
What Did You Mean?
Facing the Challenges of User-generated Software Requirements
Michaela Geierhos, Sabine Schulze and Frederik Simon B
¨
aumer
Heinz Nixdorf Institute, University of Paderborn, F
¨
urstenallee 11, D-33102 Paderborn, Germany
Keywords:
User-generated Natural Language Requirements, Interactive Requirement Disambiguation and Completion.
Abstract:
Existing approaches towards service composition demand requirements of the customers in terms of service
templates, service query profiles, or partial process models. However, addressed non-expert customers may
be unable to fill-in the slots of service templates as requested or to describe, for example, pre- and post-
conditions, or even have difficulties in formalizing their requirements. Thus, our idea is to provide non-
experts with suggestions how to complete or clarify their requirement descriptions written in natural language.
Two main issues have to be tackled: (1) partial or full inability (incapacity) of non-experts to specify their
requirements correctly in formal and precise ways, and (2) problems in text analysis due to fuzziness in
natural language. We present ideas how to face these challenges by means of requirement disambiguation
and completion. Therefore, we conduct ontology-based requirement extraction and similarity retrieval based
on requirement descriptions that are gathered from App marketplaces. The innovative aspect of our work is
that we support users without expert knowledge in writing their requirements by simultaneously resolving
ambiguity, vagueness, and underspecification in natural language.
1 INTRODUCTION
In the Collaborative Research Centre “On-The-Fly
Computing”, we develop techniques and processes
for the automatic ad-hoc configuration of individual
service compositions that fulfill customer-specific re-
quirements
1
. Upon request, suitable basic software
and hardware services available on world-wide mar-
kets have to be automatically discovered and com-
posed. For that purpose, customers have to provide
service descriptions.
Existing approaches towards service composition
demand requirements of the customers in terms of
service templates, service query profiles, or partial
process models. “The requirements include: list of
sub-services, inputs, outputs, preconditions and ef-
fects [...] of the sub-services, and the execution or-
der of these sub-services” (Bhat et al., 2014). More-
over, others force the customers to specify their ser-
vice requirements by using a formal specification lan-
guage. However, addressed non-expert customers,
may be unable to fill-in the slots of service templates
as requested, or to describe, for example, pre- and
post-conditions, or even have difficulties in formaliz-
1
Refer to http://sfb901.uni-paderborn.de for more infor-
mation.
ing their requirements. Furthermore, we have to deal
with partial requirements because “the person who
writes the requirements might forget to consider rel-
evant concepts of the problem, either because [he or]
she postpones their analysis, or because they are un-
clear and hard to specify, or because the input doc-
uments include too many concepts to consider them
all” (Ferrari et al., 2014).
When non-experts get the opportunity to describe
service requirements by using natural language (NL),
they produce highly individual user-generated text.
For this purpose, we develop strategies for the res-
olution of ambiguity, vagueness and incompleteness
of specifications created by non-expert users. Our
approach therefore analyzes (unrestricted) service re-
quirement descriptions written in NL on the one hand
and provides suggestions how to complete or clarify
their initial service descriptions on the other hand.
This paper is organized as follows: In Section 2,
we give a brief overview of related work and describe
the challenges in natural language processing (NLP)
for user-generated specifications in Section 3. Sec-
tion 4 outlines our approach to automatically identify
service requirements and how to counterbalance their
fuzziness. We conclude in Section 5 and present pos-
sible directions of future work in Section 6.
277
Geierhos M., Schulze S. and Simon Bäumer F..
What Did You Mean? - Facing the Challenges of User-generated Software Requirements.
DOI: 10.5220/0005346002770283
In Proceedings of the International Conference on Agents and Artificial Intelligence (PUaNLP-2015), pages 277-283
ISBN: 978-989-758-073-4
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

2 RELATED WORK
There have already been studies mining unstructured
texts represented in NL for software requirement
specifications (Meth et al., 2013; Ferrari et al., 2014).
Besides, the (in)completeness of requirements has al-
ready been an issue in NL requirement engineering
(Ferrari et al., 2014; Espana et al., 2009; Menzel et al.,
2010; Kaiya and Saeki, 2005; G
´
enova et al., 2013).
However, there is only one approach so far that gener-
ates automatic suggestions for NL requirement com-
pletion (Ferrari et al., 2014). Ferrari et al. (2014) pro-
pose the so-called Completeness Assistant Approach
(CAR) that automatically suggests relevant term can-
didates and possible relations among terms in natural
language to be used in the requirements. Unlike Fer-
rari et al. (2014), we use a domain ontology-based
approach – similar to Kaiya and Saeki (2005) – for
the NL requirement analysis. Domain ontologies are
widely used in requirement engineering due to their
significant advantages in the field of knowledge shar-
ing and reuse (Bhat et al., 2014). In particular, they
allow requirement engineers to analyze specifications
with respect to the domain-specific application se-
mantics and to detect incompleteness in requirement
documents even though they do not support rigorous
NLP techniques (Kaiya and Saeki, 2005). Unlike Fer-
rari et al. (2014) we focus not only on keyword extrac-
tion for requirement completion, but also on require-
ment dependencies within the discourse structure.
Moreover, we also consider ambiguities occurring
in user-generated requirement specifications. Since
the majority of requirements are often written in NL,
they entail ambiguity (Yang et al., 2010a). However,
some approaches focus on the prevention of ambigu-
ities in requirement descriptions rather than resolving
them (Fuchs and Schwitter, 1995; Boyd et al., 2005).
Nevertheless, there exist also strategies to reduce and
to eliminate ambiguity. Since we focus on interac-
tive disambiguation techniques, we have to mention
the works by Yang et al. (2010b) and Kiyavitskaya
et al. (2008) providing user support to resolve ambi-
guities. For instance, Yang et al. (2010b) presented a
tool that assists requirement engineers by highlight-
ing ambiguous expressions in their requirement spec-
ifications. Kiyavitskaya et al. (2008) also pursue a
similar approach. They developed a method for the
identification and measurement of ambiguity in re-
quirement documents written in NL. In particular, all
sequences which were recognized as probably am-
biguous in a certain sentence are shown to the user.
This warning gives the user the opportunity to remove
them and thus improve the initial requirement speci-
fications. However, this approach does not cover se-
mantic ambiguity since this requires deep language
understanding which is beyond the scope of this tool.
Discovering the sources for ambiguity is another
research topic Gleich et al. (2010) concentrate on.
Their tool provides “for every detected ambiguity [...]
an explanation why the detection result represents a
potential problem” (Gleich et al., 2010). In compar-
ison to the other approaches, this technique is able
to identify lexical, syntactic, semantic and pragmatic
ambiguity which usually occur in NL (Gleich et al.,
2010). By means of lexical and syntactic shallow
parsing, they process the unstructured NL require-
ment documents (that also do not have any grammati-
cal restrictions). Furthermore, they use the Ambiguity
Handbook (Berry et al., 2003) and Siemens-internal
guidelines for requirements writing as gold standard
in order to detect ambiguities.
However, the target group of users that we address
might not be able to resolve possible ambiguities on
their own, even if some information is provided where
to spot the ambiguity. Those customers have no prior
knowledge of requirement engineering and need sup-
port in terms of disambiguated requirement descrip-
tions. Besides, functional and non-functional require-
ments, system goals or design information may not
be clearly distinguished by non-experts. They de-
scribe specifications in different ways than experts do.
That’s why we have to create a gold standard of non-
expert service descriptions in order to detect ambi-
guity, vagueness, variability and underspecification in
requirements written in NL.
3 CHALLENGES IN NLP
We have to face various problems when non-experts
specify requirements by using NL. According to
Sommerville (2010), there are (1) ambiguity, (2) vari-
ability and (3) vagueness in requirement descriptions
which are illustrated by selecting examples from Fig-
ure 1.
1. If requirements are not expressed in a precise and
unambiguous way, they may be misunderstood.
(E.g., “hide” in Figure 1 means to make some-
thing invisible on a screen, but it can also mean
“hide and seek” in a gaming context.)
2. Requirements specifications represented in NL
are overflexible. One can say the same thing in
completely different ways. (E.g., “choose pho-
tos” could also be expressed as “select photos”.)
3. Several different requirements may be expressed
together as a single requirement but have to be
separated for NLP. (E.g., “save and share your
ICAART2015-InternationalConferenceonAgentsandArtificialIntelligence
278

Figure 1: Sample service requirement description written in natural language
2
.
edited images” contains two requirement descrip-
tions “save your edited images” and “share your
edited images” in one sentence.)
Hence, ambiguity, underspecification and vagueness
can lead to misunderstandings between customers and
developers. This is also one of the main reasons
why personalized software is not meeting user re-
quirements (Murtaza et al., 2013). Nevertheless, the
accurate capture of requirements from NL specifica-
tions is an essential step in the software development
process because incorrect requirement definitions in-
evitably lead to problems in system implementation
and design (Ilieva and Ormandjieva, 2005). The need
to face the challenges in NLP of requirement descrip-
tions becomes even more clear when considering that
software requirements are commonly written in NL
due to its expressiveness (Meth et al., 2013). In the
following three sections, we discuss these issues for
processing NL requirements in more detail.
3.1 Ambiguity
“Ambiguity is a pervasive phenomenon in natural lan-
guage, and thus in natural language requirements doc-
uments” (Yang et al., 2011). It is the possibility of
interpreting an expression in two or more distinct
ways. If an expression is ambiguous, then there still
remains uncertainty of its meaning or intention in a
certain context. Because of that, ambiguity is prob-
lematic for computational semantics and for NLP, es-
2
http://iosnoops.com/appinfo/x/597847507
pecially when their various interpretations have to
be identified by algorithms. Even worst, ambiguous
expressions can be misinterpreted by developers or
custom service providers, and thus, can lead to pro-
viding customers with wrong software and/or hard-
ware packages. In the requirement description above
(cf. Figure 1), an example for an ambiguous word is
“brushes”. Depending on the context, “brush“ has
different meanings. According to an English dictio-
nary, it is most commonly used in the sense of sweep-
ing with a broom. However, it can also be defined as
a tool for painting (i.e. image editing).
3.2 Underspecification
Requirements written in NL are underspecified if fea-
tures are omitted in underlying representations (Fab-
brini et al., 2001). The concept of underspecification
is particularly used to refer to cases in which require-
ments represented in NL do not bear an entire set of
feature-values, and are thus compatible with a wide
range of potential semantic interpretations. In addi-
tion, ambiguity can cause underspecification which
leads to difficulties in formal representation and pro-
cessing of service requirements. Therefore, “it is
important to use computational representations that
preserve the information available in ambiguous and
underspecified expressions, without distorting or in-
terpreting them incorrectly” (Loukanova, 2013). An
example for underspecification shown in Figure 1 is
“share” in the expression “share your edited images”
because it is not clear via which channel the images
WhatDidYouMean?-FacingtheChallengesofUser-generatedSoftwareRequirements
279

can be shared. Possible options would be e-mail or
social media platforms like Facebook.
3.3 Vagueness
Vagueness occurs when a phrase has a single meaning
from grammatical point of view, but still leaves room
for interpretation but, when considered as a require-
ment, leaves room for varying interpretations. “The
system should react as fast as possible provides an ex-
ample of such a vague phrase” (Gleich et al., 2010). It
is important that vaguely expressions of requirements
are detected. Further examples taken from Figure 1
are “different size of brushes”’ and “with pixel accu-
racy” because it is not specified which sizes or what
degree of accuracy are meant exactly. By timely de-
tection, they can be either prevented, e.g., by inter-
actions with the customers, or represented in a for-
mal way without imposing misinterpretations or over-
interpretations.
4 APPROACH
In the customers’ descriptions of requirements for
a certain domain-specific service, we first have to
extract the relevant specifications from their input
texts (cf. Section 4.1). Then, the user-generated re-
quirements written in NL are analyzed for ambigu-
ity, vagueness (cf. Section 4.2) and underspecifica-
tion (Section 4.3) before providing suggestions how
to improve or complete their initial requirements (cf.
Section 4.4).
4.1 Ontology-based Requirement
Extraction from Descriptions
The core topic of this task is the extraction of re-
quirements from service descriptions represented in
NL produced by customers as plain text in terms of
full sentences or phrases (cf. Figure 2). The goal of
this step is to discover and structure relevant domain-
specific information about service specifications in
the user-generated texts.
The decision criteria, determining what rele-
vant information is, comes from domain-specific
ontologies that underlie the service specifications
3
which determine the available, relevant informa-
tion, coming from requirement descriptions repre-
sented in NL. Moreover, the requirement extrac-
tion is supported by domain-specific terms and rules
3
For more information refer to http://sfb901.upb.de/
sfb-901/projects/project-area-b/tools/service-specification-
environment.html.
(∃x[image(x)∧save(x)∧share(x)]) to include further
information types that have to be extracted. Thereby,
we apply semantic-syntactic patterns in order to rec-
ognize concepts and relations within the requirement
descriptions written in NL. These semantic-syntactic
patterns are represented by local grammars. Local
grammars have the capability to describe semantic-
syntactic structures that cannot be formalized in elec-
tronic dictionaries. They are represented by directed
acyclic graphs and implemented as finite state trans-
ducers (Geierhos, 2010). These transducers produce
output in terms of semantic annotations (i.e. labels)
for recognized requirements and evaluative expres-
sions in the review texts. The grammar rules can
be instantiated with high-frequent n-grams and then
are generalized. For a comprehensive analysis of ser-
vice descriptions with simultaneous pattern genera-
tion, optimal feature combinations can be automati-
cally determined by means of machine learning tech-
niques
4
. These patterns (i.e. local grammars) are then
applied to enhance the requirement extraction process
for a better data coverage.
In order to provide large training corpora from
scratch, service descriptions from online App mar-
ketplaces (e.g. Google Play) are gathered. A data
set of similar size cannot be collected in a short time
only by user input. These texts contain various ser-
vice descriptions from different domains and help us
to cover different variations in the requirement texts
(as described in Section 3). Besides they simultane-
ously serve as reference corpora (so-called test cor-
pora) for the disambiguation and compensation of the
user-generated underspecification within their service
descriptions (cf. Section 4.3). After annotating a
small amount of training data, we automatically in-
duce rules (represented by local grammars) from this
therefor built sub-corpus of service descriptions. Be-
fore applying those rules to the non-annotated part of
our corpora for the instantiation of the correspond-
ing service description templates, we have to abstract
from the given (annotated) service requirement sam-
ples (Geierhos, 2010). When using semi-supervised
machine learning techniques due to the small amount
of annotated training data, we have to collect a large
amount of unstructured service descriptions in order
to get reliable results. But for the given input – indi-
vidual specifications by non-experts – we have no ac-
cess to a reference corpus. We therefore plan to simul-
taneously apply a bootstrapping approach based on
predefined requirement patterns on the non-annotated
user input. That way, we want to determine the most
suitable extraction method for the given use case.
4
There are other approaches, but they are out of scope
of this paper.
ICAART2015-InternationalConferenceonAgentsandArtificialIntelligence
280
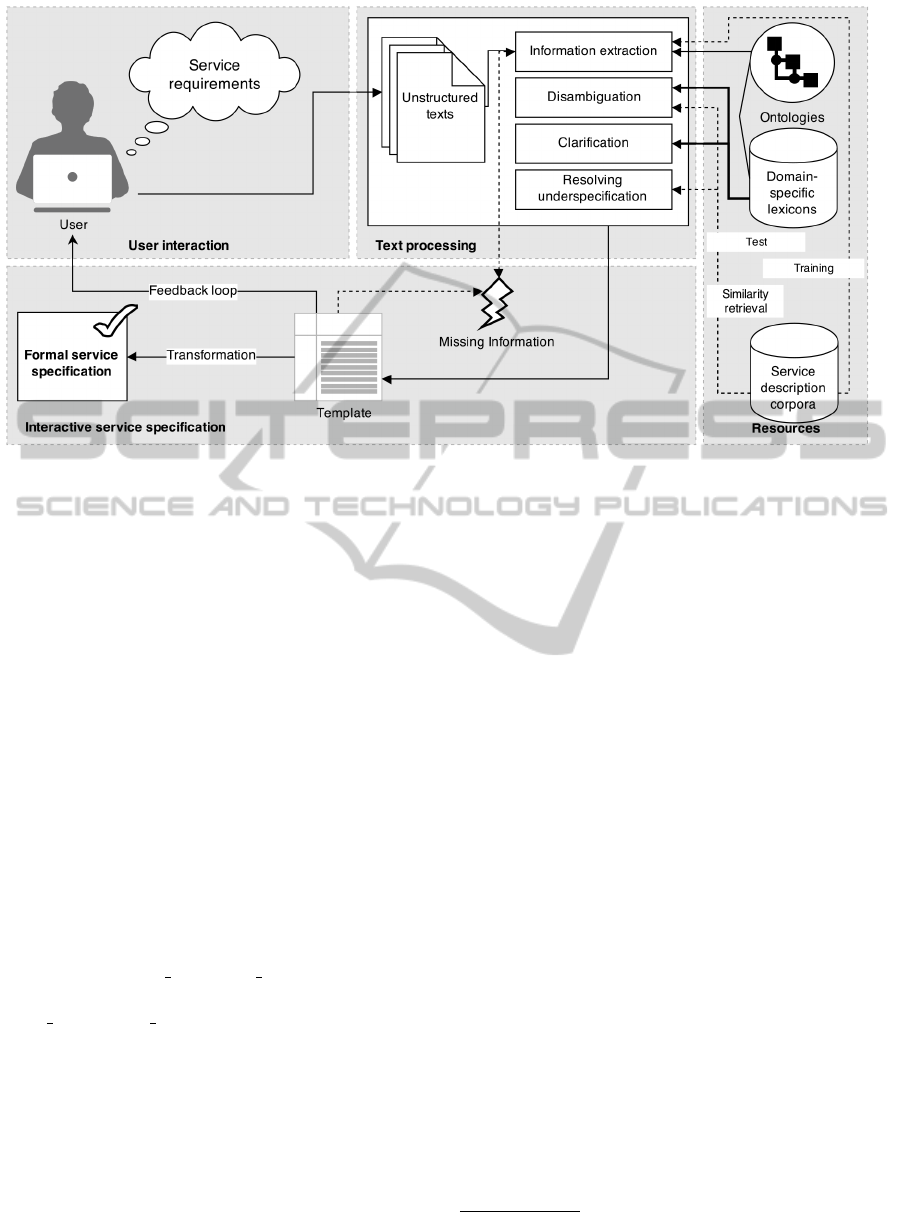
Figure 2: Pipeline for service requirement analysis using NLP
4.2 Disambiguation and Clarification
After providing requirement representations in terms
of templates (cf. Figure 2), strategies for disambigua-
tion and resolution of vagueness (i.e. clarification of
what, e.g., “different sizes” means in Figure 1) in de-
scriptions represented in NL have to be developed.
First of all, it is necessary to create test corpora out
of service descriptions. We therefore have to manu-
ally annotate all ambiguous and/or vague expressions
in the test data built from a few randomly-chosen ser-
vice descriptions, before classifying the other occur-
rences by means of co-training. The degree of vague-
ness depends on the valence of the predicates and
their unspecified arguments as well as on the impreci-
sion of the term extensions.
When applying the local grammars originally de-
veloped for requirement extraction in Section 4.1
on the test corpora, we can detect free arguments
(∃x[image(x)∧save(x, )∧share(x, )]) in service de-
scriptions using predicate-argument-tuples such as
save(x, ) or share(x, ) if details are provided where to
save or how to share (Choi et al., 2012). Apart from
lexical ambiguity, unfilled argument positions are
good indicators for syntactic ambiguity and vague-
ness because of imprecise information. This way, it
can be automatically identified which arguments (es-
pecially their position and semantic type) are still un-
specified for certain predicates within requirement de-
scriptions represented in NL (i.e. unfilled slots in the
template created after requirement extraction). On
the one hand, this step lays the foundations to deter-
mine the correct context-sensitive reading and to dis-
ambiguate the initial user-generated requirement de-
scriptions.
On the other hand, the number of unfilled slots
can be quantified (amount of free arguments) and we
get insights in the probability of the domain-specific
sense of predicate-argument-tuples representing re-
quirements.
4.3 Resolving Underspecification
Every user-generated NL requirement description of
a service is unique. By extracting its main compo-
nents, it loses its individuality. With every further
non-expert user, new requirements or at least vari-
ants of already known requirements
5
will extend the
repository of formal expressions, components, and
templates. Since our NL requirement extraction pro-
cess (cf. Section 4.1) works iteratively, we gener-
ate and instantiate templates (so-called requirement
scenarios) per description text. In this step of re-
solving underspecification, all resulting requirement
scenarios are aggregated. Here, our goal is to auto-
matically detect semantic similarities in requirement
patterns for their assignment to domain-specific ser-
vice classes such as “issue tracking system” or “event
management”. Furthermore, we perform similarity
retrieval on this repository in order to provide sugges-
tions for completion of requirements written in NL.
5
Service requirement descriptions collected by user in-
put or gathered from online App marketplaces.
WhatDidYouMean?-FacingtheChallengesofUser-generatedSoftwareRequirements
281

Since the repository grows incrementally, it is not
possible at the beginning of the extraction process to
apply a common classifier for feature learning. Due
to a lack of comparative scenarios statistical similar-
ity measures are not suitable. Therefore, a seed list
of classification rules (similarity criteria) is generated
on the basis of instances and semantic-syntactic pat-
terns identified during the requirement extraction pro-
cess (cf. Section 4.1). Moreover, it has to be inves-
tigated in how far already existing (fuzzy) matching
techniques can be applied for this.
4.4 Interactive Service Specification
Based on our findings, subsequently methods for
completion and disambiguation of requirement spec-
ifications are developed through user interaction. In
this step, incomplete requirement specifications are
compared to similar scenarios, in order to automati-
cally complete them (if necessary). Especially in the
course of the pattern matching during the requirement
extraction process, templates cannot be fully instanti-
ated if there is missing information. This can lead
to gaps in the structured requirement representations
which have to be compensated before they are trans-
formed into the formal service specification.
4.4.1 Similarity Retrieval for Auto-Completion
On the one hand, incomplete requirement specifica-
tions are matched with similar requirement scenarios
(cf. Section 4.3) in order to complete them if nec-
essary. Especially in case of the pattern matching
(cf. Figure 2) the templates cannot be instanced com-
pletely in case of missing information of the end user.
This may sometimes lead to unfilled slots in the struc-
tured representations, which have to be avoided in or-
der to describe a configurable service.
4.4.2 Suggestion Generation for Disambiguation
The most probable readings based on the grammar
analysis are suggested to the non-expert users. Then,
they take on the role of the trainer for the purpose
of validating identified ambiguities in the service de-
scription corpora. This way, it is ensured that no
incorrect readings are learned. In case of require-
ments being so vague that too many grammatical pat-
terns would be possible, paraphrases are generated
based on domain-specific similarities in the require-
ment scenarios.
4.4.3 Non-expert User Feedback
It is assumable that non-experts in requirement engi-
neering will not define the pre- and post conditions or
signatures when formulating their requirements. In
case of missing requirement scenarios, we ask the
users how to complete and specify their initial ser-
vice descriptions. However, when the users do not
provide this information, we cannot transform the re-
quirement represented in NL into the formal service
specification. As soon as the users provide additional
information, we have to restart the extraction, disam-
biguation and clarification process.
5 CONCLUSION
In the context of non-expert customers describing
their service requirements, two main issues have to
be tackled: (1) The incapability of non-experts to
specify their requirements and (2) the challenges that
arise when analyzing these requirements represented
in NL such as ambiguity, vagueness and underspec-
ification. This paper presented ideas how to face
these challenges by means of ontology-based infor-
mation extraction and similarity retrieval based on a
requirement description written NL corpora gathered
from App marketplaces. In particular, these strate-
gies are also partially supported by user interaction.
The overall goal of this approach is to support non-
experts with suggestions how to complete or clarify
their service descriptions while resolving ambiguity,
vagueness and underspecification that often occur in
requirements written in NL.
6 FUTURE WORK
A major direction of future work is the development
of a gold standard of non-expert service descriptions
in order to detect ambiguity, vagueness, and under-
specification in requirements written in NL. There-
fore, we first have to create a database of requirements
represented in NL which we plan to aggregate from
service descriptions on App marketplaces. Further-
more, it will be interesting to investigate in how far
existing matching approaches and approaches for re-
quirement reuse can be applied for the disambigua-
tion and completion tasks. Moreover, with regard
to disambiguation of requirement descriptions repre-
sented in NL we plan to explore how to refine our
disambiguation strategies with regard to existing dis-
ambiguation approaches.
ICAART2015-InternationalConferenceonAgentsandArtificialIntelligence
282

ACKNOWLEDGEMENTS
This work was partially supported by the German
Research Foundation (DFG) within the Collaborative
Research Centre 901 “On-The-Fly Computing”.
REFERENCES
Berry, D. M., Kamsties, E., and Krieger, M. M. (2003).
From contract drafting to software specification: Lin-
guistic sources of ambiguity. https://cs.uwaterloo.ca/
%7Edberry/handbook/ambiguityHandbook.pdf.
Bhat, M., Ye, C., and Jacobsen, H.-A. (2014). Orchestrating
SOA Using Requirement Specifications and Domain
Ontologies. In Service-Oriented Computing, pages
403–410. Springer.
Boyd, S., Zowghi, D., and Farroukh, A. (2005). Measuring
the expressiveness of a constrained natural language:
an empirical study. In Proceedings of the 13th IEEE
International Conference on Requirements Engineer-
ing, pages 339–349. IEEE.
Choi, S.-P., Song, S.-K., Jung, H., Geierhos, M., and
Myaeng, S. (2012). Scientic Literature Retrieval
based on Terminological Paraphrases using Predicate
Argument Tuple. Advanced Science and Technology
Letters, 4:371–378. Information Science and Indus-
trial Applications.
Espana, S., Condori-Fernandez, N., Gonzalez, A., and Pas-
tor,
´
O. (2009). Evaluating the completeness and gran-
ularity of functional requirements specifications: a
controlled experiment. In Requirements Engineering
Conference, 2009. RE’09. 17th IEEE International,
pages 161–170. IEEE.
Fabbrini, F., Fusani, M., Gnesi, S., and Lami, G. (2001).
An automatic quality evaluation for natural language
requirements. In Proceedings of the Seventh In-
ternational Workshop on Requirements Engineering:
Foundation for Software Quality (REFSQ), volume 1,
pages 4–5.
Ferrari, A., dell’Orletta, F., Spagnolo, G. O., and Gnesi, S.
(2014). Measuring and Improving the Completeness
of Natural Language Requirements. In Requirements
Engineering: Foundation for Software Quality, pages
23–38. Springer.
Fuchs, N. E. and Schwitter, R. (1995). Specifying logic pro-
grams in controlled natural language. In Proceedings
of the Workshop on Computational Logic for Natural
Language Processing, pages 3–5. Arxiv.
Geierhos, M. (2010). BiographIE – Klassifikation und Ex-
traktion karrierespezifischer Informationen, volume 5
of Linguistic Resources for Natural Language Pro-
cessing. Lincom, Munich, Germany.
G
´
enova, G., Fuentes, J. M., Llorens, J., Hurtado, O., and
Moreno, V. (2013). A framework to measure and im-
prove the quality of textual requirements. Require-
ments Engineering, 18(1):25–41.
Gleich, B., Creighton, O., and Kof, L. (2010). Ambigu-
ity detection: Towards a tool explaining ambiguity
sources. In Requirements Engineering: Foundation
for Software Quality, pages 218–232. Springer.
Ilieva, M. and Ormandjieva, O. (2005). Automatic transi-
tion of natural language software requirements speci-
fication into formal presentation. In Natural Language
Processing and Information Systems, pages 392–397.
Springer.
Kaiya, H. and Saeki, M. (2005). Ontology based require-
ments analysis: lightweight semantic processing ap-
proach. In Proceedings of the Fifth International Con-
ference on Quality Software (QSIC 2005), pages 223–
230. IEEE.
Kiyavitskaya, N., Zeni, N., Mich, L., and Berry, D. M.
(2008). Requirements for tools for ambiguity iden-
tification and measurement in natural language re-
quirements specifications. Requirements Engineering,
13(3):207–239.
Loukanova, R. (2013). Algorithmic granularity with con-
straints. In Brain and Health Informatics, pages 399–
408. Springer.
Menzel, I., Mueller, M., Gross, A., and Doerr, J. (2010).
An experimental comparison regarding the complete-
ness of functional requirements specifications. In Pro-
ceedings of the 18th IEEE International Requirements
Engineering Conference (RE), pages 15–24. IEEE.
Meth, H., Brhel, M., and Maedche, A. (2013). The state
of the art in automated requirements elicitation. Infor-
mation and Software Technology, 55(10):1695–1709.
Murtaza, M., Shah, J. H., Azeem, A., Nisar, W., and Ma-
sood, M. (2013). Structured Language Requirement
Elicitation Using Case Base Reasoning. Research
Journal of Applied Sciences, Engineering and Tech-
nology, 6(23):4393–4398.
Sommerville, I. (2010). Software Engineering. Addison-
Wesley, Harlow, England, 9th edition.
Yang, H., De Roeck, A., Gervasi, V., Willis, A., and
Nuseibeh, B. (2010a). Extending nocuous ambigu-
ity analysis for anaphora in natural language require-
ments. In Proceedings of the 18th IEEE International
Requirements Engineering Conference (RE), pages
25–34. IEEE.
Yang, H., De Roeck, A., Gervasi, V., Willis, A., and Nu-
seibeh, B. (2011). Analysing anaphoric ambiguity in
natural language requirements. Requirements Engi-
neering, 16(3):163–189.
Yang, H., Willis, A., De Roeck, A., and Nuseibeh, B.
(2010b). Automatic detection of nocuous coordina-
tion ambiguities in natural language requirements. In
Proceedings of the IEEE/ACM international confer-
ence on Automated software engineering, pages 53–
62. ACM.
WhatDidYouMean?-FacingtheChallengesofUser-generatedSoftwareRequirements
283
