
A Relevant Visual Feature Selection Approach for Image Retrieval
Olfa Allani
1,2
, Nedra Mellouli
3
, Hajer Baazaoui Zghal
2
, Herman Akdag
1
and Henda Ben Ghzala
2
1
LIASD, Universit
´
e Paris 8, Saint-Denis, France
2
LABORATOIRE RIADI, ENSI Campus Universitaire de la Manouba, Tunis, Tunisia
3
LIASD,EA 4383, Universit
´
e Paris 8 Saint-Denis, IUT de Montreuil, Montreuil, France
Keywords:
Visual Feature, Ontologies, Semantic Content, Selection.
Abstract:
Content-Based Image Retrieval approaches have been marked by the semantic gap (inconsistency) between
the perception of the user and the visual description of the image. This inconsistency is often linked to the
use of predefined visual features randomly selected and applied whatever the application domain. In this
paper we propose an approach that adapts the selection of visual features to semantic content ensuring the
coherence between them. We first design visual and semantic descriptive ontologies. These ontologies are
then explored by association rules aiming to link semantic descriptor (a concept) to a set of visual features.
The obtained feature collections are selected according to the annotated query images. Different strategies
have been experimented and their results have shown an improvement of the retrieval task based on relevant
feature selections.
1 INTRODUCTION
The development of efficient image retrieval ap-
proaches is a very active research area. Content
based image retrieval approaches (CBIR) are partic-
ularly very popular because they are automatic and
do not rely on the users to perform the retrieval pro-
cess (Liu et al., 2007). Instead, they use internal de-
scription consisting of visual feature vectors to index
images. Visual feature vectors that index the image
database are numeric information extracted from im-
age pixels using image processing and analysis tech-
niques. In literature the problem of image indexation
has been addressed using two different visual feature
categories which are common visual features and field
specific visual features (Mussarat et al., 2013).
Common visual features (low-level) can be color,
texture or shape features. They can be extracted from
a whole image (global approach) or from specific
regions (local approach) using clustering techniques
(Lavenier, 2001).
Field specific features are generally motivated by
a particular application context. For instance, to ad-
dress the face recognition problem, the Viola and
Jones detection framework has been proposed (Viola
and Jones, 2004). The work introduced in (Sarfraz
and Hellwich, 2008) propose a robust procedure for
face recognition based on a feature taking into ac-
count facial appearance shape and illumination.
Several low-level and domain specific features
have been proposed in the literature. However, the
accuracy of retrieval results remain far from users ex-
pectations (Smeulders et al., 2000). On one hand,
the adoption of sophisticated features can improve re-
sults, but highlights the high algorithms’ complexity,
the computation time and the feature vectors’ dimen-
sion problems (Vinukonda, 2011). On the other hand,
applying a large number of features disperses the re-
trieval focus and makes the process time consuming.
Our idea is to integrate a feature selection mech-
anism in the image retrieval process, aiming to guide
the selection of features to be used to index query im-
ages. The proposed selection allows retrieving im-
ages based on suitable features to the current query
image instead of applying random sets of visual fea-
tures. Our contribution consists in building feature
collections in line with specific semantic content, and
providing a dynamic selection mechanism of visual
feature sets. The selection mechanism that we pro-
pose is based on the user query annotation which is
considered by our approach as a relevant source of
semantic content description.
The remainder of this paper is organized in 3 sec-
tions. In section 2, we review some common CBIR
implementations. After discussing the study of re-
lated works, we detail our approach in section 3. The
implementations of the proposed approach as well as
the experimental results are introduced in section 4.
Finally, discussion and results analysis as well as fu-
ture works are presented in conclusion.
377
Allani O., Mellouli N., Baazaoui Zghal H., Akdag H. and Ghzala H..
A Relevant Visual Feature Selection Approach for Image Retrieval.
DOI: 10.5220/0005306303770384
In Proceedings of the 10th International Conference on Computer Vision Theory and Applications (VISAPP-2015), pages 377-384
ISBN: 978-989-758-090-1
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

2 OVERVIEW AND
MOTIVATIONS
In this section we present some related (but not ex-
haustive) works on image retrieval approaches using
low-level visual features. Then, we discuss the classi-
cal approaches problems and propose our motivations
to dynamic feature selection giving a query image.
2.1 Visual Features for CBIR
Approaches
Several low-level visual features, related to color, tex-
ture and shape; have been proposed in literature and
widely used in retrieval approaches. We review here
some common CBIR approaches.
The existing implementations of CBIR ap-
proaches are mainly based on different feature cate-
gories. The first CBIR systems rely on one feature.
Since color is an intuitive image content descriptor
and simple to extract. It was used as a basis for sev-
eral implementations.
In (Pass et al., 1996), an approach based on his-
togram with a spatial dimension has been proposed.
The experiments have been done on a large diversified
image database and have shown the improvement of
the retrieval results compared to histogram based ap-
proaches. This approach and several other approaches
rely on color histogram or some variations of it. How-
ever, these approaches store the extracted information
for each image which may require significant space.
Thus in (Paschos et al., 2003), an approach based on
the chromaticity diagram has been proposed. This ap-
proach reduces the required space and maintains the
effectiveness of the results compared to classical ap-
proaches.
Color is a restrictive parameter especially when
dealing with specific fields such as face detection or
footprint recognition. In this fields, the detection of
exact shapes seems to be necessary. Thus, another
class of approaches based on shape features has been
proposed. CBIR systems have been used for a diverse
range of images, however, shape detection algorithms
have usually been designed for special issues. We fo-
cus here on works that implement shape features for
image retrieval purpose.
In (Lin et al., 2004), an efficient and robust shape-
based image retrieval system is proposed. The Prompt
edge detection method is used to detect edge points.
Then the low-to-high sequence (LHS) shape repre-
sentation method is introduced. The results proved
the method robustness and effectiveness. But it is
worth noting that shape based approaches have higher
complexity. In (Hejazi and Ho, 2007), an image re-
trieval approach based on classical texture features,
such as orientation, directionality, and regularity has
been proposed. Their discriminant power has been
compared to the MPEG-7 texture feature through ex-
perimentation on aerial images.
Other CBIR systems combining different cate-
gories of features have been proposed. In (Jalab,
2011), a color layout and Gabor texture descriptor
based approach has been proposed. The Color Layout
Descriptor (CLD) represents the spatial distribution
of colors in an image. However, Gabor texture fea-
ture describes the texture distribution of similar col-
ors in an image. The integration of the two features
has significantly improved the retrieval performance.
Retrieval results were compared with two other ap-
proaches ((Hiremath and Pujari, 2007) and (Hafiane
and Zavidovique, 2008)) and proved to be more accu-
rate.
The approaches presented above are entirely
based on visual aspects. In fact, they focus mainly
on the problem of designing new features and find-
ing possible combinations between existing features.
These proposals do not take into account the users
perception usually expressed in textual annotations.
However, despite the large amount of approaches
such as machine learning, relevance feedback and on-
tologies, the research area is still open and new ap-
proaches appear every day. These approaches are
promising, but the use of visual features can be in-
consistent in some context with semantic descriptors.
The correlation of joint features that should be applied
is always given in order to reduce computation time of
retrieval processes, analyze feature performance or to
fit data set specificity.
Unfortunately, despite this large number of imple-
mentations, several problems persist, mainly how to
select an initial set of suitable features for a specific
semantic content. In literature, the main approaches
randomly establish a number of visual features to be
applied during retrieval (Deselaers et al., 2008), ig-
noring in someway specific semantic information re-
lated to the query image and that could be beneficial
in establishing a coherent understanding of the real
human perception.
2.2 Motivations
In the context of image indexing for retrieval pur-
poses, it can clearly be seen that content based ap-
proaches, using different features and applied on the
same image dataset, perform differently (Jalab, 2011).
As a result, the research quality heavily depends on
the selected features.
VISAPP2015-InternationalConferenceonComputerVisionTheoryandApplications
378

In addition, image retrieval systems usually estab-
lish previously a given set of visual features which
are used for any application domain. Thus, for two
queries, it is possible to obtain completely different
precision values (a high precision of retrieval results
for one and a low value for the other), although the
retrieval process relies on the same features. In this
case, semantic information deduced from image an-
notation is ignored and retrieval is performed stati-
cally without taking into account the image specific
semantic content.
Furthermore, the selection of a set of visual fea-
tures for a query image that is guided by its semantic
content can be considered as an interesting idea.
Our purpose is first to provide a set of relevant
visual features for each query image, given its seman-
tic content. This enables to improved retrieval results
accuracy, to substantially reduce the feature vectors
number and to decrease the processing time. So, the
aims of this paper can be summarized in:
• Building visual features collection according to
semantic content. These collections allow asso-
ciating, for a concept, a set of suitable visual fea-
tures that should be applied on queries containing
this concept. Suitability is deduced from the dif-
ferent application domains reviewed in literature
works.
• Integrating relevant visual feature selection dur-
ing the retrieval phase thus allowing a dynamic
retrieval process based on query image semantic
content. The feature selection uses image anno-
tation to select visual feature collection and then
extract the most relevant features.
3 RELEVANT VISUAL
FEATURES’ SELECTION FOR
IMAGE RETRIEVAL
The proposed approach is part of a research line with
wider scope, in which a hybrid retrieval approach has
been defined (Allani et al., 2014). Our idea is to use
both visual features and textual content in order to
perform a pattern-based retrieval. Our work has fo-
cused on structuring image dataset into a set of pat-
terns which are semantically and visually rich. Then
we retrieve results using similarity measure computed
between query similarity and the patterns.
Let’s consider a query image composed of the
”sky”, two ”divers”, ”ocean”, ”sand beach” and the
”clouds”. This image represents different objects and
so can be described using different visual features.
Whereas the ”sky”, the ”ocean” and the ”sand beach”
are characterized by their uniform texture, the ”diver”
and the ”clouds” are characterized by their specific
shape (shape of a person, shape of the clouds). More-
over, the image represents many meta-data character-
istics. We aim here to apply, during retrieval of sim-
ilar images, features suitable to the semantic content
and the meta-data of the image.
Shape features can be used to index images rep-
resenting shapes, same for texture. Also, meta-data
characteristics can be used to select appropriate vi-
sual features. For example a high resolution involves
a time consuming processing for feature extraction,
so features with high complexity (for example region
based shape features) should not be applied with such
images. As a result, for this specific image, using tex-
ture and shape features such as Edge Histogram and
canny edge detector which is a contour based shape
feature, can provide more relevant retrieval results be-
cause they are suitable to the query image.
The overall architecture of our approach is illus-
trated in Figure 1. The process begins with building
a set of visual features’ collections dedicated to spe-
cific concepts or meta-data characteristics. Building
process is performed given a set of annotated images
and a set of suitability rules deduced form literature.
Image dataset can be updated when new images are
added to it.
As depicted in Figure 1, our retrieval process,
based on relevant feature selection, is performed in
two phases: online and offline phases. In the next
paragraph the different steps of our retrieval approach
will be detailed.
The first step is to specify the set of candidate vi-
sual features on which selection mechanism will be
performed. Visual feature vectors are computed on
the image dataset and stored (cf. Figure 1 Step (1)).
They are then clustered into regions (cf. Figure 1 Step
(3)).
Concepts are then extracted from image annota-
tions. A disambiguation step, based on WordNet
1
, is
performed in order to retrieve the good synset (sense)
that corresponds to each word (cf. Figure 1 Step (2)).
The set of concepts associated to all of the image
dataset is stored. Finally, a unification step based on
WordNet and aiming to get common super-concepts
is performed. For example, two image annotations
containing the words ”Laguna Colorado” and ”Green
Lake” will be processed. The co-occurrences of the
two words are substituted by their lowest common an-
cestor which is ”lake”.
The previously described steps allow getting a vi-
sually and semantically indexed image dataset. Next
we define, given the semantic content of the dataset,
1
http://wordnet.princeton.edu/
ARelevantVisualFeatureSelectionApproachforImageRetrieval
379

Figure 1: Relevant visual feature selection based approach.
the visual feature collection. Image semantic content
(concepts) and meta-data are first associated to ap-
propriate visual features. These associations known
as Application rules (cf. section 3.2) define the re-
latedness between semantic content or meta-data and
low-level visual features. They are deduced from the
best practices or benchmarks collected from literature
works on CBIR implementations. In order to build a
valid set of rules, reflecting high correlation between
semantic and visual aspects, we consider about 40 lit-
erature works covering several low-level visual fea-
tures and different image datasets.
Thereafter, based on the concepts used to describe
the image dataset, we propose a mechanism for build-
ing visual features’ collections that are adapted to se-
mantic content of query images. This approach analy-
ses concept simultaneous presence frequencies to out-
line relevant visual features for a given query image.
For each concept, related concepts (used with it in
an image annotation) are collected and their presence
frequencies for each image are analysed. Inconsistent
concepts with frequencies lower than a threshold α
are removed. In contrast consistent concepts are con-
sidered to build collections of visual features based on
application rules (cf. Figure 1 Step (4)). These collec-
tions will be used next to select relevant visual feature
collection suitable to query images.
During the online phase, a query image annotated
or not is introduced. If the query image annotated,
then concepts are extracted from annotation and dis-
ambiguation is performed (cf. Figure 1 Step (5)).
When visual feature collection are selected for all the
concepts, the number of visual features can be high.
Thus, a reasoning mechanism should be applied to
keep the most relevant features (cf.Figure 1 Step (6)).
Finally, a similarity measure is used to retrieve similar
images (cf. Figure 1 Step (8)).
3.1 Visual Features, Meta-data and
Image Content Ontologies
The proposed approach takes into account the seman-
tic content and the meta-data characteristics of the
query image file, to set up relevant low-level feature
collection. In order to organize the various informa-
tion, we need to formally represent knowledge within
each of the cited domains.
Ontologies are powerful knowledge representa-
tion tools that provide an explicit specification of
knowledge in a structured and organized manner.
They allow enrichment and direct access to several
types of relationships between the different concepts
(Besbes and Baazaoui Zghal, 2014).
Thus, we propose to model three ontologies: image
semantic content, meta-data and low-level features.
First we build a semantic hierarchy integrating
concepts used to describe images textual content.
Each image in the database should be represented by
at least one concept of the image semantic content on-
tology.
Figure 2 illustrate the semantic content ontology
which is a unified characterization of images seman-
tic content. Each node of this hierarchy represents a
concept and each edge represents the relationship ”Is-
a”. An image can be described by a set of concepts
and their relationships.
Definition 1 (Image Content Ontology). Let O
C
be
the image content ontology. The ontology concepts
VISAPP2015-InternationalConferenceonComputerVisionTheoryandApplications
380
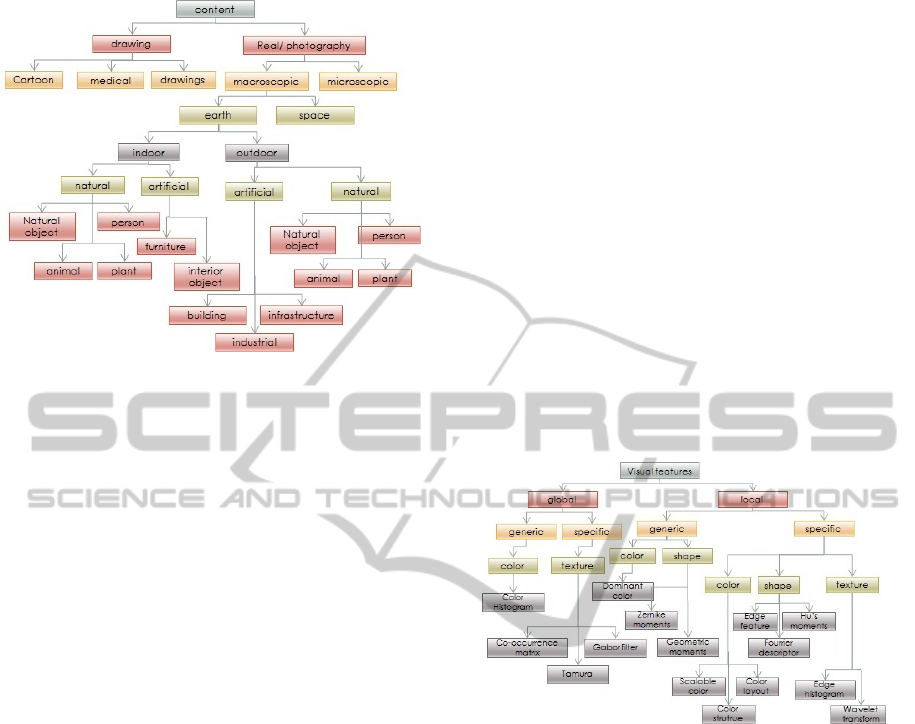
Figure 2: Image content ontology.
are noted:
C =
{
c
1
,··· , c
k
}
is the set of concepts represented by
the leaves of the ontology O
C
.
Non annotated images do not have rich semantic de-
scription, however, they rely on the surrounding tex-
tual information as meta-data. Meta-data provide use-
ful information on images namely the image author,
device, format, description, resolution etc.
We build a hierarchy to represent meta-data char-
acteristics as well as the possible values of each char-
acteristic. Image meta-data ontology is more or less
sophisticated hierarchy established to provide a uni-
fied description for image characteristics in spite of
characteristics values heterogeneous nature. In the
proposed hierarchy, nodes represent image file char-
acteristics and associated values, and edges represent
the relationship ”Is-a”. Each image is represented
with many characteristics values of the meta-data on-
tology.
Definition 2 (Meta-data Ontology). Let O
M
be the
image meta-data ontology.
Image meta-data characteristics are noted:
M =
{
m
1
,··· , m
v
}
.
A characteristic m
i
,i ∈ 1···v, m
i
is associated to
membership values.
Let V
i
be the set of possible values associated to m
i
.
V
i
=
{
v
i1
,··· , v
ik
}
defined on (M × D
m
k
∈M
) for k ∈
1···v
For example, an image has a ”high” resolution, a low
size, ”nature scene” as a title and ”JPEG” extension.
Each characteristic of the image file could be rep-
resented by a set of values (depending on the char-
acteristic domain). For example, if m
i
represents the
resolution, we associate to this characteristic the val-
ues ”low”, ”average” and ”high”.
In order to manage visual features studied in dif-
ferent literature works, we build an ontology for vi-
sual features (cf. Figure 3). This ontology has the
advantage of being extendible (a new feature or a new
use of an existing feature) and to provide an organized
description taking into account possible relationships
between features. Thus, features ontology is a unified
characterization of low-level features. it is a hierarchy
where the nodes represent features categories (shape,
color, color), application mode(global, local) and ap-
plication domains (specific, generic). Visual features
from different categories and with different use are
integrated in this hierarchy. The leaves represent vi-
sual features and the edges represent the relationship
”Is-a”.
Definition 3 (Visual Features Ontology). Let O
F
be
the visual features ontology.
We note F the set of available visual features:
F =
{
f
1
,··· , f
k
}
.
Figure 3: Visual features ontology.
3.2 Application Rules
The analysis of several literature works allowed us to
identify several feature application domains. For in-
stance, edge histogram is used in several works on
natural image datasets and provides efficient retrieval
results. Thus, we make use of this observation and ex-
tract an application rule assuming that edge histogram
is associated to natural images. Following the above
assumption, we build a set of application rules for a
set of candidate visual features related to color, shape
and texture.
We use the previously defined ontologie notations
of the concepts in rules reformulation. As a result,
each application rule is expressed according to a con-
cept from O
C
or from O
M
and a concept from O
F
.
However, application rules correspond usually to
general concepts such as nature, object or texture.
However, concepts in query image annotation are
very specific. Thus, using the image content ontology
ARelevantVisualFeatureSelectionApproachforImageRetrieval
381

as well as WordNet allows deducing implicit appli-
cation rules. For example, Building → Color-Layout
is a rule deduced from literature works. A query im-
age with a ”hospital” or a ”farm house”, which are
concepts related to building, will be associated to the
feature Color Layout.
Definition 4 (Application Rules). Let I =
{
I
1
,··· , I
N
}
is the set of images in the database where N = ]I is
the total number of images.
We note R
i
a feature application rule:
R
i
:
{
d
l
}
l∈1···p
→ c
i
, where 1 ≤ p ≤ k and such that
]
{
d
l
∈ D
}
0 .
3.3 Visual Feature Collections: Building
and Selection
As presented above, our goal is to find out relevant
features given the semantic content and to decide
which feature collection should to be applied together.
To deal with the second problem, we introduce the
collections of features idea. A collection of features
is a set of low-level features suitable to a specific con-
cept or characteristic. In order to create the feature
collection, we adopt an inductive reasoning (Akdag
et al., 2000) in which the premises seek to supply evi-
dence. In our case, the premises are the concepts used
in annotation. As previously precised, concepts used
to annotate the image dataset are unified and stored.
For each image a final set of concepts is identified.
For each concept, we extract images where this con-
cept has been used. Then, we compute appearance
frequencies of other concepts in these images. This
allows to deduce which concepts are frequently used
with the concerned concept.
Definition 5 (Feature Collection Building). Let w
i
be
the final set of concepts associated to the image I
i
.
w
i
=
{
c
i1
···c
ik
}
are the concepts in w
i
For the concept c
h
let I
h
be the set of images where c
h
exists. m is the cardinality of I
h
For the set I
h
, w
h
=
c
l1
···c
l p
are the concepts si-
multaneously used with c
h
We compute f
l1
··· f
l p
which are the numbers of oc-
currences of c
l1
···c
l p
simultaneously with c
h
from the
images in I
h
devided by m.
Concepts c
k
with f
k
≥ α are retained.
We also apply treatments on image meta-data in order
to obtain a unified description of meta-data. Finally,
on the whole image collection we compute, for every
specific concept, other concepts presence frequencies
in order to deduce the possible feature collections.
The obtained set of concepts associated to the con-
cerned concept allows to deduce the feature collec-
tion. A relationship between the concepts and the im-
age content ontology is deduced based on WordNet
relationships. Then, using these relationships we de-
duce for each concept an application rule. As a result
we obtain a set of features that we associate to the
concerned concept. It is worth noting that each col-
lection is characterized by a priority factor consisting
of the ratio of the images where the concerned con-
cept appeared and the total number of images in the
database. Moreover, image dataset update leads nec-
essarily to changing in the concepts. In this case, col-
lections update is also needed.
When a query image is introduced, image anno-
tation is processed in order to extract concepts and
use them to select relevant features to apply during
the retrieval process. To each concept, a collection of
features is proposed. In order to get the final features
collection, a reasoning step taking into account prior-
ity of the different collections is performed. Finally,
given the selected features, query image is indexed
and similarity is computed (cf. Figure 4 ).
Figure 4: Visual feature selection for image retrieval.
4 EXPERIMENTATION AND
RESULTS ANALYSIS
Our proposal has been implemented and evaluated in
order to show its interest in image retrieval. From
more technical point of view, the frameworks that
have been employed are Java as programming lan-
guage. The source codes of visual features imple-
mentations are provided by the jFeatureLib
2
and the
LIRe
3
libraries.
2
https://code.google.com/p/jfeaturelib/
3
https://code.google.com/p/lire/
VISAPP2015-InternationalConferenceonComputerVisionTheoryandApplications
382

Different strategies have been defined to allow the
evaluation of the improvement degree provided by
our approach. Query images are classified given their
content into 6 classes. On each class of query images
we perform 7 retrieval strategies given the feature(s)
categories. The goal is to get the higher precision and
recall values for a strategy conform to an image class.
For instance, the best value of precision and recall ob-
tained for textural images correspond to texture based
retrieval.
To evaluate our approach, we used the Image Clef
2013 dataset
4
. There are 117 query images (with the
qrels file) in different sizes (average image dimen-
sions: 480*360 pixels) and representing various ob-
jects and themes.
4.1 Experimental Setup
For measuring the image retrieval effectiveness we
used as evaluation metrics:
• The exact precision measure (P@10)
• The recall measure
For the experiments we apply the 7 following re-
trieval strategies: SBIR (shape strategy with canny
edge detector); TBIR (texture strategy with edge his-
togram and the Gabor filter); CBIR (color strategy
with color layout and scalable color descriptors); TS-
BIR (texture and shape strategy with edge histogram
and canny edge detector); CSBIR (color and shape
strategy with color layout and canny edge); CTBIR
(color and texture strategy with color layout and edge
histogram); SCTBIR (shape, color and texture strat-
egy with canny edge detector, color layout and edge
histogram). These strategies are applied each time on
the following 6 classes of query images in order to
evaluate the impact of our feature selection approach
given the image semantic content: S-Class ( images
with object shapes) ; T-Class (images with textures);
TS-Class (textural and shape images); CS-Class(color
and shape images); CT-Class (color and textural im-
ages); TSC-Class (texture shape and color combined
images).
4.2 Evaluation Results
Figure 5 shows the results in term of precision for
the top 10 retrieved images according to the proposed
strategies. The obtained precision result for the strat-
egy texture based image retrieval (TBIR) is clearly
higher than other strategies when applied on texture
images class (CT). The same observation could be
4
http://imageclef.org/SIAPRdata
Figure 5: Precision.
noted when the strategy applied is associated to the
image class.
Figure 6 shows the results in term of recall. The
recall values are higher for the shape and texture
based image retrieval (STBIR) strategy when applied
on the shape and texture class. This allows to de-
duce the impact of relevant feature selection on the
retrieval.
Figure 6: Recall.
To complete these results, we computed the im-
provements for image class of the adapted strategy in
front of the average precision and recall values of the
other strategies.
Figure 7 and figure 8illustrate retrieval results us-
ing the CTBIR strategy and the SCTBIR strategy.
5 CONCLUSION
In this paper, an image retrieval approach has been de-
fined. It relies on feature set collections building and
relevant feature selection mechanisms. These mech-
anisms allow a dynamic low-level feature selection
guided by the query image semantic content. In this
work, we have conducted an elementary experimen-
tal study where we are focused on the improvement
given by our approach. It is worth to be noted that
the preliminary results obtained with a targeted se-
lected features are more relevant than those obtained
ARelevantVisualFeatureSelectionApproachforImageRetrieval
383

Figure 7: Retrieval results using CTBIR strategy.
Figure 8: Retrieval results using SCTBIR strategy.
with features selected randomly. An advanced imple-
mentation and experiments are in progress to evaluate
the proposed approach: ontologies, rules and feature
building.
REFERENCES
Akdag, H., Mellouli, N., and Borgi, A. (2000). A sym-
bolic approach of linguistic modifiers. In Informa-
tion Processing and Management of Uncertainty in
Knowledge-Based Systems (IPMU).
Allani, O., Baazaoui-Zghal, H., Mellouli, N., Ben-Ghezala,
H., and Akdag, H. (2014). A pattern-based system
for image retrieval. In International Conference on
Knowledge Engineering and Ontology Development.
Besbes, G. and Baazaoui Zghal, H. (2014). Modular ontolo-
gies and cbr-based hybrid system for web information
retrieval. Journal of Multimedia Tools and Applica-
tions.
Deselaers, T., Keysers, D., and Ney, H. (2008). Features for
image retrieval: An experimental comparison. Infor-
mation Retrieval, 11.
Hafiane, A. and Zavidovique, B. (2008). Local relational
string and mutual matching for image retrieval. Infor-
mation Processing & Management, 44.
Hejazi, M. R. and Ho, Y.-S. (2007). An efficient approach
to texture-based image retrieval. International Journal
of Imaging Systems and Technology, 17.
Hiremath, P. S. and Pujari, J. (2007). P. s. hiremath and
jagadeesh pujari content based image retrieval based
on color, texture and shape features using image and
its complement.
Jalab, H. A. (2011). Image retrieval system based on color
layout descriptor and gabor filters. In Open Systems
(ICOS), 2011 IEEE Conference on. IEEE.
Lavenier, D. (2001). Paralllisation de lalgorithme du k-
means sur un systme reconfigurable application aux
images hyper-spectrales. In Traitement du Signal Vol-
ume 18.
Lin, H.-J., Kao, Y.-T., Yen, S.-H., and Wang, C.-J. (2004).
A study of shape-based image retrieval. In Distributed
Computing Systems Workshops, 2004. Proceedings.
24th International Conference on. IEEE.
Liu, Y., Zhang, D., Lu, G., and Ma, W.-Y. (2007). A sur-
vey of content-based image retrieval with high-level
semantics. Pattern Recogn., 40.
Mussarat, Y., Sharif, M., and Mohsin, S. (2013). Use of
low level features for content based image retrieval:
Survey. Research Journal of Recent Sciences, 2277.
Paschos, G., Radev, I., and Prabakar, N. (2003). Image
content-based retrieval using chromaticity moments.
Knowledge and Data Engineering, IEEE Transactions
on, 15.
Pass, G., Zabih, R., and Miller, J. (1996). Comparing im-
ages using color coherence vectors. In Aigrain, P.,
Hall, W., Little, T. D. C., and Jr., V. M. B., editors,
ACM Multimedia.
Sarfraz, M. S. and Hellwich, O. (2008). Head pose esti-
mation in face recognition across pose scenarios. In
International Conference on Computer Vision Theory
and Applications. INSTICC - Institute for Systems
and Technologies of Information, Control and Com-
munication.
Smeulders, A. W. M., Worring, M., Santini, S., Gupta, A.,
and Jain, R. (2000). Content-based image retrieval at
the end of the early years. IEEE Trans. Pattern Anal.
Mach. Intell., 22.
Vinukonda, P. (2011). A Study of the Scale-Invariant Fea-
ture Transform on a Parallel Pipeline. PhD thesis,
Louisiana State University.
Viola, P. and Jones, M. (2004). Robust real-time face detec-
tion. International Journal of Computer Vision, 57.
VISAPP2015-InternationalConferenceonComputerVisionTheoryandApplications
384
