second measure to estimate the degree of
disagreement. In multi-view learning, classifiers are
learned on different views of data using different fea-
ture subsets. Data points of one view (using a feature
f
1
) are scattered differently in a second view (using a
different feature f
2
). Therefore, it is possible for some
instance x that we are uncertain if its label is y
p
or y
g
in one view, to be less uncertain in another view.
Let us take features separately. Each feature value
f
i
of an instance x has a contribution q
f
i
y
for classify-
ing x into a class y. As an analogy, a textual document
contains terms (features) that attracts towards a given
class more strongly than another one. q
f
i
y
can be con-
sidered as any score that shows how much the feature
value f
i
attracts x towards class y. For example, let x
f
i
be the instance x restricted to the feature f
i
. Let d
f
i
y
be
the mean distance from x
f
i
to its k nearest neighbours
belonging to class y, restricted to feature f
i
. Then,
q
f
i
y
can be defined as inversely proportional to the dis-
tance d
f
i
y
, e.g. q
f
i
y
=
1
d
f
i
y
.
Considering the predicted class y
p
and the given
class y
g
, q
f
i
y
p
and q
f
i
y
g
represent how much the feature
f
i
is likely to contribute at classifying x into y
p
and
y
g
respectively. Let F
p
be the set of features that con-
tributes at classifying x in the predicted class more
than the given class, and inversely for F
g
:
F
p
= {f
i
|q
f
i
y
p
> q
f
i
y
g
} F
g
= {f
i
|q
f
i
y
p
≤ q
f
i
y
g
}
The amount of information reflecting the member-
ship of x to y
p
(resp. y
g
) is:
q
p
=
∑
f
i
∈F
p
(q
f
i
y
p
−q
f
i
y
g
) q
g
=
∑
f
i
∈F
g
(q
f
i
y
g
−q
f
i
y
p
)
Note that q
p
∈ [0, +∞) and q
g
∈ [0, +∞). Again,
by applying the silhouette coefficient, a degree of dis-
agreement D
0
2
(x) ∈ [−1, 1] among y
p
and y
g
can be
expressed as:
D
0
2
(x) =
q
p
−q
g
max(q
p
, q
g
)
Figure 2: Mislabelled and correctly labelled instances dis-
tributed according to D
1
and D
2
.
Note that D
0
2
can be normalized to be in [0, 1]
rather than [−1, 1] simply as D
2
=
D
0
2
+1
2
.
Instances distributed according to D
1
and D
2
are
shown on Fig. 2. A final mislabelling score D can
be expressed either by D
1
or D
2
or by using pos-
sible combinations of both including: the average
D
1
+D
2
2
, max(D
1
, D
2
), or min(D
1
, D
2
). In order to de-
cide whether an instance x is potentially mislabelled,
a usual way is to define a threshold (that we denote
t
D
) on D.
In summary, the presented disagreement measure
only expresses how likely x has been incorrectly la-
belled. Strong information reflecting the predicted
class label and low information reflecting the given
class label, indicates a mislabelling error. For exam-
ple, most terms in a textual document strongly attract
towards a class, but the other words weakly attracts
towards the class given by the labeller. Nonethe-
less, the mislabelling score does not give information
about the importance of an instance or how much its
queried label deserves to be reviewed. This is dis-
cussed in the next section.
3.2 Informativeness of Possibly
Mislabelled Instances
In active learning with uncertainty sampling, in-
stances for which the model is uncertain on how to
label, are designated as informative and their label is
queried. In this section we are not referring to infor-
mativeness in terms of uncertainty (the considered in-
stances are already uncertain). Rather, we are trying
to determine to which extent a possibly mislabelled
instance would be useful if corrected.
ICPRAM2015-InternationalConferenceonPatternRecognitionApplicationsandMethods
28
It is possible for the mislabelling likelihood us-
ing D
1
and/or D
2
to be uncertain if an instance x is
mislabelled or not. This appears on Fig. 2 as the
overlapped region of the mislabelled and the correctly
labelled instances. This happens essentially in the
presence of either strong or weak conflicting infor-
mations in x with respect to y
p
and y
g
, which leads to
P(y
p
|x) ' P(y
g
|x) and q
p
' q
g
. Let us again consider
the example of a textual document:
• Strongly conflicting Information: some terms
strongly attract the document towards y
p
and other
terms attract it with the same strength towards y
g
.
In this case q
p
and q
g
are both high and close to
each other.
• Weakly Conflicting Information: terms equally
but weakly attract the document towards y
p
and
y
g
, that is, there is no persuasive information for
y
p
or y
g
. In this case q
p
and q
g
are both low and
close to each other.
In both the above cases q
p
−q
g
would be low.
However, instances showing strongly conflicting in-
formation are more informative if their true class label
is available, and deserve to be reviewed and corrected
more than the other instances. Therefore, in addition
to the mislabelling likelihood (Section 3.1), we define
the informativeness measure I ∈ [0, +∞) as
I =
p
q
p
×q
g
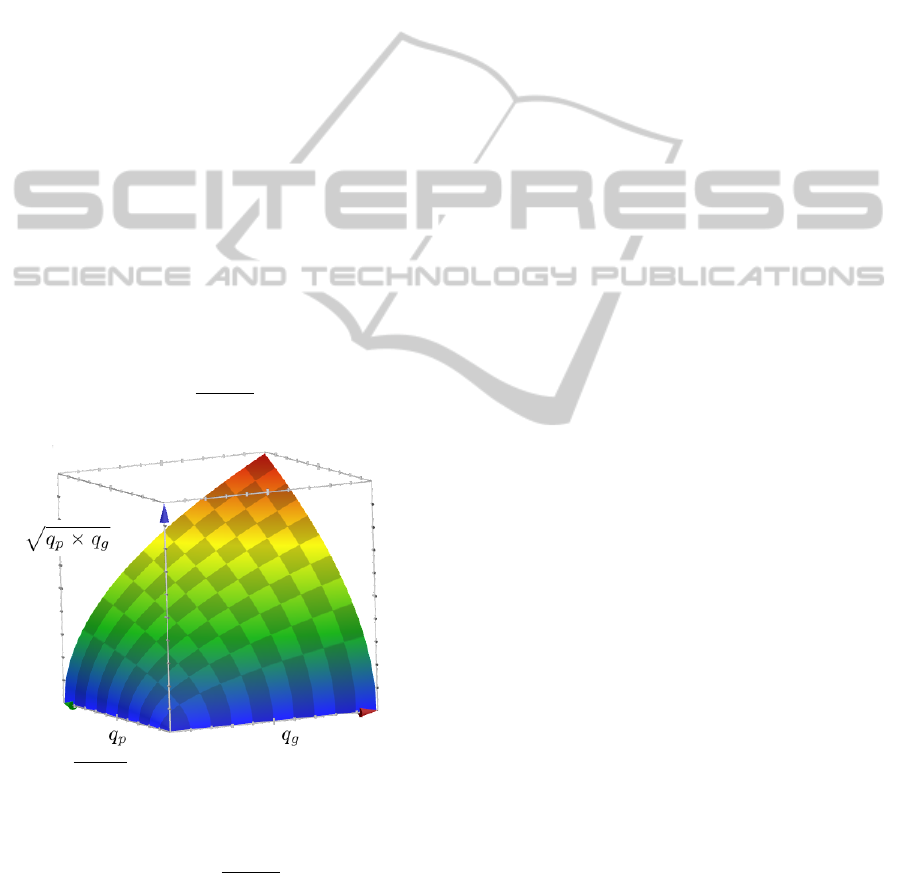
Figure 3:
√
q
p
×q
g
is high when both q
y
p
and q
y
g
are high
and close to each other.
The higher I, the more its queried label deserves
to be reviewed (and eventually corrected). Figure 3
justifies the choice of I =
√
q
p
×q
g
since it gives a
high value when both q
y
p
and q
y
g
are high and close
to each other. The measure I is unbounded but can be
normalized, for example by dividing it on a maximum
value of I which can be computed on a validation set.
This way, a threshold (that we denote t
I
) can be de-
fined on the informativeness measure I.
4 MITIGATING LABEL NOISE
When an instance x is detected as potentially misla-
belled, the next step is to decide what to do with this
instance. In usual label noise cleansing methods, the
dataset is available beforehand and the methods just
discard or remove the instances that are likely to be
mislabelled or predict their labels. In order to mitigate
the impact of label noise on the stream-based active
learning, we study three strategies including discard-
ing, weighting and relabelling by an expert labeller,
and we show a hybrid approach.
4.1 Discard, Weight and Relabel
What Not to do. In a stream-based active learning,
correcting a mislabelled instance by predicting its la-
bels is not the right way to go. Indeed, updating the
model h using the predicted label of x (i.e. y = h(x))
rather than the queried label, is usually more harmful
to active learning than the label noise itself. This is
due to the fact that the mislabelled instances are those
instances for which the model h was primarily uncer-
tain how to classify. Therefore, predicting their la-
bels will more likely result in an error that the model
would be unable to detect (otherwise it would have
avoided that error).
Discarding. When D(x) > t
D
, x is considered as
mislabelled, otherwise it is considered as correctly
labelled. This way, if x is identified as being mis-
labelled, it can be just discarded, that is, we do not
update the classification model h with x.
Weighting. Depending on the base classifier, the in-
stances can be weighted so that the classifier learns
more from instances with a higher weight. Therefore,
a possible alternative to mitigate label noise without
defining a threshold on D, is to update the model h us-
ing every instance x with its queried label y
g
weighted
by w = 1 −D(x) which is inversely proportional to its
mislabelling likelihood D. Indeed, instances with a
high mislabelling likelihood will have a weight closer
to 0 and will not affect the classification model h too
much, unlike an instance with a low mislabelling like-
lihood.
Relabelling. If an alternative reliable labeller is
available, the label of the potentially mislabelled in-
stance (having a mislabelling likelihood D > t
D
) can
be verified and eventually corrected. Then, the model
h is updated using the instance and its corrected label.
Stream-basedActiveLearninginthePresenceofLabelNoise
29

Figure 4: Active learning from a data stream with label
noise intensity σ = 0.3 and t
D
= 0.6. The dataset used is
optdigits (UCI repository).
Fig. 4 shows the results obtained using the differ-
ent strategies. It is obvious that the best alternative is
to relabel correctly the instances that are identified as
mislabelled. However, this is done under a cost by an
expert labeller which is assumed to be reliable. Dis-
carding the possible mislabelled instances may im-
prove the classification accuracy. However, informa-
tive instances that were correctly labelled may be lost,
especially if many instances are wrongly discarded
(depending on threshold t
D
). Rather than discarding
possible mislabelled instances, weighting all the in-
stances with an importance which is inversely propor-
tional to their mislabelling likelihood may improve
the performances of the active learner without loosing
informative instances (at the risk of under-weighting
some informative instances). Finally, Fig. 4 confirms
that it is very harmful to predict the label of a filtered
instance x and updating the model using the instance x
with its predicted label. Indeed, some dataset cleans-
ing methods for supervised learning propose to pre-
dict the label of the potentially mislabelled instances.
However, in an active learning configuration, this be-
comes very harmful, because the queried labels are
precisely those of uncertain instances (about which
the classifier is uncertain about its prediction).
Hybrid Strategy. Correcting mislabelled instances
using their true class label gives the best results. How-
ever, this requires an expert labeller which implies a
high cost since it is assumed to be a reliable labeller.
We present a hybrid approach that minimizes the cost
required by using the alternative expert labeller. Since
relabelling is costly, we assume that we have a limited
budget B for relabelling, that is, the expert can review
and relabel no more than B instances. Given the bud-
get B, the problem can be stated as which instances
are worth to be relabelled. Actually, relabelling in-
stances that are informative according to the measure
I (see Section 3.2) is more likely to improve the clas-
sification accuracy. Therefore, if an instance x is iden-
tified as being mislabelled and has a high informative-
ness I(x) > t
I
, then it is relabelled. Otherwise, either
the discarding or the weighting strategy can be used.
5 EXPERIMENTS
We use for our experiments different public datasets
obtained from the UCI machine learning repository
1
.
We also consider a real administrative documents
dataset provided by the ITESOFT
2
company. Each
document was processed by an OCR and represented
as a bag-of-words which is a sparse feature-vector
containing the occurrence counts of words in the doc-
ument. Without loss of generality, the label noise in-
tensity is set to σ = 0.3. An SVM is used as a base
classifier (we use the python implementation avail-
able on scikit-learn (Pedregosa and et al., 2011)).
Threshold t
D
is fixed to 0.6 for all datasets to allow
reproducibility of the experiments, although a better
threshold can be found for each dataset.
1
http://archive.ics.uci.edu/ml/
2
http://www.itesoft.com/
ICPRAM2015-InternationalConferenceonPatternRecognitionApplicationsandMethods
30

5.1 Mislabelling Likelihood
This experiment figures-out the ability of the pro-
posed mislabelling likelihood to correctly character-
ize mislabelled instances as proposed in Section 3.1,
without considering a stream-based active learning.
We corrupt the labels of each dataset such that in-
stances with a low prediction probability are more
likely to be mislabelled. Then, instances of each
dataset are ranked according to degrees of disagree-
ment defined in terms of D
1
and D
2
. Results are com-
pared with an entropy measure E which is commonly
used in active learning. Instances with a low entropy
implies a confident classification, thus, instances for
which the classifier disagrees with their queried label
are more likely to be mislabelled when they have a
low entropy E = −
∑
y∈Y
P
h
(y|x) ×log P
h
(y|x)
We select the top n ranked instances of each
dataset and we compute 2 types of errors: e
1
rep-
resents the correctly labelled instances that are erro-
neously selected, and e
2
the mislabelled instances that
are not selected:
e
1
=
correct selected
correct
e
2
=
mislabelled unselected
mislabelled
where ”correct selected” is the number of correctly
labelled instances that are selected as being poten-
tially mislabelled. ”mislabelled unselected” is the
number of mislabelled instances that are not selected.
”correct” and ”mislabelled” are the total number of
correctly labelled and mislabelled instances respec-
tively.
We also compute the percentage of selected in-
stances that are actually mislabelled prec, which rep-
resents the noise detection precision:
prec =
mislabelled selected
selected
where ”mislabelled selected” is the number of mis-
labelled instances that are selected, and ”selected” is
the number of selected instances.
Table 1 shows the obtained results. We can
see that for documents and pendigits datasets, D
2
achieves better results than D
1
and inversely for
optdigits and letter-recognition datasets. However
combining D
1
and D
2
using D = max(D
1
, D
2
) may
yield better results than both D
1
and D
2
, and always
achieves better results than the entropy measure E.
This is confirmed by the average results obtained over
all the datasets. For the reminder of the experiments
we use the D which represents a convenient disagree-
ment measure for almost all datasets.
Table 1: Mislabelling likelihood measures.
D
1
D
2
D E
Optdigits dataset
e
1
0.67% 1.49% 1.12% 1.27%
e
2
1.22% 3.14% 2.26% 2.61%
prec 98.44% 96.53% 97.4% 97.05%
Documents dataset
e
1
3.51 3.29% 2.96% 4.50%
e
2
3.07 2.56% 1.79% 5.38%
prec 92.2 92.69% 93.42% 90.0%
Pendigits dataset
e
1
2.34% 2.19% 2.07% 2.61%
e
2
1.37% 1.02% 0.75% 2.00%
prec 94.75% 95.10% 95.35% 94.15%
Letter-recognition dataset
e
1
1.82% 3.2% 1.93% 2.29%
e
2
21.1% 24.3% 21.35% 22.18%
prec 94.87% 91.03% 94.6% 93.57%
Average results over all datasets
e
1
2.08% 2.54% 2.02% 2.66%
e
2
6.69% 7.75% 6.53% 8.04%
prec 95.07% 93.84% 95.20% 93.70%
5.2 Label Noise Mitigation
In this experiment we consider a stream-based active
learning where the label noise is mitigated accord-
ing to different strategies: relabelling, discarding and
weighting. A hybrid strategy is also considered where
only a small number of instances are manually rela-
belled according to a relabelling budget B. For the hy-
brid strategy, without any loss of generality, we used
in our experiments a budget of B = 20 instances al-
lowed to be relabelled. Results with others values of
B lead to similar conclusions but are not reported due
to the space limitation. The considered strategies are
listed below:
• Full Relabelling: relabelling every instance x that
is identified as mislabelled (i.e. if D(x) > t
D
, then
x is relabelled)
• Full Discarding: discarding every instance x that
is identified as mislabelled
• Full Weighting: using every instance and its
queried label (x, y
g
) weighted by w = 1 −D(x) to
update the classification model.
• Hybrid Discarding and Relabelling: consists in
relabelling an instance that is identified as mis-
labelled only if it shows a high informativeness
(I(x) > t
I
) and the budget B is not yet exhausted.
Otherwise, the instance is discarded.
• Hybrid Weighting and Relabelling: same as the
Stream-basedActiveLearninginthePresenceofLabelNoise
31

above hybrid strategy but using weighting instead
of discarding.
The results obtained for each strategy are illus-
trated in Fig. 5 and Table 2. The classification ac-
curacy obtained on a test set is shown on Fig. 5 ac-
cording to the number of labelled instances. Table 2
shows the final classification accuracy, the final num-
ber of instances N
1
whose label was queried from the
first (unreliable) labeller, and the number of instances
N
2
that are relabelled by the alternative expert labeller
(fixed to N
2
= B = 20 for the hybrid strategies). Let c
1
and c
2
respectively be the cost required by the first la-
beller and the expert labeller to label a single instance.
It is assumed that c
2
> c
1
since the expert labeller is
supposed to be reliable (or much more reliable than
the first labeller). Then, the labelling cost is c
1
×N
1
,
the relabelling cost is c
2
×N
2
, and the overall cost is
C = c
1
×N
1
+ c
2
×N
2
.
Firstly, the results on Fig. 5 confirm that the ”full
relabelling” is obviously the most effective strategy
in terms of classification accuracy, since all instances
that are identified as being mislabelled are relabelled
by the expert. Secondly, the results obtained on all
datasets show that discarding the possibly mislabelled
instances is not better than the weighting strategy. Ac-
tually, it has been observed in many works on label
noise cleansing (Fr
´
enay and Verleysen, 2013; Gam-
berger et al., 1996; Brodley and Friedl, 1999) that
learning with mislabelled instances harms more than
removing too many correctly labelled instances, but
this is not true in the active learning setting, as it is
confirmed by the obtained results. This is due to the
fact that in the active learning setting, the discarded
instances are more likely to improve the classification
model if they are correctly labelled, thus, discarding
them may negatively impact the performances of the
active learning. Fore the same reason, we can see
that the ”hybrid weighting and relabelling” strategy
performs better than the ”hybrid discarding and rela-
belling” strategy. Also, Fig. 5 shows for the ”hybrid
weighting and relabelling” strategy that relabelling
only B = 20 instances with a high value of I, greatly
improves the accuracy compared to the ”discarding”
or the ”weighting” strategy. We can see on Table 2
that the ”hybrid weighting and relabelling” strategy
achieves a final classification accuracy which is pretty
close to that of the ”full relabelling” strategy. For
example, the final accuracy achieved by the ”hybrid
weighting and relabelling” strategy for the optdigits
dataset is 97.21%, whereas the one achieved by the
”full relabelling” strategy is 97.49%. As explained
in Section 2.2, mislabelling errors causes the active
learner to ask for more labelled instances. This ex-
plains why N
1
in Table 2 is smaller in the ”full rela-
Figure 5: Classification accuracy according to the number
of actively queried labels using different strategies.
ICPRAM2015-InternationalConferenceonPatternRecognitionApplicationsandMethods
32

Table 2: Final accuracy and cost according to different
strategies.
Relabel Discard
Discard
and
relabel
Weight
Weight
and
relabel
Optdigits dataset
Accuracy 97.49% 96.21% 96.43% 96.66% 97.21%
N
1
290 432 359 412 364
N
2
92 0 20 0 20
Pendigits dataset
Accuracy 98.11% 94.02% 97.31% 96.36% 97.88%
N
1
307 464 420 420 363
N
2
105 0 20 0 20
Letters-recognition dataset
Accuracy 85.98% 53.95% 66.79% 80.26% 85.52%
N
1
914 1242 956 1537 1344
N
2
211 0 20 0 20
Documents dataset
Accuracy 96.1%5 81.84% 90.61% 94.46% 96.0%
N
1
406 413 424 701 646
N
2
104 0 20 0 20
belling” strategy. However, by taking into consider-
ation the cost induced by relabelling the mislabelled
instances, the ”full relabelling” strategy will have a
higher overall cost than the other strategies, since all
the instances that are identified as being mislabelled
are relabelled.
Finally, we can conclude that although the ”hy-
brid weighting and relabelling” strategy has a low re-
labelling cost, it achieves a final classification accu-
racy which is close to the one achieved by the ”full re-
labelling” strategy. Therefore, if a limited relabelling
budget is available, then this budget should be devoted
to relabelling instances with a high informativeness I.
6 CONCLUSION AND FUTURE
WORK
In this paper we addressed the label noise detection
and mitigation problem in stream-based active learn-
ing for classification. In order to identify the po-
tentially mislabelled instances, we proposed a misla-
belling likelihood based on the disagreement among
the probabilities and the quantity of information that
the instance carries for the predicted and the queried
class labels. Then, we derived an informativeness
measure that reflects how much a queried label would
be useful if it is corrected. Our experiments on real
datasets show that the proposed mislabelling likeli-
hood is more efficient in characterizing label noise
compared to the commonly used entropy measure.
The experimental evaluation also shows that the po-
tentially mislabelled instances with high conflicting
information are worth relabelling.
Nonetheless, one limitation of the current hybrid
label noise mitigation strategy is that it requires a
threshold on the informativeness measure I which de-
pends on the data and its automatic adaptation con-
stitute one of our perspectives. As future work, we
want to minimize the correction cost by defining and
optimizing a multi-objective function that combines
together (i) the mislabelling likelihood, (ii) the infor-
mativeness, and (iii) the cost of relabelling instances.
Also, in the current work we observed that manually
relabelling few instances chosen according to their in-
formativeness I can improve results, but figuring out
the number of labelled instances that are required to
achieve closer accuracy to the case where all instances
are relabelled still constitute one of our future work.
REFERENCES
Bouguelia, M.-R., Bela
¨
ıd, Y., and Bela
¨
ıd, A. (2013).
A stream-based semi-supervised active learning ap-
proach for document classification. ICDAR, pages
611–615.
Brodley, C. and Friedl, M. (1999). Identifying mislabeled
training data. Journal of Artificial Intelligence Re-
search, pages 131–167.
Dasgupta, S. (2005). Coarse sample complexity bounds for
active learning. Neural Information Processing Sys-
tems (NIPS), pages 235–242.
Fang, M. and Zhu, X. (2013). Active learning with uncer-
tain labeling knowledge. Pattern Recognition Letters,
pages 98–108.
Fr
´
enay, B. and Verleysen, M. (2013). Classification in
the presence of label noise: a survey. IEEE Trans-
actions on Neural Networks and Learning Systems,
pages 845–869.
Gamberger, D., Lavrac, N., and Dzeroski, S. (1996). Noise
elimination in inductive concept learning: A case
study in medical diagnosis. Algorithmic Learning
Theory, pages 199–212.
Goldberg, A., Zhu, X., Furger, A., and Xu, J. (2011). Oasis:
Online active semi-supervised learning. AAAI Confer-
ence on Artificial Intelligence, pages 1–6.
Huang, L., Liu, Y., Liu, X., Wang, X., and Lang, B. (2014).
Graph-based active semi-supervised learning: A new
perspective for relieving multi-class annotation labor.
IEEE International Conference Multimedia and Expo,
pages 1–6.
Ipeirotis, P., Provost, F., Sheng, V., and Wang, J. (2014).
Repeated labeling using multiple noisy labelers. ACM
Conference on Knowledge Discovery and Data Min-
ing, pages 402–441.
Kremer, J., Pedersen, K. S., and Igel, C. (2014). Active
learning with support vector machines. Wiley Inter-
disciplinary Reviews: Data Mining and Knowledge
Discovery, pages 313–326.
Stream-basedActiveLearninginthePresenceofLabelNoise
33

Kushnir, D. (2014). Active-transductive learning with label-
adapted kernels. ACM SIGKDD international confer-
ence on Knowledge discovery and data mining, pages
462–471.
Pedregosa, F. and et al. (2011). scikit-learn, scikit-learn:
Machine learning in Python. Journal of Machine
Learning Research, pages 2825–2830.
Rebbapragada, Brodley, C., Sulla-Menashe, D., and Friedl,
M. A. (2012). Active label correction. IEEE Interna-
tional Conference on Data Mining, pages 1080–1085.
Rousseeuw, P. (1987). Silhouettes: a graphical aid to the
interpretation and validation of cluster analysis. Com-
putational and Applied Mathematics, pages 53–65.
Settles, B. (2012). Active learning. Synthesis Lectures on
Artificial Intelligence and Machine Learning, pages
1–114.
Sheng, V., Provost, F., and Ipeirotis, P. (2008). Get another
label? improving data quality and data mining using
multiple noisy labelers. ACM Conference on Knowl-
edge Discovery and Data Mining, pages 614–622.
Sun, S. (2013). A survey of multi-view machine learning.
Neural Computing and Applications, pages 2031–
2038.
Tuia, D. and Munoz-Mari, J. (2013). Learning user’s confi-
dence for active learning. IEEE Transactions on Geo-
science and Remote Sensing, pages 872–880.
Yan, Y., Fung, G., Rosales, R., and Dy., J. (2011). Active
learning from crowds. International Conference on
Machine Learning, pages 1161–1168.
Zhu, X., Zhang, P., Wu, X., He, D., Zhang, C., and Shi, Y.
(2008). Cleansing noisy data streams. IEEE Interna-
tional Conference on Data Mining, pages 1139–1144.
Zliobaite, I., Bifet, A., Pfahringer, B., and Holmes, G.
(2014). Active learning with drifting streaming data.
IEEE transactions on neural networks and learning
systems, pages 27–39.
ICPRAM2015-InternationalConferenceonPatternRecognitionApplicationsandMethods
34
